1, What is sharding JDBC
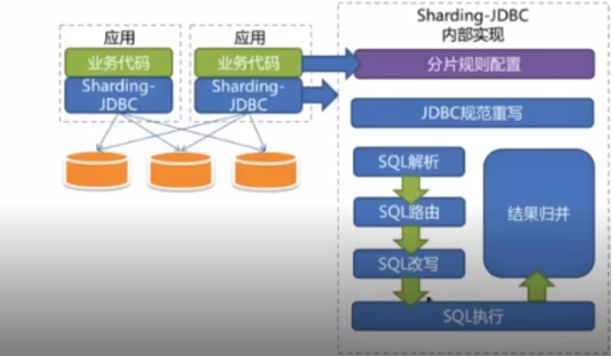
Sharding JDBC is an open source distributed database middleware developed by Dangdang. Sharding JDBC has been included in sharding sphere since 3.0, and the version after 4.0 is Apache.
ShardingSphere is an ecosystem composed of a set of open-source distributed database middleware solutions. It is composed of three independent products: sharding JDBC, sharding proxy and sharding sidecar. They all provide standardized data fragmentation, distributed transactions and database governance capabilities.
Sharding JDBC is positioned as a lightweight Java framework and provides additional services in the JDBC layer of Java. It uses the client to directly connect to the database and provides services in the form of JAR package without additional deployment and dependency. It can be understood as an enhanced jdbc driver and is fully compatible with JDBC and various ORM frameworks.
The core function of sharding JDBC is data fragmentation and read-write separation. Through sharding JDBC, applications can transparently use JDBC to access various data sources that have been divided into databases, tables and read-write separation, without caring about the number of data sources and how the data is distributed.
2, Sub database and sub table
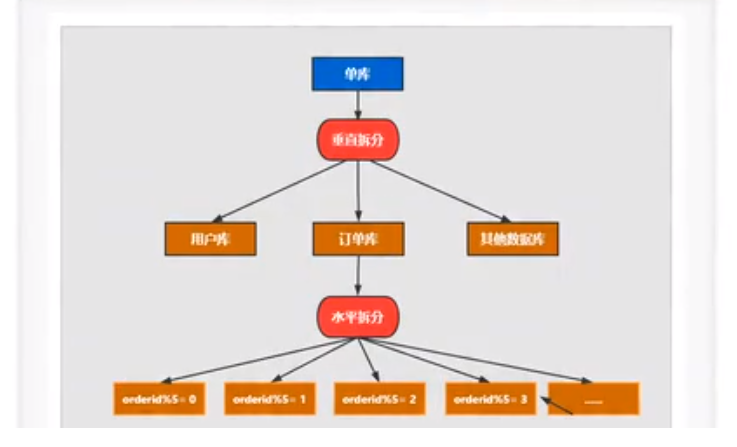
The purpose of sub database and sub table is to solve the problem of large amount of data storage of Internet applications. The sub table is usually divided into: vertical division and horizontal division; Vertical partition usually splits a large multi field table into multiple small tables with few fields according to the business scenario. Horizontal partition is the discrete storage of data. According to a partition strategy, the data of the same table is stored separately in multiple tables with the same structure.
3, What are the sharding algorithms provided by sharding?
`StandardShardingStrategy` Standard fragmentation strategy. `InlineShardingStrategy` Inline Expression fragmentation strategy. use Groovy of Inline expression. `HintShardingStrategy` adopt Hint Not SQL The method of analysis and the strategy of segmentation. `NoneShardingStrategy` No fragmentation strategy.
4, How to use sharding JDBC to store data discretely?
