[source code analysis] PyTorch distributed Autograd (3) -- context sensitive
catalogue
- [source code analysis] PyTorch distributed Autograd (3) -- context sensitive
0x00 summary
We already know how dist.autograd sends and receives messages. This article will look at other supporting parts, that is, how to coordinate the sending and receiving actions, how to determine each sending / receiving node, and how to determine each message interaction Session.
Through this article, you can understand that AutogradMetadata is used to transfer autograd meta information between different nodes. DistAutogradContext represents a distributed autograd related information. DistAutogradContainer is responsible for storing DistAutogradContext on a worker.
0x01 design context
1.1 previous review
In the previous article, when sending a message, we obtained forward through getMessageWithAutograd in sendMessageWithAutograd_ AUTOGRAD_ Message of type req.
c10::intrusive_ptr<JitFuture> sendMessageWithAutograd(
RpcAgent& agent,
const WorkerInfo& dst,
torch::distributed::rpc::Message&& wrappedRpcMsg,
bool forceGradRecording,
const float rpcTimeoutSeconds,
bool forceDisableProfiling) {
auto msg = getMessageWithAutograd( // Here, we will interact with the context and build FORWARD_AUTOGRAD_REQ
dst.id_,
std::move(wrappedRpcMsg),
MessageType::FORWARD_AUTOGRAD_REQ,
forceGradRecording,
agent.getDeviceMap(dst));
c10::intrusive_ptr<JitFuture> fut;
if (!forceDisableProfiling && torch::autograd::profiler::profilerEnabled()) {
auto profilerConfig = torch::autograd::profiler::getProfilerConfig();
auto msgWithProfiling = getMessageWithProfiling(
std::move(msg),
rpc::MessageType::RUN_WITH_PROFILING_REQ, //Build message
std::move(profilerConfig));
// send message
fut = agent.send(dst, std::move(msgWithProfiling), rpcTimeoutSeconds);
} else {
// send message
fut = agent.send(dst, std::move(msg), rpcTimeoutSeconds);
}
return fut;
}getMessageWithAutograd interacts with the context, and its code is located in torch / CSR / distributed / autograd / utils.cpp.
Message getMessageWithAutograd(
const rpc::worker_id_t dstId,
torch::distributed::rpc::Message&& wrappedRpcMsg,
MessageType msgType,
bool forceGradRecording,
const std::unordered_map<c10::Device, c10::Device>& deviceMap) {
// Get DistAutogradContainer
auto& autogradContainer = DistAutogradContainer::getInstance();
// If there is no valid context and no tensor requires grads, send original
// rpc message. otherwise, attach grad info and grad functions and send
// rpcWithAutograd message.
auto tensorsRequireGrad =
torch::autograd::compute_requires_grad(wrappedRpcMsg.tensors());
if (!autogradContainer.hasValidContext() ||
(!forceGradRecording && !tensorsRequireGrad)) {
return std::move(wrappedRpcMsg);
}
// Retrieve the appropriate context to modify.
auto autogradContext = autogradContainer.currentContext(); // Get the context. Each worker has its own context
// Wrap the original rpc with autograd information.
// newAutogradMessageId generates a messageID
AutogradMetadata autogradMetadata( // Built AutogradMetadata
autogradContext->contextId(), autogradContainer.newAutogradMessageId());
auto rpcWithAutograd = std::make_unique<RpcWithAutograd>(
RpcAgent::getCurrentRpcAgent()->getWorkerInfo().id_,
msgType,
autogradMetadata,
std::move(wrappedRpcMsg),
deviceMap);
if (tensorsRequireGrad) {
// Record autograd information for 'send'.
addSendRpcBackward( // Here, the local context and the meta information of autograd are packaged together
autogradContext, autogradMetadata, rpcWithAutograd->tensors());
}
// Record the workerID
autogradContext->addKnownWorkerId(dstId);
return std::move(*rpcWithAutograd).toMessage(); // Finally, a message is built
}Therefore, a series of basic classes such as AutogradMetadata, DistAutogradContainer and DistAutogradContext are introduced. Let's analyze them carefully next.
1.2 general idea
Let's summarize the general idea.
Let's look at the problem first: if a system includes three nodes a, b and c, and each node runs a worker, then when running a propagation operation, we involve propagating among these three nodes. Therefore, we need a mechanism to uniquely mark the propagation process among the three nodes. In the propagation process, we also need to mark each send/recv on each node, so that the node can support multiple parallel operations.
Look at the solution:
- Use context to uniquely identify a propagation process. DistAutogradContext stores the relevant information of each distributed autograd on a worker. It encapsulates forward and backward propagation and accumulates gradients in the distributed autograd, which avoids the mutual influence of multiple workers on each other's gradients. Each automatic differential process is given a unique autograd_context_id, in the container, the context of the differential process (DistAutogradContext) is based on the autograd_context_id to uniquely confirm.
- Use autogradMessageId to represent a pair of send/recv autograd functions. Each send recv pair is assigned a globally unique autograd_message_id to uniquely identify the send recv pair. This is useful for finding the corresponding function on the remote node during backward propagation.
