Idea: operate with subscript value
Firstly, the mask of the candidate target in the original image is extracted
Here are some points to note:
- We operate by subscript, so we don't need to get the pixel value of the original image. Only the subscript of the corresponding pixel value of the original image can be obtained
- When getting the subscript, you need to judge whether it exceeds the boundary.
gt_box_i = batched_inputs[select_image]['instances'].gt_boxes.tensor[i] # This is the converted box and coco data set. The original format may be x,y,w,h
ori_mask = torch.zeros_like(batched_inputs[select_image]['image'][0,:,:]) # Get the 0 matrix with the same definition
mask_h, mask_w = ori_mask.shape
ori_mask[max(0, int(gt_box_i[0])): min(mask_w, int(gt_box_i[2])),
max(0, int(gt_box_i[1])): min(mask_h, int(gt_box_i[3]))] = 1 # Set the mask value of the selected bbox to one
idx_all = torch.nonzero(ori_mask == 1, as_tuple=True) # Get the position with subscript 1 (x, y)
In the above operation, we get the location with subscript 1 and save it in idx_all. Note that in ori_ In the mask, we judge the corresponding boundary to prevent crossing the boundary.
Paste the result on the image to be converted
This step is very simple. Just use the subscript value to copy. Combined with the following description.
Complete code
images = [x["image"].to(self.device) for x in batched_inputs]
images = [(x - self.pixel_mean) / self.pixel_std for x in images]
images = ImageList.from_tensors(images,
self.backbone.size_divisibility)
if not self.training:
return images
select_image = random.randint(0, 0xfffffff) % len(batched_inputs)
select_Num = random.randint(0, 0xfffffff)
for i in range(len(batched_inputs[select_image]['instances'].gt_boxes.tensor)):
if i << 1 & select_Num:
# Put this goal on top of other pictures
gt_box_i = batched_inputs[select_image]['instances'].gt_boxes.tensor[i] # This is the box that has been converted
ori_mask = torch.zeros_like(batched_inputs[select_image]['image'][0,:,:]) # Get the 0 matrix with the same definition
mask_h, mask_w = ori_mask.shape
ori_mask[max(0, int(gt_box_i[0])): min(mask_w, int(gt_box_i[2])),
max(0, int(gt_box_i[1])): min(mask_h, int(gt_box_i[3]))] = 1 # Set the mask value of the selected bbox to one
idx_all = torch.nonzero(ori_mask == 1, as_tuple=True) # Get the position with subscript 1 (x, y)
label_rgb = images.tensor[select_image]
label_id = batched_inputs[select_image]['instances'].gt_classes[i]
for img_idx in range(len(batched_inputs)):
if img_idx == select_image:
continue
rand_num = random.randint(0, 0xffffffff)
h, w = images.tensor[img_idx, ...].shape[-2:]
trans_x = idx_all[0] + rand_num % w # (x0, x1)
trans_y = idx_all[1] + rand_num % h # (y0, y1)
trans_x, trans_y = trans_x[trans_x >= 0], trans_y[trans_x >= 0]
trans_x, trans_y = trans_x[trans_x < w], trans_y[trans_x < w]
trans_x, trans_y = trans_x[trans_y >= 0], trans_y[trans_y >= 0]
trans_x, trans_y = trans_x[trans_y < h], trans_y[trans_y < h]
if trans_x.shape[0]> 10:
images.tensor[img_idx][:, trans_y, trans_x] = label_rgb[:, trans_y - rand_num % h, trans_x - rand_num % w]
gt_box_i = torch.Tensor([gt_box_i[0] + rand_num % w, gt_box_i[1] + rand_num % h,
gt_box_i[2] + rand_num % w, gt_box_i[3] + rand_num % h])
ious = box_iou(batched_inputs[img_idx]['instances'].gt_boxes.tensor, gt_box_i.unsqueeze(0))
batched_inputs[img_idx]['instances'].gt_boxes.tensor = batched_inputs[img_idx]['instances'].gt_boxes.tensor[(ious < 0.9).squeeze(1)]
batched_inputs[img_idx]['instances'].gt_classes = batched_inputs[img_idx]['instances'].gt_classes[
(ious < 0.9).squeeze(1)]
batched_inputs[img_idx]['instances'].gt_boxes.tensor = torch.cat((batched_inputs[img_idx]['instances'].gt_boxes.tensor, gt_box_i.unsqueeze(0)))
batched_inputs[img_idx]['instances'].gt_classes = torch.cat((batched_inputs[img_idx]['instances'].gt_classes, label_id.unsqueeze(0)))
return images
There are several points to explain about this Code:
- The input is subtracted from the mean divided by the variance
- If you do not perform the following operations during training (i.e. verification), you can return directly.
