🍅 About the author: Nezha, second runner up of CSDN2021 blog star 🏆, New Star Program mentor ✌, Blog expert 💪
🍅 Nezha's work summary for many years: Java learning route summary, brick movers counter attack Java Architects
🍅 Pay attention to the official account [n. Zha] programming, reply 1024, get Java learning route map, big factory interview real question, join the WAN powder plan exchange group, study together progress
catalogue
2, Method of dividing database and table
3, Problems caused by sub database and sub table
4. Cross node count, order by, group by and aggregate function problems
5. Data migration, capacity planning and capacity expansion
7. Sorting and paging across shards
5, Third party solution for sub database and sub table -- Apache ShardingSphere
6, Three core concepts of Apache ShardingSphere
7, Three products of Apache ShardingSphere
8, Shardingsphere JDBC code example
1. Shardingsphere JDBC implementation level sub table
2. Shardingsphere JDBC realizes horizontal sub database
9, What is read write separation
10, Configure MySQL master-slave server
2. Modify the configuration files of master and slave Libraries
3. Create an account for master-slave replication
4. Set data synchronization from the library to the main library
11, Sharding JDBC realizes the separation of reading and writing
1, Sub database and sub table
1. With the development of time and business, the amount of database data is uncontrollable, resulting in more and more data in the table. At this time, CRUD operation will cause great performance problems, such as querying real-time data. The table data has reached tens of millions of levels. It is required to query once a minute, but it takes you two minutes to complete a select. Isn't it very embarrassing.
2. Database and table splitting is to solve the problem of database performance degradation due to excessive amount of data. The original independent database is divided into several databases, and the large data table is divided into several data tables, so as to reduce the amount of data in a single database and single data table, so as to improve the performance of the database.
3. Performance solutions
Option 1
Improve the data processing capacity by improving the hardware capacity of the server, such as increasing storage capacity and CPU. This scheme costs a lot, and if the bottleneck is MySQL itself, it is also helpful to improve the hardware.
Option 2
Disperse the data into different databases to reduce the amount of data in a single database, so as to alleviate the performance problem of a single database, so as to improve the performance of the database.
2, Method of dividing database and table
Vertical sub table, vertical sub warehouse, horizontal sub table and horizontal sub warehouse.
1. Vertical sub table
(1) Basic concepts
Divide a table into multiple tables according to fields, and each table stores some of the fields.
(2) Performance improvement
- In order to avoid IO contention and reduce the probability of locking the table;
- Give full play to the operation efficiency of popular data. Popular fields and unpopular fields are stored separately, such as a product basic information table and a product details table. Large fields must be placed in the table of unpopular fields.
(3) Why is large field IO inefficient?
- The length of the data itself is too long and requires longer reading time;
- Span page is the basic unit of database storage. Many search and positioning operations are based on pages. The more data rows in a single page, the better the overall performance of the database, the larger the space occupied by large fields and the less data stored on a single page, so the IO efficiency is low;
- Data is loaded into memory in behavioral units. If the field length is short, memory can load more data and reduce disk IO, so as to improve database performance;
2. Vertical sub database
(1) Basic concepts
Each CPU and vertical table are distributed to the same disk, but there is no single competing table and data table on the same network.
Vertical database division means to classify tables and deploy them on different databases. Each database is placed on different servers. Its core idea is to use special databases for special purposes.
Each microservice uses a separate database.
(2) Performance improvement
- Solve the coupling at the business level and make the business clear
- It can manage, maintain, monitor and expand the data of different businesses at different levels
- In the high concurrency scenario, the vertical sub library can improve IO, reduce the number of database connections and reduce the bottleneck of stand-alone hardware resources
3. Horizontal sub table
(1) Basic concepts
Horizontal split table is to split the data of the same table into multiple tables according to certain rules in the same database.
(2) Performance improvement
- Optimize the performance problems caused by the large amount of data in a single table
- Avoid IO contention and reduce the probability of locking the table
The horizontal split table in a single database solves the problem of too much data in a single table. The split small table contains only part of the data, which makes the single table query faster and more efficient.
(3) Horizontal table
① Hash mold splitting table
This method is generally adopted for database table splitting. For example, a position table is divided into four tables according to position ID% 4 and the results.
advantage:
Data fragmentation is relatively average, and it is not easy to have hot spots and bottlenecks of concurrent access.
Disadvantages:
It is easy to produce complex problems of cross fragment query.
② Numerical Range sub table
Segment according to time interval or ID interval.
advantage:
- Single table size controllable
- Easy to expand
- Effectively avoid the problem of cross fragment query
Disadvantages:
Hot data becomes a performance bottleneck.
