Hello, I'm Chen Cheng.
Talking about Pandas's read XXX series of functions, your first reaction will think of the more commonly used PD read_ CSV () and PD read_ Excel (), most people probably haven't used PD read_ HTML () this function. Although it is low-key, it is very powerful. It is an artifact when used to grab Table data.
Yes, this artifact can be used for reptiles!
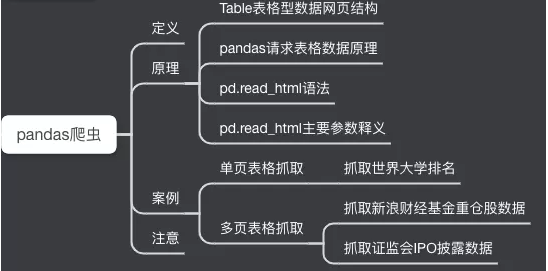
01 definition
pd.read_html() is a powerful function. You don't need to master tools such as regular expressions or xpath. You can easily grab Table web page data in just a few lines of code.
02 principle
I Table table data web page structure
To understand the structure of a Table web page, let's take a simple example.
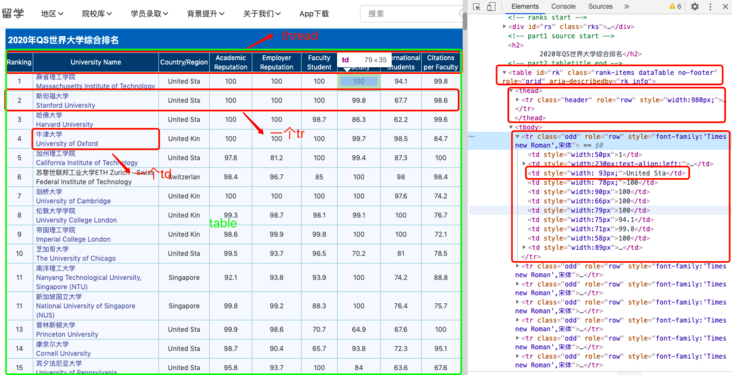
Yes, simple!
Another example:

Sina Finance and Economics
Rule: the Table data displayed in Table structure, and the web page structure is as follows:
<table class="..." id="...">
<thead>
<tr>
<th>...</th>
</tr>
</thead>
<tbody>
<tr>
<td>...</td>
</tr>
<tr>...</tr>
<tr>...</tr>
...
<tr>...</tr>
<tr>...</tr>
</tbody>
</table>
II pandas request table data principle

Basic process
Actually, PD read_ HTML can capture the table data on the web page and return it in a list in the form of DataFrame.
III pd.read_html syntax and parameters
Basic syntax:
pandas.read_html(io, match='.+', flavor=None, header=None,index_col=None,skiprows=None, attrs=None, parse_dates=False, thousands=', ', encoding=None, decimal='.', converters=None, na_values=None, keep_default_na=True, displayed_only=True)
Main parameters:
io : Receive web address, file and string;
parse_dates: Resolution date;
flavor: Parser;
header: Title line;
skiprows: Skipped lines;
attrs: Properties, such as attrs = {'id': 'table'}
Actual combat
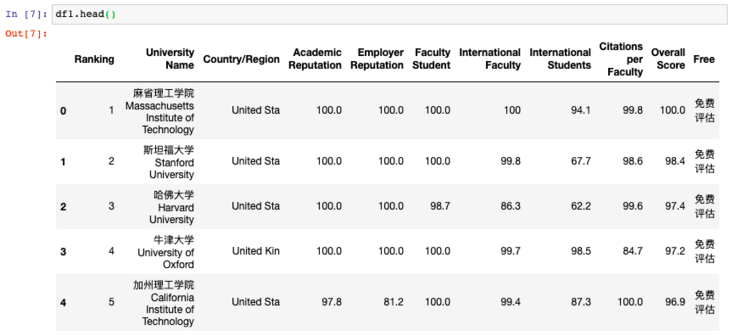
I Case 1: capturing the world university rankings (1 page of data)
1import pandas as pd
2import csv
3url1 = 'http://www.compassedu.hk/qs'
4df1 = pd.read_html(url1)[0] #0 represents the first Table in the web page
5df1.to_csv('Comprehensive ranking of World Universities.csv',index=0)5 lines of code, just a few seconds, data preview:
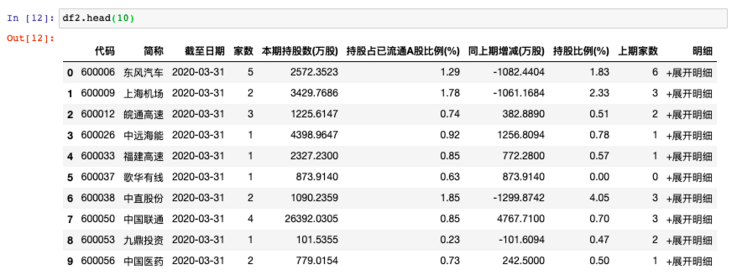
II Case 2: capture the data of heavy positions of Sina Financial Fund (6 pages of data)
