Why are sub databases and sub tables
If you think the theory is wordy, just jump to the second level 1 Title sub library and start looking.
What is sub database and sub table?
In fact, it means literally. It's easy to understand:
Sub database: the process of splitting a single database into multiple databases, scattering data in multiple databases.
Split table: the process of splitting a single table into multiple tables, scattering data in multiple tables.
Why do you want to divide the database and table?
Keywords: improve performance and increase availability.
In terms of performance
With the increasing amount of data in a single database and the higher QPS of database query, the time required to read and write the database is also increasing. The read-write performance of database may become the bottleneck of business development. Accordingly, you need to optimize the database performance. In this article, we only discuss database level optimization, not application level optimization methods such as caching.
If the query QPS of the database is too high, you need to consider splitting the database and sharing the connection pressure of a single database through database splitting. For example, if the query QPS is 3500, assuming that a single database can support 1000 connections, you can consider splitting into multiple databases to disperse the query connection pressure.
If the amount of data in a single table is too large, when the amount of data exceeds a certain order of magnitude, there may still be performance problems after traditional optimization methods at the pure database level, such as index optimization, whether for data query or data update. This is a qualitative change caused by quantitative change. At this time, we need to change ideas to solve the problem, such as solving the problem from the source of data production and data processing. Since the amount of data is large, let's divide and rule and divide into parts. This leads to a split table, which splits the data into multiple tables according to certain rules to solve the access performance problem that cannot be solved in a single table environment.
In terms of availability
If an accident occurs to a single database, it is likely to lose all data. Especially in the cloud era, many databases run on virtual machines. If the virtual machine / host has an accident, it may cause irreparable losses. Therefore, in addition to the traditional master slave, master master master and other deployment levels to solve the reliability problem, we can also consider solving this problem from the data splitting level.
Here we take database downtime as an example:
- In the case of single database deployment, if the database goes down, the impact of the failure is 100%, and the recovery may take a long time.
- If we split it into two libraries and deploy them on different machines, and one library goes down, the impact of the failure is 50%, and 50% of the data can continue to serve.
- If we split it into four libraries and deploy them on different machines, and one library goes down, the impact of the failure will be 25%, and 75% of the data can continue to serve, and the recovery time will be very short.
Of course, we can't dismantle the library without restrictions. This is also a way to sacrifice storage resources to improve performance and availability. After all, resources are always limited.
How to divide databases and tables
Sub library? Sub table? Or is it divided into databases and tables?
According to the information learned in the first part, there are three schemes for sub database and sub table:
| Segmentation scheme | Problems solved |
|---|---|
| Only partial tables of sub database | The database read / write QPS is too high and the database connection is insufficient |
| Partial database only | The amount of data in a single table is too large, and the storage performance encounters a bottleneck |
| That is, sub database and sub table | Insufficient connections + storage performance bottleneck caused by excessive data volume |
How to choose our own segmentation scheme?
If tables need to be divided, how many tables are appropriate?
Since all technologies serve the business, let's first review the business background from the perspective of data.
For example, our business system is to solve the consulting demands of members. We serve members through our XSpace customer service platform system. At present, we mainly use synchronized offline work order data as our data source to build our own data.
It is assumed that each offline work order will generate a corresponding member's consultation question (we refer to it as question list). If:
Online channel: 3w chat sessions are generated every day. Assuming that 50% of the sessions will generate an offline work order, 3w * 50% = 1.5w work orders can be generated every day;
Hotline channel: 2.5w calls are generated every day. Assuming that 80% of the calls will generate a work order, 2.5w * 80% = 2w calls / day can be generated every day;
Offline channel: assume that the offline channel directly generates 3w pens every day;
Total 1.5w + 2w + 3w = 6.5w / day
Considering the new business scenarios that may continue to be covered in the future, some expansion space needs to be reserved in advance. Here, we assume that 8w questionnaires are generated every day.
In addition to the questionnaire, there are two other commonly used business tables: user operation log table, user submitted form data table.
Among them, each questionnaire will generate multiple user operation logs. According to the historical statistics, on average, each questionnaire big appointment will generate 8 operation logs. We reserve some space, assuming that each questionnaire will generate about 10 user operation logs on average.
If the design service life of the system is 5 years, the data volume of the questionnaire is about 5 years 365 days / year 8w / day = 146 million, and the estimated number of tables is as follows:
The questionnaire needs: 146 million / 500w = 29.2 tables, so we will segment according to 32 tables;
The operation log needs 32 10 = 320 tables, so we divide it according to 32 16 = 512 tables.
If it is necessary to divide the library, how many libraries are appropriate?
In addition to the usual business peak reading and writing QPS, it is also necessary to consider the possible peak during the double 11 promotion period, which needs to be estimated in advance.
According to our actual business scenario, the data query source of the questionnaire mainly comes from Alibaba customer service Xiaomi home page. Therefore, it can be evaluated according to historical QPS, RT and other data. Assuming that we only need 3500 database connections, if a single database can bear up to 1000 database connections, we can split it into four databases.
How to segment data?
According to industry practice, the segmentation is usually carried out in two ways: horizontal segmentation and vertical segmentation. Of course, some complex business scenarios may also choose the combination of the two.
(1) Horizontal segmentation
This is a method of horizontal segmentation by business dimension. For example, the common segmentation by member dimension scatters the data related to different members in different database tables according to certain rules. Because our business scenarios decide to read and write data from the perspective of members, we choose to perform database segmentation in a horizontal manner.
(2) Vertical segmentation
Vertical segmentation can be simply understood as splitting different fields of a table into different tables.
For example, suppose there is a small e-commerce business, which puts the commodity information, buyer and seller information and payment information related to an order in a large table. You can consider splitting commodity information, buyer information, seller information and payment information into separate tables through vertical segmentation, and associating them with the basic order information through the order number.
In another case, if a table has 10 fields, only 3 of which need to be modified frequently, you can consider splitting these 3 fields into sub tables. Avoid locking the query rows that affect the remaining seven fields when modifying these three data.
sub-treasury
Database preparation
The cloud hospital management system is simulated here. When the database connection pressure is too high, the database is split. It is planned to split into two databases.
The database design relationship is as follows:
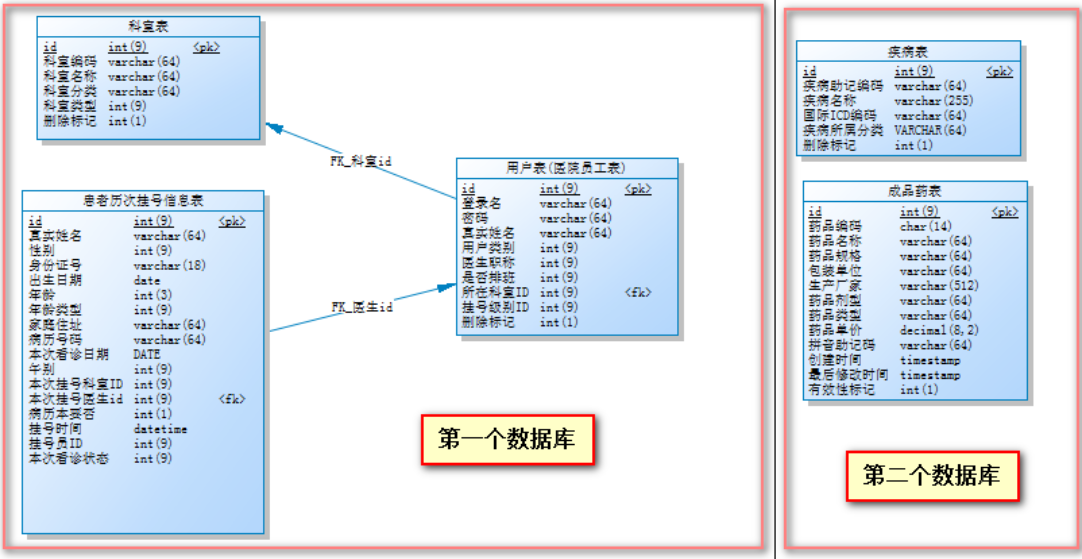
According to the association relationship of the above business tables, there is an association relationship between the Department table, user table and registration information table, so they should be placed on one data node. For testing, the other two tables should be placed on another data node, expressed as follows:
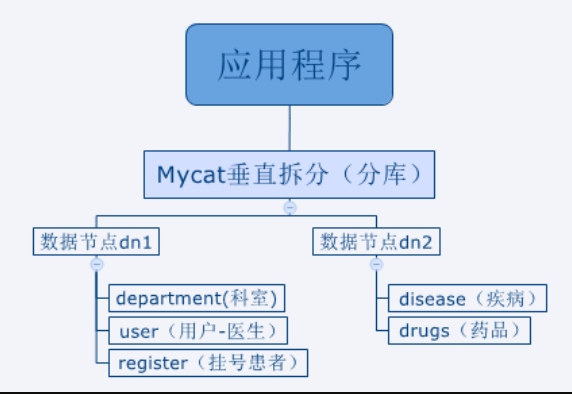
Database before stopping
The sub database must be prepared on the new database. Discard the above database here and re create a clean database
Delete the original database (container). You can only stop the logic before the container is used for testing
[root@mycat ~]# docker stop m1 && docker stop m2 && docker stop s1 && docker stop s2 m1 m2 s1 s2 [root@mycat ~]# docker rm m1 && docker rm m2 && docker rm s1 && docker rm s2 m1 m2 s1 s2 [root@mycat ~]#
Install two database services (containers)
Create two databases. Master-Slave database replication (master slave mode) is not configured here, so there is no need to map the configuration file separately on the docker host. Execute the following command to directly create two MySQL database containers
docker run --name dn1 -p 3316:3306 -e MYSQL_ROOT_PASSWORD=root -d mysql:5.7 docker run --name dn2 -p 3326:3306 -e MYSQL_ROOT_PASSWORD=root -d mysql:5.7
The specific implementation process is as follows:
[root@mycat ~]# docker run --name dn1 -p 3316:3306 -e MYSQL_ROOT_PASSWORD=root -d mysql:5.7 &&\ > docker run --name dn2 -p 3326:3306 -e MYSQL_ROOT_PASSWORD=root -d mysql:5.7 b9b3297b30ae82cd25889414e76e16c0fa20c186535a1c6b0d2d15469163b40e e61487a76ef284927f031897ac38d7c6d00c88c191265f946fcf6bb237f04f54 [root@mycat ~]#
View the ip addresses of two database machines (containers)
[root@mycat ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
fd2bea0b1f01 mysql:5.7 "docker-entrypoint.s..." 5 seconds ago Up 3 seconds 33060/tcp, 0.0.0.0:3326->3306/tcp, :::3326->3306/tcp dn2
6ae712c5f59c mysql:5.7 "docker-entrypoint.s..." 6 seconds ago Up 5 seconds 33060/tcp, 0.0.0.0:3316->3306/tcp, :::3316->3306/tcp dn1
[root@mycat ~]# docker inspect --format '{{ .NetworkSettings.IPAddress }}' dn1 &&\
> docker inspect --format '{{ .NetworkSettings.IPAddress }}' dn2
172.17.0.2
172.17.0.3
[root@mycat ~]#
The ip addresses are:
| container | IP |
|---|---|
| dn1 | 172.17.0.2 |
| dn2 | 172.17.0.3 |
Create database
Create a database on two blank database machines (containers) as follows:
CREATE DATABASE his_mycat DEFAULT CHARACTER SET utf8mb4;
Create database on dn1
[root@mycat ~]# mysql -u root -proot -h 172.17.0.2 -P3306 Welcome to the MariaDB monitor. Commands end with ; or \g. Your MySQL connection id is 5 Server version: 5.7.34 MySQL Community Server (GPL) Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. MySQL [(none)]> CREATE DATABASE his_mycat DEFAULT CHARACTER SET utf8mb4; Query OK, 1 row affected (0.01 sec) MySQL [(none)]> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | his_mycat | | mysql | | performance_schema | | sys | +--------------------+ 5 rows in set (0.00 sec) MySQL [(none)]> exit Bye [root@mycat ~]#
Create database on dn2
[root@mycat ~]# mysql -u root -proot -h 172.17.0.3 -P3306 Welcome to the MariaDB monitor. Commands end with ; or \g. Your MySQL connection id is 2 Server version: 5.7.34 MySQL Community Server (GPL) Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. MySQL [(none)]> CREATE DATABASE his_mycat DEFAULT CHARACTER SET utf8mb4; Query OK, 1 row affected (0.00 sec) MySQL [(none)]> MySQL [(none)]> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | his_mycat | | mysql | | performance_schema | | sys | +--------------------+ 5 rows in set (0.00 sec) MySQL [(none)]> exit Bye [root@mycat ~]#
Configure mycat
Sub database rules:
- dn1: department table, user table, register patient registration table
- dn2: drugs list, disease list
Modify the schema of mycat XML reconfiguration rule:
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1">
<table name="drugs" dataNode="dn2"></table>
<table name="disease" dataNode="dn2"></table>
</schema>
<dataNode name="dn1" dataHost="host1" database="his_mycat"/>
<dataNode name="dn2" dataHost="host2" database="his_mycat"/>
<dataHost name="host1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1"
slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM1" url="172.17.0.2:3306" user="root" password="root">
</writeHost>
</dataHost>
<dataHost name="host2" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1"
slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM2" url="172.17.0.3:3306" user="root" password="root">
</writeHost>
</dataHost>
</mycat:schema>
Start mycat
Execute in mycat/bin directory
./mycat console
Log in to mycat to create table structure
/****dn1****/ CREATE TABLE `department` ( `id` int(9) NOT NULL AUTO_INCREMENT COMMENT 'id', `DeptCode` varchar(64) NOT NULL COMMENT 'Department code', `DeptName` varchar(64) NOT NULL COMMENT 'Department name', `DeptCategory` varchar(64) DEFAULT NULL COMMENT 'Department classification', `DeptTypeID` int(9) NOT NULL COMMENT 'Department type', `DelMark` int(1) DEFAULT NULL COMMENT 'Delete tag', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; CREATE TABLE `user` ( `id` int(9) NOT NULL COMMENT 'id', `UserName` varchar(64) NOT NULL COMMENT 'Login name', `Password` varchar(64) DEFAULT NULL COMMENT 'password', `RealName` varchar(64) NOT NULL COMMENT 'Real name', `UserTypeID` int(9) DEFAULT NULL COMMENT '1 - Registered personnel 2 - Outpatient doctor 3 - Medical technologist 4 - Pharmacy personnel 5 - Financial personnel 6 - Administrative staff ', `DocTitleID` int(9) DEFAULT NULL COMMENT 'Doctor title', `IsScheduling` int(9) DEFAULT NULL COMMENT 'Schedule or not', `DeptId` int(9) NOT NULL COMMENT 'Department ID', `RegistId` int(9) DEFAULT NULL COMMENT 'Registration level ID', `DelMark` int(1) DEFAULT NULL COMMENT 'Delete tag', PRIMARY KEY (`id`), KEY `FK_Department