For example, some fragments are stored in the table of the latest time period, which may be read and written frequently, while the historical data table is accessed less.
③ Consistent Hash algorithm
It's complicated. Xiaobian won't introduce it for the time being. Those who are interested can baidu by themselves.
4. Horizontal sub database
(1) Basic concepts
Horizontal sub database is to divide the data of the same table into different databases according to certain rules, and each database can be placed on different servers.
(2) Performance improvement
- It solves the bottleneck of large amount of data and high concurrency in a single database
- The stability and availability of the system are improved
(3) When to use
When it is difficult for an application to perform vertical segmentation, or the number of data lines after vertical segmentation is huge, and there is a performance bottleneck of single database read-write storage, you can consider using horizontal database.
(4) Abuse of use
However, the disadvantages of horizontal database are also obvious. You need to determine which database the data you need is in, so it greatly improves the complexity of the system.
5. Summary
- Vertical table: popular data and unpopular data are stored separately, and large fields are placed in the unpopular data table.
- Vertical sub Library: split according to business and put them into different libraries. These libraries are deployed on different servers to solve the performance bottleneck of a single server and improve the business clarity of the overall architecture.
- Horizontal sub table: solve the problem of too much data in a single table
- Horizontal database Division: divide the data of a table into different databases, which are deployed on different servers to solve the problem of excessive data on a single server
3, Problems caused by sub database and sub table
1. Learning cost problem
Most junior developers can't divide databases and tables. If they can't use them, they might as well use a single database directly.

2. Transaction issues
(1) Solution 1: use distributed transactions
① Advantages
Managed by database, simple and effective.
② Shortcomings
The cost of performance is high, especially when there are more and more Shards.
(2) Solution 2: jointly controlled by application and database
① Principle
Decompose a large distributed transaction into small transactions of a single database, and control each small transaction through the application.
② Advantages
Better performance
③ Shortcomings
The application needs to be flexibly designed in transaction control. If Spring's transaction management mechanism is used, it will face some difficulties in changing.
3. Cross node join problem
The solution is to query twice.
4. Cross node count, order by, group by and aggregate function problems
Similar to the join solution, the results are obtained at each node and then merged. The difference between and join is that the query of each node can be executed in parallel, so its speed is much faster than that of a single large table. However, if the result set is large, the consumption of application memory is also a problem.
5. Data migration, capacity planning and capacity expansion
6. Primary key ID problem
Because of the split table, the primary key auto increment strategy wufa is implemented.
Solution 1: UUID
Using UUID as the primary key is the simplest solution, but the disadvantage is that UUID is very long and will occupy a lot of storage space. There are also performance problems in the query of linked tables.
Solution 2: create a Sequence table
Create a new table with table in the field_ Name and next_id.
After seeing the table structure, seconds, okay?
The general meaning is to record the next ID of each table after table splitting. The disadvantage is obvious, that is, each time you insert data, you have to access this table to obtain the ID of the inserted data. This table is easy to be called the bottleneck of system performance. At the same time, it also has a single point problem. Once the table database fails, the whole system cannot work normally. At this time, the single point problem may be solved through the synchronization mechanism of the active and standby machines.
Solution 3: Twitter's distributed self increasing ID algorithm Snowflake
The structure of snowflake is as follows (each part is separated by -)
0 - 0000000000 0000000000 0000000000 0000000000 0 - 00000 - 00000 - 000000000000
The first bit is unused, the next 41 bits are millisecond time (the length of 41 bits can be used for 69 years), followed by 5-bit datacenter ID and 5-bit workerid (the length of 10 bits can support the deployment of 1024 nodes at most), and the last 12 bits are counts within milliseconds (the counting sequence number of 12 bits supports 4096 ID sequence numbers per millisecond for each node)
Add up to 64 bits, just one. (maximum length after conversion to string is 19)
The IDs generated by snowflake are sorted by time increment as a whole, and there is no ID collision in the whole distributed system (distinguished by datacenter and workerId), and the efficiency is high. After testing, snowflake can generate 260000 IDS per second.
7. Sorting and paging across shards
Sort the data in different slice nodes, summarize the result models, and sort again.
4, Sub warehouse quantity
First of all, the number of sub databases is closely related to the processing capacity of a single database. For example, there are more than 50 million records in a single MySQL database and more than 100 million records in an Oracle database, which puts a lot of pressure on the database.
On the premise of meeting the above requirements, if the number of sub databases is small, the purpose of decentralized storage and reducing DB performance pressure cannot be achieved; If the number of sub databases is large, cross database access is also a problem. If it is concurrent mode, it will consume valuable thread resources. If it is serial, even, the execution time will increase sharply.