- Finally, each worker needs a place to keep the context and messageid, so there is the DistAutogradContainer class. Each worker has a unique singleton DistAutogradContainer, which is responsible for:
- For each automatic differential procedure, its distributed context is stored.
- Once the automatic differentiation process is completed, its data is cleared.
Thus, during forward propagation, python stores the send and recv functions for each autograd propagation in the context. This ensures that we save references to the appropriate nodes in the autograd diagram to keep them active. In addition, this makes it easy to find the corresponding send and recv functions during backward propagation.
0x02 AutogradMetadata
2.1 definitions
The AutogradMetadata class is used to transfer the meta information of autograd between different nodes, that is, encapsulate the context and other information. That is, the sender notifies the receiver of its own context information, and the receiver will process it accordingly according to the received context information.
We spoiled in advance. The receiver will use autogradContextId and autogradMessageId as the unique identifier of the context and message respectively. You can know from the notes.
- autogradContextId is a globally unique integer used to represent a unique distributed autograd propagation process (including forward propagation and backward propagation). A propagation process includes multiple pairs of send/recv autograd functions on the back propagation chain.
- autogradMessageId is a globally unique integer used to represent a pair of send/recv autograd functions. Each send recv pair is assigned a globally unique autograd_message_id to uniquely identify the send recv pair. This is useful for finding the corresponding function on the remote node during backward propagation.
// This structure represents autograd metadata that we need to pass across
// different nodes when we call an RPC which needs autograd computation.
struct TORCH_API AutogradMetadata {
AutogradMetadata(int64_t autogradContextId, int64_t autogradMessageId);
// autogradContextId_ is a globally unique integer that identifies a
// particular distributed autograd pass.
int64_t autogradContextId;
// autogradMessageId_ is a globally unique integer that identifies a pair
// of send/recv autograd functions.
int64_t autogradMessageId;
};So the question is, how can autogradContextId and autogradMessageId be globally unique (including multiple nodes)?
2.2 autogradMessageId
Let's summarize: autogradMessageId is generated indirectly by rank, and then incremented internally, so it can ensure global uniqueness.
Let's deduce from back to front.
- Let's first look at how newAutogradMessageId generates the message ID, which is the member variable next in DistAutogradContainer_ autograd_ message_ id_ Incrementally.
int64_t DistAutogradContainer::newAutogradMessageId() {
// Check for overflow into workerId_ section.
TORCH_INTERNAL_ASSERT(next_autograd_message_id_ < max_id_);
return next_autograd_message_id_++;
}- Then see how to initialize next_autograd_message_id_? From the init function of DistAutogradContainer, we can know that it is based on worker_id to generate next_autograd_message_id_. work_id is the parameter obtained by the init function.
DistAutogradContainer& DistAutogradContainer::init(int64_t worker_id) {
std::lock_guard<std::mutex> guard(dist_container_init_lock_);
auto& container = getInstanceInternal();
container.worker_id_ = worker_id;
container.next_context_id_ = static_cast<int64_t>(worker_id)
<< kAutoIncrementBits;
container.next_autograd_message_id_ = static_cast<int64_t>(worker_id)
<< kAutoIncrementBits;
container.max_id_ =
(kAutoIncrementMask |
(static_cast<int64_t>(worker_id) << kAutoIncrementBits));
container.initialized_ = true;
return container;
}- Let's deduce and see how to set the worker id. we found the following. It seems that we need to look at the python world_ init method.
module.def(
"_init",
[](int64_t worker_id) { DistAutogradContainer::init(worker_id); },
py::call_guard<py::gil_scoped_release>());In the python world, you can see that rank is used as a parameter, and rank is unique to each worker, which ensures that the worker ID is unique, so that the message id is unique.
def init_rpc(
name,
backend=None,
rank=-1,
world_size=None,
rpc_backend_options=None,
):
dist_autograd._init(rank) # rank is globally uniqueWe summarize these logical relationships:
worker_id = rank; container.worker_id_ = worker_id; container.next_autograd_message_id_ = static_cast<int64_t>(worker_id) << kAutoIncrementBits
Then next_autograd_message_id_ Internal increment.
int64_t DistAutogradContainer::newAutogradMessageId() {
// Check for overflow into workerId_ section.
TORCH_INTERNAL_ASSERT(next_autograd_message_id_ < max_id_);
return next_autograd_message_id_++;
}Therefore, AutogradMessageId is globally unique. Let's use the legend to see:
+----------------------------------------------------------------------------------------+ | worker | | +-------------------------------------+ | | | DistAutogradContainer | | | | | | | | | | | init() | | | | rank +--------------+----> worker_id_ | | | 1 | | | newAutogradMessageId() | | | +----> next_autograd_message_id_+------------------+ | | | | 2 | | | +-------------------------------------+ | | | | | | | | | | | | | | | +---------------------------------------------------------------+ | | | getMessageWithAutograd | | | | | | | | | | v | | | | | | | | AutogradMetadata autogradMetadata(contextId(), MessageId()) | | | | 4 3 | | | | | | | +---------------------------------------------------------------+ | | | +----------------------------------------------------------------------------------------+
To see why autogradContextId can be guaranteed to be unique, we need to analyze DistAutogradContainer and DistAutogradContext first.