id` (`DeptId`), CONSTRAINT `FK_Department id` FOREIGN KEY (`DeptId`) REFERENCES `department` (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; CREATE TABLE `register` ( `id` int(9) NOT NULL COMMENT 'id', `RealName` varchar(64) DEFAULT NULL COMMENT 'Real name', `Gender` int(9) DEFAULT NULL COMMENT 'Gender', `IDnumber` varchar(18) DEFAULT NULL COMMENT 'ID number', `BirthDate` date DEFAULT NULL COMMENT 'date of birth', `Age` int(3) DEFAULT NULL COMMENT 'Age', `AgeType` int(9) DEFAULT NULL COMMENT 'Age type', `HomeAddress` varchar(64) DEFAULT NULL COMMENT 'Home address', `CaseNumber` varchar(64) DEFAULT NULL COMMENT 'If a patient is seen in the same hospital for many times, determine whether the "medical record number" of the patient is the same according to whether the patient uses the same medical record book.', `VisitDate` date NOT NULL COMMENT 'Date of this visit', `Noon` int(9) NOT NULL COMMENT 'Afternoon farewell', `DeptId` int(9) DEFAULT NULL COMMENT 'This registration department ID', `UserId` int(9) DEFAULT NULL COMMENT 'Registered doctor id', `IsBook` int(1) NOT NULL COMMENT 'Do you want the medical record book', `RegisterTime` datetime DEFAULT NULL COMMENT 'Registration Time ', `RegisterID` int(9) NOT NULL COMMENT 'Registration clerk ID', `VisitState` int(9) DEFAULT NULL COMMENT 'Status of this visit', PRIMARY KEY (`id`), KEY `FK_doctor id` (`UserId`), CONSTRAINT `FK_doctor id` FOREIGN KEY (`UserId`) REFERENCES `user` (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; /****dn2****/ CREATE TABLE `disease` ( `id` int(9) NOT NULL COMMENT 'id', `DiseaseCode` varchar(64) DEFAULT NULL COMMENT 'Disease mnemonic code', `DiseaseName` varchar(255) DEFAULT NULL COMMENT 'Disease name', `DiseaseICD` varchar(64) DEFAULT NULL COMMENT 'international ICD code', `DiseaseType` varchar(64) DEFAULT NULL COMMENT 'Classification of disease', `DelMark` int(1) DEFAULT NULL COMMENT 'Delete tag', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; CREATE TABLE `drugs` ( `id` int(9) NOT NULL COMMENT 'id', `Drugs_Code` char(14) DEFAULT NULL COMMENT 'Drug code', `Drugs_Name` varchar(64) DEFAULT NULL COMMENT 'Drug name', `Drugs_Format` varchar(64) DEFAULT NULL COMMENT 'Drug specification', `Drugs_Unit` varchar(64) DEFAULT NULL COMMENT 'Packaging unit', `Manufacturer` varchar(512) DEFAULT NULL COMMENT 'Manufacturer', `Drugs_Dosage` varchar(64) DEFAULT NULL COMMENT 'Drug dosage form', `Drugs_Type` varchar(64) DEFAULT NULL COMMENT 'Drug type', `Drugs_Price` decimal(8,2) DEFAULT NULL COMMENT 'Drug unit price', `Mnemonic_Code` varchar(64) DEFAULT NULL COMMENT 'Pinyin mnemonic code', `Creation_Date` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT 'Creation time', `DelMark` int(1) DEFAULT NULL COMMENT 'Validity mark', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
verification
After creation, view the table storage in mycat client, dn1 node and dn2 node respectively
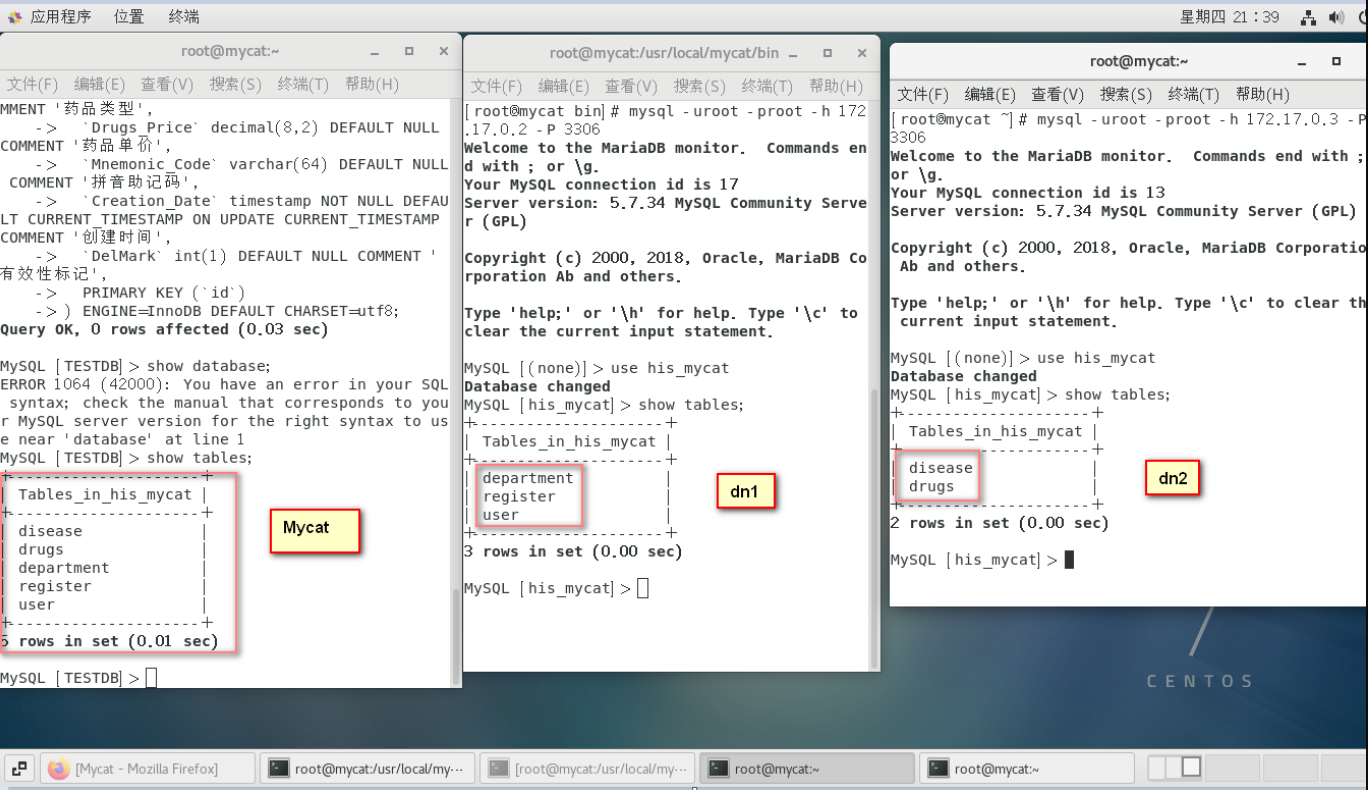
Mycat client authentication
The execution process is as follows:
[root@mycat ~]# mysql -umycat -p123456 -h 127.0.0.1 -P8066
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MySQL connection id is 1
Server version: 5.6.29-mycat-1.6-RELEASE-20161028204710 MyCat Server (OpenCloundDB)
Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MySQL [(none)]> use TESTDB
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
MySQL [TESTDB]> CREATE TABLE `department` (
-> `id` int(9) NOT NULL AUTO_INCREMENT COMMENT 'id',
-> `DeptCode` varchar(64) NOT NULL COMMENT 'Department code',
-> `DeptName` varchar(64) NOT NULL COMMENT 'Department name',
-> `DeptCategory` varchar(64) DEFAULT NULL COMMENT 'Department classification',
-> `DeptTypeID` int(9) NOT NULL COMMENT 'Department type',
-> `DelMark` int(1) DEFAULT NULL COMMENT ' Delete tag',
-> PRIMARY KEY (`id`)
-> ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
Query OK, 0 rows affected (0.02 sec)
MySQL [TESTDB]>
MySQL [TESTDB]> CREATE TABLE `user` (
-> `id` int(9) NOT NULL COMMENT 'id',
-> `UserName` varchar(64) NOT NULL COMMENT 'Login name',
-> `Password` varchar(64) DEFAULT NULL COMMENT 'password',
-> `RealName` varchar(64) NOT NULL COMMENT 'Real name',
-> `UserTypeID` int(9) DEFAULT NULL COMMENT '1 - Registered personnel 2 - Outpatient doctor 3 - Medical technologist 4 - Pharmacy personnel 5 - Financial personnel 6 - Administrative staff ',
-> `DocTitleID` int(9) DEFAULT NULL COMMENT 'Doctor title',
-> `IsScheduling` int(9) DEFAULT NULL COMMENT 'Shift scheduling',
-> `DeptId` int(9) NOT NULL COMMENT 'Department ID',
-> `RegistId` int(9) DEFAULT NULL COMMENT 'Registration level ID',
-> `DelMark` int(1) DEFAULT NULL COMMENT ' Delete tag',
-> PRIMARY KEY (`id`),
-> KEY `FK_Department id` (`DeptId`),
-> CONSTRAINT `FK_Department id` FOREIGN KEY (`DeptId`) REFERENCES `department` (`id`)
-> ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
Query OK, 0 rows affected (0.06 sec)
MySQL [TESTDB]>
MySQL [TESTDB]>
MySQL [TESTDB]> CREATE TABLE `register` (
-> `id` int(9) NOT NULL COMMENT 'id',
-> `RealName` varchar(64) DEFAULT NULL COMMENT 'Real name',
-> `Gender` int(9) DEFAULT NULL COMMENT 'Gender',
-> `IDnumber` varchar(18) DEFAULT NULL COMMENT 'ID number',
-> `BirthDate` date DEFAULT NULL COMMENT ' date of birth',
-> `Age` int(3) DEFAULT NULL COMMENT 'Age',
-> `AgeType` int(9) DEFAULT NULL COMMENT ' Age type',
-> `HomeAddress` varchar(64) DEFAULT NULL COMMENT 'Home address',
-> `CaseNumber` varchar(64) DEFAULT NULL COMMENT 'If a patient is seen in the same hospital for many times, determine whether the "medical record number" of the patient is the same according to whether the patient uses the same medical record book.',
-> `VisitDate` date NOT NULL COMMENT 'Date of this visit',
-> `Noon` int(9) NOT NULL COMMENT 'Afternoon farewell',
-> `DeptId` int(9) DEFAULT NULL COMMENT 'This registration department ID',
-> `UserId` int(9) DEFAULT NULL COMMENT 'Registered doctor id',
-> `IsBook` int(1) NOT NULL COMMENT 'Do you want the medical record book',
-> `RegisterTime` datetime DEFAULT NULL COMMENT 'Registration Time ',
-> `RegisterID` int(9) NOT NULL COMMENT 'Registration clerk ID',
-> `VisitState` int(9) DEFAULT NULL COMMENT 'Status of this visit',
-> PRIMARY KEY (`id`),
-> KEY `FK_doctor id` (`UserId`),
-> CONSTRAINT `FK_doctor id` FOREIGN KEY (`UserId`) REFERENCES `user` (`id`)
-> ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
Query OK, 0 rows affected (0.03 sec)
MySQL [TESTDB]>
MySQL [TESTDB]>
MySQL [TESTDB]> /****dn2****/
MySQL [TESTDB]> CREATE TABLE `disease` (
-> `id` int(9) NOT NULL COMMENT 'id',
-> `DiseaseCode` varchar(64) DEFAULT NULL COMMENT 'Disease mnemonic code',
-> `DiseaseName` varchar(255) DEFAULT NULL COMMENT 'Disease name',
-> `DiseaseICD` varchar(64) DEFAULT NULL COMMENT 'international ICD code',
-> `DiseaseType` varchar(64) DEFAULT NULL COMMENT 'Classification of disease',
-> `DelMark` int(1) DEFAULT NULL COMMENT ' Delete tag',
-> PRIMARY KEY (`id`)
-> ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
Query OK, 0 rows affected (0.03 sec)
MySQL [TESTDB]>
MySQL [TESTDB]>
MySQL [TESTDB]> CREATE TABLE `drugs` (
-> `id` int(9) NOT NULL COMMENT 'id',
-> `Drugs_Code` char(14) DEFAULT NULL COMMENT 'Drug code',
-> `Drugs_Name` varchar(64) DEFAULT NULL COMMENT 'Drug name',