The number of libraries will also directly affect the investment of hardware, so the number of libraries to be divided should be comprehensively evaluated. Generally, it is recommended to divide them into 4-8 libraries for the first time.
5, Third party solution for sub database and sub table -- Apache ShardingSphere
Apache ShardingSphere is an ecosystem composed of a set of distributed database middleware solutions. It is composed of sharding JDBC, sharding proxy and sharding sidecar (under planning), which are independent of each other but can be deployed and used together. They all provide standardized data fragmentation, distributed transaction and database governance functions, which can be applied to various application scenarios such as Java isomorphism, heterogeneous language, cloud native and so on.
ShardingShpere is positioned as a relational database middleware, which aims to make full and reasonable use of the computing and storage capacity of relational database in distributed scenarios, rather than realizing a new relational database. It grasps the essence of things by paying attention to the invariance.
Apache ShardingSphere 5. Version x began to focus on pluggable architecture, and the functional components of the project can be flexibly expanded in a pluggable way. At present, the functions of data fragmentation, read-write separation, data encryption, shadow database pressure test, and the support of SQL and protocols such as MySQL, postgresql, SQLServer and Oracle are woven into the project through plug-ins. Developers can customize their own unique systems like building blocks. Apache shardingsphere has provided dozens of SPI s as the extension points of the system, which is still increasing.
Apache ShardingSphere product is positioned as Database Plus, which aims to build the upper standard and ecology of multi-mode database. It focuses on how to make full and rational use of the computing and storage capacity of the database, rather than realizing a new database. Apache ShardingSphere stands at the upper level of the database and pays more attention to the cooperation between them than the database itself.
