ShardingSphere
ShardingSphere is a complete set of data ecosystem based on data fragmentation.
ShardingSphere contains three important products, ShardingJDBC, ShardingProxy and ShardingSidecar. sidecar is a sub database and sub table plug-in for service mesh, which is currently under planning.
ShardingJDBC is used for client-side sub database and sub table, while ShardingProxy is used for server-side sub database and sub table
ShardingJDBC

Sharding JDBC is positioned as a lightweight Java framework that provides additional services in the JDBC layer of Java. It enables the client to connect directly to the database and provide services in the form of jar package. It requires additional deployment and dependency. It can be understood as an enhanced jdbc driver and is fully compatible with JDBC and various ORM frameworks.
ShardingProxy
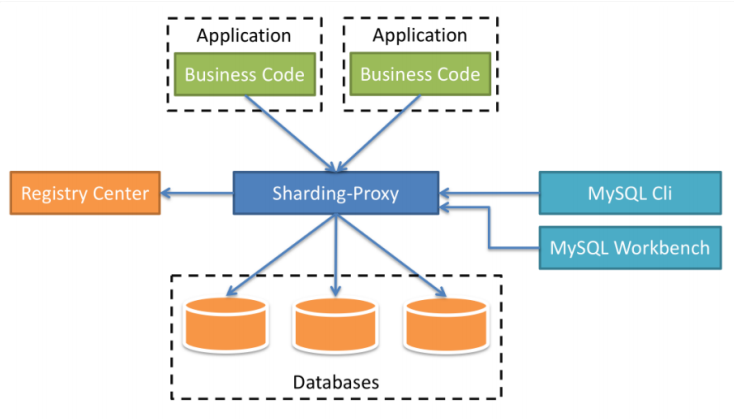
ShardingProxy is positioned as a transparent database proxy. It provides a server version that encapsulates the database binary protocol and is used to support heterogeneous languages. (MySQL and PostgreSQL versions are provided before, which can enable any access client compatible with MySQL/PostgreSQL protocol.
The difference between the two
Obviously, ShardingJDBC is only a toolkit for the client, which can be understood as a special JDBC driver package. All sub database and table logic are controlled by the business party, so its functions are relatively flexible and support a lot of databases. However, it has a large intrusion into the business, and the business party needs to customize all sub database and table logic.
ShardingProxy is an independently deployed service that does not invade the business side. The business side can interact with data like an ordinary MySQL service. Basically, it does not feel the existence of back-end database and table logic, but it also means that the functions will be relatively fixed and there are relatively few databases that can be supported. These two have their own advantages and disadvantages.
ShardingJDBC actual combat
The core function of shardingjdbc is data fragmentation and read-write separation. Through shardingjdbc, applications can transparently use JDBC to access multiple data sources that have been divided into databases, tables and read-write separation, without caring about the number of data sources and how the data is distributed.
Core concept
- Logical table: the general name of the same logical and data structure table of the horizontally split database
- Real table: a physical table that exists in a fragmented database.
- Data node: the smallest unit of data fragmentation. It consists of data source name and data table
- Binding table: main table and sub table with consistent fragmentation rules.
- Broadcast table: also known as public table, it refers to the table that exists in the known fragment data source. The table structure and the data in the table are completely consistent in each database. For example, a dictionary table.
- Sharding key: the database field used for sharding. It is the key field to split the database (table) horizontally. If there is no fragment field in SQL, full routing will be executed and the performance will be very poor.
- Slicing algorithm: the data is sliced through the slicing algorithm. Slicing through =, BETWEEN and IN is supported. The slicing algorithm needs to be implemented by the application developer, and the flexibility is very high.
- Sharding strategy: sharding key + sharding algorithm is really used for sharding operation, that is, sharding strategy. In sharding JDBC, the inline sharding strategy based on Groovy expression is generally adopted. The sharding strategy is formulated through an algorithm expression containing sharding key, such as t_ user_$-> {u_id% 8} identification according to u_ ID module 8 is divided into 8 tables, and the table name is t_user_0 to t_user_7.
Sharding JDBC sharding algorithm
ShardingSphere currently provides five fragmentation strategies:
- NoneShardingStrategy
Not divided. This is not strictly a fragmentation strategy. But ShardingSphere also provides such a configuration. - InlineShardingStrategy
The most commonly used slicing method
Configuration parameters: inline.shardingColumn slice key; inline.algorithmExpression Fragment Expression
Implementation method: slice according to the slice expression. - StandardShardingStrategy
Only the standard sharding strategy of single sharding key is supported.
Configuration parameters: standard.sharing-column partition key; standard.precise-algorithm-class-name class name of the precise slicing algorithm; standard.range-algorithm-class-name range slicing algorithm class name
Implementation method:
shardingColumn specifies the sharding algorithm.
preciseAlgorithmClassName refers to a java class name that implements the io.shardingsphere.api.algorithm.sharding.standard.precisealgorithm interface and provides precise fragmentation according to = or IN logic
rangeAlgorithmClassName refers to a java class name that implements the io.shardingsphere.api.algorithm.sharding.standard.RangeShardingAlgorithm interface and provides range fragmentation according to the Between condition.
explain:
The exact partition algorithm must be provided, and the range partition algorithm is optional. - ComplexShardingStrategy
Complex sharding strategy supporting multiple sharding keys.
Configuration parameters: complex.sharding-columns partition key (multiple); complex.algorithm-class-name partition algorithm implementation class.
Implementation method:
shardingColumn specifies multiple sharding columns.
algorithmClassName points to a java class name that implements the org.apache.shardingsphere.api.sharding.complex.ComplexKeysShardingAlgorithm interface. Provides an algorithm for comprehensive sharding according to multiple sharding columns. - HintShardingStrategy
A forced sharding policy that does not require a sharding key. This fragmentation strategy is simply understood, that is, its fragmentation key is no longer associated with the SQL statement, but specified by the program. For some complex cases, such as SQL statements such as select count(*) from (select userid from t_user where userid in (1,3,5,7,9)), it is impossible to specify a partition key through SQL statements. At this time, you can execute another partition key for him through the program. For example, under the policy of pressing userid parity partition, you can specify 1 as the partition key, and then specify his partition policy.
Configuration parameter: hint.algorithm-class-name sharding algorithm implementation class.
Implementation method:
algorithmClassName points to a java class name that implements the org.apache.shardingsphere.api.sharding.hint.HintShardingAlgorithm interface.
In this algorithm class, partition keys are also required. The partition key is specified through the HintManager.addDatabaseShardingValue method (sub database) and hintmanager.addtableshardingvalue (sub table).
Note that this partition key is thread isolated and only valid for the current thread, so it is usually recommended to close it immediately after use or open it in the way of try resources.
The Hint fragmentation strategy does not completely construct the fragmentation strategy according to the SQL parsing tree, which bypasses SQL parsing. For some complex statements, the performance of the Hint fragmentation strategy may be better (there are too many situations to analyze one by one).
However, it should be noted that Hint forced routing has many restrictions when used:
– UNION is not supported
SELECT * FROM t_order1 UNION SELECT * FROM t_order2
INSERT INTO tbl_name (col1, col2, ...) SELECT col1, col2, ... FROM tbl_name WHERE col3 = ?
– multi level subqueries are not supported
SELECT COUNT(*) FROM (SELECT * FROM t_order o WHERE o.id IN (SELECT id FROM t_order WHERE status = ?))
– function evaluation is not supported. ShardingSphere can only literally extract values for sharding through SQL
SELECT * FROM t_order WHERE to_date(create_time, 'yyyy-mm-dd') = '2019-01-01';
Case demonstration
Sub table case
- Introduce dependency
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.1.1</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.22</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.0.5</version>
</dependency>
- Define class
package com.roy.shardingDemo.entity;
public class Course {
private Long cid;
private String cname;
private Long userId;
private String cstatus;
public Long getCid() {
return cid;
}
public void setCid(Long cid) {
this.cid = cid;
}
public String getCname() {
return cname;
}
public void setCname(String cname) {
this.cname = cname;
}
public Long getUserId() {
return userId;
}
public void setUserId(Long userId) {
this.userId = userId;
}
public String getCstatus() {
return cstatus;
}
public void setCstatus(String cstatus) {
this.cstatus = cstatus;
}
@Override
public String toString() {
return "Course{" +
"cid=" + cid +
", cname='" + cname + '\'' +
", userId=" + userId +
", cstatus='" + cstatus + '\'' +
'}';
}
}
package com.roy.shardingDemo.mapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.roy.shardingDemo.entity.Course;
public interface CourseMapper extends BaseMapper<Course> {
}
package com.roy.shardingDemo;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@MapperScan("com.roy.shardingDemo.mapper")
@SpringBootApplication
public class ShardingJDBCApplication {
public static void main(String[] args) {
SpringApplication.run(ShardingJDBCApplication.class,args);
}
}
- Unit test class
@Test
public void addCourse(){
for(int i = 0 ; i < 10 ; i ++){
Course c = new Course();
// c.setCid(Long.valueOf(i));
c.setCname("shardingsphere");
c.setUserId(Long.valueOf(""+(1000+i)));
c.setCstatus("1");
courseMapper.insert(c);
}
}
- configuration file
application.properties
spring.profiles.active=dev1
application-dev1.properties
#Configure data sources
spring.shardingsphere.datasource.names=m1
spring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m1.url=jdbc:mysql://192.168.1.104:3306/coursedb?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.m1.username=root
spring.shardingsphere.datasource.m1.password=123
#Configure real table distribution
spring.shardingsphere.sharding.tables.course.actual-data-nodes=m1.course_$->{1..2}
#Primary key generation strategy
spring.shardingsphere.sharding.tables.course.key-generator.column=cid
spring.shardingsphere.sharding.tables.course.key-generator.type=SNOWFLAKE
spring.shardingsphere.sharding.tables.course.key-generator.props.worker.id=1
#Configure table splitting policy
spring.shardingsphere.sharding.tables.course.table-strategy.inline.sharding-column=cid