-> `Drugs_Format` varchar(64) DEFAULT NULL COMMENT 'Drug specification',
-> `Drugs_Unit` varchar(64) DEFAULT NULL COMMENT 'Packaging unit',
-> `Manufacturer` varchar(512) DEFAULT NULL COMMENT 'Manufacturer',
-> `Drugs_Dosage` varchar(64) DEFAULT NULL COMMENT 'Drug dosage form',
-> `Drugs_Type` varchar(64) DEFAULT NULL COMMENT 'Drug type',
-> `Drugs_Price` decimal(8,2) DEFAULT NULL COMMENT 'Drug unit price',
-> `Mnemonic_Code` varchar(64) DEFAULT NULL COMMENT 'Pinyin mnemonic code',
-> `Creation_Date` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT 'Creation time',
-> `DelMark` int(1) DEFAULT NULL COMMENT ' Validity mark',
-> PRIMARY KEY (`id`)
-> ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
Query OK, 0 rows affected (0.03 sec)
MySQL [TESTDB]> show tables;
+---------------------+
| Tables_in_his_mycat |
+---------------------+
| disease |
| drugs |
| department |
| register |
| user |
+---------------------+
5 rows in set (0.01 sec)
MySQL [TESTDB]>
dn1 node authentication
[root@mycat bin]# mysql -uroot -proot -h 172.17.0.2 -P 3306 Welcome to the MariaDB monitor. Commands end with ; or \g. Your MySQL connection id is 17 Server version: 5.7.34 MySQL Community Server (GPL) Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. MySQL [(none)]> use his_mycat Database changed MySQL [his_mycat]> show tables; +---------------------+ | Tables_in_his_mycat | +---------------------+ | department | | register | | user | +---------------------+ 3 rows in set (0.00 sec) MySQL [his_mycat]>
dn2 node authentication
[root@mycat ~]# mysql -uroot -proot -h 172.17.0.3 -P 3306 Welcome to the MariaDB monitor. Commands end with ; or \g. Your MySQL connection id is 13 Server version: 5.7.34 MySQL Community Server (GPL) Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. MySQL [(none)]> use his_mycat Database changed MySQL [his_mycat]> show tables; +---------------------+ | Tables_in_his_mycat | +---------------------+ | disease | | drugs | +---------------------+ 2 rows in set (0.00 sec) MySQL [his_mycat]>
Sub table
Compared with vertical splitting, horizontal splitting does not classify tables, but distributes them into multiple databases according to certain rules of a field, and each table contains some data. In short, we can understand the horizontal segmentation of data as the segmentation of data rows, that is, some rows in the table are segmented into one database, while others are segmented into other databases.
demand
In the telecommunications industry, there is a telecommunications billing system (BOSS system), which is assumed to store the following information:
- Customer mobile account (mobile number) information
- Mobile phone call record information
- Dictionary table (such as storing common code table information, such as call type, 01: outgoing call, 02: incoming call, etc.)
The simple ER diagram is as follows:
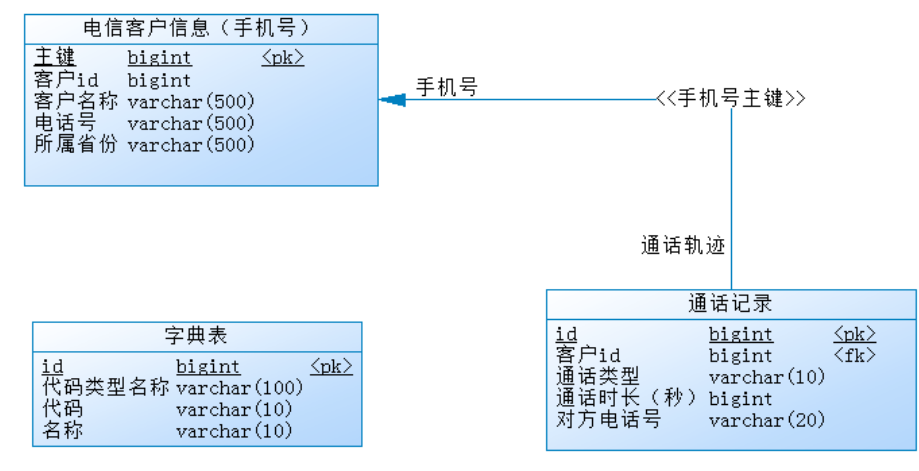
There is a bottleneck in the number of data stored in a single MySQL table. If there are 10 million data in a single table, it will reach the bottleneck, which will affect the query efficiency,
Horizontal splitting (table splitting) is needed for optimization. The BOSS system predicts that there will be more than 50 million customer mobile account tables within 5 years. The solution is to split the mobile phone number table horizontally.
The table structure sql statement is as follows:
/* Create database */ CREATE DATABASE boss; USE boss; /* Customer mobile phone number table */ CREATE TABLE customer ( id bigint(20) NOT NULL COMMENT 'Primary key', cid bigint(20) DEFAULT NULL COMMENT 'customer id', name varchar(500) DEFAULT NULL COMMENT 'Customer name', phone varchar(500) DEFAULT NULL COMMENT 'Telephone number', provice varchar(500) DEFAULT NULL COMMENT 'Province', PRIMARY KEY (id) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='Telecom customer information (mobile phone number)'; /* Phone number call record */ CREATE TABLE calllog ( id bigint(20) NOT NULL COMMENT 'id', phone_id bigint(20) DEFAULT NULL COMMENT 'Primary key', type varchar(10) DEFAULT NULL COMMENT 'Call type', duration bigint(20) DEFAULT NULL COMMENT 'Call duration (seconds)', othernum varchar(20) DEFAULT NULL COMMENT 'Opposite telephone number', PRIMARY KEY (id), KEY FK_Reference_1 (phone_id), CONSTRAINT FK_Reference_1 FOREIGN KEY (phone_id) REFERENCES customer (id) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='Call log'; /* Dictionary table */ CREATE TABLE dict ( id bigint(20) NOT NULL COMMENT 'id', caption varchar(100) DEFAULT NULL COMMENT 'Code type name', code varchar(10) DEFAULT NULL COMMENT 'code', name varchar(10) DEFAULT NULL COMMENT 'name', PRIMARY KEY (id) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='Dictionary table';
Split table implementation (mold taking)
This rule is the operation of finding the partition field
<tableRule name="mod-long">
<rule>
<columns>user_id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<!-- how many data nodes -->
<property name="count">3</property>
</function>
The columns above identify the table fields to be segmented, and the algorithm slicing function,
This configuration is very clear, that is, the decimal module calculation budget is carried out according to the id. compared with the fixed fragment hash, there may be batch insertion orders during batch insertion
The transaction inserts multiple data fragments, which increases the difficulty of transaction consistency (so the implementation of this method is the simplest, so the description is preferred).
principle
Take the customer table as an example. Different fields can be used for table splitting:
| Serial number | Split table field | explain |
|---|---|---|
| 1 | id (primary key, or creation time) | In terms of business, different mobile phone numbers of the same customer are distributed on different data nodes, which may reduce the query efficiency |
| 2 | cid (customer id), offer (province) | According to the customer id, the access of the two nodes is average. All the mobile phone numbers of a customer are on the same data node. |
mount this database
Here, as in the above process, the docker container is used to simulate different data nodes. Two MySQL database containers are created here for testing purposes.
docker run --name spt1 -p 3416:3306 -e MYSQL_ROOT_PASSWORD=root -d mysql:5.7 docker run --name spt2 -p 3426:3306 -e MYSQL_ROOT_PASSWORD=root -d mysql:5.7
The execution process is as follows:
[root@mycat ~]# docker run --name spt1 -p 3416:3306 -e MYSQL_ROOT_PASSWORD=root -d mysql:5.7 && docker run --name spt2 -p 3426:3306 -e MYSQL_ROOT_PASSWORD=root -d mysql:5.7 c9273c38f676aaf09321c6b117cf9445d5a15a632694480daf02db8cc9352bf6 5b19f22dbefbd00a65aaa6185a0c493518b4d71a5ff10b63f0bef6404efbb9bc [root@mycat ~]# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 5b19f22dbefb mysql:5.7 "docker-entrypoint.s..." 4 seconds ago Up 2 seconds 33060/tcp, 0.0.0.0:3426->3306/tcp, :::3426->3306/tcp spt2 c9273c38f676 mysql:5.7 "docker-entrypoint.s..." 6 seconds ago Up 4 seconds 33060/tcp, 0.0.0.0:3416->3306/tcp, :::3416->3306/tcp spt1 [root@mycat ~]#
Create database and table
Connect the two containers and execute the above sql script to create the database and database tables.
1. Query the ip addresses of the two containers
[root@mycat ~]# docker inspect --format '{{ .NetworkSettings.IPAddress }}' spt1 | awk '{print "spt1:",$1}' && docker inspect --format '{{ .NetworkSettings.IPAddress }}' spt2 | awk '{print "spt2:",$1}'
spt1: 172.17.0.2
spt2: 172.17.0.3
[root@mycat ~]#
2. Connect to the container spt1 and execute the database script
[root@mycat ~]# mysql -uroot -proot -h172.17.0.2 -P 3306
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MySQL connection id is 2
Server version: 5.7.34 MySQL Community Server (GPL)
Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MySQL [(none)]> /* Create database */
MySQL [(none)]> CREATE DATABASE boos;
Query OK, 1 row affected (0.00 sec)
MySQL [(none)]>
MySQL [(none)]> USE boos;
phone varchar(500) DEFAULT NULL COMMENT 'Telephone number',
provice varchar(500) DEFAULT NULL COMMENT 'Province',
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='Telecom customer information (mobile phone number)';
/* Phone number call record */
CREATE TABLE calllog (
id bigint(20) NOT NULL COMMENT 'id',
phone_id bigint(20) DEFAULT NULL COMMENT 'Customer mobile number foreign key',
type varchar(10) DEFAULT NULL COMMENT 'Call type',
duration bigint(20) DEFAULT NULL COMMENT 'Call duration (seconds)',
othernum varchar(20) DEFAULT NULL COMMENT 'Opposite telephone number',
PRIMARY KEY (id),
KEY FK_Reference_1 (phone_id),
CONSTRAINT FK_Reference_1 FOREIGN KEY (phone_id) REFERENCES customer (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='Call log';
/* Dictionary table */
CREATE TABLE dict (
id bigint(20) NOT NULL COMMENT 'id',
caption varchar(100) DEFAULT NULL COMMENT 'Code type name',
code varchar(10) DEFAULT NULL COMMENT 'code',
name varchar(10) DEFAULT NULL COMMENT 'name',
PRIMARY KEY (id)
) ENGINE=InnoDB DEFDatabase changed
MySQL [boos]>
MySQL [boos]> /* Customer mobile phone number table */
MySQL [boos]> CREATE TABLE customer (
-> id bigint(20) NOT NULL COMMENT 'Primary key',
-> cid bigint(20) DEFAULT NULL COMMENT 'customer id',
-> name varchar(500) DEFAULT NULL COMMENT 'Customer name',
-> phone varchar(500) DEFAULT NULL COMMENT 'Telephone number',
-> provice varchar(500) DEFAULT NULL COMMENT 'Province',
-> PRIMARY KEY (id)
-> ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='Telecom customer information (mobile phone number)';
AULT CHARSET=utf8mb4 COMMENT='Dictionary table';Query OK, 0 rows affected (0.04 sec)
MySQL [boos]>
MySQL [boos]>
MySQL [boos]> /* Phone number call record */
MySQL [boos]> CREATE TABLE calllog (
-> id bigint(20) NOT NULL COMMENT 'id',
-> phone_id bigint(20) DEFAULT NULL COMMENT 'Primary key',
-> type varchar(10) DEFAULT NULL COMMENT 'Call type',
-> duration bigint(20) DEFAULT NULL COMMENT 'Call duration (seconds)',
-> othernum varchar(20) DEFAULT NULL COMMENT 'Opposite telephone number',
-> PRIMARY KEY (id),
-> KEY FK_Reference_1 (phone_id),
-> CONSTRAINT FK_Reference_1 FOREIGN KEY (phone_id) REFERENCES customer (id)
-> ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='Call log';
Query OK, 0 rows affected (0.03 sec)
MySQL [boos]>
MySQL [boos]>
MySQL [boos]> /* Dictionary table */
MySQL [boos]> CREATE TABLE dict (
-> id bigint(20) NOT NULL COMMENT 'id',
-> caption varchar(100) DEFAULT NULL COMMENT 'Code type name',
-> code varchar(10) DEFAULT NULL COMMENT 'code',
-> name varchar(10) DEFAULT NULL COMMENT 'name',
-> PRIMARY KEY (id)
-> ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='Dictionary table';
Query OK, 0 rows affected (0.02 sec)
MySQL [boos]> show tables;
+----------------+
| Tables_in_boos |
+----------------+
| calllog |
| customer |
| dict |
+----------------+
3 rows in set (0.00 sec)
MySQL [boos]>
3. Connect to the container spt1 and execute the database script
[root@mycat ~]# mysql -uroot -proot -h172.17.0.3 -P 3306
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MySQL connection id is 2
Server version: 5.7.34 MySQL Community Server (GPL)
Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MySQL [(none)]> /* Create database */
MySQL [(none)]> CREATE DATABASE boos;
Query OK, 1 row affected (0.00 sec)
MySQL [(none)]>
MySQL [(none)]> USE boos;
phone varchar(500) DEFAULT NULL COMMENT 'Telephone number',
provice varchar(500) DEFAULT NULL COMMENT 'Province',
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='Telecom customer information (mobile phone number)';
/* Phone number call record */
CREATE TABLE calllog (
id bigint(20) NOT NULL COMMENT 'id',
phone_id bigint(20) DEFAULT NULL COMMENT 'Primary key',
type varchar(10) DEFAULT NULL COMMENT 'Call type',
duration bigint(20) DEFAULT NULL COMMENT 'Call duration (seconds)',
othernum varchar(20) DEFAULT NULL COMMENT 'Opposite telephone number',
PRIMARY KEY (id),
KEY FK_Reference_1 (phone_id),
CONSTRAINT FK_Reference_1 FOREIGN KEY (phone_id) REFERENCES customer (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='Call log';
/* Dictionary table */
CREATE TABLE dict (
id bigint(20) NOT NULL COMMENT 'id',
caption varchar(100) DEFAULT NULL COMMENT 'Code type name',
code varchar(10) DEFAULT NULL COMMENT 'code',
name varchar(10) DEFAULT NULL COMMENT 'name',
PRIMARY KEY (id)
) ENGINE=InnoDB DEFDatabase changed
MySQL [boos]>
MySQL [boos]> /* Customer mobile phone number table */
MySQL [boos]> CREATE TABLE customer (
-> id bigint(20) NOT NULL COMMENT 'Primary key',
-> cid bigint(20) DEFAULT NULL COMMENT 'customer id',
-> name varchar(500) DEFAULT NULL COMMENT 'Customer name',
-> phone varchar(500) DEFAULT NULL COMMENT 'Telephone number',
-> provice varchar(500) DEFAULT NULL COMMENT 'Province',
-> PRIMARY KEY (id)
-> ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='Telecom customer information (mobile phone number)';
AULT CHARSET=utf8mb4 COMMENT='Dictionary table';Query OK, 0 rows affected (0.04 sec)
MySQL [boos]>
MySQL [boos]>
MySQL [boos]> /* Phone number call record */
MySQL [boos]> CREATE TABLE calllog (
-> id bigint(20) NOT NULL COMMENT 'id',
-> phone_id bigint(20) DEFAULT NULL COMMENT 'Primary key',
-> type varchar(10) DEFAULT NULL COMMENT 'Call type',
-> duration bigint(20) DEFAULT NULL COMMENT 'Call duration (seconds)',
-> othernum varchar(20) DEFAULT NULL COMMENT 'Opposite telephone number',
-> PRIMARY KEY (id),
-> KEY FK_Reference_1 (phone_id),
-> CONSTRAINT FK_Reference_1 FOREIGN KEY (phone_id) REFERENCES customer (id)
-> ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='Call log';
Query OK, 0 rows affected (0.03 sec)
MySQL [boos]>
MySQL [boos]>
MySQL [boos]> /* Dictionary table */
MySQL [boos]> CREATE TABLE dict (
-> id bigint(20) NOT NULL COMMENT 'id',
-> caption varchar(100) DEFAULT NULL COMMENT 'Code type name',
-> code varchar(10) DEFAULT NULL COMMENT 'code',
-> name varchar(10) DEFAULT NULL COMMENT 'name',
-> PRIMARY KEY (id)
-> ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='Dictionary table';
Query OK, 0 rows affected (0.02 sec)
MySQL [boos]> show tables;
+----------------+
| Tables_in_boos |
+----------------+
| calllog |
| customer |
| dict |
+----------------+
3 rows in set (0.00 sec)
MySQL [boos]>
mycat implements sub table
According to the requirements, customer s need to be split horizontally and distributed to two data nodes spt1 and spt2. The following modifications are required
1. Modify schema xml
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="spt1">
<!--
rule="customer_rule" The fragmentation rules used need to be in rule.xml Medium configuration
-->
<table name="customer " dataNode="spt1,spt2" rule="customer_rule" ></table>
</schema>
<dataNode name="spt1" dataHost="host1" database="boos"/>
<dataNode name="spt2" dataHost="host2" database="boos"/>
<dataHost name="host1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1"
slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM1" url="172.17.0.2:3306" user="root" password="root">
</writeHost>
</dataHost>
<dataHost name="host2" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1"
slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM2" url="172.17.0.3:3306" user="root" password="root">
</writeHost>
</dataHost>
</mycat:schema>
2. Modify rule XML configuration customer_rule rule
Add segmentation rule customer in rule configuration file_ Rule, and specify that the applicable field of the rule is cid,
<tableRule name="customer_rule">
<rule>
<!-- Slice field-->
<columns>cid</columns>
<!-- Partition algorithm name -->
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
In addition, select the partition algorithm mod long (modulo operation on the field), cid modulo the two nodes, and partition according to the result
Configure the algorithm mod long parameter count to 2, two nodes
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<!-- how many data nodes -->
<property name="count">2</property>
</function>
Complete rule after configuration The XML is as follows
<?xml version="1.0" encoding="UTF-8"?>
<!-- - - Licensed under the Apache License, Version 2.0 (the "License");
- you may not use this file except in compliance with the License. - You
may obtain a copy of the License at - - http://www.apache.org/licenses/LICENSE-2.0
- - Unless required by applicable law or agreed to in writing, software -
distributed under the License is distributed on an "AS IS" BASIS, - WITHOUT
WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. - See the
License for the specific language governing permissions and - limitations
under the License. -->
<!DOCTYPE mycat:rule SYSTEM "rule.dtd">
<mycat:rule xmlns:mycat="http://io.mycat/">
<tableRule name="customer_rule">
<rule>
<columns>cid</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<tableRule name="rule1">
<rule>
<columns>id</columns>
<algorithm>func1</algorithm>
</rule>
</tableRule>
<tableRule name="rule2">
<rule>
<columns>user_id</columns>
<algorithm>func1</algorithm>
</rule>
</tableRule>
<tableRule name="sharding-by-intfile">
<rule>
<columns>sharding_id</columns>
<algorithm>hash-int</algorithm>
</rule>
</tableRule>
<tableRule name="auto-sharding-long">
<rule>
<columns>id</columns>
<algorithm>rang-long</algorithm>
</rule>
</tableRule>
<tableRule name="mod-long">
<rule>
<columns>id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<tableRule name="sharding-by-murmur">
<rule>
<columns>id</columns>
<algorithm>murmur</algorithm>
</rule>
</tableRule>
<tableRule name="crc32slot">
<rule>
<columns>id</columns>
<algorithm>crc32slot</algorithm>
</rule>
</tableRule>
<tableRule name="sharding-by-month">
<rule>
<columns>create_time</columns>
<algorithm>partbymonth</algorithm>
</rule>
</tableRule>
<tableRule name="latest-month-calldate">
<rule>
<columns>calldate</columns>
<algorithm>latestMonth</algorithm>
</rule>
</tableRule>
<tableRule name="auto-sharding-rang-mod">
<rule>
<columns>id</columns>
<algorithm>rang-mod</algorithm>
</rule>
</tableRule>
<tableRule name="jch">
<rule>
<columns>id</columns>
<algorithm>jump-consistent-hash</algorithm>
</rule>
</tableRule>
<function name="murmur"
class="io.mycat.route.function.PartitionByMurmurHash">
<property name="seed">0</property><!-- The default is 0 -->
<property name="count">2</property><!-- The number of database nodes to be partitioned must be specified, otherwise it cannot be partitioned -->
<property name="virtualBucketTimes">160</property><!-- An actual database node is mapped to so many virtual nodes. The default is 160 times, that is, the number of virtual nodes is 160 times that of physical nodes -->
<!-- <property name="weightMapFile">weightMapFile</property> The weight of a node. The default value of a node without a specified weight is 1. with properties Fill in the format of the file, starting from 0 to count-1 The integer value of, that is, the node index is key,Take the node weight value as the value. Ownership multiplicity must be a positive integer, otherwise it is replaced by 1 -->
<!-- <property name="bucketMapPath">/etc/mycat/bucketMapPath</property>
It is used to observe the distribution of each physical node and virtual node during testing. If this attribute is specified, the virtual node's murmur hash The mapping between value and physical node is output to this file by line. There is no default value. If it is not specified, nothing will be output -->
</function>
<function name="crc32slot"
class="io.mycat.route.function.PartitionByCRC32PreSlot">
<property name="count">2</property><!-- The number of database nodes to be partitioned must be specified, otherwise it cannot be partitioned -->
</function>
<function name="hash-int"
class="io.mycat.route.function.PartitionByFileMap">
<property name="mapFile">partition-hash-int.txt</property>
</function>
<function name="rang-long"
class="io.mycat.route.function.AutoPartitionByLong">
<property name="mapFile">autopartition-long.txt</property>
</function>
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<!-- how many data nodes -->
<property name="count">2</property>
</function>
<function name="func1" class="io.mycat.route.function.PartitionByLong">
<property name="partitionCount">8</property>
<property name="partitionLength">128</property>
</function>
<function name="latestMonth"
class="io.mycat.route.function.LatestMonthPartion">
<property name="splitOneDay">24</property>
</function>
<function name="partbymonth"
class="io.mycat.route.function.PartitionByMonth">
<property name="dateFormat">yyyy-MM-dd</property>
<property name="sBeginDate">2015-01-01</property>
</function>
<function name="rang-mod" class="io.mycat.route.function.PartitionByRangeMod">
<property name="mapFile">partition-range-mod.txt</property>
</function>
<function name="jump-consistent-hash" class="io.mycat.route.function.PartitionByJumpConsistentHash">
<property name="totalBuckets">3</property>
</function>
</mycat:rule>
Start Mycat, log in to Mycat and insert data for verification
insert into customer (id, cid, name, phone, provice) values('1','1','Fei Zhang','13800000001','Yan people');
insert into customer (id, cid, name, phone, provice) values('2','2','Zhao Yun','13800000002','Really');
insert into customer (id, cid, name, phone, provice) values('3','3','Zhuge Liang','13800000003','Yinan');
insert into customer (id, cid, name, phone, provice) values('4','4','Guan Yu','13800000004','Yuncheng');
insert into customer (id, cid, name, phone, provice) values('5','5','xuande ','13800000005','Zhuozhou');
insert into customer (id, cid, name, phone, provice) values('6','6','Sun CE','13800000006','Soochow');
After inserting data, query and discovery are performed on Mycat client and data nodes spt1 and sp2 respectively
- The data nodes spt1 and spt2 store part of the data respectively
- mycat client can query all data
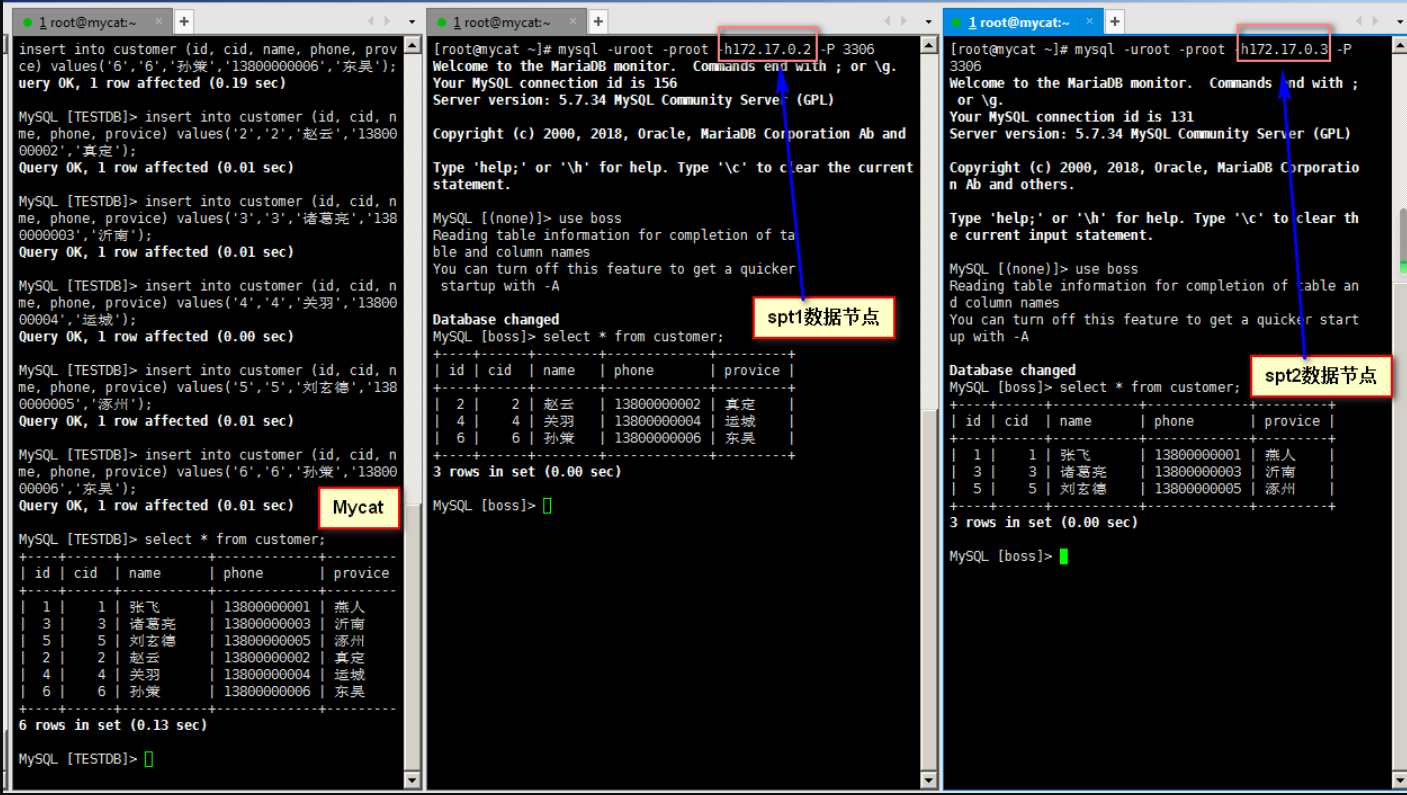
It should be noted that when mycat is inserted, it is segmented according to the field, and field enumeration needs to be provided
Insert sql correctly
Insert into customer (ID, CID, name, phone, offer) values ('5 ',' 5 ',' Liu Xuande ',' 13800000005 ',' Zhuozhou ');
Bad sql
insert into customer values('6','6 ',' sun CE ',' 13800000006 ',' Soochow ');
Enumerations that do not provide columns will report the following error:
MySQL [TESTDB]> insert into customer values('6','6','Sun CE','13800000006','Soochow');
ERROR 1064 (HY000): partition table, insert must provide ColumnList
Fragment join of Mycat
Join is definitely the most commonly used feature in relational database. However, in distributed environment, cross slice join is the most complex and difficult problem to solve.
Mycat performance recommendations
Try to avoid using Left join or Right join and use Inner join instead
When using Left join or Right join, ON will be executed first, and the where condition will be executed last. Therefore, during the use process, the condition shall be executed as much as possible
If possible, judge in the ON statement to reduce the execution of where
Use fewer subqueries and join instead.
The current version of Mycat supports cross slice join. There are four main implementation methods.
Global table, ER sharding, cattlett (Artificial Intelligence) and ShareJoin are supported in the development version. The first three methods are supported in 1.3.0.1.
ER slice
MyCAT draws lessons from the design idea of foundation dB, a rookie in the field of NewSQL. Foundation DB creatively puts forward the concept of TableGroup, which relies on the storage location of sub tables on the main table and is physically adjacent to each other. Therefore, it completely solves the efficiency and performance problems of Jian. According to this idea, a data fragmentation strategy based on E-R relationship is proposed, The records of the child table are stored on the same data slice as the associated parent table records.
Customer (customer mobile account table) adopts the segmentation strategy of taking module according to customer ID. the segmentation is on SPT1 and spt2. Call log (call record table) depends on the parent table for segmentation. The association relationship between the two tables is customer id =calllog. phone_ id. The schematic diagram of data fragmentation and storage is as follows:

In this way, customer s on spt1 and callog on spt1 can JOIN locally, and so can spt2(... sptn). The overall JOIN can be completed by merging the data of two nodes. The data fragmentation mode based on E-R mapping basically solves the problems faced by more than 80% of enterprise applications.
realization
Modify schema XML file, modify the table tag based on the last configuration, and add a sub tag under the customer table
<childTable name="calllog" primaryKey="id" joinKey="id" parentKey="phone_id" />
Complete schema The XML file is as follows:
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="spt1">
<!--
rule="customer_rule" Custom fragmentation rules need to be defined in rule.xml Medium configuration
-->
<table name="customer" dataNode="spt1,spt2" rule="customer_rule" >
<!--
name="calllog" Child table (slave table) name
primaryKey="id" Child table (slave table) primary key
joinKey="id" Primary table primary key( customer.id)
parentKey="phone_id" Foreign keys recorded from table( calllog.phone_id)
-->
<childTable name="calllog" primaryKey="id" joinKey="id" parentKey="phone_id" />
</table>
</schema>
<dataNode name="spt1" dataHost="host1" database="boss"/>
<dataNode name="spt2" dataHost="host2" database="boss"/>
<dataHost name="host1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1"
slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM1" url="172.17.0.2:3306" user="root" password="root">
</writeHost>
</dataHost>
<dataHost name="host2" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1"
slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM2" url="172.17.0.3:3306" user="root" password="root">
</writeHost>
</dataHost>
</mycat:schema>
Restart mycat (load configuration), log in to mycat and insert data
insert into calllog (id, phone_id, type, duration, othernum) values('1','1','01','77','15800000001');
insert into calllog (id, phone_id, type, duration, othernum) values('2','1','02','45','15800000002');
insert into calllog (id, phone_id, type, duration, othernum) values('3','2','01','38','15800000003');
insert into calllog (id, phone_id, type, duration, othernum) values('4','2','02','64','15800000004');
insert into calllog (id, phone_id, type, duration, othernum) values('5','3','01','57','15800000005');
insert into calllog (id, phone_id, type, duration, othernum) values('6','3','02','88','15800000006');
insert into calllog (id, phone_id, type, duration, othernum) values('7','4','01','88','15800000007');
insert into calllog (id, phone_id, type, duration, othernum) values('8','4','02','69','15800000008');
insert into calllog (id, phone_id, type, duration, othernum) values('9','5','01','23','15800000009');
insert into calllog (id, phone_id, type, duration, othernum) values('10','5','02','46','15800000010');
insert into calllog (id, phone_id, type, duration, othernum) values('11','6','01','45','15800000011');
insert into calllog (id, phone_id, type, duration, othernum) values('12','6','02','77','15800000012');
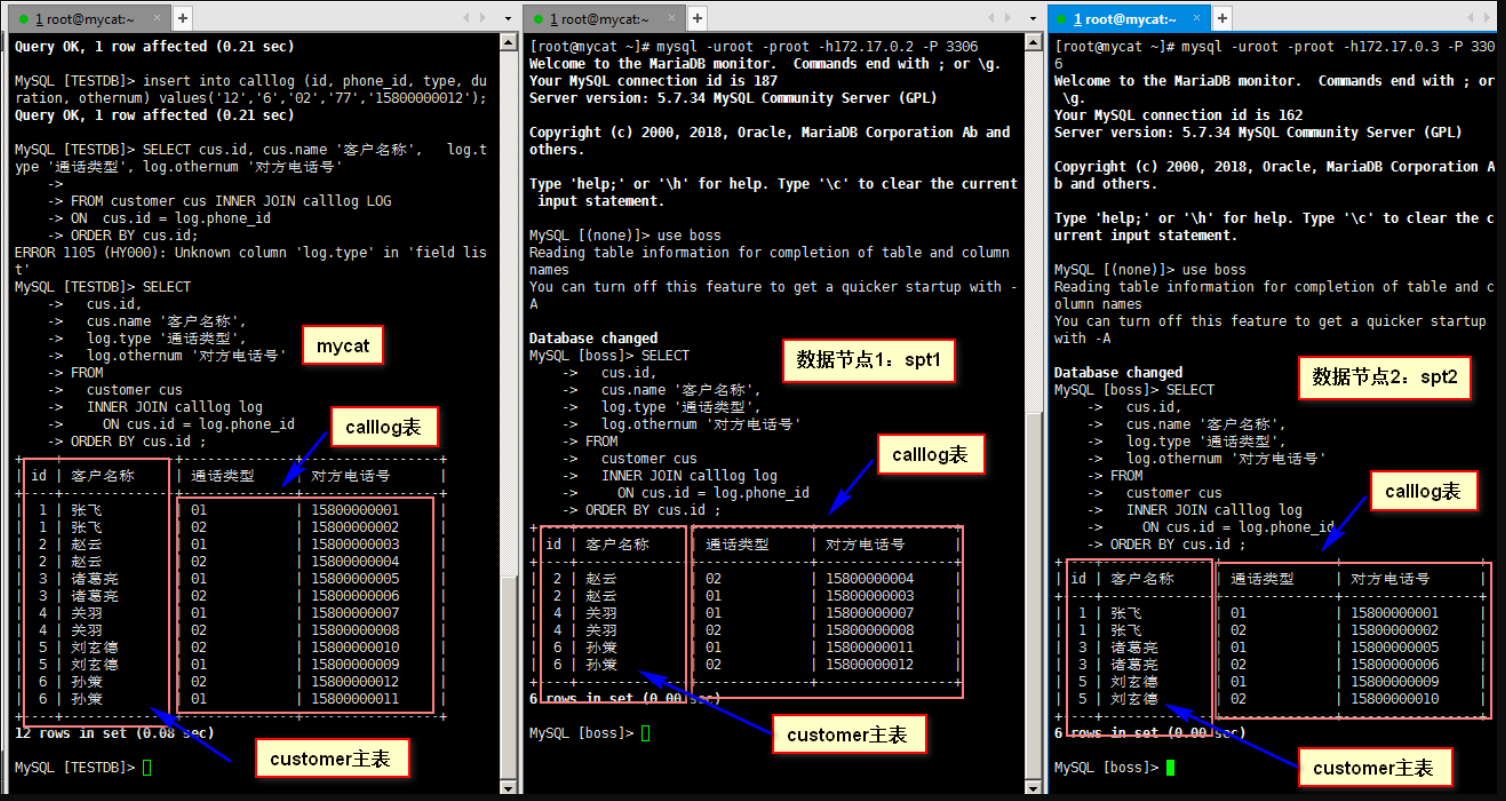
Use join query on mycat, data nodes spt1 and spt2 respectively
SELECT
cus.id,
cus.name 'Customer name',
log.type 'Call type',
log.othernum 'Opposite telephone number'
FROM
customer cus
INNER JOIN calllog log
ON cus.id = log.phone_id
ORDER BY cus.id ;
Global table
introduce
The previous chapters have realized the horizontal division of tables (sub tables). There is also a dict (dictionary table) in the above table, which stores some data dictionaries commonly used in the system, such as codes representing call types (01: incoming call, 02: outgoing call). If this table is alone on a data node (e.g. spt1), the data on another data node (e.g. spt2) cannot be associated and queried
In a real business system, there are often a large number of tables similar to dictionary tables, which are basically rarely changed. Dictionary tables have the following characteristics:
• infrequent changes;
• the overall amount of data changes little;
• the data scale is small, and there are few more than hundreds of thousands of records.
For this kind of table, in the case of fragmentation, when the business table is fragmented due to its size, the association between the business table and these auxiliary dictionary tables becomes a thorny problem. Therefore, Mycat solves the join of this kind of table through data redundancy, that is, all partitions have a copy of data, All dictionary tables or some tables that conform to the characteristics of dictionary tables are defined as global tables.
Data redundancy is a good idea to solve cross slice data join, and it is also another important rule of data segmentation planning.
realization
Modify schema XML configuration file, add the table node and set it to global type
<table name="dict" dataNode="spt1,spt2" type="global" ></table>
The full configuration file is as follows:
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="spt1">
<!--
rule="customer_rule" Custom fragmentation rules need to be defined in rule.xml Medium configuration
-->
<table name="customer" dataNode="spt1,spt2" rule="customer_rule" >
<!--
name="calllog" Child table (slave table) name
primaryKey="id" Child table (slave table) primary key
joinKey="phone_id" Foreign keys recorded from table( calllog.phone_id)
parentKey="id" Primary table primary key( customer.id)
-->
<childTable name="calllog" primaryKey="id" joinKey="phone_id" parentKey="id" />
</table>
<!--
set up dict Table is global Global table, and in spt1,spt2 Redundancy (duplicate content) of two data nodes exists
-->
<table name="dict" dataNode="spt1,spt2" type="global" ></table>
</schema>
<dataNode name="spt1" dataHost="host1" database="boss"/>
<dataNode name="spt2" dataHost="host2" database="boss"/>
<dataHost name="host1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1"
slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM1" url="172.17.0.2:3306" user="root" password="root">
</writeHost>
</dataHost>
<dataHost name="host2" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1"
slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM2" url="172.17.0.3:3306" user="root" password="root">
</writeHost>
</dataHost>
</mycat:schema>
Validate global tables
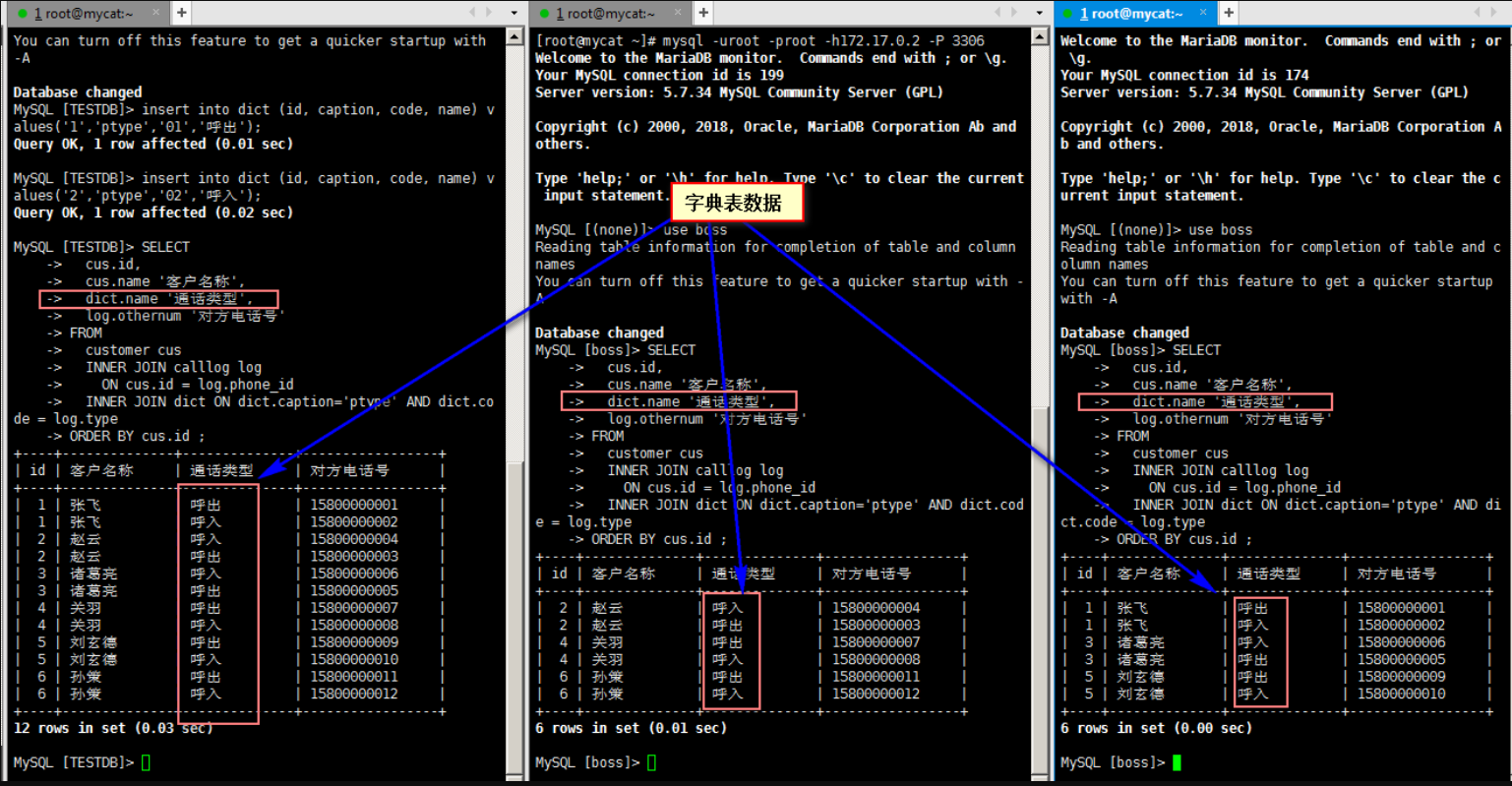
Log in to mycat to insert the data in the dictionary table
insert into dict (id, caption, code, name) values('1','ptype','01','exhale');
insert into dict (id, caption, code, name) values('2','ptype','02','Incoming call');
Query the sql of the associated dict table in the mycat client and data nodes spt1 and spt2 respectively
SELECT
cus.id,
cus.name 'Customer name',
dict.name 'Call type',
log.othernum 'Opposite telephone number'
FROM
customer cus
INNER JOIN calllog log
ON cus.id = log.phone_id
INNER JOIN dict ON dict.caption='ptype' AND dict.code = log.type
ORDER BY cus.id ;
Since the length is quite long, I will write a [simple use of Mycat (IV) [other segmentation rules] to continue the introduction
Copyright notice:
Original blogger: cattle roaring Conan
Blogger's original link: https://keafmd.blog.csdn.net/
After reading, if it helps you, thank you for your praise and support!
If you are a computer terminal, do you see the "one key three links" in the lower right corner? Yes, click it [HA HA]

come on.
make joint efforts!
Keafmd