Today, we grab a website, this website, the content is related to netizens'messages and replies, particularly simple, but the website is gov. The website is
http://www.sjz.gov.cn/col/1490066682000/index.html
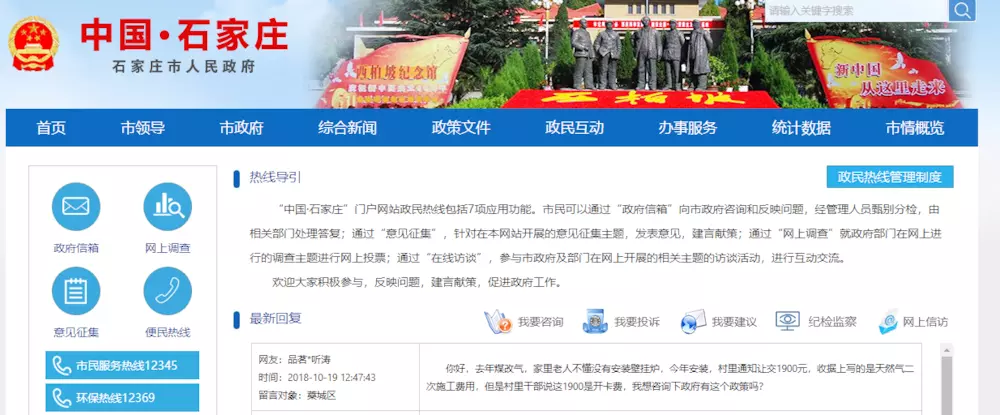
First of all, in order to learn, no malicious crawl information, believe it or not, I do not have long-term storage of data, it is expected to be stored in the reinstallation of the operating system will be deleted.
Shijiazhuang Interactive Data Crawling-Web Page Analysis
Click on more replies to see the corresponding data.
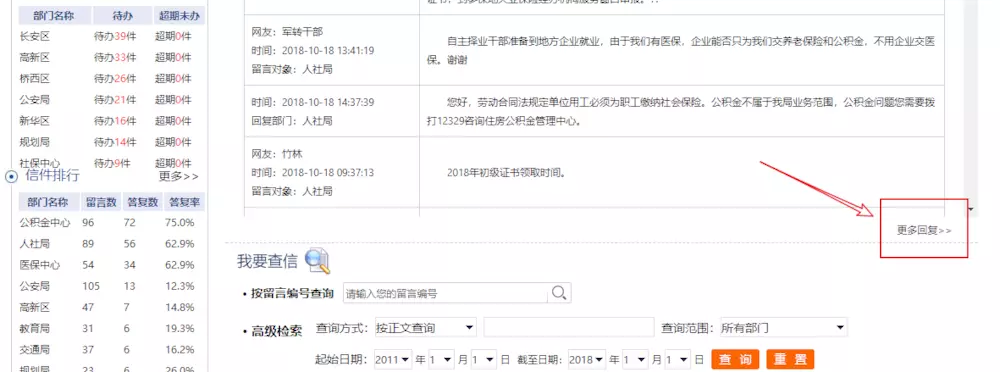
There are 140,000 pieces of data, which can also be used to learn data analysis after crawling. It's really nice.
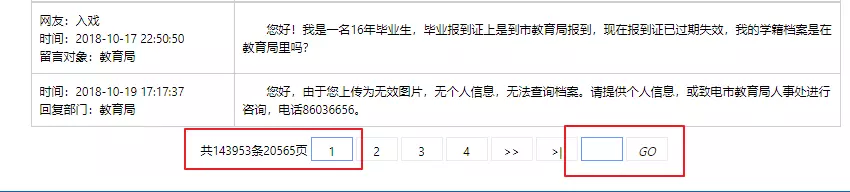
After analysis, the list page was found.
This time we use selenium to crawl data, lxml to parse pages and pymongo to store data. About selenium, you can go to search engine for related tutorials. A lot of things, the main thing is to open a browser, and then simulate the operation of users. You can learn from the system.
Shijiazhuang Interactive Data Crawling-Code
Import Required Modules
from selenium import webdriver from selenium.common.exceptions import TimeoutException from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from lxml import etree import pymongo import time Python Resource sharing qun 784758214 ,Installation packages are included. PDF,Learning videos, here is Python The gathering place of learners, zero foundation and advanced level are all welcomed.