0x03 DistAutogradContainer
Each worker has a unique singleton DistAutogradContainer, which is responsible for:
- For each automatic differential procedure, its distributed context is stored.
- Once the automatic differentiation process is completed, its data is cleared.
Each automatic differential process is given a unique autograd_context_id. In each Container, the Context of the differential process (DistAutogradContext) is based on the autograd_context_id to uniquely confirm. autograd_context_id is a 64 bit globally unique ID, and the first 16 bis are workers_ ID, the last 48 bits are automatically incremented in each worker. Therefore, it can be seen that there are multiple contexts in a Container.
This container is also responsible for maintaining a globally unique message id, which is used to associate send / receive automatic differential function pairs. The format is similar to autograd_context_id is a 64 bit integer. The first 16 bits are the worker id, and the last 48 bits are automatically incremented within the worker.
Because the first 16 bits of message id and context id are worker_id, that is, rank id, plus the internal self increment of the last 48 bits, so the message id and context id can be globally unique.
3.1 definitions
DistAutogradContainer is defined as follows, where:
- worker_id_ : The ID of this worker is actually the rank of this worker.
- next_context_id_ : The self incrementing context id is used to assign a unique autograd to each automatic differential process_ Context_ id. In a propagation chain, only the DistAutogradContainer of the first node actually uses next_context_id_ The DistAutogradContainer of subsequent nodes generates the Context of the corresponding context id locally according to the context id information of the first DistAutogradContainer.
- next_autograd_message_id_ : Maintain a globally unique message ID, which is used to associate the send / receive automatic differential function pair. This variable will be used when the node sends.
// Singleton class per worker which is responsible for storing the distributed
// autograd context for each autograd pass and also cleans up data for an
// autograd pass once its done.
//
// Each autograd pass is assigned a unique autograd_context_id and all data for
// that pass (DistAutogradContext) is stored in this container indexed by the
// autograd_context_id. The autograd_context_id itself is a 64 bit globally
// unique id. The first 16 bits is the worker_id and the next 48 bits is an
// auto-incrementing id for each worker.
//
// This container is also responsible for maintaining a globally unique message
// id, which is used to associate send/recv autograd function pairs. The format
// is similar to the autograd_context_id where we have a 64 bit integer with
// first 16 bits being the worker id and next 48 bits are auto-incrementing.
class TORCH_API DistAutogradContainer {
private:
// Number of shards for the map storing autograd contexts. We'd like this
// to be a power of 2 and we don't expect a value much higher than the
// number of cores would provide much benefit.
static constexpr uint32_t kNumDefaultShards = 128;
// Use cache line size for alignment.
static constexpr int kCacheLineSize = 64;
// Structure holding one shard of the sharded autograd context map with its
// associated lock. Align to cache line size to avoid contention between
// adjacent entries.
struct alignas(kCacheLineSize) ContextsShard {
// Lock for this shard.
mutable std::mutex lock;
// Map storing autograd contexts for this shard.
std::unordered_map<int64_t, ContextPtr> contexts; // The context pointer is stored here
};
// Auto incrementing context id used to identify unique autograd passes.
// Initialized with the first 16 bits being the worker_id.
std::atomic<int64_t> next_context_id_; // New context id
// Unique id to identify a worker in the distributed setting.
int16_t worker_id_;
// Whether or not the container has been initialized appropriately.
bool initialized_;
// Sharded autograd context map.
std::vector<ContextsShard> autograd_contexts_; // Storage context list
// Number of shards for the sharded autograd_contexts_ map.
uint32_t num_shards_;
// Autograd message id to identify unique send/recv autograd function pairs.
std::atomic<int64_t> next_autograd_message_id_;
// Maximum allowed value for autograd_context_id or autograd_message_id.
int64_t max_id_;
};3.2 construction
Init method constructs DistAutogradContainer, mainly using worker_id assigns relevant values to local member variables.
DistAutogradContainer& DistAutogradContainer::init(int64_t worker_id) {
std::lock_guard<std::mutex> guard(dist_container_init_lock_);
TORCH_CHECK(
worker_id >= 0 && worker_id <= kMaxWorkerId,
"worker_id needs to be in the range [0, 65535]")
auto& container = getInstanceInternal();
TORCH_CHECK(
!container.initialized_ || (worker_id == container.worker_id_),
"Container is already initialized with worker_id: ",
container.worker_id_,
", cannot initialize with different worker_id: ",
worker_id);
if (container.initialized_) {
return container;
}
container.worker_id_ = worker_id;
container.next_context_id_ = static_cast<int64_t>(worker_id)
<< kAutoIncrementBits;
container.next_autograd_message_id_ = static_cast<int64_t>(worker_id)
<< kAutoIncrementBits;
container.max_id_ =
(kAutoIncrementMask |
(static_cast<int64_t>(worker_id) << kAutoIncrementBits));
container.initialized_ = true;
return container;
}0x04 DistAutogradContext
DistAutogradContext stores the relevant information of each distributed autograd on a worker. It encapsulates forward and backward propagation and accumulates gradients in the distributed autograd, which avoids the mutual influence of multiple workers on each other's gradients.
