background
Recently, I was working on improving the performance of the client performance test. I would compare the performance data of the current version with the performance data of the previous version, and then put the comparison conclusion and data on the docx document to automatically generate a performance report. I learned the relevant operations of Python docx, as recorded below.
Basic introduction
Python docx is a python library used to create and modify Microsoft Word. It provides a full set of word operations. It is the most commonly used word tool. Documents can be changed, including paragraphs, page breaks, tables, pictures, titles, styles, etc. almost all the functions commonly used in word documents are included. Only docx files can be parsed, but doc files cannot be parsed. Python docx regards the whole article as a Document object, and its basic structure is as follows:
- Each Document contains many Paragraph objects representing "paragraphs", which are stored in Document In paragraphs
- Each Paragraph has many Run objects representing "inline elements", which are stored in Paragraph runs
Some basic uses
from docx import Document as Doc from docx.document import Document import os doc: Document = Doc() word_path = os.getcwd() doc.save(os.path.join(word_path, 'demo.docx'))
In the above code, we introduce the core object Document of Python docx, which corresponds to a word file, through which all the contents in word can be operated.
- title
doc.add_heading(text="Primary title", level=1) doc.add_heading(text="Secondary title", level=2)
The text parameter specifies the text of the title, and the level specifies the level of the title, whether the first level title or the second level title. If the level is equal to 0, the title will be regarded as the title of the document, and the level supports 1-9 levels.
- paragraph
doc.add_paragraph("Test paragraph I")
paragraph = doc.add_paragraph()
paragraph.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER
run = paragraph.add_run("Test paragraph 2")
run.bold = True
run.font.name = u'Song typeface'There are two ways to add paragraphs, as above: use doc add_ Paragraph ("test paragraph 1") is added directly, and the other is added through add_run to add, and you can manipulate various attributes of text, such as bold, font, color and so on
This paper focuses on operating tables
establish
table = doc.add_table(2, 3, style="Table Grid")
Call add_table method and pass in the number of rows and columns to complete the creation of a table, as shown in the following figure:

Add header
['scenario', 'version', 'memory', 'CPU', 'Caton number', 'GPU'] suppose that our header content is stored in such a list
columns = ['scene', 'edition', 'Memory', 'CPU', 'Caton number', 'GPU']
table = doc.add_table(1, len(columns), style="Table Grid")
for i in range(len(columns)):
row = table.rows[0]
row.cells[i].text = columns[i]The number of columns in the table is determined according to the length of the header. At present, we don't know how many rows there are, so we only need to add one row.
table.rows can get all rows, row Cells can all cells in the row, and then the cell content can be filled by assigning a value to the text attribute. The effects are as follows:

We generally need to add a background color to the contents of the header to make the overall layout look better
columns = ['scene', 'edition', 'Memory', 'CPU', 'Caton number', 'GPU']
table = doc.add_table(1, len(columns), style="Table Grid")
for i in range(len(columns)):
row = table.rows[0]
row.cells[i].text = columns[i]
shading = parse_xml(r'<w:shd {} w:fill="{bgColor}"/>'.format(nsdecls('w'), bgColor='129563'))
row.cells[i]._tc.get_or_add_tcPr().append(shading)Define a background color through xml, and then call get_or_add_tcPr, so adding Beijing color is successful.

reminder:
shading = parse_xml(r'<w:shd {} w:fill="{bgColor}"/>'.format(nsdecls('w'), bgColor='129563'))
Here, a shading is parsed first. If this shading is added to each cell, only the last cell can have a background color. Therefore, you need to re parse every time you add it.
merge cell
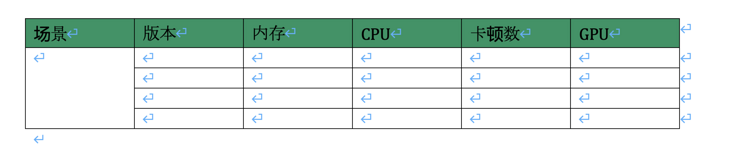
For example, we added four rows to merge the first column of each row. The code is as follows:
a = table.add_row() b = table.add_row() c = table.add_row() d = table.add_row() d.cells[0].merge(a.cells[0])
The actual effect is shown in the figure below. It's used here_ The merge method of the Cell object implements Cell merging. Here, 0 is the index of the first Cell.
Add color to cell font
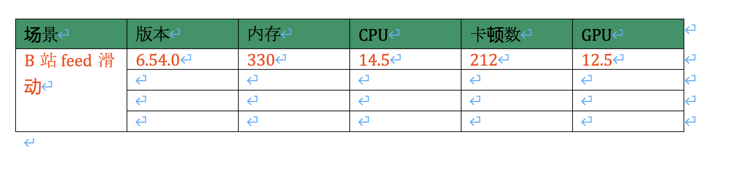
The principle of adding color to cell text is the same as that of operating paragraph text. Both are operated by run. The code is as follows:
data = ['B station feed slide', '6.54.0', 330, 14.5, 212, 12.5]
for i in range(len(columns)):
run = a.cells[i].paragraphs[0].add_run(str(data[i]))
run.font.color.rgb = RGBColor(255, 69, 0) # This is red RGBThe effects are as follows:
Friendly tips:
Note that when adding content to a cell, it must be in the form of a string, or an error will be reported
Set page paper size
The document generated by Python docx is A4 by default. If you want to change it to A3 or other sizes, you can see here
document.sections[0].page_height = Cm(42) # Sets the height of the A3 paper document.sections[0].page_width = Cm(29.7) # Sets the width of the A3 paper