Introduction
As the core component of the operating system, scheduler has a very important significance, which is constantly updated with the update of Linux kernel. This series of articles through linux-3.18.3 source for scheduler learning and analysis, step by step to Linux existing scheduler original show. As the beginning of this paper, it mainly introduces the principle and important data structure of scheduler.
Scheduler introduction
With the development of the times, linux has developed steadily from its initial version to today, from the non preemptive kernel of 2.4 to the preemptive kernel of today. The scheduler has undergone tremendous changes in code structure and design idea, and its scheduling algorithm for ordinary processes has also changed from O(1) to CFS. A good scheduling algorithm should consider the following aspects:
- Fairness: ensure that each process gets a reasonable CPU time.
- Efficient: keep the CPU busy, that is, there are always processes running on the CPU.
- Response time: make the response time of interactive users as short as possible.
- Turnaround time: make the batch user wait for output as short as possible.
- Throughput: maximize the number of processes processed per unit time.
- Load balancing: providing higher performance in multi-core multiprocessor systems
The whole scheduling system contains at least two scheduling algorithms, which are respectively for real-time process and common process. So in the whole linux kernel, real-time process and common process coexist, but they use different scheduling algorithms. The common process uses CFS scheduling algorithm (red black tree scheduling). Later, I will show you how the scheduler schedules these two processes.
process
As shown in the previous section, in linux, there are two types of processes, one is real-time process and the other is ordinary process
- Real time process: the response time requirements of the system are very high, they need short response time, and the change of this time is very small. Typical real-time processes include music player, video player, etc.
- Ordinary process: including interactive process and non interactive process. Interactive process, such as text editor, will sleep and wake up through mouse and keyboard continuously, while non interactive process, such as background maintenance process, has no high requirements for IO and response time, such as compiler.
They coexist when running in linux kernel. The priority of real-time process is 0-99. The priority of real-time process will not change during running (static priority), while the priority of ordinary process is 100-139. The priority of ordinary process will change during running of kernel (dynamic priority).
scheduling strategy
In linux system, scheduling strategy is divided into
- SCHED_NORMAL: the scheduling policy used by ordinary processes. Now this scheduling policy uses CFS scheduler.
- SCHED_FIFO: a scheduling policy used by real-time processes. Once the process of this scheduling policy uses CPU, it will run until a higher priority real-time process enters the queue, or it will automatically give up CPU. It is suitable for processes with higher time requirements but shorter running time each time.
- SCHED_RR: the time slice rotation strategy used by the real-time process. When the time slice of the real-time process is used up, the scheduler will put it at the end of the queue, so that each real-time process can execute for a period of time. It is suitable for real-time processes with long running time.
Dispatch
First of all, we need to know what kind of process will enter the scheduler for selection, that is, the process in the task "running state, while the processes in other states will not enter the scheduler for scheduling. The timing of system scheduling is as follows
- When cond ou reset() is called
- When schedule() is called explicitly
- When returning to user space from a system call or an exception interrupt
- When returning user space from an interrupt context
When kernel preemption is enabled (enabled by default), there will be several more scheduling opportunities, as follows
- When preempt_enable() is invoked in the context of system call or exception interrupt, the system will be scheduled only when it is called at the last time (preempt_enable()).
- In the interrupt context, when returning from the interrupt processing function to the preemptive context (here is the lower part of the interrupt, the upper part of the interrupt will actually close the interrupt, while the new interrupt will only be registered. Because the upper part of the interrupt processing is very fast, the new interrupt signal will be executed only after the upper part of the processing is completed, thus forming the interrupt reentrant, but even the lower part of the interrupt cannot Scheduled)
When the system starts the scheduler initialization, a scheduling timer will be initialized. The scheduling timer will execute an interrupt every certain time. During the interrupt, the running time of the current running process will be updated. If the process needs to be scheduled, a scheduling flag bit will be set in the scheduling timer interrupt, and then it will return from the timer interrupt, because it has been mentioned above There may be scheduling opportunities when the timer interrupts return. If the timer interrupts return to the user state space, and the scheduling flag bit is set again, process switching will be done. In the assembly code of the kernel source code, all interrupt return processing must determine whether the scheduling flag bit is set. If it is set, execute schedule() to schedule. We know that real-time processes and ordinary processes coexist. How does the scheduler coordinate the scheduling between them? In fact, it is very simple. When scheduling, we will first check whether there are real-time processes that can run in the real-time process running queue. If not, we will go to the ordinary process running queue to find the next ordinary process that can run. If not, the scheduler will use I The dle process runs. Later chapters will be detailed with code.
The system does not allow scheduling all the time. When it is in the period of interruption (whether the first half or the second half), scheduling is forbidden by the system, and then scheduling is allowed again after interruption. For exceptions, the system does not prohibit scheduling, that is, in the context of exceptions, the system is likely to schedule.
data structure
In this section, we take ordinary process as the explanation object, because the scheduling algorithm used by ordinary process is CFS scheduling algorithm, which is based on the red black tree. Compared with the scheduling algorithm of real-time process, it is much more complex, while the organization structure of real-time process is not too different from that of ordinary process, and the algorithm is relatively simple.
Composition form
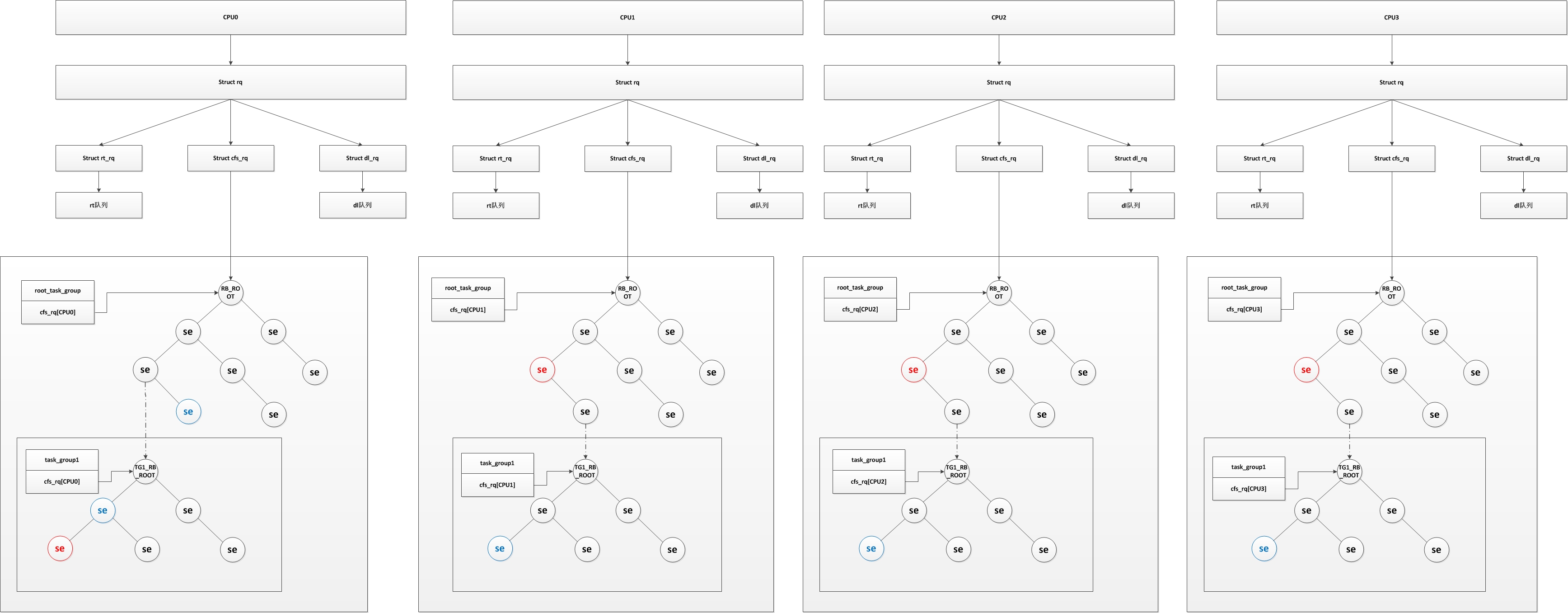
It can be seen from the figure that each CPU contains a run queue structure (struct rq), and each run queue contains its own real-time process run queue (struct rt_q), common process run queue (struct cfs_q), and a DL queue (struct dl_q) which I don't know what to use, that is to say, each CPU has its own real-time process run For convenience, we only describe the organization structure of ordinary processes (the most complex is the organization structure of ordinary processes), red se is the program currently executing on the CPU, and blue is the next program to be executed. In fact, the figure is not standardized. In fact, when the process is running, it will be detached from the red black tree, and then set the next one Scheduling processes. When the running time of the process is over, they will be put into the red black tree again. Why two blue processes on CPU0 will be scheduled will be explained in group scheduling. Why there is another red black tree in the red black tree, we will explain in the scheduling entity.
Structure task group
We know that linux is a multi-user system. If there are two processes belonging to two users respectively, and the priority of the processes is different, the CPU time occupied by the two users will be different, which is obviously unfair (if the priority difference is large, the CPU time used by the user of the low priority process is small), so the kernel introduces group scheduling. If it is based on user grouping, the CPU time used by both users is 50% even if the process priority is different. This is why CPU0 in Figure 1 has two programs that will be scheduled in blue. If the running time of task ﹣ group1 is not used up, and the running time of the current process is used up, the next scheduled process in task ﹣ group1 will be scheduled. On the contrary, if the running time of task ﹣ group1 is used up, the next scheduled process in the previous layer will be called. It should be noted that there may be a part of real-time process and a part of ordinary process in a group scheduling, which also leads to the group being able to meet the requirements of both real-time scheduling and CFS scheduling.
linux can group processes in two ways:
- USER ID: it is grouped according to the USER ID of the process. A file of cpu.share will be generated in the corresponding directory / sys/kernel/uid /. You can configure the proportion of the user's CPU time by configuring the file.
- cgourp(control group): the generation group is used to limit all its processes. For example, if I generate a group (the group is empty after generation, and there are no processes in it), set its CPU utilization rate to 10%, and drop a process into this group, then this process can only use up to 10% of the CPU. If we drop multiple processes into this group, all processes in this group will share this 10% equally.
Note that the concept of process group here is different from that of parent-child process group generated by fork call. The concept of process group used in this paper is all the concept of process group in group scheduling. In order to manage group scheduling, the kernel introduces the struct task group structure, as follows:
1 /* Process groups for group scheduling */
2 struct task_group {
3 /* Used to find the process group structure to which the process belongs */
4 struct cgroup_subsys_state css;
5
6 #ifdef CONFIG_FAIR_GROUP_SCHED
7 /* CFS The process group variable of the scheduler, which initializes and allocates memory in alloc fair sched group() */
8 /* This process group has A corresponding scheduling entity on each CPU, because it is possible that this process group runs on two CPUs at the same time (its A process runs on CPU0, and B process runs on CPU1) */
9 struct sched_entity **se;
10 /* Process groups have a CFS run queue on each CPU (why, explain later) */
11 struct cfs_rq **cfs_rq;
12 /* Used to save the priority whose default is NICE 0 */
13 unsigned long shares;
14
15 #ifdef CONFIG_SMP
16 atomic_long_t load_avg;
17 atomic_t runnable_avg;
18 #endif
19 #endif
20
21 #ifdef CONFIG_RT_GROUP_SCHED
22 /* The process group variable of the real-time process scheduler is the same as CFS */
23 struct sched_rt_entity **rt_se;
24 struct rt_rq **rt_rq;
25
26 struct rt_bandwidth rt_bandwidth;
27 #endif
28
29 struct rcu_head rcu;
30 /* Used to establish a process list (the process list belonging to this scheduling group) */
31 struct list_head list;
32
33 /* The process group of each layer is a scheduling entity of the running queue of the process group of the upper layer. In the same layer, the process group and the process are treated equally */
34 struct task_group *parent;
35 /* Process group's sibling list */
36 struct list_head siblings;
37 /* List of child nodes of process group */
38 struct list_head children;
39
40 #ifdef CONFIG_SCHED_AUTOGROUP
41 struct autogroup *autogroup;
42 #endif
43
44 struct cfs_bandwidth cfs_bandwidth;
45 };
In the structure of struct task group, the most important members are struct sched entity * * se and struct CFS FQ * * CFS FQ. In Figure 1, there is only one root task group and task group 1. They allocate space for se and CFS RQ according to the number of CPUs during initialization, that is, one se and CFS RQ will be allocated for each CPU in task group 1 and root task group. The same is true for struct sched ~ RT ~ entity * * RT ~ se and struct RT ~ RT ~ RQ * * RT ~ RQ used for real-time processes. The reason is that in the case of multi-core and multi CPU, the processes of the same process group may run on different CPUs at the same time, so each process group must allocate its scheduling entities (struct sched'entity and struct sched'rt'entity) and running queues (struct cfs'rq and struct rt'rq) to each CPU.