Process Description:
- First, we randomly select a photo from the input batch. Select is obtained by generating a random number and taking the remainder of batchsize_ image.
- Then we randomly select a subset from the label of the picture and paste it on other pictures. Judge whether it is selected by generating random number and I < < 1.
- After obtaining the subscript value of label in the original figure, the random number rand_num gets the offset of other images.
- Finally, judge whether the obtained subscript is out of bounds.
- Finally, judge whether the iou is greater than the set threshold (0.9) to update the label of the corresponding picture
Disadvantages:
- Since the author is engaged in target detection, he may be familiar with the evaluation indicators of target detection. In fact, it is better to use the label of segmentation when obtaining the corresponding subscript of the original label. It can prevent a large amount of background information from being imported.
Insert picture description here
 Figure 1 original picture Figure 1 original picture
|
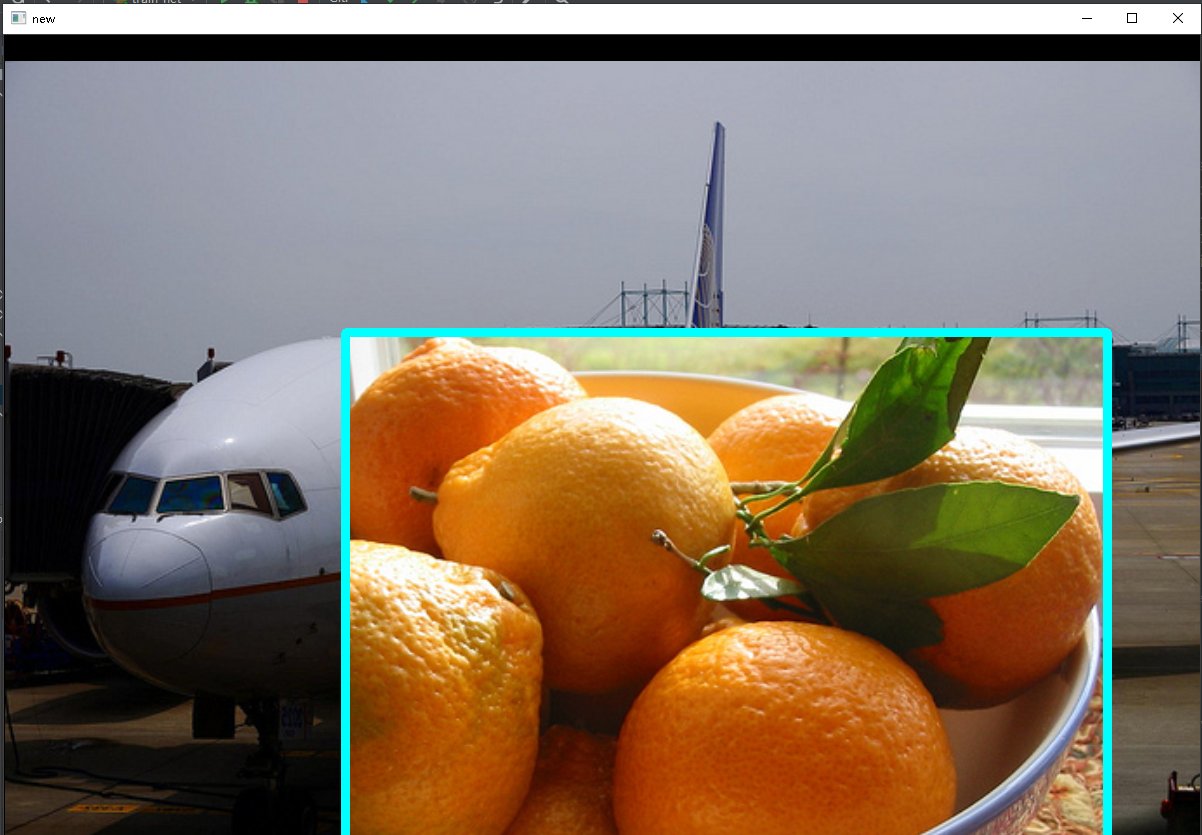 Figure 2 Map Figure 2 Map
|
It can be seen that the background information is also extracted during the conversion. Therefore, it is better to use segmentation as the subscript of label. (here I shield the first step of subtracting the mean divided by the variance)