As you can see from the front, contextId_ Is globally unique.
4.1 definitions
Here, only the DistAutogradContext member variable is given, and its member function is ignored. There are three main member variables:
- contextId_ Is the context id.
- sendAutogradFunctions_ Is a map type variable, which will collect the backpropagation operator SendRpcBackward corresponding to all send requests.
- recvAutogradFunctions_ It is a map type variable, which will collect the back propagation operator RecvRpcBackward corresponding to all incoming requests.
We will analyze SendRpcBackward and RecvRpcBackward in combination with the engine later.
// DistAutogradContext which stores information for a single distributed
// autograd pass on a worker.
class TORCH_API DistAutogradContext {
private:
friend class BackwardPassCleanupGuard;
friend class DistEngine;
friend class RecvRpcBackward;
friend class DistAccumulateGradCaptureHook;
const int64_t contextId_;
// Set containing known worker IDs, used in cleaning up autograd context.
// Whenever a sendRpcBackward is attached to the autograd graph for this
// context, the destination is added here.
std::unordered_set<rpc::worker_id_t> knownWorkerIds_;
// Map from autograd_message_id to appropriate 'send' autograd function.
std::unordered_map<int64_t, std::shared_ptr<SendRpcBackward>>
sendAutogradFunctions_;
// Map from autograd_message_id to appropriate 'recv' autograd function.
std::unordered_map<int64_t, std::shared_ptr<RecvRpcBackward>>
recvAutogradFunctions_;
// Gradients accumulated in this context so far. The key is the variable on
// which the gradient needs to be accumulated and the value is the gradient
// that needs to be accumulated on that variable..
c10::Dict<torch::Tensor, torch::Tensor> accumulatedGrads_;
// See comments for recordGradEvent(c10::Device device);
std::unordered_map<c10::Device, c10::Event> gradReadyEvents_;
const c10::impl::VirtualGuardImpl impl_;
// The autograd GraphTask for the backward pass on this node for this context.
std::shared_ptr<torch::autograd::GraphTask> graphTask_;
// List of futures for RPCs initiated by this node to propagate gradients to
// other nodes. The distributed autograd engine on this node can return
// successfully only if all these futures are done and are successful.
std::vector<c10::intrusive_ptr<rpc::JitFuture>> outStandingRpcs_;
// Lock to protect concurrent modification of the context.
mutable std::mutex lock_;
};4.2 messages
Context mainly includes several message types, such as:
// Messages with autograd info FORWARD_AUTOGRAD_REQ = 0x0f | MessageTypeFlags::REQUEST_TYPE, FORWARD_AUTOGRAD_RESP = 0x10 | MessageTypeFlags::RESPONSE_TYPE, // Messages to propagate gradients on the backward pass. BACKWARD_AUTOGRAD_REQ = 0x11 | MessageTypeFlags::REQUEST_TYPE, BACKWARD_AUTOGRAD_RESP = 0x12 | MessageTypeFlags::RESPONSE_TYPE,
4.3 construction
Let's first look at how to build context.
4.3.1 getOrCreateContext
The getOrCreateContext function is used to obtain the context. If it already exists, it will be obtained directly. If not, it will be newly built. This is a passive call, which will be used by the recv end.
ContextPtr DistAutogradContainer::getOrCreateContext(int64_t context_id) {
auto& shard = getShard(context_id);
std::lock_guard<std::mutex> guard(shard.lock);
auto it = shard.contexts.find(context_id); // Search according to the context id
if (it != shard.contexts.end()) {
return it->second; // Return when found
}
auto& context = // If not, build a context
shard.contexts
.emplace(
std::piecewise_construct,
std::forward_as_tuple(context_id),
std::forward_as_tuple(
std::make_shared<DistAutogradContext>(context_id)))
.first->second;
return context;
}4.3.2 newContext
This is an active call. The send side will call this method.
4.3.2.1 Python
When a distributed call is made, the python world generates a context.
with dist_autograd.context() as context_id:
output = model(indices, offsets)
loss = criterion(output, target)
# Run distributed backward pass
dist_autograd.backward(context_id, [loss])
# Run distributed optimizer. Gradients propagated all the way to the parameter servers
opt.step(context_id)When generated__ enter__ Will call_ new_context() generates a context in C + +.
class context(object):
'''
Context object to wrap forward and backward passes when using
distributed autograd. The ``context_id`` generated in the ``with``
statement is required to uniquely identify a distributed backward pass
on all workers. Each worker stores metadata associated with this
``context_id``, which is required to correctly execute a distributed
autograd pass.
Example::
>>> import torch.distributed.autograd as dist_autograd
>>> with dist_autograd.context() as context_id:
>>> t1 = torch.rand((3, 3), requires_grad=True)
>>> t2 = torch.rand((3, 3), requires_grad=True)
>>> loss = rpc.rpc_sync("worker1", torch.add, args=(t1, t2)).sum()
>>> dist_autograd.backward(context_id, [loss])
'''
def __enter__(self):
self.autograd_context = _new_context() # A context is generated here
return self.autograd_context._context_id()
def __exit__(self, type, value, traceback):
_release_context(self.autograd_context._context_id())Through the following mapping, we can see that the corresponding methods in the C + + world call DistAutogradContainer::getInstance().newContext().
module.def(
"_new_context",
[]() -> const ContextPtr {
return DistAutogradContainer::getInstance().newContext();
},
py::return_value_policy::reference);4.3.2.2 C++
We came to the C + + world. Each thread has an autograd_context_id.
constexpr int64_t kInvalidContextId = -1; // Each thread has a single autograd_context_id valid at any point in time. static thread_local int64_t current_context_id_ = kInvalidContextId;
newContext generates a DistAutogradContext through the member variable next of the Container_ context_ id_ To specify the ID of the next context.
const ContextPtr DistAutogradContainer::newContext() {
auto context_id = next_context_id_++; // Increasing
current_context_id_ = context_id; // The current of the local thread is set here_ context_ id_
// Check for overflow into workerId_ section.
TORCH_INTERNAL_ASSERT(context_id < max_id_);
auto& shard = getShard(context_id);
std::lock_guard<std::mutex> guard(shard.lock);
auto& context =
shard.contexts
.emplace(
std::piecewise_construct,
std::forward_as_tuple(context_id),
std::forward_as_tuple(
std::make_shared<DistAutogradContext>(context_id)))
.first->second;
return context;
}4.4 how to share context
In specific use, the context generated in the with statement_ ID can be used to uniquely identify a distributed backward propagation (including forward propagation and backward propagation) on all workers. Each worker stores this context_id, which is necessary to correctly perform the distributed automatic loading process.
Because this context needs to be stored in multiple workers_ ID is associated with metadata, so a encapsulation / send / accept mechanism is needed to transfer this metadata between workers. The encapsulation mechanism is the AutogradMetadata we mentioned earlier. Let's look at how to send / receive context meta information.
4.4.1 sender
When sending a message, getMessageWithAutograd will use autogradContainer.currentContext() to get the current context and send it.
Message getMessageWithAutograd(
const rpc::worker_id_t dstId,
torch::distributed::rpc::Message&& wrappedRpcMsg,
MessageType msgType,
bool forceGradRecording,
const std::unordered_map<c10::Device, c10::Device>& deviceMap) {
auto& autogradContainer = DistAutogradContainer::getInstance();
// If there is no valid context and no tensor requires grads, send original
// rpc message. otherwise, attach grad info and grad functions and send
// rpcWithAutograd message.
auto tensorsRequireGrad =
torch::autograd::compute_requires_grad(wrappedRpcMsg.tensors());
if (!autogradContainer.hasValidContext() ||
(!forceGradRecording && !tensorsRequireGrad)) {
return std::move(wrappedRpcMsg);
}
// Retrieve the appropriate context to modify.
auto autogradContext = autogradContainer.currentContext(); // Gets the current context
// Wrap the original rpc with autograd information.
AutogradMetadata autogradMetadata( // Use context id and message id to construct metadata
autogradContext->contextId(), autogradContainer.newAutogradMessageId());
auto rpcWithAutograd = std::make_unique<RpcWithAutograd>(
RpcAgent::getCurrentRpcAgent()->getWorkerInfo().id_,
msgType,
autogradMetadata,
std::move(wrappedRpcMsg),
deviceMap);
if (tensorsRequireGrad) {
// Record autograd information for 'send'.
addSendRpcBackward(
autogradContext, autogradMetadata, rpcWithAutograd->tensors());
}
// Record the workerID
autogradContext->addKnownWorkerId(dstId);
return std::move(*rpcWithAutograd).toMessage();
}Our previous diagram can now be expanded by adding context ID.
+----------------------------------------------------------------------------------------+ | worker | | +------------------------------------------+ | | |DistAutogradContainer | | | init() | | | | rank +-------------+----> worker_id_ | | | | | | | | | +----> next_context_id_+-------------+ | | | | | | | | | | +----> next_autograd_message_id_ +----------------------+ | | | | | | | | | | | | | | +------------------------------------------+ | | | | | | | | | | | | | | | +------------------------------------------------------------------+ | | |getMessageWithAutograd | | | | | | | | | | | | v v | | | | | | | | AutogradMetadata autogradMetadata(contextId(), MessageId()) | | | | | | | | | | | +------------------------------------------------------------------+ | | | +----------------------------------------------------------------------------------------+
addSendRpcBackward is passed into the current context. In subsequent backpropagation, this addSendRpcBackward will be taken out.
void addSendRpcBackward(
const ContextPtr& autogradContext,
const AutogradMetadata& autogradMetadata,
std::vector<torch::Tensor>& tensors) {
// Attach autograd information only for tensors requiring grad.
std::vector<torch::Tensor> tensors_with_grad;
std::copy_if(
tensors.begin(),
tensors.end(),
std::back_inserter(tensors_with_grad),
[](const torch::Tensor& t) { return t.requires_grad(); });
// Attach the appropriate autograd edges.
auto grad_fn = std::make_shared<SendRpcBackward>();
grad_fn->set_next_edges(
torch::autograd::collect_next_edges(tensors_with_grad));
// Add the appropriate input metadata for the grad_fn.
for (const auto& tensor : tensors_with_grad) {
grad_fn->add_input_metadata(tensor);
}
// Record the send autograd function in our current context.
autogradContext->addSendFunction(grad_fn, autogradMetadata.autogradMessageId);
}4.4.2 recipient
In addRecvRpcBackward, a context will be built according to the passed autogradMetadata.autogradContextId.