Structure sched'entity
In group scheduling, the concept of scheduling entity is also involved. Its structure is struct sched'entity (se for short), which is the se in the red black tree in Figure 1. It actually represents a scheduling object, which can be a process or a process group. For the root red black tree, a process group is equivalent to a scheduling entity, and a process is also equivalent to a scheduling entity. We can first look at its structure, as follows:
1 /* A scheduling entity (a node of the red black tree), which contains a group or a specified process, including its own running queue, a parent pointer, and a pointer to the running queue to be scheduled */
2 struct sched_entity {
3 /* Weight, which contains the value of priority to weight in the array */
4 struct load_weight load; /* for load-balancing */
5 /* Node information of entity in red black tree */
6 struct rb_node run_node;
7 /* Process group of entity */
8 struct list_head group_node;
9 /* Whether the entity is in the red black tree running queue */
10 unsigned int on_rq;
11
12 /* Start time */
13 u64 exec_start;
14 /* Total operation time */
15 u64 sum_exec_runtime;
16 /* Virtual runtime, which is updated when time is interrupted or task status changes
17 * It will continue to grow, and the growth rate is inversely proportional to the load weight. The higher the load is, the slower the growth rate is, the more likely it is to be scheduled on the left of the red black tree
18 * The value is changed every time the clock is interrupted
19 * For details, see the calc? Delta? Fair() function
20 */
21 u64 vruntime;
22 /* Sum ﹣ exec ﹣ runtime value of the process when switching into CPU */
23 u64 prev_sum_exec_runtime;
24
25 /* The number of processes moved to other CPU groups in this scheduling entity */
26 u64 nr_migrations;
27
28 #ifdef CONFIG_SCHEDSTATS
29 /* For statistics */
30 struct sched_statistics statistics;
31 #endif
32
33 #ifdef CONFIG_FAIR_GROUP_SCHED
34 /* Represents the depth of this process group. Each process group is 1 deeper than its parent scheduling group */
35 int depth;
36 /* Pointer to the parent scheduling entity. If it is a process, it points to the scheduling entity of its running queue. If it is a process group, it points to the scheduling entity of the previous process group
37 * Set in the set task RQ function
38 */
39 struct sched_entity *parent;
40 /* Red black tree running queue of entity */
41 struct cfs_rq *cfs_rq;
42 /* The red black tree running queue of entity. If it is NULL, it indicates that it is a process. If it is not NULL, it indicates that it is a scheduling group */
43 struct cfs_rq *my_q;
44 #endif
45
46 #ifdef CONFIG_SMP
47 /* Per-entity load-tracking */
48 struct sched_avg avg;
49 #endif
50 };
In fact, red black tree is based on struct RB node, but struct RB node and struct sched entity are one-to-one correspondence, or a red black tree node is a scheduling entity. It can be seen that the struct sched entity structure contains all the data scheduled by a process (or process group), which is included in the se of struct task struct structure, as follows:
1 struct task_struct {
2 ........
3 /* Indicates whether the queue is running */
4 int on_rq;
5
6 /* Process priority
7 * prio: Dynamic priority, ranging from 100 to 139, related to static priority and compensation (bonus)
8 * static_prio: Static priority, static_prio = 100 + nice + 20 (nice value is - 20 ~ 19, so static_prio value is 100 ~ 139)
9 * normal_prio: There is no normal priority that is affected by priority inheritance. For details, please refer to the normal prio function, which is related to the type of process
10 */
11 int prio, static_prio, normal_prio;
12 /* Real time process priority */
13 unsigned int rt_priority;
14 /* Scheduling class, scheduling processing function class */
15 const struct sched_class *sched_class;
16 /* Scheduling entity (a node of red black tree) */
17 struct sched_entity se;
18 /* Scheduling entity (used for real-time scheduling) */
19 struct sched_rt_entity rt;
20 #ifdef CONFIG_CGROUP_SCHED
21 /* Point to the process group it is in */
22 struct task_group *sched_task_group;
23 #endif
24 ........
25 }
In the struct sched'entity structure, the members that we should pay attention to are:
- load: weight, converted from priority, is the key to vruntime calculation.
- On \\\\\\\\\\\\\\\. For a simple example, when a normal program is running, it is not in the red black tree, but it is still in the CFS running queue, and its on ﹐ RQ is true. Only processes that are ready to quit, are about to sleep and wait, and are turned into real-time processes have their CFS run queue on ﹣ RQ false.
