Clipping input data to the valid range for imshow with RGB data
Today, there is a problem when extracting RGB channel values of color images to synthesize single channel images:
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Give the reason first:
matplotlib.pyplot.imshow() function automatically normalizes the value of gray image when processing it
When processing color images, the floating-point value is not converted to [0,1], and the integer value is converted to the range of [0,255]
Upper Code:
def slic_image(image_path, block_number, compactness, sigma):
image = cv2.imread(image_path)
image_depth = image.shape[2]
if image_depth == 3:
image_r, image_g, image_b = cv2.split(image)
image_r = image_r.astype('float32')
image_g = image_g.astype('float32')
image_b = image_b.astype('float32')
syn_image_g = syn_single_channel_image(sig_channel_image=image_g, channel_name="g")
plt.imshow(syn_image_g)
plt.show()
def syn_single_channel_image(sig_channel_image, channel_name,):
image_height = sig_channel_image.shape[0]
image_width = sig_channel_image.shape[1]
b = np.empty(shape=(image_height, image_width), dtype="float32")
g = np.empty(shape=(image_height, image_width), dtype="float32")
r = np.empty(shape=(image_height, image_width), dtype="float32")
b[:][:] = 0
g[:][:] = 0
r[:][:] = 0
synthesis = [r, g, b]
if channel_name == 'r':
synthesis = [sig_channel_image, g, b]
elif channel_name == 'g':
synthesis = [r, sig_channel_image, r]
elif channel_name == 'b':
synthesis = [r, g, sig_channel_image]
synthesis_image = cv2.merge(synthesis)
return synthesis_image
slic_image(image_path='test.png', block_number=30, compactness=10, sigma=5)
The simple description is to extract the three channel information of an image and synthesize a monochrome image with two equal size 0 arrays.
Here, I convert the extracted information of each channel into float32. The original purpose is to better preserve the image information (later, I found that the pixel value type of the image read by cv2.imread() function is uint8, so it is absolutely unnecessary to do so)
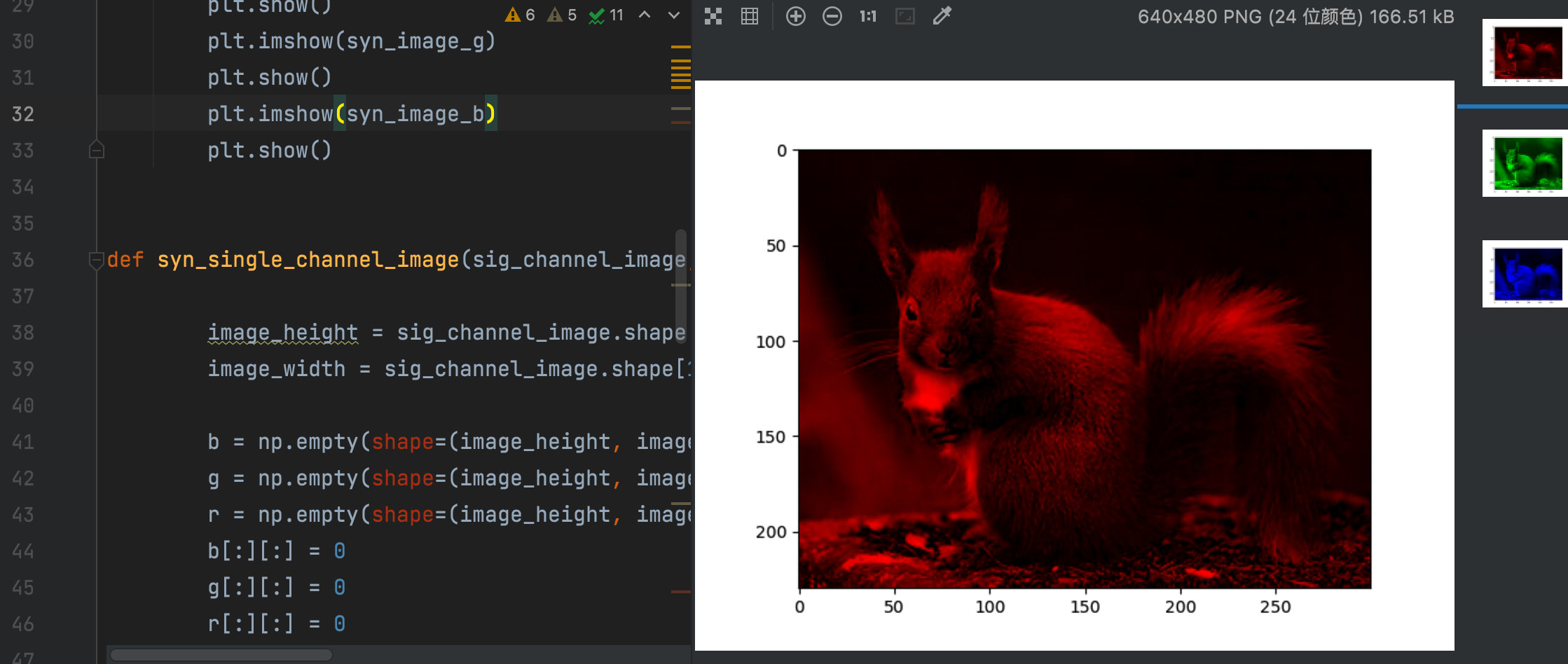
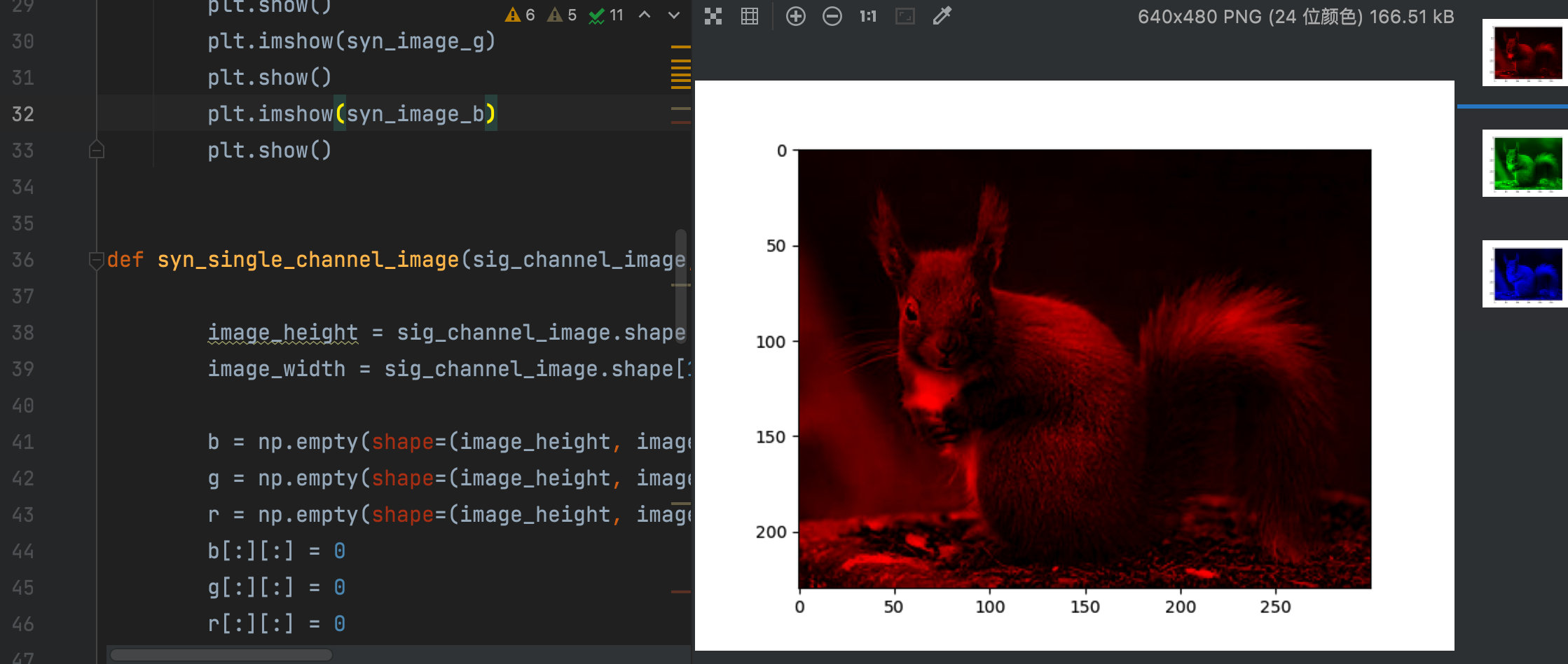
The result of the final synthesis is naturally that the data types of the three channels are all float32. When calling PLT The imshow() function is adjusted to the range of [0,1], resulting in almost all green images:
Display comparison between original image and composite image
resolvent:
Finally, I defined all the data types in the array as uint8, which is normal.
result:
Today, there is a problem when extracting RGB channel values of color images to synthesize single channel images:
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Give the reason first:
matplotlib.pyplot.imshow() function automatically normalizes the value of gray image when processing it
When processing color images, the floating-point value is not converted to [0,1], and the integer value is converted to the range of [0,255]
Upper Code:
def slic_image(image_path, block_number, compactness, sigma):
image = cv2.imread(image_path)
image_depth = image.shape[2]
if image_depth == 3:
image_r, image_g, image_b = cv2.split(image)
image_r = image_r.astype('float32')
image_g = image_g.astype('float32')
image_b = image_b.astype('float32')
syn_image_g = syn_single_channel_image(sig_channel_image=image_g, channel_name="g")
plt.imshow(syn_image_g)
plt.show()
def syn_single_channel_image(sig_channel_image, channel_name,):
image_height = sig_channel_image.shape[0]
image_width = sig_channel_image.shape[1]
b = np.empty(shape=(image_height, image_width), dtype="float32")
g = np.empty(shape=(image_height, image_width), dtype="float32")
r = np.empty(shape=(image_height, image_width), dtype="float32")
b[:][:] = 0
g[:][:] = 0
r[:][:] = 0
synthesis = [r, g, b]
if channel_name == 'r':
synthesis = [sig_channel_image, g, b]
elif channel_name == 'g':
synthesis = [r, sig_channel_image, r]
elif channel_name == 'b':
synthesis = [r, g, sig_channel_image]
synthesis_image = cv2.merge(synthesis)
return synthesis_image
slic_image(image_path='test.png', block_number=30, compactness=10, sigma=5)
The simple description is to extract the three channel information of an image and synthesize a monochrome image with two equal size 0 arrays.
Here, I convert the extracted information of each channel into float32. The original purpose is to better preserve the image information (later, I found that the pixel value type of the image read by cv2.imread() function is uint8, so it is absolutely unnecessary to do so)
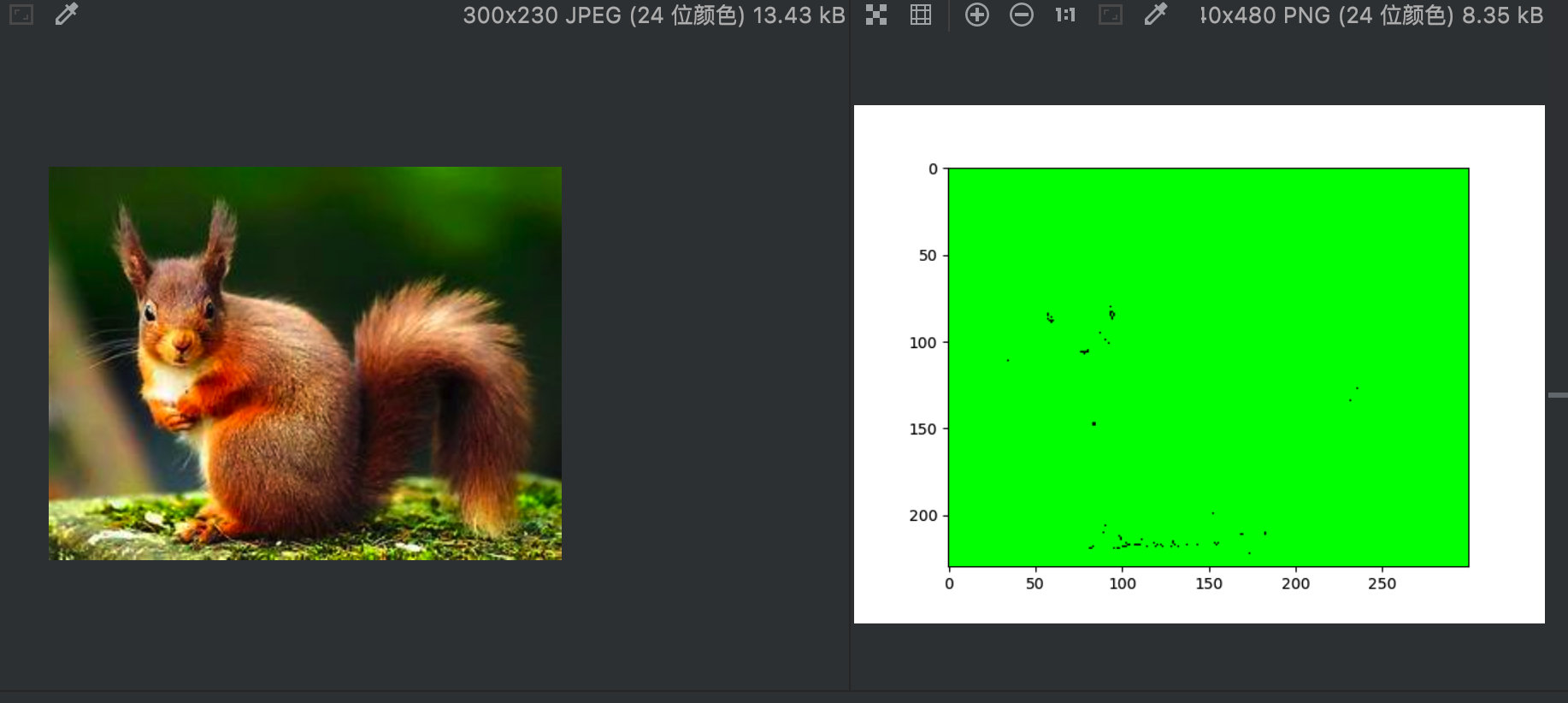
The result of the final synthesis is naturally that the data types of the three channels are all float32. When calling PLT The imshow() function is adjusted to the range of [0,1], resulting in almost all green images:
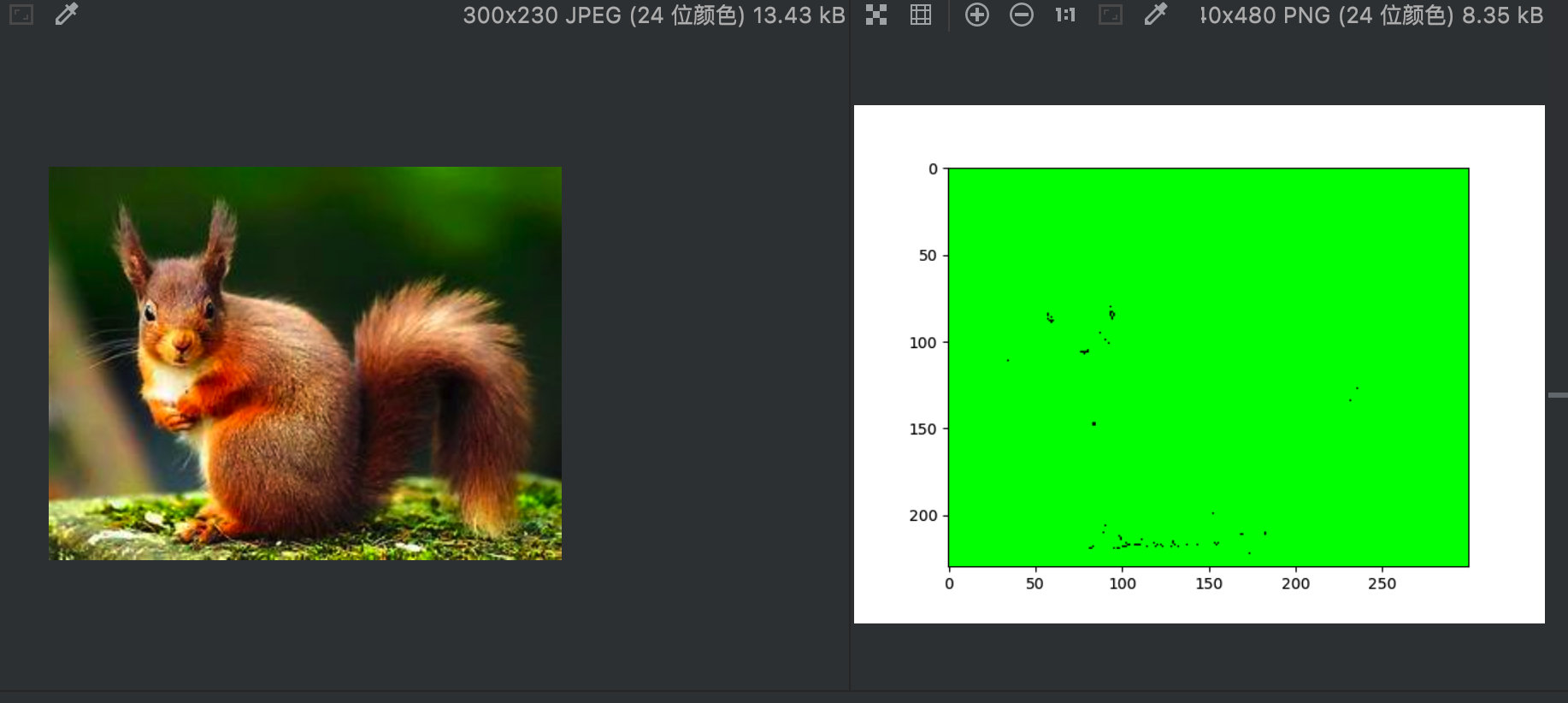
Display comparison between original image and composite image
resolvent:
Finally, I defined all the data types in the array as uint8, which is normal.
result: