Common attribute definitions
//Maximum capacity of hash table data
private static final int MAXIMUM_CAPACITY = 1 << 30;
//Hash table capacity default
private static final int DEFAULT_CAPACITY = 16;
static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
//Default concurrency level. This version is rarely used. It is defined here to be compatible with previous versions
private static final int DEFAULT_CONCURRENCY_LEVEL = 16;
//Load factor
private static final float LOAD_FACTOR = 0.75f;
//Tree threshold. If the specified bucket list length reaches 8, tree operation may occur.
static final int TREEIFY_THRESHOLD = 8;
//Threshold value of the length of a tree to a linked list
static final int UNTREEIFY_THRESHOLD = 6;
//Minimum treelization capacity. Treelization is triggered only when the length of hash table array reaches 64 and the length of a linked list reaches 8. Otherwise, it is only capacity expansion
static final int MIN_TREEIFY_CAPACITY = 64;
//Minimum step size of thread migration data
private static final int MIN_TRANSFER_STRIDE = 16;
//The number of bits in sizeCtl used to generate stamp.
private static int RESIZE_STAMP_BITS = 16;
//Maximum number of expansion threads
private static final int MAX_RESIZERS = (1 << (32 - RESIZE_STAMP_BITS)) - 1;
//Record the bit shift of stamp in sizeCtl
private static final int RESIZE_STAMP_SHIFT = 32 - RESIZE_STAMP_BITS;
//⭐ The hash value of the FWD node, that is, the current node has been migrated
static final int MOVED = -1; // hash for forwarding nodes
//⭐ The hash value of the root node of the red black tree
static final int TREEBIN = -2; // hash for roots of trees
static final int RESERVED = -3; // hash for transient reservations
//Number of bits used by normal node hash
static final int HASH_BITS = 0x7fffffff; // usable bits of normal node hash
//Hash table array
transient volatile Node<K,V>[] table;
//During the capacity expansion, the new table in the capacity expansion will be assigned to nextTable to keep the reference. After the capacity expansion, it will be set to Null
//Therefore, when nextTable is not null, it indicates that it is expanding
private transient volatile Node<K,V>[] nextTable;
//Similar to baseCount in LongAdder, when there is no thread contention, the baseCount is added directly
private transient volatile long baseCount;
//⭐️
//When sizectl < 0, the hash table is initializing or expanding.
// Sizecl = - 1 indicates that the table is initializing (another thread is creating the table array), and the current thread needs to spin
// !=- 1, the current data is expanding; sizeCtl corresponds to the identification stamp of capacity expansion in the binary system. The upper 16 bits represent (1+resizeThreadNum), that is, the number of threads participating in concurrent capacity expansion
//When sizecl = 0, it means to create a table array with default capacity
//When sizecl > 0, if the table data has not been initialized, it indicates the initialization size; If it has been initialized, it indicates the threshold of the next expansion
private transient volatile int sizeCtl;
//Record the current progress during capacity expansion. All threads need to allocate interval tasks from transferIndex to execute their own tasks.
private transient volatile int transferIndex;
private transient volatile int cellsBusy;
/**
* Table of counter cells. When non-null, size is a power of 2.
* LongAdder The cells array in. When the baseCount competes, the cells array will be created,
* The thread will get its own cell by calculating the hash value and accumulate the increment to the specified cell
* Total = sum(cells) + baseCount
*/
private transient volatile CounterCell[] counterCells;
Among these constants, sizeCtl, MOVED and TREEBIN are important, which will be described in detail later
The implementation logic of baseCount, cellsBusy and counterCells is similar to that of LongAddr. When there is no thread competition, the baseCount is added directly. When multiple threads add baseCount concurrently, an array of counterCells will be created. The thread will locate a certain location of counterCells through hash modulus. Each thread will add in its own counterCell. The final sum of elements = baseCount + the sum of operands of each thread
This is a space for time approach to reduce concurrency
Common small method analysis
spread method
static final int spread(int h) {
//HASH_BITS=0x7fffffff==>0111 1111 1111 1111 1111 1111 1111 1111
return (h ^ (h >>> 16)) & HASH_BITS;
}
Perturbation function, which makes hash value more hash, has two functions:
1. Let the high bit of hash value also participate in the operation
2. Make the obtained hash value positive (the highest bit of binary is 1, which means binary is negative, so & hash_bits can change the highest bit from 1 - > 0 to make the final result positive)
Let's counter prove the first point:
spread is often used to locate the position of the specified key in the table array, such as
int hash = spread(key.hashCode()); int i = (n - 1) & hash)
If the hash value of the key is 1100 0000 1110 0011 0001 1100 0001 1110, and the data length of the table is n=16, the key will be used directly without the spread method Hashcode () to locate the location. Let's see what's the disadvantage?
