You can also use my independent blog—— www.huliujia.com Get this article
Array and linked list
Array and linked list are two very basic data structures. Each search of linked list needs to traverse linearly from the beginning of the node, and the time complexity is O(n). The array can use binary search by maintaining the element order, and the time complexity of search is O(lg(n)). In terms of search efficiency, the array wins the linked list.
However, because all affected nodes must be moved when inserting or deleting elements in the array, the time complexity is O(n) And the length of the array is fixed. When there is not enough space, you need to reallocate memory. The insertion and deletion of elements in the linked list only need to change a few pointers, and the time complexity is O(1). However, because half of the insertion and deletion need to find elements first, the insertion and deletion time complexity of the linked list is O(n).
Today, we introduce a data structure based on linked list - skip list. While maintaining the characteristics of easy insertion and deletion of linked list, we can reduce the time complexity of search, insertion and deletion to O(lg(n)).
Principle of jump table
The array can realize the search time complexity O(lg(n)), mainly because the binary search can exclude half of the elements every time. Is there any way for the linked list to exclude half of the elements every time?
Obviously, the original linked list can only exclude one element (current element) at a time. If you want to exclude half of the elements, you need to meet two conditions. First, the linked list must be orderly, and then you can access the middle element. This is actually the principle of array binary search.
It is an easy requirement to make the linked list orderly, so how to access the middle element? We can use an external node to save the intermediate node.
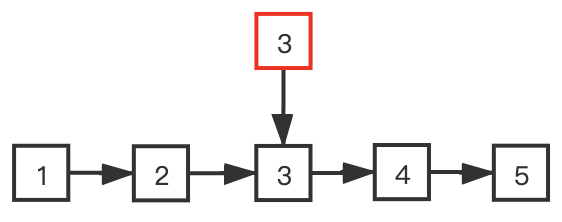
For example, the above figure is an ordered linked list with five elements. The red element 3 points to the middle element 3. If we want to find 4, it is easy to judge that the element to be found is on the right side of 3 by comparing with the middle element 3, then all nodes on the left side of 3 are excluded.
The above linked list has only 5 elements. What if the linked list has more elements, such as 8 elements? Obviously, an external node can only complete element exclusion once. If you want to exclude half of the elements every time, you need more external nodes.
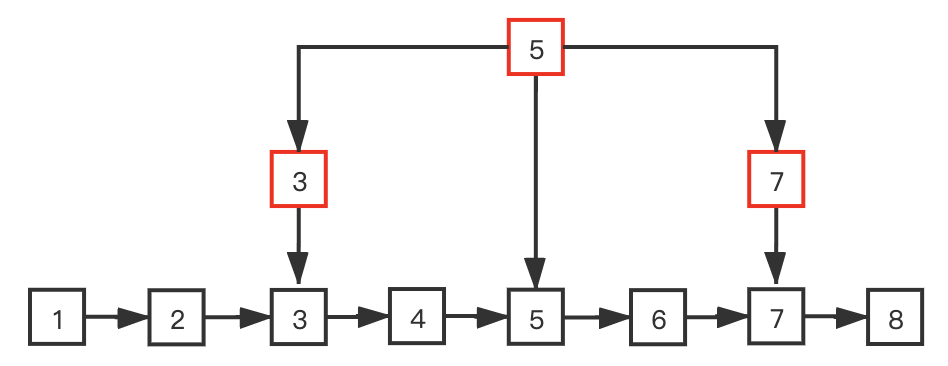
For example, there are 8 elements in the linked list above, and a total of 3 external nodes are used. The external nodes are divided into two layers. By comparing with the top external node element 5, we can exclude half of the elements, and the remaining elements can be compared with element 3 or element 7 to exclude another half of the elements.
Similarly, if there are more elements, you can use more external nodes and manage external nodes with more layers.
It can be seen that by adding external nodes, we can exclude half of the elements each time. Then, similar to binary search, we can finally realize the search time complexity of O(lg(n)).
Implementation of jump table
The above uses external nodes as an example to demonstrate the principle of jump table lookup acceleration, but if it is implemented directly in the above way, the management and lookup operations of external nodes are very complex and difficult to implement.
Therefore, in the actual implementation, the external nodes of each layer will also be managed in the way of orderly linked list, and a fake head node and tail node will be added to each linked list to facilitate the search and judgment of whether they have reached the tail of the linked list.
Finally, our jump table should be like this
[the external link image transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the image and upload it directly (img-eRW18yAr-1618188079241)(/images / jump table - Figure 3.png)]
You can see that the nodes of each layer become a linked list. The more you go to the upper layer, the fewer the elements of the linked list. The linked list of each layer contains the head node Hx and the tail node Tx.
So how many layers of linked lists are the most efficient? This depends on the number of elements in the lowest linked list. In order to realize the time complexity O(lg(n)). The number of elements in each layer of the linked list (excluding head and tail nodes) should be half of the number of elements in its lower layer, and the number of elements in the top layer of the linked list should be 1. Then it is easy to calculate that the best number of layers is lg(N), and N is the number of elements at the bottom of the list, that is, the actual number of elements in the list. For example, if there are 8 nodes, the number of layers should be lg(8) = 3;
Find element
When searching, take the top-level head node H2 node as the starting point, compare the size of the searched element X and the right element Y, and decide whether to return Y (X == Y), continue the search on the left side of Y (x < y), or search on the right side of Y (x > y). Repeat this process until x is found or it is determined that X does not exist.
Assuming X=4, the first step is to compare elements 5 on the right side of X and H2, where x < 5. Therefore, search on the left side of 5 and switch to the next layer. The starting point changes from H2 to H1. Compare elements 3 on the right side of X and H1, where x > 3. Therefore, search on the right side of 3 and switch to the next layer. The starting point changes from H1 to element 3. Compare elements 5 on the right side of X and element 3. X < 5, so search on the left side of element 5, switch the starting point to element 3 of layer 0 (just element 3 of layer 1), compare element 4 on the right side of X and 3, X==4, and find X.
What if X=4.5? Obviously, the previous process is the same as when X=4, but when the starting point is switched to element 3 on layer 0, compare element 4 on the right of X and 3 and find that x > 4. Since it is already on layer 0 and cannot continue to search, it can be judged that element X=4.5 does not exist.
Insert element
When inserting elements, first determine the insertion position, and then modify the pointers before and after. However, there is a problem. When more and more elements are inserted, it is obvious that the upper linked list can no longer be evenly divided, and the efficiency of search will be reduced.
Can the upper linked list be reorganized at each insertion so that the upper linked list elements can evenly split the lower linked list? The answer is obviously no, because the time complexity of each insertion becomes O(n). Jump table is also often called probability based data structure. The so-called probability based data structure is involved here.
Simply put, let the number of elements in the linked list of each layer be 1 / 2 of the number of elements in the lower layer by means of probability, as long as each node of layer N has a 1 / 2 probability of entering layer N+1. When the number of elements is enough, the linked list elements of layer N+1 can divide the elements of layer n approximately evenly.
When inserting a new element, we first insert the element into the lowest layer, that is, layer 0, and then let it enter layer 1 with a half probability (for example, through random numbers). If it enters layer 1, then let it enter layer 2 with a half probability, and so on. If the current layer is already the highest level allowed, stop at the current layer.
In actual implementation, the highest layer of this element is calculated based on probability. For example, when the element is highest to layer M, the element is inserted into each layer between layer 0 and layer M (including layer M).
Delete element
Deleting an element is relatively simple. After finding the element, delete the node of the element in each layer. Because the probability of each element in the nth layer is the same, the distribution probability of multi-layer linked list will not be affected when deleting elements.
code implementation
During the actual code implementation, in order to improve the performance and reduce the storage overhead, multi-layer linked lists will not be really created. Each element will actually have only one node. In addition to saving the value of the element, the node also has A pointer array next, which is used to save the linked list relationship of elements in different layers. next[i] points to the element on the right side of layer I. If next[i] is empty, it indicates that there is no current element in layer I. If next[i] points to element A, it means that the current element is on the right side of layer I, and the element is A. The specific code is as follows:
#include <stdio.h>
#include <cstring>
#include <random>
#include <vector>
const int kMaxLevelNum = 12;
struct Node
{
int value_;
Node *next_[kMaxLevelNum];
};
class Skiplist
{
public:
Skiplist()
{
//Each layer creates a head and tail node
head_ = new Node();
head_->value_ = -1;
auto *tail = new Node();
tail->value_ = 1;
memset(tail->next_, 0, kMaxLevelNum * sizeof(void *));
for (int i = 0; i < kMaxLevelNum; i++)
{
head_->next_[i] = tail;
}
}
bool search(int target)
{
Node *prev[kMaxLevelNum];
//FindEqual finds the target node and saves the front node of each layer
return FindEqual(target, prev) != nullptr;
}
void add(int num)
{
Node *prev[kMaxLevelNum];
//Findgreateroequal will find the smallest node greater than or equal to the target value and save the front node of each layer
Node *ge_node = FindGreaterOrEqual(num, prev);
Node *node = new Node();
node->value_ = num;
int height = RandomHeight();
for (int i = 0; i < height; i++)
{
node->next_[i] = prev[i]->next_[i];
prev[i]->next_[i] = node;
}
}
bool erase(int num)
{
Node *prev[kMaxLevelNum];
//Find before delete
auto *ge_node = FindEqual(num, prev);
if (ge_node == nullptr)
{
return false;
}
for (int i = 0; i < kMaxLevelNum; i++)
{
if (ge_node->next_[i] == nullptr)
{
break;
}
prev[i]->next_[i] = ge_node->next_[i];
ge_node->next_[i] = prev[i];
}
delete ge_node;
return true;
}
//Layering the current jump table is mainly to visualize the output, and does not involve the insertion, deletion and search of the jump table.
void PrintAll()
{
auto* cur_node = head_->next_[0];
int counter = 1;
std::vector<Node*> node_list;
std::string debug_str[kMaxLevelNum];
for(int i=0; i<kMaxLevelNum; i++)
{
debug_str[i] += "|";
}
printf("%p, ",head_);
while (cur_node->next_[0] != nullptr)
{
char buf[100];
sprintf(buf, "%-2d", cur_node->value_);
debug_str[0] += " -> ";
debug_str[0] += buf;
node_list.emplace_back(cur_node);
printf("%p, ",cur_node);
cur_node = cur_node->next_[0];
}
printf("%p, ",cur_node);
printf("\n");
debug_str[0] += "-> |";
cur_node = head_;
for(int i=1; i<kMaxLevelNum; i++)
{
debug_str[i] = "|";
auto* cur_left_node = head_;
for(auto* node: node_list)
{
printf("node: %p, left: %p, left->next[i]: %p\n", node, cur_left_node, cur_left_node->next_[i]);
printf("node: %d, left: %d\n", node->value_, cur_left_node->next_[i]->value_);
if(node == cur_left_node->next_[i])
{
printf("true\n");
char buf[100];
sprintf(buf, "%-2d", node->value_);
debug_str[i] += " -> ";
debug_str[i] += buf;
cur_left_node = node;
}else
{
printf("false\n");
debug_str[i] += "------";
}
}
debug_str[i] += "-> |";
}
for(int i=kMaxLevelNum-1; i>=0; i--)
{
printf("level: %d: %s\n", i, debug_str[i].c_str());
}
printf("\n");
}
private:
Node *head_;
int cur_max_level_ = 0;
int RandomHeight()
{
static std::mt19937 mt_rand(0);
int height = 1;
while (height < kMaxLevelNum and mt_rand() & 0x1)
{
height++;
}
return height;
}
Node *FindEqual(int target, Node **prev)
{
Node *ge_node = FindGreaterOrEqual(target, prev);
if (ge_node->next_[0] != nullptr and ge_node->value_ == target)
{
return ge_node;
}else
{
return nullptr;
}
}
//The return value should be the smallest number larger than the key. prev is an array with the length of kMaxHeight, which holds the pointer of the number smaller than the key in each layer. Finally, use this pointer to embed the current key.
Node *FindGreaterOrEqual(int target, Node **prev)
{
int level = kMaxLevelNum - 1;
Node *cur_node = head_;
while (true)
{
auto *next = cur_node->next_[level];
if (next == nullptr) // right edge
{
return cur_node;
}else if (next->next_[level] == nullptr or next->value_ >= target)
{
//right node is right edge or is larger
if (level == 0)
{
prev[level] = cur_node;
return next;
}else
{
prev[level] = cur_node;
level--;
}
}else //(next->value_ < target)
{
cur_node = next;
}
}
}
};
int main()
{
auto *obj = new Skiplist();
const char *name[3];
name[0] = "add";
name[1] = "erase";
name[2] = "search";
obj->PrintAll();
for (int i = 0; i < 30; i++)
{
int which = rand() % 3;
int num = rand() % 100;
printf("i:%d, %s(%d)\n", i, name[which], num);
switch (which)
{
case 0:
obj->add(num);
break;
case 1:
obj->erase(num);
break;
case 2:
obj->search(num);
break;
default:
break;
}
}
obj->PrintAll();
return 0;
}