spring.shardingsphere.sharding.tables.course.table-strategy.inline.algorithm-expression=course_$->{cid%2+1}
#Other run properties
spring.shardingsphere.props.sql.show = true
spring.main.allow-bean-definition-overriding=true
- demonstration
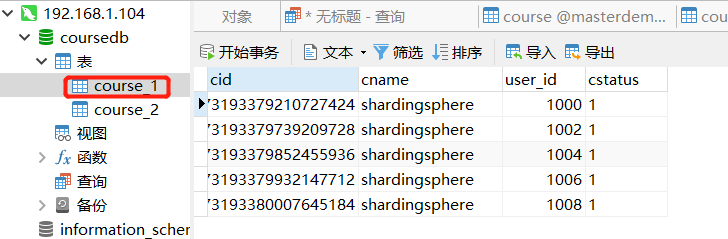
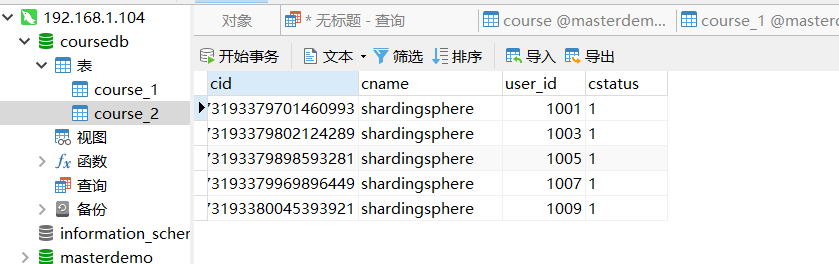
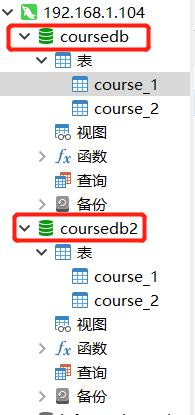
Sub database case
Precise query
- Configuration file change
spring.profiles.active=dev2
#Configure multiple data sources
spring.shardingsphere.datasource.names=m1,m2
spring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m1.url=jdbc:mysql://192.168.1.104:3306/coursedb?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.m1.username=root
spring.shardingsphere.datasource.m1.password=123
spring.shardingsphere.datasource.m2.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m2.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m2.url=jdbc:mysql://192.168.1.104:3306/coursedb2?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.m2.username=root
spring.shardingsphere.datasource.m2.password=123
#Real table distribution, sub database, sub table
spring.shardingsphere.sharding.tables.course.actual-data-nodes=m$->{1..2}.course_$->{1..2}
spring.shardingsphere.sharding.tables.course.key-generator.column=cid
spring.shardingsphere.sharding.tables.course.key-generator.type=SNOWFLAKE
spring.shardingsphere.sharding.tables.course.key-generator.props.worker.id=1
#inline slicing strategy
spring.shardingsphere.sharding.tables.course.table-strategy.inline.sharding-column=cid
spring.shardingsphere.sharding.tables.course.table-strategy.inline.algorithm-expression=course_$->{cid%2+1}
spring.shardingsphere.sharding.tables.course.database-strategy.inline.sharding-column=cid
spring.shardingsphere.sharding.tables.course.database-strategy.inline.algorithm-expression=m$->{cid%2+1}
- Unit test cases remain unchanged
- Case demonstration
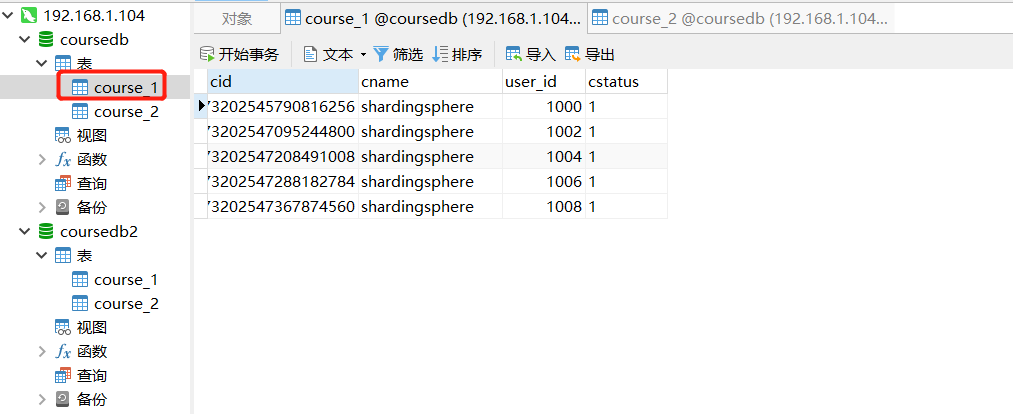
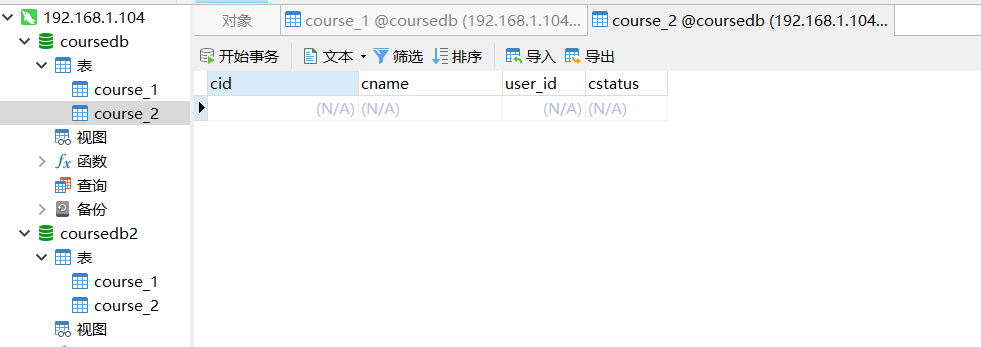
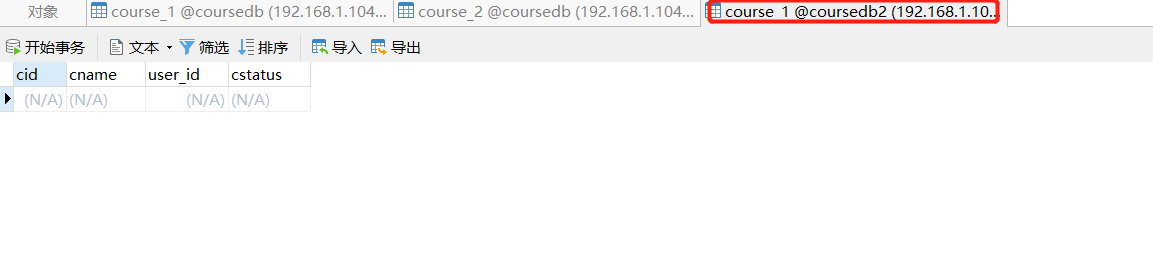
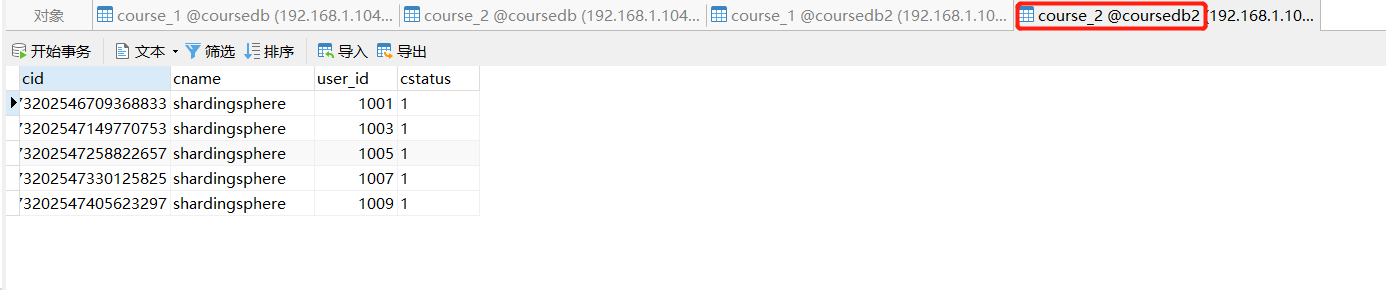
- Add query case
@Test
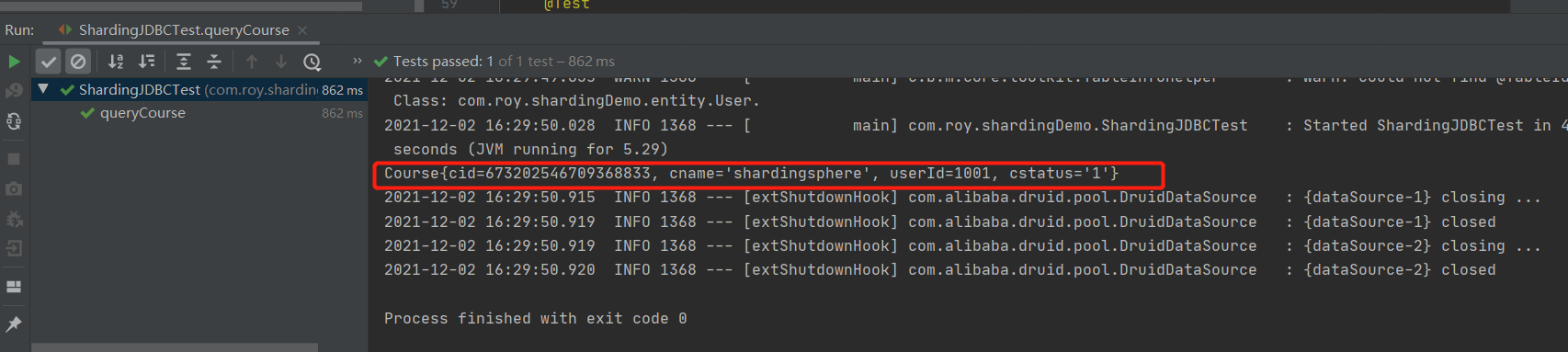
public void queryCourse(){
//select * from course
QueryWrapper<Course> wrapper = new QueryWrapper<>();
wrapper.orderByDesc("cid");
wrapper.eq("cid",673202546709368833L);
// wrapper.in()
List<Course> courses = courseMapper.selectList(wrapper);
courses.forEach(course -> System.out.println(course));
}
Range query
- Add range query case
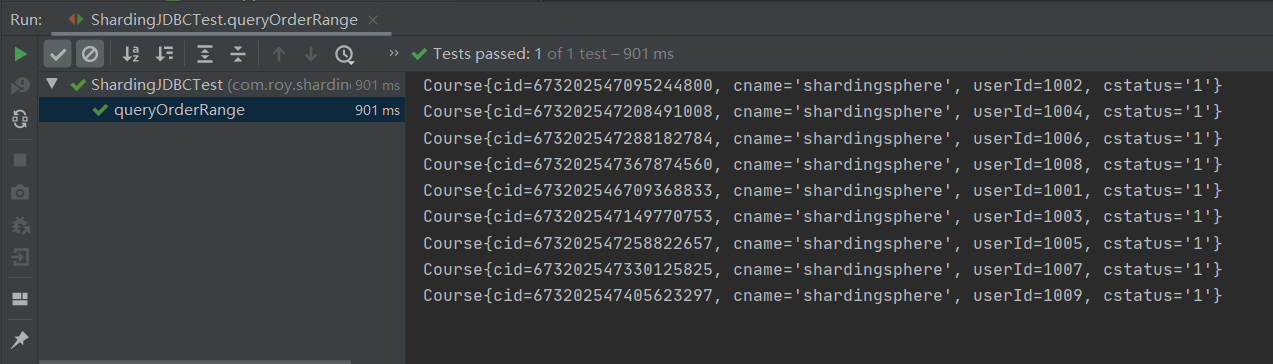
@Test
public void queryOrderRange(){
//select * from course
QueryWrapper<Course> wrapper = new QueryWrapper<>();
wrapper.between("cid",673202546709368833L,673202547405623297L);
// wrapper.in()
List<Course> courses = courseMapper.selectList(wrapper);
courses.forEach(course -> System.out.println(course));
}
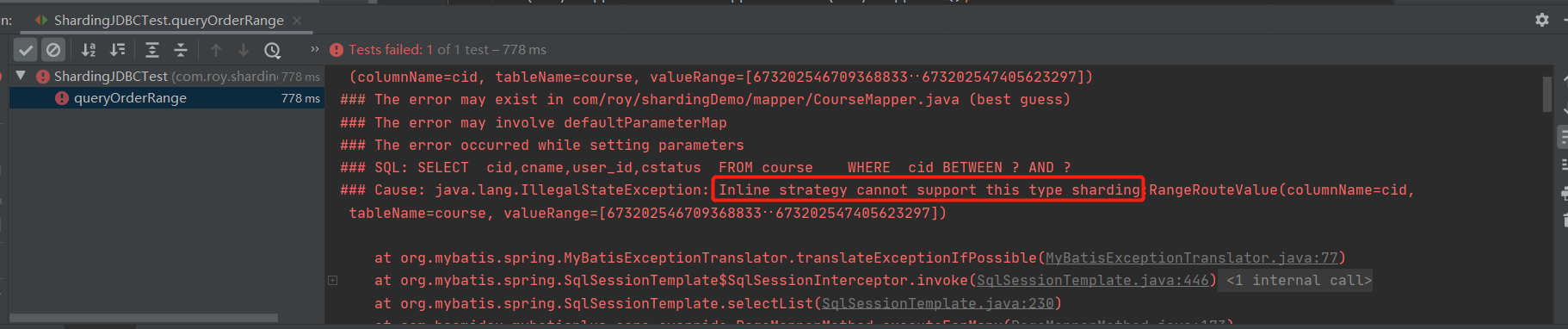
When the above error is found, inline does not support range query. It needs to be configured into standard mode, so the configuration file needs to be modified
