[source code analysis] NVIDIA HugeCTR, GPU version parameter server - (4)
0x00 summary
In this series, we introduce HugeCTR, an industry-oriented recommendation system training framework, which is optimized for large-scale CTR models with model parallel embedding and data parallel intensive networks.
This paper mainly introduces the first two stages of the assembly line, and the last stage will be written independently. Which draws lessons from HugeCTR source code reading Thank you for this masterpiece.
Other articles in this series are as follows:
[Source code analysis] NVIDIA HugeCTR, GPU version parameter server -- (1)
[Source code analysis] NVIDIA HugeCTR, GPU version parameter server - (2)
[Source code analysis] NVIDIA HugeCTR, GPU version parameter server - (3)
0x01 overall process
Due to efficient data exchange and three-stage pipeline, the scalability of HugeCTR and the number of active GPU s have increased. This pipeline consists of three stages:
- Read data from file.
- Data transmission from host to device (between and within nodes).
- Use GPU to calculate.
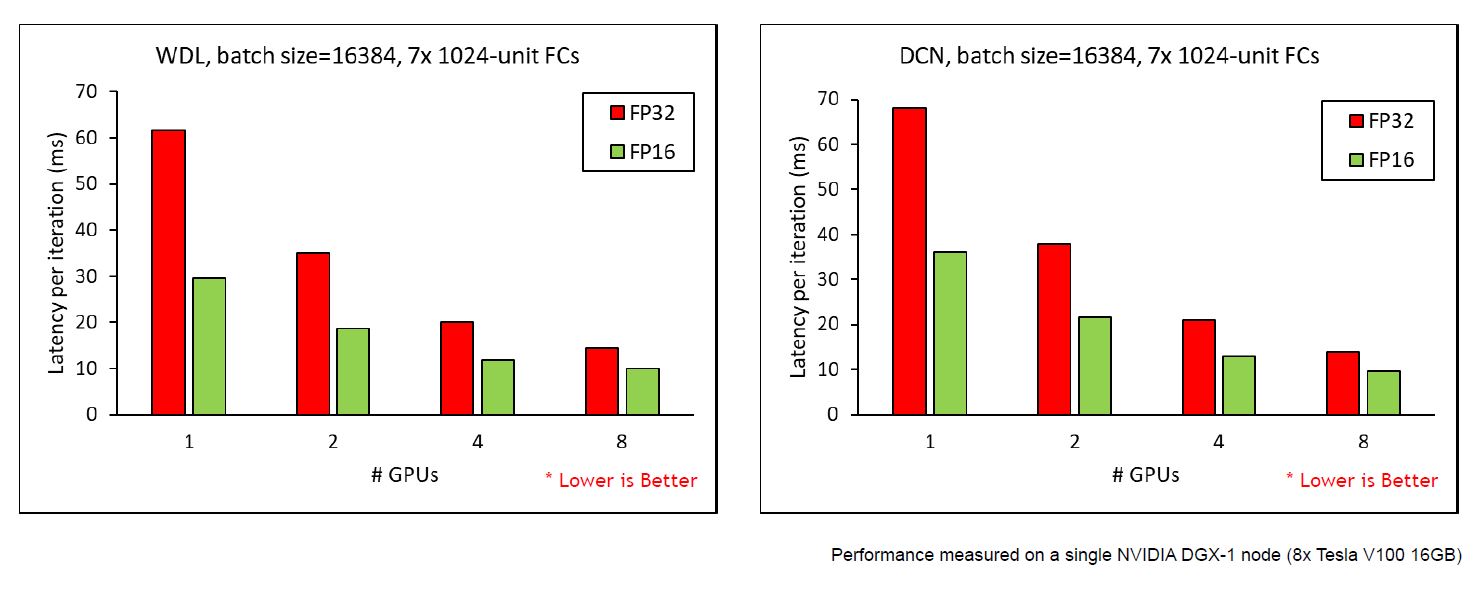
The data read overlaps and trains the GPU. The following figure shows the scalability of HugeCTR. The batch size is 16384 and there are seven layers on the DGX1 server.
0x02 DataReader
DataReader is used to copy data from data set to embedded layer. It is the entrance of the pipeline, including the first two steps of the pipeline: reading files and copying to GPU.

Figure 5. HugeCTR training pipeline with its data reader.
2.1 definitions
In order to analyze the needs, we only give member variables, and we will introduce the methods in detail when using them.
From a dynamic point of view, the following two important member variables are:
- worker_group: working thread group, which is responsible for reading data from dataset file into memory. This can be regarded as the first level of pipeline. In the previous version, there was a HeapEx data structure used for intermediate cache. At present, this data structure has been removed.
- data_collector_ : Have a thread responsible for copying data to GPU. This can be considered the second stage of the pipeline.
From a static point of view, there are mainly three buffer s:
- std::vector<std::shared_ ptr<ThreadBuffer>> thread_ buffers_: The buffer used internally by the thread.
- std::shared_ ptr<BroadcastBuffer> broadcast_ buffer_: It is used for subsequent interaction with the collector, which takes it as an intermediate buffer.
- std::shared_ ptr<DataReaderOutput> output_: The output of reader, the last read of training is here.
The data flow of the above three buffers is threadbuffer -- > broadcastbuffer -- > datareaderoutput.
From the perspective of resources, it is:
- std::shared_ptr resource_manager_ : This is the member variable of Session, which is passed in the DataReader constructor.
- const std::vector params_ : This is the meta information of spark parameters sorted out according to the configuration file.
/**
* @brief Data reading controller.
*
* Control the data reading from data set to embedding.
* An instance of DataReader will maintain independent
* threads for data reading (IDataReaderWorker)
* from dataset to heap. Meanwhile one independent
* thread consumes the data (DataCollector),
* and copy the data to GPU buffer.
*/
template <typename TypeKey>
class DataReader : public IDataReader {
private:
std::vector<std::shared_ptr<ThreadBuffer>> thread_buffers_; // gpu_id -> thread_idx
std::shared_ptr<BroadcastBuffer> broadcast_buffer_;
std::shared_ptr<DataReaderOutput> output_;
std::shared_ptr<DataReaderWorkerGroup> worker_group_;
std::shared_ptr<DataCollector<TypeKey>> data_collector_; /**< pointer of DataCollector */
/* Each gpu will have several csr output for different embedding */
const std::vector<DataReaderSparseParam> params_;
std::shared_ptr<ResourceManager> resource_manager_; /**< gpu resource used in this data reader*/
const size_t batchsize_; /**< batch size */
const size_t label_dim_; /**< dimention of label e.g. 1 for BinaryCrossEntropy */
const size_t dense_dim_; /**< dimention of dense */
long long current_batchsize_;
bool repeat_;
std::string file_name_;
SourceType_t source_type_;
}
2.2 construction
The construction of DataReader is divided into two parts:
- In the constructor:
- Configure various buffer s.
- Build a DataCollector for.
- In create_ Train will be processed separately in datareader_ data_ reader and evaluate_data_reader, that is, two readers for training and evaluation. Then a workgroup will be established for them.
We first omit the analysis of the constructor because it involves a series of data structures. After introducing the data structure, we will discuss it.
2.3 DataReaderSparseParam
2.3.1 definitions
DataReaderSparseParam is the meta information of the spare parameter obtained according to the configuration. Its main member variables are as follows:
-
sparse_name is the name of the sparse input tensor referenced by its subsequent layers. There is no default value, which should be specified by the user.
-
nnz_per_slot is the maximum number of features entered by the specified spark for each slot.
- ‘nnz_per_slot 'can be' int ', that is, the average nnz of each slot, so the maximum number of functions of each instance should be' nnz '_ per_ slot*slot_ num’.
- Alternatively, you can use List[int] to initialize 'nnz'_ per_ Slot ', then the maximum number of features of each sample should be' sum(nnz_per_slot) ', in which case, the array' nnz_ per_ The length of 'slot' should be the same as' slot '_ Num 'is the same.
-
'is_ fixed_ Length 'is used to identify whether the category inputs of each slot in all samples have the same length. If different samples have the same number of characteristics for each slot, the user can set "is_fixed_length=True", and Hugetr can use this information to reduce the data transmission time.
-
slot_num specifies the number of slots used for this sparse input in the dataset.
- **Note: * * if multiple 'DataReaderSparseParam' are specified, there should be no overlap between any pair of 'DataReaderSparseParam'. For example, in [wdl samples] (... / samples/wdl/wdl.py), we have a total of 27 slots; We specify the first slot as "wide_data" and the next 26 slots as "deep_data".
struct DataReaderSparseParam {
std::string top_name;
std::vector<int> nnz_per_slot;
bool is_fixed_length;
int slot_num;
DataReaderSparse_t type;
int max_feature_num;
int max_nnz;
DataReaderSparseParam() {}
DataReaderSparseParam(const std::string& top_name_, const std::vector<int>& nnz_per_slot_,
bool is_fixed_length_, int slot_num_)
: top_name(top_name_),
nnz_per_slot(nnz_per_slot_),
is_fixed_length(is_fixed_length_),
slot_num(slot_num_),
type(DataReaderSparse_t::Distributed) {
max_feature_num = std::accumulate(nnz_per_slot.begin(), nnz_per_slot.end(), 0);
max_nnz = *std::max_element(nnz_per_slot.begin(), nnz_per_slot.end());
}
DataReaderSparseParam(const std::string& top_name_, const int nnz_per_slot_,
bool is_fixed_length_, int slot_num_)
: top_name(top_name_),
nnz_per_slot(slot_num_, nnz_per_slot_),
is_fixed_length(is_fixed_length_),
slot_num(slot_num_),
type(DataReaderSparse_t::Distributed) {
max_feature_num = std::accumulate(nnz_per_slot.begin(), nnz_per_slot.end(), 0);
max_nnz = *std::max_element(nnz_per_slot.begin(), nnz_per_slot.end());
}
};
2.3.2 use
As mentioned earlier, Parser is used to parse configuration files, and HugeCTR also supports code settings. For example, two DataReaderSparseParam and corresponding DistributedSlotSparseEmbeddingHash are set below.
model = hugectr.Model(solver, reader, optimizer)
model.add(hugectr.Input(label_dim = 1, label_name = "label",
dense_dim = 13, dense_name = "dense",
data_reader_sparse_param_array =
[hugectr.DataReaderSparseParam("wide_data", 30, True, 1),
hugectr.DataReaderSparseParam("deep_data", 2, False, 26)]))
model.add(hugectr.SparseEmbedding(embedding_type = hugectr.Embedding_t.DistributedSlotSparseEmbeddingHash,
workspace_size_per_gpu_in_mb = 23,
embedding_vec_size = 1,
combiner = "sum",
sparse_embedding_name = "sparse_embedding2",
bottom_name = "wide_data",
optimizer = optimizer))
model.add(hugectr.SparseEmbedding(embedding_type = hugectr.Embedding_t.DistributedSlotSparseEmbeddingHash,
workspace_size_per_gpu_in_mb = 358,
embedding_vec_size = 16,
combiner = "sum",
sparse_embedding_name = "sparse_embedding1",
bottom_name = "deep_data",
optimizer = optimizer))
0x03 DataReader Buffer mechanism
Next, let's look at several buffers of DataReader. Depending on these buffers, HugeCTR implements the first two stages of the pipeline.
3.1 comparison
We must first make a historical comparison to see the development context of this part of the code. Let's look at the code of version 3.1 first. DataReader we selected some member variables. Before version 3.1, a heap was used for operation, that is, the following csr_heap_.
class DataReader : public IDataReader {
std::shared_ptr<HeapEx<CSRChunk<TypeKey>>> csr_heap_; /**< heap to cache the data set */
Tensors2<float> label_tensors_; /**< Label tensors for the usage of loss */
std::vector<TensorBag2> dense_tensors_; /**< Dense tensors for the usage of loss */
/* Each gpu will have several csr output for different embedding */
Tensors2<TypeKey> csr_buffers_; /**< csr_buffers contains row_offset_tensor and value_tensors */
Tensors2<TypeKey> row_offsets_tensors_; /**< row offset tensors*/
Tensors2<TypeKey> value_tensors_; /**< value tensors */
std::vector<std::shared_ptr<size_t>> nnz_array_;
const size_t label_dim_; /**< dimention of label e.g. 1 for BinaryCrossEntropy */
const size_t dense_dim_; /**< dimention of dense */
}
Let's take a look at the code of version 3.2.1, which also selects some member variables.
template <typename TypeKey>
class DataReader : public IDataReader {
std::vector<std::shared_ptr<ThreadBuffer>> thread_buffers_; // gpu_id -> thread_idx
std::shared_ptr<BroadcastBuffer> broadcast_buffer_;
std::shared_ptr<DataReaderOutput> output_;
const size_t label_dim_; /**< dimention of label e.g. 1 for BinaryCrossEntropy */
const size_t dense_dim_; /**< dimention of dense */
}
3.2.1 here is:
- label_tensors_, dense_tensors_ Move to AsyncReader.
- Put csr_heap_ Using thread_buffers_, broadcast_buffer_, output_ And so on.