1100 0000 1110 0011 0001 1100 0001 1110 0000 0000 0000 0000 0000 0000 0000 1111 ==>n-1=15 Binary --------------------------------------- 0000 0000 0000 0000 0000 0000 0000 1110
**Because it is an and operation, if the data length is not long enough, there will be no data in the high binary bit, then key The result of hashcode () & (n-1) is limited by this** Take this as an example, if n=16, then key Hashcode () only the lower 4 bits will participate in the in place operation, so as long as the key is different If the last four digits of the hashcode () value are the same, the same table array position can be calculated, which greatly increases the probability of hash conflict.
Will things get better if you use the spread() function? For example, the data are still as above
1100 0000 1110 0011 0001 1100 0001 1110==>key.hashCode() 0000 0000 0000 0000 1100 0000 1110 0011==>key.hashCode()>>>16 --------------------------------------------- 1100 0000 1110 0011 1101 1100 1111 1101 ==>The same XOR result is 0, and the difference is 1 0111 1111 1111 1111 1111 1111 1111 1111 ==> HASH_BITS --------------------------------------------- 0100 0000 1110 0011 1101 1100 1111 1101 ==>&HASH_BITS Later results 0000 0000 0000 0000 0000 0000 0000 1111 ==>n-1=15 Binary --------------------------------------------- 0000 0000 0000 0000 0000 0000 0000 1101 ==> And operation
It can be seen that the spring method can make the upper 16 bits of the hash value participate in the operation, make the hash value more hash and reduce hash conflict
tableSizeFor
This method can find the minimum 2-power idempotent greater than or equal to the specified value, so as to keep the length of the table array at the 2-power idempotent
private static final int tableSizeFor(int c) {
int n = c - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
//MAXIMUM_CAPACITY=2^30
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
Take c=26 as an example to demonstrate the calculation process,
N = 26-1 = 25 = = > binary 0000 0001 1001
0000 0000 0000 0000 0000 0000 0001 1001 0000 0000 0000 0000 0000 0000 0000 1100 ==> n>>>1 ---------------------------------------- 0000 0000 0000 0000 0000 0000 0001 1101 ==> n= n | n >>> 1; 0000 0000 0000 0000 0000 0000 0000 1110 ==> n>>>2 ---------------------------------------- 0000 0000 0000 0000 0000 0000 0001 1111 ==> n = n | n >>> 2; 0000 0000 0000 0000 0000 0000 0000 0001 ==> n>>>4 ---------------------------------------- 0000 0000 0000 0000 0000 0000 0001 1111 ==>n = n | n >>> 4; 0000 0000 0000 0000 0000 0000 0000 0000 ==>n>>>8 ---------------------------------------- 0000 0000 0000 0000 0000 0000 0001 1111 ==>n = n | n >>> 8; 0000 0000 0000 0000 0000 0000 0000 0000 ==>n>>>16 ---------------------------------------- 0000 0000 0000 0000 0000 0000 0001 1111 ==>n = n | n >>> 16;
After calculation, n=31, because it is < maximum_ Capability, final n=31+1=32
tabAt,casTabAt,setAt
static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) {
return (Node<K,V>)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE);
}
static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i,
Node<K,V> c, Node<K,V> v) {
return U.compareAndSwapObject(tab, ((long)i << ASHIFT) + ABASE, c, v);
}
static final <K,V> void setTabAt(Node<K,V>[] tab, int i, Node<K,V> v) {
U.putObjectVolatile(tab, ((long)i << ASHIFT) + ABASE, v);
}
These three methods are based on CAS. By comparing the latest value in memory, they obtain the element at the specified position, insert the element in the specified position in a spin manner, and set the element to the specified position
Here I want to explain the calculation related to element positioning.
Get the address of Node [] data in memory, and calculate the actual position of specific subscript elements in the form of offset. For example, if you want to get the element at the subscript of data index=5: first, you need to know the memory address of the first element of the array, and then you can get the location of index=5 in memory by adding the memory address of the first element of the array + offset 5
Among them, the memory address of the array in the above example is similar to ABASE field, and the offset corresponds to ASHIFT
//Represents the offset address of the first element of the array
private static final long ABASE;
//Indicates the size of each spatial unit in the data. For example, if the size of each spatial unit is n, the starting position of the fifth subscript is ABSE+n*5
private static final int ASHIFT;
static {
try {
U = sun.misc.Unsafe.getUnsafe();
Class<?> ak = Node[].class;
//Calculates the offset address of the first element of the data in memory
ABASE = U.arrayBaseOffset(ak);
//Calculate the space occupied by array cells
int scale = U.arrayIndexScale(ak);
// If the space size is not a power of 2, an error is reported
if ((scale & (scale - 1)) != 0)
throw new Error("data type scale not a power of two");
//numberOfLeadingZeros indicates the number of consecutive zeros starting from the high order,
//For example, scale=16, binary is 0000 0000 0000 0001 0000
//So integer numberOfLeadingZeros(16)=27
ASHIFT = 31 - Integer.numberOfLeadingZeros(scale);
} catch (Exception e) {
throw new Error(e);
}
}
About the relationship between ABASE and ASHIFT and how to calculate them, let's take chestnuts as an example
If we want to calculate the position of trees at the specified position in a row of trees, we know that the first tree is 3m from the starting position of the road, and every two trees are 2m apart, how many M is the fourth tree on the road?
Calculation method: 3+2*(4-1)=9m. Here, ABSE can be compared to 3m, and ASHIT is equivalent to 2m of the interval
In the source code ((long) I < < ashift) + abase, the bit operation is equivalent to the multiplication operation above
ConcurrentHashMap(int initialCapacity) construction method
public ConcurrentHashMap(int initialCapacity) {
//An exception is thrown when the initial capacity is less than 0
if (initialCapacity < 0)
throw new IllegalArgumentException();
//Calculate initialization capacity
int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ?
MAXIMUM_CAPACITY :
tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1));
//Here, the table array has not been initialized. sizeCtl indicates the initialization capacity,
this.sizeCtl = cap;
}
initTable
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
//If the table is null or the length is 0, the initialization table operation is performed
while ((tab = table) == null || tab.length == 0) {
//① sizeCtl is assigned to sc
if ((sc = sizeCtl) < 0)
Thread.yield(); // lost initialization race; just spin
//②
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if ((tab = table) == null || tab.length == 0) {
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc;
}
break;
}
}
return tab;
}
If multiple threads do not initialize the table together, the code logic will come to ②,
//Assign sizeCtl to - 1
if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
//The reason for judging again here is to prevent the current thread from initializing again after other threads have been initialized, resulting in the loss of initialized table data
if ((tab = table) == null || tab.length == 0) {
//table data capacity
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
//sc=n-1/4n=(3/4)n=0.75n
sc = n - (n >>> 2);
}
} finally {
//1. If the current thread is the first thread to initialize the table, sizeCtl = the threshold of the next capacity expansion
//2. The current thread is not the first incoming thread to initialize the table. You need to restore sizeCtl to its original value, because the if block assigns sizeCtl to - 1. The original value of sizeCtl is retained in the variable sc at ①
sizeCtl = sc;
}
break;
}
If multiple threads initialize the table together, such as thread A and thread B, thread A has started executing the code at ②, and thread B will be stopped by the code at ① when entering the ininTable method
if ((sc = sizeCtl) < 0)
Thread.yield();
Because the initialization table thread sets sizeCtl to - 1, which meets the if condition here, thread B will release the execution right of the CPU
ForwardingNode constructor
final Node<K,V>[] nextTable;
ForwardingNode(Node<K,V>[] tab) {
//Set the hash value to MOVED, i.e. - 1
super(MOVED, null, null, null);
//Assign tab to the member variable nextTable
this.nextTable = tab;
}
put operation
public V put(K key, V value) {
return putVal(key, value, false);
}
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
//hash value is calculated by perturbation function
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
//f bucket head node
//n table array length
//i bucket level subscript
//fh bucket head node hash value
Node<K,V> f; int n, i, fh;
//If the table has not been initialized, perform the initialization action
if (tab == null || (n = tab.length) == 0)
tab = initTable();
//If there is no element in the bucket calculated according to the hash value, the current value is placed here
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
// If the hash value of bucket element = - 1, it indicates that the current bucket element is an FWD node and is being migrated
else if ((fh = f.hash) == MOVED)
//Help migration ① ⭐ ️
tab = helpTransfer(tab, f);
else {
V oldVal = null;
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
//1. When there is no conflict, the key value is inserted into the tail of the linked list, where binCount represents the length of the linked list
//2. If a conflict occurs, the key value will replace the old value. Here (bincount-1) (the index starts from 0, so - 1) indicates the conflict location
binCount = 1;
//Loop traversal
for (Node<K,V> e = f;; ++binCount) {
K ek;
//If the key and hash values are consistent with the key and hash values of an element in the linked list, it indicates that there is a conflict. Replace the current newly inserted value with the old value oldVal
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
//If the current element is inconsistent with the key of the inserted element, it will be inserted at the end of the linked list
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
//If the node type is red black tree, the node type is TreeBin
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
//If the number of bucket elements > = 8, the treeifyBin operation is called
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
//1. Count the number of elements in the table
//2. Judge whether the capacity expansion threshold has been reached and whether the capacity expansion operation needs to be triggered
addCount(1L, binCount);
return null;
}
To summarize the putVal operation, we mainly do the following:
1. If table is not initialized, initialize table first
2. If the bucket index element is empty, insert value into the current bucket index
3. If the bucket node type is FWD, help with migration
4. If bucket element type is linked list
- If there is no conflict, put the key value at the end of the linked list
- If there is a conflict, replace the old value with value
5. If the bucket element type is TreeBin, execute the red black tree putTreeVal operation
6. If the length of the linked list is > = 8, the linked list to red black tree operation will be triggered
7. Calculate the number of table elements and whether expansion is required
helpTransfer
resizeStamp
static final int resizeStamp(int n) {
//RESIZE_STAMP_BITS=16
return Integer.numberOfLeadingZeros(n) | (1 << (RESIZE_STAMP_BITS - 1));
}
This method is mainly used to calculate the capacity expansion identification stamp. In a batch of capacity expansion (such as 16 - > 32), the value will not change after multiple calculations. Take n=16 as an example, integer numberOfLeadingZeros(n)=27
0000 0000 0000 0000 0000 0000 0001 1011 0000 0000 0000 0000 1000 0000 0000 0000 --------------------------------------- 0000 0000 0000 0000 1000 0000 0001 1011
Here, we need to explain that sizeCtl indicates the capacity expansion. The high 16 bits indicate the capacity expansion identification stamp, and the low 16 bits indicate 1 + the number of capacity expansion threads
final Node<K,V>[] helpTransfer(Node<K,V>[] tab, Node<K,V> f) {
//nextTable capacity expansion table
//sc stands for sizeCtl
Node<K,V>[] nextTab; int sc;
//If the node is an FWD node and the nextTable is not empty
if (tab != null && (f instanceof ForwardingNode) &&
(nextTab = ((ForwardingNode<K,V>)f).nextTable) != null) {
//Tab Take length = 16 as an example, where rs = 0000 1000 0000 0001 1011
int rs = resizeStamp(tab.length);
//Indicates that capacity expansion is in progress, (SC = sizectl) < 0. Here, it indicates that capacity expansion is in progress
while (nextTab == nextTable && table == tab &&
(sc = sizeCtl) < 0) {
//1. If the upper 16 bits of sc are different from the capacity expansion identification stamp represented by rs, it indicates that it is not the capacity expansion of the current batch
//If the condition sc=rs+1 is incorrect, it should be sc = (RS < < 16) + 1, that is, if the lower 16 bits of sc = 1, it means that the capacity expansion is completed and all threads have exited the capacity expansion operation
//Condition sc == rs + MAX_RESIZERS is incorrect. It should be SC = = (RS < < 16) + max_ Resizers indicates that the thread participating in concurrent capacity expansion has reached the maximum value, and the current thread does not need to participate
//transferIndex is used to record the progress in capacity expansion. Since the capacity expansion migration data is migrated from the back to the front, that is, from the bucket bit of position 15 and the bucket bit of position 14 Bucket position 0 is in this order. Therefore, transferIndex < = 0 indicates that the migration has been completed. The current thread can exit
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || transferIndex <= 0)
break;
//sizeCtl+1 indicates that a thread enters to help the migration work
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1)) {
transfer(tab, nextTab);
break;
}
}
return nextTab;
}
return table;
}
First, if it is a capacity expansion operation of the same batch, the upper 16 bits of RS and sizeCtl are the same. Here, assume rs = 0000 1000 0000 0001 1011
Explain SC = = (RS < < 16) + 1 as follows:
We know that when it indicates capacity expansion, the lower 16 bits of sizeCtl = 1+nThread, that is, 1 + the number of capacity expansion threads
RS < < 16 + 1 = = > 1000 0000 0001 1011 0000 001. At this time, if SC = (RS < < 16) + 1 = 1000 0000 0001 1011 0000 001, its lower 16 bits are 1, that is, the number of threads for capacity expansion = 0. It can be inferred that the capacity expansion has been completed and the threads have exited one after another
Let's look at SC = = RS < < 16 + max_ RESIZERS
Similar to the above explanation, SC = RS < < 16 + Max_ Resizers = = > 1000 0000 0001 1011 1111 1111 1111 1111. At this time, the low bit is full. It can be understood that the number of threads participating in capacity expansion has reached the upper limit.
transfer method
The real logic of migration is in transfer
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {
//n the hash table array length is assumed to be 16
//stride thread migration processing step
int n = tab.length, stride;
//Assuming ncpu = 4 and N = 16, then n > > > 3 = 2, so stripe = min_ TRANSFER_ STRIDE=16
if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)
stride = MIN_TRANSFER_STRIDE; // subdivide range
//1. If nextTable==null is true, it indicates that the current thread is the thread that triggers this expansion
//2. If nextTable==null is not true, it indicates that the current thread is assisting in capacity expansion, mainly data migration
if (nextTab == null) { // initiating
try {
@SuppressWarnings("unchecked")
// Define a 2n capacity Node array
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];
//The reference is assigned to nextTab
nextTab = nt;
} catch (Throwable ex) { // try to cope with OOME
//New array construction failed
sizeCtl = Integer.MAX_VALUE;
return;
}
//Assign to member variable nextTable
nextTable = nextTab;
//Assuming n=16, transferIndex=16 indicates that the capacity expansion operation starts from the 16th element (here transferIndex starts from 1)
transferIndex = n;
}
// Expansion array length nexttn=32
int nextn = nextTab.length;
//Declare an FWD node with a hash value of - 1,
//After a bucket data is processed, set this bucket as a fwd node, and other read / write threads will have different processing logic
ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);
//Push mark
boolean advance = true;
//Completion mark
boolean finishing = false; // to ensure sweep before committing nextTab
// First, when multiple threads participate in data migration, each thread will allocate several table array intervals, and exit after processing
// For example, thread A processes the elements of table array subscripts 10 ~ 15, thread B 4~9 and thread C 0~3
//i indicates the bucket subscript to which the current thread migration work is executed
//Bound the lower bound of the current thread migration workflow
for (int i = 0, bound = 0;;) {
//f bucket head node
//fh bucket head node hash value
Node<K,V> f; int fh;
//
while (advance) {
//nextIndex indicates the start position of the assigned task
//nextBound indicates the end position of the assigned task
int nextIndex, nextBound;
if (--i >= bound || finishing)
advance = false;
//There are two meanings here. 1. Assign transferIndex to nextIndex,
//2. If nextindex < = 0 is true, the migration data range has been allocated, and the current thread has no migration work to deal with
// You can do the logic related to exiting the migration task
//⭐️
else if ((nextIndex = transferIndex) <= 0) {
i = -1;
advance = false;
}
// Here, the CAS mode determines the end position of the assigned task
// There are two meanings here: if there are enough data to be migrated, allocate stripe data to the thread to migrate; Otherwise, all the remaining data will be given to one thread
//Assuming nextIndex=16, nextBound=0
else if (U.compareAndSwapInt
(this, TRANSFERINDEX, nextIndex,
nextBound = (nextIndex > stride ?
nextIndex - stride : 0))) {
//bound=0,i=15, so it can be inferred that the data range of the table array to be migrated by the current thread is [0,15]
bound = nextBound;
i = nextIndex - 1;
advance = false;
}
}
// If I < 0 is true, the previous (nextindex = transferindex) < = 0 means that the current thread is not assigned to the migration task and needs to exit the migration task
if (i < 0 || i >= n || i + n >= nextn) {
int sc;
//If the migration task is completed
if (finishing) {
//nextTable is assigned null
nextTable = null;
// Point the table to the expanded array
table = nextTab;
//sizeCtl indicates the next capacity expansion threshold at this time
//2n-1/2n=1.5n, where n is the length before expansion, so 1.5n = (0.75) (length after expansion)
sizeCtl = (n << 1) - (n >>> 1);
return;
}
//When CAS is established, the lower 16 bits of sc - 1 indicates that there is a migration thread to exit
if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {
// We know that the resizeStamp calculated during capacity expansion of the same batch is the same. Here, assume n=16
//Then resizestamp (n) = = > 0000 1000 0000 0001 1011
//resizeStamp(n) << RESIZE_STAMP_SHIFT ==>1000 0000 0001 1011 0000 0000 0000 0000
//sc-2 participates in the calculation of the lower 16 bits. If the if condition is true, it indicates that the current thread is not the last thread to exit the migration task, then it can exit normally
if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)
return;
// If it is the last thread to exit the migration task
finishing = advance = true;
i = n; // recheck before commit
}
}
//When the program comes here, it indicates that the migration task of the current thread has not been completed
// If the condition here is true, it means that the current bucket does not store data, and it is set as the FWD node
else if ((f = tabAt(tab, i)) == null)
advance = casTabAt(tab, i, null, fwd);
//Condition holds: indicates that the current node has been migrated.
else if ((fh = f.hash) == MOVED)
advance = true; // already processed
else {
//Start migration
synchronized (f) {
if (tabAt(tab, i) == f) {
Node<K,V> ln, hn;
//For linked list migration, you need to pay attention to the previous variable TREEBIN=-2, so use FH > 0 to judge whether it is a linked list. If it is greater than or equal to 0, it is a linked list
if (fh >= 0) {
int runBit = fh & n;
Node<K,V> lastRun = f;
for (Node<K,V> p = f.next; p != null; p = p.next) {
int b = p.hash & n;
if (b != runBit) {
runBit = b;
lastRun = p;
}
}
if (runBit == 0) {
ln = lastRun;
hn = null;
}
else {
hn = lastRun;
ln = null;
}
for (Node<K,V> p = f; p != lastRun; p = p.next) {
int ph = p.hash; K pk = p.key; V pv = p.val;
if ((ph & n) == 0)
ln = new Node<K,V>(ph, pk, pv, ln);
else
hn = new Node<K,V>(ph, pk, pv, hn);
}
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
setTabAt(tab, i, fwd);
advance = true;
}
//Red black tree node treeBin migration
else if (f instanceof TreeBin) {
TreeBin<K,V> t = (TreeBin<K,V>)f;
TreeNode<K,V> lo = null, loTail = null;
TreeNode<K,V> hi = null, hiTail = null;
int lc = 0, hc = 0;
for (Node<K,V> e = t.first; e != null; e = e.next) {
int h = e.hash;
TreeNode<K,V> p = new TreeNode<K,V>
(h, e.key, e.val, null, null);
if ((h & n) == 0) {
if ((p.prev = loTail) == null)
lo = p;
else
loTail.next = p;
loTail = p;
++lc;
}
else {
if ((p.prev = hiTail) == null)
hi = p;
else
hiTail.next = p;
hiTail = p;
++hc;
}
}
ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) :
(hc != 0) ? new TreeBin<K,V>(lo) : t;
hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) :
(lc != 0) ? new TreeBin<K,V>(hi) : t;
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
setTabAt(tab, i, fwd);
advance = true;
}
}
}
}
}
}
The transfer method mainly does the following things:
1. When the data has not been expanded, perform the data expansion operation and create a 2x table array
2. Assign migration intervals to threads. Each thread handles the work of its own interval. After processing, it exits. The last exiting thread handles some marking work
- If the current migration bucket element is null, set the FWD node to this bucket
- If the bucket head node hash value is - 1, this bucket has been migrated
3. Bucket migration
- Linked list migration
- Red black tree migration
Let's take the linked list as an example to illustrate how to migrate?
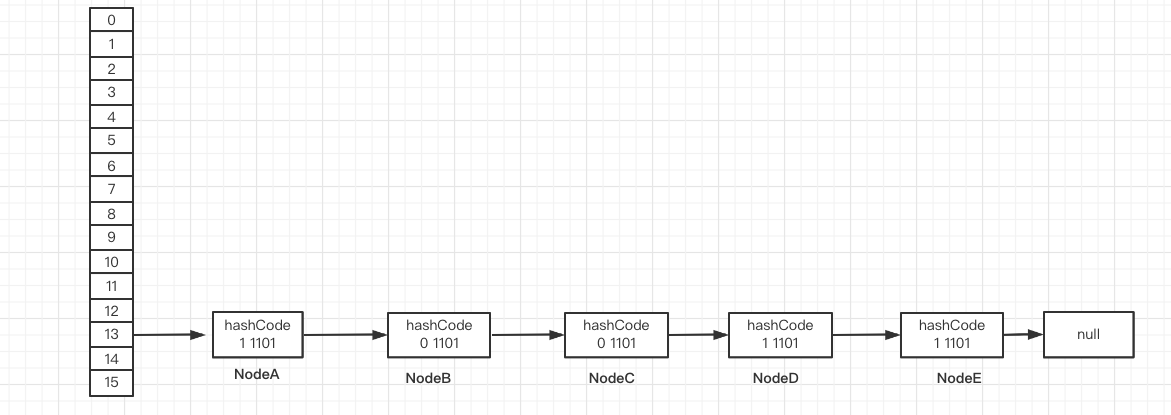
Here, it is assumed that NodeA-E are 11101, 01101, 11101, 11101 and 11101 respectively; Table array length n=16
These nodes are finally located in bucket 13 after hash=spread(), and hash & (n-1)
Before analyzing the migrated data, first clarify one problem:
1. Because of the length of the table array, only the last four bits are involved in & operation during bucket positioning. If the length of the table array becomes longer, will the bucket positions of these nodes change?
My answer will change. For ex amp le, when n=16 is expanded to 32, the number of bits involved in the & operation becomes 5 bits, so the final result will change.
Take NodeA and NodeB as examples
Suppose NodeA hash value is 0100 0000 1110 0011 1101 1100 1111 1101 and NodeB hash value is 0100 0000 1110 0011 1101 1100 1110 1101
NodeA.hashCode&(32-1)==>0000 0000 0000 0000 0000 0000 0001 1101=29
NodeB.hashCode&(32-1)==>0000 0000 0000 0000 0000 0000 0000 1101=13
It can be seen that after capacity expansion, NodeA is positioned at 29 barrels, while NodeB is still positioned at 13 barrels.
