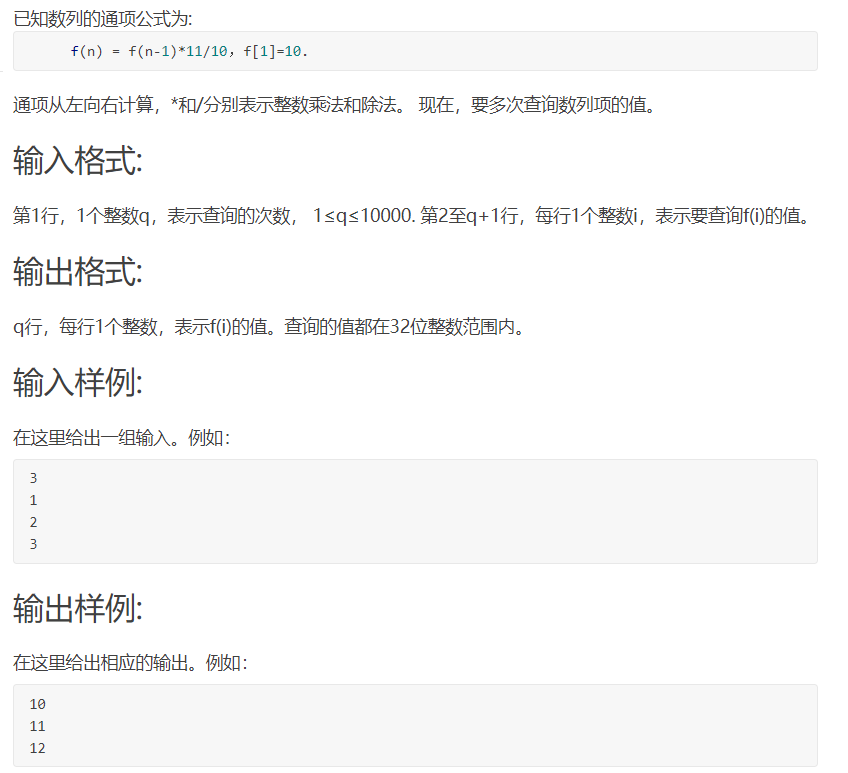
T1: sequence query
This question can be queried up to 10000 times. If recursion is used only, there will be multiple repeated calculations. Therefore, an array can be used to store the results calculated in the recursion process. When querying f(i), if f(i) has been calculated before, it can be output directly; If it has not been calculated, it will be calculated and stored in the array.
The code is as follows:
T2: difference of sparse matrix

This problem is represented by triples. When entering the matrix, it is sorted by rows and columns, so it can be stored directly without sorting. If the row and column numbers of a and B are different, then "legal!" will be output directly. When calculating A-B, operate from the beginning and point to the elements to be operated by a and B with pa and pb respectively. If the rows and columns of A[pa] and B[pb] are the same, compare their values. If the subtraction is 0, it will not be stored in C. if it is not 0, it will be stored in C, cnt + + (the number of non-0 data items in cnt record matrix C). If the rows and columns of A[pa] and B[pb] are different, operate the high priority one in the order of first and last columns and store it in C, cnt + +. At the same time, the pointer (pa/pb) of this matrix (referring to the matrix where the data with just high priority is located) moves to the next bit, and the pointer of the other matrix without operation remains unchanged.
The code is as follows:
#include<iostream>
#include<cstdlib>
#include<cstdio>
#include<algorithm>
using namespace std;
int N1,M1,t1,N2,M2,t2;
int cnt;
struct node{
int x,y;
int data;
};
node a[50000+5],b[50000+5],c[500000+5];
void work(){
if(!((N1==N2)&&(M1==M2))){
printf("Illegal!");
exit(0);
}else{
int pa=0,pb=0,j;
for(j=0;pa<t1&&pb<t2;){
if(a[pa].x==b[pb].x&&a[pa].y==b[pb].y){ //When the rows and columns are the same
if(a[pa].data==b[pb].data); //Subtract to 0, no storage
else{
c[j].x=a[pa].x;
c[j].y=a[pa].y;
c[j].data=a[pa].data-b[pb].data;
j++;
}
pa++;pb++;
}else if(a[pa].x==b[pb].x){
if(a[pa].y<b[pb].y){
c[j].x=a[pa].x;
c[j].y=a[pa].y;
c[j].data=a[pa].data;
pa++;
}else{
c[j].x=b[pb].x;
c[j].y=b[pb].y;
c[j].data=-b[pb].data;
pb++;
}
j++;
}else if(a[pa].x<b[pb].x){
c[j].x=a[pa].x;
c[j].y=a[pa].y;
c[j].data=a[pa].data;
pa++;
j++;
}else{
c[j].x=b[pb].x;
c[j].y=b[pb].y;
c[j].data=-b[pb].data;
pb++;
j++;
}
}
cnt=j;
if(pa>=t1&&pb>=t2)return;
else if(pa>=t1){
for(;pb<t2;j++,pb++){
c[j].x=b[pb].x;
c[j].y=b[pb].y;
c[j].data=-b[pb].data;
}
}else{
for(;pa<t1;j++,pa++){
c[j].x=a[pa].x;
c[j].y=a[pa].y;
c[j].data=a[pa].data;
}
}
cnt=j;
}
}
void print(){
printf("%d %d %d\n",N1,M1,cnt);
for(int i=0;i<cnt;i++){
printf("%d %d %d\n",c[i].x,c[i].y,c[i].data);
}
}
int main(){
scanf("%d%d%d",&N1,&M1,&t1);
int x,y;
long long data;
for(int i=0;i<t1;i++){
scanf("%d%d%d",&x,&y,&data);
a[i].x=x;
a[i].y=y;
a[i].data=data;
}
scanf("%d%d%d",&N2,&M2,&t2);
for(int i=0;i<t2;i++){
scanf("%d%d%d",&x,&y,&data);
b[i].x=x;
b[i].y=y;
b[i].data=data;
}
work();
print();
return 0;
}
T3: text editing