- Vruntime: virtual running time, the key of scheduling, its calculation formula: virtual running time of a scheduling interval = actual running time * (nice__load / weight). It can be seen that it is related to the actual running time and weight. The red black tree is based on this as the sorting standard. The higher the priority, the slower the vruntime of the process will grow, the longer its running time will be, and the more likely it is to be in the leftmost node of the red black tree. The scheduler selects the leftmost node as the next scheduling process every time. Note that the value is monotonically increasing, and the virtual running time of the current process will be accumulated when the clock of each scheduler is interrupted. Simply speaking, the process is the smallest vruntime, and the smallest one will be scheduled.
- cfs_rq: CFS run queue in which this scheduling entity is located.
- My Q: if this scheduling entity represents a process group, then this scheduling entity contains its own CFS operation queue. The CFS operation queue holds the processes in this process group, and these processes will not be included in the red black tree of other CFS operation queues (including the top-level red black tree, which only belongs to this process group).
How to understand that A process group has its own CFS operation queue is A good idea. For example, in the red black tree of the root CFS operation queue, there is A process A and A process group B, each accounting for 50% of the CPU. For the red black tree of the root, they are two scheduling entities. The scheduler schedules either process A or process group B. if it is scheduled to process group B, process group B can choose A program to run by itself and give it to the CPU. How process group B chooses A program to run by its own CFS is to choose the red black tree of the running queue. If process group B has sub process group C, the principle is the same, which is A hierarchy.
In the struct task struct structure, we notice that there is a scheduling class, which contains scheduling processing functions, as follows:
1 struct sched_class {
2 /* Scheduling class of next priority
3 * Priority order of scheduling class: stop ﹐ sched ﹐ class - > DL ﹐ sched ﹐ class - > RT ﹐ sched ﹐ class - > fair ﹐ sched ﹐ class - > idle ﹐ sched ﹐ class
4 */
5 const struct sched_class *next;
6
7 /* Add the process to the running queue, i.e. put the scheduling entity (process) into the red black tree, and add 1 to the NR UU running variable */
8 void (*enqueue_task) (struct rq *rq, struct task_struct *p, int flags);
9 /* Remove the process from the run queue, and subtract 1 from the NR UU running variable */
10 void (*dequeue_task) (struct rq *rq, struct task_struct *p, int flags);
11 /* Discard the CPU. When compat ﹣ yield sysctl is turned off, the function actually performs first out and then enters the queue. In this case, it places the scheduling entity at the far right end of the red black tree */
12 void (*yield_task) (struct rq *rq);
13 bool (*yield_to_task) (struct rq *rq, struct task_struct *p, bool preempt);
14
15 /* Check whether the current process can be preempted by the new process */
16 void (*check_preempt_curr) (struct rq *rq, struct task_struct *p, int flags);
17
18 /*
19 * It is the responsibility of the pick_next_task() method that will
20 * return the next task to call put_prev_task() on the @prev task or
21 * something equivalent.
22 *
23 * May return RETRY_TASK when it finds a higher prio class has runnable
24 * tasks.
25 */
26 /* Select the next process to run */
27 struct task_struct * (*pick_next_task) (struct rq *rq,
28 struct task_struct *prev);
29 /* Put the process back on the run queue */
30 void (*put_prev_task) (struct rq *rq, struct task_struct *p);
31
32 #ifdef CONFIG_SMP
33 /* Choose an appropriate CPU for the process */
34 int (*select_task_rq)(struct task_struct *p, int task_cpu, int sd_flag, int flags);
35 /* Migrate task to another CPU */
36 void (*migrate_task_rq)(struct task_struct *p, int next_cpu);
37 /* Used after context switching */
38 void (*post_schedule) (struct rq *this_rq);
39 /* For process wakeup */
40 void (*task_waking) (struct task_struct *task);
41 void (*task_woken) (struct rq *this_rq, struct task_struct *task);
42 /* Modify the CPU affinity of the process */
43 void (*set_cpus_allowed)(struct task_struct *p,
44 const struct cpumask *newmask);
45 /* Start run queue */
46 void (*rq_online)(struct rq *rq);
47 /* Disable running queue */
48 void (*rq_offline)(struct rq *rq);
49 #endif
50 /* Called when a process changes its scheduling class or process group */
51 void (*set_curr_task) (struct rq *rq);