Therefore, we can also draw a conclusion: the location of the original bucket location element in the new table after capacity expansion: 1. It is still in the current location; 2. New bucket location = Original bucket location + original table length
Therefore, the node with the highest bit of 1 involved in the & operation on the bucket is also called the high-level chain node, otherwise it is the low-level chain node. There is a feature of the high-level chain node. After migrating to the new table, the bucket position = the original bucket position + the length of the original table, and the low-level chain node is still the same as the original bucket position after migration.
Taking the above figure as an example, the bucket head node is NodeA
if (fh >= 0) {
//fh last five bits 11101 & 10000 (16 binary) = 1
int runBit = fh & n;
//lastRun points to the bucket head node ①
Node<K,V> lastRun = f;
for (Node<K,V> p = f.next; p != null; p = p.next) {
int b = p.hash & n;
if (b != runBit) {
runBit = b;
lastRun = p;
}
}
//If runBit=0, it is a low order chain
if (runBit == 0) {
ln = lastRun;
hn = null;
}
else {
hn = lastRun;
ln = null;
}
for (Node<K,V> p = f; p != lastRun; p = p.next) {
int ph = p.hash; K pk = p.key; V pv = p.val;
if ((ph & n) == 0)
//Construct low order chain
ln = new Node<K,V>(ph, pk, pv, ln);
else
//Tectonic highstand chain
hn = new Node<K,V>(ph, pk, pv, hn);
}
//Insert the lower chain into the same bucket position of the new table
setTabAt(nextTab, i, ln);
//Insert the high-level chain into the original bucket position + n of the new table
setTabAt(nextTab, i + n, hn);
// Set the current bucket position to FWD
setTabAt(tab, i, fwd);
//Bucket migration completed
advance = true;
}
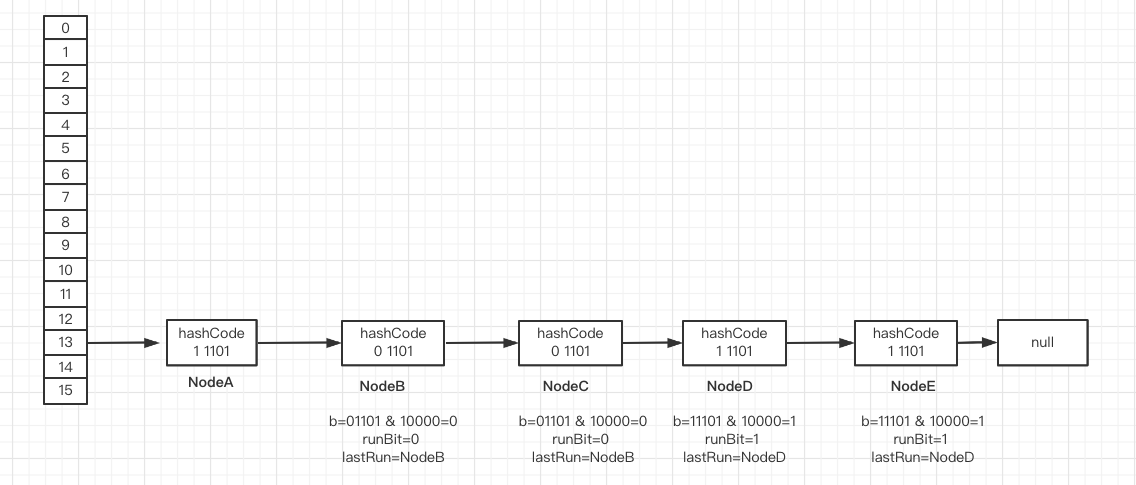
Taking the above figure as an example, the direction of lastRun in the for loop at ① has changed several times. Finally, lastRun points to NodeD and runBit=1, indicating that it is a high-order chain at this time, so
hn=lastRun==>NodeD ln=null
Construct high-low chain
//Starting from NodeA, the judgment condition is p= Lastrun, i.e. P= NodeD
for (Node<K,V> p = f; p != lastRun; p = p.next) {
int ph = p.hash; K pk = p.key; V pv = p.val;
if ((ph & n) == 0)
//Construct low order chain
ln = new Node<K,V>(ph, pk, pv, ln);
else
//Tectonic highstand chain
hn = new Node<K,V>(ph, pk, pv, hn);
}
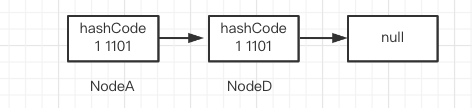
When p points to NodeA, (pH & n) = = 1, construct the high-order chain, hn
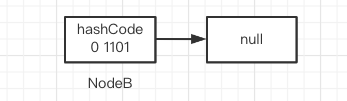
When p points to NodeB, (pH & n) = = 0, construct the low order chain ln
When p points to NodeC, (pH & n) = = 0, construct the low order chain ln
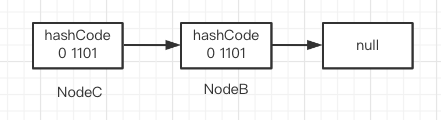
When p points to NodeD, it is skipped directly because p==lastRun
When p points to NodeE, (pH & n) = = 1, construct the high-order chain, hn

So far, the high-order chain and low-order chain have been constructed, and then they are inserted into the specified position
addCount()
This method mainly does two things: 1. Count and count the number of elements in the table. 2. Expand the capacity
//If check < 0, do not check the expansion, and - 1 will be passed when remove
//Check < = 1 indicates that it is only checked in non competitive situations
private final void addCount(long x, int check) {
CounterCell[] as; long b, s;
//The principle of counting is similar to LongAddr
//counterCells!=null indicates that multiple threads are accumulating baseCount. In this case, each thread is allocated a counterCell
//Final cumulative sum = sum of each counterCell + baseCount
if ((as = counterCells) != null ||
!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {
CounterCell a; long v; int m;
boolean uncontended = true;
if (as == null || (m = as.length - 1) < 0 ||
