Introduction to C++11
In 2003, the C + + Standard Committee submitted a Technical Corrigendum (TC1) so that the name of C++03 has replaced the name of C++98 as the latest C + + standard before C++11. However, TC1 mainly fixes the loopholes in the C++98 Standard, and the core part of the language has not been changed. Therefore, people habitually combine the two standards as the C++98/03 Standard. From C++0x to C++11, the C + + standard has been sharpened for 10 years, and the second real standard is too late. Compared with C++98/03, C++11 has brought a considerable number of changes, including about 140 new features and the correction of about 600 defects in C++03 Standard, which makes C++11 more like a new language bred from C++98/03. In comparison, C++11 can be better used for system development and library development. The syntax is more extensive and simplified, more stable and secure. It not only has more powerful functions, but also can improve the development efficiency of programmers
List initialization
Initialization of {} in C++98
In C++98, the standard allows the use of curly braces {} to set the unified list initial value of array elements. For example:
int array1[] = {1,2,3,4,5};
int array2[5] = {0};
For some custom types, such initialization cannot be used. For example:
vector<int> v{1,2,3,4,5};
It cannot be compiled. As a result, each time you define a vector, you need to define the vector first, and then use the loop to assign the initial value to it. It is very important
inconvenient. C++11 expands the scope of use of the list enclosed in braces (initialization list), so that it can be used for all built-in types and user-defined
When using the initialization list, you can add an equal sign (=) or not
List initialization of built-in types
int main()
{
// Built in type variable
int x1 = { 10 };
int x2{ 10 };
int x3 = 1 + 2;
int x4 = { 1 + 2 };
int x5{ 1 + 2 };
// array
int arr1[5]{ 1,2,3,4,5 };
int arr2[]{ 1,2,3,4,5 };
// Dynamic array, not supported in C++98
int* arr3 = new int[5]{ 1,2,3,4,5 };
// Standard container
vector<int> v{ 1,2,3,4,5 };
map<int, int> m{ {1,1}, {2,2,},{3,3},{4,4} };
return 0;
}
Note: the equal sign can be used before {} for list initialization, and its effect is no different from that of not using =
List initialization of custom types
-
The standard library supports list initialization of a single object
class Point { public: Point(int x = 0, int y = 0) : _x(x), _y(y) {} private: int _x; int _y; }; int main() { Pointer p{ 1, 2 }; return 0; } -
List initialization of multiple objects
If multiple objects want to support list initialization, you need to add an initializer to this class (template class)_ The constructor of the list type parameter is
Yes. Note: initializer_list is a class template customized by the system. There are three main methods in this class template: begin() and end() iterators
And the method to obtain the number of elements in the interval size()#include <initializer_list> template<class T> class Vector { public: // ... Vector(initializer_list<T> l) : _capacity(l.size()), _size(0) { _array = new T[_capacity]; for (auto e : l) _array[_size++] = e; } Vector<T>& operator=(initializer_list<T> l) { delete[] _array; size_t i = 0; for (auto e : l) _array[i++] = e; return *this; } // ... private: T* _array; size_t _capacity; size_t _size; };
Variable type derivation
Why type derivation is needed
When defining a variable, you must first give the actual type of the variable before the compiler can define it. However, in some cases, you may not know how to give the actual type, or the type writing is particularly complex, such as
#include <map>
#include <string>
int main()
{
short a = 32670;
short b = 32670;
// If c is given as short, it will cause data loss. If the compiler can deduce the actual type of c according to the result of a+b, there will be no problem
short c = a + b;
std::map<std::string, std::string> m{ {"apple", "Apple"}, {"banana","Banana"} };
// Iterators are used to traverse containers. Iterator types are too cumbersome
std::map<std::string, std::string>::iterator it = m.begin();
while (it != m.end())
{
cout << it->first << " " << it->second << endl;
++it;
}
return 0;
}
In C++11, auto can be used to deduce the actual type of variable according to the type of variable initialization expression, which can provide a lot of convenience for program writing. By changing the type of c and it in the program to auto, the program can be compiled and more concise
decltype type derivation
Why decltype
The premise of using auto is that the type declared by auto must be initialized, otherwise the compiler cannot deduce the actual type of auto. However, sometimes it may be necessary to deduce according to the type of the result after the expression is run, because the code will not run during compilation, and there is nothing auto can do at this time
template<class T1, class T2>
T1 Add(const T1& left, const T2& right)
{
return left + right;
}
If the actual type of the result after addition can be used as the return value type of the function, there will be no error, but the actual type of the result can be known only after the program runs, that is, RTTI(Run-Time Type Identification).
RTTI is indeed supported in C++98:
-
typeid can only view types and cannot define types with its result class
Use of typeid:
typeid can take out the type of variable and return the type name in string form through the name interface. But typeid cannot be used to define variables
The decltype mentioned below is OK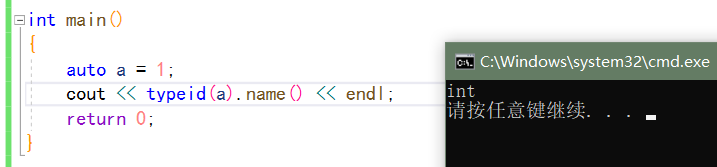
-
dynamic_cast can only be applied to inheritance systems with virtual functions
The defect of runtime type recognition is to reduce the efficiency of program operation
decltype
decltype is the type used to define variables based on the actual type of the expression, such as:
-
Deduce the expression type as the definition type of the variable
int main() { int a = 10; int b = 20; // Deduce the actual type of a+b with decltype as the type of c decltype(a + b) c; cout << typeid(c).name() << endl; return 0; } -
Deduce the type of the return value of the function
void* GetMemory(size_t size) { return malloc(size); } int main() { // If there are no parameters, the type of function is deduced cout << typeid(decltype(GetMemory)).name() << endl; // If there is a parameter list, the type of the return value of the function is deduced. Note: This is only a deduction and the function will not be executed cout << typeid(decltype(GetMemory(0))).name() <<endl; return 0; }
auto and range for
auto simplifies the writing of some codes
For example, the following code:
int main()
{
//Suppose we don't expand std
std::map<std::string, std::string> m = { {"Apple", "apple"}, {"Banana", "banana"} };
//Ergodic m
//std::map<std::string, std::string>::iterator it = m.begin();
auto it = m.begin();
while (it != m.end())
{
std::cout << it->first << ":" << it->second << std::endl;
++it;
}
return 0;
}
Obviously, using auto directly is much simpler than using type names
Note: auto does not support as a formal parameter and return value type
The above traversal can be realized by returning for:
for (const auto& e : m)//Here, auto and range for are used together, which makes the code much simpler