# Table configuration tables.course.table-strategy.standard.sharding-column=cid spring.shardingsphere.sharding.tables.course.table-strategy.standard.precise-algorithm-class-name=com.roy.shardingDemo.algorithem.MyPreciseTableShardingAlgorithm spring.shardingsphere.sharding.tables.course.table-strategy.standard.range-algorithm-class-name=com.roy.shardingDemo.algorithem.MyRangeTableShardingAlgorithm # Library Configuration spring.shardingsphere.sharding.tables.course.database-strategy.standard.sharding-column=cid spring.shardingsphere.sharding.tables.course.database-strategy.standard.precise-algorithm-class-name=com.roy.shardingDemo.algorithem.MyPreciseDSShardingAlgorithm spring.shardingsphere.sharding.tables.course.database-strategy.standard.range-algorithm-class-name=com.roy.shardingDemo.algorithem.MyRangeDSShardingAlgorithm
Precise configuration class of Library
package com.roy.shardingDemo.algorithem;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingValue;
import java.math.BigInteger;
import java.util.Collection;
public class MyPreciseDSShardingAlgorithm implements PreciseShardingAlgorithm<Long> {
//select * from course where cid = ? or cid in (?,?)
@Override
public String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<Long> shardingValue) {
String logicTableName = shardingValue.getLogicTableName();
String cid = shardingValue.getColumnName();
Long cidValue = shardingValue.getValue();
//Implement M $- > {CID% 2 + 1}
BigInteger shardingValueB = BigInteger.valueOf(cidValue);
BigInteger resB = (shardingValueB.mod(new BigInteger("2"))).add(new BigInteger("1"));
String key = "m"+resB;
if(availableTargetNames.contains(key)){
return key;
}
//couse_1, course_2
throw new UnsupportedOperationException("route "+ key +" is not supported ,please check your config");
}
}
Scope configuration class of Library
package com.roy.shardingDemo.algorithem;
import org.apache.shardingsphere.api.sharding.standard.RangeShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.RangeShardingValue;
import java.util.Arrays;
import java.util.Collection;
public class MyRangeDSShardingAlgorithm implements RangeShardingAlgorithm<Long> {
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames, RangeShardingValue<Long> shardingValue) {
//select * from course where cid between 1 and 100;
Long upperVal = shardingValue.getValueRange().upperEndpoint();//100
Long lowerVal = shardingValue.getValueRange().lowerEndpoint();//1
String logicTableName = shardingValue.getLogicTableName();
return Arrays.asList("m1","m2");
}
}
Exact configuration class of table
package com.roy.shardingDemo.algorithem;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingValue;
import java.math.BigInteger;
import java.util.Collection;
public class MyPreciseTableShardingAlgorithm implements PreciseShardingAlgorithm<Long> {
//select * from course where cid = ? or cid in (?,?)