- Put row_offsets_tensors_, value_tensors_, nnz_array_ Wait, use ThreadBuffer, BroadcastBuffer and SparseTensorBag in DataReaderOutput to manage CSR uniformly.
3.2 Buffer related classes
Let's compare the historical versions above.
- In previous versions (such as 3.1), there was a HeapEX class, which implemented a data caching function between CPU and GPU.
- In the latest version, it is changed to a series of buffer related classes, such as ThreadBuffer and BroadcastBuffer, whose states are implemented by BufferState.
enum class BufferState : int { FileEOF, Reading, ReadyForRead, Writing, ReadyForWrite };
The following are the definitions of three buffer s.
struct ThreadBuffer {
std::vector<SparseTensorBag> device_sparse_buffers; // same number as embedding number
std::vector<unsigned char> is_fixed_length; // same number as embedding number
TensorBag2 device_dense_buffers;
std::atomic<BufferState> state;
long long current_batch_size;
int batch_size;
size_t param_num;
int label_dim;
int dense_dim;
int batch_size_start_idx; // dense buffer
int batch_size_end_idx;
};
struct BroadcastBuffer {
std::vector<SparseTensorBag>
sparse_buffers; // same number as (embedding number * local device number)
std::vector<unsigned char> is_fixed_length; // same number as embedding number
std::vector<TensorBag2> dense_tensors; // same number as local device number
std::vector<cudaEvent_t> finish_broadcast_events; // same number as local device number
std::atomic<BufferState> state;
long long current_batch_size;
size_t param_num;
};
struct DataReaderOutput {
std::map<std::string, std::vector<SparseTensorBag>> sparse_tensors_map;
std::vector<std::string> sparse_name_vec;
std::vector<TensorBag2> label_tensors;
std::vector<TensorBag2> dense_tensors;
bool use_mixed_precision;
int label_dense_dim;
};
The above classes correspond to the following member variables of DataReader.
class DataReader : public IDataReader {
private:
std::vector<std::shared_ptr<ThreadBuffer>> thread_buffers_; // gpu_id -> thread_idx
std::shared_ptr<BroadcastBuffer> broadcast_buffer_;
std::shared_ptr<DataReaderOutput> output_;
}
Next, we will analyze them one by one.
3.3 DataReader structure
We skipped the constructor of DataReader. Next, we analyze the constructor. Its main function is to reserve space for three buffer s, allocate memory, and finally build the collector.
DataReader(int batchsize, size_t label_dim, int dense_dim,
std::vector<DataReaderSparseParam> ¶ms,
const std::shared_ptr<ResourceManager> &resource_manager, bool repeat, int num_threads,
bool use_mixed_precision)
: broadcast_buffer_(new BroadcastBuffer()),
output_(new DataReaderOutput()),
params_(params),
resource_manager_(resource_manager),
batchsize_(batchsize),
label_dim_(label_dim),
dense_dim_(dense_dim),
repeat_(repeat) {
size_t local_gpu_count = resource_manager_->get_local_gpu_count();
size_t total_gpu_count = resource_manager_->get_global_gpu_count();
// batchsize_ is a multiple of total_gpu_count
size_t batch_size_per_gpu = batchsize_ / total_gpu_count;
// 1. A temporary variable buffs is generated to allocate memory specifically. There are several cudaallocators, and each CudaAllocator corresponds to i GPU s
std::vector<std::shared_ptr<GeneralBuffer2<CudaAllocator>>> buffs;
// Reserve some memory space first
buffs.reserve(local_gpu_count);
// Initialize a GeneralBuffer2 for each GPU
for (size_t i = 0; i < local_gpu_count; ++i) {
buffs.push_back(GeneralBuffer2<CudaAllocator>::create());
}
// 2. Reserved buffer
// Process thread_buffers_
thread_buffers_.reserve(num_threads);
for (int i = 0; i < num_threads; ++i) {
// a worker may maintain multiple buffers on device i % local_gpu_count
auto local_gpu = resource_manager_->get_local_gpu(i % local_gpu_count);
CudaCPUDeviceContext context(local_gpu->get_device_id());
auto &buff = buffs[i % local_gpu_count]; // Find the CudaAllocator corresponding to the corresponding GPU and allocate it
std::shared_ptr<ThreadBuffer> current_thread_buffer = std::make_shared<ThreadBuffer>();
thread_buffers_.push_back(current_thread_buffer);
current_thread_buffer->device_sparse_buffers.reserve(params.size());
current_thread_buffer->is_fixed_length.reserve(params.size()); // reserve of vector
for (size_t param_id = 0; param_id < params.size(); ++param_id) {
auto ¶m = params_[param_id];
SparseTensor<TypeKey> temp_sparse_tensor;
// Reserved memory
buff->reserve({(size_t)batchsize, (size_t)param.max_feature_num}, param.slot_num,
&temp_sparse_tensor);
current_thread_buffer->device_sparse_buffers.push_back(temp_sparse_tensor.shrink());
current_thread_buffer->is_fixed_length.push_back(param.is_fixed_length);
}
Tensor2<float> temp_dense_tensor;
// Reserved memory
buff->reserve({batch_size_per_gpu * local_gpu_count, label_dim + dense_dim},
&temp_dense_tensor);
current_thread_buffer->device_dense_buffers = temp_dense_tensor.shrink();
current_thread_buffer->state.store(BufferState::ReadyForWrite);
current_thread_buffer->current_batch_size = 0;
current_thread_buffer->batch_size = batchsize;
current_thread_buffer->param_num = params.size();
current_thread_buffer->label_dim = label_dim;
current_thread_buffer->dense_dim = dense_dim;
current_thread_buffer->batch_size_start_idx =
batch_size_per_gpu * resource_manager_->get_gpu_global_id_from_local_id(0);
current_thread_buffer->batch_size_end_idx =
current_thread_buffer->batch_size_start_idx + batch_size_per_gpu * local_gpu_count;
}
// When dealing with broadcast buffer, note that reserve here is the method of vector data structure, not reserved memory
broadcast_buffer_->sparse_buffers.reserve(local_gpu_count * params.size());
broadcast_buffer_->is_fixed_length.reserve(local_gpu_count * params.size());
broadcast_buffer_->dense_tensors.reserve(local_gpu_count);
broadcast_buffer_->finish_broadcast_events.resize(local_gpu_count);
broadcast_buffer_->state.store(BufferState::ReadyForWrite);
broadcast_buffer_->current_batch_size = 0;
broadcast_buffer_->param_num = params.size();
// When processing output buffer, note that reserve here is the method of vector data structure, not reserved memory
output_->dense_tensors.reserve(local_gpu_count);
output_->label_tensors.reserve(local_gpu_count);
output_->use_mixed_precision = use_mixed_precision;
output_->label_dense_dim = label_dim + dense_dim;
// Reserve the sparse tensor. Note that reserve here is the method of vector data structure, not memory
for (size_t param_id = 0; param_id < params.size(); ++param_id) {
auto ¶m = params_[param_id];
output_->sparse_tensors_map[param.top_name].reserve(local_gpu_count);
output_->sparse_name_vec.push_back(param.top_name);
}
// Traverse the local GPU
for (size_t local_id = 0; local_id < local_gpu_count; ++local_id) {
// You still need to find the corresponding CudaAllocator for each GPU for allocation
auto local_gpu = resource_manager_->get_local_gpu(local_id);
CudaDeviceContext ctx(local_gpu->get_device_id());
auto &buff = buffs[local_id];
for (size_t param_id = 0; param_id < params.size(); ++param_id) {
auto ¶m = params_[param_id];
SparseTensor<TypeKey> temp_sparse_tensor;
// To broadcast_buffer_ Allocate memory
buff->reserve({(size_t)batchsize, (size_t)param.max_feature_num}, param.slot_num,
&temp_sparse_tensor);
broadcast_buffer_->sparse_buffers.push_back(temp_sparse_tensor.shrink());
broadcast_buffer_->is_fixed_length.push_back(param.is_fixed_length);
}
Tensor2<float> temp_dense_tensor;
buff->reserve({batch_size_per_gpu, label_dim + dense_dim}, &temp_dense_tensor);
broadcast_buffer_->dense_tensors.push_back(temp_dense_tensor.shrink());
CK_CUDA_THROW_(cudaEventCreateWithFlags(&broadcast_buffer_->finish_broadcast_events[local_id],
cudaEventDisableTiming));
for (size_t param_id = 0; param_id < params.size(); ++param_id) {
auto ¶m = params_[param_id];
SparseTensor<TypeKey> temp_sparse_tensor;
// Reserved memory
buff->reserve({(size_t)batchsize, (size_t)param.max_feature_num}, param.slot_num,
&temp_sparse_tensor);
output_->sparse_tensors_map[param.top_name].push_back(temp_sparse_tensor.shrink());
}
Tensor2<float> label_tensor;
// Reserved memory
buff->reserve({batch_size_per_gpu, label_dim}, &label_tensor);
output_->label_tensors.push_back(label_tensor.shrink());
if (use_mixed_precision) {
Tensor2<__half> dense_tensor;
// Reserved memory
buff->reserve({(size_t)batch_size_per_gpu, (size_t)dense_dim}, &dense_tensor);
output_->dense_tensors.push_back(dense_tensor.shrink());
} else {
Tensor2<float> dense_tensor;
// Reserved memory
buff->reserve({(size_t)batch_size_per_gpu, (size_t)dense_dim}, &dense_tensor);
output_->dense_tensors.push_back(dense_tensor.shrink());
}
buff->allocate(); // 3. Allocate memory
}
// 4. Data collector construction
data_collector_ = std::make_shared<DataCollector<TypeKey>>(thread_buffers_, broadcast_buffer_,
output_, resource_manager);
return;
}
Next, we will carefully divide the various parts of the construction code.
3.3.1 auxiliary GeneralBuffer2
First, we analyze the buffs part of the above code. The function of this variable is to uniformly allocate memory.
// 1. A temporary variable buffs is generated
std::vector<std::shared_ptr<GeneralBuffer2<CudaAllocator>>> buffs;
// Reserve some capacity first
buffs.reserve(local_gpu_count);
// Initialize a GeneralBuffer2 for each GPU
for (size_t i = 0; i < local_gpu_count; ++i) {
buffs.push_back(GeneralBuffer2<CudaAllocator>::create());
}
3.3.2 ThreadBuffer
Then let's see how to handle thread_buffers_ Part, here is to process the thread buffer. First, we get the ThreadBuffer class definition as follows, which can be compared during later analysis.
struct ThreadBuffer {
std::vector<SparseTensorBag> device_sparse_buffers; // same number as embedding number
std::vector<unsigned char> is_fixed_length; // same number as embedding number
TensorBag2 device_dense_buffers;
std::atomic<BufferState> state;
long long current_batch_size;
int batch_size;
size_t param_num;
int label_dim;
int dense_dim;
int batch_size_start_idx; // dense buffer
int batch_size_end_idx;
};
Secondly, the logic in the specific construction function is as follows:
- First, for thread_buffers_ This vector will expand the vector capacity to the number of threads.
- Get the buffer corresponding to the thread (or GPU) in the buffers and assign it to the buffer.
- For each thread, a ThreadBuffer named current will be generated_ thread_ Buffer, put it into thread_buffers_ in
- For each ThreadBuffer, the device of ThreadBuffer is reserved_ sparse_ Buffers and is_fixed_length the capacity of these two vector s.
- Traverse the spark parameter. For each parameter, a temporary tensor will be established, and the memory (CPU or GPU) will be reserved through buff, and then put this temporary tensor into device_sparse_buffers.
- Establish a tensor for dense, reserve tensor memory through buff, and put the temporary tensor into device_dense_buffers.
- Set current_thread_buffer status.
- Set current_thread_buffer other information.
// Process thread_buffers_, It will expand the vector capacity to the number of threads
thread_buffers_.reserve(num_threads);
for (int i = 0; i < num_threads; ++i) { // Traversal thread
// a worker may maintain multiple buffers on device i % local_gpu_count
auto local_gpu = resource_manager_->get_local_gpu(i % local_gpu_count);
CudaCPUDeviceContext context(local_gpu->get_device_id());
auto &buff = buffs[i % local_gpu_count]; // Get the corresponding buffer of the thread (or GPU) in the buffers
// Generate a ThreadBuffer and store it into thread_buffers_
std::shared_ptr<ThreadBuffer> current_thread_buffer = std::make_shared<ThreadBuffer>();
thread_buffers_.push_back(current_thread_buffer);
// Reserved ThreadBuffer device_sparse_buffers and is_fixed_length the capacity of these two vector s
current_thread_buffer->device_sparse_buffers.reserve(params.size());
current_thread_buffer->is_fixed_length.reserve(params.size());
// Traversal parameters
for (size_t param_id = 0; param_id < params.size(); ++param_id) {
auto ¶m = params_[param_id];
SparseTensor<TypeKey> temp_sparse_tensor;
// Create a temporary tensor and reserve memory (CPU or GPU)
buff->reserve({(size_t)batchsize, (size_t)param.max_feature_num}, param.slot_num,
&temp_sparse_tensor);
// Put the tensor into device_sparse_buffers
current_thread_buffer->device_sparse_buffers.push_back(temp_sparse_tensor.shrink());
current_thread_buffer->is_fixed_length.push_back(param.is_fixed_length);
}
// Establish a tensor for dense
Tensor2<float> temp_dense_tensor;
// Reserved tensor memory
buff->reserve({batch_size_per_gpu * local_gpu_count, label_dim + dense_dim},
&temp_dense_tensor);
// Put the temporary tensor into the device_dense_buffers
current_thread_buffer->device_dense_buffers = temp_dense_tensor.shrink();
// Set status
current_thread_buffer->state.store(BufferState::ReadyForWrite);
// Set additional information
current_thread_buffer->current_batch_size = 0;
current_thread_buffer->batch_size = batchsize;
current_thread_buffer->param_num = params.size();
current_thread_buffer->label_dim = label_dim;
current_thread_buffer->dense_dim = dense_dim;
current_thread_buffer->batch_size_start_idx =
batch_size_per_gpu * resource_manager_->get_gpu_global_id_from_local_id(0);
current_thread_buffer->batch_size_end_idx =
current_thread_buffer->batch_size_start_idx + batch_size_per_gpu * local_gpu_count;
}
At this point, note that the DataReader includes multiple ThreadBuffer.