52 /* This function is usually called from the time tick function; it can cause process switching. This will drive runtime preemption */
53 void (*task_tick) (struct rq *rq, struct task_struct *p, int queued);
54 /* Called when the process is created, the process initialization of different scheduling policies is different */
55 void (*task_fork) (struct task_struct *p);
56 /* Used when the process exits */
57 void (*task_dead) (struct task_struct *p);
58
59 /* For process switching */
60 void (*switched_from) (struct rq *this_rq, struct task_struct *task);
61 void (*switched_to) (struct rq *this_rq, struct task_struct *task);
62 /* Change priority */
63 void (*prio_changed) (struct rq *this_rq, struct task_struct *task,
64 int oldprio);
65
66 unsigned int (*get_rr_interval) (struct rq *rq,
67 struct task_struct *task);
68
69 void (*update_curr) (struct rq *rq);
70
71 #ifdef CONFIG_FAIR_GROUP_SCHED
72 void (*task_move_group) (struct task_struct *p, int on_rq);
73 #endif
74 };What's the use of this scheduling class? Actually, different scheduling algorithms in the kernel have different operations. In order to modify and replace the scheduling algorithm conveniently, each scheduling algorithm only needs to implement its own scheduling class. CFS algorithm has its own scheduling class, SCHED_FIFO also has its own scheduling class. When a process is created, what kind of scheduling is used The task structure > sched class of the algorithm points to its corresponding scheduling class. Each time the scheduler schedules, it will operate through the scheduling function process of the current process, which greatly improves the portability and modifiability.
CFS run queue (struct cfs_rq)
We now know that there is at least one CFS running queue in the system, which is the root CFS running queue, while other process groups and processes are included in this running queue. The difference is that the process group has its own CFS running queue, and its running queue contains all processes in this process group. When the scheduler selects a process group from the root CFS operation queue for scheduling, the process group will select a scheduling entity from its own CFS operation queue for scheduling (the scheduling entity may be a process or a sub process group), so it goes deep until the last process is selected for running.
There is no good explanation for struct CFS ﹣ RQ structure, as long as it represents a CFS operation queue and contains a red black tree to select the scheduling process.
1 /* CFS The rq of each CPU will contain a CFS rq, and the sched entity of each group will also have its own CFS rq queue */
2 struct cfs_rq {
3 /* CFS Total load of all processes in the run queue */
4 struct load_weight load;
5 /*
6 * nr_running: cfs_rq Number of scheduling entities
7 * h_nr_running: It is only valid for process groups. The sum of NR ﹣ running of CFS ﹣ RQ in all process groups under it
8 */
9 unsigned int nr_running, h_nr_running;
10
11 u64 exec_clock;
12 /* Minimum running time on current CFS queue, monotonically increasing
13 * Update the value in two cases:
14 * 1,When updating the cumulative run time of the current running task
15 * 2,When a task is deleted from the queue, such as task sleep or exit, it will be checked whether the vruntime of the remaining tasks is greater than min? Vruntime. If so, the value will be updated.
16 */
17 u64 min_vruntime;
18 #ifndef CONFIG_64BIT
19 u64 min_vruntime_copy;
20 #endif
21 /* The root of the red black tree */
22 struct rb_root tasks_timeline;
23 /* Next scheduling node (the leftmost node of the red black tree, and the leftmost node is the next scheduling entity) */
24 struct rb_node *rb_leftmost;
25
26 /*
27 * 'curr' points to currently running entity on this cfs_rq.
28 * It is set to NULL otherwise (i.e when none are currently running).
29 */
30 /*
31 * curr: Currently running sched ﹣ entity (for a group, although it will not run on the cpu, when there is a task running on the cpu at its lower level, its CFS ﹣ RQ will regard it as the currently running sched ﹣ entity on the CFS ﹣ RQ)
32 * next: Indicates that some processes are in urgent need of running, even if they do not comply with CFS scheduling, they must run it. When scheduling, it will check whether next needs to be scheduled. If so, next will be scheduled
33 *
34 * skip: Skip process (the process schedule specified by skip will not be selected)
35 */
36 struct sched_entity *curr, *next, *last, *skip;
37
38 #ifdef CONFIG_SCHED_DEBUG
39 unsigned int nr_spread_over;
40 #endif
41
42 #ifdef CONFIG_SMP
43 /*
44 * CFS Load tracking
45 * Under CFS, load is tracked on a per-entity basis and aggregated up.
46 * This allows for the description of both thread and group usage (in
47 * the FAIR_GROUP_SCHED case).
48 */
49 unsigned long runnable_load_avg, blocked_load_avg;
50 atomic64_t decay_counter;
51 u64 last_decay;
52 atomic_long_t removed_load;
53
54 #ifdef CONFIG_FAIR_GROUP_SCHED
55 /* Required to track per-cpu representation of a task_group */
56 u32 tg_runnable_contrib;
57 unsigned long tg_load_contrib;
58
59 /*
60 * h_load = weight * f(tg)
61 *
62 * Where f(tg) is the recursive weight fraction assigned to
63 * this group.
64 */
65 unsigned long h_load;
66 u64 last_h_load_update;
67 struct sched_entity *h_load_next;
68 #endif /* CONFIG_FAIR_GROUP_SCHED */
69 #endif /* CONFIG_SMP */
70
71 #ifdef CONFIG_FAIR_GROUP_SCHED
72 /* CPU rq of */
73 struct rq *rq; /* cpu runqueue to which this cfs_rq is attached */
74
75 /*
76 * leaf cfs_rqs are those that hold tasks (lowest schedulable entity in
77 * a hierarchy). Non-leaf lrqs hold other higher schedulable entities
78 * (like users, containers etc.)
79 *
80 * leaf_cfs_rq_list ties together list of leaf cfs_rq's in a cpu. This
81 * list is used during load balance.
82 */
83 int on_list;
84 struct list_head leaf_cfs_rq_list;
85 /* Process group that owns the CFS run queue */
86 struct task_group *tg; /* group that "owns" this runqueue */
87
88 #ifdef CONFIG_CFS_BANDWIDTH
89 int runtime_enabled;
90 u64 runtime_expires;
91 s64 runtime_remaining;
92
93 u64 throttled_clock, throttled_clock_task;
94 u64 throttled_clock_task_time;
95 int throttled, throttle_count;
96 struct list_head throttled_list;
97 #endif /* CONFIG_CFS_BANDWIDTH */
98 #endif /* CONFIG_FAIR_GROUP_SCHED */
99 };- Load: it stores the sum of the weights of all processes in the process group. Note that the load of the process group is used by the sub process when calculating vruntime.
CPU run queue (struct rq)
Each CPU has its own struct rq structure, which is used to describe all processes running on this CPU. It includes a real-time process queue and a root CFS run queue. When scheduling, the scheduler will first go to the real-time process queue to find out whether there is a real-time process to run. If not, it will go to the CFS run queue to find out whether there is a real-time process to run It is often said that the priority of real-time process is higher than that of ordinary process, not only reflected in the prio priority, but also reflected in the design of the scheduler. As for the dl operation queue, I don't know what's the use for the time being. Its priority is higher than that of real-time process, but if the dl process is created, it will be wrong (see sys_fork for details).
1 /* CPU Run queue, each CPU contains a struct rq */
2 struct rq {
3 /* The sum of the load s of all ready processes in the running queue */
4 raw_spinlock_t lock;
5
6 /*
7 * nr_running and cpu_load should be in the same cacheline because
8 * remote CPUs use both these fields when doing load calculation.
