1.Dijkstra algorithm
1.1 algorithm flow interpretation
1. Initialization:
The shortest path length of the starting point is set to zero, and the shortest path length of the other points is set to positive infinity.
2.n wheel slack:
Dij algorithm divides the points into the set of points with the shortest path and the set of points without the shortest path. The final result must make the set of points without the shortest path empty. At the beginning, the shortest path is not found at all points, so N rounds of relaxation is required, that is, the number of outermost cycles.
3. Each round of relaxation: find the point closest to the starting point in the set of points where the shortest path is not found:
Find a point closest to the starting point in the set of points without the shortest path, and add it to the set of points with the shortest path.
4. Each round of relaxation: update the distance from the point to the point in the set of all points that have not found the shortest path:
After finding the point, traverse all the adjacent vertices of the point. If the adjacent vertex is in the set of points without the shortest path, update the distance from it to the starting point.
1.2 precautions
The Dijkstra algorithm given in the Yan Weimin edition of data structure is described by the graph of adjacency matrix, and the background is that there is no self ring and double edge. It is written in the book that Dijkstra algorithm needs n-1 rounds of relaxation. For the starting point, the book directly initializes the shortest path of the point that the starting point can access. This is not universal. If there are double edges and self rings, you need to pay attention to these two details during initialization and rewrite them additionally. In this way, it is better to incorporate the starting point into the relaxation, a total of N rounds of relaxation to simplify the code logic.
1.3 complexity
The time complexity is O(n2). The main reason is that there are n rounds of relaxation, and the time complexity is O(n). In each round of relaxation, it is necessary to find and update the target point in the set of points that have not found the shortest path. This operation is O(n), and the total complexity is O(n2)
1.4 example of Dijkstra seeking the shortest circuit of single source:
Give a description of a graph and a starting point, and find the shortest path from this starting point to all points( https://www.luogu.com.cn/problem/P3371)
#include <iostream>
#include <vector>
#include <climits>
#include <cmath>
using namespace std;
struct Edge {
int to;
int cost;
Edge(int to, int cost) {
this->to = to;
this->cost = cost;
}
Edge() {}
};
const int INF = INT_MAX;
vector<Edge>ar[10001];
int dis[10001];
bool vis[10001];
int main() {
int n, m, st, x, y, z;
cin >> n >> m >> st;
for(int i = 0; i < m; i ++) {
cin >> x >> y >> z;
ar[x].push_back(Edge(y, z));
}
// init
for(int i = 1; i <= n; i ++)
dis[i] = INF;
dis[st] = 0;
// dijkstra
int target = st, size, minn = INF;
Edge next;
for(int i = 1; i <= n; i ++) {
minn = INF;
for(int j = 1; j <= n; j ++) {
if(!vis[j] && dis[j] < minn) {
minn = dis[j];
target = j;
}
}
vis[target] = true;
size = ar[target].size();
for(int j = 0; j < size; j ++) {
next = ar[target][j];
if(!vis[next.to])
dis[next.to] = min(dis[next.to], dis[target] + next.cost);
}
}
for(int i = 1; i <= n; i ++)
cout << dis[i] << " ";
}
1.5 record path
Add some content on the basis of 1.4. In step 4 of 1.1, the shortest path will be updated. At this time, the precursor of the vertex where the shortest path changes can be recorded. Here, a new data structure Node is used to record the precursor of a vertex.