The use of InlineShardingStrategy;
Step 1: introduce relevant pom dependencies
<dependency> <groupId>io.shardingsphere</groupId> <artifactId>sharding-jdbc-spring-boot-starter</artifactId> <version>3.1.0</version> </dependency> <dependency> <groupId>io.shardingsphere</groupId> <artifactId>sharding-jdbc-spring-namespace</artifactId> <version>3.1.0</version> </dependency>
The second step is to prepare two databases. There are two tables under db0 and db1. Their structures are the same, but their names are different
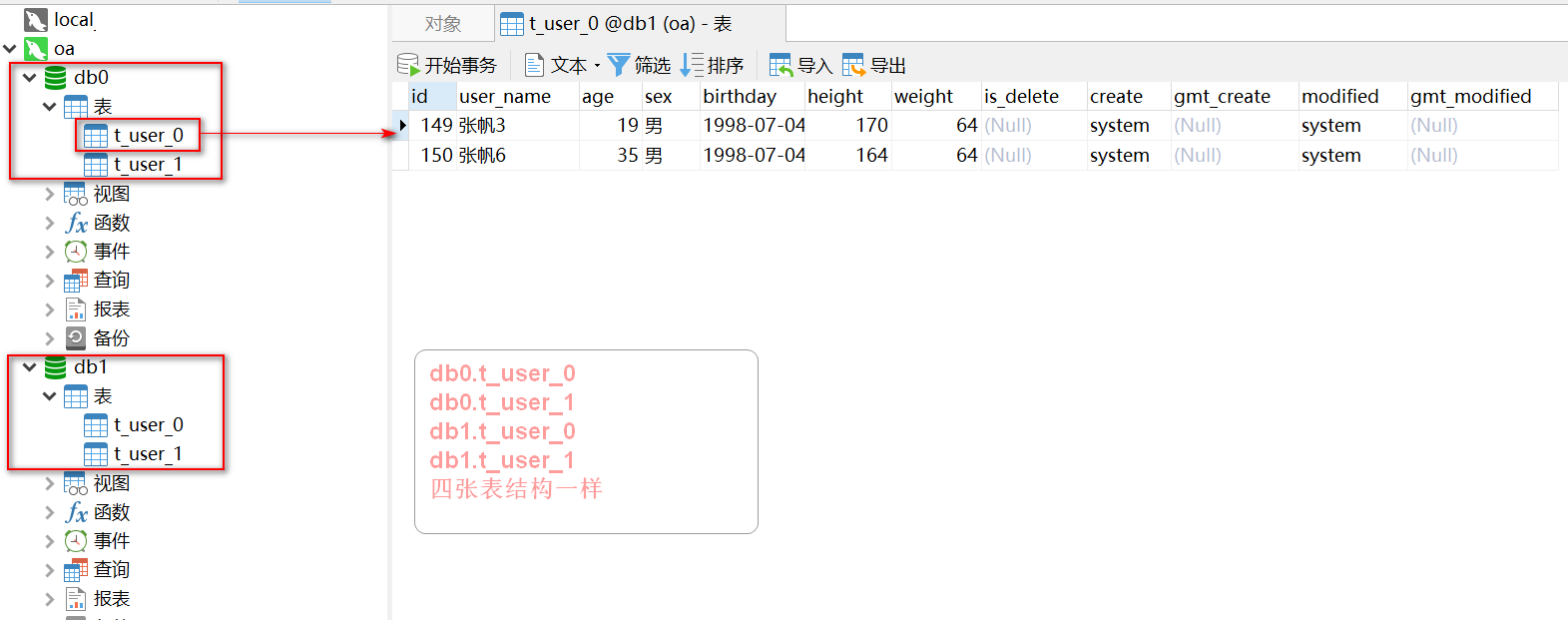
Step 3: configure the yml file IN the yml file sharding jdbc. Datasource: connect two database data sources under configuration. If there are more sub databases, the configured connection can also be increased, and then sharding Default database strategy: configure the strategy of sub database and sub table. The strategy column of sub database and sub table is groovy row expression and Inline expression fragmentation strategy. Groovy's Inline expression is used to provide slicing support for = and IN in SQL statements
app:
id: zt-frank-shardingSphere-service-9960
name: zt-frank-shardingSphere-service-9960
server:
port: 9960
spring:
application:
name: zt-frank-shardingSphere-service-9960 #Spring of 7001, 70027003 is required for Ribbon load balancing application. The name of name is consistent
main:
allow-bean-definition-overriding: true #Allow Bean to inject repeatedly, and the latter overrides the former
#Start configuring connection database
sharding:
jdbc:
datasource:
names: db0,db1
db0:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://localhost:3306/db0?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone = GMT
username: root
password: password
db1:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://localhost:3306/db1?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone = GMT
username: root
password: password
config:
props:
sql.show: true #Print sql
#Start configuring the policy column of sub database and sub table
sharding:
