Relevant knowledge points
- What is AST abstract syntax tree
- Compilation process of program
- Use of AST
- Babel's principle
- Examples and thoughts of burying points based on babel in personal implementation

What is AST abstract syntax tree
Compilation process of program
What is program compilation? As we all know, in the traditional compilation language process, a piece of code in the program will go through three steps before it is executed. The execution process of this step is the compilation process of the program.
- Word segmentation (lexical analysis)
The process of lexical analysis is the first step. The code we write is essentially a string of strings, and the process of lexical analysis will decompose these strings composed of characters into meaningful code blocks. For example:
let a = 1 // let a = 1 Copy code
In this program, let, a, =, 1 and will be split. Whether some special placeholders (such as spaces) need to be split depends on whether the placeholder has practical significance.
- Parsing (parsing)
The process of syntax analysis is to combine the results of lexical analysis according to certain rules, associate the hashed code blocks and form a tree representing the program syntax structure, also known as abstract syntax tree (AST). The reason why the syntax of each node in the tree represents the abstract structure of the source code is transformed into an abstract structure of the source code. It is said that the syntax of js tree represents the abstract structure of the source code. This data structure is actually a large json object, which we are all familiar with. It is like a tree with luxuriant branches and leaves. There are roots, trunks, branches and leaves. No matter how small or large, it is a complete tree. The simple understanding is to convert the code we write into a tree structure according to certain rules, such as:
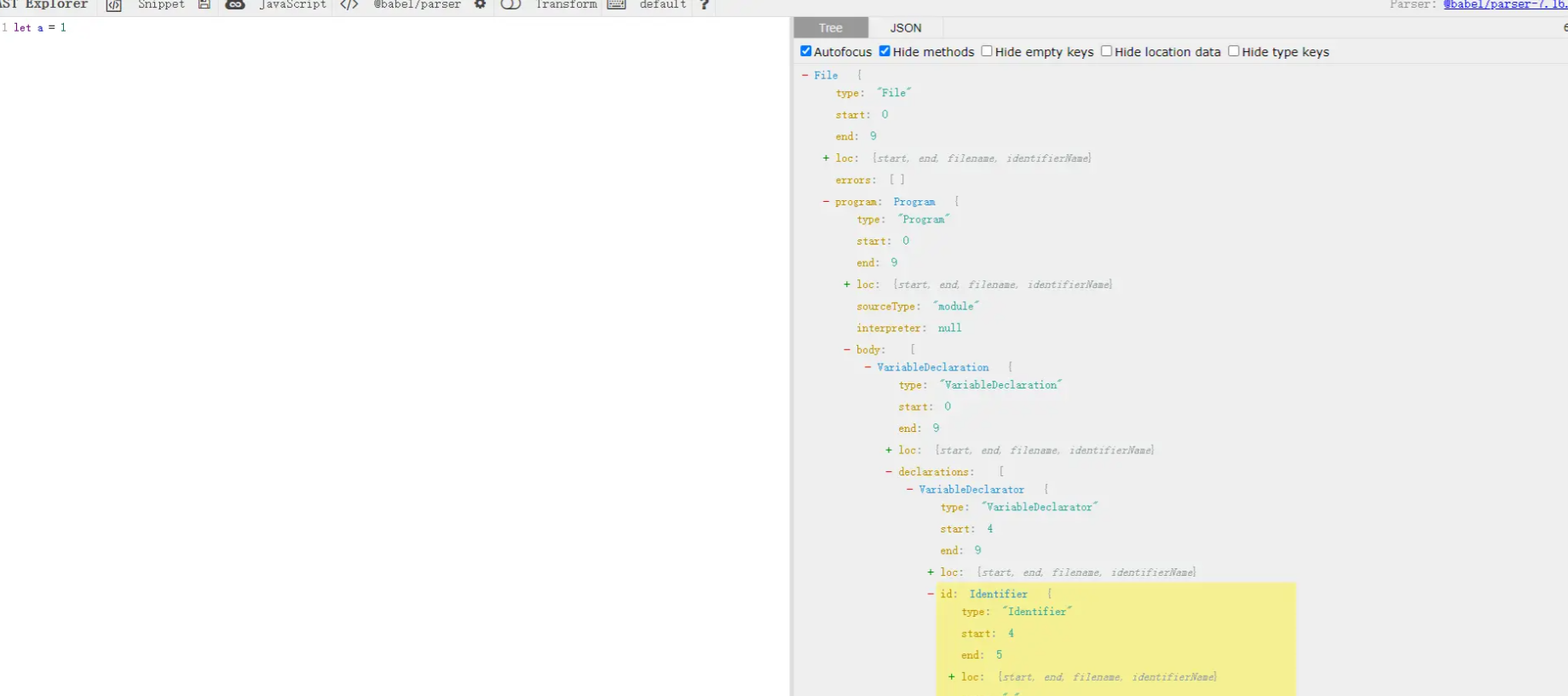
The specific ast content can also be passed here Input and view by yourself. In addition, for this tool, there are places to select the language and disassemble the tool. You can also choose the corresponding environment according to your own language
- code generation
Code generation is also the last section of the compilation process. It will convert the AST abstract syntax tree in the syntax analysis stage into executable code, and then exchange US. As for what kind of code to generate, it can also be decided by ourselves. In theory, it can comply with the rules of the language.