#include <iostream>
#include <vector>
#include <climits>
#include <cmath>
using namespace std;
struct Edge {
int to;
int cost;
Edge(int to, int cost) {
this->to = to;
this->cost = cost;
}
Edge() {}
};
struct Node {
int to;
int pre;
};
const int INF = INT_MAX;
vector<Edge>ar[10001];
int dis[10001];
bool vis[10001];
Node nodes[10001];
void printRoute(int x, int st) {
if(x == st)
return;
printRoute(nodes[x].pre, st);
cout << nodes[x].pre << "->";
}
int main() {
int n, m, st, x, y, z;
cin >> n >> m >> st;
for(int i = 0; i < m; i ++) {
cin >> x >> y >> z;
ar[x].push_back(Edge(y, z));
}
// init
for(int i = 1; i <= n; i ++)
dis[i] = INF;
dis[st] = 0;
// dijkstra
int target = st, size, minn = INF;
Edge next;
for(int i = 1; i <= n; i ++) {
minn = INF;
for(int j = 1; j <= n; j ++) {
if(!vis[j] && dis[j] < minn) {
minn = dis[j];
target = j;
}
}
vis[target] = true;
size = ar[target].size();
for(int j = 0; j < size; j ++) {
next = ar[target][j];
if(!vis[next.to]) {
if(dis[next.to] > dis[target] + next.cost) {
dis[next.to] = dis[target] + next.cost;
nodes[next.to].pre = target;
}
}
}
}
for(int i = 1; i <= n; i ++) {
cout << dis[i] << endl;
printRoute(i, st);
cout << i << endl;
}
}
2.stl priority queue custom heap
#include <iostream>
#include <queue>
using namespace std;
struct Student {
int grade;
string name;
Student(int grade, string name) {
this->grade = grade;
this->name = name;
}
};
struct Cmp {
bool operator()(const Student &a, const Student &b) {
// Sorting basis of large top heap (same as sort in JavaScript, opposite to sort in c + +)
return a.grade < b.grade;
}
};
priority_queue<Student, vector<Student>, Cmp> q;
int main() {
int n, grade;
string name;
cin >> n;
for(int i = 0; i < n; i ++) {
cin >> name >> grade;
q.push(Student(grade, name));
}
while(!q.empty()) {
Student tmp = q.top();
cout << tmp.name << " " << tmp.grade << endl;
q.pop();
}
}
3. Dijkstra algorithm for heap optimization
3.1 algorithm flow interpretation
1. Initialization:
The shortest path length of the starting point is set to zero, and the shortest path length of other points is set to positive infinity.
2.m wheel slack:
Dijkstra algorithm allows points to be distributed in two different sets according to the rules mentioned in 1. In fact, traversing all the edges in the graph is equivalent to traversing all the points. The shortest path of vertices without adjacent edges is positive infinity, so there is no need to traverse.
3. Each round of relaxation: add all the points in the set of points adjacent to the current vertex that have not found the shortest path to a small top pile
Add all the edges in the set of points that are adjacent to the current vertex without finding the shortest path to a small top heap. A strategy is used here so that we do not need to judge whether a point is in the set of points without finding the shortest path through the vis array. In the relaxation process, we add the adjacent vertices whose shortest path to the source point of all adjacent vertices of the current vertex is greater than the current vertex plus the weight of the edge to the small top heap and reflect it in the code, that is, if (DIS [next. To] > dis [target] + next. Cost). Only the points in the set of points that do not find the shortest path can meet this formula. This operation corresponds to the operation in the Dijkstra algorithm without optimization: after finding the target point, update the shortest path of the adjacent points in the set of points that have not found the shortest path.
4. Sequence of each round of relaxation: small top pile:
In addition to the Edge, we also need another structure Node. In the small top heap, the sorting is based on the shortest path from the vertex to the source point, which is dis[i] in the code. The Node needs to have the number of vertices and the shortest path length from the vertex to the source point. Therefore, each Node in the small top heap stores a Node data structure. In this way, at the beginning of each round of relaxation, the first element of the queue is taken out from the priority queue (we set it to a small top heap structure), which is equivalent to finding the point closest to the source point in the set of points that have not found the shortest path, and the time complexity is O(logn). Corresponding to Dijkstra without optimization, it finds this vertex through the complexity of O(n). This operation corresponds to the operation in the Dijkstra algorithm without optimization: find a point closest to the source point in the set of points that do not find the shortest path.
