0x00 preparation
- Make up day account
- Python 3 running environment
- Third party libraries such as requests
0x01 process analysis
Check the corresponding URL s of exclusive SRC, enterprise SRC and public SRC respectively, and it is found that there is no change. It is preliminarily judged that the website uses Ajax, that is, asynchronous JavaScript and XML.

Enter the public welfare SRC and check the URL s corresponding to different page numbers. There is still no change.
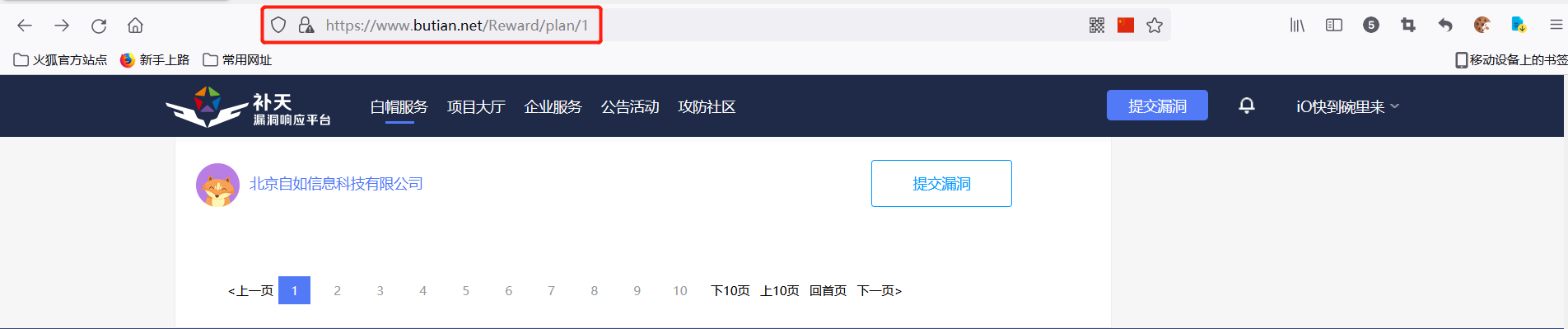
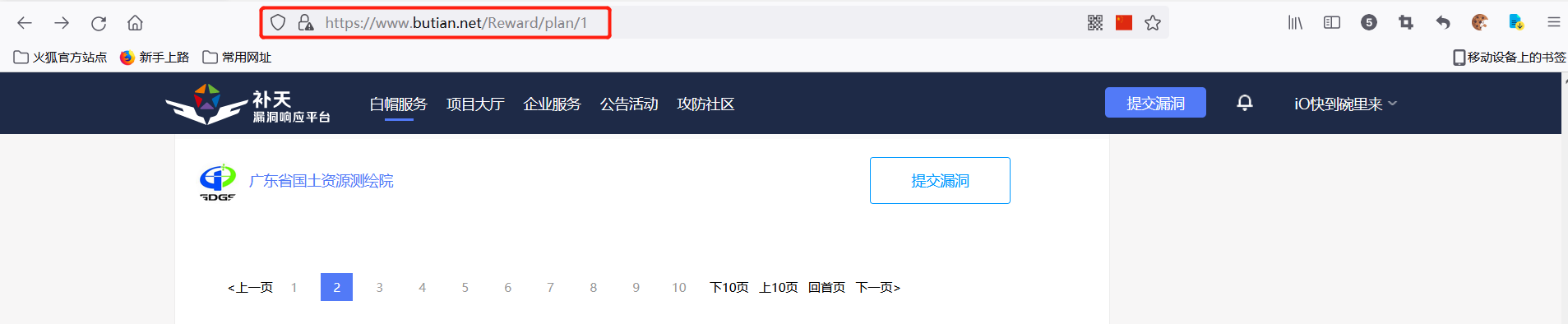
Randomly select a vendor and click Submit vulnerability. It is found that the URL has changed, and the manufacturer name and domain name we want to crawl are found.
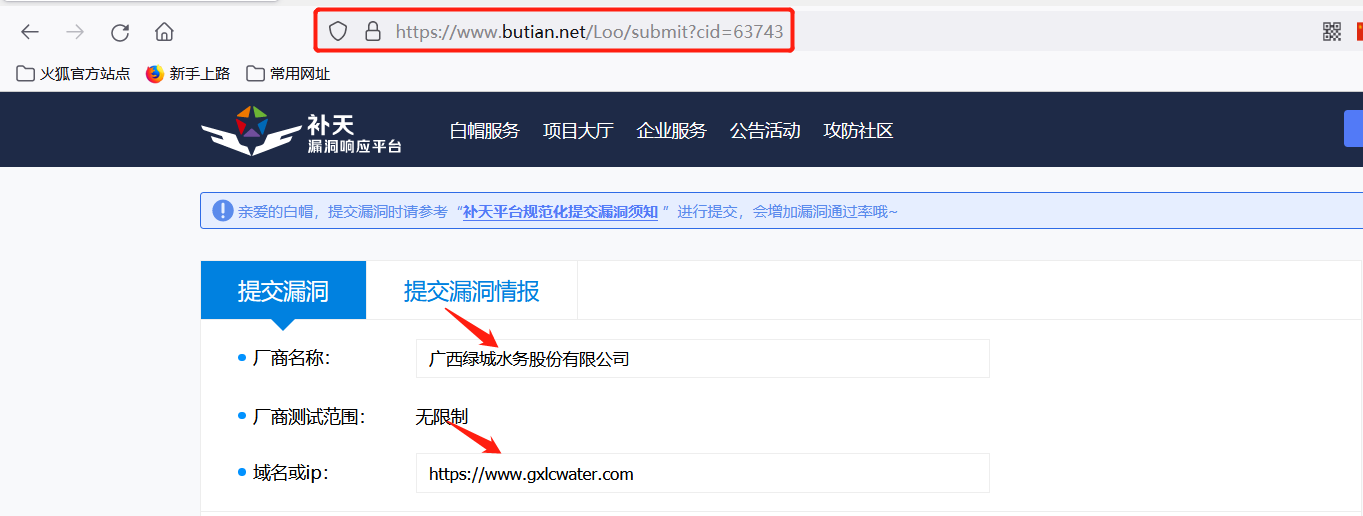
By analyzing the URL s of vulnerability pages submitted by different manufacturers, it is found that each manufacturer has its corresponding cid. The key is how to obtain this parameter.
index_url = 'https://www.butian.net/Loo/submit?cid={c_id}'
Ajax is a technology that uses JavaScript to exchange data with the server and update some web pages without refreshing the page and changing the page links. It realizes the separation of front and back ends, and reduces the pressure brought by the server to render the page directly. The analysis process is as follows:
- Request occurred: HttpXMLRequest
- Parse content: when the request gets a response, trigger the corresponding method of onreadystatechange property and return relevant content. The returned content may be HTML or Json. If the returned content is Json, we can further process it through JavaScript, parse and transform it.
- Rendering a web page: for example, change the content of an element through docume.getElementById().innetHTML = XMLHttpRequest.responseText, that is, DOM operation.
In a word, JavaScript sends an Ajax request to the server. After the request is responded, it returns new data. The data is loaded through Ajax. JavaScript calls the Ajax function interface in the background to get the data, and then parses and renders the data. To crawl the page information, you can directly crawl the Ajax interface to get the data.
0x02 scripting
1, Crawl the manufacturer CID list based on the page number:
def get_company_id(data):
try:
reponse = requests.post('https://www.butian.net/Reward/pub',data=data,timeout=(4,20))
if reponse.status_code == 200:
return reponse.json()
logging.error('get invalid status_code %s while scraping %s',reponse.status_code,url)
except requests.RequestException:
logging.error('error occurred while scraping %s',url,exc_info=True)
def scrape_index_company_id(page):
data={
's': '1',
'p': page,
'token': ''
}
return get_company_id(data)
def scrape_parse_company_id(json):
company_list = json['data']['list']
page_num = json['data']['count']
return company_list,page_num
The request interface of Ajax usually contains encryption parameters, such as token and sign, but the token here is empty, so you can directly use requests. When the token is not empty, there are usually two solutions:
- Dig deep into the logic, find out the logic of token completely, and then reproduce it in python.
- You can bypass this process by simulating the browser directly through selenium.
2, Crawl the manufacturer name and domain name based on the manufacturer CID:
def get_domain(url):
try:
reponse = requests.get(url,headers=headers)
if reponse.status_code == 200:
return reponse.text
logging.error('get invalid status_code %s while scraping %s',reponse.status_code,url)
except requests.RequestException:
logging.error('error occurred while scraping %s',url,exc_info=True)
def scrape_index_domain(company_id):
url = index_url.format(c_id=company_id)
return get_domain(url)
def scrape_parse_domain(html):
doc = pq(html)
name = doc('input#inputCompy.input-xlarge').attr('value')
try:
url = re.search('type="text" name="host"[^>]+value="([^\"]+)"',html).group(1)
except:
url = "www.null.com"
return name,url
3, Save vendor name and domain name:
def save_log(name,domain):
obj = open("target.text",'a+')
obj.write(name + "\t" + domain + "\n")
obj.close()
- r: Read only, not created (if the file does not exist, an error is reported)
- r +: overwrite read / write, do not create (if the file does not exist, an error will be reported)
- w: Write only, new (empty the contents of the original file)
- w +: read / write, new (empty the contents of the original file)
- a: Additional write (create if original file does not exist)
- a +: additional read / write (created if the original file does not exist)
0x03 multithreading
threads = []
for page in range(1,188):
time.sleep(10)
thread = threading.Thread(target=main,args=(page,))
thread.start()
threads.append(thread)
for thread in threads:
thread.join()
0x04 multi process
pool = multiprocessing.Pool(4) pages = range(1,188) pool.map(main,pages) pool.close() pool.join()
0x05 Extension
1, Anti shielding:
from selenium import webdriver
from selenium.webdriver import ChromeOptions
option = ChromeOptions()
option.add_experimental_option('excludeSwitchese',['enable-automation'])
option.add_experimental_option('useAutomationExtension',False)
browser = webdriver.Chrome(options=option)
browser.execute_cdp_cmd('Page.addScriptToEvaluateOnNewdocument',{'source':'Object.defineProperty(navigator,"webdriver",{get:()=>undefined})'})
2, Headless mode:
from selenium import webdriver
from selenium import ChromeOptions
option = ChromeOptions()
option.add_argument('--headless')
browser = webdriver.Chrome(options=option)
browser.set_window_size(1366,768)
3, Explicit wait:
from selenium.webdriver.commom.by import By from selenium.common.exceptions import TimeoutException from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC wait = WebDriverWait(browser,10) def scrape_page(url,condition,locator):
4, Implicit waiting
browser.implicitly_wait(10)
0x06 Extension_Script
Enter the SRC page:
def scrape_page(url,condition,locator):
try:
browser.get(url)
wait.until(condition(locator))
except TimeoutException:
logging.error('error occurred while sraping %s',url,exc_info=True)
def scrape_index():
href = '/Reward/plan/1'
url = urljoin(base_url,href)
scrape_page(url,condition=EC.element_to_be_clickable,locator=(By.LINK_TEXT,'public welfare SRC'))
def parse_index():
button = browser.find_element_by_link_text('public welfare SRC')
button.click()
Realize page turning:
def next_page():
next = browser.find_element_by_class_name('next')
wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,'a.btn')))
next.click()
Based on page turning, crawl the URL of the vulnerability page submitted by the manufacturer:
def main():
scrape_index()
parse_index()
while True:
wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,'a.btn')))
elements = browser.find_elements_by_css_selector('a.btn')
for element in elements:
href = element.get_attribute('href')
print(href)
time.sleep(5)
next_page()
Crawl vendor name and domain name based on URL:
print(href) => get_domain(href)
The_fu11_extensi0n_scr1pt:
import time
import logging
from selenium import webdriver
from urllib.parse import urljoin
from selenium.webdriver.common.by import By
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
browser = webdriver.Chrome()
wait = WebDriverWait(browser,10)
base_url = 'https://www.butian.net'
logging.basicConfig(level=logging.INFO,format='%(asctime)s-%(levelname)s:%(message)s')
def scrape_page(url,condition,locator):
try:
browser.get(url)
wait.until(condition(locator))
except TimeoutException:
logging.error('error occurred while sraping %s',url,exc_info=True)
def scrape_index():
href = '/Reward/plan/1'
url = urljoin(base_url,href)
scrape_page(url,condition=EC.element_to_be_clickable,locator=(By.LINK_TEXT,'public welfare SRC'))
def parse_index():
button = browser.find_element_by_link_text('public welfare SRC')
button.click()
def next_page():
next = browser.find_element_by_class_name('next')
try:
next.click()
wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,'a.btn')))
except Exceptions as e:
print("Exception found", format(e))
def main():
scrape_index()
parse_index()
while True:
elements = browser.find_elements_by_css_selector('a.btn')
for element in elements:
href = element.get_attribute('href')
print(href)
time.sleep(5)
next_page()
if __name__=='__main__':
main()
This part is an extension. When the token is not empty, you can compare the script with the previous get_domain,scrape_parse_domain,save_log and other functions are concatenated to crawl the manufacturer's name and domain name.
0x06 Summary
Informaintion garthering is the first and most critical step.
Due to space reasons, the author only posted some key functions above and will not connect them in series. You can connect and improve by yourself, so as to achieve multi-threaded and multi process crawling of the target domain name.