Introduction to pandas
numpy can help us with numeric data, but that's not enough. Many times, our data includes not only numeric values, but also strings, time series, and so on.
That's where we need pandas to help us with them.
What is Pandas?
The Pandas name comes from panel data
Pandas is a powerful toolset for analyzing structured data, built on NumPy, which provides advanced data structures and data manipulation tools. It is one of the important factors that make Python a powerful and efficient data analysis environment.
.A powerful set of tools for analyzing and manipulating large structured datasets
.Foundation is NumPy, which provides high-performance matrix operations
.Provides a large number of functions and methods to process data quickly and easily
.Apply to data mining, data analysis
.Provides data cleaning capabilities
Data structure of pandas
The pandas library has two important data structures: Series [ˈsɪəriːz] Series and DataFrame Frame [fre]ɪm]Framework
Series object
Let's start with Series, because Pandas are built on NumPy, so we can refer to one-dimensional array objects to understand Series objects.
import numpy as np
import pandas as pd
list_1=list(range(1,6))
arr=np.array(list_1)
ser=pd.Series(list_1)
print(f'This is a one-dimensional array of one to five, with only data elements:\n{arr}')
print(f'This is made up of one to five Series Object, by data elements and their indexes:\n{ser}')

So we can better understand the Ndarray and Seres objects.
- Both are collections of data of the same type. The difference is that Ndarray objects can only store numeric data, while Series objects can not store numeric data tightly, but also string, python object and other types, that is, a Series object can contain numeric data, string, python object and so on.
- Both indexes start with 0. The difference is that the index of the Series object starts with 0 by default and can be re-specified, while the index of the Ndarray object cannot be changed.The index of the Series object is displayed in the content, while the index of the Ndarray object is not.
Series object creation:
pandas. Series ( data , index , dtype , name , copy )
- Data: As long as it is data, when the type of data is a dictionary, the key is index and the value is content.
- Index: Starts from zero by default, and when an index is specified, the number of indexes is equal to the number of data elements.
- dtype: The data type of the element, which is determined by default
- Name: Sets the name of the index and element value
Series. name=str Sets the name of the element value
Series. index.name=str Sets the name of the index - Copy: copy data, default is False
import numpy as np
import pandas as pd
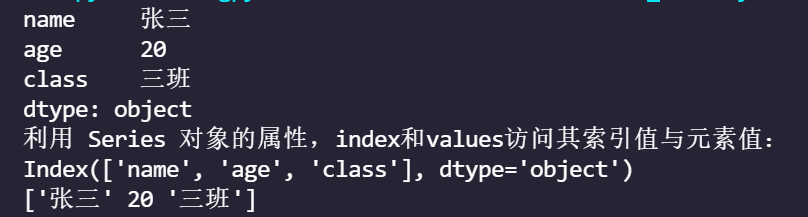
data={'name':'Zhang San','age':20,'class':'Class 3'}
ser=pd.Series(data)
print(ser)
print('utilize Series The properties of the object, index and values Access its index and element values:')
print(ser.index)
print(ser.values)
Basic use of Series - - Find missing values
Series. isnull ( )
Series. notnull ( )
import numpy as np
import pandas as pd
from pandas.core.indexes.base import Index
data={'name':'Zhang San','age':20,'class':'Class 3'}
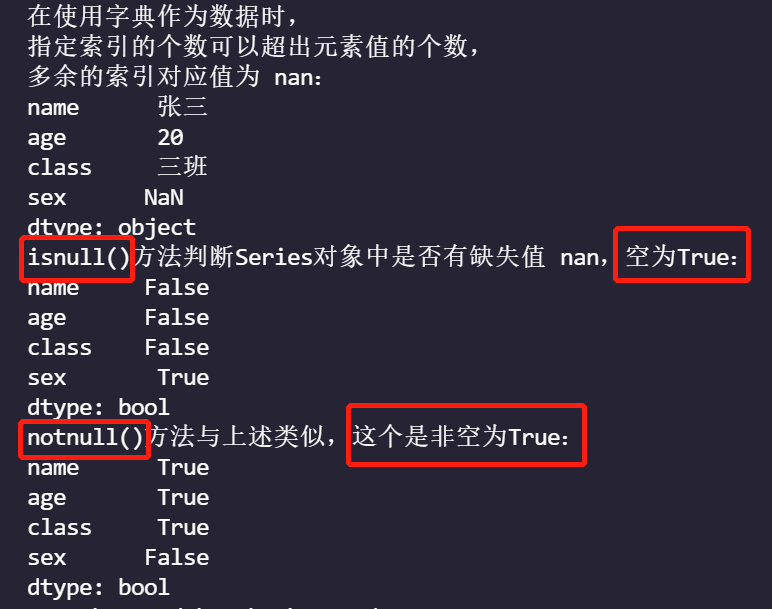
string='''When using dictionaries as data,
The number of indexes specified can exceed the number of element values.
