Task07
This study refers to the Datawhale open source learning: https://github.com/datawhalechina/machine-learning-toy-code/tree/main/ml-with-sklearn
The content is arranged as follows, mainly some code implementation and some principles.
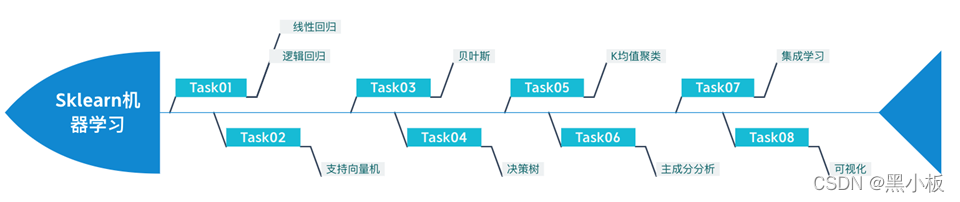
7. Integrated Learning
In the previous chapter, we talked about the decline in the effect of the dimension disaster mapping model. In addition to using the dimension reduction method, there is also a subspace method commonly used to deal with such high-dimensional problems. Integration is one of the common methods in subspace thinking, which combines the outputs of several algorithms or base detectors that perform well in subspace. Integrated learning accomplishes learning tasks by building and combining multiple learners, sometimes referred to as multi-classifier systems. The general strategy of integrated learning is to produce a set of "individual learners" and then combine them with a certain strategy.
The simplest method of integration is voting. Voting method is an integrated learning model that follows the principle of minority obeying majority, and reduces variance through the integration of multiple models, thereby improving the robustness of the model. Ideally, the voting method should be better than any base model.
Voting methods can be used in both regression and classification models:
- Regression voting: The predictions are the average of all model predictions.
- Classified voting: The predicted results are those that appear most frequently for all model types.
Classified voting can also be divided into hard and soft votes:
- Hard votes: The class with the most predicted results for all votes.
- Soft votes: The predicted result is the class with the highest probability of summing all the voting results.
7.1. Bagging
Unlike voting, Bagging not only integrates the final predictions of the model, but also uses strategies to influence the training of the base model.
At the heart of Bagging is the concept of bootstrap, where there is a playback to sample from a dataset, that is, the same sample may be sampled multiple times. First we randomly take a sample and put it into the sample set. Then we put the sample back into the initial data set and repeat the sample K times. Finally we can get a sample set of K size. In the same way, we can sample T sample sets with K samples and then train a base learner based on each sample set, a total of T learners. Combining these basic learners is the basic process of Bagging.
Sklearn provides us with an API for two Bagging methods, Bagging Regressor and Bagging Classifier. Explain the application with two official examples:
'''BaggingRegressor''' from sklearn.svm import SVR from sklearn.ensemble import BaggingRegressor from sklearn.datasets import make_regression X, y = make_regression(n_samples=100, n_features=4,n_informative=2, n_targets=1,random_state=0, shuffle=False) # Generate data regr = BaggingRegressor(base_estimator=SVR(),n_estimators=10, random_state=0).fit(X, y) # Select ten SVR models as base models regr.predict([[0, 0, 0, 0]])
array([-2.87202411])
'''BaggingClassifier''' from sklearn.svm import SVC from sklearn.ensemble import BaggingClassifier from sklearn.datasets import make_classification X, y = make_classification(n_samples=100, n_features=4,n_informative=2, n_redundant=0,random_state=0, shuffle=False)# Generate data clf = BaggingClassifier(base_estimator=SVC(),n_estimators=10, random_state=0).fit(X, y)# Select ten SVR models as base models clf.predict([[0, 0, 0, 0]])
array([1])
7.2. Boosting
Bagging reduces prediction error mainly by reducing variance. Boosting thought improves the ultimate predictive effect by continuously reducing bias. In other words, Bagging averages many strong classifiers, and Boosting combines many weak classifiers into one strong classifier.
Boosting first trains a base learner from the initial training set, then adjusts the training samples according to the performance of the base learner, so that the samples made by the previous base learner errors get more attention later, and then trains the next base learner based on the adjusted sample distribution. Repeat this until the number of base learners reaches the pre-specified value T, and finally the T base learners are weighted together.
Boosting has two common Boosting styles: Adaptive Boosting and Gradient Boosting, and their variants, Xgboost, LightGBM, and Catboost.
