catalogue
5, 2.0 Version 3 usage configuration
6, 4.1 Version 1 usage configuration
7, 5.0 0 version use configuration
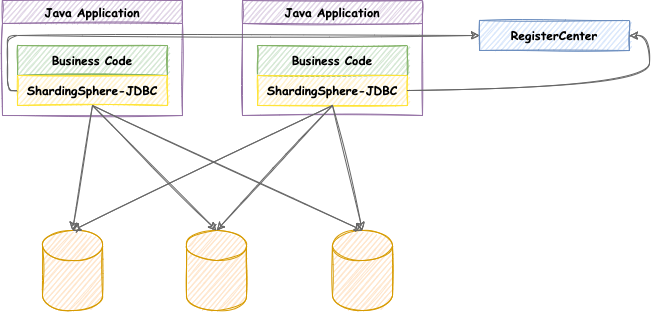
1, Background
-
problem
The traditional solution of centralized storage of data to a single node has been difficult to meet the scenario of massive data in terms of performance, availability and operation and maintenance cost. Splitting the data by database and table to keep the data volume of each table below the threshold, and dredge the traffic to deal with the high traffic is an effective means to deal with the high concurrency and massive data system. Data fragmentation can be divided into vertical fragmentation and horizontal fragmentation.
-
Vertical slice
According to the business splitting method, it is called vertical splitting, also known as vertical splitting. Its core concept is dedicated to special database. Before splitting, a database is composed of multiple data tables, and each table corresponds to different businesses. After splitting, the tables are classified according to business and distributed to different databases, so as to disperse the pressure to different databases.
Vertical fragmentation often requires adjustments to the architecture and design. Generally speaking, it is too late to respond to the rapid changes in Internet business needs; Moreover, it can not really solve the single point bottleneck. Vertical splitting can alleviate the problems caused by data volume and access volume, but it can not cure them. If the amount of data in the table still exceeds the threshold that a single node can carry after vertical splitting, horizontal splitting is required for further processing.
-
Horizontal slice
Horizontal splitting is also called horizontal splitting. Compared with vertical sharding, it no longer classifies data according to business logic, but disperses data into multiple libraries or tables according to certain rules through a certain field (or several fields), and each shard contains only a part of the data. This paper configures horizontal sharding.
Horizontal slicing theoretically breaks through the bottleneck of single machine data processing and expands relatively freely. It is a standard solution for data slicing.
2, Definition
Positioned as a lightweight Java framework, additional services are provided in the JDBC layer of Java. It uses the client to directly connect to the database and provides services in the form of jar package without additional deployment and dependency. It can be understood as an enhanced jdbc driver and is fully compatible with JDBC and various ORM frameworks.
- It is applicable to any Java based ORM framework, such as JPA, Hibernate, Mybatis, Spring JDBC Template or directly using JDBC.
- Database connection pool based on any third party, such as DBCP, C3P0, BoneCP, Druid, HikariCP, etc.
- Support any database that implements JDBC specification. Currently, MySQL, Oracle, SQL server and PostgreSQL are supported.
3, Quick start
1. Introduce maven dependency
Note: please change ${latest.release.version} to the actual version number.
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core</artifactId>
<version>${latest.release.version}</version>
</dependency>2. Rule configuration
Shardingsphere JDBC can be configured in four ways: Java, YAML, Spring namespace and Spring Boot Starter. Developers can choose the appropriate configuration method according to the scenario.
Java API is the basis of all configuration methods in shardingsphere JDBC, and other configurations will eventually be transformed into Java API configuration methods.
This article uses the Java API.
Java API is the most cumbersome and flexible configuration method, which is suitable for scenarios requiring dynamic configuration through programming.
3. Create a data source
Obtain ShardingSphereDataSource through ShardingSphereDataSourceFactory factory and rule configuration object. This object is implemented from the standard DataSource interface of JDBC and can be used for native JDBC development, or ORM class libraries such as JPA, Hibernate, MyBatis, etc.
DataSource dataSource = ShardingSphereDataSourceFactory.createDataSource(schemaName, modeConfig, dataSourceMap, ruleConfigs, props);
4, Core concept
Table 1
- Logical table: the general name of tables of the same type (with the same logic and data structure) during horizontal splitting. For example, the test log table is divided into 10 tables by year according to the update time. They are test2020 to test2029 respectively, and their logical table name is test.