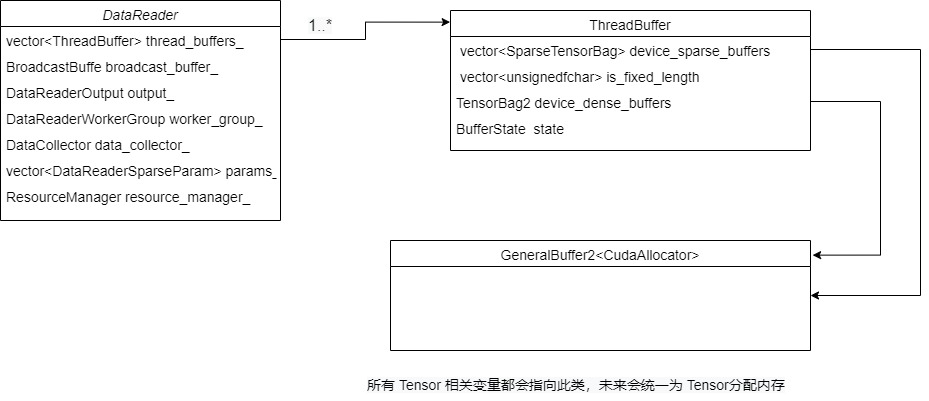
3.3.3 BroadcastBuffer
Next, let's look at how to build a BroadcastBuffer.
BroadcastBuffer is defined as follows:
struct BroadcastBuffer {
std::vector<SparseTensorBag>
sparse_buffers; // same number as (embedding number * local device number)
std::vector<unsigned char> is_fixed_length; // same number as embedding number
std::vector<TensorBag2> dense_tensors; // same number as local device number
std::vector<cudaEvent_t> finish_broadcast_events; // same number as local device number
std::atomic<BufferState> state;
long long current_batch_size;
size_t param_num;
};
According to the construction code, only some reservations and settings are made here, and memory is not involved. Memory will be processed uniformly in the future.
// Handle broadcast buffer // Reserved vector capacity broadcast_buffer_->sparse_buffers.reserve(local_gpu_count * params.size()); // Reserved vector capacity broadcast_buffer_->is_fixed_length.reserve(local_gpu_count * params.size()); // Reserved vector capacity broadcast_buffer_->dense_tensors.reserve(local_gpu_count); broadcast_buffer_->finish_broadcast_events.resize(local_gpu_count); // Set status broadcast_buffer_->state.store(BufferState::ReadyForWrite); broadcast_buffer_->current_batch_size = 0; broadcast_buffer_->param_num = params.size();
3.3.4 DataReaderOutput
Let's next look at how to build DataReaderOutput.
struct DataReaderOutput {
std::map<std::string, std::vector<SparseTensorBag>> sparse_tensors_map;
std::vector<std::string> sparse_name_vec;
std::vector<TensorBag2> label_tensors;
std::vector<TensorBag2> dense_tensors;
bool use_mixed_precision;
int label_dense_dim;
};
According to the construction code, only some reservations and settings are made here, and memory is not involved. Memory will be processed uniformly in the future.
output_->dense_tensors.reserve(local_gpu_count); // Reserved vector capacity
output_->label_tensors.reserve(local_gpu_count); // Reserved vector capacity
output_->use_mixed_precision = use_mixed_precision;
output_->label_dense_dim = label_dim + dense_dim;
for (size_t param_id = 0; param_id < params.size(); ++param_id) {
auto ¶m = params_[param_id];
output_->sparse_tensors_map[param.top_name].reserve(local_gpu_count);
output_->sparse_name_vec.push_back(param.top_name);
}
3.3.5 reservation and allocation
broadcast and output will be reserved here, and memory will be allocated uniformly here.
for (size_t local_id = 0; local_id < local_gpu_count; ++local_id) { // Traverse GPU
auto local_gpu = resource_manager_->get_local_gpu(local_id);
CudaDeviceContext ctx(local_gpu->get_device_id());
auto &buff = buffs[local_id]; // Get the allocator corresponding to a local gpu in the temporary buffs
for (size_t param_id = 0; param_id < params.size(); ++param_id) {
auto ¶m = params_[param_id];
SparseTensor<TypeKey> temp_sparse_tensor;
// Allocate spark memory
buff->reserve({(size_t)batchsize, (size_t)param.max_feature_num}, param.slot_num,
&temp_sparse_tensor);
// Assign to broadcast
broadcast_buffer_->sparse_buffers.push_back(temp_sparse_tensor.shrink());
broadcast_buffer_->is_fixed_length.push_back(param.is_fixed_length);
}
// Allocate deny memory
Tensor2<float> temp_dense_tensor;
buff->reserve({batch_size_per_gpu, label_dim + dense_dim}, &temp_dense_tensor);
// Assign to broadcast
broadcast_buffer_->dense_tensors.push_back(temp_dense_tensor.shrink());
CK_CUDA_THROW_(cudaEventCreateWithFlags(&broadcast_buffer_->finish_broadcast_events[local_id],
cudaEventDisableTiming));
for (size_t param_id = 0; param_id < params.size(); ++param_id) {
auto ¶m = params_[param_id];
// Allocate spark memory
SparseTensor<TypeKey> temp_sparse_tensor;
buff->reserve({(size_t)batchsize, (size_t)param.max_feature_num}, param.slot_num,
&temp_sparse_tensor);
// Assign to output
output_->sparse_tensors_map[param.top_name].push_back(temp_sparse_tensor.shrink());
}
// Allocate memory for label
Tensor2<float> label_tensor;
buff->reserve({batch_size_per_gpu, label_dim}, &label_tensor);
// Assign to output
output_->label_tensors.push_back(label_tensor.shrink());
if (use_mixed_precision) {
Tensor2<__half> dense_tensor;
// Allocate deny memory
buff->reserve({(size_t)batch_size_per_gpu, (size_t)dense_dim}, &dense_tensor);
// Assign to output
output_->dense_tensors.push_back(dense_tensor.shrink());
} else {
Tensor2<float> dense_tensor;
// Allocate deny memory
buff->reserve({(size_t)batch_size_per_gpu, (size_t)dense_dim}, &dense_tensor);
// Assign to output
output_->dense_tensors.push_back(dense_tensor.shrink());
}
buff->allocate(); // Uniform distribution
}
The specific logic of reserving buffer is as follows:
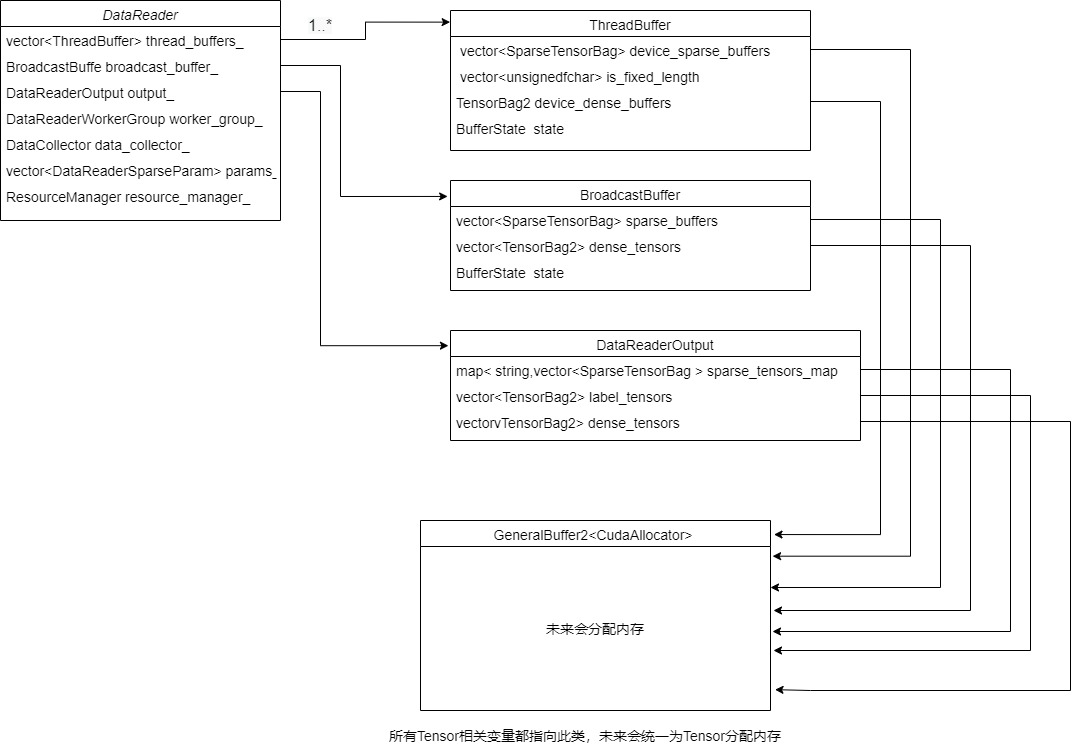
After allocation, it should be noted that these are simplified versions and do not reflect the status of multiple local GPUs. For example, the member variables of the following three classes will be assigned to multiple local GPUs.
// embedding number refers to the number of DataReaderSparseParam in this model, that is, there are several embedding layers
struct ThreadBuffer {
std::vector<SparseTensorBag> device_sparse_buffers; // same number as embedding number
// device_sparse_buffers are allocated over multiple local GPU s
struct BroadcastBuffer {
std::vector<SparseTensorBag>
sparse_buffers; // same number as (embedding number * local device number)
// sparse_buffers will also be allocated over multiple local GPU s
struct DataReaderOutput {
std::map<std::string, std::vector<SparseTensorBag>> sparse_tensors_map;
// Each spark_ tensors_ Map [param. Top_name] will be allocated on multiple local GPU s
// For example, output_ - > sparse_ tensors_ map[param.top_name]. reserve(local_gpu_count);
In the following simplified versions, only one GPU is reflected, and these buffer s are located on the GPU.
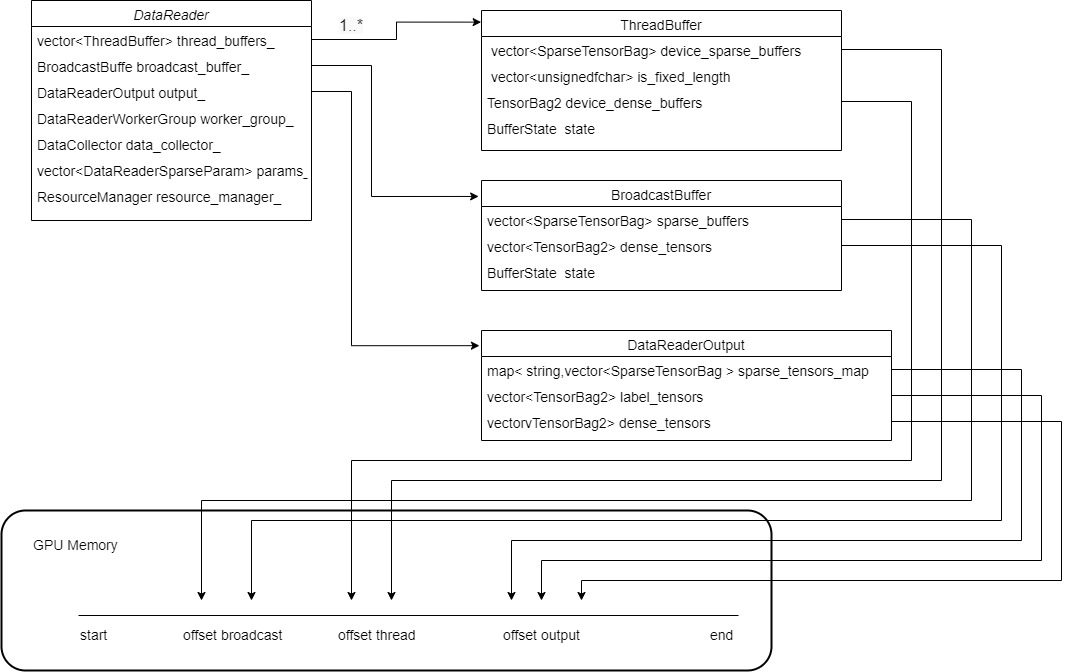
Now DataReader has a series of buffer s. Let's see how to use them.