Use of AST
After knowing what is ast, we must have some answers about the uses of AST. AST is not only used to compile JavaScript engine, but also often used in the actual development process. For example, our commonly used babel plug-in converts ES6 to ES5, uses UglifyJS to compress code, css preprocessor, develops WebPack plug-in, Vue cli front-end automation tool, etc. these underlying principles are based on ast, AST is very powerful and can help developers understand the essence of JavaScript. With these, we can accurately control the runtime and compile time processing of the code.
For example, big silly stumbled upon Vue3.0 while visiting GIthub Issue of X. The specific situation is that when using vue3 When I was 0, I suddenly found that if I use jsx writing method, some, such as v-once, are not supported. What should I do if they are not supported? Baidu and Google searched it and came to issue before they understood it. Here's an idea. Because it's jsx syntax, we're not going to Vue's issue. It must be a conversion tool. Here we use babel-plugin-jsx , and the following issue s are found
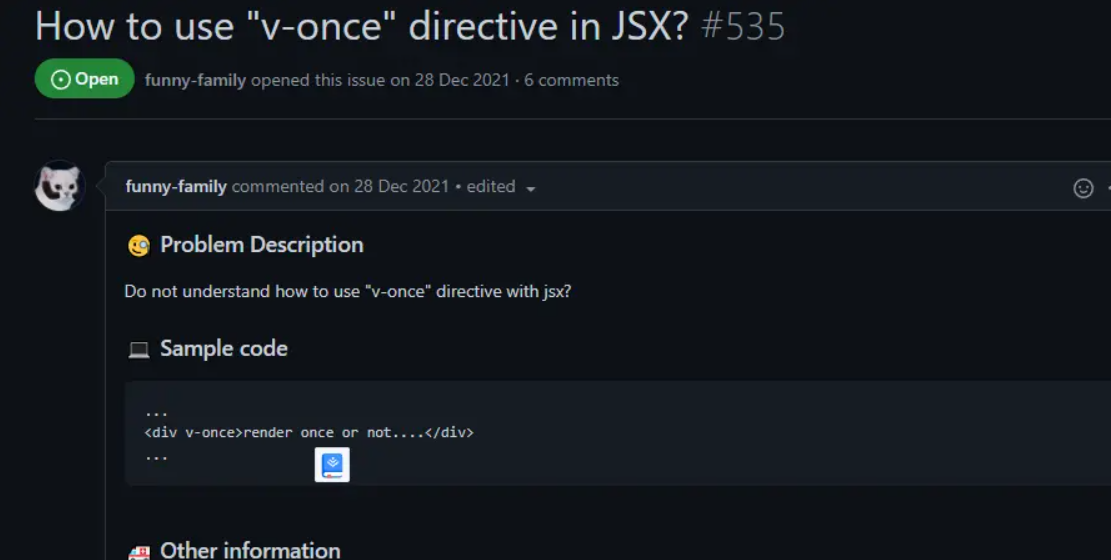
After a fierce debate, the fool lost. He calmed down and found these two points in the code compilation( 1,2 )Some instructions such as v-once are not processed accordingly.
This small example also illustrates the role of AST. For example, after some errors are reported, we suspect that it is an error of a library or framework. In fact, it may also be due to inconsistent rules or no exposed errors in the compilation stage. If we can accurately analyze the cause of the error, my mother won't have to worry about me mentioning the issue any more.

Babel's principle
With the rise of front-end engineering, we are exposed to more language tools. babel is a unique tool here.
Our common understanding of babel is that it can help us deal with compatibility, that is, some new features of JavaScript that we may want to use, but it is not supported by some browsers. At this time, we can downgrade our code to a browser compatible executive version through babel, so as to achieve two sets of code in the development and production environment, Convenient development of one-time operation.
- Babel plug-in acts on the abstract syntax tree
- Babel's three main processing steps are parse, transform and generate.
- analysis
Parsing is equivalent to the combined version of lexical analysis and syntax analysis in our compilation process. The code is parsed into an abstract syntax tree (AST). Each js engine (such as V8 engine in Chrome browser) has its own ast parser, and Babel is implemented through Babylon. The parsing process has two stages: lexical analysis and syntax analysis. In the lexical analysis stage, the code in the form of string is transformed into a token stream, which is similar to the node in AST; The syntax analysis stage will convert a token stream into the form of AST, and this stage will convert the information in the token into the expression structure of AST.
- transformation
Generally speaking, the step of transformation is the processing step leaked to us. At this stage, nodes will be added, updated and removed. traverse performs depth first traversal, maintains the overall state of the AST tree, and can replace, delete or add nodes. The returned result is our processed AST.
- generate
The generation stage is to convert the final AST of our second stage into our string code, and create a code map, that is, source map. Code generation is to deeply traverse the whole AST, and then convert it into a string that can represent the converted code through generate.
Examples and thoughts of burying points based on babel in personal implementation
When embedding points, we usually pass in the specified parameters in the form of functions to realize the embedding points. If we give some special marks to the places where the embedding points are needed in the development process (I use console. Log here), can we deal with these embedding points in batches through tools before the execution of our code, so as to realize the unified embedding points The whole process suggests that you refer to the previous ast generator website to read and write at the same time
The first is Tucker JS, this file is mainly used to process the AST generated by our source code, mainly in two aspects
- Import our buried point function in this module
- Traverse and find our identification area for replacement
const { declare } = require('@babel/helper-plugin-utils');
const importModule = require('@babel/helper-module-imports');
const {default: template} = require("@babel/template");
const autoTrackPlugin = declare((api, options, dirname) => {
api.assertVersion(7); // Indicates version 7
return {
visitor: {
Program: {
enter (path, state) {
path.traverse({
ImportDeclaration (curPath) {
const requirePath = curPath.get('source').node.value;
if (requirePath === options.trackerPath) {
const specifierPath = curPath.get('specifiers.0');
if (specifierPath.isImportSpecifier()) {
state.trackerImportId = specifierPath.toString();
} else if(specifierPath.isImportNamespaceSpecifier()) {
state.trackerImportId = specifierPath.get('local').toString();
}
path.stop();
}
}
});
if (!state.trackerImportId) {
state.trackerImportId = importModule.addDefault(path, 'tracker',{
nameHint: path.scope.generateUid('tracker')
}).name;
}
}
},
'ClassMethod|ArrowFunctionExpression|FunctionExpression|FunctionDeclaration'(path, state) //For this knowledge, you can see more official documents. This is to find AST nodes that conform to the function{