1import pandas as pd
2import csv
3df2 = pd.DataFrame()
4for i in range(6):
5 url2 = 'http://vip.stock.finance.sina.com.cn/q/go.php/vComStockHold/kind/jjzc/index.phtml?p={page}'.format(page=i+1)
6 df2 = pd.concat([df2,pd.read_html(url2)[0]])
7 print('The first{page}Page grab complete'.format(page = i + 1))
8df2.to_csv('./Sina Financial Data.csv',encoding='utf-8',index=0)8 lines of code, it's still that simple.
Let's preview the data crawled down:
III Case 3: capture the IPO data disclosed by the CSRC (217 pages of data)
1import pandas as pd
2from pandas import DataFrame
3import csv
4import time
5start = time.time() #time
6df3 = DataFrame(data=None,columns=['corporate name','Disclosure date','Listing places and sectors','Disclosure type','see PDF data']) #Add column name
7for i in range(1,218):
8 url3 ='http://eid.csrc.gov.cn/ipo/infoDisplay.action?pageNo=%s&temp=&temp1=&blockType=byTime'%str(i)
9 df3_1 = pd.read_html(url3,encoding='utf-8')[2] #utf-8 must be added, otherwise the code is garbled
10 df3_2 = df3_1.iloc[1:len(df3_1)-1,0:-1] #Filter out the last row and last column (NaN column)
11 df3_2.columns=['corporate name','Disclosure date','Listing places and sectors','Disclosure type','see PDF data'] #New df add column name
12 df3 = pd.concat([df3,df3_2]) #Data merging
13 print('The first{page}Page grab complete'.format(page=i))
14df3.to_csv('./listed company IPO information.csv', encoding='utf-8',index=0) #Save data to csv file
15end = time.time()
16print ('Co grab',len(df3),'Company,' + 'Time use',round((end-start)/60,2),'minute')
Here, pay attention to filtering the captured Table data, mainly using iloc method. In addition, I also added a program timing to check the crawling speed.
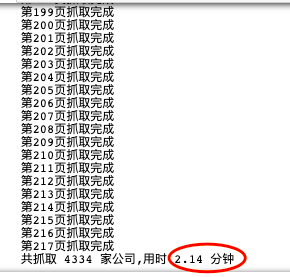
2 minutes to climb down 217 pages of 4334 data, quite nice. Let's preview the data crawled down:
IPO data of listed companies: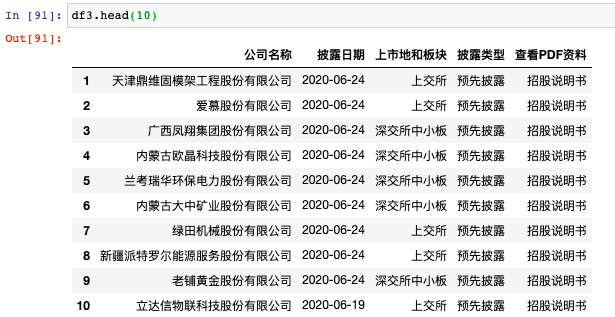
Note that not all tables can use PD read_html crawling, some websites look like tables on the surface, but in the web page source code, it is not in table format, but in list format. This form does not apply to read_html crawling, you have to use other methods, such as selenium.