This question is the application of dance chain.
The code is as follows:
#include<iostream>
#include<cstdio>
using namespace std;
int t; //There are t sets of test data
int n,m;
int Left[10000+8],Right[10000+8];
// Left[i] indicates the number of the previous Chinese character of the Chinese character numbered I
///Right[i] indicates the number of the next Chinese character of the Chinese character numbered I
int main(){
scanf("%d",&t);
char s;
int x,y;
for(int i=0;i<t;i++){
scanf("%d%d",&n,&m);
for(int j=1;j<=n;j++){ //initialization
Left[j]=j-1;
Right[j]=j+1;
}
Left[1]=n;
Right[n]=1;
for(int j=0;j<m;j++){
scanf("\n%c%d%d",&s,&x,&y);
/* When reading in, add carriage return in front, otherwise the carriage return of the previous operation will be read in as an operand. Or you can read the string directly, because when you use% s to read the string, blank characters such as carriage return and space will be automatically ignored.*/
if(s=='A'){
Right[Left[x]]=Right[x]; //Dance away from the original chain
Left[Right[x]]=Left[x];
Right[Left[y]]=x;
Left[x]=Left[y];
Left[y]=x;
Right[x]=y;
}else if(s=='B'){
Right[Left[x]]=Right[x]; //Dance away from the original chain
Left[Right[x]]=Left[x];
Left[Right[y]]=x;
Right[x]=Right[y];
Right[y]=x;
Left[x]=y;
}else{
if(x==0){
printf("%d\n",Left[y]);
}else{
printf("%d\n",Right[y]);
}
}
}
}
return 0;
}
T4: happiness index

Use the Day array to store the happiness value of each Day, and Pre to store the prefix and of the happiness value. For each element Day[i], find the interval with Day[i] as the minimum value, that is, find the first smaller element on the left and right of Day[i]. Therefore, we can use monotone stack to maintain, and then use arrays L[i] and R[i] to store the subscript of the first element smaller than it on the left and right respectively, and finally compare it. However, it should be noted that the topic requires the longest and leftmost interval, so it should be judged separately. (use long long)
The code is as follows:
#include<iostream>
#include<cstdio>
#include<stack>
#define MAX 10000000
using namespace std;
int n;
long long ans;
int FL,FR;
int L[MAX],R[MAX];
long long Day[MAX],Pre[MAX];
stack<int> s; //s storage subscript
int main(){
scanf("%d",&n);
for(int i=1;i<=n;i++){
scanf("%lld",&Day[i]);
Pre[i]=Pre[i-1]+Day[i];
}
Day[0]=-100;Day[n+1]=-100;
s.push(0);
for(int i=1;i<=n;i++){
while(Day[s.top()]>=Day[i]) s.pop();
L[i]=s.top();
s.push(i);
}
while(!s.empty())s.pop();
s.push(n+1);
for(int i=n;i>=1;i--){
while(Day[s.top()]>=Day[i])s.pop();
R[i]=s.top();
s.push(i);
}
ans=Day[1];
FL=FR=1;
for(int i=1;i<=n;i++){
long long tmp=(Pre[R[i]-1]-Pre[L[i]])*Day[i];
if(ans<tmp){
ans=tmp;
FL=L[i]+1;
FR=R[i]-1;
}else if(ans==tmp){
int dl=L[i]+1;
int dr=R[i]-1;
if(FR-FL<dr-dl){ //Longest judgment
FR=dr;
FL=dl;
}else if(dr-dl==FR-FL){ //Judge leftmost
if(dl<FL){
FL=dl;
FR=dr;
}
}
}
}
printf("%lld\n%d %d",ans,FL,FR);
return 0;
}