6, Three core concepts of Apache ShardingSphere
1. Connect
Through the flexible adaptation of database protocol, SQL dialect and database storage, it can quickly connect applications with multi-mode heterogeneous databases.
2. Increment
Obtain the access traffic of the database, and provide transparent incremental functions such as traffic redirection (data fragmentation, read-write separation, shadow database), traffic deformation (data encryption, data desensitization), traffic authentication (security, audit, authority), traffic governance (fusing, flow restriction) and traffic analysis (service quality analysis, observability).
3. Pluggable
The project adopts micro kernel + 3-layer pluggable mode, so that the kernel, functional components and ecological docking can be pluggable expanded in a flexible way, and developers can customize their own unique system of data like building blocks.
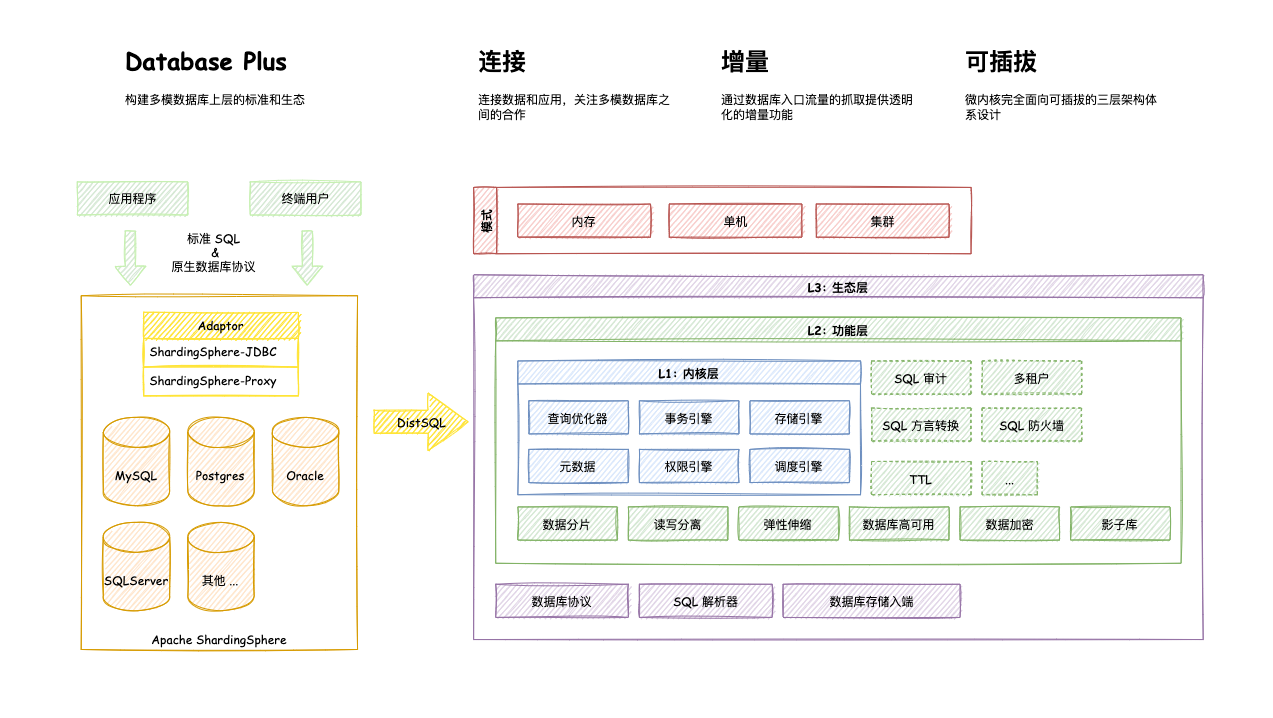
7, Three products of Apache ShardingSphere
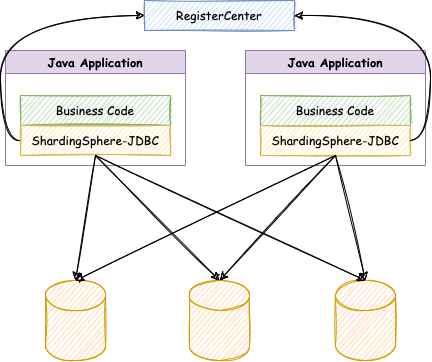
1,ShardingSphere-JDBC
Positioned as a lightweight Java framework, it provides additional services in the JDBC layer of Java. It uses the client to directly connect to the database and provides services in the form of jar package without additional deployment and dependence. It can be understood as an enhanced jdbc driver and is fully compatible with JDBC and various ORM frameworks.
It is applicable to any ORM framework based on JDBC, such as mybatis, hibernate, JPA, Spring JDBC Template or directly using JDBC.
It supports any database that implements JDBC specification. At present, it supports MySQL, Oracle, SQLServer and PostgreSQL.
Support any third-party database connection pool, such as Druid, DBCP, C3P0, BoneCP, HikariCP, etc.
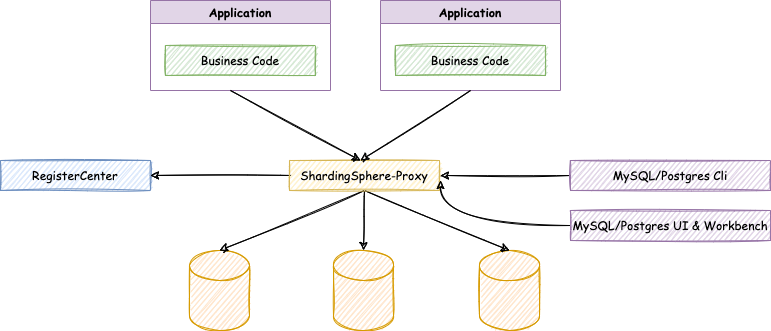
2,Sharding-Proxy
Positioned as a transparent database agent, it provides a server version encapsulating the database binary protocol to support heterogeneous languages. At present, MySQL and PostgreSQL are supported, which can be compatible with Navicat, dbaver and other database third-party clients.