'''AdaBoostRegressor''' from sklearn.ensemble import AdaBoostRegressor from sklearn.datasets import make_regression X, y = make_regression(n_features=4, n_informative=2,random_state=0, shuffle=False) regr = AdaBoostRegressor(random_state=0, n_estimators=100)# Generate data regr.fit(X, y) AdaBoostRegressor(n_estimators=100, random_state=0)# Select 100 boosting base models regr.predict([[0, 0, 0, 0]])
array([4.79722349])
'''AdaBoostClassifier''' from sklearn.ensemble import AdaBoostClassifier from sklearn.datasets import make_classification X, y = make_classification(n_samples=1000, n_features=4,n_informative=2, n_redundant=0,random_state=0, shuffle=False)# Generate data clf = AdaBoostClassifier(n_estimators=100, random_state=0)# Select 100 boosting base models clf.fit(X, y) clf.predict([[0, 0, 0, 0]])
array([1])
7.3. Blending and Staking
Stacking is not strictly an algorithm, but a model integration strategy. Stacking integration algorithm can be understood as a two-tier integration. The first tier contains several basic classifiers, which provide the predicted results to the second tier. The second tier classifiers are usually logical regression. He uses the results of one tier classifiers as features to fit the output predicted results. Blending is essentially the same as Stacking, but with one less level of cross-validation, it can be considered a simplified version of Stacking.
'''Blending'''
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
data, target = make_blobs(n_samples=10000, centers=2, random_state=1, cluster_std=1.0 )
## Create training and test sets
X_train1,X_test,y_train1,y_test = train_test_split(data, target, test_size=0.2, random_state=1)
## Create training and validation sets
X_train,X_val,y_train,y_val = train_test_split(X_train1, y_train1, test_size=0.3, random_state=1)
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
# Setting the first layer classifier
clfs = [SVC(probability = True),RandomForestClassifier(n_estimators=5, n_jobs=-1, criterion='gini'),KNeighborsClassifier()]
# Setting the second layer classifier
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
# Output Layer 1 Verification Set Results and Test Set Results
val_features = np.zeros((X_val.shape[0],len(clfs))) # Construct validation data prediction matrix, store validation data prediction results for each model, each column being a validation set result for model initialization
test_features = np.zeros((X_test.shape[0],len(clfs))) # Construct test data prediction matrix, store test data prediction results for each model, each column being a model
for i,clf in enumerate(clfs):
clf.fit(X_train,y_train) # Training model
val_feature = clf.predict_proba(X_val)[:, 1] # Get the results of each base model in the validation set
test_feature = clf.predict_proba(X_test)[:,1] # Obtain the results of each base model in the test set
val_features[:,i] = val_feature # Record the results of each base model in the validation set
test_features[:,i] = test_feature # Record the results of each base model in the test set
# Enter the results of the first level validation set into the second level training second level classifier
lr.fit(val_features,y_val)
# Output Test Data Prediction Results
from sklearn.model_selection import cross_val_score
scores = cross_val_score(clf, X_test, y_test, cv=3, scoring='accuracy')
print(scores.mean())
1.0
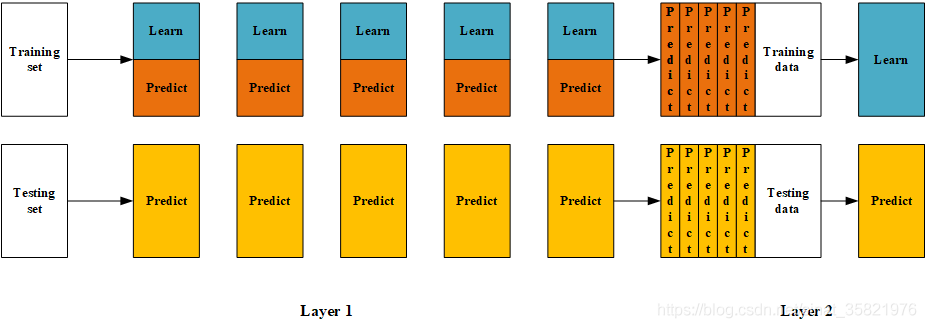
The Blending process can be represented by the following diagram, which combines code to understand the process:
'''Stacking'''
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
data, target = make_blobs(n_samples=10000, centers=2, random_state=1, cluster_std=1.0 )
## Create training and test sets
X_train1,X_test,y_train1,y_test = train_test_split(data, target, test_size=0.2, random_state=1)
# ## Create training and validation sets
# X_train,X_val,y_train,y_val = train_test_split(X_train1, y_train1, test_size=0.3, random_state=1)
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
# Setting the first layer classifier
clfs = [SVC(probability = True),RandomForestClassifier(n_estimators=5, n_jobs=-1, criterion='gini'),KNeighborsClassifier()]
# Setting the second layer classifier
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
# Output Layer 1 Verification Set Results and Test Set Results
val_features = np.zeros((X_train1.shape[0],len(clfs))) # Construct validation data prediction matrix, store validation data prediction results for each model, each column being a validation set result for model initialization
test_features = np.zeros((X_test.shape[0],len(clfs))) # Construct test data prediction matrix, store test data prediction results for each model, each column being a model
from sklearn.model_selection import StratifiedKFold
n_splits = 5
skf = StratifiedKFold(n_splits)
skf = skf.split(X_train1,y_train1) #Divide training data into 5 folds
for j, clf in enumerate(clfs): # Jth Model
#Train each single model in turn
test_features_j = np.zeros((X_test.shape[0], 5)) # Construct validation data prediction matrix (each fold), store validation data single model prediction results for each fold, and validation data training model for each column
for i, (train, val) in enumerate(skf): # i-fold, 5-fold total
#5-Fold cross-training uses part i I as the prediction, and the rest to train the model to obtain its predicted output as the new feature of part i I.
X_train, y_train, X_val, y_val = X_train1[train], y_train1[train], X_train1[val], y_train1[val] # Divide training data into training data and validation data, 5 fold cross validation
clf.fit(X_train, y_train) # Training model
y_submission = clf.predict(X_val) # Prediction validation data. Record prediction type in y_submission
val_features[val, j] = y_submission # The predicted results of the j th model fold i validation data (validation data comes from training data, which accounts for 1/5 of training data) are put into the training model prediction matrix according to the index of the 5-fold split
test_features_j[:, i] = clf.predict(X_test) # Place the predicted results of the j th model fold i test data into the fold test data prediction matrix
# Enter the results of the first level validation set into the second level training second level classifier
lr.fit(val_features,y_train1)
# Output Test Data Prediction Results
from sklearn.model_selection import cross_val_score
scores = cross_val_score(clf, X_test, y_test, cv=3, scoring='accuracy')
print(scores.mean())
1.0
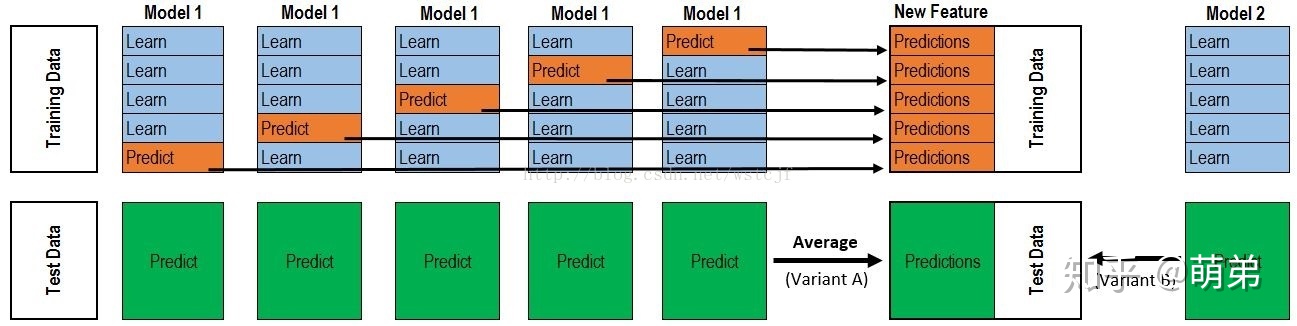
The Stacking process can be represented in the following diagram, which combines code to understand the process:
In addition, we can implement the stacking model directly with the mlxtend toolkit (pip install mlxtend).
'''Stacking(Use mlxtedn Toolkit implementation)'''
from sklearn.datasets import make_blobs
from sklearn.model_selection import train_test_split
data, target = make_blobs(n_samples=10000, centers=2, random_state=1, cluster_std=1.0 )
## Create training and test sets
X_train1,X_test,y_train1,y_test = train_test_split(data, target, test_size=0.2, random_state=1)
# ## Create training and validation sets
# X_train,X_val,y_train,y_val = train_test_split(X_train1, y_train1, test_size=0.3, random_state=1)
from mlxtend.classifier import StackingCVClassifier
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
# Setting the first layer classifier
clfs = [SVC(probability = True),RandomForestClassifier(n_estimators=5, n_jobs=-1, criterion='gini'),KNeighborsClassifier()]
# Setting the second layer classifier
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
sclf = StackingCVClassifier(classifiers=clfs, # Layer 1 Classifier
meta_classifier=lr, # Layer 2 Classifier
random_state=42)
# Output Test Data Prediction Results
from sklearn.model_selection import cross_val_score
scores = cross_val_score(clfs[0], X_test, y_test, cv=3, scoring='accuracy')
print(scores.mean())
1.0