Introduction and optimization process of simple second kill system
windows native hardware configuration:
- 8-core 32G

linux server hardware configuration:
- 2-core 4G
Foreword, the optimized simple second kill system does not involve distribution, so naturally there are no technical points such as master-slave replication. Here, we should all have our own second kill interface demo. We start to optimize according to our ability around this demo.
- QPS (Query Per Second): query rate per second, the number of times a server can Query Per Second, is a measure of the ability of a specific query server to process traffic within a specified time. Generally speaking, it is how many requests the server processes in a second.
- TPS (Transactions Per Second): the number of transactions processed per second. A transaction here refers to the process in which a client sends a request to the server and the server responds * * (complete processing, that is, the client initiates the request and gets the response) * *. The client starts timing when sending the request and ends timing after receiving the server response, so as to calculate the time used and the number of completed transactions, and finally make the evaluation score using this information. A transaction may correspond to multiple requests. You can refer to the transaction operation of the database.
First pressure test of seckill interface:
/usr/local/jmeter/apache-jmeter-5.3/bin/jmeter -n -t /usr/local/jmeter/jmx/first-kill-test.jmx -l result.jtl ./jmeter.sh -n -t first-kill-test.jmx -l result.jtl
Condition: 1000 threads, 10 cycles, 10000 accesses in total.
-
Windows:
- QPS: 984.5|4384
- Database error, oversold problem.
-
Linux:
- QPS: 526.4
- Database error, oversold problem.

Problems in the second kill interface of pressure measurement
- Database oversold = =.
- Order confusion.
- QPS is not high and cannot withstand greater concurrency.
Analyze the reason
- The difference between the two systems is that windows is generally slower, but my computer configuration is relatively high, so it will be faster than linux.
- There are operations on data and direct access to the database without using cache.
- No lock, resulting in data confusion.
Request code after optimization
The following code block is our optimized second kill request code block. Next, we will explain each optimization step one by one.
@ApiOperation(value = "Make a second kill request" )
@PostMapping("/private/do")
public Response doSecondKill(@ApiParam(value = "commodity vo", required = true) @RequestBody SeckillGoodsDetailVo goods) {
/** Get the information of the current login user**/
Long userId = UserThreadLocalUtil.get();
/** First judge whether to repeat purchase**/
Boolean isRepeat = seckillOrderService.checkCurrentUserOrder(userId, goods.getId());
if (isRepeat) {
return Response.setResponse(StatusCode.REPEAT_ORDER);
}
/** Check inventory and pre reduction inventory**/
Boolean hasStock = seckillGoodsService.checkStockAndDecrement(goods.getId());
if (!hasStock) {
return Response.error().message("The second kill is over!");
}
/** Second kill successful, order**/
Order order = seckillOrderService.secondKill(userId, goods);
Map<String, Object> data = new HashMap<>();
data.put("goods", goods);
data.put("order", order);
return Response.success().message("Second kill success").data(data);
}
Optimization 1: page resource optimization method
Since the current page rendering requires the establishment of a connection from the database, the efficiency is certainly not as fast as that of memory. Moreover, the current bottleneck is the performance bottleneck of the database. We can first store some data that is not very changeable, or insensitive, or data that does not require so high consistency of data into the cache according to the required granularity, After that, the page request accesses the cache first, which will be much faster. What should I do? Then it is a simple redis application. Select the required redis data type and put it into redis. I won't elaborate here.
Optimization 2: solve the oversold problem (key)
In the code, we can clearly find the core code block about oversold:
/** Determine whether to repeat purchase**/
Boolean aBoolean = seckillOrderService.checkCurrentUserOrder(userId);
if (aBoolean) {
return Response.setResponse(StatusCode.REPEAT_ORDER);
}
/** The corresponding goods in the current inventory are killed by the stopwatch, and then the corresponding goods are killed by the stopwatch**/
LambdaQueryWrapper<SeckillGoods> wrapper = new LambdaQueryWrapper<>();
wrapper.eq(SeckillGoods::getGoodsId, goods.getId());
SeckillGoods currentSeckillGoods = seckillGoodsService.getOne(wrapper);
currentSeckillGoods.setStockCount(currentSeckillGoods.getStockCount() - 1);
seckillGoodsService.updateById(currentSeckillGoods);
The change of inventory is based on the code blocks in the above two different methods. Then, we have learned some basic knowledge of MySQL database in relational database, right? We can first consider the solution at the database level.
Thinking process
Can I use atomic classes? I personally think it can be used, but it involves cas, so if there are many parallel cases in the case of concurrency, there will be more spin of cas operation at the same time, and the cpu occupancy rate will be very high, which is not very friendly to some machines with poor hardware, so I first thought of solving it at the database level.
In the previous study, I wrote a registration function. The registration function can be passed in as an account through three different data types: email, mobile phone number and user name. However, these three things basically correspond to different people in today's society, that is, they are one-to-one relationships, so naturally there can be no duplication, but if I deal with them in the code logic, It would involve multiple queries to the database, which inadvertently increased the pressure on the database, but I didn't have a better way at that time, so I thought of the unique index. This thing does not allow duplicate field contents, so I tried to establish a unique index for these fields, and then I tested again and found that if the existing data, Under the constraint of unique index, it cannot be inserted. It is similar to an optimistic lock. I think I can insert it successfully.
Therefore, at this point, we can try to establish a unique index for the commodity id and the corresponding user id in the order. Sure enough, after the test, we can successfully control the inventory. However, this is still a direct operation on the database, which will inevitably be unable to withstand a large number of accesses. It is high open and low go, and the problem of unequal number of orders and inventory has not been solved, This method will still be repeatedly modified.
After learning the basics of redis, we can learn that the incr of redis is atomic and self increasing. We may be able to get the inventory of spike goods into redis. We should consider that if the user spike once, and if the cache fails again, it will repeat, so the default spike time must be less than the cache survival time.
With the condition that the default second kill time must be less than the cache lifetime, we can start the operation. First, when we think of incr, we think of directly increasing or decreasing inventory in redis, but the following two problems arise:
- How can we make the inventory of spike goods enter redis in advance?
- How to ensure the final consistency of data between cache and database?
- How to ensure that orders are not repeated? And not oversold?
Once the problem is solved
Let's solve it slowly. First, design a solution to the first problem:
- My first thought is to initialize redis directly before the project starts, but I don't have to update the cache data. It's easy to use scheduled tasks, but it generally involves multithreading. In this case, our server has insufficient hardware, but it still uses multithreading, or it costs a lot to maintain a thread pool for a long time, so I personally deny this method for the time being.
- The second method I think of is simple and crude. Write an interface that directly updates the cache, but we also have to synchronize regularly and maintain a thread pool.
But on second thought, we are now focusing on optimization. As for the above situation, we don't go deep into it. Let's use an interface to directly update the cache, and then think about the problem of delayed double deletion:
- Solve the code block of inventory entering Redis:
@ApiOperation(value = "Make an inventory cache update request for second kill goods" )
@PostMapping("/public/update/cache")
public Response updateCache() {
IPage<SeckillGoodsDetailVo> list = seckillGoodsService.list(new Page<>(0, -1));
List<SeckillGoodsDetailVo> records = list.getRecords();
records.stream().forEach((record) -> {
/** Set the second kill commodity cache. Generally, the cache existence time should be greater than the total second kill time**/
redisTemplate.opsForValue().set( "SECONDKILL::PRODUCT:" + record.getId() + "-STOCK::COUNT:", record.getStockCount(), 1, TimeUnit.DAYS);
});
return Response.success().message("Seckill inventory cache updated successfully");
}
Problem 2 solved
How to solve the data consistency between cache and database?
- First of all, the number of threads that can be accommodated by the built-in tomcat of the SpringBoot project is not large. In a high concurrency environment, it may run out. At this time, all subsequent requests have to wait for the previous request to be processed after it is completed, and the previous request may involve database operation, so the concurrency of mysql database is not high, Therefore, blocking is likely to occur in a high concurrency environment.
- In order to respond to the request faster, we adopt the way of asynchronous request to ensure the final consistency of data, which can greatly reduce the pressure of our database.
We can solve this asynchronous request through message queue. Here we can quickly understand why asynchronous requests are needed and why asynchronous requests can bring more request carrying capacity to highly concurrent systems through several diagrams:
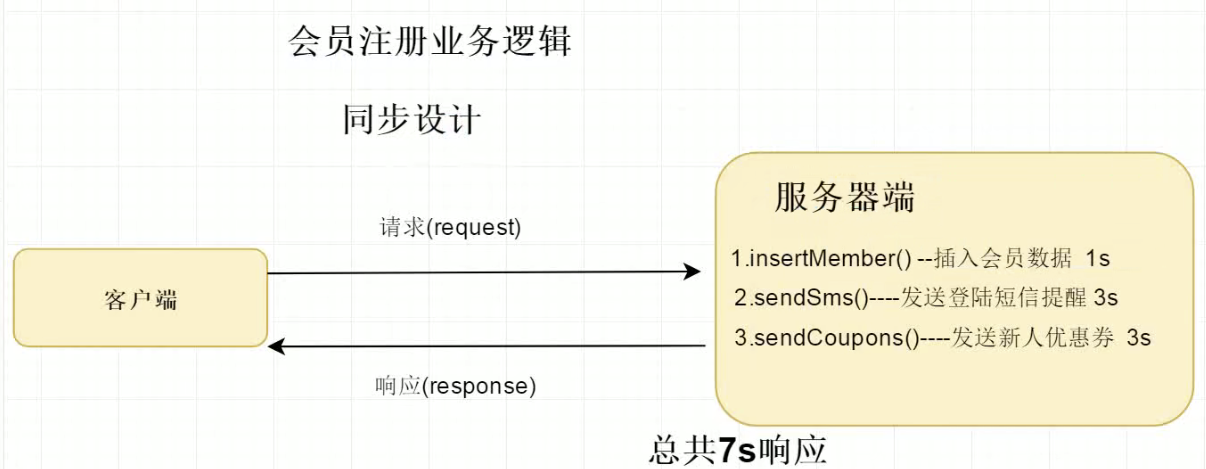
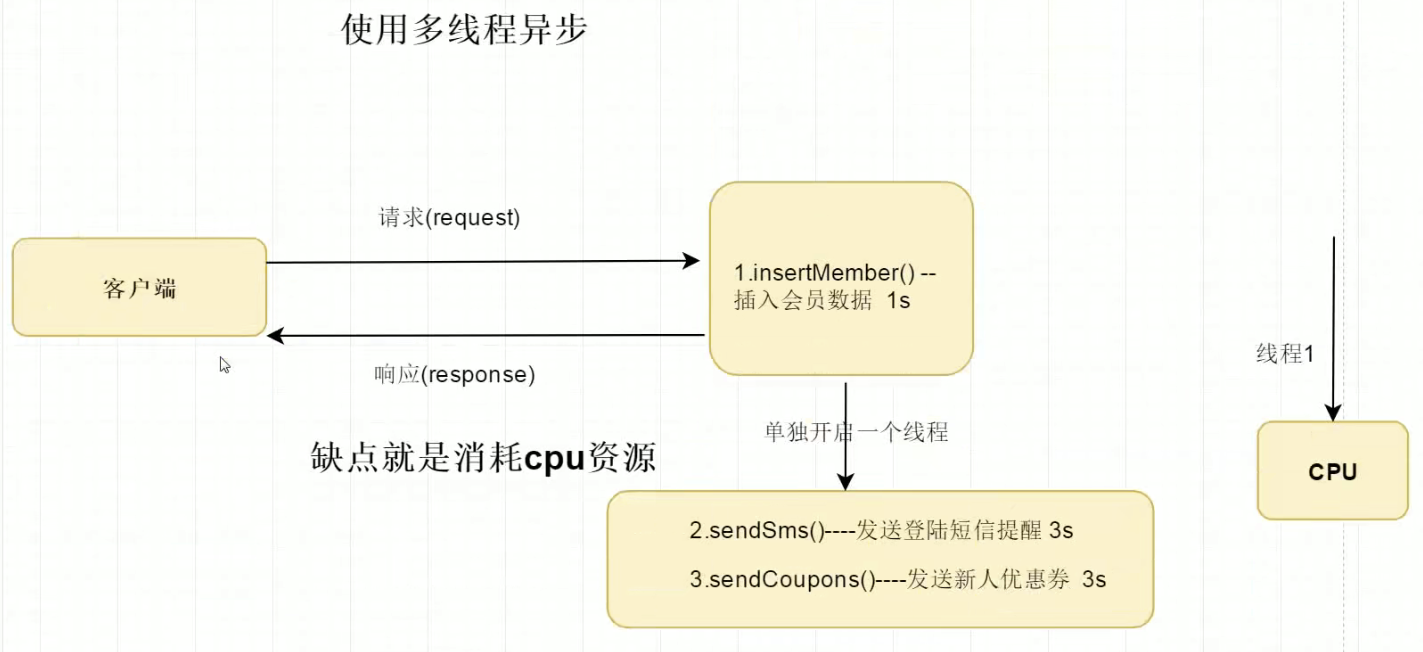
When it comes to using multithreaded asynchrony, we have to consider our own computer hardware and coupling. At this time, we introduce message oriented middleware:
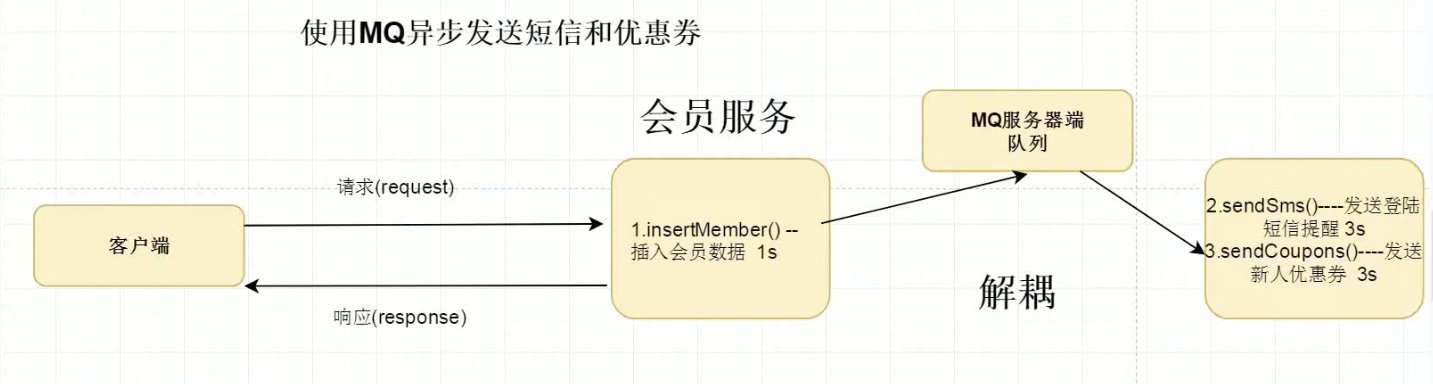
Therefore, we can easily use message queue to solve problem 2.
Problem 3 solution
Through the code block of the above problem, we have solved the problem of updating the inventory cache of second kill goods. Next, we need to solve the problem of ensuring that orders are not repeated and oversold:
I think so. Through the solution to the previous problem, we have brought the inventory cache data of second kill goods to our cache. We can use * * incr operation of * * redis * * to update the inventory atomically, so that thread insecurity will not be involved. Moreover, we force the inventory to be deducted from the cache first, and then asynchronously synchronized to the database.
We first query the current latest inventory according to the key in the cache of the library. After obtaining the current latest inventory, we judge the legitimacy. After it is legal, we perform the atomic self increment of incr to complete the final inventory reduction operation. Finally, we use the message queue to asynchronously synchronize the data to the database.
- Code block to solve non oversold problem:
@Override
public Boolean checkStockAndDecrement(Long goodsId) {
String key = "SECONDKILL::PRODUCT:" + goodsId + "-STOCK::COUNT";
Integer stock = (Integer) redisTemplate.opsForValue().get(key);
if (null == stock) {
/** Second kill goods or off the shelf**/
return false;
}
if (stock <= 0) {
/** There is no stock**/
return false;
}
/** The decrease here will reduce the inventory to negative one instead of zero, so use increase to reverse self increase**/
redisTemplate.opsForValue().increment(key, -1);
/** mq Asynchronously ensure the final consistency of database and cache inventory**/
secondKillSender.toDoUpdateStock(goodsId);
return true;
}
Current optimization results
I will show all the contents of this optimization, with clear annotation from top to bottom, from inside to outside
Second kill main entrance
- Make a second kill request
@ApiOperation(value = "Make a second kill request" )
@PostMapping("/private/do")
public Response doSecondKill(@ApiParam(value = "commodity vo", required = true) @RequestBody SeckillGoodsDetailVo goods) {
/** Get the information of the current login user**/
Long userId = UserThreadLocalUtil.get();
/** First judge whether to repeat purchase**/
Boolean isRepeat = seckillOrderService.checkCurrentUserOrder(userId, goods.getId());
if (isRepeat) {
return Response.setResponse(StatusCode.REPEAT_ORDER);
}
/** Check inventory and pre reduction inventory**/
Boolean hasStock = seckillGoodsService.checkStockAndDecrement(goods.getId());
if (!hasStock) {
return Response.error().message("The second kill is over!");
}
/** Second kill successful, order**/
Order order = seckillOrderService.secondKill(userId, goods);
Map<String, Object> data = new HashMap<>();
data.put("goods", goods);
data.put("order", order);
return Response.success().message("Second kill success").data(data);
}
Interface to determine whether to repeat purchase
- Query whether the current user places repeated orders
/**
* Query whether the current user places repeated orders
* @param userId
* @param goodsId
* @return Repeat order
*/
@Override
public Boolean checkCurrentUserOrder(Long userId, Long goodsId) {
String key = "SECONDKILL::USERID:" + userId + "-ORDER::GOODSID:" + goodsId;
/** Assert that he repeated the order! Is the assertion expression true? If the order is placed repeatedly, an exception will be thrown, otherwise it will be executed normally**/
Assert.isTrue(StringUtils.isEmpty(redisTemplate.opsForValue().get(key)), StatusCode.REPEAT_ORDER);
return false;
}
Check inventory and pre decrease inventory interface
- Check inventory and pre reduction inventory
/**
* Check inventory and pre reduction inventory
* @param goodsId
* @return Is there any inventory
*/
@Override
public Boolean checkStockAndDecrement(Long goodsId) {
String key = "SECONDKILL::PRODUCT:" + goodsId + "-STOCK::COUNT";
Integer stock = (Integer) redisTemplate.opsForValue().get(key);
if (null == stock) {
/** Second kill goods or off the shelf**/
return false;
}
if (stock <= 0) {
/** There is no stock**/
return false;
}
/** The decrease here will reduce the inventory to negative one instead of zero, so use increase to reverse self increase**/
redisTemplate.opsForValue().increment(key, -1);
/** mq Asynchronously ensure the final consistency of database and cache inventory**/
secondKillSender.toDoUpdateStock(goodsId);
return true;
}
Second kill successful order interface
- Second kill order interface
/**
* Second kill order
* @param userId
* @param goods
* @return Second kill order
*/
@Override
public Order secondKill(Long userId, SeckillGoodsDetailVo goods) {
/** Entering this method means that we have won the second kill quota, so we directly create the order**/
/** Pre load the order into redis**/
preOrder(userId, goods.getId());
/** Generate ordinary order**/
Order order = new Order();
order.setUserId(userId);
order.setGoodsId(goods.getId());
order.setDeliveryAddrId(0L);
order.setGoodsName(goods.getGoodsName());
order.setGoodsCount(1);
order.setGoodsPrice(goods.getSeckillPrice());
order.setOrderChannel(1);
order.setStatus(0);
order.setCreateDate(new Date());
/** mq How to ensure the final consistency of asynchronous data**/
secondKillSender.toDoUpdateOrder(order);
/** Return the order information completed by rush purchase**/
return order;
}
- Order pre entry method
/**
* Order advance operation
* @param userId
* @param goodsId
*/
private void preOrder(Long userId, Long goodsId) {
String key = "SECONDKILL::USERID:" + userId + "-ORDER::GOODSID:" + goodsId;
/** The effective time of cache is longer than the duration of second kill**/
redisTemplate.opsForValue().set(key, "Enable pre order", 1, TimeUnit.DAYS);
}
mq asynchronous configuration
- Configuration class
package com.zhao.seckill.config;
import org.springframework.amqp.core.Binding;
import org.springframework.amqp.core.BindingBuilder;
import org.springframework.amqp.core.Queue;
import org.springframework.amqp.core.TopicExchange;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* @author noblegasesgoo
* @version 0.0.1
* @date 2022/2/17 20:51
* @description RabbitMQ Configuration class
*/
@Configuration
public class RabbitMQConfig {
private static final String ORDER_QUEUE = "orderQueue";
private static final String GOODS_QUEUE = "goodsQueue";
private static final String SECONDKILL_EXCHANGE = "secondkillExchange";
@Bean
public Queue orderQueue() {
return new Queue(ORDER_QUEUE, true);
}
@Bean
public Queue goodsQueue() {
return new Queue(GOODS_QUEUE, true);
}
@Bean
public TopicExchange topicExchange() {
return new TopicExchange(SECONDKILL_EXCHANGE);
}
@Bean
public Binding orderQueueBind() {
return BindingBuilder.bind(orderQueue()).to(topicExchange()).with("secondkill.order");
}
@Bean
public Binding goodsQueueBind() {
return BindingBuilder.bind(goodsQueue()).to(topicExchange()).with("secondkill.stock");
}
}
- Producer class of mq
package com.zhao.seckill.service.mq;
import com.alibaba.fastjson.JSON;
import com.zhao.seckill.domain.pojo.Order;
import lombok.extern.slf4j.Slf4j;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
/**
* @author noblegasesgoo
* @version 0.0.1
* @date 2022/2/18 19:52
* @description Second kill system message producer
*/
@Service
@Slf4j
public class SecondKillSender {
@Autowired
private RabbitTemplate rabbitTemplate;
/**
* Asynchronously update inventory message (database)
* @param goodsId
*/
public void toDoUpdateStock(Long goodsId) {
rabbitTemplate.convertAndSend("seckillExchange", "secondkill.stock", goodsId.toString());
}
/**
* Asynchronous update order message (database)
* @param order
*/
public void toDoUpdateOrder(Order order) {
rabbitTemplate.convertAndSend("seckillExchange", "secondkill.order", JSON.toJSONString(order));
}
}
- mq consumer class
package com.zhao.seckill.service.mq;
import com.alibaba.fastjson.JSON;
import com.baomidou.mybatisplus.core.conditions.update.UpdateWrapper;
import com.zhao.seckill.domain.pojo.Goods;
import com.zhao.seckill.domain.pojo.Order;
import com.zhao.seckill.domain.pojo.SeckillGoods;
import com.zhao.seckill.domain.pojo.SeckillOrder;
import com.zhao.seckill.service.IGoodsService;
import com.zhao.seckill.service.IOrderService;
import com.zhao.seckill.service.ISeckillGoodsService;
import com.zhao.seckill.service.ISeckillOrderService;
import lombok.extern.slf4j.Slf4j;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
/**
* @author noblegasesgoo
* @version 0.0.1
* @date 2022/2/18 19:52
* @description Second kill system message consumer
*/
@Service
@Slf4j
public class SecondKillReceiver {
@Autowired
private IGoodsService goodsService;
@Autowired
private ISeckillGoodsService seckillGoodsService;
@Autowired
private IOrderService orderService;
@Autowired
private ISeckillOrderService seckillOrderService;
/**
* Asynchronously update product information message
* @param goodsId
*/
@RabbitListener(queues = "goodsQueue")
public void doUpdateStock(String goodsId){
/** The method of obtaining inventory from the cache is not used here because the cache may expire and the required number cannot be obtained**/
/** The following inventory reduction methods are atomic and thread safe**/
goodsService.update(new UpdateWrapper<Goods>().eq("id", Long.parseLong(goodsId))
.setSql("stock_count=stock_count-1"));
seckillGoodsService.update(new UpdateWrapper<SeckillGoods>().eq("goods_id", Long.parseLong(goodsId))
.setSql("stock_count=stock_count-1"));
}
/**
* Asynchronous update order message
* @param orderString
*/
@RabbitListener(queues = "orderQueue")
public void doUpdateOrder(String orderString){
/** Convert JSON strings to objects**/
Order order = JSON.parseObject(orderString, Order.class);
/** Execute the database receipt operation of the order table**/
orderService.save(order);
/**Execute the database warehousing operation of the second kill order table**/
SeckillOrder seckillOrder = new SeckillOrder();
seckillOrder.setUserId(order.getUserId());
seckillOrder.setOrderId(order.getId());
seckillOrder.setGoodsId(order.getGoodsId());
seckillOrderService.save(seckillOrder);
}
}
You are welcome to synchronize your notes https://gitee.com/noblegasesgoo/notes
If something goes wrong, I hope the leaders in the comment area can discuss and correct each other, maintain the health of the community, and everyone can contribute together. We can't have the knowledge of tolerating mistakes. ----------- Love you noblegasesgoo