Shijiazhuang Interactive Data Crawling - Open Browser, Get Total Page Number
The most important step of this operation, you will know after searching, need to download a chromedriver.exe in advance, and then configure it, solve it by yourself.~
# To load the browser engine, you need to download chromedriver.exe in advance.
browser = webdriver.Chrome()
wait = WebDriverWait(browser,10)
def get_totle_page():
try:
# Browser Jump
browser.get("http://www.sjz.gov.cn/zfxxinfolist.jsp?current=1&wid=1&cid=1259811582187")
# Waiting for elements to load
totle_page = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR,'input[type="hidden"]:nth-child(4)'))
)
# get attribute
totle = totle_page.get_attribute('value')
# To get the home page data, this place does not need to be
##############################
#get_content()
##############################
return totle
except TimeoutError:
return get_totle_page()
After testing the above code, you will get the following results
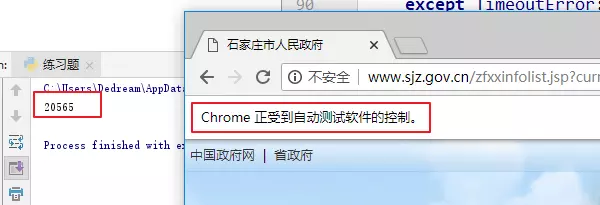
By this time, you have got the total number of 20565 pages, just need to do a series of cyclic operations, then there is an important function called next_page, which needs to simulate user behavior, enter a page number, and click jump.
def main():
totle = int(get_totle_page()) # Get the full page number
for i in range(2,totle+1):
print("Loading section{}Page data".format(i))
# Get the next page
next_page(i)
if __name__ == '__main__':
print(main())
Enter the page number and click jump
def next_page(page_num):
try:
input = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR,"#pageto"))
)
submit = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR,"#goPage"))
)
input.clear() # Clear the text box
input.send_keys(page_num) # Send Page Number
submit.click() # Click Jump
#get_content(page_num)
except TimeoutException:
next_page(page_num)
The effect of the above code implementation is dynamically demonstrated as follows
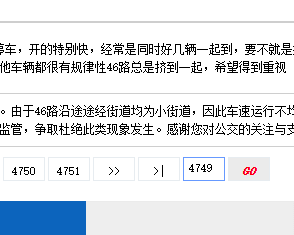
Shijiazhuang Interactive Data Crawling-Analysis Page
After page turning, the source code of the web page can be obtained by browser.page_source, and the source code of the web page can be parsed by lxml. Writing the corresponding method is as follows
def get_content(page_num=None):
try:
wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, "table.tably"))
)
html = browser.page_source # Getting Web Source Code
tree = etree.HTML(html) # analysis
tables = tree.xpath("//table[@class='tably']")
for table in tables:
name = table.xpath("tbody/tr[1]/td[1]/table/tbody/tr[1]/td")[0].text
public_time = table.xpath("tbody/tr[1]/td[1]/table/tbody/tr[2]/td")[0].text
to_people = table.xpath("tbody/tr[1]/td[1]/table/tbody/tr[3]/td")[0].text
content = table.xpath("tbody/tr[1]/td[2]/table/tbody/tr[1]/td")[0].text
repl_time = table.xpath("tbody/tr[2]/td[1]/table/tbody/tr[1]/td")[0].text
repl_depart = table.xpath("tbody/tr[2]/td[1]/table/tbody/tr[2]/td")[0].text
repl_content = table.xpath("tbody/tr[2]/td[2]/table/tbody/tr[1]/td")[0].text
# Clean up data
consult = {
"name":name.replace("Net friend:",""),
"public_time":public_time.replace("Time:",""),
"to_people":to_people.replace("Message object:",""),
"content":content,
"repl_time":repl_time.replace("Time:",""),
"repl_depart":repl_depart.replace("Response Department:",""),
"repl_content":repl_content
}
# Data stored in mongo
#save_mongo(consult)
except Exception: # This place needs special explanation.
print("Exceptional error X1")
print("Browsers take a break")
time.sleep(60)
browser.get("http://www.sjz.gov.cn/zfxxinfolist.jsp?current={}&wid=1&cid=1259811582187".format(page_num))
get_content()
Python Resource sharing qun 784758214 ,Installation packages are included. PDF,Learning videos, here is Python The gathering place of learners, zero foundation and advanced level are all welcomed.
In the actual crawling process, it is found that after hundreds of pages, IP will be limited, so when we capture page information errors, we need to pause, waiting for the page to be normal, and continue crawling data.
Data stored in mongodb
The final data I crawled is stored in mongodb, which is no more difficult. We can write it according to the usual routine.
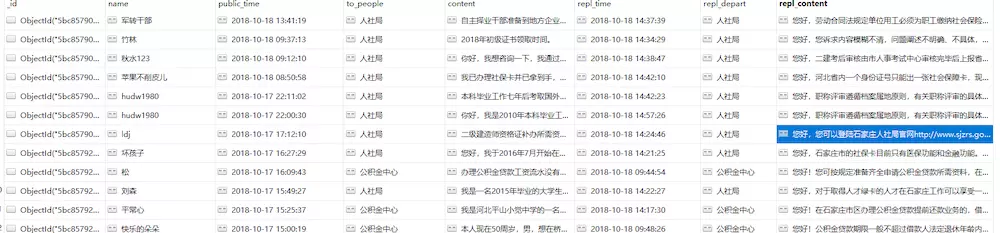
Write at the end
Since this crawl site is gov, it is recommended not to use multi-threading, the source code is not sent to github, or cause trouble, if you have any questions, please comment.