- Actual table: a physical table that exists in a fragmented database, that is, test2020 to test2029 in the previous example.
- BindingTable: refers to the main table and sub table with consistent fragmentation rules. When using a bound table for multi table Association query, you must use the fragmentation key for association, otherwise Cartesian product association or cross database association will occur, which will affect the query efficiency.
- Broadcast table: refers to the table that exists in all fragment data sources. The table structure and its data are completely consistent in each database. It is applicable to scenarios where the amount of data is small and needs to be associated with massive data tables, such as dictionary tables and provincial and urban tables.
- Single table: refers to the only table that exists in all fragmented data sources. It is applicable to tables with small amount of data and without fragmentation.
2 data node
The smallest unit of data fragmentation, which is composed of data source name and real table. Example: ds_0.test2020.
3 slices
- ShardingColumn: the sharding field is used to split the database (table) horizontally. It supports single field and multi field sharding. For example, if the update time in the log table is sharded by year, the update time is a sharding field. If there is no sharding field in SQL, full routing will be executed, and the performance is poor.
- Partition algorithm (ShardingAlgorithm): the algorithm used for horizontal splitting. The sharding algorithm needs to be implemented by the application developer, and the flexibility is very high. At present, there are four sharding algorithms. Because the sharding algorithm is closely related to the business implementation, the built-in sharding algorithm is not provided, but various scenarios are extracted through the sharding strategy to provide a higher level of abstraction And provide an interface for application developers to implement the fragmentation algorithm by themselves.
- Precise sharding algorithm: required. It is used to process the scene of sharding with = and IN using a single key as the sharding key.
- Range sharding algorithm (RangeSharding): optional. It is used to process the scenario of sharding using a single key as the BETWEEN AND. If RangeShardingAlgorithm is not configured, the BETWEEN AND in SQL will be processed according to the full database route.
- Complex keys sharding: it is used to deal with scenarios where multiple keys are used as sharding keys. The logic of multiple sharding keys is complex, and the complexity needs to be handled by the application developer.
- Hint sharding algorithm: used to process scenes using hint row sharding. It needs to be used in conjunction with HintShardingStrategy.
- Sharding strategy: it includes sharding keys and sharding algorithms. Due to the independence of sharding algorithms, they are separated independently. Sharding keys + sharding algorithms, that is, sharding strategies, are really used for sharding operations. At present, there are five kinds of sharding strategies.
- Standard fragmentation strategy (StandardShardingStrategy): provides support for slicing operations of =, IN and BETWEEN AND IN SQL statements. StandardShardingStrategy only supports single slicing key and provides two slicing algorithms: PreciseSharding and RangeSharding. PreciseSharding is required to process the slicing of = and IN. RangeSharding is optional to process BETWEEN AND if RangeSharding is not configured Rding, BETWEEN AND IN SQL will be processed according to the whole database route.
- Composite fragmentation strategy (ComplexShardingStrategy): it supports the slicing operation of =, IN and BETWEEN AND IN SQL statements. ComplexShardingStrategy supports multi slicing keys. Because the relationship between multi slicing keys is complex, it does not carry out too much encapsulation. Instead, it directly combines the slicing key values and transparently transmits the slicing operators to the slicing algorithm, which is completely implemented by the application developer and provides the greatest flexibility Flexibility.
- Hint sharding strategy: a strategy for sharding through hint rather than SQL parsing.
- InlineShardingStrategy: Groovy's expression is used to support the slicing operation of = and IN in SQL statements, and only single slicing key is supported. Simple slicing algorithms can be used through simple configuration, so as to avoid cumbersome Java code development, such as t_user_ $- > {u_id% 8} Represents t_ User table according to u_ ID module 8 is divided into 8 tables, and the table name is t_user_0 to t_user_7.
- Non sharding strategy: a non sharding strategy.