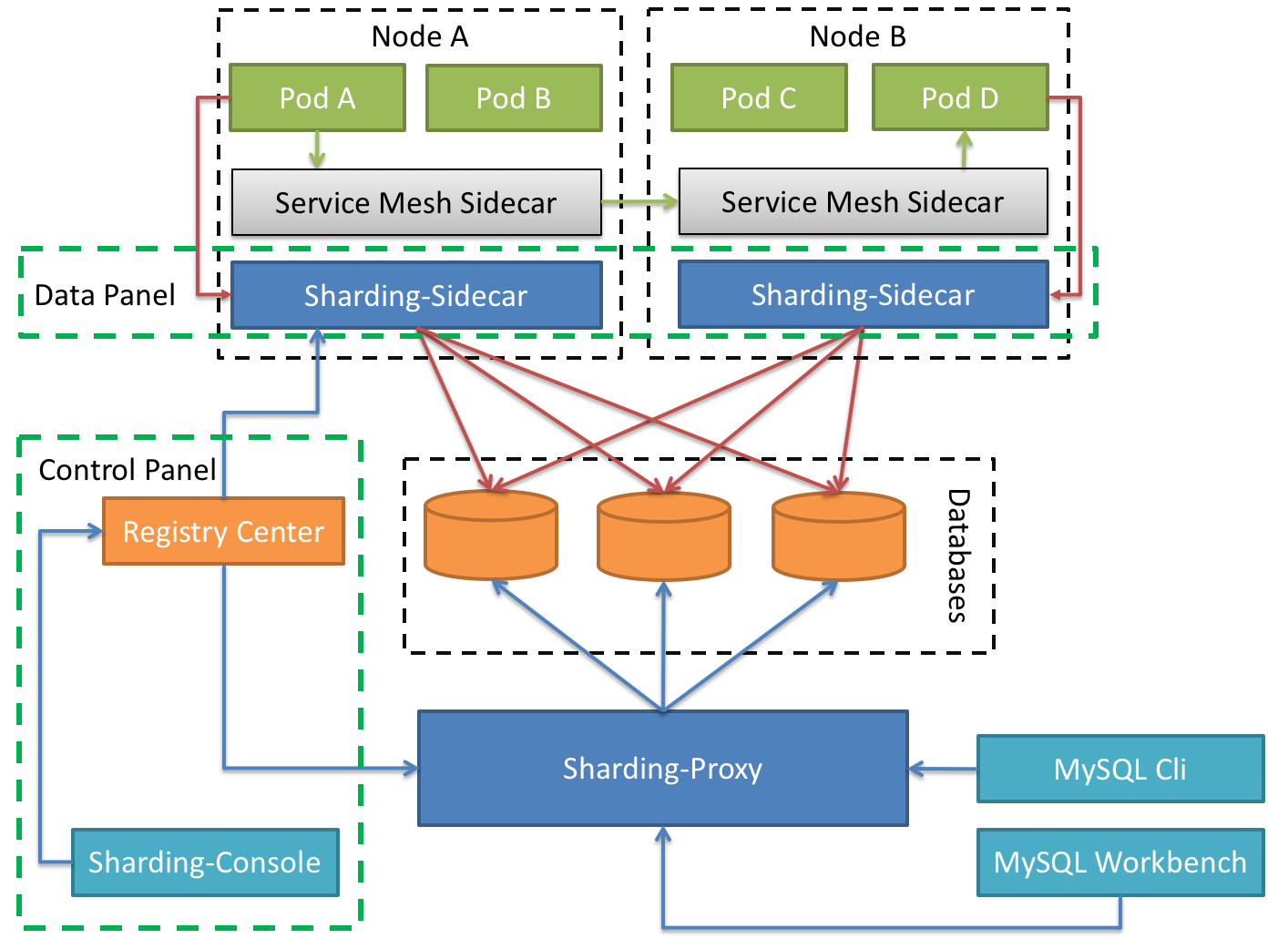
3,ShardingSphere-Sidecar
The cloud native database agent, located as kubernetes, acts as a sidecar agent for all access to the database. The meshing layer that interacts with the database is provided through the scheme of no center and zero intrusion, that is, Database Mesh, also known as database grid.
Database Mesh focuses on how to organically connect distributed data access applications with databases. It pays more attention to interaction, which effectively combs the interaction between chaotic applications and databases. Using Database Mesh, the application and database accessing the database will eventually form a huge grid system. The application and database only need to be seated in the grid system, and they are the objects governed by the meshing layer.
8, Shardingsphere JDBC code example
1. Shardingsphere JDBC implementation level sub table
(1)pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.2.1.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.guor</groupId>
<artifactId>shardingjdbc</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>shardingjdbc</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.20</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.0.5</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
(2)application.properties
For simple configuration of ShardingSphere JDBC, please refer to the official ShardingSphere documentation.
# Sharding JDBC sharding strategy
# Configure the data source and give it a name,
# Horizontal sub database with two data sources configured
spring.shardingsphere.datasource.names=g1
# One entity class corresponds to two tables, covering
spring.main.allow-bean-definition-overriding=true
#Configure the specific content of the first data source, including connection pool, driver, address, user name and password
spring.shardingsphere.datasource.g1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.g1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.g1.url=jdbc:mysql://localhost:3306/guor?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.g1.username=root
spring.shardingsphere.datasource.g1.password=root
#Specify the database distribution and the table distribution in the database
spring.shardingsphere.sharding.tables.course.actual-data-nodes=g1.student_$->{1..2}
# Specify the primary key id generation policy SNOWFLAKE in the student table
spring.shardingsphere.sharding.tables.student.key-generator.column=id
spring.shardingsphere.sharding.tables.student.key-generator.type=SNOWFLAKE
# Specifies that the id value of the table fragmentation Policy Convention is even and added to the student_1 table, if cid is odd, add to student_ Table 2
spring.shardingsphere.sharding.tables.student.table-strategy.inline.sharding-column=id
spring.shardingsphere.sharding.tables.student.table-strategy.inline.algorithm-expression=student_$->{id % 2 + 1}
# Open sql output log
spring.shardingsphere.props.sql.show=true(3)student
package com.guor.shardingjdbc.bean;
import lombok.Data;
import java.util.Date;
@Data
public class Student {
private Long id;
private String name;
private Integer age;
private Integer sex;
private String address;
private String phone;
private Date create_time;
private Date update_time;
private String deleted;
private String teacher_id;
}
(4)mapper
Because mybatis is used_ Plus, so the CRUD of a single table can inherit BaseMapper.
package com.guor.shardingjdbc.mapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.guor.shardingjdbc.bean.Student;
import org.springframework.stereotype.Repository;
@Repository
public interface StudentMapper extends BaseMapper<Student> {
}
(5) Startup class
package com.guor.shardingjdbc;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
@MapperScan("com.guor.shardingjdbc.mapper")
public class ShardingjdbcApplication {
public static void main(String[] args) {
SpringApplication.run(ShardingjdbcApplication.class, args);
}
}
(6)test
package com.guor.shardingjdbc;
import com.guor.shardingjdbc.bean.Student;
import com.guor.shardingjdbc.mapper.StudentMapper;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.Date;
@SpringBootTest
class ShardingjdbcApplicationTests {
@Autowired
private StudentMapper studentMapper;
@Test
void addStudent() {
Student student = new Student();
student.setName("nezha");
student.setAge(18);
student.setCreate_time(new Date());
student.setPhone("10086");
studentMapper.insert(student);
}
}
(7) sql table creation statement
-- guor.student_1 definition CREATE TABLE `student_1` ( `id` bigint(20) DEFAULT NULL, `name` varchar(100) NOT NULL, `age` int(10) NOT NULL, `sex` int(11) DEFAULT NULL, `address` varchar(100) DEFAULT NULL, `phone` varchar(100) DEFAULT NULL, `create_time` timestamp NULL DEFAULT NULL, `update_time` timestamp NULL DEFAULT NULL, `deleted` int(11) DEFAULT NULL, `teacher_id` int(11) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
(8) Horizontal split table - > insert database

2. Shardingsphere JDBC realizes horizontal sub database
First, build a new library, guor1 library, and then build two students like the above_ 1 and student_ Table 2.
(1) Add application properties
# Sharding JDBC sharding strategy
# Configure the data source and give it a name,
# Horizontal sub database with two data sources configured
spring.shardingsphere.datasource.names=ds1,ds2
# One entity class corresponds to two tables, covering
spring.main.allow-bean-definition-overriding=true
#Configure the specific content of the first data source, including connection pool, driver, address, user name and password
spring.shardingsphere.datasource.ds1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds1.url=jdbc:mysql://localhost:3306/guor?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.ds1.username=root
spring.shardingsphere.datasource.ds1.password=root
#Configure the specific content of the second data source, including connection pool, driver, address, user name and password
spring.shardingsphere.datasource.ds2.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds2.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds2.url=jdbc:mysql://localhost:3306/guor1?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.ds2.username=root
spring.shardingsphere.datasource.ds2.password=root
#Specify the database distribution and the table distribution in the database
spring.shardingsphere.sharding.tables.course.actual-data-nodes=ds$->{1..2}.course_$->{1..2}
# Specify the primary key id generation policy SNOWFLAKE in the student table
spring.shardingsphere.sharding.tables.student.key-generator.column=id
spring.shardingsphere.sharding.tables.student.key-generator.type=SNOWFLAKE
# Specifies that the id value of the table fragmentation Policy Convention is even and added to the student_1 table, if cid is odd, add to student_ Table 2
spring.shardingsphere.sharding.tables.student.table-strategy.inline.sharding-column=id
spring.shardingsphere.sharding.tables.student.table-strategy.inline.algorithm-expression=student_$->{id % 2 + 1}
# Specify database fragmentation policy_ ID is an even number to add ds1 and an odd number to add ds2
#spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column=teacher_id
#spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression=m$->{teacher_id % 2 + 1}
spring.shardingsphere.sharding.tables.student.database-strategy.inline..sharding-column=teacher_id
spring.shardingsphere.sharding.tables.student.database-strategy.inline.algorithm-expression=ds$->{teacher_id % 2 + 1}
# Open sql output log
spring.shardingsphere.props.sql.show=true(2) Testing
package com.guor.shardingjdbc;
import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;
import com.guor.shardingjdbc.bean.Student;
import com.guor.shardingjdbc.mapper.StudentMapper;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.Date;
@SpringBootTest
class ShardingjdbcApplicationTests {
@Autowired
private StudentMapper studentMapper;
//Test level sub database
@Test
void addStudentDb() {
Student student = new Student();
student.setName("nezha");
student.setAge(28);
student.setCreate_time(new Date());
student.setPhone("110");
student.setTeacher_id(101);
studentMapper.insert(student);
}
@Test
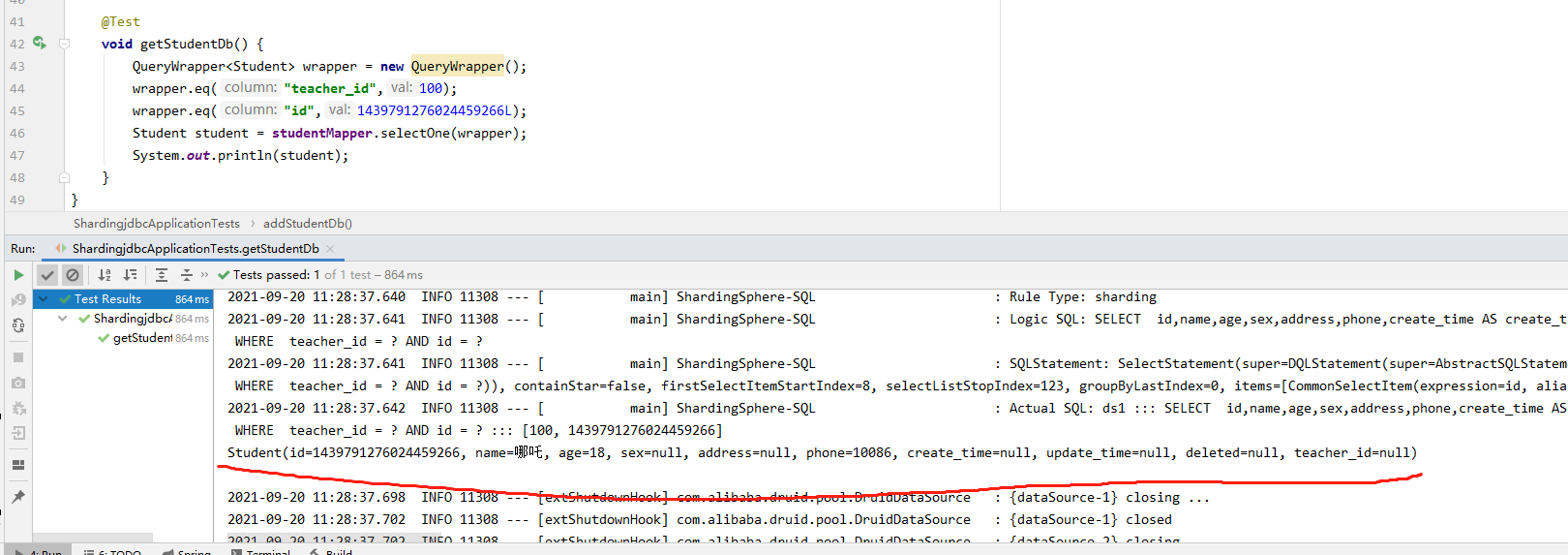
void getStudentDb() {
QueryWrapper<Student> wrapper = new QueryWrapper();
wrapper.eq("teacher_id",100);
wrapper.eq("id",1439791276024459266L);
Student student = studentMapper.selectOne(wrapper);
System.out.println(student);
}
}
(3) Execution results
Horizontal sub database - > insert database

Horizontal sub database - > query database
3. Configure public tables
# Configure public tables spring.shardingsphere.sharding.broadcast-tables=t_udict spring.shardingsphere.sharding.tables.t_udict.key-generator.column=dictid spring.shardingsphere.sharding.tables.t_udict.key-generator.type=SNOWFLAKE
9, What is read write separation
In order to ensure the stability of the database, the dual standby product has many functions.
The first database server provides external production data of addition, deletion and modification business;
The second database server is mainly used for reading;
Sharding JDBC realizes the read-write separation process through the semantic analysis of sql statements, and does not do data synchronization.
10, Configure MySQL master-slave server
1. New MySQL instance
Copy the original mysql, for example: D: \ mysql-5.7.25 (as the master database) - > D: \ mysql-5.7.25-s1 (as the slave database), and modify the my ini:
[mysqld]
#Set 3307 port
port = 3307
#Set the installation directory of mysql +
basedir = D : \mysql‐5.7.25‐s1
#Set the storage directory of data in mysql database
datadir = D : \mysql‐5.7.25‐s1\data
Then install the from the library as a windows service. Pay attention to the location of the configuration file:
D:\mysql‐5.7.25‐s1\b in >mysqld install mysqls1
‐‐defaults‐file = "D:\mysql‐5.7.25‐s1\my.ini"
Delete service command
sc delete service name
Since the slave database is copied from the master database, the data in it is completely consistent. You can log in with the original account and password.
2. Modify the configuration files of master and slave Libraries
Add the following new contents:
Main library my,ini
[mysqld]
#Open log
log‐bin = mysql‐bin
#Set the service id, but the master and slave cannot be consistent
server‐id = 1
#Set the database to be synchronized
binlog‐do‐db = user_db
#Shielding system library synchronization
binlog‐ignore‐db = mysql
binlog‐ignore‐db = information_schema
binlog‐ignore‐db = performance_schema
From library {my ini
[mysqld]
#Open log
log‐bin = mysql‐bin
#Set the service id, but the master and slave cannot be consistent
server‐id = 2
#Set the database to be synchronized
replicate_wild_do_table = user_db.%
#Shielding system library synchronization
replicate_wild_ignore_table = mysql.%
replicate_wild_ignore_table = information_schema.%
replicate_wild_ignore_table = performance_schema.%
Restart master and slave Libraries
3. Create an account for master-slave replication
#Switch to the bin directory of the main database and log in to the main database
mysql ‐h localhost ‐uroot ‐p
#Authorized active / standby replication special account
GRANT REPLICATION SLAVE ON *.* TO 'db_sync' @ '%' IDENTIFIED BY 'db_sync' ;
#Refresh permissions
FLUSH PRIVILEGES;
#Confirm the location and record the file name and location
show master status;
4. Set data synchronization from the library to the main library
# switch to the slave bin directory and log in to the slave
mysql ‐h localhost ‐P3307 ‐uroot ‐p
#Stop synchronization first
STOP SLAVE;
#Modify the point from the library to the main library, and use the file name and location recorded in the previous step
CHANGE MASTER TO
master_host = 'localhost' ,
master_user = 'db_sync' ,
master_password = 'db_sync' ,
master_log_file = 'mysql‐bin.000002' ,
master_log_pos = 154 ;
#Start synchronization
START SLAVE;
#View slave status_ IO_ Running # and # slave_ SQL_ If "running" is "Yes", it indicates that the synchronization is successful. If it is not "Yes", please check
error_log, then
Check relevant abnormalities.
show slave status
#Note: if this slave library has a primary library, you need to clear it by executing the following command first
STOP SLAVE IO_THREAD FOR CHANNEL '' ;
reset slave all;
11, Sharding JDBC realizes the separation of reading and writing
Sharding JDBC cannot realize the master-slave database synchronization. The master-slave database synchronization is realized by MySQL database, while sharding JDBC realizes the operation of the master database when adding, deleting and modifying, and the operation of the slave database when querying data.
# Add data source s0 and use the slave library configured for master-slave synchronization above. spring.shardingsphere.datasource.names = m0,m1,m2,s0 ... spring.shardingsphere.datasource.s0.type = com.alibaba.druid.pool.DruidDataSource spring.shardingsphere.datasource.s0.driver‐class‐name = com.mysql.jdbc.Driver spring.shardingsphere.datasource.s0.url =jdbc:mysql://localhost:3307/user_db?useUnicode=true spring.shardingsphere.datasource.s0.username = root spring.shardingsphere.datasource.s0.password = root .... # The master library defines ds0 as user from the logical data source of the slave library_ db spring.shardingsphere.sharding.master‐slave‐rules.ds0.master‐data‐source‐name=m0 spring.shardingsphere.sharding.master‐slave‐rules.ds0.slave‐data‐source‐names=s0 # t_user sub table policy, which is fixed to the T of ds0_ User real table spring.shardingsphere.sharding.tables.t_user.actual‐data‐nodes = ds0.t_user
🍅 About the author: Nezha, second runner up of CSDN2021 blog star 🏆, New Star Program mentor ✌, Blog expert 💪
🍅 Nezha's work summary for many years: Java learning route summary, brick movers counter attack Java Architects
🍅 Pay attention to the official account [n. Zha] programming, reply 1024, get Java learning route map, big factory interview real question, join the WAN powder plan exchange group, study together progress

Pay attention to the official account, reply 1024, get the Java learning route, mind map, and join the WAN Fen plan exchange group.