0x04 DataReaderWorkerGroup
DataReaderWorkerGroup is responsible for specific data reading operations.
4.1 construction
In create_ In datareader, the following code is used to establish DataReaderWorkerGroup, which corresponds to three groups respectively.
switch (format) {
case DataReaderType_t::Norm: {
train_data_reader->create_drwg_norm(source_data, check_type, start_right_now);
evaluate_data_reader->create_drwg_norm(eval_source, check_type, start_right_now);
break;
}
case DataReaderType_t::Raw: {
train_data_reader->create_drwg_raw(source_data, num_samples, float_label_dense, true,
false);
evaluate_data_reader->create_drwg_raw(eval_source, eval_num_samples, float_label_dense,
false, false);
break;
}
case DataReaderType_t::Parquet: {
train_data_reader->create_drwg_parquet(source_data, slot_offset, true);
evaluate_data_reader->create_drwg_parquet(eval_source, slot_offset, true);
break;
}
We use create_drwg_norm to continue the analysis and found that it built DataReaderWorkerGroupNorm. That is, the member variable worker in the DataReader is configured_ group_ For a DataReaderWorkerGroupNorm.
Note that thread is passed in here_ buffers_, The thread of DataReader describes the operation of DataReaderWorkerGroup_ buffers_.
void create_drwg_norm(std::string file_name, Check_t check_type,
bool start_reading_from_beginning = true) override {
source_type_ = SourceType_t::FileList;
worker_group_.reset(new DataReaderWorkerGroupNorm<TypeKey>(
thread_buffers_, resource_manager_, file_name, repeat_, check_type, params_,
start_reading_from_beginning));
file_name_ = file_name;
}
4.2 DataReaderWorkerGroup definition
We only look at its member variables, mainly idataareaderworker, which is the specific data reader.
class DataReaderWorkerGroup {
std::vector<std::thread> data_reader_threads_; /**< A vector of the pointers of data reader .*/
protected:
int data_reader_loop_flag_{0}; /**< p_loop_flag a flag to control the loop */
DataReaderType_t data_reader_type_;
std::vector<std::shared_ptr<IDataReaderWorker>>
data_readers_; /**< A vector of DataReaderWorker' pointer.*/
std::shared_ptr<ResourceManager> resource_manager_;
}
4.3 DataReaderWorkerGroupNorm
We use DataReaderWorkerGroupNorm to analyze. The most important thing is to set which GPU resources each DataReaderWorker corresponds to when building a DataReaderWorker.
template <typename TypeKey>
class DataReaderWorkerGroupNorm : public DataReaderWorkerGroup {
std::string file_list_; /**< file list of data set */
std::shared_ptr<Source> create_source(size_t worker_id, size_t num_worker,
const std::string &file_name, bool repeat) override {
return std::make_shared<FileSource>(worker_id, num_worker, file_name, repeat);
}
public:
// Ctor
DataReaderWorkerGroupNorm(const std::vector<std::shared_ptr<ThreadBuffer>> &output_buffers,
const std::shared_ptr<ResourceManager> &resource_manager_,
std::string file_list, bool repeat, Check_t check_type,
const std::vector<DataReaderSparseParam> ¶ms,
bool start_reading_from_beginning = true)
: DataReaderWorkerGroup(start_reading_from_beginning, DataReaderType_t::Norm) {
int num_threads = output_buffers.size();
size_t local_gpu_count = resource_manager_->get_local_gpu_count();
// create data reader workers
int max_feature_num_per_sample = 0;
for (auto ¶m : params) {
max_feature_num_per_sample += param.max_feature_num;
}
set_resource_manager(resource_manager_);
for (int i = 0; i < num_threads; i++) {
std::shared_ptr<IDataReaderWorker> data_reader(new DataReaderWorker<TypeKey>(
// GPU resources corresponding to each DataReaderWorker are set here
i, num_threads, resource_manager_->get_local_gpu(i % local_gpu_count),
&data_reader_loop_flag_, output_buffers[i], file_list, max_feature_num_per_sample, repeat,
check_type, params));
data_readers_.push_back(data_reader);
}
create_data_reader_threads(); // Multiple worker threads are established
}
};
4.4 establishing threads
create_data_reader_threads establishes multiple working threads and sets the GPU resources corresponding to each thread.
/**
* Create threads to run data reader workers
*/
void create_data_reader_threads() {
size_t local_gpu_count = resource_manager_->get_local_gpu_count();
for (size_t i = 0; i < data_readers_.size(); ++i) {
// GPU resources corresponding to each thread are set here
auto local_gpu = resource_manager_->get_local_gpu(i % local_gpu_count);
// Thread body function specified
data_reader_threads_.emplace_back(data_reader_thread_func_, data_readers_[i],
&data_reader_loop_flag_, local_gpu->get_device_id());
}
}
4.5 thread body function
data_reader_thread_func_ It is the main function of the worker thread, which sets the device of this thread, and then calls IDataReaderWorker to complete the reading data.
/**
* A helper function to read data from dataset to heap in a new thread.
* @param data_reader a pointer of data_reader.
* @param p_loop_flag a flag to control the loop,
and break loop when IDataReaderWorker is destroyed.
*/
static void data_reader_thread_func_(const std::shared_ptr<IDataReaderWorker>& data_reader,
int* p_loop_flag, int device_id) {
try {
CudaCPUDeviceContext context(device_id); // Set the device of this thread
while ((*p_loop_flag) == 0) {
usleep(2);
}
while (*p_loop_flag) {
data_reader->read_a_batch(); // Then start reading file data
}
} catch (const std::runtime_error& rt_err) {
std::cerr << rt_err.what() << std::endl;
}
}
Therefore, here we set which sample should be placed on which card. For example, the following four threads correspond to GPU 0 and GPU 1 respectively.
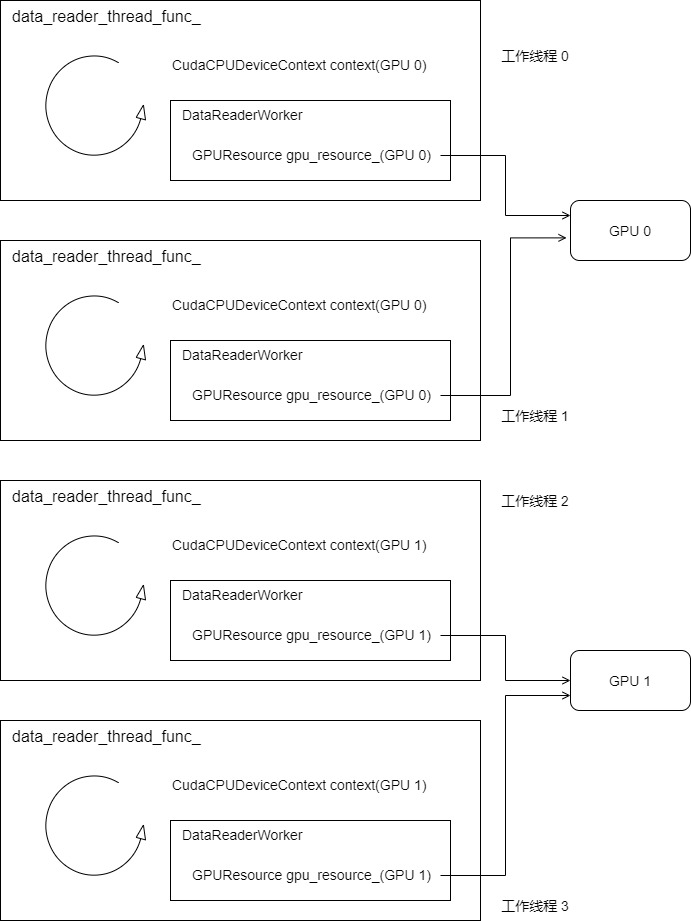
4.6 DataReaderWorker
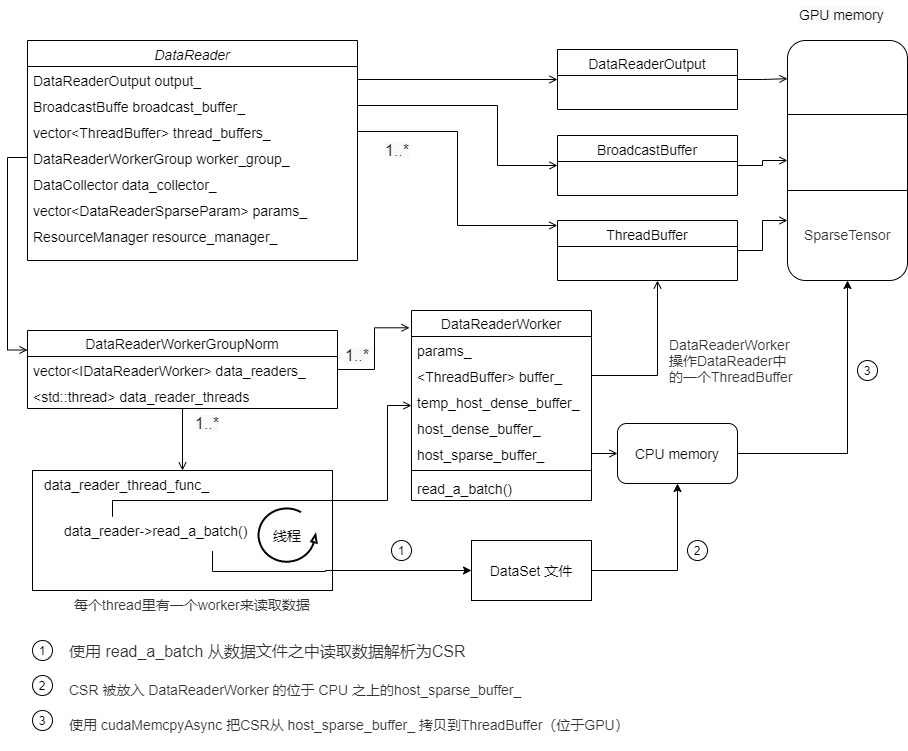
Datareader worker is a business module that parses data. IDataReaderWorker is the base class and its buffer_ Is the key, which points to ThreadBuffer.
class IDataReaderWorker {
std::shared_ptr<Source> source_; /**< source: can be file or network */
int worker_id_;
int worker_num_;
std::shared_ptr<GPUResource> gpu_resource_; // This is the GPU resource of this worker
bool is_eof_;
int *loop_flag_;
std::shared_ptr<ThreadBuffer> buffer_;
IDataReaderWorker(const int worker_id, const int worker_num,
const std::shared_ptr<GPUResource> &gpu_resource, bool is_eof, int *loop_flag,
const std::shared_ptr<ThreadBuffer> &buff)
: worker_id_(worker_id),
worker_num_(worker_num),
gpu_resource_(gpu_resource), // Set GPU resources
is_eof_(is_eof),
loop_flag_(loop_flag),
buffer_(buff) {}
};
DataReaderWorker is defined as follows:
template <class T>
class DataReaderWorker : public IDataReaderWorker {
private:
DataSetHeader
data_set_header_; /**< the header of data set, which has main informations of a data file */
size_t buffer_length_; /**< buffer size for internal use */
Check_t check_type_; /**< check type for data set */
std::vector<DataReaderSparseParam> params_; /**< configuration of data reader sparse input */
std::shared_ptr<Checker> checker_; /**< checker aim to perform error check of the input data */
bool skip_read_{false}; /**< set to true when you want to stop the data reading */
int current_record_index_{0};
size_t total_slot_num_;
std::vector<size_t> last_batch_nnz_;
Tensor2<float> temp_host_dense_buffer_; // read data to make checker move
Tensor2<float> host_dense_buffer_;
std::vector<CSR<T>> host_sparse_buffer_;
}
The construction code is as follows, which should be noted,
- There is a variable STD:: shared inherited from the base class_ ptr buffer_ It points to ThreadBuffer.
- Variable host_sparse_buffer_ It is built on the Host, not on the GPU. This host_sparse_buffer_ The function is to read data from the file, parse it into csr and place it in the host_sparse_buffer_ above.
- About the description of the variable DataReaderSparseParam, this is a DataReaderSparseParam array. If the following settings are made, params will be set_ It contains three elements, namely user, good and cat.
model.add(hugectr.Input(label_dim = 1, label_name = "label",
dense_dim = 0, dense_name = "dense",
data_reader_sparse_param_array =
[hugectr.DataReaderSparseParam("UserID", 1, True, 1),
hugectr.DataReaderSparseParam("GoodID", 1, True, 11),
hugectr.DataReaderSparseParam("CateID", 1, True, 11)]))
DataReaderWorker is defined as follows:
DataReaderWorker(const int worker_id, const int worker_num,
const std::shared_ptr<GPUResource>& gpu_resource, int* loop_flag,
const std::shared_ptr<ThreadBuffer>& buffer, const std::string& file_list,
size_t buffer_length, bool repeat, Check_t check_type,
const std::vector<DataReaderSparseParam>& params)
: IDataReaderWorker(worker_id, worker_num, gpu_resource, !repeat, loop_flag, buffer),
buffer_length_(buffer_length),
check_type_(check_type),
params_(params),
total_slot_num_(0),
last_batch_nnz_(params.size(), 0) {
total_slot_num_ = 0;
for (auto& p : params) {
total_slot_num_ += p.slot_num;
}
source_ = std::make_shared<FileSource>(worker_id, worker_num, file_list, repeat);
create_checker();
int batch_size = buffer->batch_size;
int batch_size_start_idx = buffer->batch_size_start_idx;
int batch_size_end_idx = buffer->batch_size_end_idx;
int label_dim = buffer->label_dim;
int dense_dim = buffer->dense_dim;
CudaCPUDeviceContext ctx(gpu_resource->get_device_id()); // Which GPU does the worker correspond to
std::shared_ptr<GeneralBuffer2<CudaHostAllocator>> buff =
GeneralBuffer2<CudaHostAllocator>::create();
buff->reserve({static_cast<size_t>(batch_size_end_idx - batch_size_start_idx),
static_cast<size_t>(label_dim + dense_dim)},
&host_dense_buffer_);
buff->reserve({static_cast<size_t>(label_dim + dense_dim)}, &temp_host_dense_buffer_);
for (auto& param : params) {
host_sparse_buffer_.emplace_back(batch_size * param.slot_num,
batch_size * param.max_feature_num);
}
buff->allocate();
}
The specific expansion is as follows. Each thread contains a worker:
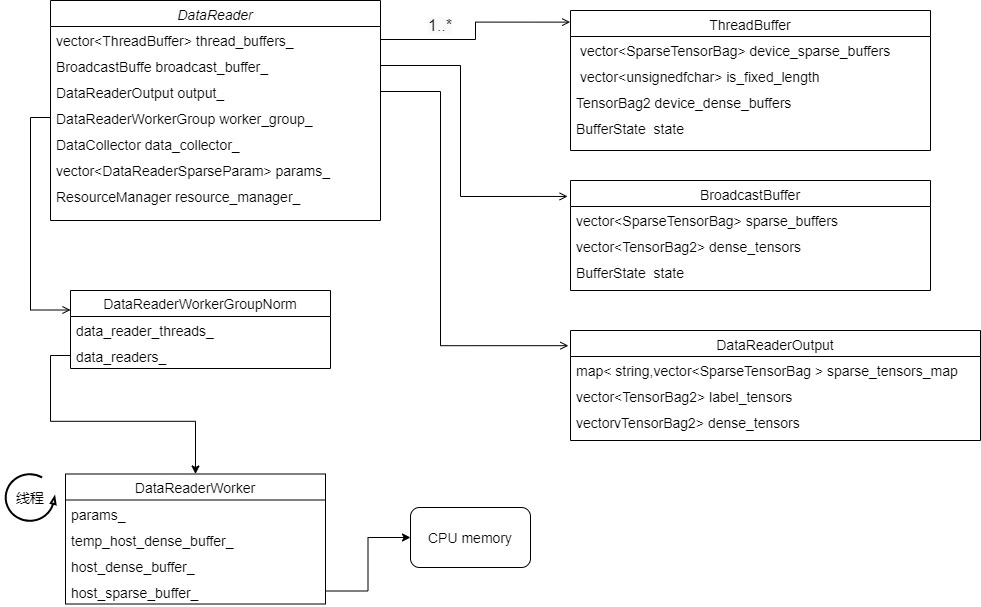
Or we can further simplify several memory classes and get the following: DataReaderWorker operates a ThreadBuffer in DataReader,
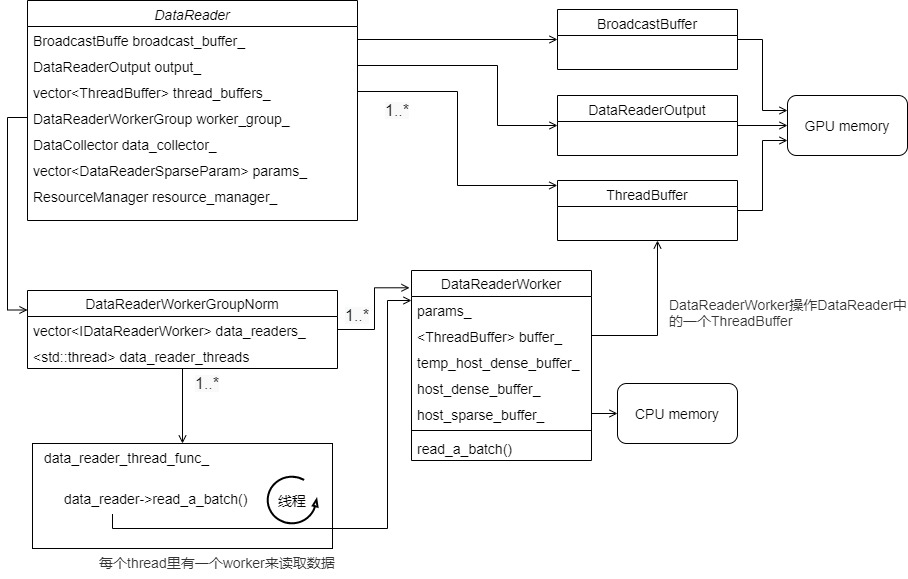
4.7 reading data
When the Reader is built, a checker will be created, Used to read data from a file.
4.7.1 Checker
void create_checker() {
switch (check_type_) {
case Check_t::Sum:
checker_ = std::make_shared<CheckSum>(*source_);
break;
case Check_t::None:
checker_ = std::make_shared<CheckNone>(*source_);
break;
default:
assert(!"Error: no such Check_t && should never get here!!");
}
}
Taking CheckNone as an example, you can see that it is reading files.
class CheckNone : public Checker {
private:
const int MAX_TRY{10};
public:
CheckNone(Source& src) : Checker(src) {}
/**
* Read "bytes_to_read" byte to the memory associated to ptr.
* Users don't need to manualy maintain the check bit offset, just specify
* number of bytes you really want to see in ptr.
* @param ptr pointer to user located buffer
* @param bytes_to_read bytes to read
* @return `DataCheckError` `OutOfBound` `Success` `UnspecificError`
*/
Error_t read(char* ptr, size_t bytes_to_read) noexcept {
try {
Checker::src_.read(ptr, bytes_to_read);
return Error_t::Success;
} catch (const std::runtime_error& rt_err) {
std::cerr << rt_err.what() << std::endl;
return Error_t::BrokenFile;
}
}
/**
* Start a new file to read.
* @return `FileCannotOpen` or `UnspecificError`
*/
Error_t next_source() {
for (int i = MAX_TRY; i > 0; i--) {
Error_t flag_eof = Checker::src_.next_source();
if (flag_eof == Error_t::Success || flag_eof == Error_t::EndOfFile) {
return flag_eof;
}
}
CK_THROW_(Error_t::FileCannotOpen, "Checker::src_.next_source() == Error_t::Success failed");
return Error_t::FileCannotOpen; // to elimate compile error
}
};
4.7.2 CSR example
From samples / NCF / preprocess-1m Py to see the format of the csr file.
def write_hugeCTR_data(huge_ctr_data, filename='huge_ctr_data.dat'):
with open(filename, 'wb') as f:
#write header
f.write(ll(0)) # 0: no error check; 1: check_num
f.write(ll(huge_ctr_data.shape[0])) # the number of samples in this data file
f.write(ll(1)) # dimension of label
f.write(ll(1)) # dimension of dense feature
f.write(ll(2)) # long long slot_num
for _ in range(3): f.write(ll(0)) # reserved for future use
for i in tqdm.tqdm(range(huge_ctr_data.shape[0])):
f.write(c_float(huge_ctr_data[i,2])) # float label[label_dim];
f.write(c_float(0)) # dummy dense feature
f.write(c_int(1)) # slot 1 nnz: user ID
f.write(c_uint(huge_ctr_data[i,0]))
f.write(c_int(1)) # slot 2 nnz: item ID
f.write(c_uint(huge_ctr_data[i,1]))
4.7.3 reading batch data
read_ a_ The specific work of batch data set analysis is completed.
- First read the data from the file.
- Wait for the state of ThreadBuffer (that is, the thread_buffers_member variable of DataReader) to become ReadyForWrite.
- Parse it into csr and put it into host_dense_buffer_.
- Call wait_until_h2d_ready waits for the copy to complete.
- Secondly, cudaMemcpyAsync is called to transfer the data from the host_dense_buffer_ Copy to ThreadBuffer. Here are two important points:
- The current data is in host_sparse_buffer_ (CPU), it needs to be copied to GPU (the target is the device_spark_buffers member variable of ThreadBuffer).
- And, host_sparse_buffer_ It is in CSR format and the device of ThreadBuffer_ sparse_ The buffers member variable is in SparseTensor format and needs to be converted.
- Here is the conversion through copy.
There are several points as follows:
- nnz means: non zero feature number.
- Each slot data corresponds to a CSR row.
The specific codes are as follows:
/**
* read a batch of data from data set to heap.
*/
void read_a_batch() {
// Get various configurations
long long current_batch_size = buffer_->batch_size;
int label_dim = buffer_->label_dim;
int dense_dim = buffer_->dense_dim;
int label_dense_dim = label_dim + dense_dim;
int batch_size_start_idx = buffer_->batch_size_start_idx;
int batch_size_end_idx = buffer_->batch_size_end_idx;
try {
if (!checker_->is_open()) {
read_new_file(); // Read a new file
}
} catch (const internal_runtime_error& rt_err) {
Error_t err = rt_err.get_error();
if (err == Error_t::EndOfFile) { // Have you finished reading the document
if (!wait_until_h2d_ready()) return; // Wait for buffer_ The status changes to ReadyForWrite
buffer_->current_batch_size = 0;
assert(buffer_->state.load() == BufferState::Writing); // set up
is_eof_ = true;
buffer_->state.store(BufferState::ReadyForRead); // Set status to readable
while (buffer_->state.load() != BufferState::ReadyForWrite) {
usleep(2);
if (*loop_flag_ == 0) return; // in case main thread exit
}
return; // need this return to run from begining
} else {
throw;
}
}
// if the EOF is faced, the current batch size can be changed later
for (auto& each_csr : host_sparse_buffer_) {
each_csr.reset();
}
// batch loop
for (int batch_idx = 0; batch_idx < buffer_->batch_size; ++batch_idx) {//Read a batch
if (batch_idx >= current_batch_size) { // If you have read all the data in batch
for (size_t param_id = 0; param_id < params_.size(); ++param_id) { // Multiple embedding
// If it is the previous example, the traversal here is user, good and cat
auto& param = params_[param_id];
// host_sparse_buffer_ The type is STD:: vector < CSR < T > >
auto& current_csr = host_sparse_buffer_[param_id];
for (int k = 0; k < param.slot_num; k++) { // The number of slot s is the number of rows
current_csr.new_row(); // Add a line
}
}
if (batch_idx >= batch_size_start_idx &&
batch_idx < batch_size_end_idx) { // only read local device dense data
// Set deny
float* ptr =
host_dense_buffer_.get_ptr() + (batch_idx - batch_size_start_idx) * label_dense_dim;
for (int j = 0; j < label_dense_dim; j++) {
ptr[j] = 0.f;
}
}
continue;
}
try {
try {
if (batch_idx >= batch_size_start_idx &&
batch_idx < batch_size_end_idx) { // only read local device dense data
// Read the deny parameter
CK_THROW_(checker_->read(reinterpret_cast<char*>(host_dense_buffer_.get_ptr() +
(batch_idx - batch_size_start_idx) *
label_dense_dim),
sizeof(float) * label_dense_dim),
"failure in reading label_dense");
} else {
// Read the deny parameter
CK_THROW_(checker_->read(reinterpret_cast<char*>(temp_host_dense_buffer_.get_ptr()),
sizeof(float) * label_dense_dim),
"failure in reading label_dense");
}
for (size_t param_id = 0; param_id < params_.size(); ++param_id) {
auto& current_csr = host_sparse_buffer_[param_id];
current_csr.set_check_point();
}
// Read spark parameter
for (size_t param_id = 0; param_id < params_.size(); ++param_id) {
auto& param = params_[param_id];
auto& current_csr = host_sparse_buffer_[param_id];
for (int k = 0; k < param.slot_num; k++) {
int nnz; // Read an int to nnz to get the size of nnz, non zero feature number
CK_THROW_(checker_->read(reinterpret_cast<char*>(&nnz), sizeof(int)),
"failure in reading nnz");
current_csr.new_row(); // Line feed
size_t num_value = current_csr.get_num_values();
// Read nnz data
CK_THROW_(checker_->read(reinterpret_cast<char*>(
current_csr.get_value_tensor().get_ptr() + num_value),
sizeof(T) * nnz),
"failure in reading feature_ids_");
current_csr.update_value_size(nnz);
}
}
} catch (const internal_runtime_error& rt_err) { // Back off
batch_idx--; // restart i-th sample
for (auto& each_csr : host_sparse_buffer_) {
each_csr.roll_back();
}
Error_t err = rt_err.get_error();
if (err == Error_t::DataCheckError) {
ERROR_MESSAGE_("Error_t::DataCheckError");
} else { // Error_t::BrokenFile, Error_t::UnspecificEror, ...