default-database-strategy: #Default sub database policy
inline:
sharding-column: age #Divide the database by age. Note that the data type corresponding to dto needs to be a number, because modular operation is required here. If it is String, the database will not be found and an error will be reported
algorithm-expression: db$->{age % 2} #Using Groovy expressions
tables:
t_user:
actual-data-nodes: db$->{0..1}.t_user_$->{0..1} #Actual node (data source: two data sources are configured above, db0 and db1)
table-strategy: #Table splitting strategy
inline:
sharding-column: height #Slice field Height (slice key)
algorithm-expression: t_user_$->{height % 2}
Step 4: write code to insert data
t_ DO of user logical table,
Mybatis plus is used here. Note that the table name of @ TableName("t_user") is a logical table, and there is no t in the database_ For the user table, sharding JDBC will parse - route - rewrite the original sql according to the fragmentation rules configured in the yml file to match the real table of the database. If you write sql, the xml file is also written t_ user
@Data
@AllArgsConstructor
@NoArgsConstructor
@TableName("t_user") //Although there is no t in the database_ User table, is t_user_0,t_user_1. However, there can be no suffix here, including the mapper file for writing sql, and the table name is also t_user
public class UserDO {
@TableId(value = "id", type = IdType.AUTO)
private Integer id;
private String userName;
private Integer age;
private String sex;
private Integer height;
private Integer weight;
private Date birthday;
private String isDelete;
private String create;
private Date gmtCreate;
private String modified;
private Date gmtModified;
}
service layer
@Override
public Boolean saveUser(UserReqDTO req) {
UserDO userDO = new UserDO();
BeanUtils.copyProperties(req,userDO);
System.out.println("UserDO:"+userDO.toString());
int i = userDao.insert(userDO);
return i>0;
}
controller layer
@PostMapping("/save/user")
public Boolean saveUser(@Valid @RequestBody UserReqDTO req){