3.2 precautions
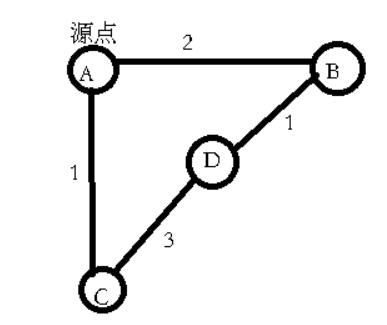
Dijkstra with heap optimization can be further optimized. Every vertex with adjacent edges in the graph will be queued out of the priority queue once to find the shortest path. However, adding vertices to the small top heap is a bfs operation, which is similar to the bfs in spfa algorithm. In this way, there may be a situation that the same vertex may be added to the priority queue many times before it is relaxed. Each time it is added to the priority queue, a heap sorting will be triggered. Finally, the dis value in the Node must be the smallest when the vertex is out of the queue for the first time. When this vertex is out of the team again, the result must not be optimal, but it will take up a relaxation, which will take time. The solution is to maintain a vis array to judge whether the current vertex has been out of the queue. If you are out of line, skip this relaxation process of the vertex. For example, D will join the team twice. When we leave the team, we only relax D who leaves the team for the first time
3.3 complexity
The optimization point of Dijkstra algorithm for heap optimization is to find the point closest to the source point in the set of points that do not find the shortest path with the time complexity of O(logn). The total complexity is O(mlogn) and m is the number of edges.
3.4 examples
Give a description of a graph and a starting point, and find the shortest path from this starting point to all points( https://www.luogu.com.cn/problem/P4779
#include <iostream>
#include <vector>
#include <climits>
#include <queue>
using namespace std;
#define ll long long
struct Edge {
int to;
int cost;
Edge(int to, int cost) {
this->to = to;
this->cost = cost;
}
Edge(){}
};
struct Node {
int to;
int dis;
Node(int to, int dis) {
this->to = to;
this->dis = dis;
}
Node() {}
};
struct Cmp {
bool operator()(Node &a, Node &b) {
// The sorting basis of small root heap is the same as the sort basis in JavaScript and opposite to the sort basis in c + +. Indicates that a and B are exchanged when a.dis is greater than b.dis
return a.dis > b.dis;
}
};
const int INF = INT_MAX;
vector<Edge>ar[100001];
int dis[100001];
bool vis[100001];
priority_queue<Node, vector<Node>, Cmp>q;
int main() {
int n, m, st, x, y, z;
cin >> n >> m >> st;
for(int i = 0; i < m; i ++) {
cin >> x >> y >> z;
ar[x].push_back(Edge(y, z));
}
// init
for(int i = 1; i <= n; i ++)
dis[i] = INF;
dis[st] = 0;
q.push(Node(st, 0));
// dijkstra
while(!q.empty()) {
int target = q.top().to;
q.pop();
if(vis[target])
continue;
vis[target] = true;
int size = ar[target].size();
Edge next;
for(int i = 0; i < size; i ++) {
next = ar[target][i];
if(dis[next.to] > dis[target] + next.cost) {
dis[next.to] = dis[target] + next.cost;
q.push(Node(next.to, dis[next.to]));
}
}
}
for(int i = 1; i <= n; i ++)
cout << dis[i] << " ";
}
3.5 record path
#include <iostream>
#include <vector>
#include <climits>
#include <queue>
using namespace std;
#define ll long long
struct Edge {
int to;
int cost;
Edge(int to, int cost) {
this->to = to;
this->cost = cost;
}
Edge(){}
};
struct Node {
int to;
int dis;
Node(int to, int dis) {
this->to = to;
this->dis = dis;
}
Node() {}
};
struct Node2 {
int to;
int pre;
};
struct Cmp {
bool operator()(Node &a, Node &b) {
return a.dis > b.dis;
}
};
const int INF = INT_MAX;
vector<Edge>ar[100001];
int dis[100001];
bool vis[100001];
priority_queue<Node, vector<Node>, Cmp>q;