{
std::cout << e.first << ":" << e.second << std::endl;
}
The bottom layer of the range for is implemented by the iterator. The array can also use the range for. The pointer is a natural iterator
int main()
{
int a[5] = { 1, 2, 3 ,4 ,5 };
for (const auto& e : a)
{
cout << e << " ";
}
cout << endl;
return 0;
}
final and override
Final is used to modify a class. The modified class becomes the final class and cannot be inherited

final can also modify virtual functions, which cannot be rewritten

override can check whether subclasses rewrite virtual functions. If not, an error will be reported
class Car{
public:
virtual void Drive()
{}
};
class Benz :public Car {
public:
virtual void Drive() override
{
cout << "Benz-comfortable" << endl;
}
};
New container
C++98
string/vector/list/deque/map/bitset + stack/queue/priority_queue
C++11 new container
Array (fixed length array): it is rarely used in practice. Disadvantages: the space of fixed length + data storage is on the stack, and the space of the stack is not large
forward_ List (single linked list): it is rarely used in practice. Disadvantage: it does not support tail insertion and tail deletion + insert, and the data is also behind the current position
unordered_map/unordered_set: recommended because they are more efficient than map/set
Default member function control
In C + +, for empty classes, the compiler will generate some default member functions, such as constructor, copy constructor, operator overload, destructor and & and const & overload, mobile construct, mobile copy construct and so on. If explicitly defined in a class, the compiler will not regenerate the default version. Sometimes such rules may be forgotten. The most common is to declare a constructor with parameters. If necessary, you need to define a version without parameters to instantiate an object without parameters. And sometimes the compiler will generate, sometimes not, which is easy to cause confusion, so C++11 allows the programmer to control whether the compiler generation is required
Explicit default function
In C++11, you can add = default when defining or declaring the default function, so as to explicitly instruct the compiler to generate the default version of the function. The function modified with = default is called the explicit default function
class A
{
public:
A(int a) : _a(a)
{}
//If we don't specify it explicitly, we can't use the default constructor, because we wrote the constructor ourselves
// Explicit default constructor, generated by compiler
A() = default;
// Declare in class and let the compiler generate a default assignment operator overload when defined outside the class
A& operator=(const A& a);
private:
int _a;
};
A& A::operator=(const A& a) = default;
int main()
{
A a1(10);
A a2;
a2 = a1;
return 0;
}
If compiler generation is not explicitly specified:
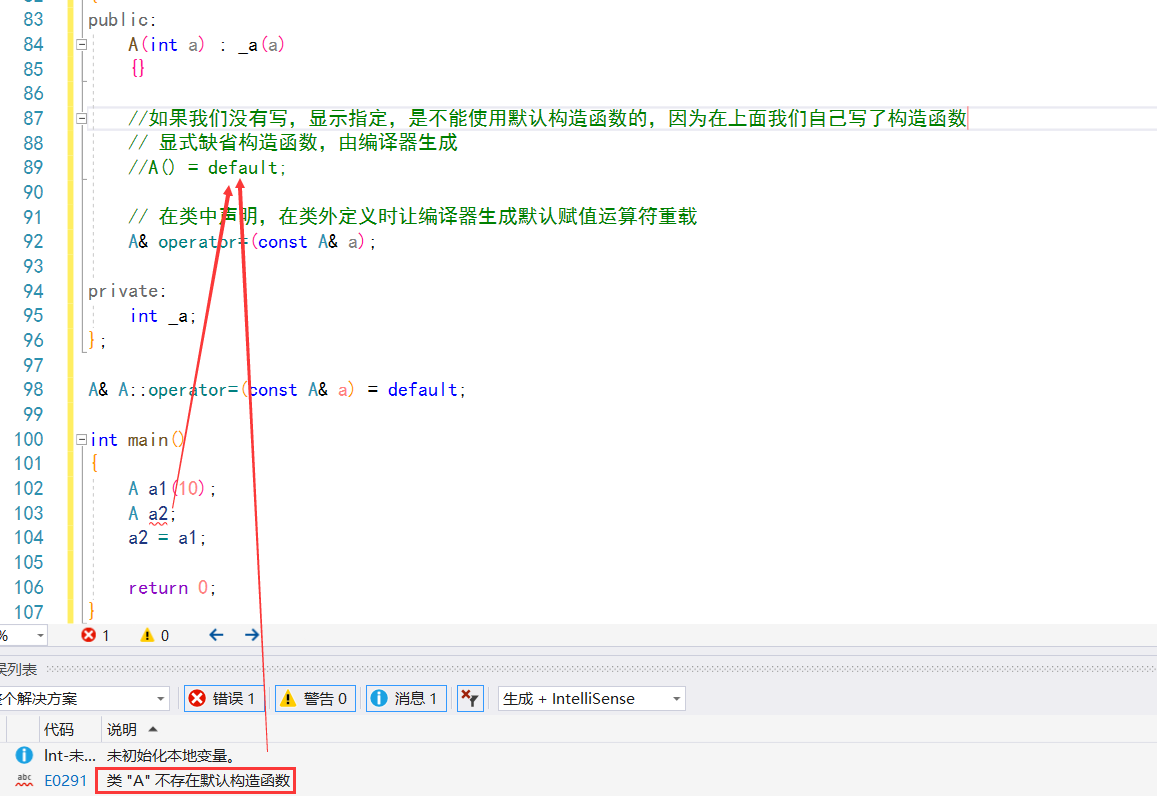
Note: if the constructor defined by ourselves is the default constructor (no parameter or all default), only one default constructor can be selected. If it is not defined by ourselves or generated by the compiler itself
Delete default function
If you want to limit the generation of some default functions, in C++98, the function is set to private and only declared undefined. In this way, an error will be reported as long as others want to call. It is simpler in C++11. Just add = delete to the function declaration. This syntax instructs the compiler not to generate the default version of the corresponding function. The function modified by = delete is called the delete function
class A
{
public:
A(int a) : _a(a)
{}
// Prevents the compiler from generating default copy constructors and assignment operator overloads
A(const A&) = delete;
A& operator(const A&) = delete;
private:
int _a;
};
int main()
{
A a1(10);
// Compilation failed because the class does not have a copy constructor
//A a2(a1);
// Compilation failed because the class has no assignment operator overload
A a3(20);
a3 = a2;
return 0;
}
Note: avoid deleting functions together with explicit
rvalue reference
Right value reference concept
The concept of reference is put forward in C++98. Reference is alias. The reference variable shares the same memory space with its reference entity, and the bottom layer of reference is realized through pointer. Using reference can improve the readability of the program.
void Swap(int& left, int& right)
{
int temp = left;
left = right;
right = temp;
}
int main()
{
int a = 10;
int b = 20;
Swap(a, b);
}
In order to improve the running efficiency of the program, the right value reference is introduced in C++11. The right value reference is also an alias, but it can only refer to the right value
int Add(int a, int b)
{
return a + b;
}
int main()
{
const int&& ra = 10;
// The return value of the reference function is a temporary variable, which is a right value
int&& rRet = Add(10, 20);
return 0;
}
In order to distinguish it from the reference in C++98, C++11 calls this method right value reference
Left and right values
Left value and right value are concepts in C language, but the C standard does not give a strict way to distinguish. It is generally believed that those that can be placed on the = left or can take the address are called left value, and those that can only be placed on the = right or cannot take the address are called right value, but they are not necessarily completely correct
int g_a = 10;
// The return value of the function is a reference
int& GetG_A()
{
return g_a;
}
int main()
{
int a = 10;
int b = 20;
// Both a and b are left values, and b can be on the left or right of =,
// Note: the left value can be placed either on the left side of =, or on the right side of =
a = b;
b = a;
const int c = 30;
// Compilation failed. c is const constant. It is read-only and cannot be modified
//c = a;
// Because c can be addressed, c is not strictly an lvalue
cout << &c << endl;
// Compilation failure: because the result of b+1 is a temporary variable without a specific name and address, it is a right value
//b + 1 = 20;
GetG_A() = 100;
return 0;
}
Therefore, the distinction between left value and right value is not very good. It is generally believed that:
- Ordinary type variables, because they have a name and can take an address, are considered to be lvalues.
- const modifier is a constant variable that cannot be modified and is of read-only type. The theory should treat it as an R-value, but because it can take the address (if only
The compiler does not make room for the definition of const type constant. If the constant is addressed, the compiler will make room for it),
C++11 considers it to be an lvalue. - If the result of the expression is a temporary variable or object, it is considered to be an R-value.
- If the result of an expression run or a single variable is a reference, it is considered to be an lvalue.
Summary:
- The left or right value cannot be judged simply by whether it can be placed on the left or right of = or by taking the address. It should be determined according to the result of the expression or the nature of the variable
Judgment, such as the above: c constant - The expression that can be referenced must be used as a reference, otherwise it is often referenced.
C++11 strictly distinguishes the right value:
- Pure right value in C language: constant or temporary object of basic type, such as a+b, 100
- Set value: a temporary object of custom type. For example, the intermediate result of the expression and the function are returned by value.
Comparison between reference and right value reference
The difference between common reference and const reference in C++98 in reference entity:
int main()
{
// Common type references can only reference left values, not right values
int a = 10;
int& ra1 = a; // ra is the alias of a
//int& ra2 = 10; // Compilation failed because 10 is an R-value
const int& ra3 = 10;
const int& ra4 = a; // const reference to lvalue reference
return 0;
}
Note: ordinary references can only refer to left values, not right values. const references can refer to both left and right values.
R-value reference in C++11: only r-values can be referenced. Generally, l-values cannot be referenced directly
int main()
{
// 10 pure right value, originally just a symbol, there is no specific space,
// The R-value refers to the variable r1. During the definition process, the compiler generates a temporary variable, and r1 actually refers to the temporary variable
int&& r1 = 10;
r1 = 100;
int a = 10;
int&& r2 = a; // Compilation failure: right value reference cannot refer to left value
return 0;
}
Question: since the const type reference in C++98 can reference both left and right values, why should C++11 put forward the right value reference in a complex way?
Returns the defect of the object as a value
If resource management is involved in a class, the user must explicitly provide copy construction, assignment operator overload and destructor, otherwise the compiler will automatically generate a default. If copy objects or mutual assignment between objects are encountered, an error will occur, such as:
class String
{
public:
String(const char* str = "")
{
if (nullptr == str)
str = "";
_str = new char[strlen(str) + 1];
strcpy(_str, str);
}
String(const String& s)
: _str(new char[strlen(s._str) + 1])
{
strcpy(_str, s._str);
}
String& operator=(const String& s)
{
if (this != &s)
{
char* pTemp = new char[strlen(s._str) + 1];
strcpy(pTemp, s._str);
delete[] _str;
_str = pTemp;
}
return *this;
}
String operator+(const String& s)
{
char* pTemp = new char[strlen(_str) + strlen(s._str) + 1];
strcpy(pTemp, _str);
strcpy(pTemp + strlen(_str), s._str);
String strRet(pTemp);
return strRet;
}
~String()
{
if (_str) delete[] _str;
}
private:
char* _str;
};
int main()
{
String s1("hello");
String s2("world");
String s3(s1 + s2);
return 0;
}
There seems to be nothing wrong with the above code, but there is one unsatisfactory aspect:

In operator +, when strRet returns by value, a temporary object must be created. After the temporary object is created, strRet is destroyed. Finally, s3 is constructed with the returned temporary object. After s3 is constructed, the temporary object is destroyed. After careful observation, it will be found that strRet, temporary object and s3 each object has its own independent space, and the contents stored in the space are the same, which is equivalent to creating three objects with exactly the same contents. It is a waste of space, the efficiency of the program will be reduced, and the temporary object does not play a great role. Can we optimize this situation?
Mobile semantics
C++11 puts forward the concept of mobile semantics, that is, the way to move resources in one object to another object can effectively alleviate this problem
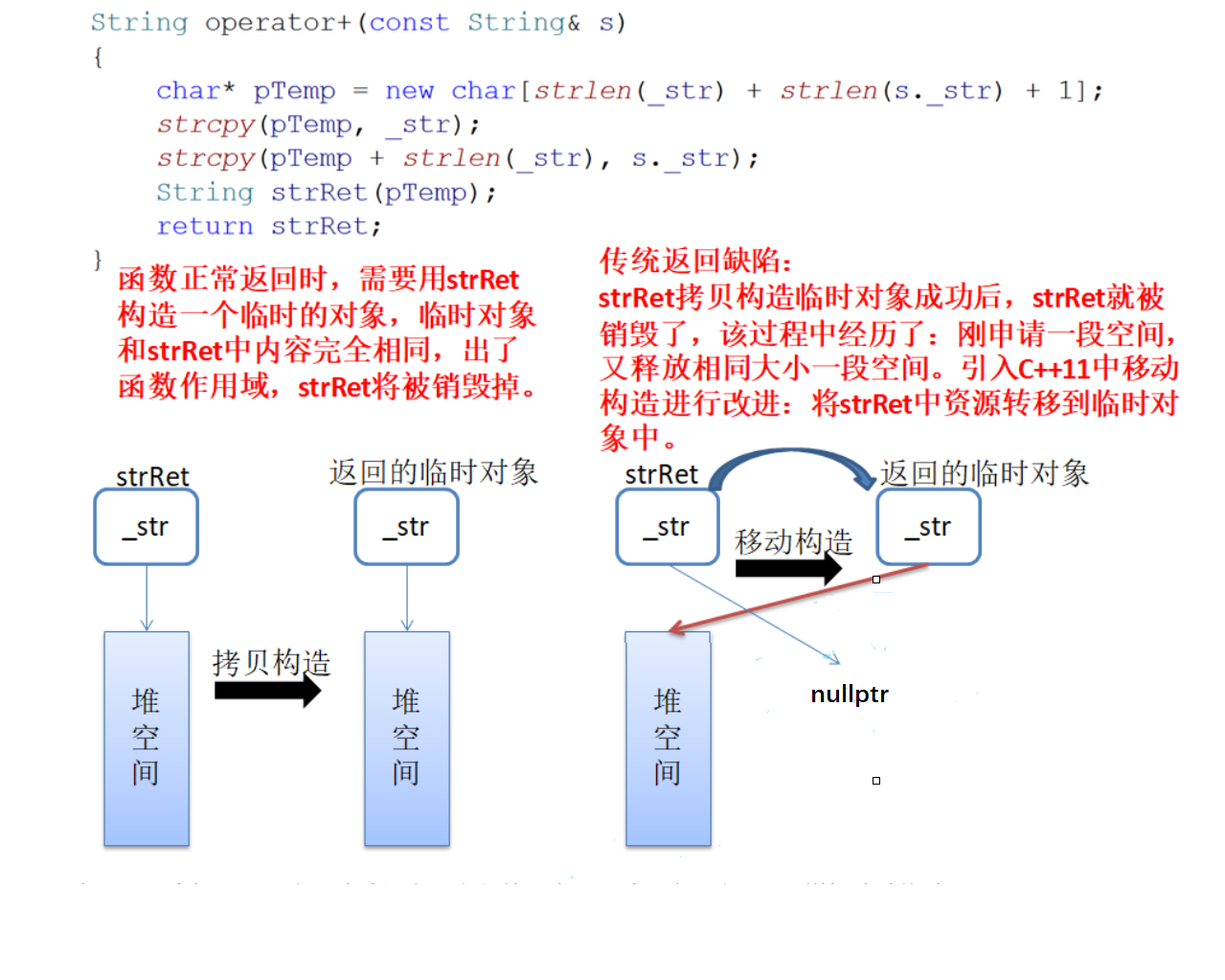
In C++11, if you need to implement mobile semantics, you must use right value reference. The above String class adds a mobile structure:
String(String&& s)
: _str(s._str)
{
s._str = nullptr;
}
Because the life cycle of strRet object ends after the temporary object is created and is about to die, C++11 considers it to be a right value. When constructing a temporary object with strRet, it will adopt mobile construction, that is, the resources in strRet will be transferred to the temporary object. The temporary object is also an R-value. Therefore, when using the temporary object to construct s3, the mobile structure is also adopted to transfer the resources of the temporary object to s3. In the whole process, only one heap memory needs to be created, which not only saves space, but also greatly improves the efficiency of program operation.
Note: in the actual debugging process, the returned value may not be copied to s3, because the compiler will optimize it. When there are two consecutive temporary object constructions, the compiler will optimize it to one

be careful:
- The parameters of the mobile constructor must not be set to the R-value reference of const type, which will lead to the inability of resource transfer and the invalidation of mobile semantics.
- In C++11, the compiler will generate a mobile construct for the class by default, which is a shallow copy. Therefore, when resource management is involved in the class, users must explicitly define their own mobile construct.
The right value refers to the left value
According to the syntax, an R-value reference can only refer to an R-value, but must an R-value reference not refer to an l-value? No, because: in some scenarios, you may really need to use the right value to reference the left value to realize the mobile semantics. When you need to reference an lvalue with an R-value reference, you can convert the lvalue to an R-value through the move function. In C++11, the std::move() function is located in the header file. The name of the function is confusing. It does not move anything. Its only function is to forcibly convert an lvalue into an lvalue reference, and then realize the moving semantics
template<class _Ty>
inline typename remove_reference<_Ty>::type&& move(_Ty&& _Arg) _NOEXCEPT
{
// forward _Arg as movable
return ((typename remove_reference<_Ty>::type&&)_Arg);
}
be careful:
- The life cycle of the transformed lvalue does not change with the transformation of lvalue, that is, the lvalue transformed by std::move will not be destroyed.
- There is also another move function in STL, which is to move elements in a range to another location
int main()
{
String s1("hello world");
String s2(move(s1));
String s3(s2);
return 0;
}
Note: the above code is a classic misuse of the move function, because after move converts s1 into an R-value, the move structure will be used when copying s2. At this time, the resources of s1 will be transferred to s2, and s1 will become an invalid string.
An example of using move:
class Person
{
public:
//structure
Person(char* name, char* sex, int age)
: _name(name)
, _sex(sex)
, _age(age)
{}
//copy construction
Person(const Person& p)
: _name(p._name)
, _sex(p._sex)
, _age(p._age)
{}
#if 0
Person(Person&& p)
: _name(p._name)
, _sex(p._sex)
, _age(p._age)
{}
#else
Person(Person&& p)
: _name(move(p._name))
, _sex(move(p._sex))
, _age(p._age)
{}
#endif
private:
String _name;
String _sex;
int _age;
};
Person GetTempPerson()
{
Person p("prety", "male", 18);
return p;//Take out the Person object in the function
}
int main()
{
Person p(GetTempPerson());
return 0;
}
Summary:
The essence of using right value reference as parameter and return value to reduce copy is to use mobile construction and mobile assignment
The essence of left reference and right value reference is to reduce copy, and the essence of right value reference can be considered to make up for the deficiency of left value reference
Lvalue reference: it solves the problem of copying during parameter transfer and return value
- Make parameters: for example: void push (t x) - > void push (const T & x). What is reduced is the copy in the process of parameter transmission, that is, the copy of formal parameters
- Make the return value: t F2 () - > T & F2 (). What is reduced is the copy of the return process, that is, the copy of the return value temporary object is reduced.
If there is no reference in C + +, the left value cannot be returned. Note: if there is no reference in C + +, the left value cannot be returned.
Right value reference:
-
It solves the problem of moving the X object to the container space inside the push / insert (T & & x) function, taking some STL containers as an example after passing parameters. The premise is that x is a dead value or X is no longer needed.
Void push (T & & x). The copy structure is no longer used in the push. Instead, the structure is moved and X is placed in the container space.
-
Take the return value of the function as the construction: T f2(), call f2 outside the function, copy with the return value of f2 as the object, T ret = f2(), use the right value reference to move the data inside the function into ret, reducing the copy.
Perfect forwarding
Perfect forwarding means that the function is passed to the other function in the function template according to the type of the template parameter in the function template.
void Func(int x)
{
// ......
}
template<typename T>
void PerfectForward(T t)
{
Fun(t);
}
PerfectForward is the template function of forwarding and Func is the actual objective function, but the above forwarding is not perfect. Perfect forwarding is that the objective function always wants to transfer the parameters to the objective function according to the actual type passed to the forwarding function without additional overhead, as if the forwarder does not exist.
The so-called perfection: when a function template passes its own formal parameters to other functions, if the corresponding arguments are lvalues, it should be forwarded to lvalues; If the corresponding argument is an R-value, it should be forwarded as an R-value. This is done to preserve that other functions handle the left and right value attributes of the forwarded parameters differently (for example, copy semantics is implemented when the parameter is left value; move semantics is implemented when the parameter is right value).
C++11 realizes perfect forwarding through the forward function, such as:
void Fun(int& x)
{
cout << "lvalue ref" << endl;
}
void Fun(int&& x)
{
cout << "rvalue ref" << endl;
}
void Fun(const int& x)
{
cout << "const lvalue ref" << endl;
}
void Fun(const int&& x)
{
cout << "const rvalue ref" << endl;
}
template<typename T>
void PerfectForward(T&& t) //Right value references can receive both right and left values
{
Fun(std::forward<T>(t));
}
int main()
{
PerfectForward(10); // rvalue ref
int a;
PerfectForward(a); // lvalue ref
PerfectForward(std::move(a)); // rvalue ref
const int b = 8;
PerfectForward(b); // const lvalue ref
PerfectForward(std::move(b)); // const rvalue ref
return 0;
}
result:

If perfect forwarding is not used, all parameters and types passed into the func function inside PerfectForward will be lost and will be considered as lvalues:
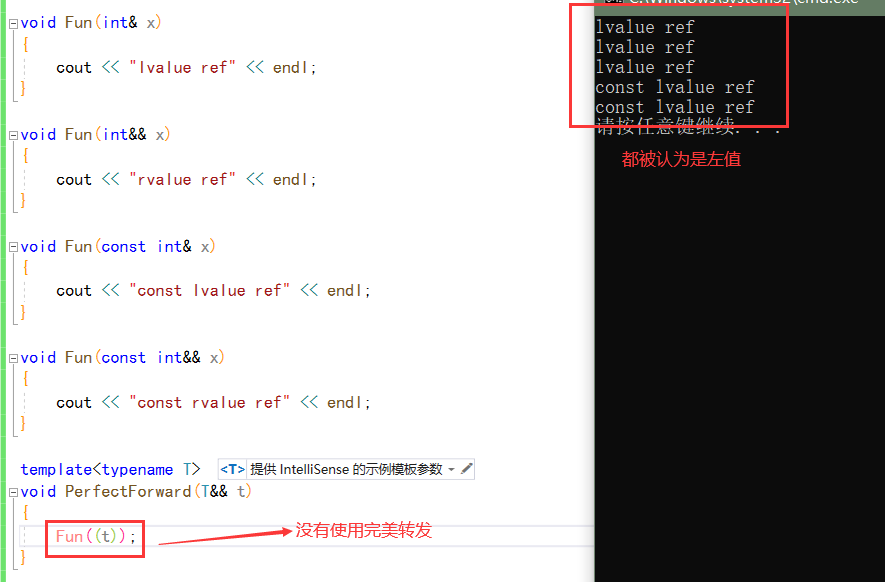
Right value reference
Reference function in C++98: because reference is an alias, where pointer operation is required, pointer can be used instead, which can improve the readability and security of the code.
The right value reference in C++11 has the following functions:
-
Implement mobile semantics (mobile construction and mobile assignment)
-
Alias intermediate temporary variables:
int main() { string s1("hello"); string s2(" world"); string s3 = s1 + s2; // s3 is a new object constructed from the result copy after the splicing of s1 and s2 string&& s4 = s1 + s2; // s4 is the alias of the result after the splicing of s1 and s2 return 0; } -
Perfect forwarding
lambda expressions
An example in C++98
In C++98, if you want to sort the elements in a data set, you can use the std::sort method
#include <algorithm>
#include <functional>
template <class T>
bool GreaterFunc(const T& t1, const T& t2)
{
return t1 > t2;
}
int main()
{
int array[] = { 4,1,8,5,3,7,0,9,2,6 };
// By default, the comparison is based on less than, and the results are sorted in ascending order
std::sort(array, array + sizeof(array) / sizeof(array[0]));
// If descending order is required, the comparison rules of elements need to be changed
std::sort(array, array + sizeof(array) / sizeof(array[0]), greater<int>());
//You can also use function pointers
std::sort(array, array + sizeof(array) / sizeof(array[0]), GreaterFunc<int>);
return 0;
}
Note: functor and function pointer are two completely different things, but the effect is the same here
If the element to be sorted is a user-defined type, you need to define the comparison rules when sorting
struct Goods
{
string _name;
double _price;
};
struct Compare
{
bool operator()(const Goods& gl, const Goods& gr)
{
return gl._price <= gr._price;
}
};
int main()
{
Goods gds[] = { { "Apple", 2.1 }, { "Banana", 3 }, { "orange", 2.2 }, {"pineapple", 1.5} };
sort(gds, gds + sizeof(gds) / sizeof(gds[0]), Compare());
return 0;
}
With the development of C + + syntax, people begin to feel that the above writing method is too complex. Every time in order to implement an algorithm algorithm, they have to write a new class. If the logic of each comparison is different, they have to implement multiple classes, especially the naming of the same class, which brings great inconvenience to programmers. Therefore, Lambda expressions appear in C++11 syntax.
lambda expressions
int main()
{
Goods gds[] = { { "Apple", 2.1 }, { "Banana", 3 }, { "orange", 2.2 }, {"pineapple", 1.5} };
sort(gds, gds + sizeof(gds) / sizeof(gds[0]), [](const Goods& l, const Goods& r)
->bool
{
return l._price < r._price;
});
return 0;
}
The above code is solved by using the lambda expression in C++11. It can be seen that the lambda expression is actually an anonymous function.
lambda expression syntax
lambda expression writing format: [capture list] (parameters) mutable - > return type {statement}
-
Description of each part of lambda expression
- [capture list]: the capture list always appears at the beginning of the lambda function. The compiler judges whether the next code is a lambda function according to []. The capture list can capture variables in the context for lambda function.
- (parameters): parameter list. It is consistent with the parameter list of ordinary functions. If parameter passing is not required, it can be omitted together with ()
- mutable: by default, lambda function is always a const function. mutable can cancel its constancy. When using this modifier, the parameter list cannot be omitted (even if the parameter is empty).
- ->ReturnType: return value type. Declare the return value type of the function in the form of tracking return type. If there is no return value, this part can be omitted. If the return value type is clear, it can also be omitted, and the compiler deduces the return type.
- {statement}: function body. In the function body, you can use all captured variables in addition to its parameters.
Note: in the lambda function definition, the parameter list and return value type are optional parts, while the capture list and function body can be empty.
Therefore, the simplest lambda function in C++11 is: [] {}; This lambda function cannot do anything
Note: in the lambda function definition, the parameter list and return value type are optional parts, while the capture list and function body can be empty.
Therefore, the simplest lambda function in C++11 is: [] {}; This lambda function cannot do anythingint main() { // The simplest lambda expression, which has no meaning [] {}; // Omit the parameter list and return value type, which is deduced by the compiler as int int a = 3, b = 4; [=] {return a + 3; }; // The return value type is omitted and there is no return value type auto fun1 = [&](int c) {b = a + c; }; fun1(10) cout << a << " " << b << endl; // All parts are perfect lambda functions auto fun2 = [=, &b](int c)->int {return b += a + c; }; cout << fun2(10) << endl; // Copy snap x int x = 10; auto add_x = [x](int a) mutable { x *= 2; return a + x; }; cout << add_x(10) << endl; return 0; } -
Capture list description
The capture list describes which data in the context can be used by lambda, and whether it is passed by value or reference.- [var]: indicates the value transfer method and captures the variable var
- [= =: indicates that the value transfer method captures all variables in the parent scope (including this)
- [& var]: refers to the reference transfer capture variable var
- [&]: indicates that reference passing captures all variables in the parent scope (including this)
- [this]: indicates that the value transfer method captures the current this pointer
be careful:
a. The parent scope refers to the statement block containing the lambda function
b. Syntactically, the capture list can be composed of multiple capture items and separated by commas.For example: [=, & A, & b]: capture variables A and b by reference, capture all other variables by value transfer [&, a, this]: capture variables A and this by value transfer, and capture other variables by reference c. the capture list does not allow repeated transmission of variables, otherwise compilation errors will be caused. For example: [=, a]: = all variables have been captured by value transfer, and a repetition is captured
d. The lambda function capture list outside the scope of the block must be empty.
e. The lambda function in the block scope can only capture local variables in the parent scope. Capturing any non local or non local variables will lead to compilation errors.
f. lambda expressions cannot be assigned to each other, even if they appear to be of the same typevoid (*PF)(); int main() { auto f1 = [] {cout << "hello world" << endl; }; auto f2 = [] {cout << "hello world" << endl; }; // The reason will not be explained here. After reading the underlying implementation principle of lambda expression, we will be clear //f1 = f2; // Compilation failed -- > prompt: operator = () not found // Allows a copy of a lambda expression to be used to construct a new copy auto f3(f2); f3(); // lambda expressions can be assigned to function pointers of the same type PF = f2; PF(); return 0; }
Use of lambda expressions
1. Value transfer capture: [a], capture a; [a,b], capture a,b; [], capture all objects in the same scope
int main()
{
int a = 1, b = 2;
//Capture a
auto get = [a]() {return a;};
cout << get() << endl;
//Capture a, b
auto add1 = [a, b]() {return a + b;};
cout << add1() << endl;
//Compilation error. At this time, a and b are const by default
/*auto swapab = [a, b]() {
int tmp = a;
a = b;
b = tmp;
};
*/
//Correct usage
auto swapab = [a, b]()mutable {
int tmp = a;
a = b;
b = tmp;
};
//a. The value of b is not exchanged, because the lambda expression exchanges copies of a and b, similar to the formal parameters of a function.
cout << a << " " << b << endl;
//Capture all variables in the current scope
auto add2 = [=]() {return a + b;};
cout << add2() << endl;
return 0;
}
The value captured by value transfer is const by default and cannot be modified. If mutable is added, it can be modified in the body, but at this time, what is modified is only a copy, and the variables actually captured will not be modified.
The examples used above omit the parameter list.
2. Pass reference capture: [& A], capture a, [& A, & B], capture a,b; [&], capture all objects in the same scope
int a = 1, b = 2;
//Reference capture a
auto get = [&a]() {return a;};
cout << get() << endl;
//Reference capture a, b
auto add1 = [&a, &b]() {return a + b;};
cout << add1() << endl;
//Exchange a, b
auto swapab = [&a, &b]() {
int tmp = a;
a = b;
b = tmp;
};
swapab();
cout << a << " " << b << endl;
lambda expressions in the same scope cannot have the same name. Different scopes can have the same name or function.
Usage scenario of lambda expression
For example, in the previous sort, we can pass an anonymous lambda expression to the third parameter to make the code more intuitive.
int main()
{
Goods gds[] = { { "Apple", 2.1 }, { "Banana", 3 }, { "orange", 2.2 }, {"pineapple", 1.5} };
//In descending order according to price
sort(gds, gds + sizeof(gds) / sizeof(gds[0]), [](const Goods& l, const Goods& r)->bool {
return l._price > r._price;
});
//Descending by name
sort(gds, gds + sizeof(gds) / sizeof(gds[0]), [](const Goods& l, const Goods& r)->bool {
return l._name > r._name;
});
return 0;
}
Function object and lambda expression
A function object, also known as an imitation function, is an object that can be used like a function, which is a class object that overloads the operator() operator in the class
class Rate
{
public:
Rate(double rate) : _rate(rate)
{}
double operator()(double money, int year)
{
return money * _rate * year;
}
private:
double _rate;
};
int main()
{
// Function object
double rate = 0.49;
Rate r1(rate);
r1(10000, 2);
// lamber
auto r2 = [=](double monty, int year)->double {return monty * rate * year; };
r2(10000, 2);
return 0;
}
In terms of usage, function objects are exactly the same as lambda expressions.
The function object takes rate as its member variable and gives the initial value when defining the object. The lambda expression can capture the variable directly through the capture list
Principle of lambda expression

In fact, the underlying compiler processes lambda expressions in the way of function objects, that is, if a lambda expression is defined, the compiler will automatically generate a lambda_uuid class. uuid is generated by a certain algorithm to identify the class. operator() is overloaded in this class.
When we execute auto add = [] (int a, int b){return a + b;}; The lambda expression is replaced with the generated lambda at run time_ UUID is the object of imitation function, and add is assigned by this object
So since it is an object, we can also use lambda expression by reference:
int main()
{
int a = 1, b = 2;
//Must be const reference
const auto& add = [a, b]() {return a + b;};
return 0;
}
Thread library
A brief introduction to thread class
Before C++11, multithreading problems were related to the platform. For example, windows and linux had their own interfaces, which made the portability of the code poor.
Under windows: use CreateThread and other interfaces
Under linux: use POSIX's third-party pthread library, such as pthread_create and other interfaces.
In C++98, if you want to write multithreaded programs, you can run under windows and linux. What should you do?
Use conditional compilation:
#ifdef _win32 CreateThread(...); ... #else pthread_create(...); ... #endif
The most important feature of C++11 is to support threads, so that C + + does not need to rely on third-party libraries in parallel programming, and the concept of atomic class is also introduced in atomic operation. To use threads in the standard library, you must include < thread > header files.
Thread library of C++11: cross platform, object-oriented encapsulated classes (each thread is an object of a class)
Implementation principle: conditional compilation is used when encapsulating the library, that is, the thread API s of different platforms are called at its bottom.
| Function name | function |
|---|---|
| thread() | Construct a thread object without any thread function associated, that is, no thread is started |
| thread(fn, args1, args2, ...) | Construct a thread object and associate the thread functions fn, args1, args2,... As the parameters of the thread function |
| get_id() | Get thread id |
| jionable() | Whether the thread is still executing, joinable represents an executing thread. |
| join() | After the function is called, the main thread will be blocked. When the thread ends, the main thread will continue to execute |
| detach() | Called immediately after the thread object is created. It is used to separate the created thread from the thread object. The separated thread becomes a background thread. The "life and death" of the created thread has nothing to do with the main thread |
be careful:
-
Thread is a concept in the operating system. A thread object can be associated with a thread to control the thread and obtain the state of the thread.
-
When a thread object is created, no thread function is provided, and the object does not actually correspond to any thread
#include <thread> int main() { std::thread t1; cout << t1.get_id() << endl; return 0; }get_ The return value type of id () is id type. The id type is actually a class encapsulated under the std::thread namespace, which contains a structure:
// View under vs typedef struct { /* thread identifier for Win32 */ void *_Hnd; /* Win32 HANDLE */ unsigned int _Id; } _Thrd_imp_t; -
When a thread object is created and a thread function is associated with the thread, the thread is started and runs with the main thread. Thread functions can generally be provided in the following three ways:
-
Function pointer
-
lambda expressions
-
Function object
#include <iostream> using namespace std; #include <thread> void ThreadFunc(int a) { cout << "Thread1" << a << endl; } class TF { public: void operator()() { cout << "Thread3" << endl; } }; int main() { // Thread function is a function pointer thread t1(ThreadFunc, 10); // The thread function is a lambda expression thread t2([] {cout << "Thread2" << endl; }); // Thread function is an object of imitation function class TF tf; thread t3(tf); t1.join(); t2.join(); t3.join(); cout << "Main thread!" << endl; return 0; }
-
-
Thread class is copy proof and does not allow copying construction and assignment, but can move construction and assignment, that is, the state of a thread object associated with a thread is transferred to other thread objects, and the execution of the thread is not affected during the transfer.
-
You can judge whether the thread is valid through the joinable() function. If it is any of the following cases, the thread is invalid
- Thread object constructed with parameterless constructor
- The state of the thread object has been transferred to another thread object
- The thread has called join or detach to end
Interview question: what is the difference between concurrency and parallelism?
Interview required: what's the difference between concurrency and parallelism
Thread function parameters
The parameters of the thread function are copied to the thread stack space in the form of value copy. Therefore, even if the thread parameter is of reference type, the external argument cannot be modified in the thread after modification, because it actually refers to the copy in the thread stack rather than the external argument
#include <thread>
void ThreadFunc1(int& x)
{
x += 10;
}
void ThreadFunc2(int* x)
{
*x += 10;
}
int main()
{
int a = 10;
// Modifying a in the thread function will not affect the external arguments, because although the thread function parameters are referenced, they actually refer to the copy in the thread stack
thread t1(ThreadFunc1, a);
t1.join();
cout << a << endl;
// If you want to change an external argument through a formal parameter, you must use the std::ref() function
thread t2(ThreadFunc1, std::ref(a));
t2.join();
cout << a << endl;
// Copy of address
thread t3(ThreadFunc2, &a); // You can modify the value of an external parameter through a pointer
t3.join();
cout << a << endl;
return 0;
}
Note: if the class member function is used as the thread parameter, this must be used as the thread function parameter
join and detach
After starting a thread, how to recycle the resources used by the thread when the thread ends? The thread library gives us two options:
-
join() method
Join(): the main thread is blocked. When the new thread terminates, join() will clean up the related thread resources and then return. The main thread will continue to execute downward, and then destroy the thread object. Because join () cleans up the related resources of the thread, the thread object has nothing to do with the destroyed thread. Therefore, a thread object can only use join () once, otherwise the program will crash
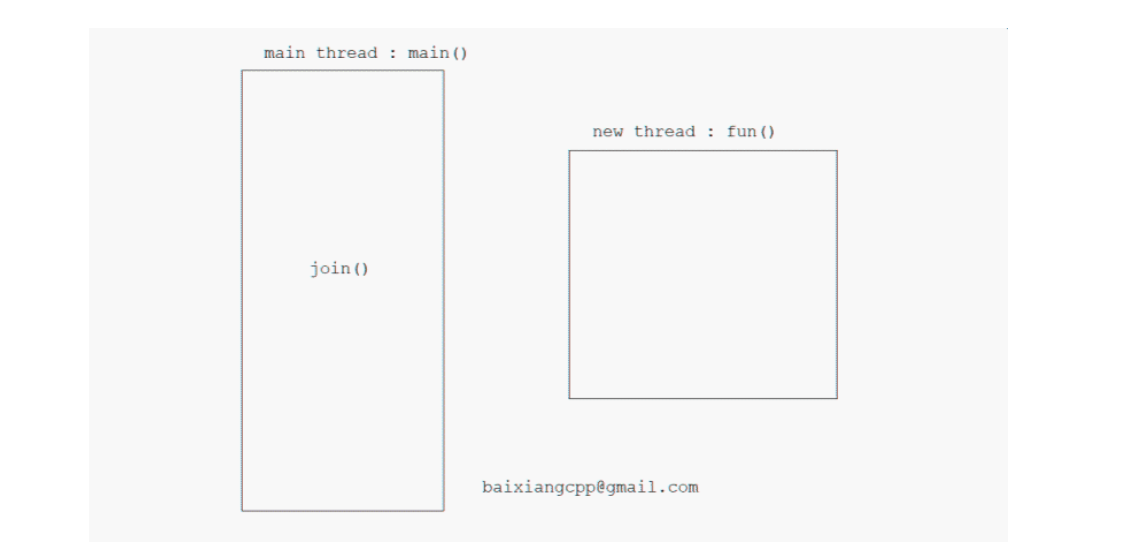
// Misuse of join() void ThreadFunc() { cout << "ThreadFunc()" << endl; } bool DoSomething() { return false; } int main() { std::thread t(ThreadFunc); if (!DoSomething()) return -1; t.join(); return 0; } /* Note: if the DoSomething() function returns false, the main thread will end, the join() is not called, and the thread resources are not recycled, resulting in resource leakage. */ // Misuse of join() 2 void ThreadFunc() { cout << "ThreadFunc()" << endl; } void Test1() { throw 1; } void Test2() { int* p = new int[10]; std::thread t(ThreadFunc); try { Test1(); } catch (...) { delete[] p; throw; } t.join(); // Note: similar to the above reasons }Therefore, when using join() to end the thread, the call position of join() is very critical. To avoid this problem, RAII can be used to encapsulate Thread objects, such as:
#include <thread> class mythread { public: explicit mythread(std::thread& t) :m_t(t) {} ~mythread() { if (m_t.joinable()) m_t.join(); } mythread(mythread const&) = delete; mythread& operator=(const mythread&) = delete; private: std::thread& m_t; }; void ThreadFunc() { cout << "ThreadFunc()" << endl; } bool DoSomething() { return false; } int main() { thread t(ThreadFunc); mythread q(t); if (DoSomething()) return -1; return 0; } -
detach() mode
detach(): after the function is called, the new thread is separated from the thread object and is no longer expressed by the thread object, so the thread cannot be controlled through the thread object. The new thread will run in the background, and its ownership and control will be handed over to the C + + runtime. At the same time, the C + + runtime ensures that when the thread exits, its related resources can be recycled correctly.
It's like you break up with your girlfriend, then you won't have contact (interaction) anymore, and you don't need to pay for all kinds of resources she consumes later (clean up resources).
The detach() function is usually called after the thread object is created, because if it is not the end of the join() wait mode, the thread object may be destroyed before the end of the new thread, resulting in program crash. Because in the destructor of std::thread, if the state of the thread is joinable, std::terminate will be called, and the terminate() function will directly terminate the program
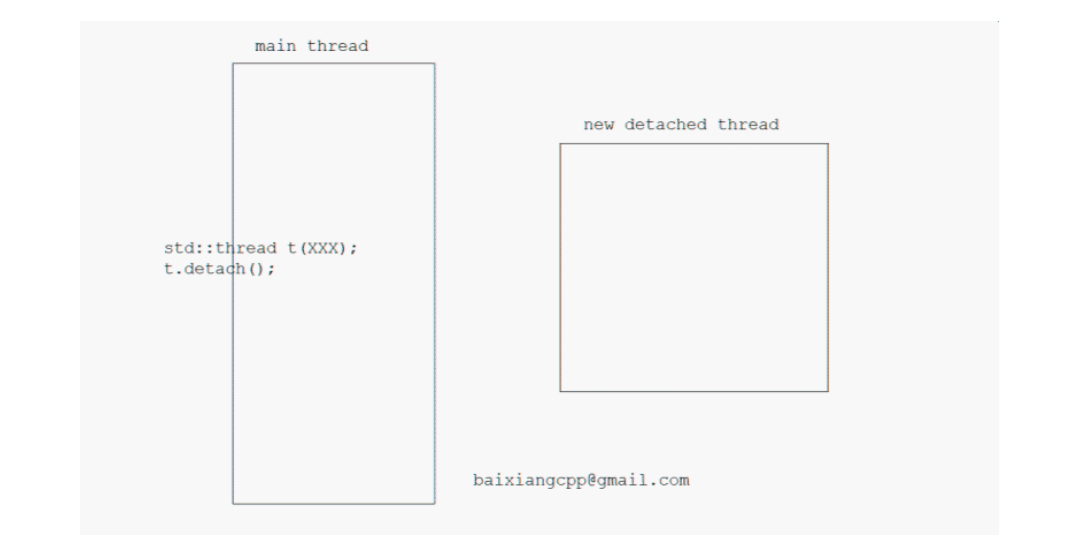
Therefore, before the thread object is destroyed, either wait for the thread to end in the way of join() or separate the thread from the thread object in the way of detach()
Conditional variable
Condition variables are contained in the header file < condition_ In variable >
Use of conditional variables
Two threads are required. One thread prints odd numbers and one thread prints even numbers
Take printing odd and even numbers between 0-10 as an example
int main()
{
//Thread 1 print odd
thread t1([]() {
for (int i = 0; i <= 10; ++i)
{
if (i % 2 == 1)
{
cout << this_thread::get_id() << " : " << i << endl;
}
}
});
//Thread 2 print even
thread t2([]() {
for (int i = 0; i <= 10; ++i)
{
if (i % 2 == 0)
{
cout << this_thread::get_id() << " : " << i << endl;
}
}
});
t1.join();
t2.join();
return 0;
}
result:

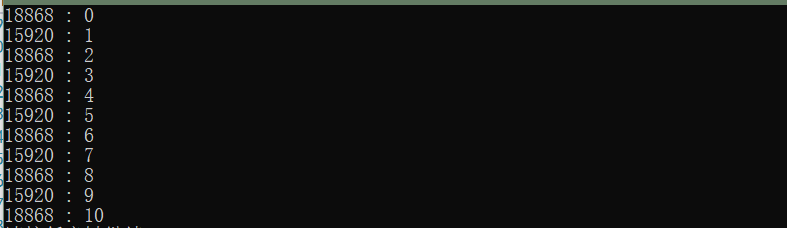
Solution: since two threads will rob the buffer resources, we will try to make them occupy the buffer equally. So we should use conditional variables and locks. When an odd number is printed, we will inform another thread to print an even number, and then proceed alternately
int main()
{
mutex mtx1;
mutex mtx2;
condition_variable c1;
condition_variable c2;
//Thread 1 print odd
thread t1([&]() {
for (int i = 0; i <= 10; i++)
{
if (i % 2 == 1)
{
//Wait until the even number is printed
unique_lock<mutex> lck2(mtx2);
c2.wait(lck2);
cout << this_thread::get_id() << " : " << i << endl;
//After the odd number is printed, notify the even number to print, and enter the wait (the next cycle will wait)
c1.notify_all();
}
}
});
//Thread 2 print even
thread t2([&]() {
for (int i = 0; i <= 10; i++)
{
//Print even first
if (i % 2 == 0)
{
cout << this_thread::get_id() << " : " << i << endl;
//After printing, notify t1 to print the odd number and enter the waiting by yourself
c2.notify_all();
unique_lock<mutex> lck1(mtx1);
if (i < 10)//When you finish printing 10, you don't have to wait any longer and end directly
c1.wait(lck1);
}
}
});
t1.join();
t2.join();
return 0;
}
result:
Atomic operation Library (atomic)
The main problem of multithreading is the problem caused by sharing data (i.e. thread safety). If the shared data is read-only, there is no problem, because the read-only operation will not affect the data, let alone involve the modification of the data, so all threads will get the same data. However, when one or more threads want to modify the shared data, there will be a lot of potential trouble. For example:
#include <iostream>
using namespace std;
#include <thread>
unsigned long sum = 0L;
void fun(size_t num)
{
for (size_t i = 0; i < num; ++i)
sum++;
}
int main()
{
cout << "Before joining,sum = " << sum << std::endl;
thread t1(fun, 10000000);
thread t2(fun, 10000000);
t1.join();
t2.join();
cout << "After joining,sum = " << sum << std::endl;
return 0;
}
The traditional solution in C++98: the shared modified data can be locked and protected
#include <iostream>
using namespace std;
#include <thread>
#include <mutex>
std::mutex m;
unsigned long sum = 0L;
void fun(size_t num)
{
for (size_t i = 0; i < num; ++i)
{
m.lock();
sum++;
m.unlock();
}
}
int main()
{
cout << "Before joining,sum = " << sum << std::endl;
thread t1(fun, 10000000);
thread t2(fun, 10000000);
t1.join();
t2.join();
cout << "After joining,sum = " << sum << std::endl;
return 0;
}
Although locking can be solved, there is a defect in locking: as long as one thread is running on sum + +, other threads will be blocked, which will affect the efficiency of program operation. Moreover, if the lock is not well controlled, it is easy to cause deadlock. Therefore, atomic operation is introduced into C++11. The so-called atomic operation: that is, one or a series of operations that cannot be interrupted. The atomic operation type introduced by C++11 makes the data synchronization between threads very efficient
Note: when the above atomic operation variables need to be used, the header file must be added
#include <iostream>
using namespace std;
#include <thread>
#include <atomic>
atomic_long sum{ 0 };
void fun(size_t num)
{
for (size_t i = 0; i < num; ++i)
sum++; // Atomic operation
}
int main()
{
cout << "Before joining, sum = " << sum << std::endl;
thread t1(fun, 1000000);
thread t2(fun, 1000000);
t1.join();
t2.join();
cout << "After joining, sum = " << sum << std::endl;
return 0;
}
In C++11, programmers do not need to lock and unlock atomic type variables, and threads can access atomic type variables mutually exclusive. More generally, programmers can use atomic class templates to define any atomic type they need.
atmoic<T> t; // Declare an atomic variable t of type T
Note: atomic types usually belong to "resource-based" data, and multiple threads can only access the copy of a single atomic type. Therefore, in C++11, atomic types can only be constructed from their template parameters, and atomic types are not allowed to carry out copy construction, move construction and operator =. In order to prevent accidents, the standard library has incorporated the copy construction, move construction The overload of assignment operator is deleted by default
#include <atomic>
int main()
{
atomic<int> a1(0);
//atomic<int> a2(a1); // Compilation failed
atomic<int> a2(0);
//a2 = a1; // Compilation failed
return 0;
}
lock_guard and unique_lock
In a multithreaded environment, if you want to ensure the security of a variable, just set it to the corresponding atomic type, which is efficient and not prone to deadlock. However, in some cases, we may need to ensure the security of a piece of code, so we can only control it by locking.
For example, one thread adds 100 times to the variable number, and the other subtracts 100 times. After adding or subtracting one for each operation, the result of number is output. It is required that the last value of number is 1
#include <thread>
#include <mutex>
int number = 0;
mutex g_lock;
int ThreadProc1()
{
for (int i = 0; i < 100; i++)
{
g_lock.lock();
++number;
cout << "thread 1 :" << number << endl;
g_lock.unlock();
}
return 0;
}
int ThreadProc2()
{
for (int i = 0; i < 100; i++)
{
g_lock.lock();
--number;
cout << "thread 2 :" << number << endl;
g_lock.unlock();
}
return 0;
}
int main()
{
thread t1(ThreadProc1);
thread t2(ThreadProc2);
t1.join();
t2.join();
cout << "number:" << number << endl;
system("pause");
return 0;
}
Defects of the above Codes: when the lock is not well controlled, it may cause deadlock. The most common ones are that the code returns in the middle of the lock or throws exceptions within the scope of the lock. Therefore, C++11 encapsulates the lock in the way of RAII, that is, lock_guard and unique_lock
Types of Mutex
In C++11, Mutex contains four types of Mutex:
-
std::mutex
The most basic mutex provided by C++11. Objects of this class cannot be copied or moved. The three most commonly used functions of mutex:Function name Function function lock() Lock: lock the mutex unlock() Unlock: release ownership of mutex try_lock() Try to lock the mutex. If the mutex is occupied by another thread, the current thread will not be blocked Note that the following three situations may occur when a thread function calls lock():
- If the mutex is not currently locked, the calling thread locks the mutex until unlock is called
- If the current mutex is locked by another thread, the current calling thread is blocked
- If the current mutex is locked by the current calling thread, a deadlock (deadlock) is generated.
Thread function call try_ When lock(), the following three situations may occur:
- If the current mutex is not occupied by other threads, the thread locks the mutex until the thread calls unlock to release the mutex
- If the current mutex is locked by other threads, the current call thread returns to false, and it will not be blocked.
- If the current mutex is locked by the current calling thread, a deadlock (deadlock) is generated.
-
std::recursive_mutex
It allows the same thread to lock the mutex multiple times (i.e. recursive locking) to obtain multi-layer ownership of the mutex object. When releasing the mutex, you need to call unlock() the same number of times as the lock hierarchy depth. In addition, std::recursive_mutex has roughly the same characteristics as std::mutex
-
std::timed_mutex
There are two more member functions than std::mutex, try_lock_for(),try_lock_until() .- try_lock_for()
Accept a time range, which means that within this time range, if the thread does not obtain a lock, it will be blocked (unlike try_lock() of std::mutex, try_ Lock returns false directly if the lock is not obtained when it is called. If another thread releases the lock during this period, the thread can obtain the lock on the mutex. If it times out (that is, it still does not obtain the lock within the specified time), it returns false. - try_lock_until()
Accept a time point as a parameter. Before the specified time point, if the thread does not obtain the lock, it will be blocked. If other threads release the lock during this period, the thread can obtain the lock on the mutex. If it times out (that is, it still does not obtain the lock within the specified time), it will return false.
- try_lock_for()
-
std::recursive_timed_mutex
lock_guard
std::lock_gurad is a template class defined in C++11. As defined below
template<class _Mutex>
class lock_guard
{
public:
// Constructing lock_ When Gard_ Mtx is not locked yet
explicit lock_guard(_Mutex& _Mtx)
: _MyMutex(_Mtx)
{
_MyMutex.lock();
}
// Constructing lock_ When Gard_ Mtx has been locked. There is no need to lock it here
lock_guard(_Mutex& _Mtx, adopt_lock_t)
: _MyMutex(_Mtx)
{}
~lock_guard() _NOEXCEPT
{
_MyMutex.unlock();
}
lock_guard(const lock_guard&) = delete;
lock_guard& operator=(const lock_guard&) = delete;
private:
_Mutex& _MyMutex;
};
From the above code, you can see that lock_ The guard class template mainly encapsulates the mutex managed by it through RAII. Where locking is required, you only need to instantiate a lock with any mutex described above_ Guard, call the constructor to lock successfully. Before leaving the scope, lock_ If the guard object needs to be destroyed, call the destructor to unlock it automatically, which can effectively avoid the deadlock problem.
lock_ The defect of guard: it is too single for users to control the lock, so C++11 provides unique_lock.
unique_lock
And lock_gard similar, unique_lock class templates also encapsulate locks in the way of RAII, and manage the locking and unlocking operations of Mutex objects in the way of exclusive ownership, that is, there can be no copy between their objects. When constructing (or moving) assignment), unique_ The lock object needs to pass a Mutex object as its parameter, and the newly created unique_ The lock object is responsible for locking and unlocking the Mutex object passed in. Instantiate unique using the above type Mutex_ Lock object, automatically call the constructor to lock, unique_ When the lock object is destroyed, the destructor is automatically called to unlock, which can easily prevent deadlock.
And lock_ The difference between guard and unique_lock is more flexible and provides more member functions:
- Lock / unlock operation: lock, try_lock,try_lock_for,try_lock_until and unlock
- Modification operations: move assignment, swap (swap: exchange the managed mutex ownership with another unique_lock object), release (release: return the pointer of the managed mutex object and release the ownership)
- Get attribute: owns_ Lock (returns whether the current object is locked), operator bool() (the same function as owns_lock()), mutex (returns the pointer of the mutex managed by the current unique_lock).