read_new_file(); // can throw Error_t::EOF
}
}
current_record_index_++;
// start a new file when finish one file read
if (current_record_index_ >= data_set_header_.number_of_records) {
read_new_file(); // can throw Error_t::EOF
}
} catch (const internal_runtime_error& rt_err) {
Error_t err = rt_err.get_error();
if (err == Error_t::EndOfFile) {
current_batch_size = batch_idx + 1;
} else {
throw;
}
}
}
for (auto& each_csr : host_sparse_buffer_) {
each_csr.new_row();
}
// do h2d
// wait buffer and schedule
// The current data is in host_sparse_buffer_ (CPU), you need to copy it to GPU (the target is the device_spark_buffers member variable of ThreadBuffer), and use cudaMemcpyHostToDevice
// And, host_sparse_buffer_ It is in CSR < T > format and the device of ThreadBuffer_ sparse_ The buffers member variable is in sparsetensor < T > format and needs to be converted
if (!wait_until_h2d_ready()) return;
buffer_->current_batch_size = current_batch_size;
{
CudaCPUDeviceContext context(gpu_resource_->get_device_id());
// The target is the device of ThreadBuffer_ sparse_ Buffers member variable
auto dst_dense_tensor = Tensor2<float>::stretch_from(buffer_->device_dense_buffers);
CK_CUDA_THROW_(cudaMemcpyAsync(dst_dense_tensor.get_ptr(), host_dense_buffer_.get_ptr(),
host_dense_buffer_.get_size_in_bytes(), cudaMemcpyHostToDevice,
gpu_resource_->get_memcpy_stream()));
for (size_t param_id = 0; param_id < params_.size(); ++param_id) { // Traverse the embedded layer
auto dst_sparse_tensor =
SparseTensor<T>::stretch_from(buffer_->device_sparse_buffers[param_id]);
if (buffer_->is_fixed_length[param_id] &&
last_batch_nnz_[param_id] == host_sparse_buffer_[param_id].get_num_values()) {
// It is copied to GPU and converted at the same time. The member variables of CSR are extracted and copied to the corresponding address of SparseTensor
CK_CUDA_THROW_(cudaMemcpyAsync(dst_sparse_tensor.get_value_ptr(),
host_sparse_buffer_[param_id].get_value_tensor().get_ptr(),
host_sparse_buffer_[param_id].get_num_values() * sizeof(T),
cudaMemcpyHostToDevice,
gpu_resource_->get_memcpy_stream()));
} else {
// Copy to GPU
sparse_tensor_helper::cuda::copy_async(dst_sparse_tensor, host_sparse_buffer_[param_id],
gpu_resource_->get_memcpy_stream());
last_batch_nnz_[param_id] = host_sparse_buffer_[param_id].get_num_values();
}
}
// Synchronize
CK_CUDA_THROW_(cudaStreamSynchronize(gpu_resource_->get_memcpy_stream()));
}
assert(buffer_->state.load() == BufferState::Writing);
buffer_->state.store(BufferState::ReadyForRead);
}
};
4.7.3.1 waiting
Wait here_ until_ h2d_ Ready will wait.
bool wait_until_h2d_ready() {
BufferState expected = BufferState::ReadyForWrite;
while (!buffer_->state.compare_exchange_weak(expected, BufferState::Writing)) {
expected = BufferState::ReadyForWrite;
usleep(2);
if (*loop_flag_ == 0) return false; // in case main thread exit
}
return true;
}
4.7.3.2 reading files
read_new_file finished reading the file.
void read_new_file() {
constexpr int MAX_TRY = 10;
for (int i = 0; i < MAX_TRY; i++) {
if (checker_->next_source() == Error_t::EndOfFile) {
throw internal_runtime_error(Error_t::EndOfFile, "EndOfFile");
}
Error_t err =
checker_->read(reinterpret_cast<char*>(&data_set_header_), sizeof(DataSetHeader));
current_record_index_ = 0;
if (!(data_set_header_.error_check == 0 && check_type_ == Check_t::None) &&
!(data_set_header_.error_check == 1 && check_type_ == Check_t::Sum)) {
ERROR_MESSAGE_("DataHeaderError");
continue;
}
if (static_cast<size_t>(data_set_header_.slot_num) != total_slot_num_) {
ERROR_MESSAGE_("DataHeaderError");
continue;
}
if (err == Error_t::Success) {
return;
}
}
CK_THROW_(Error_t::BrokenFile, "failed to read a file");
}
4.7.4 summary
We summarize the logic as follows: the thread always calls data_reader_thread_func_ To read circularly:
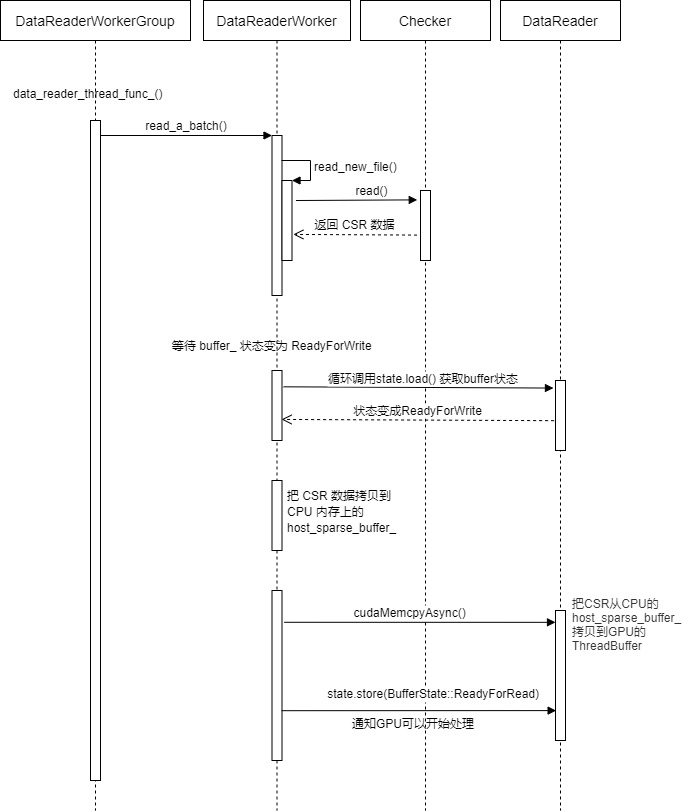
Another logical perspective is:
- Multi thread calling data_reader_thread_func_, It uses read_a_batch reads data from the data file and parses it into CSR. Each embedding layer corresponds to a CSR.
- CSR is put into the host of DataReaderWorker_ sparse_ buffer_.
- As batch continues to read, the number of CSR rows is increasing. Each slot corresponds to one row, so the number of rows of a batch is batch_size * slot_num.
- Use cudaMemcpyAsync to remove CSR from host_sparse_buffer_ Copy to ThreadBuffer (located on GPU). ThreadBuffer is of SparseTensor type.
- At present, CSR data is on top of GPU.
This simplifies the case of multiple GPU s and multiple worker s.
0x05 reading embedding
Let's take a look at the data collector, which is the second stage of the pipeline, and the yellow box "Copy to GPU" here. In fact, the internal text is modified to Copy To Embedding.
[the external chain image transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the image and upload it directly (img-fblibage-1645370206379)( https://developer.nvidia.com/blog/wp-content/uploads/2020/07/hugectr-training-pipeline-with-data-reader-625x220.png )]
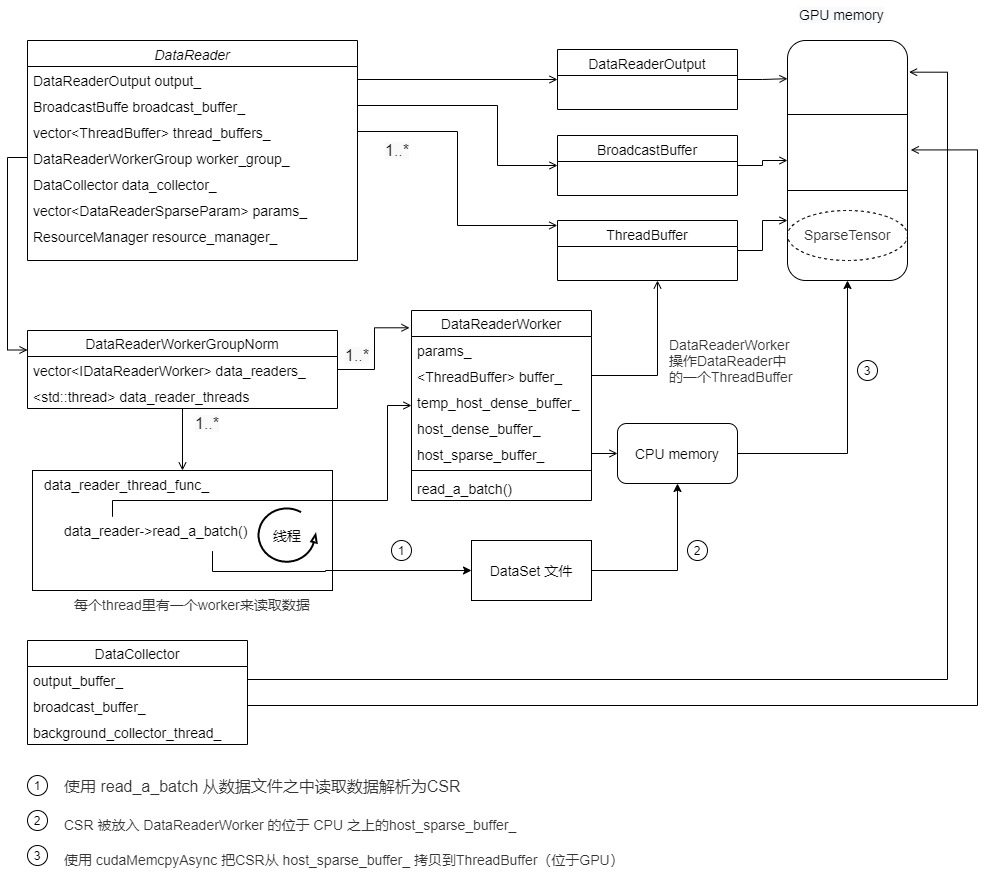
5.1 DataCollector
Let's first look at the definition of DataCollector. The member function is omitted here, and the main member variable is.
- std::shared_ ptr broadcast_ buffer_ : The CPU data is copied to the GPU, which is right here.
- std::shared_ptr output_buffer_ : This is DataReaderOutput, which is the member variable of Reader. It is copied here for the convenience of collector operation.
- BackgroundDataCollectorThread background_collector_ : Thread bodies, mainly including ThreadBuffer and BroadcastBuffer, copy data from ThreadBuffer to BroadcastBuffer.
- std::thread background_collector_thread_ : Worker thread.
/**
* @brief A helper class of data reader.
*
* This class implement asynchronized data collecting from heap
* to output of data reader, thus data collection and training
* can work in a pipeline.