9 */
10 /* The total number of ready processes on this CPU, including cfs, rt, and running */
11 unsigned int nr_running;
12 #ifdef CONFIG_NUMA_BALANCING
13 unsigned int nr_numa_running;
14 unsigned int nr_preferred_running;
15 #endif
16 #define CPU_LOAD_IDX_MAX 5
17 /* According to the load calculated according to the historical situation of CPU, CPU load [0] is always equal to load.weight. When load balance is reached, both CPU load [1] and CPU load [2] should be equal to load.weight */
18 unsigned long cpu_load[CPU_LOAD_IDX_MAX];
19 /* Time of last CPU load update */
20 unsigned long last_load_update_tick;
21 #ifdef CONFIG_NO_HZ_COMMON
22 u64 nohz_stamp;
23 unsigned long nohz_flags;
24 #endif
25 #ifdef CONFIG_NO_HZ_FULL
26 unsigned long last_sched_tick;
27 #endif
28 /* Need to update run time of rq */
29 int skip_clock_update;
30
31 /* capture load from *all* tasks on this cpu: */
32 /* CPU load, the sum of the loads of all the runnable processes on the CPU. This value must also be updated when NR < running is updated */
33 struct load_weight load;
34 unsigned long nr_load_updates;
35 /* The number of context switches. Only proc will use this */
36 u64 nr_switches;
37
38 /* cfs Scheduling run queue with root of red black tree */
39 struct cfs_rq cfs;
40 /* Real time scheduling operation queue */
41 struct rt_rq rt;
42 struct dl_rq dl;
43
44 #ifdef CONFIG_FAIR_GROUP_SCHED
45 /* list of leaf cfs_rq on this cpu: */
46 struct list_head leaf_cfs_rq_list;
47
48 struct sched_avg avg;
49 #endif /* CONFIG_FAIR_GROUP_SCHED */
50
51 /*
52 * This is part of a global counter where only the total sum
53 * over all CPUs matters. A task can increase this counter on
54 * one CPU and if it got migrated afterwards it may decrease
55 * it on another CPU. Always updated under the runqueue lock:
56 */
57 /* The number of processes that were in the queue but are now in the task? Unique state */
58 unsigned long nr_uninterruptible;
59
60 /*
61 * curr: Processes currently running on this CPU
62 * idle: The pointer of idle process on the current CPU. Idle process is used to call when the CPU has nothing to do. It does not execute anything
63 */
64 struct task_struct *curr, *idle, *stop;
65 /* Next load balancing execution time */
66 unsigned long next_balance;
67 /* Memory descriptor address used to store the swap out process during process switching */
68 struct mm_struct *prev_mm;
69
70 /* rq Running time */
71 u64 clock;
72 u64 clock_task;
73
74 atomic_t nr_iowait;
75
76 #ifdef CONFIG_SMP
77 struct root_domain *rd;
78 /* The current CPU is located in the basic scheduling domain. Each scheduling domain contains one or more CPU groups. Each CPU group contains one or more CPU subsets in the scheduling domain. Load balancing is done between groups in the scheduling domain. Cross domain load balancing is not allowed */
79 struct sched_domain *sd;
80
81 unsigned long cpu_capacity;
82
83 unsigned char idle_balance;
84 /* For active balancing */
85 int post_schedule;
86 /* If you need to migrate a process to another run queue, you need to set this bit */
87 int active_balance;
88 int push_cpu;
89 struct cpu_stop_work active_balance_work;
90
91 /* CPU to which the run queue belongs */
92 int cpu;
93 int online;
94
95 struct list_head cfs_tasks;
96
97 u64 rt_avg;
98 /* Lifetime of this run queue */
99 u64 age_stamp;
100 u64 idle_stamp;
101 u64 avg_idle;
102
103 /* This is used to determine avg_idle's max value */
104 u64 max_idle_balance_cost;
105 #endif
106
107 #ifdef CONFIG_IRQ_TIME_ACCOUNTING
108 u64 prev_irq_time;
109 #endif
110 #ifdef CONFIG_PARAVIRT
111 u64 prev_steal_time;
112 #endif
113 #ifdef CONFIG_PARAVIRT_TIME_ACCOUNTING
114 u64 prev_steal_time_rq;
115 #endif
116
117 /* calc_load related fields */
118 /* For load balancing */
119 unsigned long calc_load_update;
120 long calc_load_active;
121
122 #ifdef CONFIG_SCHED_HRTICK
123 #ifdef CONFIG_SMP
124 int hrtick_csd_pending;
125 struct call_single_data hrtick_csd;
126 #endif
127 /* High precision timer for scheduling */
128 struct hrtimer hrtick_timer;
129 #endif
130
131 #ifdef CONFIG_SCHEDSTATS
132 /* latency stats */
133 struct sched_info rq_sched_info;
134 unsigned long long rq_cpu_time;
135 /* could above be rq->cfs_rq.exec_clock + rq->rt_rq.rt_runtime ? */
136
137 /* sys_sched_yield() stats */
138 unsigned int yld_count;
139
140 /* schedule() stats */
141 unsigned int sched_count;
142 unsigned int sched_goidle;
143
144 /* try_to_wake_up() stats */
145 unsigned int ttwu_count;
146 unsigned int ttwu_local;
147 #endif
148
149 #ifdef CONFIG_SMP
150 struct llist_head wake_list;
151 #endif
152
153 #ifdef CONFIG_CPU_IDLE
154 /* Must be inspected within a rcu lock section */
155 struct cpuidle_state *idle_state;
156 #endif
157 };
summary
The key data structure is also introduced almost. Later chapters will explain how the kernel scheduler is implemented in detail from the code.