4 process
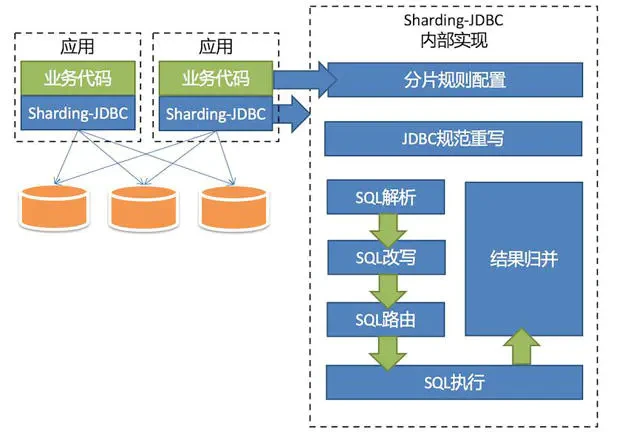
- SQL parsing: it is divided into lexical parsing and syntax parsing. First, the SQL is divided into non separable words through the lexical parser. Then use the syntax parser to understand SQL, and finally extract the parsing context. The parsing context includes tables, selections, sorting items, grouping items, aggregation functions, paging information, query criteria, and markers of placeholders that may need to be modified.
- SQL rewrite: Rewrite SQL into statements that can be executed correctly in a real database. SQL rewriting is divided into correctness rewriting and optimization rewriting.
- SQL Routing: match the partition policy configured by the user according to the resolution context, and generate a routing path. At present, fragment routing and broadcast routing are supported.
- SQL execution: executed asynchronously through a multithreaded executor.
- Result merging: merge multiple execution results to facilitate output through a unified JDBC interface. Result merging includes stream merging, memory merging and additional merging using decorator mode.
5-line expression
Line expression: it is essentially a piece of Groovy code. It can return the corresponding real data source or real table name according to the calculation method of fragment key. The simplification and integration of configuration are the two main problems that row expressions want to solve.
- Syntax: use ${expression} or $- > {expression} to identify line expressions$ {begin..end} indicates the range interval$ {[unit1, unit2, unit_x]} represents the enumeration value.
- application
Data node
Raw data structure
ds0
├── test2020
└── test2021
ds1
├── test2022
└── test2023
Convert to line expression
ds0.test202${0..1},ds1.test202${2..3}
Sharding algorithm: for SQL sharding using = and IN with only one sharding key, line expression can be used instead of coding configuration.
It is divided into 10 libraries. The data with mantissa 0 is routed to the data source with suffix 0, the data with mantissa 1 is routed to the data source with suffix 1, and so on.
ds${id % 10}
5, 2.0 Version 3 usage configuration
1 data preparation
Build tables test2020, test2021, test2022, etc. in MySQL in advance. The rule is to set updateTime as the sub table column, and the timestamp is changed to the sub table after the year.
2 rule configuration
Customize the table splitting algorithm and determine the table splitting rules in the doSharding method.
1. Standard shardingstrategy
// Accurate sub table UpdateTimePreciseShardingAlgorithm
public class UpdateTimePreciseShardingAlgorithm implements PreciseShardingAlgorithm {
@Override
public String doSharding(Collection availableTargetNames, PreciseShardingValue shardingValue) {
// Custom table splitting rules
return "Table name after sub table";
}
}
// Range sub table UpdateTimeRangeShardingAlgorithm
public class UpdateTimeRangeShardingAlgorithm implements RangeShardingAlgorithm {
@Override
public Collection<String> doSharding(Collection availableTargetNames, RangeShardingValue shardingValue) {
// Customize the sub table according to the range, and the table names after the sub table
return new ArrayList<String>();
}
}
2. Composite shardingstrategy
public final class ComplexModuloTableShardingAlgorithm implements ComplexKeysShardingAlgorithm<Integer> {
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames, Collection<ShardingValue> shardingValues) {
// Rules of composite partition, table names after table partition
return new ArrayList<String>();
}
}
3. HintShardingStrategy
public final class HintModuloTableShardingAlgorithm implements HintShardingAlgorithm<Integer> {
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames, ShardingValue shardingValue) {
// Hint segmentation rules, table names after table segmentation
return new ArrayList<String>();
}
}
3 create data source
The user-defined partition key is associated with the data source. Here, take the standard partition strategy and row expression as an example.