Redundant Index Correspondence Value nan: '''
print(string)
ser=pd.Series(data,index=['name','age','class','sex'])
print(ser)
print(f'isnull()Method Judgment Series Is there a missing value in the object nan,Empty is True: \n{ser.isnull()}')
print(f'notnull()The method is similar to the above, this is a non-empty True: \n{ser.notnull()}')
Basic Use of Series - Get Elements by Index
Because Pandas are built on NumPy, pandas can use the operation of arrays, referencing the index of the array to get element values.
import numpy as np
import pandas as pd
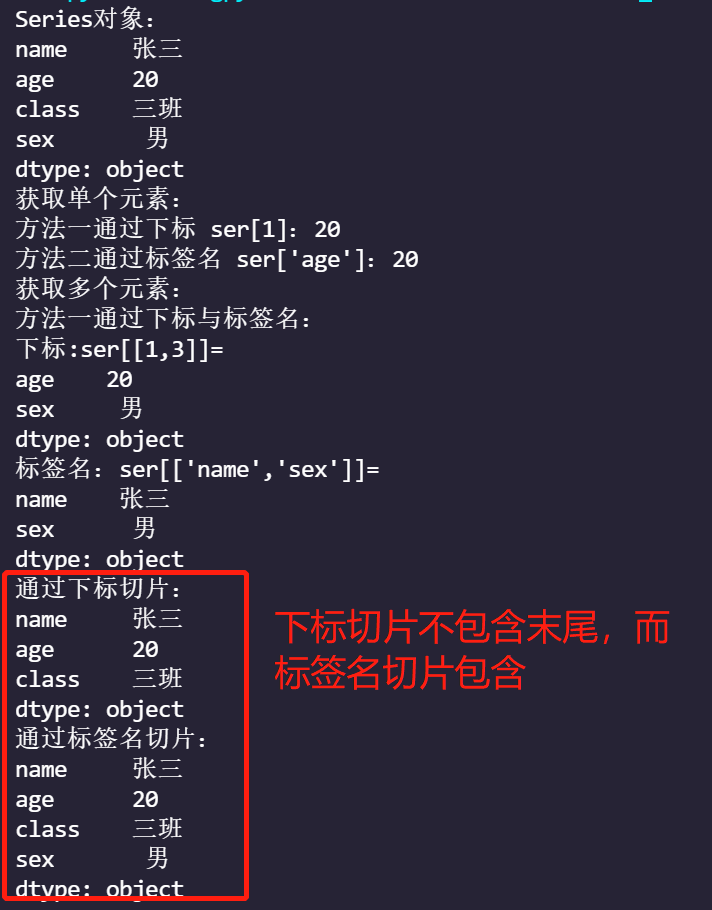
data={'name':'Zhang San','age':20,'class':'Class 3','sex':'male'}
ser=pd.Series(data)
print(f'Series Object:\n{ser}')
print('Get a single element:')
print(f'Method 1 passes through Subscripts ser[1]: {ser[1]}')
print(f"Method 2 uses label names ser['age']: {ser['age']}")
print('Get multiple elements:')
print(f'Method one is signed by subscripts and labels:\n subscript:ser[[1,3]]=\n{ser[[1,3]]}')
print(f"Label name: ser[['name','sex']]=\n{ser[['name','sex']]}")
print(f"Slice by subscript:\n{ser[0:3]}")
