Many people on the Internet ask why copy is necessary_ from_ User, someone answered. For example, baidu:
I think this question needs to be answered from two levels
-
The first level is why you want to copy, can you not copy?
-
The second level is why copy is used_ from_ User instead of memcpy directly
Why copy
Copying is necessary. It doesn't even have anything to do with Linux. For example, Linux has a kobject structure, which has a name pointer:
struct kobject {
const char *name;
struct list_head entry;
struct kobject *parent;
struct kset *kset;
struct kobj_type *ktype;
struct kernfs_node *sd; /* sysfs directory entry */
struct kref kref;
...
};
But when we set the name of a device, we actually set the name of the kobject of the device:
int dev_set_name(struct device *dev, const char *fmt, ...)
{
va_list vargs;
int err;
va_start(vargs, fmt);
err = kobject_set_name_vargs(&dev->kobj, fmt, vargs);
va_end(vargs);
return err;
}
name is often set in the driver, such as:
dev_set_name(&chan->dev->device, "dma%dchan%d",
device->dev_id, chan->chan_id);
However, Linux is not stupid enough to directly assign the name pointer as follows:
struct device {
struct kobject kobj;
...
};
dev_set_name(struct device *dev, char *name)
{
dev->kobj.name = name_param; //Hypothetical bad code
}
If it does so, it will be finished, because the name can be set in the driver as follows:
driver_func()
{
char name[100];
....
dev_set_name(dev, name);
}
Pass to dev_ set_ The root of name () is a temporary variable in the stack area. It is a passer-by. The name of the device must exist for a long time. So you see, the real code of the kernel is to reapply a memory for kobject's name, and then put dev_ set_ Copy the name passed to it by name():
int kobject_set_name_vargs(struct kobject *kobj, const char *fmt,
va_list vargs)
{
const char *s;
..
s = kvasprintf_const(GFP_KERNEL, fmt, vargs);
...
if (strchr(s, '/')) {
char *t;
t = kstrdup(s, GFP_KERNEL);
kfree_const(s);
if (!t)
return -ENOMEM;
strreplace(t, '/', '!');
s = t;
}
kfree_const(kobj->name);
kobj->name = s;
return 0;
}
This problem exists completely at the junction of user space and kernel space. Suppose XXX of a driver in the kernel_ Write () is written as follows:
struct globalmem_dev {
struct cdev cdev;
unsigned char *mem;
struct mutex mutex;
};
static ssize_t globalmem_write(struct file *filp, const char __user * buf,
size_t size, loff_t * ppos)
{
struct globalmem_dev *dev = filp->private_data;
dev->mem = buf; //Hypothetical bad code
return ret;
}
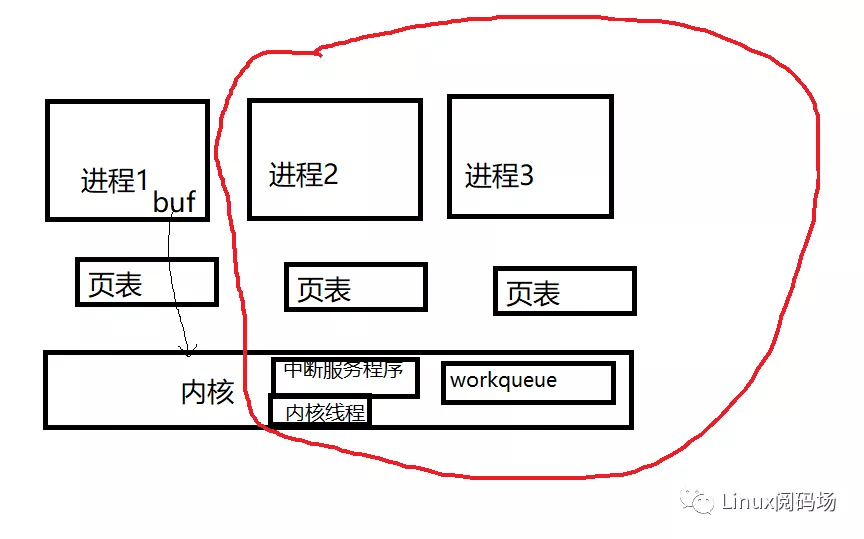
The const char passed from the user mode is directly used in the kernel__ The user * buf pointer is disastrous, because the virtual address of buf is valid only in this process space, and cross process is invalid. However, scheduling always occurs. Interrupts exist, workqueue s exist, kernel threads exist, and other processes exist. The buffer address of the original user process doesn't know what it is after cutting a process! In another process, the page table has changed. Can you find someone at your buf address? The buf address of process 1 is nothing in the red box below!
Therefore, the correct way for the kernel is to copy the buf to a long-term effective memory that spans interrupts, processes, workqueue s and kernel threads:
struct globalmem_dev {
struct cdev cdev;
unsigned char mem[GLOBALMEM_SIZE];//Long term effectiveness
struct mutex mutex;
};
static ssize_t globalmem_write(struct file *filp, const char __user * buf,
size_t size, loff_t * ppos)
{
unsigned long p = *ppos;
unsigned int count = size;
int ret = 0;
struct globalmem_dev *dev = filp->private_data;
....
if (copy_from_user(dev->mem + p, buf, count))//Copy!!
ret = -EFAULT;
else {
*ppos += count;
ret = count;
...
}
Remember, for the kernel, the pointer passed in by the user state at the moment is just a passer-by, just a brilliant fireworks, just a flash in the pan and a flash in the pan! It doesn't even promise that you will cheat at any time!
Therefore, if you must give a reason to copy, the reason is to prevent cheating! Don't give me anything.
The second reason for having to copy may be related to security. For example, call pwritev and preadv in user mode:
ssize_t preadv(int fd, const struct iovec *iov, int iovcnt, off_t offset); ssize_t pwritev(int fd, const struct iovec *iov, int iovcnt, off_t offset);
The user passes an iov array to the kernel. Each member of the array describes the base address and length of a buffer:
struct iovec
{
void __user *iov_base; /* BSD uses caddr_t (1003.1g requires void *) */
__kernel_size_t iov_len; /* Must be size_t (1003.1g) */
};
The user passes an iovec array, which contains the len and base of each iov (the base also points to the user state buffer). When passing it to the kernel, the kernel will check the iovec address to ensure that each buffer is in the user space, and will copy the whole iovec array to the kernel space:
ssize_t import_iovec(int type, const struct iovec __user * uvector,
unsigned nr_segs, unsigned fast_segs,
struct iovec **iov, struct iov_iter *i)
{
ssize_t n;
struct iovec *p;
n = rw_copy_check_uvector(type, uvector, nr_segs, fast_segs,
*iov, &p);
...
iov_iter_init(i, type, p, nr_segs, n);
*iov = p == *iov ? NULL : p;
return n;
}
This process has strict security considerations. The entire iov array will be copied_ from_ User(), and each buf in the array must be accessed_ OK check:
ssize_t rw_copy_check_uvector(int type, const struct iovec __user * uvector,
unsigned long nr_segs, unsigned long fast_segs,
struct iovec *fast_pointer,
struct iovec **ret_pointer)
{
...
if (copy_from_user(iov, uvector, nr_segs*sizeof(*uvector))) {
ret = -EFAULT;
goto out;
}
...
ret = 0;
for (seg = 0; seg < nr_segs; seg++) {
void __user *buf = iov[seg].iov_base;
ssize_t len = (ssize_t)iov[seg].iov_len;
...
if (type >= 0
&& unlikely(!access_ok(buf, len))) {
ret = -EFAULT;
goto out;
}
...
}
out:
*ret_pointer = iov;
ret
urn ret;
}
access_ok(buf, len) is to ensure that the long len interval from buf must be in user space. The application cannot pass in an address in kernel space to the system call, so that the user can make the kernel write the kernel itself through system call, resulting in a series of internal core security vulnerabilities.
