preface
Whether it is ID generation in distributed systems or the generation of unique numbers such as requesting serial numbers in business systems, it is a scenario that software developers often face. The snowflake algorithm is a solution to these scenes.
Taking distributed ID as an example, its generation often requires uniqueness, increment, high availability, high performance and so on. In addition, during business processing, crawlers should be prevented from crawling data according to the self increment of ID. The snowflake algorithm performs well in these aspects.
Common distributed ID generation
Common distributed ID generation algorithms and class libraries in the market:
UUID: Java's own API generates a unique random 36 bit string (32 strings + 4 "-"). The uniqueness can be guaranteed, but the readability is poor and cannot be increased orderly.
SnowFlake: SnowFlake algorithm, an open-source distributed ID composed of 64 bit integers, has high performance and is incremented on a single machine. Official address on GitHub: https://github.com/twitter-ar... .
UidGenerator: Baidu open source distributed ID generator, based on snowflake algorithm. GitHub reference link: https://github.com/baidu/uid-... . The description documents and test cases of the project are worthy of in-depth study.
Leaf: meituan's open source distributed ID generator can ensure global uniqueness and increasing trend, but it needs middleware such as relational database and Zookeeper. For relevant implementation, please refer to this article: https://tech.meituan.com/2017... .
Snowflake algorithm
Snow flake is beautiful, unique and unpredictable. There are hardly two identical snowflakes in nature. These characteristics of snowflake are just shown in the snowflake algorithm.
SnowFlake algorithm is an open source distributed ID generation algorithm for Twitter. The core idea is to use a 64 bit long number as the globally unique ID. The time stamp is also introduced into the algorithm, which basically ensures the self increasing characteristic.
The original version of snowflake algorithm was written based on scala. Of course, different programming languages can implement it according to its algorithm logic.
###Principle of snowflake algorithm
The result of ID generated by SnowFlake algorithm is an integer with the size of 64bit. The structure is as follows:
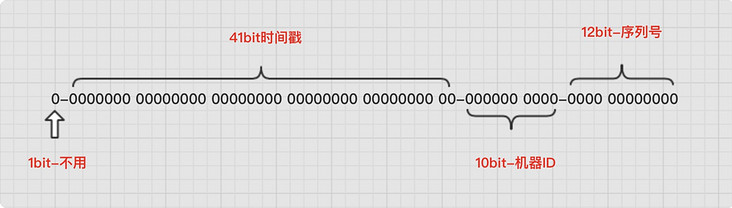
Algorithm analysis:
- The first part: 1 bit, meaningless, fixed to 0. The highest bit in binary is the sign bit, 1 represents negative number and 0 represents positive number. ID s are positive integers, so they are fixed to 0.
- The second part: 41 bit s, representing the timestamp, accurate to milliseconds, can be used for 69 years. Timestamp has self incrementing attribute.
- The third part: 10 bits, which represents 10 bit machine identification, and supports 1024 nodes at most. This part can also be divided into 5-digit datacenter ID and 5-digit workerId. Datacenter ID represents machine room ID and workerId represents machine ID.
- Part IV: 12 bit s, indicating serialization, that is, the self incrementing ID of some columns, which can support the generation of up to 4095 ID sequence numbers at the same node in the same millisecond.
In Java, the 64bit integer is of long type, so the id generated by SnowFlake algorithm in Java is long.
Java implementation of snowflake algorithm
Implementation of snowflake algorithm Java tool class:
public class SnowFlake {
/**
* Starting timestamp (the adjacent time before the current time can be set)
*/
private final static long START_STAMP = 1480166465631L;
/**
* Number of digits occupied by serial number
*/
private final static long SEQUENCE_BIT = 12;
/**
* Number of digits occupied by machine identification
*/
private final static long MACHINE_BIT = 5;
/**
* Number of bits occupied by data center
*/
private final static long DATA_CENTER_BIT = 5;
/**
* Maximum value of each part
*/
private final static long MAX_DATA_CENTER_NUM = ~(-1L << DATA_CENTER_BIT);
private final static long MAX_MACHINE_NUM = ~(-1L << MACHINE_BIT);
private final static long MAX_SEQUENCE = ~(-1L << SEQUENCE_BIT);
/**
* Displacement of each part to the left
*/
private final static long MACHINE_LEFT = SEQUENCE_BIT;
private final static long DATA_CENTER_LEFT = SEQUENCE_BIT + MACHINE_BIT;
private final static long TIMESTAMP_LEFT = DATA_CENTER_LEFT + DATA_CENTER_BIT;
/**
* Data center ID(0~31)
*/
private final long dataCenterId;
/**
* Working machine ID(0~31)
*/
private final long machineId;
/**
* Sequence in milliseconds (0 ~ 4095)
*/
private long sequence = 0L;
/**
* Last generated ID
*/
private long lastStamp = -1L;
public SnowFlake(long dataCenterId, long machineId) {
if (dataCenterId > MAX_DATA_CENTER_NUM || dataCenterId < 0) {
throw new IllegalArgumentException("dataCenterId can't be greater than MAX_DATA_CENTER_NUM or less than " +
"0");
}
if (machineId > MAX_MACHINE_NUM || machineId < 0) {
throw new IllegalArgumentException("machineId can't be greater than MAX_MACHINE_NUM or less than 0");
}
this.dataCenterId = dataCenterId;
this.machineId = machineId;
}
/**
* Generate next ID
*/
public synchronized long nextId() {
long currStamp = getNewStamp();
if (currStamp < lastStamp) {
throw new RuntimeException("Clock moved backwards. Refusing to generate id");
}
if (currStamp == lastStamp) {
//Within the same milliseconds, the serial number increases automatically
sequence = (sequence + 1) & MAX_SEQUENCE;
//The number of sequences in the same millisecond has reached the maximum
if (sequence == 0L) {
//Block to the next millisecond and get a new timestamp
currStamp = getNextMill();
}
} else {
//Within different milliseconds, the serial number is set to 0
sequence = 0L;
}
lastStamp = currStamp;
// Shift and put together by or operation to form a 64 bit ID
return (currStamp - START_STAMP) << TIMESTAMP_LEFT //Timestamp part
| dataCenterId << DATA_CENTER_LEFT //Data center part
| machineId << MACHINE_LEFT //Machine identification part
| sequence; //Serial number part
}
private long getNextMill() {
long mill = getNewStamp();
while (mill <= lastStamp) {
mill = getNewStamp();
}
return mill;
}
private long getNewStamp() {
return System.currentTimeMillis();
}
public static void main(String[] args) {
SnowFlake snowFlake = new SnowFlake(11, 11);
long start = System.currentTimeMillis();
for (int i = 0; i < 10; i++) {
System.out.println(snowFlake.nextId());
}
System.out.println(System.currentTimeMillis() - start);
}
}In the above code, in the core method of the algorithm, thread safety is ensured by adding synchronized lock. In this way, the same server thread is safe, and the generated ID will not be repeated. Due to different machine codes of different servers, even if two servers generate snowflake ID at the same time, the results are different.
Other issues
The 41 bit timestamp can only be 69 years at most
Let's use the program to calculate why the 41 bit timestamp can only support 69 years.
For the binary of 41, the maximum value of 41 bits is 1, that is, 41 bits can represent the value of 2 ^ {41} - 1 milliseconds, and when converted into unit year, it is (2 ^ {41} - 1) / (1000 60 24 365) = 69 years.
Verify through the code:
public static void main(String[] args) {
//41 bit binary minimum
String minTimeStampStr = "00000000000000000000000000000000000000000";
//41 bit binary maximum
String maxTimeStampStr = "11111111111111111111111111111111111111111";
//Convert to decimal
long minTimeStamp = new BigInteger(minTimeStampStr, 2).longValue();
long maxTimeStamp = new BigInteger(maxTimeStampStr, 2).longValue();
//How many milliseconds are there in a year
long oneYearMills = 1L * 1000 * 60 * 60 * 24 * 365;
//Calculate the maximum number of years
System.out.println((maxTimeStamp - minTimeStamp) / oneYearMills);
}Therefore, the ID generated by snowflake algorithm can only ensure that it will not be repeated in 69 years. If it exceeds 69 years, consider deploying another server (server ID), and ensure that the ID of the server and the ID of the server have not been repeated before.
Front and rear value types
When using the snowflake algorithm, because the generated ID is 64 bits, you need to consider passing it to the front end as a string type, otherwise the front end type may overflow and become another value when it is returned to the server.
This is because the ID of Number type only supports 53 bits at most in JS. Directly passing the ID generated by snowflake algorithm to JS will lead to overflow.
Summary
The generation of unique ID (other data) is a common scenario in almost every system. The generation algorithm should not only ensure global uniqueness and increasing trend, but also ensure information security (such as crawled data), but also ensure the high availability of the algorithm (QPS, five 9s of feasibility, average delay, TP999 and other indicators). This has certain requirements for the algorithm of ID generation, and the snowflake algorithm is a good choice.
However, it also has some disadvantages, such as strong dependence on the machine clock. If the clock on the machine is dialed back, it will lead to duplication or service unavailability, which is also something we need to pay attention to when using.
About the blogger: the author of the technical book "inside of SpringBoot technology", loves to study technology and write technical dry goods articles.
The official account: "new horizon of procedures", the official account of bloggers, welcome the attention.
Technical exchange: please contact blogger wechat: zhuan2quan