print(f"Slice by tag name:\n{ser['name':'sex']}")
Series. head ( n : int = 5)
Series. tail ( n : int = 5)
Take n rows from the front;N rows from the back, default n = 5
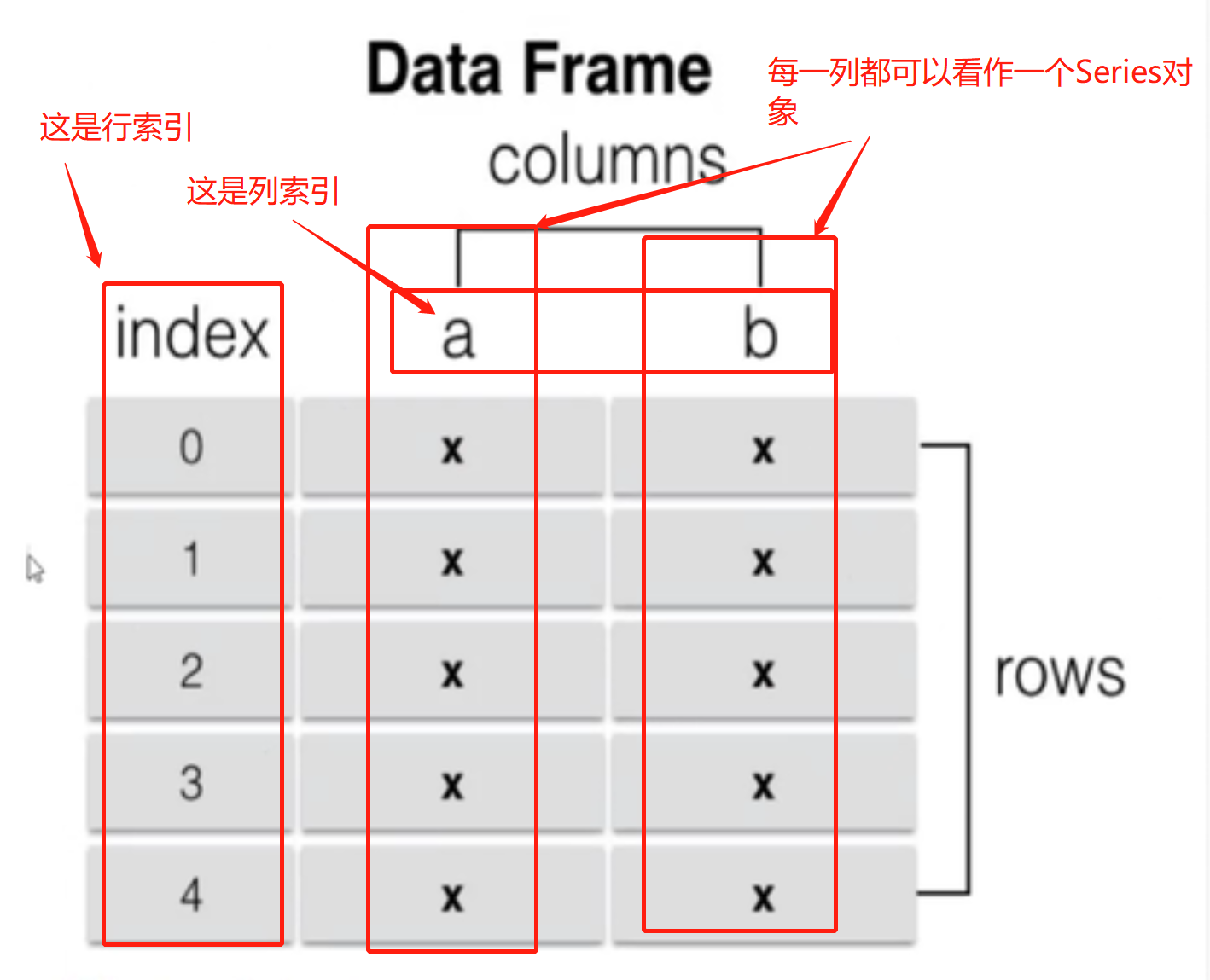
DataFrame Object
A DataFrame is a tabular data structure that contains an ordered set of columns, each of which can be of different value types (numeric, string, Boolean).The DataFrame has both row and column indexes and can be thought of as a dictionary of Series (with one index).You can refer to excel tables
The DataFrame is constructed as follows:
pandas.DataFrame( data, index, columns, dtype, copy)
Parameter description:
- Data: A set of data (ndarray, series, map, lists, dict, and so on).
- Index: The index value, or row label, defaults to RangeIndex (0, 1, 2,..., n).
- columns: column label, default is RangeIndex (0, 1, 2,..., n).
- dtype: Data type.
- copy: copy the data, defaulting to False.
The Pandas DataFrame is a two-dimensional array structure, similar to a two-dimensional array.
Construction of DataFrame
- data is a dictionary type:
Key as index and value as content.
A dictionary consisting of arrays, lists, or tuples;
import numpy as np
import pandas as pd
data={'a':[1,2,3,4],
'b':(4,5,6,7),
'c':np.arange(9,13)}
frame=pd.DataFrame(data)
print(f'DataFrame Object:\n{frame}')
string='''Through attributes index View row index of object;
columns View the object column index;
values View the value of the object.'''
print(string)
print(f'Row index:{frame.index}')
print(f'Column index:{frame.columns}')
print(f'Element value:\n{frame.values}')
print('Specify index:')
frame=pd.DataFrame(data,index=['A','B','C','D'],columns=['a','b','c','d'])
print(frame)
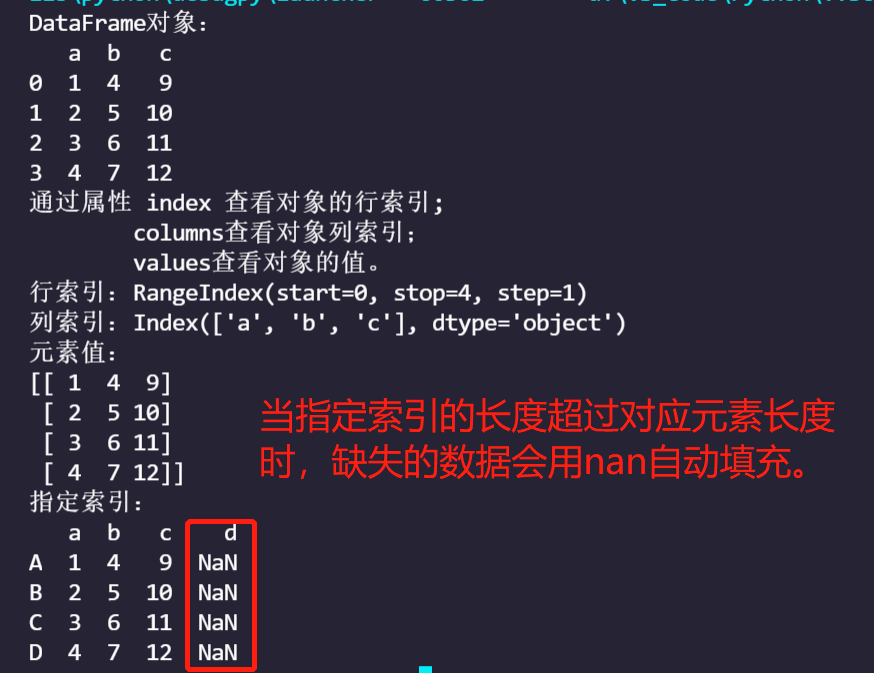
A Dictionary of Series objects;
import numpy as np
import pandas as pd
data={
'a':pd.Series(np.arange(3)),
'b':pd.Series(np.arange(3,5))
}
frame=pd.DataFrame(data)
print(frame)
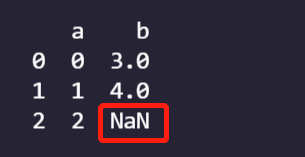
A dictionary made up of dictionaries;
import numpy as np
import pandas as pd
data={
'a':{'apple':3.6,'banana':5.6},
'b':{'apple':3,'banana':5},
'c':{'apple':3.6}
}
frame=pd.DataFrame(data)
print(frame)
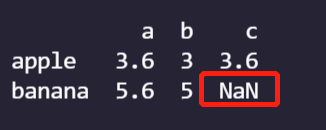
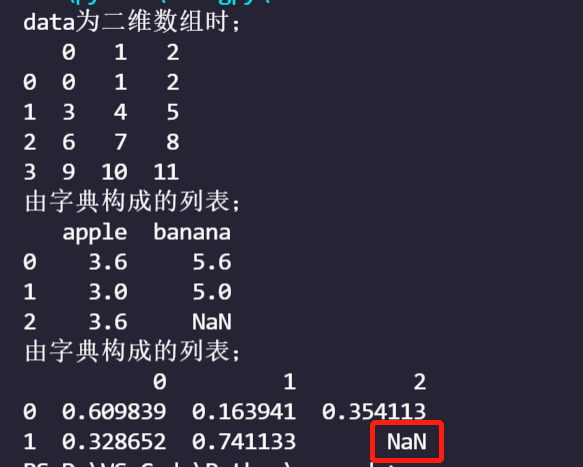
- data is a list type:
When data is a two-dimensional array;
A list of Series objects;
A list of dictionaries;
import numpy as np
import pandas as pd
arr=np.arange(12).reshape(4,3)
frame_arr=pd.DataFrame(arr)
print('data When it is a two-dimensional array;')
print(frame_arr)
list_dic=[{'apple':3.6,'banana':5.6},{'apple':3,'banana':5},{'apple':3.6}]
frame_list_dic=pd.DataFrame(list_dic)
print('A list of dictionaries;')
print(frame_list_dic)
list_ser=[pd.Series(np.random.rand(3)),pd.Series(np.random.rand(2))]
frame_list_ser=pd.DataFrame(list_ser)
print(f'A list of dictionaries;\n{frame_list_ser}')
Basic usage of DataFrame
- Transpose
- Get column data from column index (Series type)
- Add column data
- Delete Columns
Not Ended!!!!