*/
template <typename T>
class DataCollector {
class BackgroundDataCollectorThread {
std::vector<std::shared_ptr<ThreadBuffer>> thread_buffers_;
std::shared_ptr<BroadcastBuffer> broadcast_buffer_;
std::atomic<bool> loop_flag_;
int counter_;
std::vector<size_t> last_batch_nnz_; // local_gpu_count * embedding number
std::vector<char> worker_status_;
int eof_worker_num_;
std::shared_ptr<ResourceManager> resource_manager_;
}
std::shared_ptr<BroadcastBuffer> broadcast_buffer_;
std::shared_ptr<DataReaderOutput> output_buffer_;
BackgroundDataCollectorThread background_collector_;
std::thread background_collector_thread_;
std::atomic<bool> loop_flag_;
std::vector<size_t> last_batch_nnz_;
std::shared_ptr<ResourceManager> resource_manager_;
};
At present, the details are as follows: broadcast in Collector_ buffer_ And output_buffer_ All point to the GPU, but there is no data in the GPU:
5.2 ThreadBuffer 2 BroadBuffer
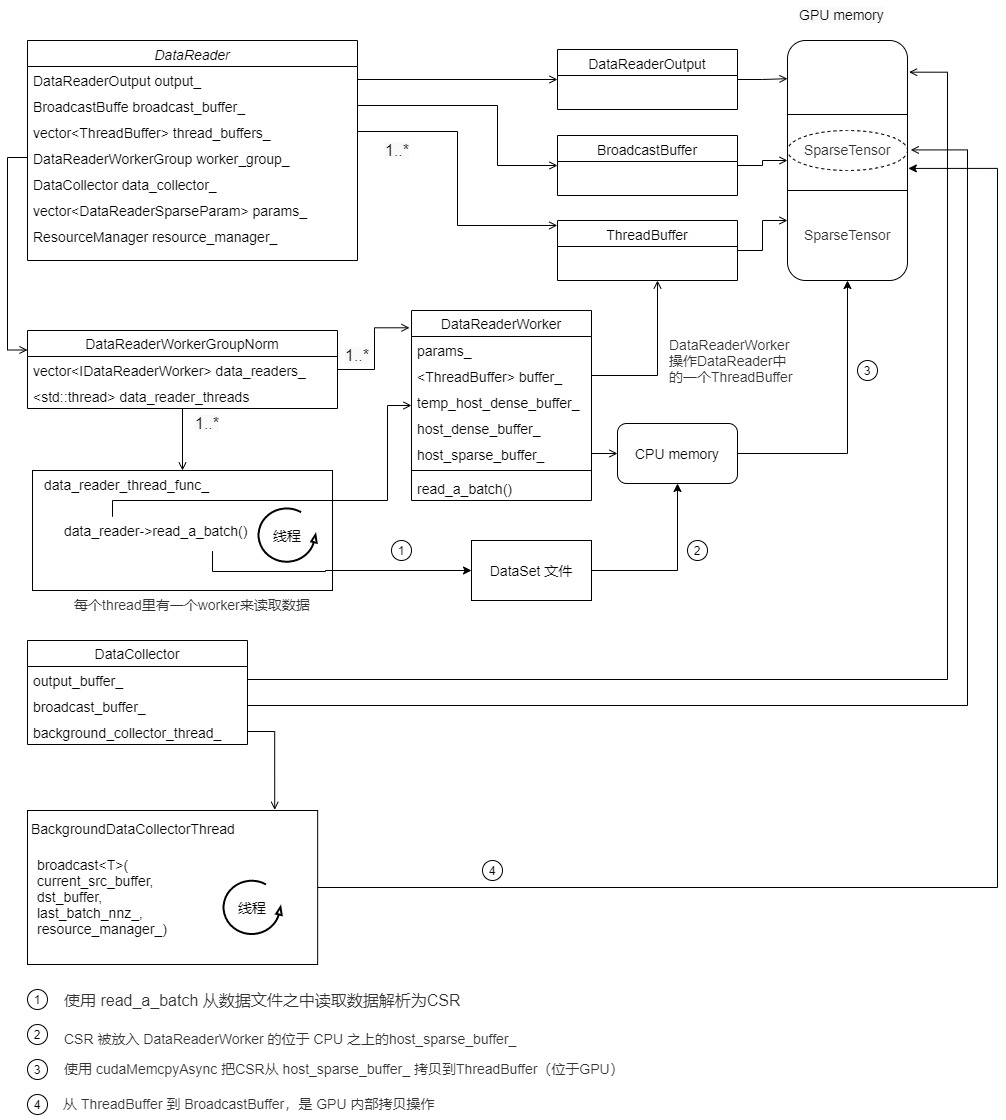
5.2.1 working thread
The function of BackgroundDataCollectorThread is to extract data from the thread of DataReader_ buffers_ Copy to broadcast_buffer_.
class BackgroundDataCollectorThread {
std::vector<std::shared_ptr<ThreadBuffer>> thread_buffers_;
std::shared_ptr<BroadcastBuffer> broadcast_buffer_;
std::atomic<bool> loop_flag_;
int counter_;
std::vector<size_t> last_batch_nnz_; // local_gpu_count * embedding number
std::vector<char> worker_status_;
int eof_worker_num_;
std::shared_ptr<ResourceManager> resource_manager_;
public:
BackgroundDataCollectorThread(const std::vector<std::shared_ptr<ThreadBuffer>> &thread_buffers,
const std::shared_ptr<BroadcastBuffer> &broadcast_buffer,
const std::shared_ptr<ResourceManager> &resource_manager)
: thread_buffers_(thread_buffers),
broadcast_buffer_(broadcast_buffer),
loop_flag_{true},
counter_{0},
last_batch_nnz_(
broadcast_buffer->is_fixed_length.size() * resource_manager->get_local_gpu_count(),
0),
worker_status_(thread_buffers.size(), 0),
eof_worker_num_(0),
resource_manager_(resource_manager) {}
void start() {
while (loop_flag_.load()) {
// threadbuffer is the source data and broadcast buffer is the target data
auto ¤t_src_buffer = thread_buffers_[counter_];
auto &dst_buffer = broadcast_buffer_;
auto src_expected = BufferState::ReadyForRead; // The expected source data is in this state
auto dst_expected = BufferState::ReadyForWrite; // The expected target data is in this state
if (worker_status_[counter_]) {
counter_ = (counter_ + 1) % thread_buffers_.size();
continue;
}
if ((current_src_buffer->state.load() == BufferState::Reading ||
current_src_buffer->state.compare_exchange_weak(src_expected, BufferState::Reading)) &&
(dst_buffer->state.load() == BufferState::Writing ||
dst_buffer->state.compare_exchange_weak(dst_expected, BufferState::Writing))) {
// If the source data is readable or being read, and the target data is writable or being written, it can be operated
if (current_src_buffer->current_batch_size == 0) {
worker_status_[counter_] = 1;
eof_worker_num_ += 1;
current_src_buffer->state.store(BufferState::FileEOF);
}
if (static_cast<size_t>(eof_worker_num_) != thread_buffers_.size() &&
current_src_buffer->current_batch_size == 0) {
counter_ = (counter_ + 1) % thread_buffers_.size();
dst_buffer->state.store(BufferState::ReadyForWrite); // Set the status of target data
continue;
}
dst_buffer->current_batch_size = current_src_buffer->current_batch_size;
if (current_src_buffer->current_batch_size != 0) {
// Broadcast operation
broadcast<T>(current_src_buffer, dst_buffer, last_batch_nnz_, resource_manager_);
current_src_buffer->state.store(BufferState::ReadyForWrite); // Set the status of target data
counter_ = (counter_ + 1) % thread_buffers_.size();
} else {
memset(worker_status_.data(), 0, sizeof(char) * worker_status_.size());
eof_worker_num_ = 0;
counter_ = 0;
}
dst_buffer->state.store(BufferState::ReadyForRead); // It will notify the source data that it can be read again
} else {
usleep(2); // Otherwise, wait for a while
}
}
}
void stop() { loop_flag_.store(false); }
};
5.2.2 copy operation
Here is to copy the source data to the target data, and copy the parameters one by one. This is a copy within the device.
template <typename T>
void broadcast(const std::shared_ptr<ThreadBuffer>& thread_buffer,
std::shared_ptr<BroadcastBuffer>& broadcast_buffer,
std::vector<size_t>& last_batch_nnz_,
const std::shared_ptr<ResourceManager>& resource_manager) {
int param_num = thread_buffer->param_num;
int dense_dim = thread_buffer->dense_dim;
int label_dim = thread_buffer->label_dim;
int batch_size = thread_buffer->batch_size;
int batch_size_per_gpu = batch_size / resource_manager->get_global_gpu_count();
int local_gpu_count = resource_manager->get_local_gpu_count();
#pragma omp parallel for num_threads(local_gpu_count)
for (int i = 0; i < local_gpu_count; ++i) { // Traverse the local GPU
auto local_gpu = resource_manager->get_local_gpu(i);
CudaDeviceContext ctx(local_gpu->get_device_id());
for (int param_id = 0; param_id < param_num; ++param_id) { // Traverse the embedded layer
// From thread_ Copy buffer to broadcast_buffer
auto src_sparse_tensor =
SparseTensor<T>::stretch_from(thread_buffer->device_sparse_buffers[param_id]);
auto dst_sparse_tensor =
SparseTensor<T>::stretch_from(broadcast_buffer->sparse_buffers[i * param_num + param_id]);
// Copy spark parameter
if (thread_buffer->is_fixed_length[param_id] &&
last_batch_nnz_[i * param_num + param_id] == src_sparse_tensor.nnz()) {
CK_CUDA_THROW_(cudaMemcpyAsync(dst_sparse_tensor.get_value_ptr(),
src_sparse_tensor.get_value_ptr(),
src_sparse_tensor.nnz() * sizeof(T),
cudaMemcpyDeviceToDevice, local_gpu->get_p2p_stream()));
} else {
sparse_tensor_helper::cuda::copy_async(dst_sparse_tensor, src_sparse_tensor,
cudaMemcpyDeviceToDevice,
local_gpu->get_p2p_stream());
last_batch_nnz_[i * param_num + param_id] = src_sparse_tensor.nnz();
}
}
// Copy deny parameter
auto dst_dense_tensor = Tensor2<float>::stretch_from(broadcast_buffer->dense_tensors[i]);
auto src_dense_tensor = Tensor2<float>::stretch_from(thread_buffer->device_dense_buffers);
CK_CUDA_THROW_(cudaMemcpyAsync(
dst_dense_tensor.get_ptr(),
src_dense_tensor.get_ptr() + i * batch_size_per_gpu * (label_dim + dense_dim),
batch_size_per_gpu * (label_dim + dense_dim) * sizeof(float), cudaMemcpyDeviceToDevice,
local_gpu->get_p2p_stream()));
// synchronization
CK_CUDA_THROW_(cudaStreamSynchronize(local_gpu->get_p2p_stream()));
}
}
The logic is as follows. There is one more step from ThreadBuffer to BroadcastBuffer.
5.3 read output
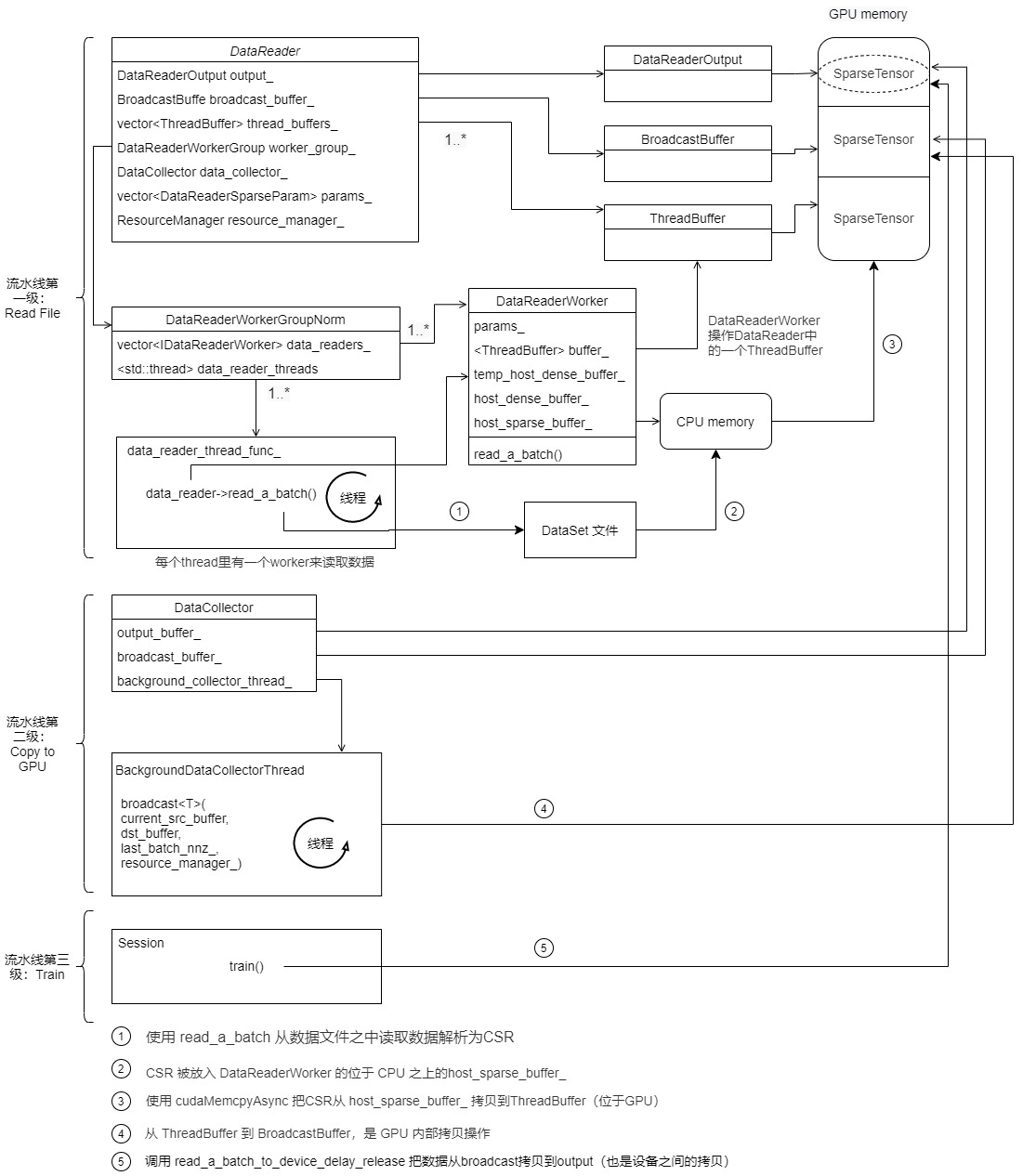
The current process is: DataFile - > host buffer - > threadbuffer - > broadcastbuffer.