ContextPtr addRecvRpcBackward(
const AutogradMetadata& autogradMetadata,
std::vector<torch::Tensor>& tensors,
rpc::worker_id_t fromWorkerId,
const std::unordered_map<c10::Device, c10::Device>& deviceMap) {
// Initialize autograd context if necessary.
auto& autogradContainer = DistAutogradContainer::getInstance();
// Generate or get a context and pass in the sender's autogradContextId, that is, use autogradContextId as the key to find the context later
auto autogradContext =
autogradContainer.getOrCreateContext(autogradMetadata.autogradContextId);
if (!tensors.empty() && torch::autograd::compute_requires_grad(tensors)) {
// Attach the tensors as inputs to the autograd function.
auto grad_fn = std::make_shared<RecvRpcBackward>(
autogradMetadata, autogradContext, fromWorkerId, deviceMap);
for (auto& tensor : tensors) {
if (tensor.requires_grad()) {
torch::autograd::set_history(tensor, grad_fn);
}
}
// Now update the autograd context with the necessary information.
autogradContext->addRecvFunction(
grad_fn, autogradMetadata.autogradMessageId);
}
return autogradContext;
}In this way, the sender and receiver share a context, and the id of this context is globally unique.
The specific logic is as follows: the sender is above and the receiver is below.
- Sender
- Using local context_id constructs AutogradMetadata, which contains ctx_id, msg_id.
- Message is built with AutogradMetadata.
- Sent a Message using agent.send.
- Receiving end:
- Received Message.
- Parse AutogradMetadata from Message.
- Extract context from AutogradMetadata_ id.
- Using context_id builds the local DistAutogradContext.
- The sender and receiver share a context (the id of this context is globally unique).
+----------------------------------------------------------------------------------+
| sendMessageWithAutograd |
| |
| +----------------------------------------------------------------------------+ |
| | addSendRpcBackward | |
| | | |
| | | |
| | autogradMetadata = AutogradMetadata(context_id, message_id) | |
| | + | |
| | | | |
| +----------------------------------------------------------------------------+ |
| | |
| v |
| agent.send(message(autogradMetadata) |
| + |
| | |
+----------------------------------------------------------------------------------+
|
|
|
| Sender
+-----------------------------------------------------------------------------------+
| Receiver
| message
v
|
+----------------------------------------------------------------------------------+
| processForwardAutogradReq | |
| | |
| | message.autogradMetadata |
| v |
| +----------------------------------------------------------------------------+ |
| | addSendRpcBackward | | |
| | | | |
| | +--------------------+ | |
| | | | |
| | v | |
| | autogradContext = getOrCreateContext(autogradMetadata.autogradContextId) | |
| | | |
| | | |
| +----------------------------------------------------------------------------+ |
| |
+----------------------------------------------------------------------------------+0x05 forward propagation interaction process
The previous sharing process is still brief. Let's analyze the complete sending / receiving process in detail.
5.1 sending
This corresponds to the following text in the design:
During forward propagation, we store the send and recv functions for each autograd propagation in the context. This ensures that we save references to the appropriate nodes in the autograd diagram to keep them active. In addition, this makes it easy to find the corresponding send and recv functions during backward propagation.
5.1.1 sending logic
The code logic is as follows:
- Generate a grad_fn, whose type is SendRpcBackward.
- Call collect_next_edges and set_next_edges adds subsequent edges to SendRpcBackward. These functions are analyzed in the previous series.
- Call add_input_metadata adds input metadata.
- Call addSendFunction to add grad to the context_ fn.
void addSendRpcBackward(
const ContextPtr& autogradContext,
const AutogradMetadata& autogradMetadata,
std::vector<torch::Tensor>& tensors) {
// Attach autograd information only for tensors requiring grad.
std::vector<torch::Tensor> tensors_with_grad;
std::copy_if(
tensors.begin(),
tensors.end(),
std::back_inserter(tensors_with_grad),
[](const torch::Tensor& t) { return t.requires_grad(); });
// Attach the appropriate autograd edges.
auto grad_fn = std::make_shared<SendRpcBackward>();
grad_fn->set_next_edges( // Its output edge is set here
torch::autograd::collect_next_edges(tensors_with_grad));
// Add the appropriate input metadata for the grad_fn.
for (const auto& tensor : tensors_with_grad) {
grad_fn->add_input_metadata(tensor);
}
// Record the send autograd function in our current context.
autogradContext->addSendFunction(grad_fn, autogradMetadata.autogradMessageId);
}5.1.2 setting context
Let's recall the DistAutogradContext definition, which only gives some of its member variables.