@Override
public String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<Long> shardingValue) {
String logicTableName = shardingValue.getLogicTableName();
String cid = shardingValue.getColumnName();
Long cidValue = shardingValue.getValue();
//Realize course $- > {cid%2+1)
BigInteger shardingValueB = BigInteger.valueOf(cidValue);
BigInteger resB = (shardingValueB.mod(new BigInteger("2"))).add(new BigInteger("1"));
String key = logicTableName+"_"+resB;
if(availableTargetNames.contains(key)){
return key;
}
//couse_1, course_2
throw new UnsupportedOperationException("route "+ key +" is not supported ,please check your config");
}
}
Scope configuration class of Library
package com.roy.shardingDemo.algorithem;
import org.apache.shardingsphere.api.sharding.standard.RangeShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.RangeShardingValue;
import sun.rmi.runtime.Log;
import java.util.Arrays;
import java.util.Collection;
/**
* @author : Loulan
* @date : Created in 2021/1/6
* @description:
**/
public class MyRangeTableShardingAlgorithm implements RangeShardingAlgorithm<Long> {
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames, RangeShardingValue<Long> shardingValue) {
//select * from course where cid between 1 and 100;
Long upperVal = shardingValue.getValueRange().upperEndpoint();//100
Long lowerVal = shardingValue.getValueRange().lowerEndpoint();//1
String logicTableName = shardingValue.getLogicTableName();
return Arrays.asList(logicTableName+"_1",logicTableName+"_2");
}
}
Complex supports multiple sharding keys
@Test
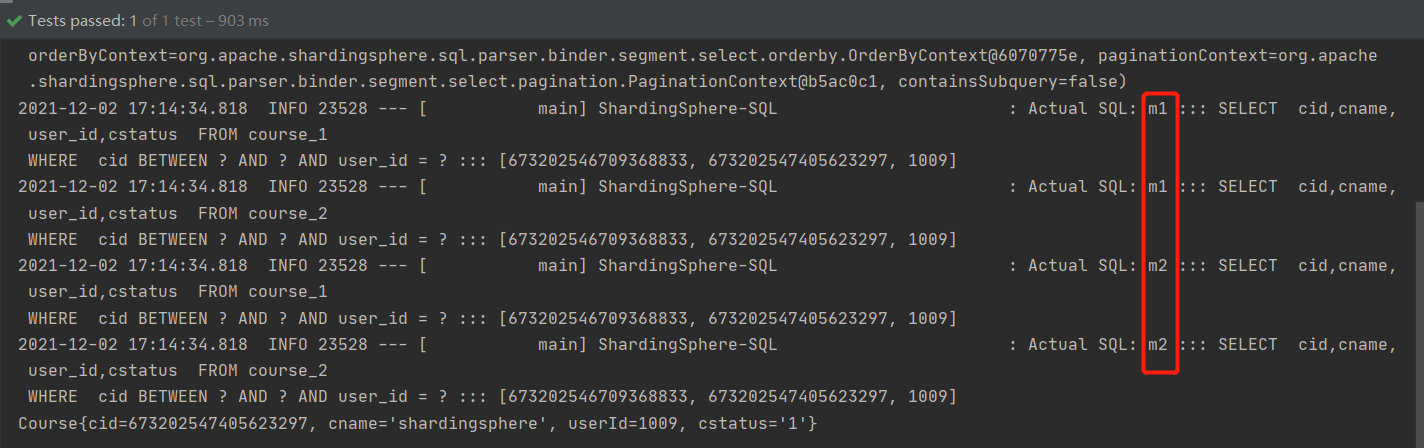
public void queryCourseComplex(){
QueryWrapper<Course> wrapper = new QueryWrapper<>();
wrapper.between("cid",673202546709368833L,673202547405623297L);
wrapper.eq("user_id",1009L);
// wrapper.in()
List<Course> courses = courseMapper.selectList(wrapper);
courses.forEach(course -> System.out.println(course));
}
#Complex complex partition strategy spring.shardingsphere.sharding.tables.course.table-strategy.complex.sharding-columns= cid, user_id spring.shardingsphere.sharding.tables.course.table-strategy.complex.algorithm-class-name=com.roy.shardingDemo.algorithem.MyComplexTableShardingAlgorithm spring.shardingsphere.sharding.tables.course.database-strategy.complex.sharding-columns=cid, user_id spring.shardingsphere.sharding.tables.course.database-strategy.complex.algorithm-class-name=com.roy.shardingDemo.algorithem.MyComplexDSShardingAlgorithm
package com.roy.shardingDemo.algorithem;
import com.google.common.collect.Range;
import org.apache.shardingsphere.api.sharding.complex.ComplexKeysShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.complex.ComplexKeysShardingValue;
import java.math.BigInteger;
import java.util.ArrayList;
import java.util.Collection;
import java.util.List;
import java.util.Map;
public class MyComplexDSShardingAlgorithm implements ComplexKeysShardingAlgorithm<Long> {
// SELECT cid,cname,user_id,cstatus FROM course
// WHERE cid BETWEEN ? AND ? AND user_id = ?
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames, ComplexKeysShardingValue<Long> shardingValue) {
Range<Long> cidRange = shardingValue.getColumnNameAndRangeValuesMap().get("cid");
Collection<Long> userIdCol = shardingValue.getColumnNameAndShardingValuesMap().get("user_id");
Long upperVal = cidRange.upperEndpoint();
Long lowerVal = cidRange.lowerEndpoint();
List<String> res = new ArrayList<>();
for(Long userId: userIdCol){
//course_{userID%2+1}
BigInteger userIdB = BigInteger.valueOf(userId);
BigInteger target = (userIdB.mod(new BigInteger("2"))).add(new BigInteger("1"));
res.add("m"+target);