1. Standard segmentation strategy
public class MySqlConfiguration {
public ShardingDataSource shardingDataSource(DataSource dataSource) throws SQLException {
// Custom logical nodes and table keys
TableRuleConfiguration testTableRuleConfig = new TableRuleConfiguration();
testTableRuleConfig.setLogicTable("test");
testTableRuleConfig.setKeyGeneratorColumnName("updateTime");
ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration();
shardingRuleConfig.getTableRuleConfigs().add(testTableRuleConfig);
shardingRuleConfig.getBindingTableGroups().add("test");
// Custom table splitting policies PreciseModuloTableShardingAlgorithm and RangeModuloTableShardingAlgorithm
shardingRuleConfig.setDefaultTableShardingStrategyConfig(new StandardShardingStrategyConfiguration("updateTime", UpdateTimePreciseShardingAlgorithm.class.getName(), UpdateTimeRangeShardingAlgorithm.class.getName()));
Map<String, DataSource> result = new HashMap<>(2);
result.put("ShardingDataSource", dataSource);
return new ShardingDataSource(shardingRuleConfig.build(result));
}
}
2. Row expression
public class MySqlConfiguration {
public ShardingDataSource shardingDataSource(DataSource dataSource) throws SQLException {
// Custom logical nodes and table keys
TableRuleConfiguration testTableRuleConfig = new TableRuleConfiguration();
testTableRuleConfig.setLogicTable("test");
testTableRuleConfig.setKeyGeneratorColumnName("id");
ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration();
shardingRuleConfig.getTableRuleConfigs().add(testTableRuleConfig);
shardingRuleConfig.getBindingTableGroups().add("test");
// Row expression table splitting strategy
shardingRuleConfig.setDefaultTableShardingStrategyConfig(new InlineShardingStrategyConfiguration("id", "test${id % 2}"));
Map<String, DataSource> result = new HashMap<>(2);
result.put("ShardingDataSource", dataSource);
return new ShardingDataSource(shardingRuleConfig.build(result));
}
}
6, 4.1 Version 1 usage configuration
1 data preparation
Build tables test2020, test2021, test2022, etc. in MySQL in advance. The rule is to set updateTime as the sub table column, and the timestamp is changed to the sub table after the year.
2 rule configuration
Customize the table splitting algorithm and determine the table splitting rules in the doSharding method.
1. Standard shardingstrategy
// Accurate sub table UpdateTimePreciseShardingAlgorithm
public class UpdateTimePreciseShardingAlgorithm implements PreciseShardingAlgorithm {
@Override
public String doSharding(Collection availableTargetNames, PreciseShardingValue shardingValue) {
// Custom table splitting rules
return "Table name after sub table";
}
}
// Range sub table UpdateTimeRangeShardingAlgorithm
public class UpdateTimeRangeShardingAlgorithm implements RangeShardingAlgorithm {
@Override
public Collection<String> doSharding(Collection availableTargetNames, RangeShardingValue shardingValue) {
// Customize sub table according to range
return "Table names after sub table";
}
}
2. Composite shardingstrategy
public class UpdateTimeComplexShardingAlgorithm implements ComplexKeysShardingAlgorithm {
@Override
public Collection<String> doSharding(Collection availableTargetNames, ComplexKeysShardingValue shardingValue) {
// Rules of composite partition, table names after table partition
return new ArrayList<String>();
}
}
3. HintShardingStrategy
public class UpdateTimeHintShardingAlgorithm implements HintShardingAlgorithm {
@Override
public Collection<String> doSharding(Collection availableTargetNames, HintShardingValue shardingValue) {
// Hint segmentation rules, table names after table segmentation
return new ArrayList<String>();
}
}
3 create data source
Customize the table key and data source. Here, take the standard fragmentation strategy and row expression as an example
1. Standard segmentation strategy
public class MysqlConfiguration {
public DataSource shardingMysqlDataSource(DataSource dataSource) {
// Customize the table splitting policies timeprecisesshardingalgorithm and TimeRangeShardingAlgorithm, and the fragment key updateTime
ShardingStrategyConfiguration strategyConfiguration = new StandardShardingStrategyConfiguration("updateTime",
new UpdateTimePreciseShardingAlgorithm(), new UpdateTimeRangeShardingAlgorithm());
// Set logical node and real node
ShardingTableRuleConfiguration testTableRule = new ShardingTableRuleConfiguration("test", "mysql.test202${2..9}");
// Adding sharding rules to nodes
testTableRule.setTableShardingStrategy(strategyConfiguration);
// Sharding global configuration
ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration();
shardingRuleConfig.getTables().add(testTableRule);
Map<String, DataSource> dataSourceMap = new HashMap<>(1);
dataSourceMap.put("mysql", dataSource);
Properties properties = new Properties();
properties.setProperty("sql.show", "false");
// create data source
DataSource dataSource = null;
try {
dataSource = ShardingSphereDataSourceFactory.createDataSource(dataSourceMap, Collections.singleton(shardingRuleConfig), properties);
} catch (SQLException e) {
e.printStackTrace();
}
return dataSource;
}
}
2. Row expression
public class MysqlConfiguration {
public DataSource shardingMysqlDataSource(DataSource dataSource) {
// Set logical node and real node
ShardingTableRuleConfiguration testTableRule = new ShardingTableRuleConfiguration("test", "mysql.test202${2..9}");
// Adding sharding rules to nodes
alarmTableRule.setTableShardingStrategyConfig(new InlineShardingStrategyConfiguration("id", "test${id % 2}"));
// Sharding global configuration
ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration();
shardingRuleConfig.getTables().add(testTableRule);
Map<String, DataSource> dataSourceMap = new HashMap<>(1);
dataSourceMap.put("mysql", dataSource);
Properties properties = new Properties();
properties.setProperty("sql.show", "false");
// create data source
DataSource dataSource = null;
try {
dataSource = ShardingSphereDataSourceFactory.createDataSource(dataSourceMap, Collections.singleton(shardingRuleConfig), properties);
} catch (SQLException e) {
e.printStackTrace();
}
return dataSource;
}
}
7, 5.0 0 version use configuration
1 data preparation
Create tables test2020, test2021 and test2022 in the clickhouse in advance, with updateTime as the sub table column.
2 rule configuration
Customize the table splitting algorithm and determine the table splitting rules in the doSharding method.
1. Standard shardingstrategy
@Slf4j
public class UpdateTimePreciseShardingAlgorithm implements StandardShardingAlgorithm {
// Precise shardingvalue
@Override
public String doSharding(Collection availableTargetNames, PreciseShardingValue shardingValue) {
// Rules for accurate table division
return "Table name after sub table";
}
// Range sub table RangeShardingValue
@Override
public Collection<String> doSharding(Collection availableTargetNames, RangeShardingValue shardingValue) {
// Rules for range table splitting, table names after table splitting
return new ArrayList<String>();
}
@Override
public void init() {
log.info("Initialize standard partition");
}
// The StandardShardingStrategy here needs to be consistent with the new shardingspherealgorithmconfiguration ("StandardShardingStrategy", new properties()) in the data source
@Override
public String getType() {
return "StandardShardingStrategy";
}
}
2. Composite shardingstrategy
@Slf4j
public class UpdateTimeComplexShardingAlgorithm implements ComplexKeysShardingAlgorithm {
@Override
public Collection<String> doSharding(Collection availableTargetNames, ComplexKeysShardingValue shardingValue) {
// Rules of composite partition, table names after table partition
return new ArrayList<String>();
}
@Override
public void init() {
log.info("Initializing composite shards");
}
// The ComplexShardingStrategy here needs to be consistent with the new shardingspherealgorithmconfiguration ("ComplexShardingStrategy", new properties()) in the data source
@Override
public String getType() {
return "ComplexShardingStrategy";
}
}
3.Hint shardingstrategy
@Slf4j
public class UpdateTimeHintShardingAlgorithm implements HintShardingAlgorithm {
@Override
public void init() {
log.info("initialization Hint Slice");
}
// The HintShardingStrategy here needs to be consistent with the new shardingspherealgorithmconfiguration ("HintShardingStrategy", new properties()) in the data source
@Override
public String getType() {
return "HintShardingStrategy";
}
@Override
public Collection<String> doSharding(Collection availableTargetNames, HintShardingValue shardingValue) {
// Hint segmentation rules, table names after table segmentation
return new ArrayList<String>();
}
}
3 create data source
Customize table keys and data sources. Here you can configure standard sharding policies and row expression examples
1. Standard segmentation strategy
public class ClickHouseConfiguration {
public DataSource shardingClickHouseDataSource(DataSource clickHouseDataSource) {
// Table splitting strategy
StandardShardingStrategyConfiguration strategyConfiguration = new StandardShardingStrategyConfiguration("updateTime", "tableShardingAlgorithm");