- contextId_ Is the context id.
- sendAutogradFunctions_ Is a map type variable, which will collect the backpropagation operator SendRpcBackward corresponding to all send requests.
- recvAutogradFunctions_ It is a map type variable, which will collect the back propagation operator RecvRpcBackward corresponding to all incoming requests.
// DistAutogradContext which stores information for a single distributed
// autograd pass on a worker.
class TORCH_API DistAutogradContext {
const int64_t contextId_;
// Map from autograd_message_id to appropriate 'send' autograd function.
std::unordered_map<int64_t, std::shared_ptr<SendRpcBackward>>
sendAutogradFunctions_;
// Map from autograd_message_id to appropriate 'recv' autograd function.
std::unordered_map<int64_t, std::shared_ptr<RecvRpcBackward>>
recvAutogradFunctions_;
};addSendFunction is to sendAutogradFunctions_ Add SendRpcBackward to the message id to get the SendRpcBackward.
void DistAutogradContext::addSendFunction(
const std::shared_ptr<SendRpcBackward>& func,
int64_t autograd_message_id) {
std::lock_guard<std::mutex> guard(lock_);
TORCH_INTERNAL_ASSERT(
sendAutogradFunctions_.find(autograd_message_id) ==
sendAutogradFunctions_.end());
sendAutogradFunctions_.emplace(autograd_message_id, func);
}From the perspective of context construction, this time from the perspective of context content.
At this time, the logic of the sender is as follows:
+--------------------------------------------------------------+ +-------------------+
| worker | |SendRpcBackward |
| +---------------------------------------------------------+ | | |
| | DistAutogradContext | | | input_metadata_ |
| | +-------------> | |
| | contextId_ = context_id_1 | | | | next_edges_ |
| | + | | | |
| | sendAutogradFunctions_ = [msg_id_1, SendRpcBackward_1] | | +-------------------+
| | | |
| | | |
| | recvAutogradFunctions_ | |
| | | |
| +---------------------------------------------------------+ |
| |
+--------------------------------------------------------------+
sender
+---------------------------------------------------------------------------------------+5.2 acceptance
Let's skip the internal processing of agent sending and turn to forward_ AUTOGRAD_ Business process of req.
5.2.1 receive message -- > receiver
When generating TensorPipeAgent, configure RequestCallbackImpl as a callback function. This is the unified response function of agent.
When we mentioned the agent receiving logic earlier, we will enter the following function, where we can see the processing logic of processForwardAutogradReq.
void RequestCallbackNoPython::processRpc(
RpcCommandBase& rpc,
const MessageType& messageType,
const int64_t messageId,
const c10::intrusive_ptr<JitFuture>& responseFuture,
std::shared_ptr<LazyStreamContext> ctx) const {
case MessageType::FORWARD_AUTOGRAD_REQ: {
// Will come here
processForwardAutogradReq(rpc, messageId, responseFuture, std::move(ctx));
return;
}
case MessageType::BACKWARD_AUTOGRAD_REQ: {
processBackwardAutogradReq(rpc, messageId, responseFuture);
return;
};
} 5.2.2 message processing
processForwardAutogradReq is responsible for processing messages. Its processing logic is as follows:
- Although the forward propagation request is received, because this is the receiving end, the subsequent back propagation is required, so the deviceMap is transposed.
- Use addRecvRpcBackward to add rpc messages to the context.
- There may be the possibility of the nested command, so you need to call processRpc again.
- Set the original message as finished processing and perform relevant operations.
void RequestCallbackNoPython::processForwardAutogradReq(
RpcCommandBase& rpc,
const int64_t messageId,
const c10::intrusive_ptr<JitFuture>& responseFuture,
std::shared_ptr<LazyStreamContext> ctx) const {
auto& rpcWithAutograd = static_cast<RpcWithAutograd&>(rpc);
// Need to reverse the device map for the backward pass of distributed
// autograd.
std::unordered_map<c10::Device, c10::Device> reverseDeviceMap;
// Transpose deviceMap
for (const auto& mapEntry : rpcWithAutograd.deviceMap()) {
reverseDeviceMap.insert({mapEntry.second, mapEntry.first});
}
// Attach 'recv' autograd function.
auto autogradContext = addRecvRpcBackward( // addRecvRpcBackward was called to join the context
rpcWithAutograd.autogradMetadata(),
rpcWithAutograd.tensors(),
rpcWithAutograd.fromWorkerId(),
reverseDeviceMap);
// For this recv thread on server side, before processRpc(),
// set current_context_id_ to be context_id passed from client.
// In this way, if there is nested rpc call in python rpc call, original
// context_id from client can be passed in the chain calls.
DistAutogradContextGuard ctxGuard(autogradContext->contextId());
// Process the original RPC.
auto wrappedMessageType = rpcWithAutograd.wrappedMessageType();
// Make an overall future for the wrapped response.
auto wrappedRpcResponseFuture =
c10::make_intrusive<JitFuture>(at::AnyClassType::get());
// Kick off processing for the nested RPC command.