(a = as[ThreadLocalRandom.getProbe() & m]) == null ||
!(uncontended =
U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {
fullAddCount(x, uncontended);
return;
}
//Check < = 1 exit
if (check <= 1)
return;
//Cyclic counter cell accumulation
s = sumCount();
}
//Execute expansion logic
if (check >= 0) {
Node<K,V>[] tab, nt; int n, sc;
//S > = (long) (SC = sizeCtl) holds, indicating that sizeCtl is either a negative number, indicating capacity expansion, or a positive number, indicating capacity expansion threshold
//(tab = table) != null program can go here is basically established
//(n = tab.length) < MAXIMUM_ Capability holds if the length of the table array is less than the maximum limit
while (s >= (long)(sc = sizeCtl) && (tab = table) != null &&
(n = tab.length) < MAXIMUM_CAPACITY) {
//Capacity expansion identification stamp
int rs = resizeStamp(n);
//SC < 0 indicates that capacity expansion is in progress. Incoming threads assist in capacity expansion and data migration
if (sc < 0) {
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
}
//If the current thread is the thread that triggers capacity expansion, take this branch and the number of threads participating in capacity expansion will be + 1
//(the lower 16 bits of sizeCtl indicate 1 + number of threads for capacity expansion, where + 2 is not equivalent to 1 + 1)
else if (U.compareAndSwapInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2))
//The nextTable=null passed in here can also indicate that it is the first thread to trigger capacity expansion, and it is going to create nextTable
transfer(tab, null);
s = sumCount();
}
}
}
get operation
public V get(Object key) {
//tab represents an array of table s
//e represents the bucket head node
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
//Calculate hash value
int h = spread(key.hashCode());
//If the bucket position obtained according to the hash value is not empty
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
//If the key/hash values of the bucket head node match, it indicates that it has been found
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
//There are two cases of EH < 0. 1. eh=-1 indicates that the FWD node has migrated. 2. eh=-2 indicates that the red black tree node TreeBin
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
//Here is the linked list. Traverse the linked list and compare them one by one
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
//null if not found
return null;
}
Here we mainly describe the case of EH < 0. Eh < 0 indicates that the node may be FWD or TreeBin,
If it is a FWD node, it indicates that the capacity has been expanded and the data has been migrated. You need to find it in the new table
//ForwardingNode#find
Node<K,V> find(int h, Object k) {
// loop to avoid arbitrarily deep recursion on forwarding nodes
//The FWD node stores the data length after capacity expansion
outer: for (Node<K,V>[] tab = nextTable;;) {
Node<K,V> e; int n;
//If the bucket element in the table is null after capacity expansion, it will be returned directly
if (k == null || tab == null || (n = tab.length) == 0 ||
(e = tabAt(tab, (n - 1) & h)) == null)
return null;
for (;;) {
int eh; K ek;
//If the bucket head node meets the conditions after comparison, the bucket head node is returned
if ((eh = e.hash) == h &&
((ek = e.key) == k || (ek != null && k.equals(ek))))
return e;
//Here, the hash value of bucket head node is less than 0, indicating that the current table is expanded again
if (eh < 0) {
//The head node type is FWD
if (e instanceof ForwardingNode) {
tab = ((ForwardingNode<K,V>)e).nextTable;
continue outer;
}
else
//The head node type is TreeBin
return e.find(h, k);
}
//If you find it, you don't know
if ((e = e.next) == null)
return null;
}
}
}