}
return res;
}
}
package com.roy.shardingDemo.algorithem;
import com.google.common.collect.Range;
import org.apache.shardingsphere.api.sharding.complex.ComplexKeysShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.complex.ComplexKeysShardingValue;
import java.math.BigInteger;
import java.util.ArrayList;
import java.util.Collection;
import java.util.List;
public class MyComplexTableShardingAlgorithm implements ComplexKeysShardingAlgorithm<Long> {
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames, ComplexKeysShardingValue<Long> shardingValue) {
Range<Long> cidRange = shardingValue.getColumnNameAndRangeValuesMap().get("cid");
Collection<Long> userIdCol = shardingValue.getColumnNameAndShardingValuesMap().get("user_id");
Long upperVal = cidRange.upperEndpoint();
Long lowerVal = cidRange.lowerEndpoint();
List<String> res = new ArrayList<>();
for(Long userId: userIdCol){
//course_{userID%2+1}
BigInteger userIdB = BigInteger.valueOf(userId);
BigInteger target = (userIdB.mod(new BigInteger("2"))).add(new BigInteger("1"));
res.add(shardingValue.getLogicTableName()+"_"+target);
}
return res;
}
}
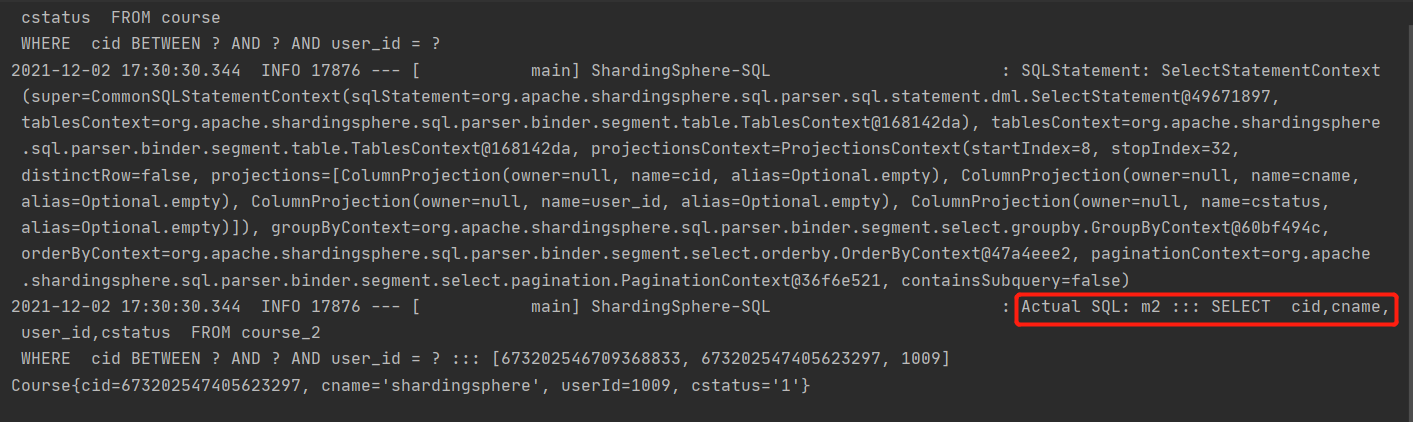
Compared with the original query, it plays an optimization role
hint forced routing
@Test
public void queryCourseByHint(){
HintManager hintManager = HintManager.getInstance();
hintManager.addTableShardingValue("course",2);
List<Course> courses = courseMapper.selectList(null);
courses.forEach(course -> System.out.println(course));
hintManager.close();
}
#hint forced routing policy spring.shardingsphere.sharding.tables.course.table-strategy.hint.algorithm-class-name=com.roy.shardingDemo.algorithem.MyHintTableShardingAlgorithm
package com.roy.shardingDemo.algorithem;
import org.apache.shardingsphere.api.sharding.hint.HintShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.hint.HintShardingValue;
import java.util.Arrays;
import java.util.Collection;
public class MyHintTableShardingAlgorithm implements HintShardingAlgorithm<Integer> {
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames, HintShardingValue<Integer> shardingValue) {
String key = shardingValue.getLogicTableName() + "_" + shardingValue.getValues().toArray()[0];
if(availableTargetNames.contains(key)){
return Arrays.asList(key);
}
throw new UnsupportedOperationException("route "+ key +" is not supported ,please check your config");
}
}
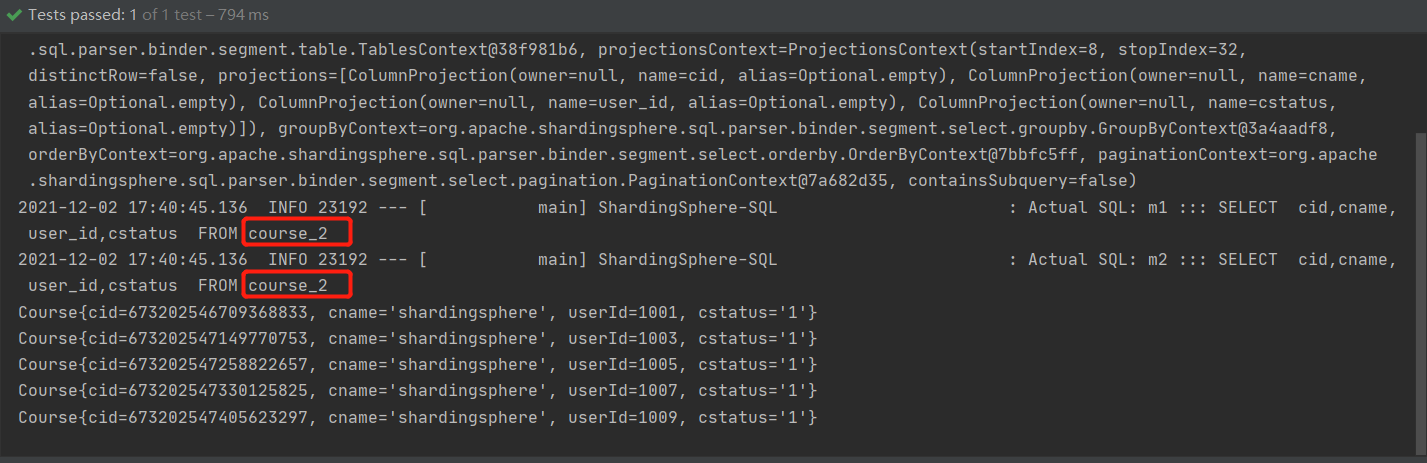
Force it to only look up the course_2 table
Broadcast table
#Broadcast table configuration spring.shardingsphere.sharding.broadcast-tables=t_dict spring.shardingsphere.sharding.tables.t_dict.key-generator.column=dict_id spring.shardingsphere.sharding.tables.t_dict.key-generator.type=SNOWFLAKE
@Test
public void addDict(){
Dict d1 = new Dict();
d1.setUstatus("1");
d1.setUvalue("normal");
dictMapper.insert(d1);
Dict d2 = new Dict();
d2.setUstatus("0");
d2.setUvalue("abnormal");
dictMapper.insert(d2);
}
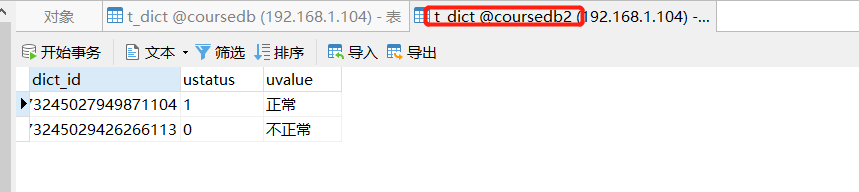
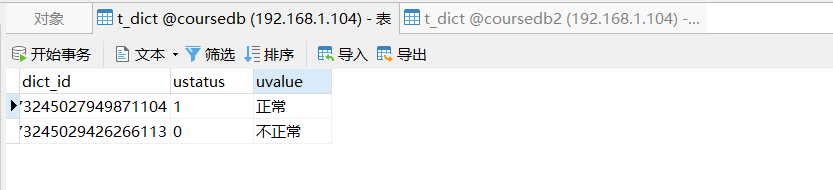
Binding table
spring.profiles.active=dev3
spring.shardingsphere.datasource.names=m1
spring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m1.url=jdbc:mysql://192.168.1.104:3306/coursedb?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.m1.username=root
spring.shardingsphere.datasource.m1.password=123
spring.shardingsphere.sharding.tables.t_dict.actual-data-nodes=m1.t_dict_$->{1..2}
spring.shardingsphere.sharding.tables.t_dict.key-generator.column=dict_id
spring.shardingsphere.sharding.tables.t_dict.key-generator.type=SNOWFLAKE
spring.shardingsphere.sharding.tables.t_dict.key-generator.props.worker.id=1
