Previously, Installation and Configuration of Solr 6.5 on Centos6 (I) Installation of Solr 6.5 is introduced in this paper. This article focuses on creating Solr Core and configuring Chinese IKAnalyr word segmentation and Pinyin retrieval.
First, create Core:
1. First, in solrhome (see the path and configuration of solrhome) Installation and Configuration of Solr 6.5 on Centos6 (I) Create mycore directory in web.xml of solr.
[root@localhost down]# [root@localhost down]# mkdir /down/apache-tomcat-8.5.12/solrhome/mycore [root@localhost down]# cd /down/apache-tomcat-8.5.12/solrhome/mycore[root@localhost mycore]#
2. Copy all files under solr-6.5.0exampleexample-DIHsolrsolrsolr to / down/apache-tomcat-8.5.12/solrhome/mycore:
[root@localhost mycore]# cp -R /down/solr-6.5.0/example/example-DIH/solr/solr/* ./ [root@localhost mycore]# ls conf core.properties [root@localhost mycore]#
3. Restart tomcat;
[root@localhost down]# /down/apache-tomcat-8.5.12/bin/shutdown.sh [root@localhost down]# /down/apache-tomcat-8.5.12/bin/startup.sh
4. Enter in the browser at this time http://localhost:8080/solr/index.html Solr's management interface will appear, and you can see our mycore just now.
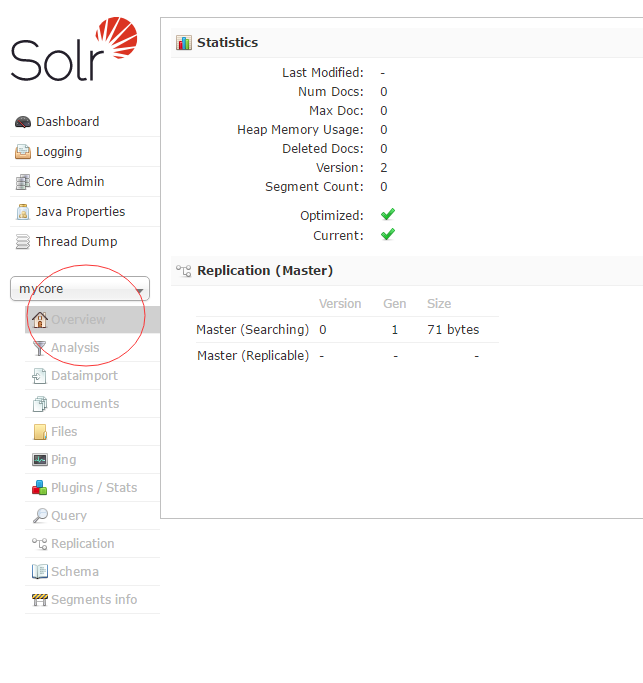
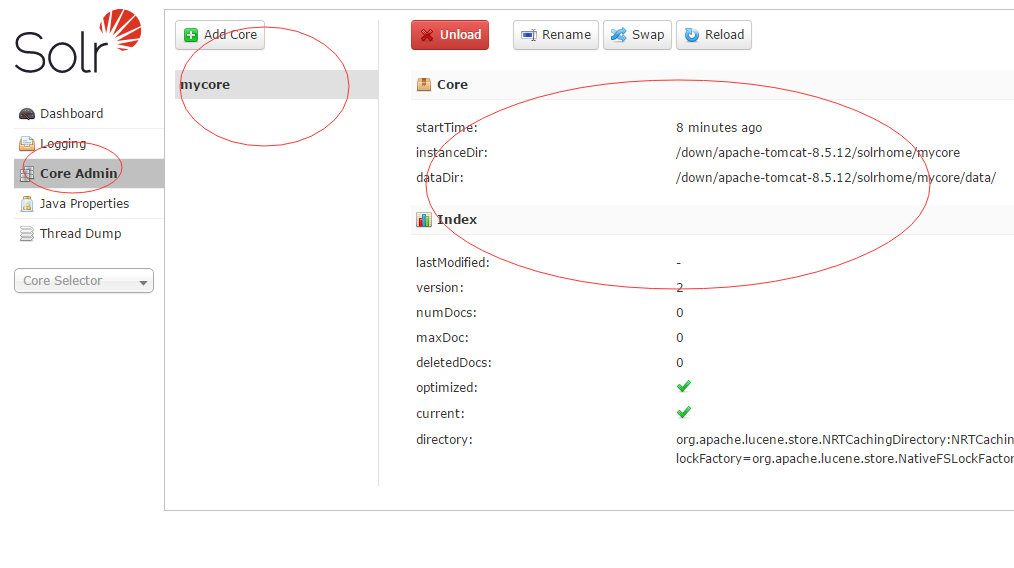
2. Configure the Chinese word segmentation with solr:
1. Configure solr6.5 with Chinese word segmentation. Copy solr-6.5.0/contrib/analysis-extras/lucene-libs/lucene-analyzers-smartcn-6.5.0.jar to apache-tomcat-8.5.12/webapps/solr/WEB-INF/lib/directory.
[root@localhost down]# cp /down/solr-6.5.0/contrib/analysis-extras/lucene-libs/lucene-analyzers-smartcn-6.5.0.jar /down/apache-tomcat-8.5.12/webapps/solr/WEB-INF/lib/
2. Adding support for Chinese word segmentation to core. Edit the managed-schema file under conf under mycore.
[root@localhost conf]# cd /down/apache-tomcat-8.5.12/solrhome/mycore/conf [root@localhost conf]# vi managed-schema
Add before </schema> of the file
<fieldType name="text_smartcn" class="solr.TextField" positionIncrementGap="0"> <analyzer type="index"> <tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/> </analyzer> <analyzer type="query"> <tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/> </analyzer> </fieldType>
Restart tomcat and enter it in the browser http://localhost:8080/solr/index.html#/mycore/analysis
Enter some Chinese in the Field Value (Index) text box, and then analyze Fieldname / FieldType: Select text_smartcn to see the effect of Chinese word segmentation.
As shown in the figure:
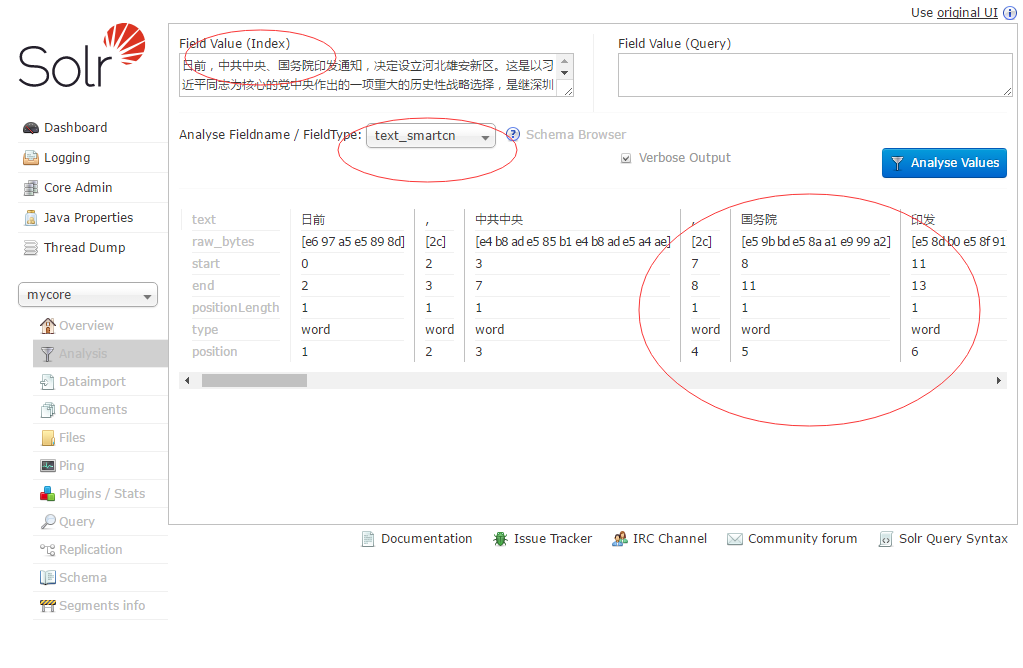
3. Configure the Chinese participle of IKAnalyr:
1. Download first IKAnalyzer This is the latest support Solr 6.5.
There will be four files after decompression.
[root@localhost ikanalyzer-solr5]# ls ext.dic IKAnalyzer.cfg.xml ik-analyzer-solr5-5.x.jar stopword.dic
ext.dic is an extended dictionary, stopword.dic is a stop word dictionary, IKAnalyr.cfg.xml is a configuration file, and ik-analyzer-solr5-5.x.jar is a participle jar package.
2. Copy the IKAnalyr.cfg.xml, ext.dic and stopword.dic files under the folder to the directory of/webapps/solr/WEB-INF/classes, and modify IKAnalyr.cfg.xml.
[root@localhost ikanalyzer-solr5]# cp ext.dic IKAnalyzer.cfg.xml stopword.dic /down/apache-tomcat-8.5.12/webapps/solr/WEB-INF/classes/
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer Extension Configuration </comment>
<! - Users can configure their own extended dictionary here - >.
<entry key="ext_dict">ext.dic;</entry>
<! - Users can configure their extended stop word dictionary here - >.
<entry key="ext_stopwords">stopword.dic;</entry>
</properties>
3. Add your own extended dictionary in ext.dic, for example, merchandise gathers fine products
4. Copy ik-analyzer-solr5-5.x.jar to / down/apache-tomcat-8.5.12/webapps/solr/WEB-INF/lib/directory.
[root@localhost down]# cp /down/ikanalyzer-solr5/ik-analyzer-solr5-5.x.jar /down/apache-tomcat-8.5.12/webapps/solr/WEB-INF/lib/
5. Add the following configuration before solrhome mycore conf managed-schema file </schema>.
<!-- I added IK participle --> <fieldType name="text_ik" class="solr.TextField"> <analyzer type="index" isMaxWordLength="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/> <analyzer type="query" isMaxWordLength="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/> </fieldType>
Note: Remember to code stopword.dic, ext.dic as UTF-8 without BOM.
Restart tomcat to see the segmentation effect.
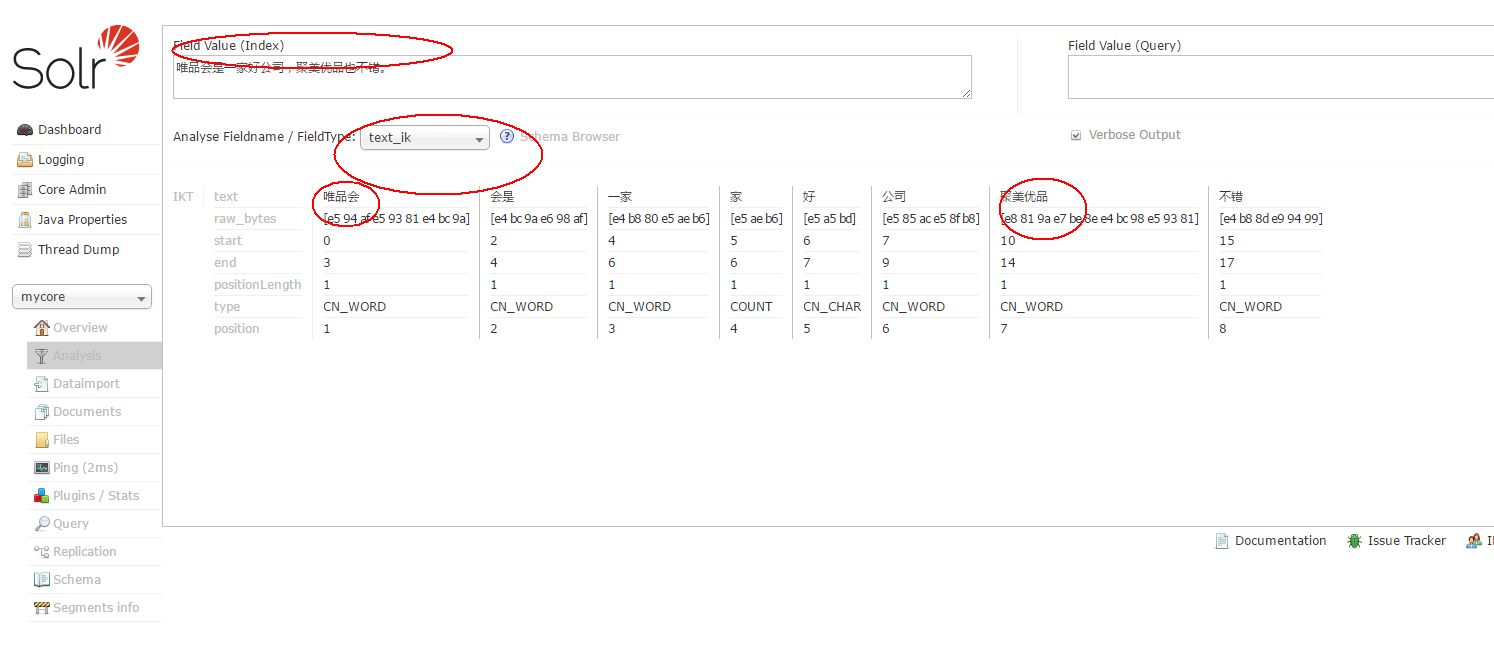
4. Configuring Pinyin Retrieval:
1. Pre-preparation requires two jar packages, pinyin4j-2.5.0.jar and pinyinAnalyr.jar. Download address.
2. Copy the two jar packages pinyin4j-2.5.0.jar and pinyinAnalyr.jar to / down/apache-tomcat-8.5.12/webapps/solr/WEB-INF/lib/directory.
[root@localhost down]# cp pinyin4j-2.5.0.jar pinyinAnalyzer4.3.1.jar /down/apache-tomcat-8.5.12/webapps/solr/WEB-INF/lib/
3. Add the following configuration before solrhome mycore conf managed-schema file </schema>:
<fieldType name="text_pinyin" class="solr.TextField" positionIncrementGap="0"> <analyzer type="index"> <tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/> <filter class="com.shentong.search.analyzers.PinyinTransformTokenFilterFactory" minTermLenght="2" /> <filter class="com.shentong.search.analyzers.PinyinNGramTokenFilterFactory" minGram="1" maxGram="20" /> </analyzer> <analyzer type="query"> <tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/> <filter class="com.shentong.search.analyzers.PinyinTransformTokenFilterFactory" minTermLenght="2" /> <filter class="com.shentong.search.analyzers.PinyinNGramTokenFilterFactory" minGram="1" maxGram="20" /> </analyzer> </fieldType>
Restart tomcat to see the Pinyin retrieval effect.
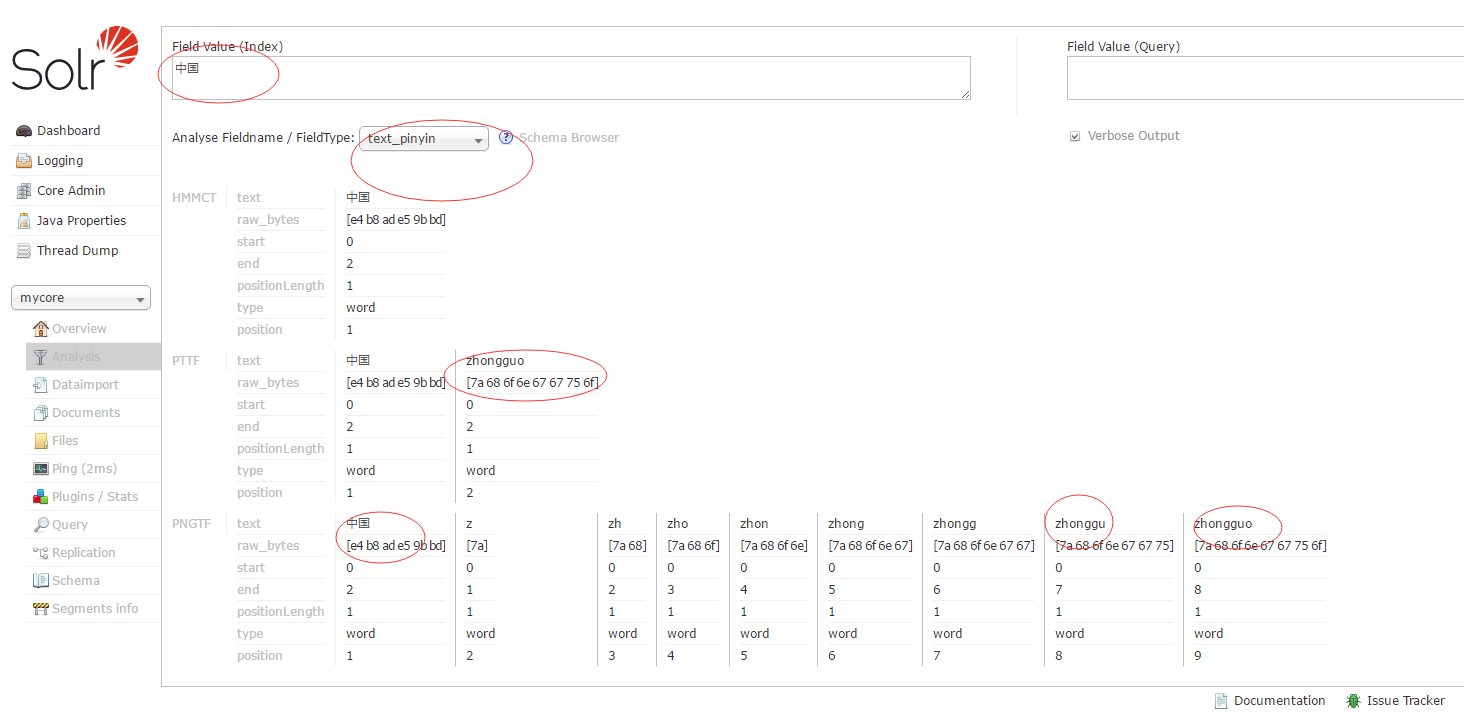
Here we use the Chinese word segmentation with solr plus pinyin4j to achieve.
The download address of the relevant documents: