preface
Python: what? Writing crawler, you actually use java?
you 're right! Today, break the routine and write a simple crawler in java. It is mainly based on java. Some functions need crawlers; It's a little late to change the question now, so I have to bite the bullet (no matter how ridiculous the road I choose, I have to finish o(﹏╥) o)
This is also the reason for the publication of this hydrological article. After studying for half a day, I have a little understanding of jsoup, so I try to use it to write a simple crawler.
1, Jsup overview
1.1 INTRODUCTION
jsoup is a Java HTML parser, which can directly parse a URL address and HTML text content. It provides a very labor-saving API, which can fetch and manipulate data through DOM, CSS and operation methods similar to jQuery.
1.2 main functions of jsup
- Parse HTML from a URL, file, or string.
- Use DOM or CSS selectors to find and retrieve data.
- It can manipulate HTML elements, attributes and text.
Note: jsoup is released based on MIT protocol and can be safely used in commercial projects.
Example: pandas is a NumPy based tool created to solve data analysis tasks.
2, Use steps
1.Idea importing jsoup
My idea doesn't use the cracked version, but uses the free community version. In fact, the function is enough.
First create a Maven project.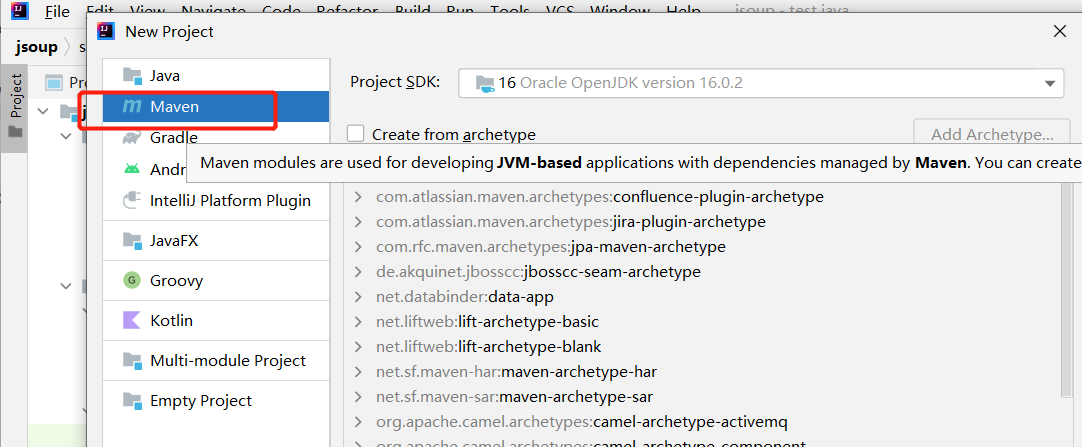
Then open Maven's official website, https://mvnrepository.com/ , search for jsoup in the search bar, like this:
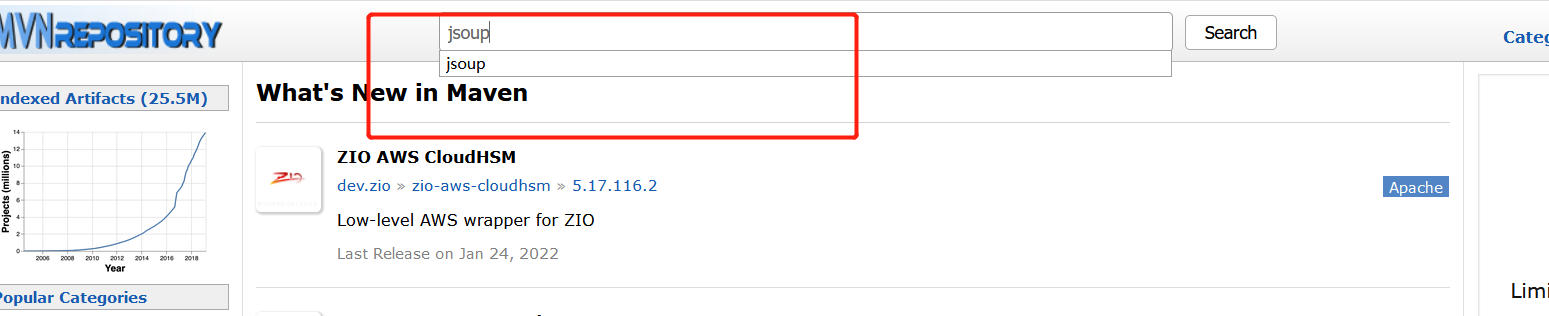
Click in:
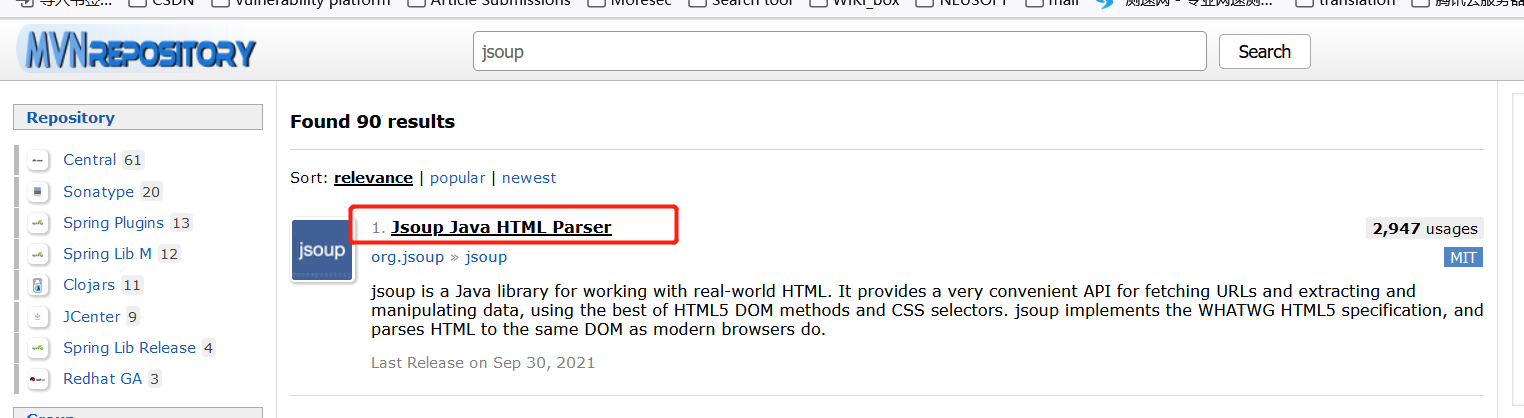
Select the latest version 1.14.3:
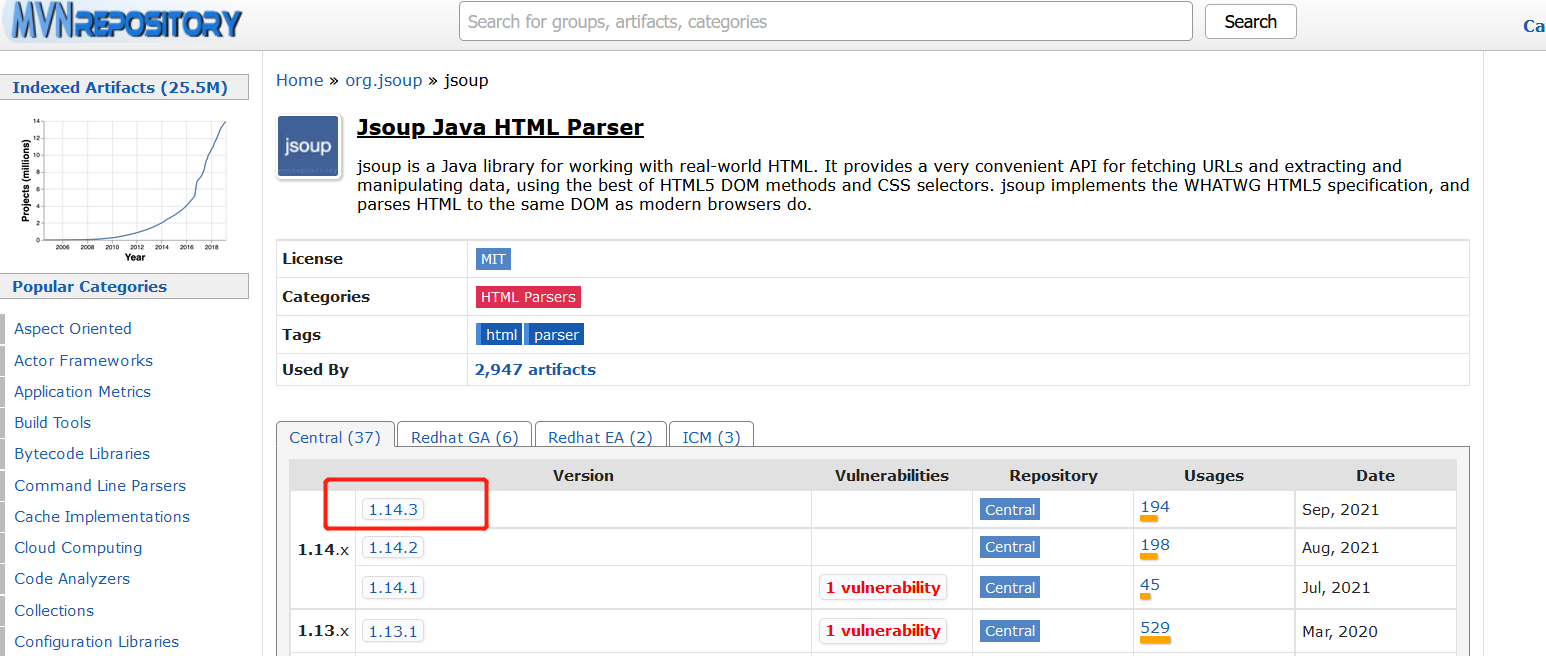
Copy this string into POM XML file:
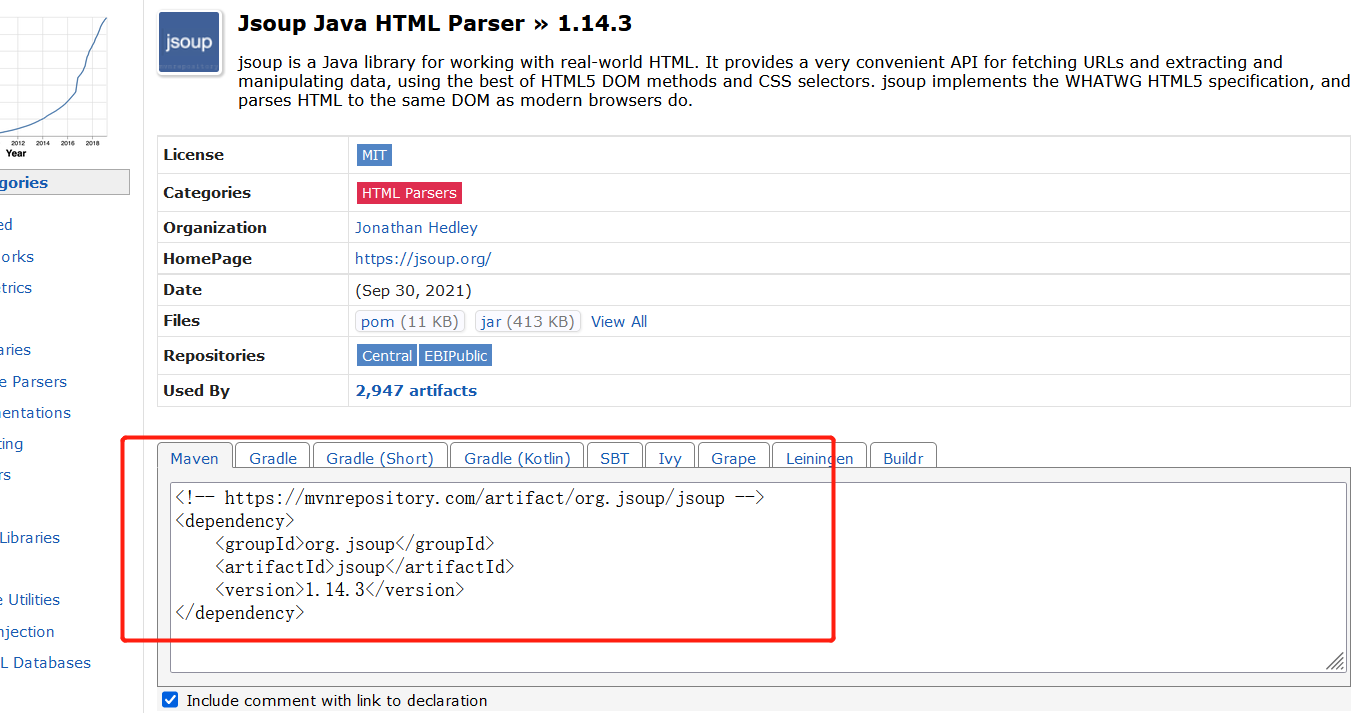
Note that you should wrap it with a < dependencies > label, otherwise an error will be reported:
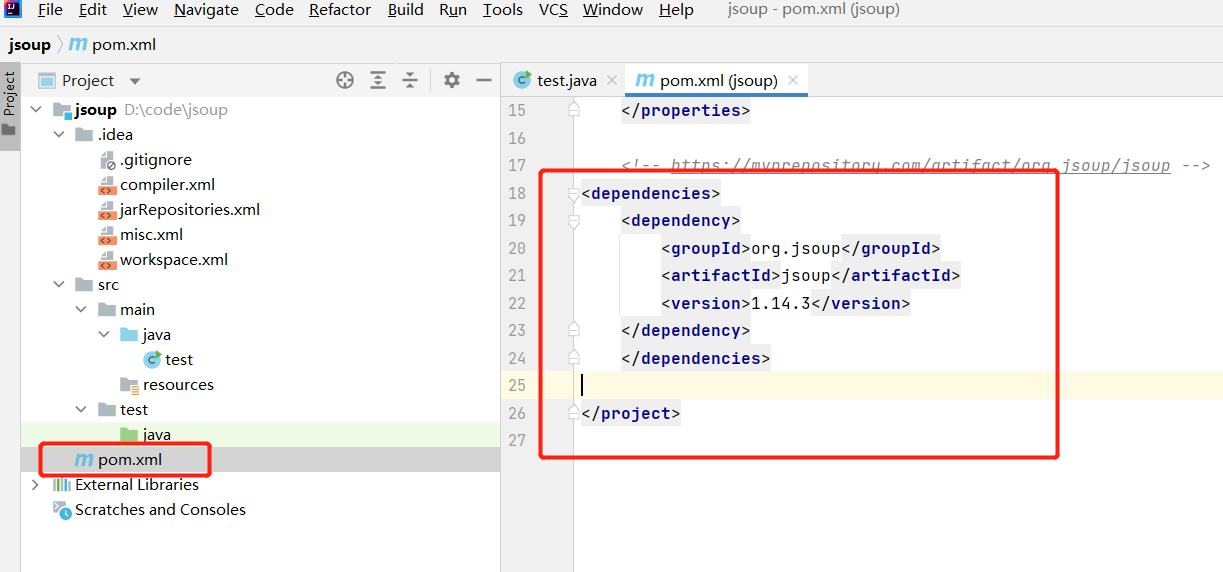
I'll paste it directly. Just copy and paste the whole paragraph into it.
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependencies>
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.14.3</version>
</dependency>
</dependencies>
2. Crawler code design
After the jsoup is configured, you can start writing crawlers.
The complete code is as follows (change the url you want to climb, and change the code accordingly):
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
public class test {
public static void main(String[] args) throws IOException {
String url = "https://mp.weixin.qq.com/s/YPrqMOYYrAtCni2VT8c4jA?";
Document document = Jsoup.parse(new URL(url), 10000);
//System.out.println(totle);
Element id = document.getElementById("js_content");
Elements imgs = id.getElementsByTag("img");
int pid = 0;
//System.out.println(imgs);
for (Element img : imgs) {
//Get data SRC attribute
String src = img.attr("data-src");
//System.out.println(src);
//Get input stream
URL target = new URL(src);
URLConnection urlConnection = target.openConnection();
InputStream inputStream = urlConnection.getInputStream();
//Output stream
pid++;
FileOutputStream outputStream = new FileOutputStream("D:\\code\\picture\\" + pid + ".jpg");
int temp = 0;
while ((temp = inputStream.read())!= -1){
outputStream.write(temp);
}
System.out.println(pid + ".jpg Download complete!");
outputStream.close();
inputStream.close();
}
}
}
Let's analyze it one by one
First of all, a bunch of things imported by import are actually added automatically by idea when typing the code.
First visit the website where you want to crawl pictures:
There are many pictures in the data SRC attribute of img tag, so the overall idea of the code is to send a request to connect to this website, obtain the response package, obtain the data SRC attribute of img tag from the response package, and finally save the input and output stream to your own computer.
1. Set a url variable and put the url address to be crawled:
String url = "https://mp.weixin.qq.com/s/YPrqMOYYrAtCni2VT8c4jA?";
Document document = Jsoup.parse(new URL(url), 10000);
//You can print it out and see the html results of the crawled page
//System.out.println(totle);
2. Navigate to img tag:
Element id = document.getElementById("js_content");
Elements imgs = id.getElementsByTag("img");
//System.out.println(imgs);
Right click on the website, click Check, and then select the image. Turn it up and see that its parent tag div has an ID called JS_ content. So document Getelementbyid ("js_content"), get the ID in the html code called JS_ Content, and then id.getElementsByTag("img") gets all IDS called JS_ All contents of img tag of content.
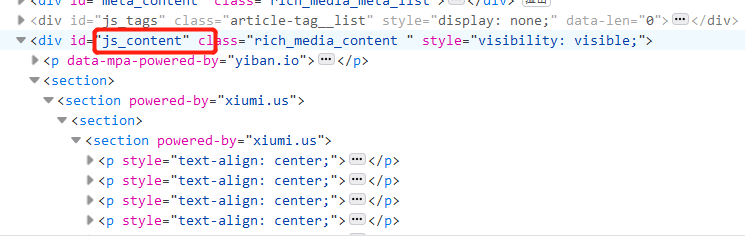
The following results can be printed out:
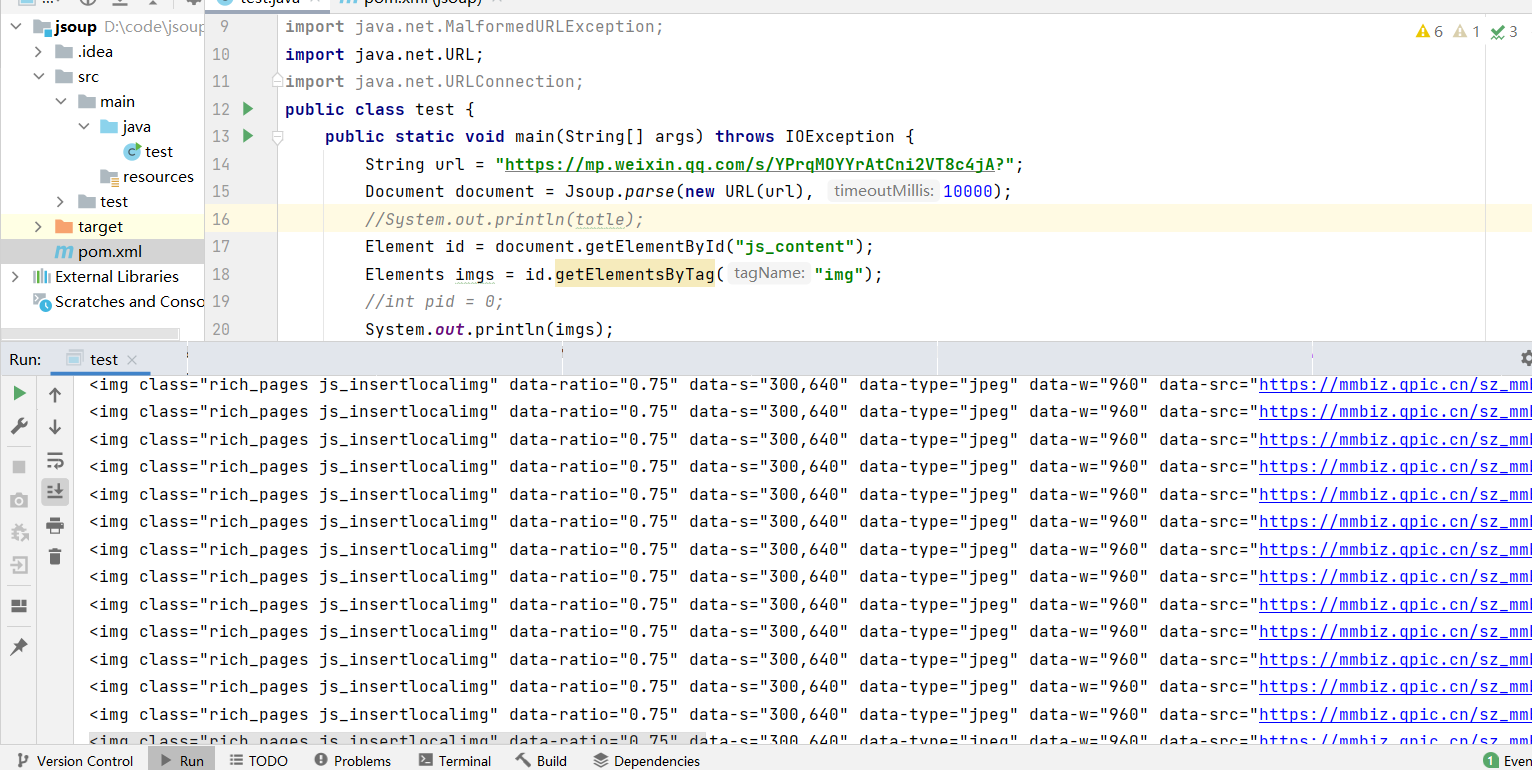
3. Climb the picture down
int pid = 0;
//System.out.println(imgs);
for (Element img : imgs) {
//Get data SRC attribute
String src = img.attr("data-src");
//System.out.println(src);
//Get input stream
URL target = new URL(src);
URLConnection urlConnection = target.openConnection();
InputStream inputStream = urlConnection.getInputStream();
//Output stream
pid++;
FileOutputStream outputStream = new FileOutputStream("D:\\code\\picture\\" + pid + ".jpg");
int temp = 0;
while ((temp = inputStream.read())!= -1){
outputStream.write(temp);
}
System.out.println(pid + ".jpg Download complete!");
outputStream.close();
inputStream.close();
}
The for loop traverses all the data SRC attribute contents, that is, the links of images.
4. Run the code, and then you can see the downloaded content on the path you set:
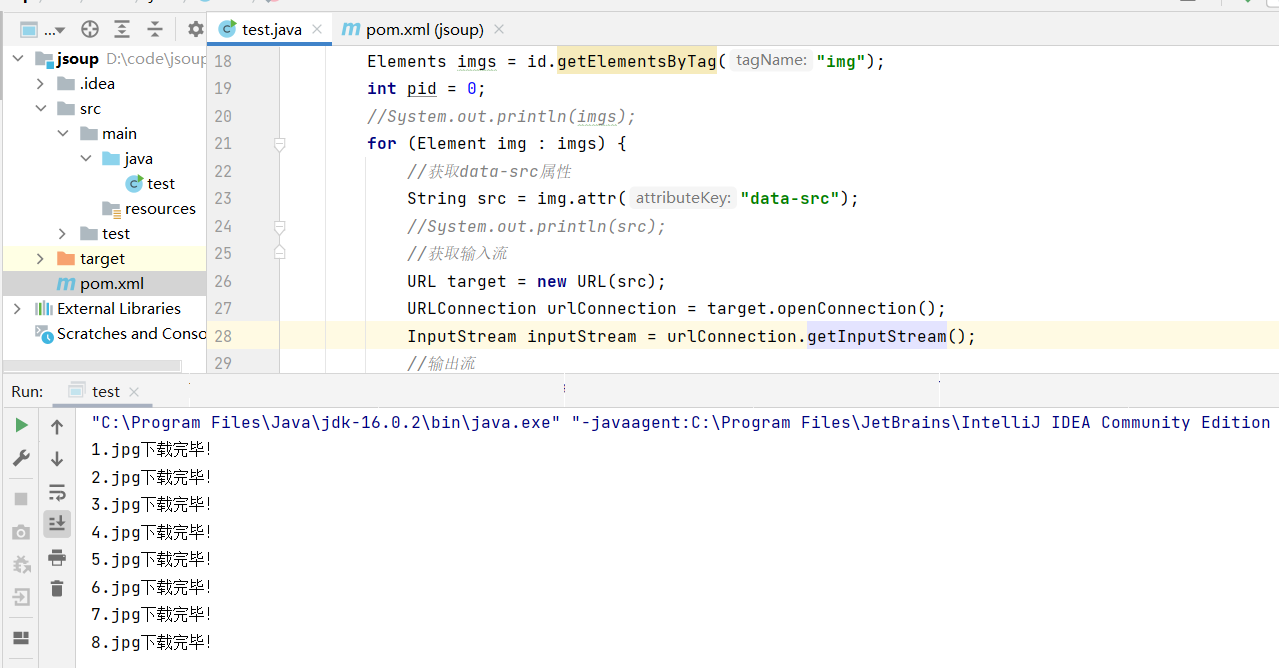 Download the picture to D:\code\picture\
Download the picture to D:\code\picture\
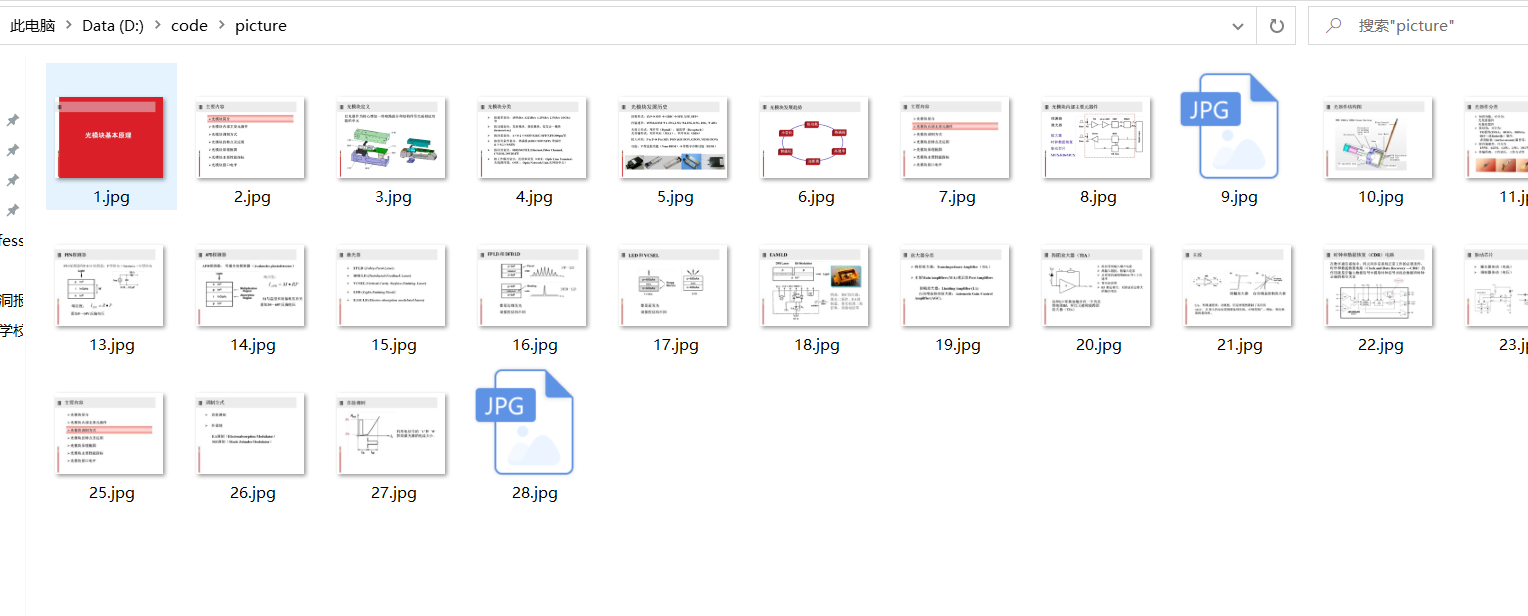
summary
Writing crawlers in java is really complex, and java is object-oriented programming. Everything is an object. I haven't learned it before, and it's difficult to understand it, but practice makes perfect, and it will be better and better.
The article is original and welcome to reprint. Please indicate the source of the article: Soon, java crawler based on jsoup .. Baidu and all kinds of collection stations are not trusted. Please identify them carefully. Technical articles generally have timeliness. I am used to revising and updating my blog posts from time to time. Therefore, please visit the source to view the latest version of this article.