Suppose that the kernel does not copy the entire iov array into the kernel through the following code:
copy_from_user(iov, uvector, nr_segs*sizeof(*uvector))
Instead, you can directly access the iov in the user state, the access_ok is completely worthless, because users can access you_ When OK checks, the user state buffer is passed to you, and then the iov_ Change the content of base to point to a kernel buffer.
Therefore, for this reason, the initial copy is also necessary. But this reason is far less than the reason for cheating at any time at the beginning!
Why not use memcpy directly?
This problem mainly involves two levels, one is copy_from_user() has its own access_ok check that if the buffer passed in by the user does not belong to the user space but the kernel space, it will not be copied at all; Second, copy_from_user() has its own exception repair mechanism after page fault.
Let's look at the first question first. If the code directly uses memcpy():
static ssize_t globalmem_write(struct file *filp, const char __user * buf,
size_t size, loff_t * ppos)
{
struct globalmem_dev *dev = filp->private_data;
....
memcpy(dev->mem + p, buf, count))
return ret;
}
memcpy does not have this check. Even if the buf passed in by the user points to the kernel address, this copy should be done. Imagine that when a user makes a system call, he can easily pass in the pointer of the kernel. Can't the user do whatever he wants? For example, the commit of the kernel caused a famous security vulnerability:
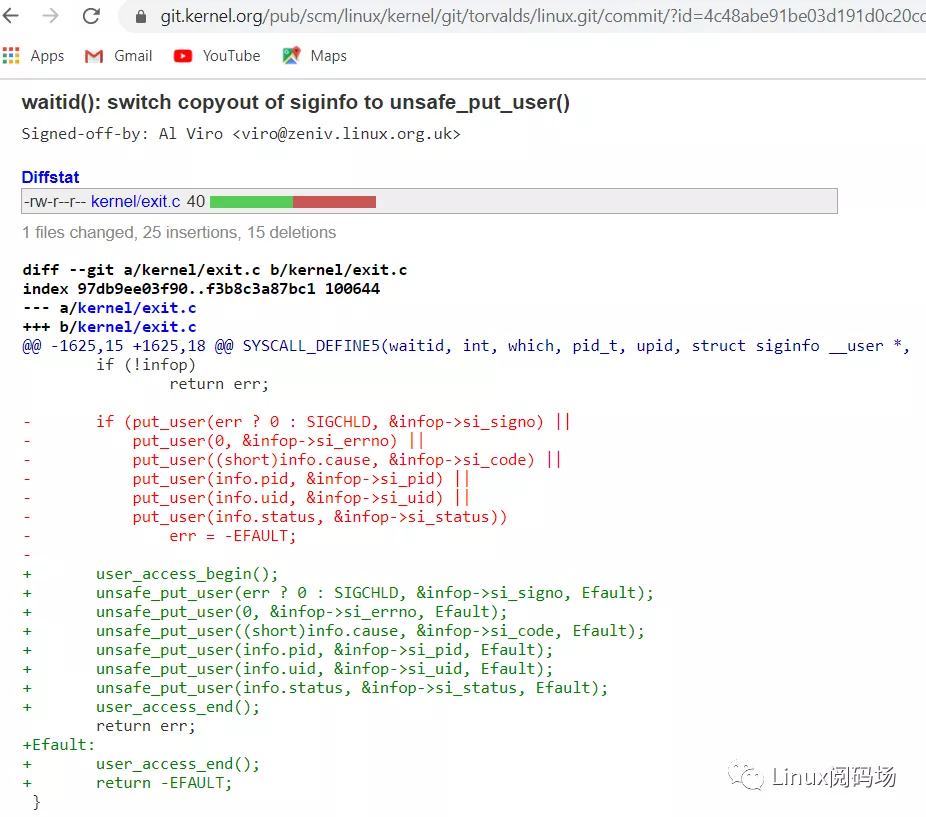
Because the author has access_ok put_ Change user to no access_ok, unsafe_put_user. In this way, if the user passes the uid address of a process to the kernel, the kernel is unsafe_put_user, can't you change its uid to 0?
Therefore, when you see the kernel repairing this CVE, you have an access to these addresses_ OK:
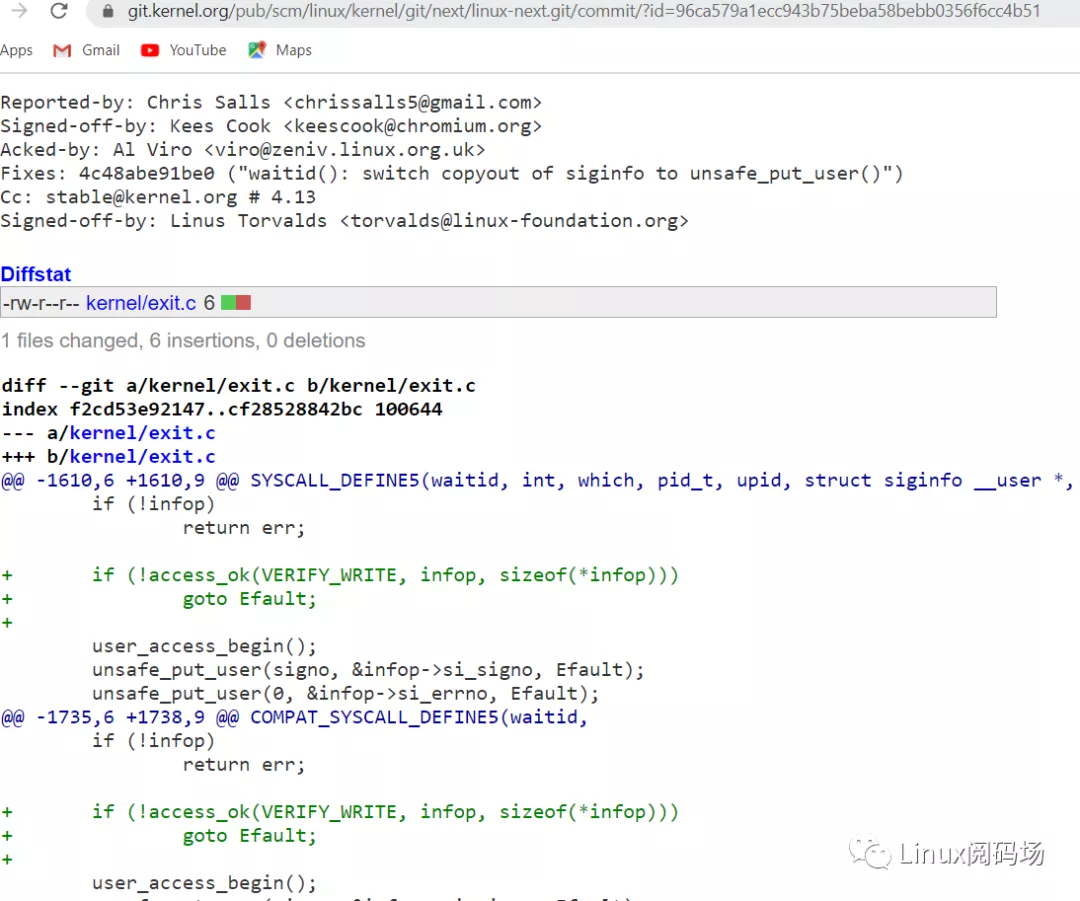
Let's look at the second problem, the repair mechanism of page fault. Suppose the user program randomly sends a user state address to the kernel:
void main(void)
{
int fd;
fd = open("/dev/globalfifo", O_RDWR, S_IRUSR | S_IWUSR);
if (fd != -1) {
int ret = write(fd, 0x40000000, 10);//Hypothetical code
if (ret < 0)
perror("write error\n");
}
}
0x40000000 this address is in user status, so access_ok, there's no problem. But this address is not any valid data, heap or stack at all. My special code is nonsense.
What happens if the kernel driver uses memcpy? We will see a section of kernel Oops:
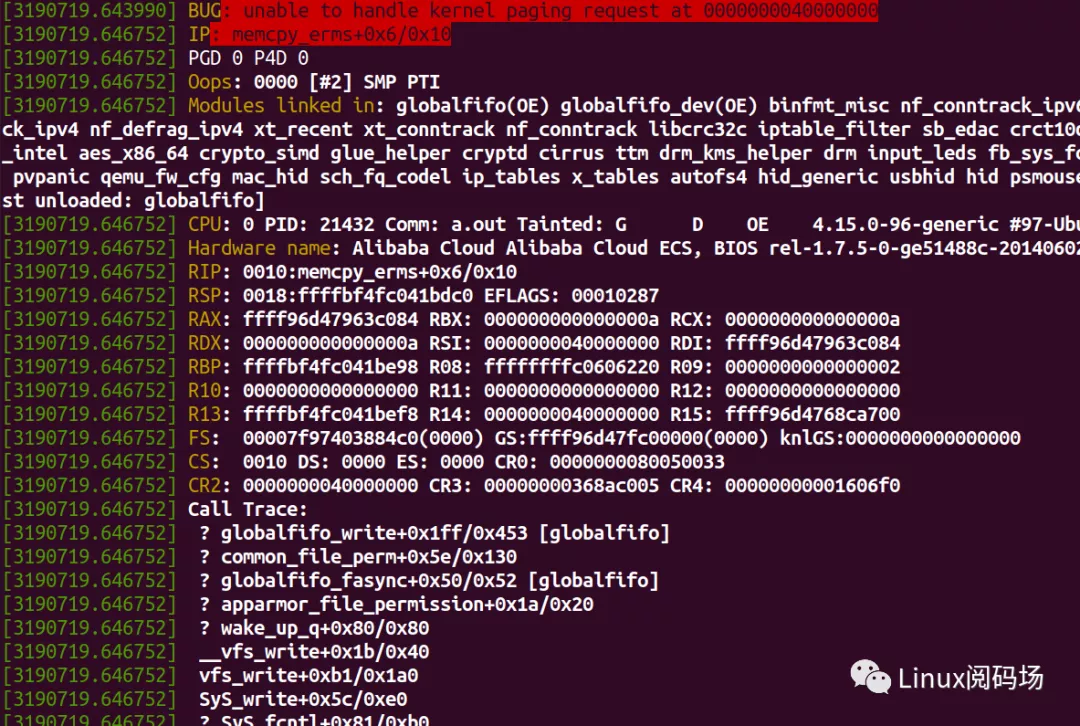
The user process will also be kill ed:
# ./a.out Killed
Of course, if you set / proc / sys / kernel / panic_ on_ If oops is 1, the kernel is not as simple as Opps, but directly panic.
But if the kernel uses copy_ from_ What about user? The kernel will not Oops, and the user application will not die. It just receives the bad address error:
# ./a.out write error : Bad address
The kernel just kindly prompts you that the buffer address 0x40000000 intruded by the user is a wrong address. The parameters of this system call are wrong, which is obviously more in line with the essence of system call.
Kernel for copy_from_user has exception fixup mechanism, but memcpy() does not. For detailed exception repair mechanism, see:
https://www.kernel.org/doc/Documentation/x86/exception-tables.txt
PAN
If we want to study further, hardware and software work together to make a more secure mechanism, which is called PAN (Privileged Access Never). It can limit the buffer access of user space to a specific code interval. PAN can prevent the kernel from directly accessing users. It requires that access permissions must be enabled on the hardware before access. According to ARM's spec document
https://static.docs.arm.com/ddi0557/ab/DDI0557A_b_armv8_1_supplement.pdf
Description:
Therefore, before the kernel accesses the user every time, it needs to modify the PSATE register to open the access permission. After that, it should modify the PSTATE again to close the kernel's access permission to the user.
According to the patch:
https://patchwork.kernel.org/patch/6808781/