logger.info("Save user start:"+req.toString());
Boolean bool = userService.saveUser(req);
logger.info("Save user end:"+req);
return bool;
}
Step 5; Testing;
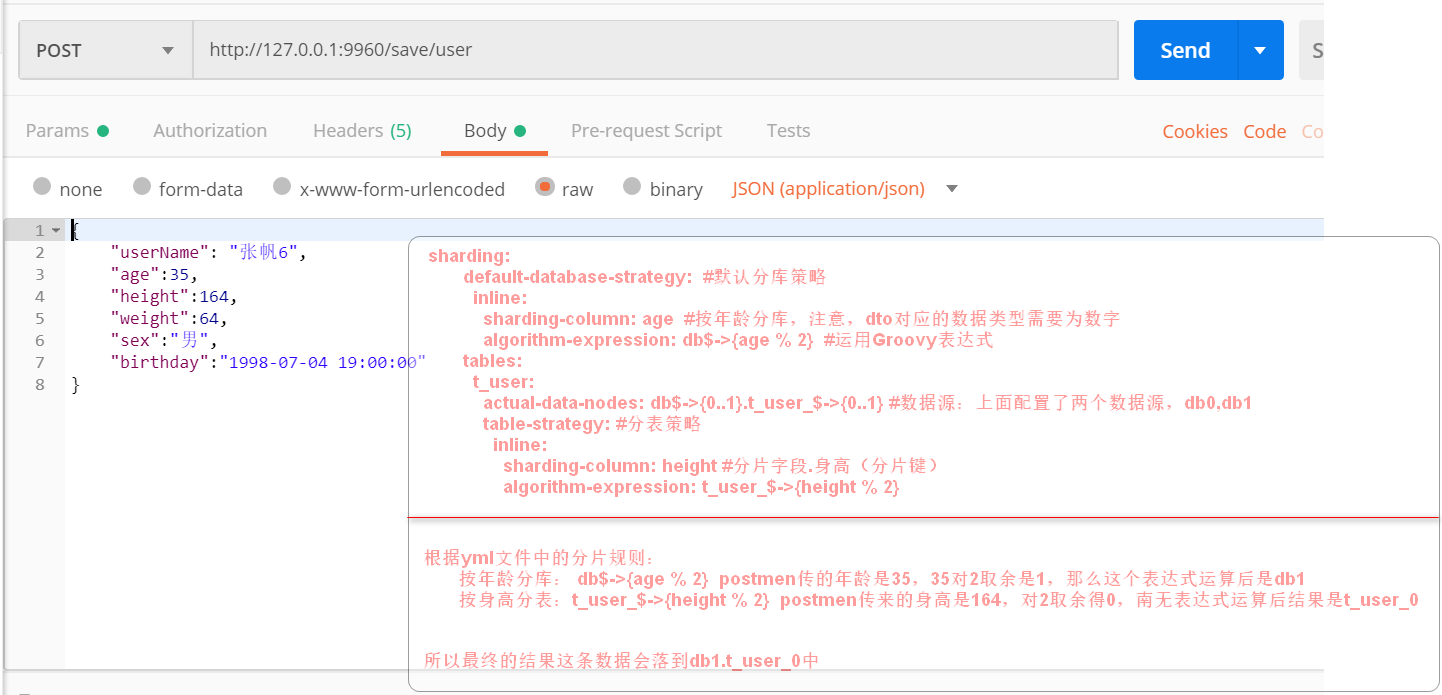
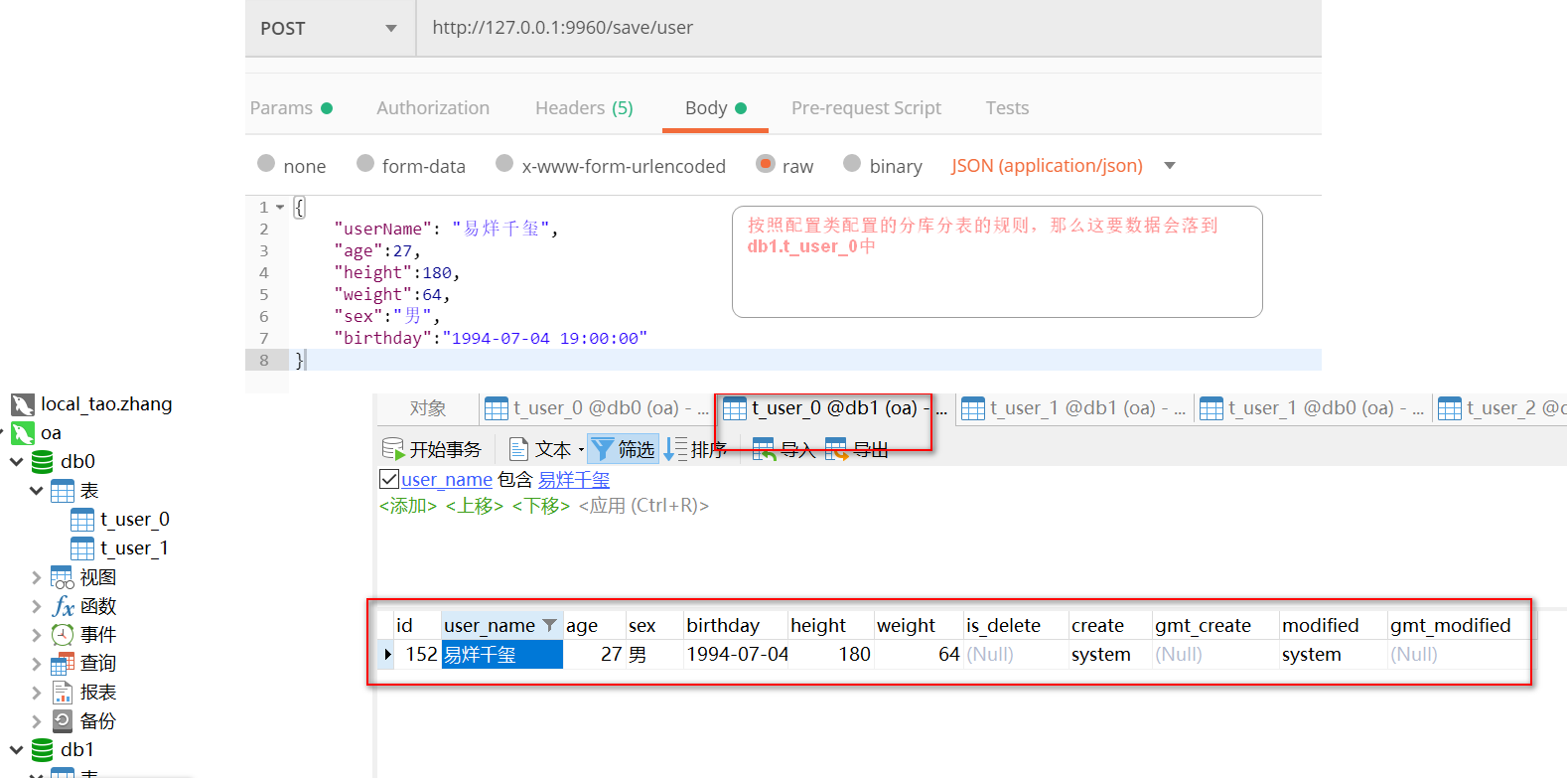
5, The above rules of sub database and sub table are configured in the yml file. When the business scenario of some sub database and sub table is complex, the logic of sub database and sub table can be replaced by code, and the standard (standard sharding strategy) standard fragmentation strategy
StandardShardingStrategy ` use of standard fragmentation strategy
Step 1: change the yml file and adopt the standard sharding strategy
sharding:
jdbc:
datasource:
names: db0,db1
db0:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://localhost:3306/db0?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone = GMT
username: root
password: password
db1:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://localhost:3306/db1?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone = GMT
username: root
password: password
config:
props:
sql.show: true #Print sql
sharding:
default-database-strategy: #Default sub database policy
# inline:
# sharding-column: age #Divide the database by age. Note that the data type corresponding to dto needs to be a number, because modular operation is required here. If it is String, the database will not be found and an error will be reported
# algorithm-expression: db$->{age % 2} #Using Groovy expressions
standard:
sharding-column: age
precise-algorithm-class-name: com.zt.frank.config.SubDBConfig #The sub database rules are configured in the class
tables:
t_user:
actual-data-nodes: db$->{0..1}.t_user_$->{0..1} #Actual node (data source: two data sources are configured above, db0 and db1)
table-strategy: #Table splitting strategy
# inline:
# sharding-column: height #Slice field Height (slice key)
# algorithm-expression: t_user_$->{height % 2}
standard:
sharding-column: height
precise-algorithm-class-name: com.zt.frank.config.SubTableConfig #Table splitting rules are configured in classes
Part II: writing configuration classes
Sub database configuration class:
/**
* Sub database configuration
*
* When the sub library rules configured by yml cannot be met, the code can be used to configure the sub rule, and the PreciseShardingAlgorithm interface needs to be implemented,
* yml The configuration file sub library configuration will reference this class
*/
public class SubDBConfig implements PreciseShardingAlgorithm<Integer> {
private static Logger logger = Logger.getLogger(SubDBConfig.class);
@Override
public String doSharding(Collection<String> collection, PreciseShardingValue<Integer> preciseShardingValue) {
Integer value = preciseShardingValue.getValue();
Object[] objects = collection.toArray();
if((value % 2) == 0){
logger.info("Library name:"+objects[0]);
return objects[0]+"";
}else{
logger.info("Library name:"+objects[1]);
return objects[1]+"";
}
}
}
Table configuration class
/**
* Sub table configuration
*
* When the table splitting rules configured by yml cannot be met, the code can be used to configure the segmentation rules, and the PreciseShardingAlgorithm interface needs to be implemented
* yml The configuration file table configuration will refer to this class
*/
public class SubTableConfig implements PreciseShardingAlgorithm<Integer> {
private static Logger logger = Logger.getLogger(SubTableConfig.class);
@Override
public String doSharding(Collection<String> collection, PreciseShardingValue<Integer> preciseShardingValue) {
Integer value = preciseShardingValue.getValue();
//actual-data-nodes: db$->{0..1}.t_user_$->{0..1}
Object[] objects = collection.toArray();
if((value % 2) == 0){
logger.info("Table name:"+objects[0]);
return objects[0]+"";
}else{
logger.info("Table name:"+objects[1]);
return objects[1]+"";
}
}
}
Note that the configuration classes of sub database and sub table need to implement the PreciseShardingAlgorithm interface. These two configuration classes will be referenced in the yml file
Test: