Idea 1: SQL optimization
In order to specifically simulate the second kill scenario, assume that the inventory table is called stock, the commodity quantity is called num, and the new number calculated by the business code is new_num=num-1, the original SQL executed is:
update stock set num=new_num where id = id=#{id};We can improve SQL and let the database update data according to its current value. For example, it is written as follows:
update stock set num=num-1 where id = #{id};
Copy codeAlthough this seems to solve the problem, assuming that the quantity of inventory is 1 at this time, after the two threads subtract 1 respectively, it will be found that the inventory is deducted to - 1, which can not completely solve the concurrency problem.
Idea 2: code locking
Since there is still a problem with two threads taking data at the same time, is there any way to make them execute in turn? Therefore, it is easy to think of locking them before checking the inventory, such as the synchronized keyword of Java.
This can ensure the serialization and ensure that only one thread executes the code segment of inventory check and inventory deduction at a time, but there are also many disadvantages:
- It is impossible to achieve fine-grained control. If some people second kill commodity A and some second kill commodity B, they all have to take the second kill method. There is no conflict between them, but they can only be executed serially, and the access will become very slow.
- Because the @ service in spring is a singleton, it can be written like this. If you use the django framework of python language, you can't do similar control in the code layer and it's not universal.
- It only supports single point (stand-alone and server environment) and cannot achieve horizontal expansion. Now it is basically deployed in clusters, and only one machine can take effect.
Maybe we need a third-party mechanism to implement such a lock.
Idea 3: pessimistic lock based on MySQL
Because all threads are accessing the same table, you can lock the database. There are two typical methods: pessimistic lock and optimistic lock.
Pessimistic locks take advantage of select For update syntax, for example:
select * from stock where id=#{id} for update;Note: when using pessimistic lock, put the business code in the transaction.
Pessimistic lock locks the data row when acquiring data. If other transactions want to acquire locks, they must wait until the end of the original transaction.
Using selec For update will lock the data. MySQL InnoDB defaults to row level lock. Therefore, MySQL will execute Row lock (only lock the selected data) only if the primary key is "explicitly" specified. Otherwise, MySQL will execute Table Lock (lock the whole data form).
The disadvantage of using pessimistic lock is that the concurrency is not high because the table needs to be locked. If the concurrency is too high and the database pressure is too high, it will go down.
Idea 4: optimistic lock based on MySQL
Compared with pessimistic lock, optimistic lock assumes that the data will not cause conflict under normal circumstances. Therefore, when the data is submitted and updated, the conflict of the data will be officially detected. If the conflict is found, the user will return the wrong information and let the user decide how to do it.
There are two ways to implement optimistic locks.
Implement optimistic locking with version number
There are two ways to implement version number, one is the data version mechanism, the other is the timestamp mechanism. The details are as follows.
It is implemented using the data version recording mechanism, which is the most commonly used implementation of optimistic locking. What is data version? That is, adding a version ID to the data is generally realized by adding a digital version field to the database table. When reading data, read out the value of the version field together. Add one to the version value every time the data is updated. When we submit the update, we judge that the current version information of the corresponding record of the database table is compared with the version value obtained for the first time. If the current version number of the database table is equal to the version value obtained for the first time, it will be updated, otherwise it will be considered as expired data.
If optimistic lock is used, the SQL change of inventory deduction is as follows:
1. Query the commodity information
select num,version from stock where id=#{id};- Number of deductions. new_num = num -1
- Modify the database.
update stock set num=new_num, version=version+1 where id=#{id} and version=#{version};If the version has changed at this time, the update will fail. You can retry or report an error according to the specific business.
Using conditional constraints to achieve optimistic locking
This is applicable to update only and data security verification. It is suitable for inventory model, deduction share and rollback share. It has higher performance and is very convenient and practical.
Change SQL to:
update stock SET num = num - #{buyNum} where id = #{id} and num - #{buyNum} >= 0;Note: for the update operation of optimistic lock, it is best to update with primary key or unique index. This is row lock, otherwise the table will be locked during update.
Optimistic lock has higher ability to carry concurrency than pessimistic lock, and will be applied more. However, when the concurrency is higher and higher, the pressure on the database will be greater, because if the update fails to retry, you may constantly query the database.
Idea 5: Redis based distributed lock
Since the implementation of database lock can never bypass the concurrency problem, we turn to third-party middleware, such as Redis.
It is mentioned here that if the concurrency is not high, the pessimistic lock or optimistic lock based on MySQL can solve the problem, and the maintenance is relatively simple. There is no need to introduce additional components, and the system availability is high. The so-called architecture is actually doing trade-off.
Let's briefly explain the implementation principle. Thread A first sets the key of the commodity (such as goods_1) to 1 in Redis. If thread B also finds 1, it will not only poll until thread A releases the lock, but thread B can get the lock again.
Here, I simply simulated the implementation in Python language. Using the redis py library, I wrote a Lock class, which contains two methods to obtain Lock acquire and release Lock release:
import redis
class Lock:
def __init__(self, name):
self.redis_client = redis.Redis(host="127.0.0.1")
self.name = name
def acquire(self):
# If it is empty or None, it means that the lock has been obtained
if not self.redis_client.get(self.name):
self.redis_client.set(self.name, 1)
return True
else:
# If you do not want to block the polling acquisition lock, you can directly return False
while True:
import time
time.sleep(1)
if self.redis_client.get(self.name):
return True
def release(self):
self.redis_client.delete(self.name)Idea 6: Problems and improvement of Redis distributed lock
Ensure atomicity
Experienced partners will certainly find the problem of the above code. When the concurrency is very high, multiple threads may enter if not self at the same time redis_ client. Get (self. Name), so the lock is obtained at the same time, which invalidates the distributed lock.
Therefore, we should ensure the atomicity of reading and setting values.
How to solve it? Redis naturally provides the setnx command to ensure atomic operation. When the specified key does not exist, the command sets the specified value for the key.
So we can upgrade the above Lock code as follows:
import redis
class Lock:
def __init__(self, name):
self.redis_client = redis.Redis(host="127.0.0.1")
self.name = name
def acquire(self):
if self.redis_client.setnx(self.name, 1): # If the setting does not exist and returns 1, no returns 0, which is an atomic operation
return True
else:
# If you do not want to block the polling acquisition lock, you can directly return False
while True:
import time
time.sleep(1)
if self.redis_client.setnx(self.name, 1): # Note that this place should also be changed
return True
def release(self):
self.redis_client.delete(self.name)Lock expiration time
Let's continue to think. If a thread gets the lock, but the lock is not released due to some reasons (such as the network can't connect to redis, abnormal code, sudden power failure), other threads can't get the lock and are in a state of waiting forever, resulting in deadlock.
A better solution is to set the expiration time for the lock. We use the set function provided by redis py library and add atomic operation and expiration parameters to the lock.
self.redis_client.set(self.name, self.id, nx=True, ex=15)
Renewal of locks
However, the expiration setting creates new problems:
If the current thread does not finish executing after a period of time, and then the key expires, another thread will continue to execute after getting the lock, and the program is unsafe.
In addition, another thread may finish executing first and release the current lock, which belongs to the original thread.
Therefore, if the current thread has not finished executing, it should renew the lease at an appropriate time and reset the expiration time.
For example, if the expiration time is 15s, renew the lease at 2 / 3 of 15s, that is, reset the expiration time to 15s after running for 10s. You can start a new thread in the program to complete the renewal process at a fixed time.
Delete lock security
As mentioned earlier, other threads are at risk of releasing the lock of the current thread.
We can use uuid instead of 1 when obtaining the lock setting value, and judge whether it is the uuid of the current thread when releasing, so as to prevent it from being released by other threads.
So the code of distributed lock has evolved into the following:
import uuid
import redis
class Lock:
def __init__(self, name, id=None):
self.id = uuid.uuid4()
self.redis_client = redis.Redis(host="192.168.0.104")
self.name = name
def acquire(self):
# Set the expiration time to 15s. If there is no setting and 1 is returned, no is returned. This is an atomic operation
if self.redis_client.set(self.name, self.id, nx=True, ex=15):
# Start a thread and periodically refresh the expired data. It's best to use lua script to complete this operation
return True
else:
while True:
import time
time.sleep(1)
if self.redis_client.set(self.name, self.id, nx=True, ex=15):
return True
def release(self):
# Make a judgment first, take out the value first, and then judge whether the current value is consistent with the id in your own lock. If it is consistent, delete it, and report an error if it is inconsistent
# This code is unsafe and atomizes get and delete operations, but Redis can use lua script to complete this operation and atomize the operation
id = self.redis_client.get(self.name)
if id == self.id:
self.redis_client.delete(self.name)
else:
print("You cannot delete a lock that does not belong to you")The above code is not complete, because Redis does not have relevant operation instructions to atomize the get and delete operations, and there will still be security problems. Similarly, there will be such problems in the process of rent renewal.
However, redis provides lua script support for such user scenarios. Users can send lua scripts to the server to perform custom actions and obtain the response data of the scripts. Redis server will execute lua script atomically in a single thread to ensure that lua script will not be interrupted by any other request during processing.
Summarize Redis distributed locks
So far, let's summarize the problems that need to be solved for distributed locks:
- Mutex: only one client can have a lock at any time, and multiple clients cannot obtain it at the same time
- Deadlock: the client that obtains the lock fails to release the lock due to downtime for some reason, and other clients cannot obtain the lock. An organic system is needed to avoid such problems
- For example, the code is abnormal, which makes it impossible to run to release
- There is a problem with the current server network. For example, when it is time to release, Redis cannot be accessed suddenly
- Server power down
- Security: a lock can only be deleted by the user holding the lock, not by other users
- Fault tolerance: when some nodes are down, the client can still obtain or release the lock
Idea 7: Python third-party open source library
It was mentioned earlier that Lua script is needed to solve security problems, but it is troublesome to write Lua script. Here I recommend a third-party open source library on the network, which has a very complete Python method to realize Redis distributed lock.
I'll post the flow chart of this library here:
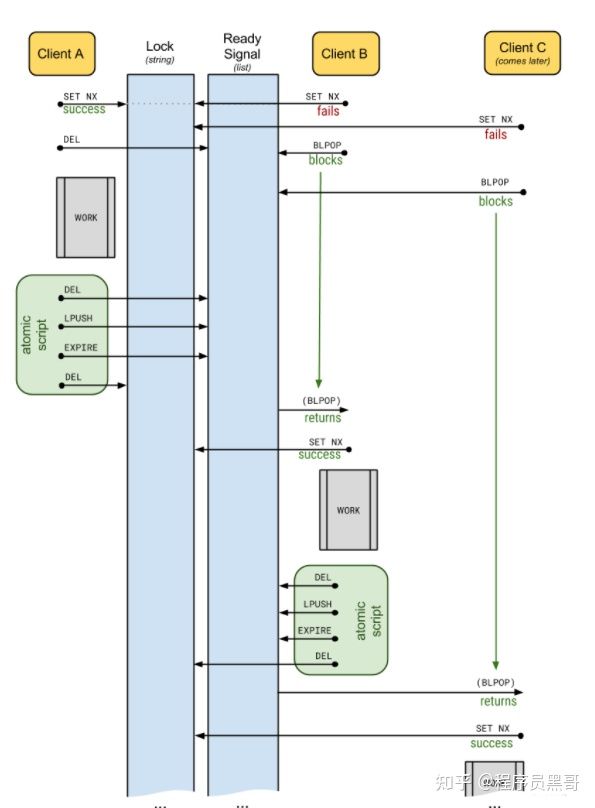
The overall implementation of this library is the same as we mentioned earlier, but there are some differences in details. By reading the source code, I summarize as follows:
- In order to reduce meaningless polling, another Redis list will be created. The blpop instruction of Redis is used to move out and obtain the first element of the list. If there is no element in the list, the list will be blocked until the waiting timeout or pop-up element is found.
- Renewal is difficult to understand. In short, it will start a thread to renew the lease. Assuming that the lock time is 15s, the renewal inspection interval is 2 / 3 of 15s, that is, 10s. The renewal is to reset the lock timeout to 15s and continue the inspection after 10s.
- If the business code is blocked, the renewal may cause the code to wait indefinitely, which needs to be used with caution. Therefore, the library provides optional parameters.
- Used__ enter__,__exit__ Magic method, which supports the implementation of with when called by the client.
So far, the distributed lock of Redis lock has been fully introduced. Its advantages are simple to use and high performance. Moreover, Redis is also a very common component and does not need additional maintenance.
In addition, due to the risk of single Redis hanging up, we will use Redis cluster or Redis sentinel in production to ensure high availability.
Idea 8: distributed lock based on zookeeper
In addition to Redis implementation, zookeeper can also implement distributed locks. However, if zookeeper is not used in the project, I don't think it is necessary to introduce additional components. I won't introduce this method more.
Idea 9: redistribution in Java
If it is Java code, you can use the redistribution package to implement distributed locks.
The example code is as follows:
// 1. Construct redisson to realize the necessary Config of distributed lock
Config config = new Config();
config.useSingleServer().setAddress("redis://127.0.0.1:5379").setPassword("123456").setDatabase(0);
// 2. Construct RedissonClient
RedissonClient redissonClient = Redisson.create(config);
// 3. Obtain the lock object instance (it cannot be guaranteed to be obtained in the order of threads)
RLock rLock = redissonClient.getLock(lockKey);
try {
/**
* 4.Attempt to acquire lock
* waitTimeout The maximum waiting time for trying to acquire a lock. If it exceeds this value, it is considered that acquiring a lock has failed
* leaseTime The holding time of the lock. After this time, the lock will automatically expire (the value should be set to be greater than the business processing time to ensure that the business can be processed within the lock validity period)
*/
boolean res = rLock.tryLock((long)waitTimeout, (long)leaseTime, TimeUnit.SECONDS);
if (res) {
//Successfully obtain the lock and process the business here
}
} catch (Exception e) {
throw new RuntimeException("aquire lock fail");
}finally{
//In any case, unlock it in the end
rLock.unlock();
}Follow up planning
Due to time constraints, this article only focuses on the distributed lock theory and does not involve the complete project code. I will focus on this later