outline
According to Anthony Williams's "C + + concurrent programming practice",
One worker thread operates at the head of the task queue, while other worker threads operate at the end of the task queue. This actually means that the queue is a last in, first out stack for owning threads. The tasks recently put in the queue will be taken out first. From the perspective of caching, this can improve performance, because the data of the extracted task is more likely to be in the cache than that of the task previously put in the queue.
Tried to adjust Simple thread pool (VII) The implementation scheme of non blocking mutual aid thread pool mentioned in, uses std::deque to replace std::queue as the underlying data structure for storing work tasks, and newly defines a non blocking thread safe double ended queue lockwise_ Deque<>.
Work tasks are always added to the end of a two ended queue. In order to verify whether the performance can be improved from the perspective of caching, the author realizes the acquisition of work tasks in four ways,
- The current worker thread obtains the task from the head of its own task queue. If there is no work task, it obtains the task from the head of other task queues (A);
- The current worker thread obtains tasks from the tail of its own task queue. If there are no work tasks, it obtains tasks from the head of other task queues (B);
- The current worker thread obtains tasks from the head of its own task queue. If there are no work tasks, it obtains tasks from the tail of other task queues (C);
- The current worker thread obtains tasks from the tail of its own task queue. If there are no work tasks, it obtains tasks from the tail of other task queues (D).
Mode A is the initial mode Non blocking mutual aid , the difference is that the underlying data structure is changed from std::queue to std::deque; Mode B is implemented according to Anthony; C and D are added by the author to fully confirm the impact of caching on performance.
This article will not repeat the lawsuit and Simple thread pool (VII) The same content. If there is any ambiguity, please refer to this blog.
realization
The following code gives the implementation of non blocking thread safe double ended queue, (lockwise_deque.h)
template<class T>
class Lockwise_Deque {
private:
struct Spinlock_Mutex { ...
} mutable _m_;
deque<T> _q_;
public:
void push(T&& element) {
lock_guard<Spinlock_Mutex> lk(_m_);
_q_.push_back(std::move(element)); // #1
}
bool pop(T& element) {
lock_guard<Spinlock_Mutex> lk(_m_);
if (_q_.empty())
return false;
element = std::move(_q_.front()); // #2
_q_.pop_front();
return true;
}
bool pull(T& element) {
lock_guard<Spinlock_Mutex> lk(_m_);
if (_q_.empty())
return false;
element = std::move(_q_.back()); // #3
_q_.pop_back();
return true;
}
...
};
The push (T & &) function adds tasks (#1) from the tail of the double ended queue, the pop (T &) function obtains tasks (#2) from the head of the double ended queue, and the pull (T &) function obtains tasks (#3) from the tail of the double ended queue.
The following code shows the implementation of mode A, (lockwise_mutual_2a_pool.h)
class Thread_Pool {
...
void work(unsigned index) {
Task_Wrapper task;
while (!_done_.load(memory_order_acquire)) {
if (_workerqueues_[index].pop(task)) // #1
task();
else
for (unsigned i = 0; i < _workersize_; ++i)
if (_workerqueues_[(index + i + 1) % _workersize_].pop(task)) { // #2
task();
break;
}
while (_suspend_.load(memory_order_acquire))
std::this_thread::yield();
}
}
...
}
The current worker thread obtains the work task (#1) from the head of its own task queue. If there is no work task, it obtains the task (#2) from the head of other task queues.
The following code shows the implementation of mode B, (lockwise_mutual_2b_pool.h)
class Thread_Pool {
...
void work(unsigned index) {
Task_Wrapper task;
while (!_done_.load(memory_order_acquire)) {
if (_workerqueues_[index].pull(task)) // #1
task();
else
for (unsigned i = 0; i < _workersize_; ++i)
if (_workerqueues_[(index + i + 1) % _workersize_].pop(task)) { // #2
task();
break;
}
while (_suspend_.load(memory_order_acquire))
std::this_thread::yield();
}
}
...
}
The current worker thread obtains the work task (#1) from the tail of its own task queue. If there is no work task, it obtains the task (#2) from the head of other task queues.
The following code shows the implementation of C mode, (lockwise_mutual_2c_pool.h)
class Thread_Pool {
...
void work(unsigned index) {
Task_Wrapper task;
while (!_done_.load(memory_order_acquire)) {
if (_workerqueues_[index].pop(task)) // #1
task();
else
for (unsigned i = 0; i < _workersize_; ++i)
if (_workerqueues_[(index + i + 1) % _workersize_].pull(task)) { // #2
task();
break;
}
while (_suspend_.load(memory_order_acquire))
std::this_thread::yield();
}
}
...
}
The current worker thread obtains the work task (#1) from the head of its own task queue. If there is no work task, it obtains the task (#2) from the tail of other task queues.
The following code shows the implementation of mode D, (lockwise_mutual_2d_pool.h)
class Thread_Pool {
...
void work(unsigned index) {
Task_Wrapper task;
while (!_done_.load(memory_order_acquire)) {
if (_workerqueues_[index].pull(task)) // #1
task();
else
for (unsigned i = 0; i < _workersize_; ++i)
if (_workerqueues_[(index + i + 1) % _workersize_].pull(task)) { // #2
task();
break;
}
while (_suspend_.load(memory_order_acquire))
std::this_thread::yield();
}
}
...
}
The current worker thread obtains work tasks (#1) from the tail of its own task queue. If there are no work tasks, it obtains tasks (#2) from the tail of other task queues.
logic
The following class diagram shows the main logical structure of the code of this thread pool.
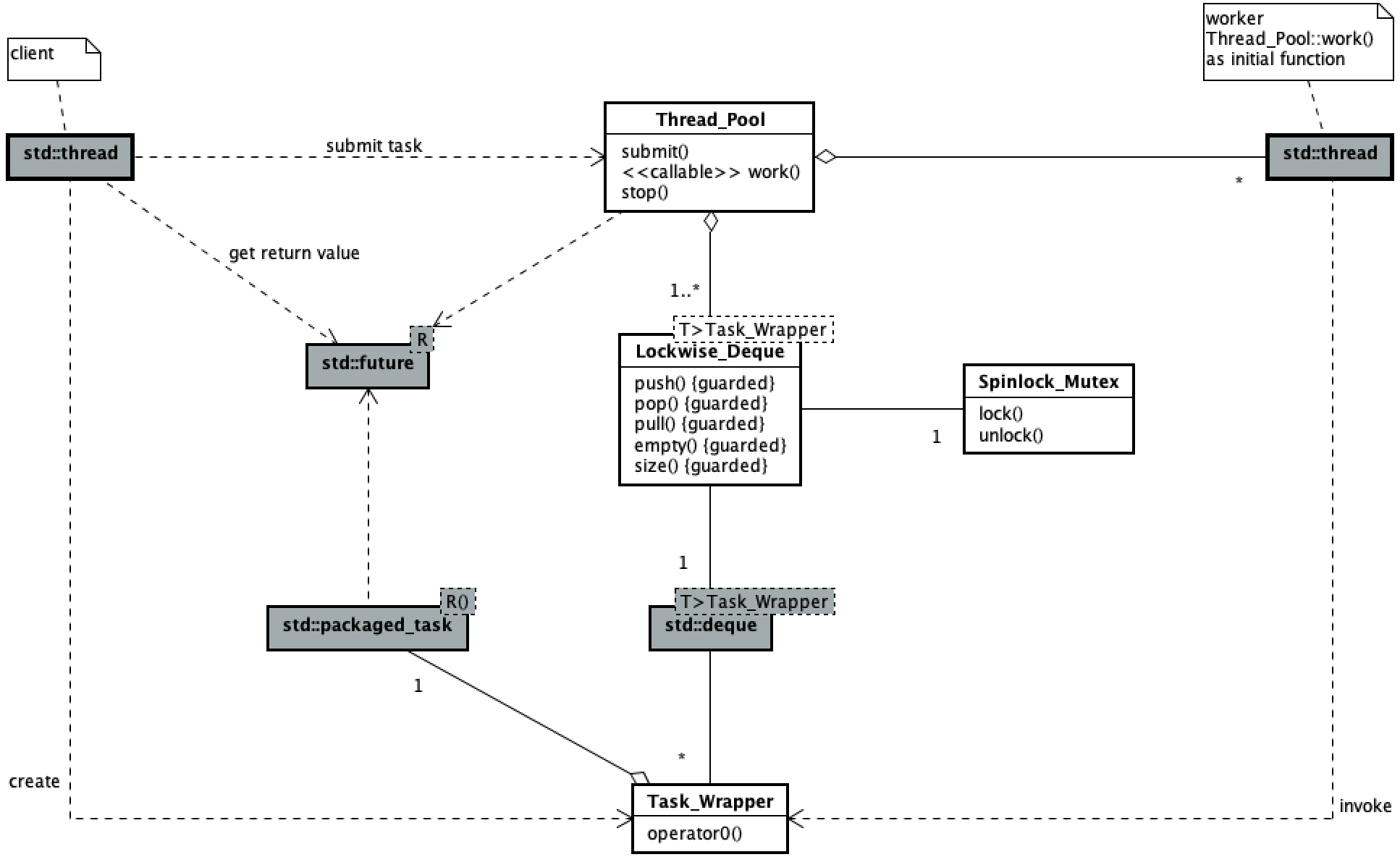
Thread pool: the concurrent process of user submitting tasks and worker executing tasks Simple thread pool (I) Consistent in, omitted here.
verification
The validation process uses Simple thread pool (3) Test cases defined in. The author compares the test results with Simple thread pool (VII) The results are as follows,
Figure 1 illustrates the comparison of the difference in throughput 1 in different thinking times in the submission cycle of 0.5 minutes, 1 minute and 3 minutes.
[note] the four non blocking thread safe two terminal queues are abbreviated as LM2A, LM2B, LM2C and LM2D, the same below.
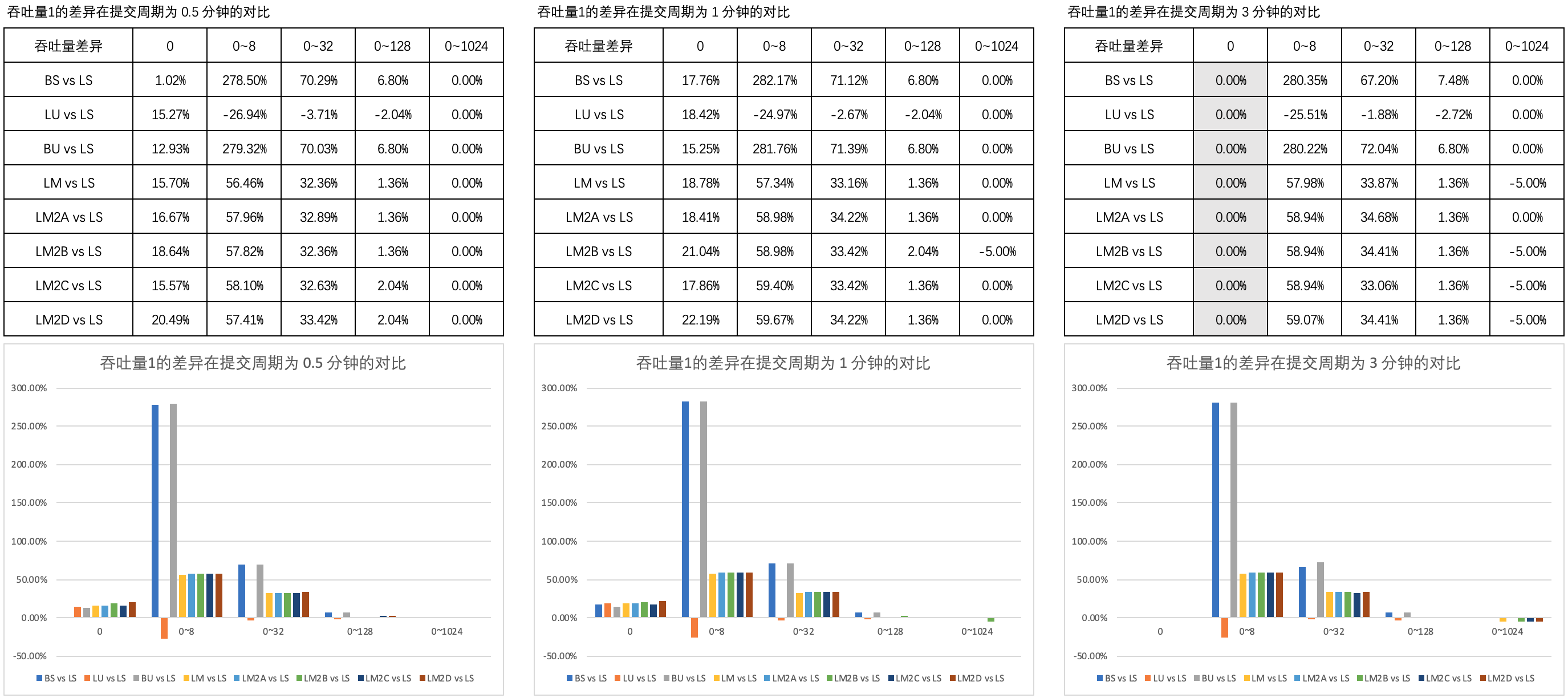
Figure 2 shows the comparison of the difference in throughput 2 in different thinking time in the submission cycle of 0.5 minutes, 1 minute and 3 minutes.
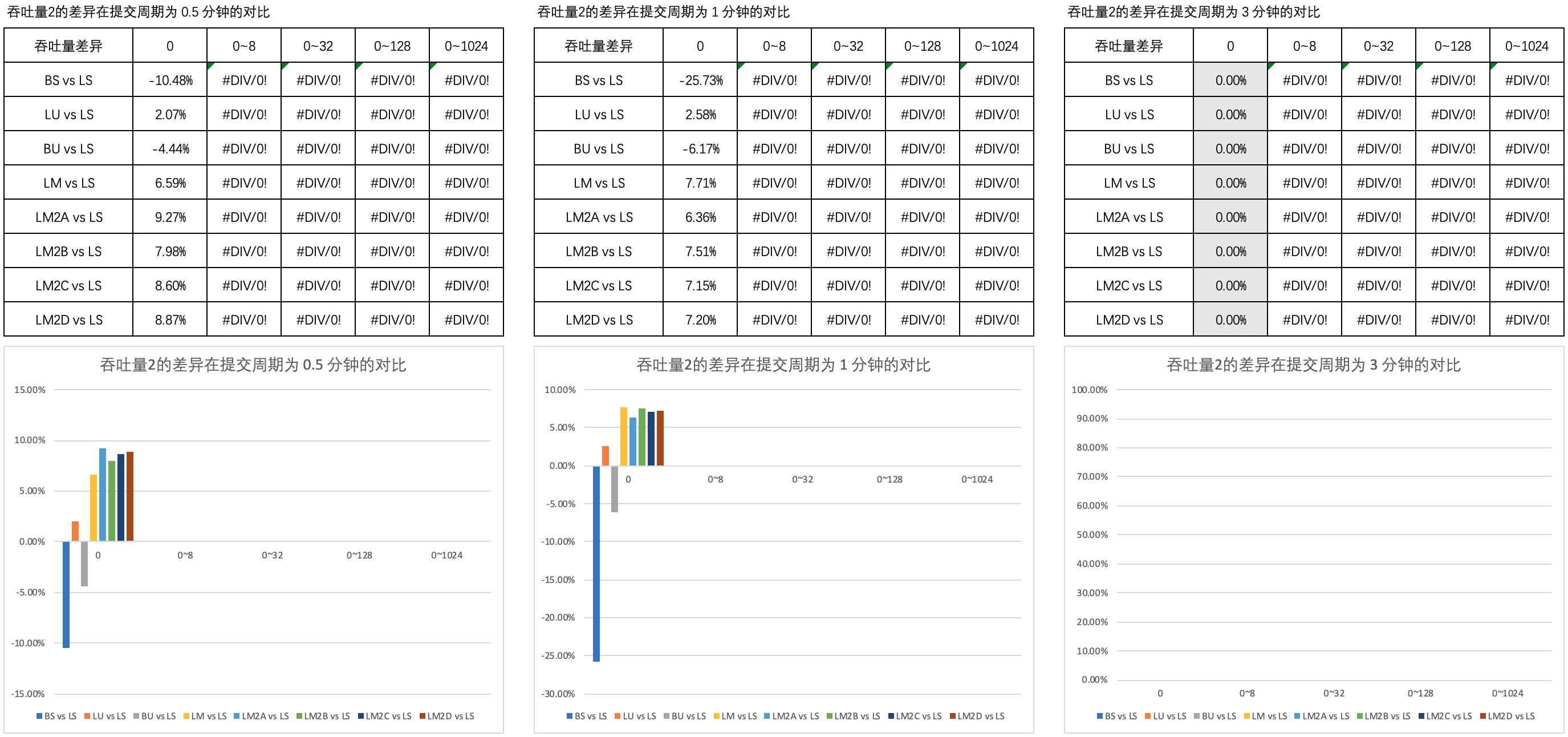
Figure 3 illustrates the comparison of throughput differences in different thinking times in 0.5 minute, 1 minute and 3 minute submission cycles.
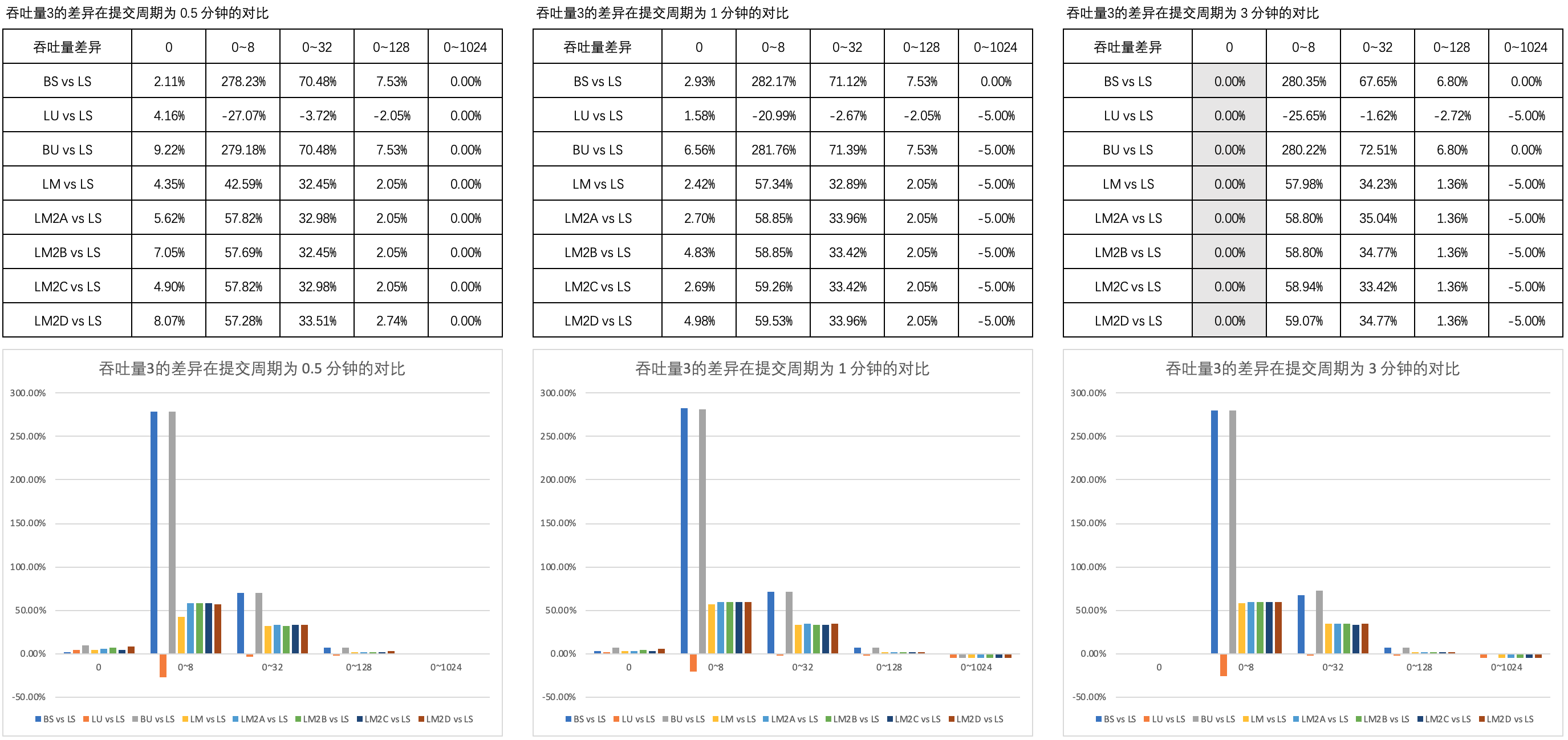
It can be seen that the throughput performance of the non blocking mutual aid thread pool of mode B is almost the same as that of modes A, C, D and ordinary queues.
Based on the above comparative analysis, the author believes that using double ended queue in non blocking thread pool,
From a caching perspective, this can improve performance
Such a discussion is worth discussing.
last
For complete code examples and test data, please refer to [github] cnblogs/15723078 .
The author refers to C + + concurrent programming practice / written by Williams (a.); Complete translation- Beijing: People's Posts and Telecommunications Press, 2015.6 (reprinted in April 2016), some design ideas. To Anthony Williams, Zhou Quan and other translators.