// Configure device table rules
ShardingTableRuleConfiguration testTableRule = new ShardingTableRuleConfiguration("test", "clickHouse.test202${0..9}");
testTableRule .setTableShardingStrategy(strategyConfiguration);
// Sharding global configuration
ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration();
shardingRuleConfig.getTables().add(testTableRule );
// Configure the table splitting algorithm and set the table splitting by month
shardingRuleConfig.getShardingAlgorithms().put("tableShardingAlgorithm", new ShardingSphereAlgorithmConfiguration("StandardShardingStrategy", new Properties()));
Map<String, DataSource> dataSourceMap = new HashMap<>(1);
dataSourceMap.put("clickHouse", clickHouseDataSource);
Properties properties = new Properties();
properties.setProperty("sql.show", "false");
// create data source
DataSource dataSource = null;
try {
dataSource = ShardingSphereDataSourceFactory.createDataSource(dataSourceMap, Collections.singleton(shardingRuleConfig), properties);
} catch (SQLException e) {
e.printStackTrace();
}
return dataSource;
}
}
2. Row expression
public class ClickHouseConfiguration {
public DataSource shardingClickHouseDataSource(DataSource clickHouseDataSource) {
// Table splitting strategy
StandardShardingStrategyConfiguration strategyConfiguration = new StandardShardingStrategyConfiguration("id", "tableShardingAlgorithm");
// Configure device table rules
ShardingTableRuleConfiguration testTableRule = new ShardingTableRuleConfiguration("test", "clickHouse.test202${0..9}");
testTableRule .setTableShardingStrategy(strategyConfiguration);
// Sharding global configuration
ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration();
shardingRuleConfig.getTables().add(testTableRule );
// Configure row expression fragmentation
Properties dbShardingAlgorithmrProps = new Properties();
dbShardingAlgorithmrProps.setProperty("algorithm-expression", "test${id % 2}");
shardingRuleConfig.getShardingAlgorithms().put("tableShardingAlgorithm", new ShardingSphereAlgorithmConfiguration("INLINE", dbShardingAlgorithmrProps));
Map<String, DataSource> dataSourceMap = new HashMap<>(1);
dataSourceMap.put("clickHouse", clickHouseDataSource);
Properties properties = new Properties();
properties.setProperty("sql.show", "false");
// create data source
DataSource dataSource = null;
try {
dataSource = ShardingSphereDataSourceFactory.createDataSource(dataSourceMap, Collections.singleton(shardingRuleConfig), properties);
} catch (SQLException e) {
e.printStackTrace();
}
return dataSource;
}
}
4 attention
If you want to customize the sharding policy, because you cannot directly specify the custom sharding class when creating the sharding rule new StandardShardingStrategyConfiguration in 5.0, you need to specify it in the configuration file
Create a new file in resources\META-INF\services \ org apache. shardingsphere. sharding. spi. Shardingalgorithm, which specifies the custom sharding class
com.main.UpdateTimePreciseShardingAlgorithm
8, Testing
1.Mapper.java
@Repository
public interface test {
void insertTest(Map<String,Object> map);
List<Map<String, Object>> getListTest(Map<String,Object> map);
}
2.Mapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" >
<mapper namespace="test">
<insert id="insertTest" parameterType="hashmap">
insert into test (
<if test="id != null">id,</if>
<if test="updateTime != null">updateTime</if>
)
values (
<if test="id != null">#{id},</if>
<if test="updateTime != null">#{updateTime}</if>
)
</insert>
<select id="getListTest" resultType="java.util.HashMap">
select id,updateTime from test
<where>
<if test="updateTime != null">
updateTime <![CDATA[ <= ]]> #{updateTime}
and updateTime >= #{updateTime}
</if>
</where>
</select>
</mapper>
3 verification insertion
@GetMapping(value = "/TestInsertOrder")
public void TestInsertOrder(){
List<Map<String,Object>> orderList = new ArrayList<>();
Map<String,Object> map = new HashMap<>();
map.put("id",1);
map.put("updateTime",1577808000);
orderList.add(map);
map = new HashMap<>();
map.put("id",2);
map.put("updateTime",1609430400);
orderList.add(map);
for(Map<String,Object> maptmp:orderList){
netMapper.insertTest(maptmp);
}
}
4. Verification query
@GetMapping(value = "/TestListOrder")
public void TestListOrder(){
Map<String,Object> map = new HashMap<>();
map.put("updateTime",1577808000);
List<Map<String,Object>> orderList= netMapper.getListTest(map);
for (Map<String,Object> o:orderList){
System.out.println(o.toString());
}
}