Now that the data has been copied to the BroadcastBuffer on the GPU, we need to see how to get the data during the final training.
5.3.1 Train
We first return to the train function, which calls read_a_batch_to_device_delay_release to copy data from the BroadcastBuffer.
bool Session::train() {
try {
// Ensure train_data_reader_ Already started
if (train_data_reader_->is_started() == false) {
CK_THROW_(Error_t::IllegalCall,
"Start the data reader first before calling Session::train()");
}
#ifndef DATA_READING_TEST
// The reader needs to read the data of a batch size first.
long long current_batchsize = train_data_reader_->read_a_batch_to_device_delay_release(); // Read data
if (!current_batchsize) {
return false; // Quit if you can't read it. There's no data
}
#pragma omp parallel num_threads(networks_.size()) / / subsequent statements will be deleted by networks_ Size () threads execute in parallel
{
size_t id = omp_get_thread_num();
CudaCPUDeviceContext ctx(resource_manager_->get_local_gpu(id)->get_device_id());
cudaStreamSynchronize(resource_manager_->get_local_gpu(id)->get_stream());
}
// The reader can start parsing the data
train_data_reader_->ready_to_collect();
#ifdef ENABLE_PROFILING
global_profiler.iter_check();
#endif
// If true we're gonna use overlaping, if false we use default
if (solver_config_.use_overlapped_pipeline) {
train_overlapped();
} else {
for (const auto& one_embedding : embeddings_) {
one_embedding->forward(true); // The embedded layer performs forward propagation, that is, reading embedding from the parameter server for processing
}
// Network forward / backward
if (networks_.size() > 1) {
// Single machine multi card or multi machine multi card
// execute dense forward and backward with multi-cpu threads
#pragma omp parallel num_threads(networks_.size())
{
// Forward and reverse of dense network
size_t id = omp_get_thread_num();
long long current_batchsize_per_device =
train_data_reader_->get_current_batchsize_per_device(id);
networks_[id]->train(current_batchsize_per_device); // Forward operation
const auto& local_gpu = resource_manager_->get_local_gpu(id);
local_gpu->set_compute_event_sync(local_gpu->get_stream());
local_gpu->wait_on_compute_event(local_gpu->get_comp_overlap_stream());
}
} else if (resource_manager_->get_global_gpu_count() > 1) {
// Multi machine single card
long long current_batchsize_per_device =
train_data_reader_->get_current_batchsize_per_device(0);
networks_[0]->train(current_batchsize_per_device); // Forward operation
const auto& local_gpu = resource_manager_->get_local_gpu(0);
local_gpu->set_compute_event_sync(local_gpu->get_stream());
local_gpu->wait_on_compute_event(local_gpu->get_comp_overlap_stream());
} else {
// Single card
long long current_batchsize_per_device =
train_data_reader_->get_current_batchsize_per_device(0);
networks_[0]->train(current_batchsize_per_device); // Forward operation
const auto& local_gpu = resource_manager_->get_local_gpu(0);
local_gpu->set_compute_event_sync(local_gpu->get_stream());
local_gpu->wait_on_compute_event(local_gpu->get_comp_overlap_stream());
networks_[0]->update_params();
}
// Embedding backward
for (const auto& one_embedding : embeddings_) {
one_embedding->backward(); // Reverse operation of embedded layer
}
// Exchange wgrad and update params
if (networks_.size() > 1) {
#pragma omp parallel num_threads(networks_.size())
{
size_t id = omp_get_thread_num();
exchange_wgrad(id); // Gradient of exchanging dense parameters between multi cards
networks_[id]->update_params();
}
} else if (resource_manager_->get_global_gpu_count() > 1) {
exchange_wgrad(0);
networks_[0]->update_params();
}
for (const auto& one_embedding : embeddings_) {
one_embedding->update_params(); // The embedded layer updates the spark parameter
}
// Join streams
if (networks_.size() > 1) {
#pragma omp parallel num_threads(networks_.size())
{
size_t id = omp_get_thread_num();
const auto& local_gpu = resource_manager_->get_local_gpu(id);
local_gpu->set_compute2_event_sync(local_gpu->get_comp_overlap_stream());
local_gpu->wait_on_compute2_event(local_gpu->get_stream());
}
}
else {
const auto& local_gpu = resource_manager_->get_local_gpu(0);
local_gpu->set_compute2_event_sync(local_gpu->get_comp_overlap_stream());
local_gpu->wait_on_compute2_event(local_gpu->get_stream());
}
return true;
}
#else
data_reader_->read_a_batch_to_device();
#endif
} catch (const internal_runtime_error& err) {
std::cerr << err.what() << std::endl;
throw err;
} catch (const std::exception& err) {
std::cerr << err.what() << std::endl;
throw err;
}
return true;
}
5.3.2 read_a_batch_to_device_delay_release
read_a_batch_to_device_delay_release is where the embedding data is finally configured.
long long read_a_batch_to_device_delay_release() override {
current_batchsize_ = data_collector_->read_a_batch_to_device();
return current_batchsize_;
}
Let's see read_a_batch_to_device. Here read_a_batch_to_device_delay_release and read_a_batch_to_device is named after the old version, which is inconsistent with the current situation.
The specific logic is: look at broadcast_buffer_ Can I read ReadyForRead? If not, wait a minute. If you can, continue, that is, traverse the GPU, copy from broadcast to output one by one (which is also a copy between devices), and split the label and deny.
long long read_a_batch_to_device() {
BufferState expected = BufferState::ReadyForRead;
while (!broadcast_buffer_->state.compare_exchange_weak(expected, BufferState::Reading)) {
expected = BufferState::ReadyForRead;
usleep(2);
}
long long current_batch_size = broadcast_buffer_->current_batch_size;
if (current_batch_size != 0) {
int local_gpu_count = resource_manager_->get_local_gpu_count();
#pragma omp parallel for num_threads(local_gpu_count)
for (int i = 0; i < local_gpu_count; ++i) {
auto local_gpu = resource_manager_->get_local_gpu(i);
CudaDeviceContext ctx(local_gpu->get_device_id());
// wait until last iteration finish
auto label_tensor = Tensor2<float>::stretch_from(output_buffer_->label_tensors[i]);
auto label_dense_tensor = Tensor2<float>::stretch_from(broadcast_buffer_->dense_tensors[i]);
// Traverse the spark parameter
for (size_t param_id = 0; param_id < output_buffer_->sparse_name_vec.size(); ++param_id) {
const auto &top_name = output_buffer_->sparse_name_vec[param_id];
int idx_broadcast = i * broadcast_buffer_->param_num + param_id;
// broadcast is the source
auto src_sparse_tensor =
SparseTensor<T>::stretch_from(broadcast_buffer_->sparse_buffers[idx_broadcast]);
if (output_buffer_->sparse_tensors_map.find(top_name) ==
output_buffer_->sparse_tensors_map.end()) {
CK_THROW_(Error_t::IllegalCall, "can not find sparse name");
}
// output is the target
auto dst_sparse_tensor =
SparseTensor<T>::stretch_from(output_buffer_->sparse_tensors_map[top_name][i]);
// Copy from broadcast to output
if (broadcast_buffer_->is_fixed_length[idx_broadcast] &&
last_batch_nnz_[idx_broadcast] == src_sparse_tensor.nnz()) {
CK_CUDA_THROW_(cudaMemcpyAsync(dst_sparse_tensor.get_value_ptr(),
src_sparse_tensor.get_value_ptr(),
src_sparse_tensor.nnz() * sizeof(T),
cudaMemcpyDeviceToDevice, local_gpu->get_stream()));
} else {
// Copy from broadcast to output
sparse_tensor_helper::cuda::copy_async(dst_sparse_tensor, src_sparse_tensor,
cudaMemcpyDeviceToDevice,
local_gpu->get_stream());
last_batch_nnz_[idx_broadcast] = src_sparse_tensor.nnz();
}
}
const int label_dense_dim = output_buffer_->label_dense_dim;
// Copy label and deny
if (output_buffer_->use_mixed_precision) {
auto dense_tensor = Tensor2<__half>::stretch_from(output_buffer_->dense_tensors[i]);
// Block
split(label_tensor, dense_tensor, label_dense_tensor, label_dense_dim,
local_gpu->get_stream());
} else {
auto dense_tensor = Tensor2<float>::stretch_from(output_buffer_->dense_tensors[i]);
split(label_tensor, dense_tensor, label_dense_tensor, label_dense_dim,
local_gpu->get_stream());
}
}
} else {
broadcast_buffer_->state.store(BufferState::ReadyForWrite);
}
return current_batch_size;
}
5.3.3 split
label and deny have already been copied to GPU. This step is to divide them into block s and then use GPU thread for operation.
template <typename TypeComp>
__global__ void split_kernel__(int batchsize, float* label_ptr, int label_dim, TypeComp* dense_ptr,
int dense_dim, const float* label_dense, int label_dense_dim) {
int idx = blockDim.x * blockIdx.x + threadIdx.x;
if (idx < batchsize * label_dense_dim) {
const int in_col = idx % label_dense_dim;
const int in_row = idx / label_dense_dim;
const int out_row = in_row;
if (in_col < label_dim) {
const int out_col = in_col;
label_ptr[out_row * label_dim + out_col] = label_dense[idx];
} else {
const int out_col = in_col - label_dim;
dense_ptr[out_row * dense_dim + out_col] = label_dense[idx];
}
}
return;
}
template <typename TypeComp>
void split(Tensor2<float>& label_tensor, Tensor2<TypeComp>& dense_tensor,
const Tensor2<float>& label_dense_buffer, const int label_dense_dim,
cudaStream_t stream) {
// check the input size
assert(label_tensor.get_dimensions()[0] == dense_tensor.get_dimensions()[0]);
assert(label_tensor.get_num_elements() + dense_tensor.get_num_elements() ==
label_dense_buffer.get_num_elements());
const int batchsize = label_tensor.get_dimensions()[0];
const int label_dim = label_tensor.get_dimensions()[1];
const int dense_dim = dense_tensor.get_dimensions()[1];
const int BLOCK_DIM = 256;
const int GRID_DIM = (label_dense_buffer.get_num_elements() - 1) / BLOCK_DIM + 1;
if (dense_dim > 0) {
split_kernel__<<<GRID_DIM, BLOCK_DIM, 0, stream>>>(
batchsize, label_tensor.get_ptr(), label_dim, dense_tensor.get_ptr(), dense_dim,
label_dense_buffer.get_ptr(), label_dense_dim);
} else if (dense_dim == 0) {
split_kernel__<<<GRID_DIM, BLOCK_DIM, 0, stream>>>(
batchsize, label_tensor.get_ptr(), label_dim, (TypeComp*)0, 0, label_dense_buffer.get_ptr(),
label_dense_dim);
} else {
CK_THROW_(Error_t::WrongInput, "dense_dim < 0");
}
return;
}
In this way, you can train in the follow-up. The follow-up is through finalize_batch.
void finalize_batch() {
for (size_t i = 0; i < resource_manager_->get_local_gpu_count(); i++) {
const auto &local_gpu = resource_manager_->get_local_gpu(i);
CudaDeviceContext context(local_gpu->get_device_id());
CK_CUDA_THROW_(cudaStreamSynchronize(local_gpu->get_stream()));
}
broadcast_buffer_->state.store(BufferState::ReadyForWrite);
}
template <typename SparseType>
void AsyncReader<SparseType>::ready_to_collect() {
auto raw_device_id = reader_impl_->get_last_batch_device();
auto local_gpu = resource_manager_->get_local_gpu(raw_device_id);
CudaDeviceContext ctx(local_gpu->get_device_id());
CK_CUDA_THROW_(cudaEventRecord(completion_events_[raw_device_id], local_gpu->get_stream()));
reader_impl_->finalize_batch(&completion_events_[raw_device_id]);
}
0x06 summary
The specific logic is as follows. In this chapter, the copying between buffer s is completed according to the status of ReadyForRead and ReadyForWrite. The embedding of the final spark parameter is in DataReaderOutput, that is, the calculation on subsequent GPU s starts from output.
0xEE personal information
★★★★★★★ thinking about life and technology ★★★★★★
Wechat public account: Rossi's thinking
If you want to get the news push of personal writing articles in time, or want to see the technical materials recommended by yourself, please pay attention.

0xFF reference
https://developer.nvidia.com/blog/introducing-merlin-hugectr-training-framework-dedicated-to-recommender-systems/
https://developer.nvidia.com/blog/announcing-nvidia-merlin-application-framework-for-deep-recommender-systems/
https://developer.nvidia.com/blog/accelerating-recommender-systems-training-with-nvidia-merlin-open-beta/
How does the embedding layer back propagate
https://web.eecs.umich.edu/~justincj/teaching/eecs442/notes/linear-backprop.html
Sparse matrix storage format summary + storage efficiency comparison: COO,CSR,DIA,ELL,HYB