Node2 nodes[100001];
void printRoute(int x, int st) {
if(x == st)
return;
printRoute(nodes[x].pre, st);
cout << nodes[x].pre << "->";
}
int main() {
int n, m, st, x, y, z;
cin >> n >> m >> st;
for(int i = 0; i < m; i ++) {
cin >> x >> y >> z;
ar[x].push_back(Edge(y, z));
}
// init
for(int i = 1; i <= n; i ++)
dis[i] = INF;
dis[st] = 0;
q.push(Node(st, 0));
// dijkstra
while(!q.empty()) {
int target = q.top().to;
q.pop();
if(vis[target])
continue;
vis[target] = true;
int size = ar[target].size();
Edge next;
for(int i = 0; i < size; i ++) {
next = ar[target][i];
if(dis[next.to] > dis[target] + next.cost) {
dis[next.to] = dis[target] + next.cost;
nodes[next.to].to = next.to;
nodes[next.to].pre = target;
q.push(Node(next.to, dis[next.to]));
}
}
}
for(int i = 1; i <= n; i ++) {
cout << dis[i] << endl;
printRoute(i, st);
cout << i << endl;
}
}
4.SPFA algorithm
4.1 complexity:
O(nm)
4.2 precautions:
The vertices in the queue must be different. Multiple identical vertices in the queue are not allowed, so there are invalid operations. The same vertex can be queued and updated multiple times.
4.3 example:
Give a description of a graph and a starting point, and find the shortest path from this starting point to all points( https://www.luogu.com.cn/problem/P3371)
#include <iostream>
#include <climits>
#include <vector>
#include <queue>
using namespace std;
const int INF = INT_MAX;
struct Edge {
int to;
int cost;
Edge(int to, int cost) {
this->to = to;
this->cost = cost;
}
};
vector<Edge>ar[10001];
queue<int>q;
int dis[10001];
bool vis[10001];
int main() {
int n, m, st, x, y, z;
cin >> n >> m >> st;
for(int i = 0; i < m; i ++) {
cin >> x >> y >> z;
ar[x].push_back(Edge(y, z));
}
for(int i = 1; i <= n; i ++)
dis[i] = INF;
dis[st] = 0;
vis[st] = true;
q.push(st);
while(!q.empty()) {
int node = q.front();
int size = ar[node].size();
vis[node] = false;
q.pop();
for(int i = 0; i < size; i ++) {
Edge next = ar[node][i];
if(dis[next.to] > dis[node] + next.cost) {
dis[next.to] = dis[node] + next.cost;
if(!vis[next.to]) {
vis[next.to] = true;
q.push(next.to);
}
}
}
}
for(int i = 1; i <= n; i ++)
cout << dis[i] << " ";
}
4.4 record path
#include <iostream>
#include <climits>
#include <vector>
#include <queue>
using namespace std;
const int INF = INT_MAX;
struct Edge {
int to;
int cost;
Edge(int to, int cost) {
this->to = to;
this->cost = cost;
}
};
struct Node {
int to;
int pre;
};
vector<Edge>ar[10001];
queue<int>q;
int dis[10001];
Node nodes[10001];
bool vis[10001];
void printRoute(int x, int st) {
if(x == st)
return;
printRoute(nodes[x].pre, st);
cout << nodes[x].pre << "->";
}
int main() {
int n, m, st, x, y, z;
cin >> n >> m >> st;
for(int i = 0; i < m; i ++) {
cin >> x >> y >> z;
ar[x].push_back(Edge(y, z));
}
for(int i = 1; i <= n; i ++)
dis[i] = INF;
dis[st] = 0;
vis[st] = true;
q.push(st);
while(!q.empty()) {
int node = q.front();
int size = ar[node].size();
vis[node] = false;
q.pop();
for(int i = 0; i < size; i ++) {
Edge next = ar[node][i];
if(dis[next.to] > dis[node] + next.cost) {
dis[next.to] = dis[node] + next.cost;
if(!vis[next.to]) {
vis[next.to] = true;
nodes[next.to].pre = node;
q.push(next.to);
}
}
}
}
for(int i = 1; i <= n; i ++) {
cout << dis[i] << endl;
printRoute(i, st);
cout << i << endl;
}
}
4.4 negative loop judgment
https://www.luogu.com.cn/problem/P3385
A negative loop indicates that there is a loop starting from a certain point and returning to that point, and the total weight is negative.