const targetCalleeName = ['log', 'info', 'error', 'debug'].map(item => `console.${item}`);
// TODO find child node
const bodyPath = path.get('body');
if (bodyPath.isBlockStatement()) {// Find the scope at the block level first
const bodyPath2 = bodyPath.get('body.0') // What we are looking for is the first block level body content
console.log(bodyPath.get('body').type)
if(bodyPath2.isExpressionStatement()){// This is the ast statement corresponding to the console
const calleeName = bodyPath2.get('expression').get('callee').toString()//
const bodyPath3 = bodyPath2.get('expression')
if (targetCalleeName.includes(calleeName)) {
let arg = []
bodyPath3.node.arguments.forEach((item,index,array)=>{
if(array[0].value==='tracker'){
// If the first value of our console is tracker, it means that it is a buried point, otherwise it is an ordinary console log
if(index>0){
let ret = item.value || item.name
arg.push(ret)
}
}
})
if(arg.length>0){
state.trackerAST = template.expression(`${state.trackerImportId}(${arg.join(',')})`)();
bodyPath3.remove()// Remove the original console code
bodyPath.node.body.unshift(state.trackerAST);// Insert the latest code of our own
}
}
}
}
}
}
}
});
module.exports = autoTrackPlugin;
Copy codeThen there's our starttracker JS, this file is our entry function. When we test locally, we can use node starttracker JS instruction to run this code. Its main function is to convert it into AST and give it to our tracker function to process ast, get the processed AST and generate new code
const { transformFromAstSync } = require('@babel/core');
const parser = require('@babel/parser');
const autoTrackPlugin = require('./tracker');
const fs = require('fs');
const path = require('path');
const sourceCode = fs.readFileSync(path.join(__dirname, './code.js'), {
encoding: 'utf-8'
});
const ast = parser.parse(sourceCode, {
sourceType: 'unambiguous'
});
const { code } = transformFromAstSync(ast, sourceCode, {
plugins: [[autoTrackPlugin, {
trackerPath: 'tracker'
}]]
//
/*
* Call function conversion
* 1 Incoming ast content
* 2 The incoming map ast error problem is mapped to the map file
* 3 One object is configuration related
* 1 The incoming plugins is an array. The array is different plug-ins and can also be identified by an array
* Array of plug-ins
* The first is the plug-in
* The second is to put the configuration provided by the plug-in and the constants that can be customized into the received options
* */
});
console.log(code);
Copy codeFinally, the Code code for our test (at present, only one block level scope has been simulated, and multiple block level scopes have not been written. You can watch the AST improve itself)
const obj={
a:111
}
function a () {
console.log(obj);
}
class B {
bb() {
console.log('tracker',232)
return 'bbb';
}
}
const c = () => 'ccc';
const d = function () {
console.log('tracker','1818',11);
}
Copy code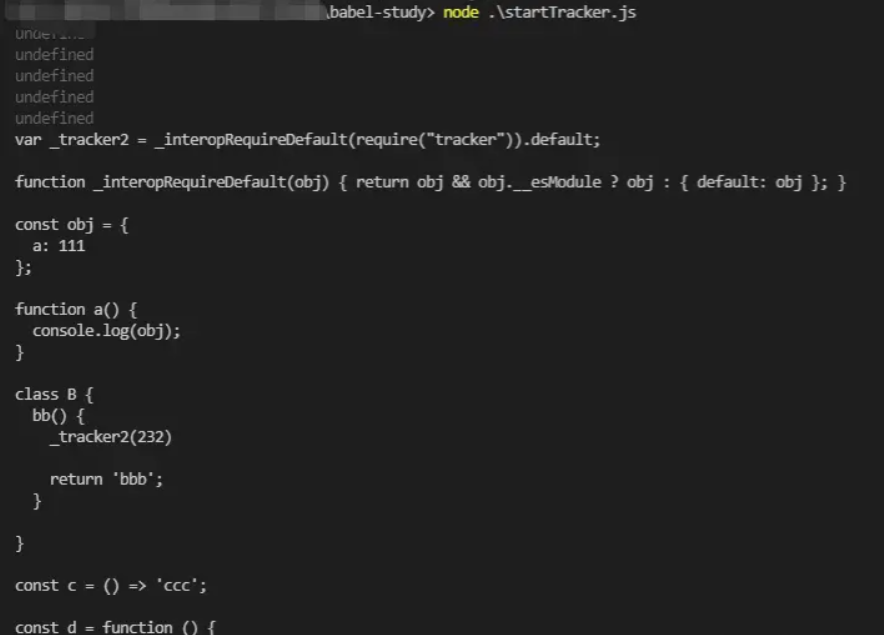
Finally, by running, we can see the output results and the comparison results with the source code how? Does it feel interesting I hope you have a preliminary understanding after reading the article, and you can also find some materials to consolidate and learn And make some of your own gadgets to increase your impression. Finally, I wish you all the best in your work and life in the New Year!!!
last
If you think this article is a little helpful to you, give it a compliment. Or you can join my development exchange group: 1025263163 learn from each other, and we will have professional technical Q & A to solve doubts
If you think this article is useful to you, please click star: http://github.crmeb.net/u/defu Thank you very much!
PHP learning manual: https://doc.crmeb.com
Technical exchange forum: https://q.crmeb.com