spring.shardingsphere.sharding.tables.t_dict.table-strategy.inline.sharding-column=ustatus
spring.shardingsphere.sharding.tables.t_dict.table-strategy.inline.algorithm-expression=t_dict_$->{ustatus.toInteger()%2+1}
spring.shardingsphere.sharding.tables.user.actual-data-nodes=m1.t_user_$->{1..2}
spring.shardingsphere.sharding.tables.user.key-generator.column=user_id
spring.shardingsphere.sharding.tables.user.key-generator.type=SNOWFLAKE
spring.shardingsphere.sharding.tables.user.key-generator.props.worker.id=1
spring.shardingsphere.sharding.tables.user.table-strategy.inline.sharding-column=ustatus
spring.shardingsphere.sharding.tables.user.table-strategy.inline.algorithm-expression=t_user_$->{ustatus.toInteger()%2+1}
#Binding example
spring.shardingsphere.sharding.binding-tables[0]=user,t_dict
spring.shardingsphere.props.sql.show = true
spring.main.allow-bean-definition-overriding=true
@Test
public void addDict(){
Dict d1 = new Dict();
d1.setUstatus("1");
d1.setUvalue("normal");
dictMapper.insert(d1);
Dict d2 = new Dict();
d2.setUstatus("0");
d2.setUvalue("abnormal");
dictMapper.insert(d2);
for(int i = 0 ; i < 10 ; i ++){
User user = new User();
user.setUsername("user No "+i);
user.setUstatus(""+(i%2));
user.setUage(i*10);
userMapper.insert(user);
}
}


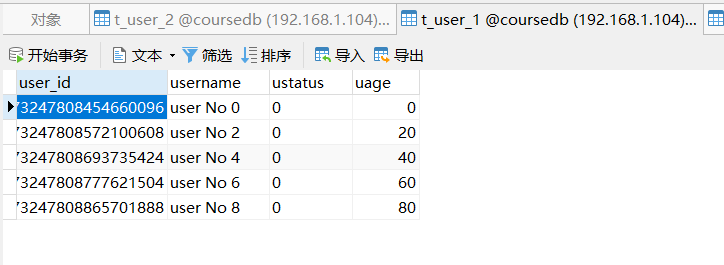
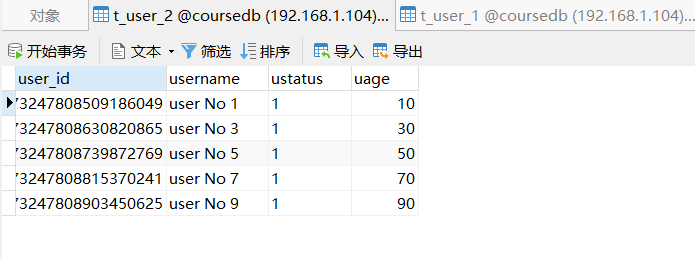
@Test
public void queryUserStatus(){
List<User> users = userMapper.queryUserStatus();
users.forEach(user -> System.out.println(user));
}
package com.roy.shardingDemo.mapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.roy.shardingDemo.entity.User;
import org.apache.ibatis.annotations.Select;
import java.util.List;
public interface UserMapper extends BaseMapper<User> {
@Select("select u.user_id,u.username,d.uvalue ustatus from user u left join t_dict d on u.ustatus = d.ustatus")
public List<User> queryUserStatus();
}
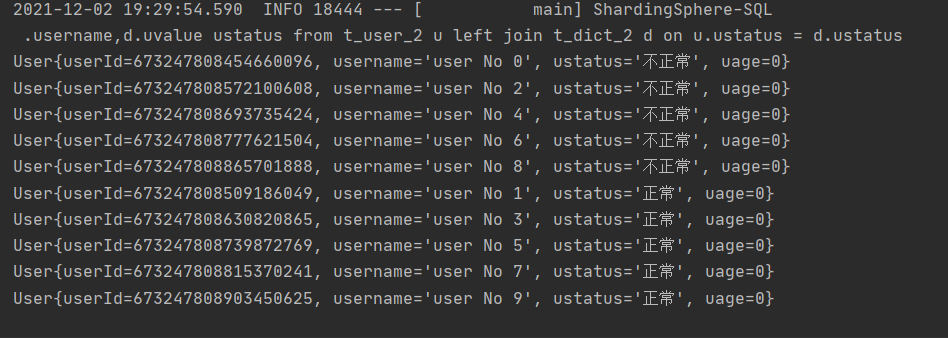
Read write separation
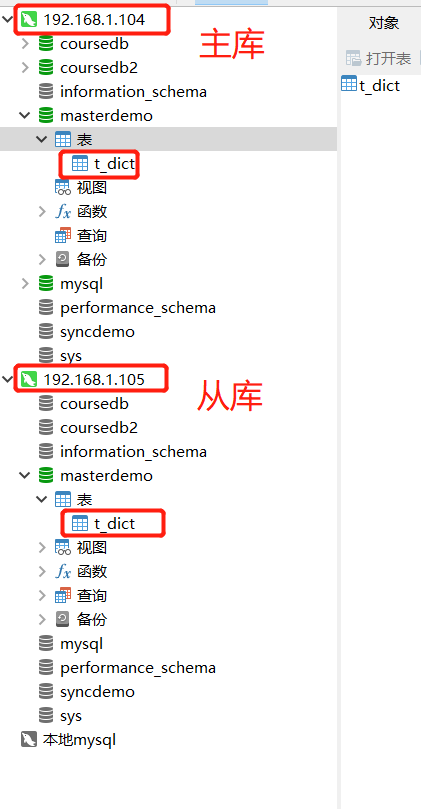
spring.profiles.active=dev4
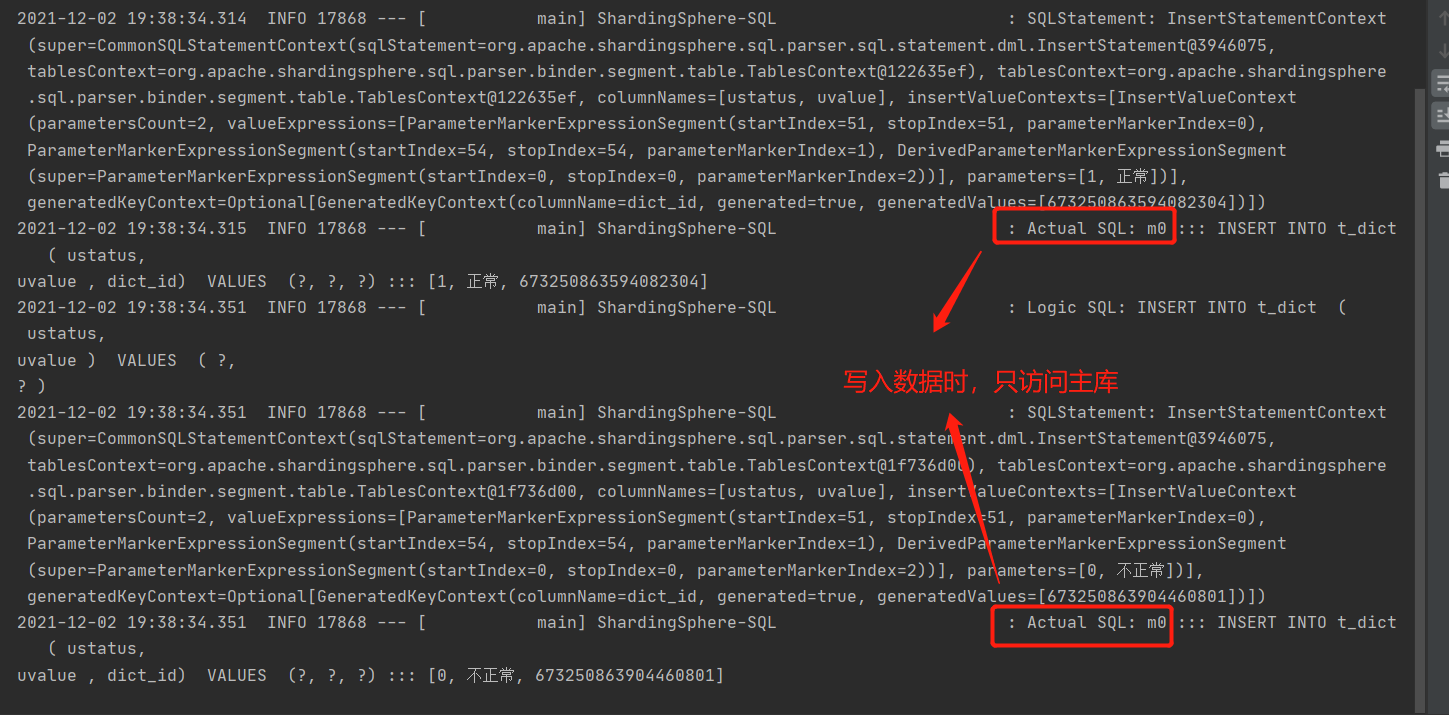
#Configure master-slave data sources based on MySQL master-slave architecture. spring.shardingsphere.datasource.names=m0,s0 spring.shardingsphere.datasource.m0.type=com.alibaba.druid.pool.DruidDataSource spring.shardingsphere.datasource.m0.driver-class-name=com.mysql.cj.jdbc.Driver spring.shardingsphere.datasource.m0.url=jdbc:mysql://192.168.1.104:3306/masterdemo?serverTimezone=GMT%2B8 spring.shardingsphere.datasource.m0.username=root spring.shardingsphere.datasource.m0.password=123 spring.shardingsphere.datasource.s0.type=com.alibaba.druid.pool.DruidDataSource spring.shardingsphere.datasource.s0.driver-class-name=com.mysql.cj.jdbc.Driver spring.shardingsphere.datasource.s0.url=jdbc:mysql://192.168.1.105:3306/masterdemo?serverTimezone=GMT%2B8 spring.shardingsphere.datasource.s0.username=root spring.shardingsphere.datasource.s0.password=123 #Read write separation rule, m0 master library, s0 slave Library spring.shardingsphere.sharding.master-slave-rules.ds0.master-data-source-name=m0 spring.shardingsphere.sharding.master-slave-rules.ds0.slave-data-source-names[0]=s0 #Table Slicing Based on read-write separation spring.shardingsphere.sharding.tables.t_dict.actual-data-nodes=ds0.t_dict spring.shardingsphere.sharding.tables.t_dict.key-generator.column=dict_id spring.shardingsphere.sharding.tables.t_dict.key-generator.type=SNOWFLAKE spring.shardingsphere.sharding.tables.t_dict.key-generator.props.worker.id=1 spring.shardingsphere.props.sql.show = true spring.main.allow-bean-definition-overriding=true
@Test
public void addDictByMS(){
Dict d1 = new Dict();
d1.setUstatus("1");
d1.setUvalue("normal");
dictMapper.insert(d1);
Dict d2 = new Dict();
d2.setUstatus("0");
d2.setUvalue("abnormal");
dictMapper.insert(d2);
}
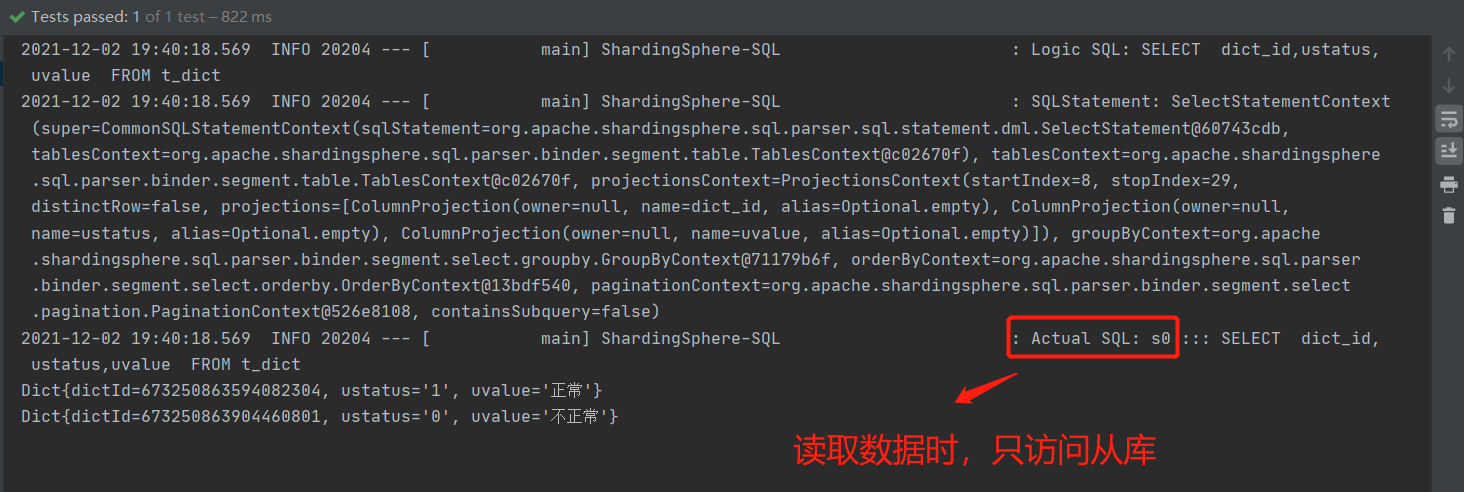
@Test
public void queryDictByMS(){
List<Dict> dicts = dictMapper.selectList(null);
dicts.forEach(dict -> System.out.println(dict));
}
SQL usage restrictions for ShardingSphere
See the official website document: https://shardingsphere.apache.org/document/current/cn/features/sharding/use-norms/sql/ The document lists in detail many SQL types supported and not supported by the current version of ShardingSphere. These things should be paid attention to frequently.
Problems caused by sub database and sub table
1. In fact, the core problem of database and table splitting is the capacity of a single database. We should understand that there are many solutions to this problem, not just database and table splitting. However, ShardingSphere hopes to manage hardware resources at the software level, so as to facilitate the horizontal expansion of the database It is undoubtedly a way with low cost.
Let's think about what better solutions are there?
2. Generally, if the capacity of a stand-alone database cannot support, we should start with caching technology to reduce the access pressure to the database. If the database access is still very large after the cache is used, we can consider the database read-write separation strategy. If the pressure on the database is still very large and the continuous growth of business data is incalculable, we can finally consider database and table splitting, The split data of single table shall be controlled within 10 million.
Of course, with the continuous development of Internet technology, there are more and more choices to deal with massive data. In actual system design, it is best to use MySQL database only to store hot data with strong relationship, and adopt other distributed storage products for massive data. For example, PostGreSQL, VoltDB and even HBase, Hive, ES and other big data components are used to store massive data .
3. From the ShardingJDBC fragmentation algorithm in the previous part, we can see that the functions of SQL statements are too many and too comprehensive, so it is difficult to support SQL statements step by step after database and table splitting. If you are not careful, you will cause many problems, such as unsupported SQL statements and chaotic business data. Therefore, we will recommend this database splitting in actual use Watch, try not to use it if you can't use it.
If you want to use it in the OLTP scenario, you should give priority to solving the problem of query speed under a large amount of data. In the OLAP scenario, it usually involves a lot of complex SQL, and the limitation of database and table will be more obvious. Of course, this is also a direction for ShardingSphere to improve in the future.
4. If you decide to use sub database and sub table, you should consider the coupling degree and use of business data at the beginning of system design, try to control the use scope of business SQL statements, and weaken the database in the direction of simple data storage layer of addition, deletion, modification and query. First, you should plan the vertical split strategy in detail to make the data layer architecture clear. As for Horizontal splitting will cause a lot of data problems in the later stage, so you should be cautious. Generally, it is only occasionally used in some edge scenarios such as log table and operation record table.