The judgment of negative ring can be judged according to the number of vertices in the queue. If the number of vertices in the queue is greater than or equal to n times, there is a negative ring.
Note: SPFA before 4.4 did not deal with the code of negative ring, so it can't stop once it encounters negative ring.
#include <iostream>
#include <vector>
#include <queue>
#include <climits>
using namespace std;
struct Edge {
int to;
int cost;
Edge(int to, int cost) {
this->to = to;
this->cost = cost;
}
Edge() {}
};
vector<Edge>ar[2001];
queue<int>q;
int cnt[2001], dis[2001];
bool vis[2001];
int main() {
int T, n, m, u, v, w;
bool exist = false;
cin >> T;
for(int i = 0; i < T; i ++) {
cin >> n >> m;
for(int k = 0; k < 2001; k ++) {
cnt[k] = 0;
dis[k] = INT_MAX;
ar[k].clear();
vis[k] = false;
}
q = queue<int>();
exist = false;
for(int j = 0; j < m; j ++) {
cin >> u >> v >> w;
if(w >= 0)
ar[u].push_back(Edge(v, w)), ar[v].push_back(Edge(u, w));
else
ar[u].push_back(Edge(v, w));
}
q.push(1);
dis[1] = 0;
vis[1] = true;
cnt[1] ++;
while(!q.empty()) {
int now = q.front();
q.pop();
vis[now] = false;
if(cnt[now] >= n) {
cout << "YES" << endl;
exist = true;
break;
}
int size = ar[now].size();
for(int j = 0; j < size; j ++) {
Edge next = ar[now][j];
if(dis[next.to] > dis[now] + next.cost) {
dis[next.to] = dis[now] + next.cost;
if(!vis[next.to]) {
vis[next.to] = true;
q.push(next.to);
cnt[next.to] ++;
}
}
}
}
if(!exist)
cout << "NO" << endl;
}
}
5.Floyd algorithm
5.1 precautions:
The first layer circularly enumerates the middle point k. When comparing the size of the current path and the path passing through the middle point, be careful not to cross the boundary. The following code makes a special judgment on the situation of crossing the upper boundary of int.
5.2 example:
Give a description of a graph and a starting point, and find the shortest path from this starting point to all points( https://www.luogu.com.cn/problem/P3371)
70 points
#include <iostream>
#include <climits>
#include <cmath>
using namespace std;
const int INF = INT_MAX;
int ar[1001][1001];
int main() {
int n, m, st, u, v, w;
cin >> n >> m >> st;
for(int i = 1; i <= n; i ++)
for(int j = 1; j <= n; j ++)
if(i == j)
ar[i][j] = 0;
else
ar[i][j] = INF;
for(int i = 0; i < m; i ++) {
cin >> u >> v >> w;
ar[u][v] = min(ar[u][v], w);
}
for(int k = 1; k <= n; k ++)
for(int i = 1; i <= n; i ++)
for(int j = 1; j <=n ;j ++) {
if(ar[i][k] == INF || ar[k][j] == INF)
continue;
ar[i][j] = min(ar[i][j], ar[i][k] + ar[k][j]);
}
for(int i = 1; i <= n; i ++)
cout << ar[st][i] << " ";
}