// wrappedRpcResponseFuture will be a Future<T> to the result.
processRpc( // There may be the possibility of the nested command, so it needs to be processed again
rpcWithAutograd.wrappedRpc(),
wrappedMessageType,
messageId,
wrappedRpcResponseFuture,
std::move(ctx));
auto fromWorkerId = rpcWithAutograd.fromWorkerId();
// The original future needs to be marked as completed when the wrapped
// one completes, with the autograd context information wrapped.
wrappedRpcResponseFuture->addCallback(
[responseFuture,
messageId,
fromWorkerId,
ctxId =
autogradContext->contextId()](JitFuture& wrappedRpcResponseFuture) {
// As this callback can be invoked by a different thread, we have to
// make sure that the thread_local states in the previous thread is
// correctly propagated.
// NB: The execution of TorchScript functions can also run on a
// different thread, which is addressed by
// https://github.com/pytorch/pytorch/pull/36395
// NB: when adding async UDF support, we should also propagate
// thread_local states there.
// TODO: Land on a general solution for RPC ThreadLocalState. See
// https://github.com/pytorch/pytorch/issues/38510
DistAutogradContextGuard cbCtxGuard(ctxId);
if (wrappedRpcResponseFuture.hasError()) {
// Propagate error to responseFuture if we had one.
responseFuture->setError(wrappedRpcResponseFuture.exception_ptr());
} else {
auto msg = getMessageWithAutograd(
fromWorkerId,
std::move(
*wrappedRpcResponseFuture.value().toCustomClass<Message>()),
MessageType::FORWARD_AUTOGRAD_RESP);
msg.setId(messageId);
responseFuture->markCompleted(
IValue(c10::make_intrusive<Message>(std::move(msg))));
}
});
}5.2.3 context interaction
In torch / CSR / distributed / autograd / utils.cpp, the addRecvRpcBackward function handles the context.
This corresponds to the following in the design:
During forward propagation, we store the send and recv functions for each autograd propagation in the context. This ensures that we save references to the appropriate nodes in the autograd diagram to keep them active. In addition, this makes it easy to find the corresponding send and recv functions during backward propagation.
The specific logic is:
- Get the local context according to the autogradContextId in the rpc information.
- Generate a RecvRpcBackward.
- Use the tensor in rpc information to configure RecvRpcBackward, including torch::autograd::set_history(tensor, grad_fn).
- Call addRecvFunction to add RecvRpcBackward to the context.
ContextPtr addRecvRpcBackward(
const AutogradMetadata& autogradMetadata,
std::vector<torch::Tensor>& tensors,
rpc::worker_id_t fromWorkerId,
const std::unordered_map<c10::Device, c10::Device>& deviceMap) {
// Initialize autograd context if necessary.
auto& autogradContainer = DistAutogradContainer::getInstance();
auto autogradContext =
autogradContainer.getOrCreateContext(autogradMetadata.autogradContextId);
if (!tensors.empty() && torch::autograd::compute_requires_grad(tensors)) {
// Attach the tensors as inputs to the autograd function.
auto grad_fn = std::make_shared<RecvRpcBackward>(
autogradMetadata, autogradContext, fromWorkerId, deviceMap);
for (auto& tensor : tensors) {
if (tensor.requires_grad()) {
torch::autograd::set_history(tensor, grad_fn);
}
}
// Now update the autograd context with the necessary information.
autogradContext->addRecvFunction(
grad_fn, autogradMetadata.autogradMessageId);
}
return autogradContext;
}addRecvFunction is added as follows. Just look at recvuutogradfunctions_ Whether the operator corresponding to this message id already exists in the. If not, add it.
void DistAutogradContext::addRecvFunction(
std::shared_ptr<RecvRpcBackward>& func,
int64_t autograd_message_id) {
TORCH_INTERNAL_ASSERT(func != nullptr);
std::lock_guard<std::mutex> guard(lock_);
TORCH_INTERNAL_ASSERT(
recvAutogradFunctions_.find(autograd_message_id) ==
recvAutogradFunctions_.end());
recvAutogradFunctions_.emplace(autograd_message_id, func);
}So far, the logic is expanded as follows. There is a DistAutogradContext at both the sending end and the receiving end, and its ID is context_id_1.
Within each DistAutogradContext, MSG is used_ id_ 1 as the key, one is SendRpcBackward, and the other is RecvRpcBackward.
This corresponds to the following mentioned in the design:
Each automatic differential process is given a unique autograd_context_id, in the Container, the Context of the differential process (DistAutogradContext) is based on the autograd_context_id to uniquely confirm. autograd_context_id is a 64 bit globally unique id, and the first 16 bis are workers_ id, the last 48 bits are automatically incremented in each worker. Therefore, it can be seen that there are multiple contexts in a Container. This container is also responsible for maintaining a globally unique message id, which is used to associate send / receive automatic differential function pairs. The format is similar to autograd_context_id is a 64 bit integer. The first 16 bits are the worker id, and the last 48 bits are automatically incremented within the worker.
+----------------------------------------------------------------+
| worker | +-------------------+
| | |SendRpcBackward |
| +---------------------------------------------------------+ | | |
| | DistAutogradContext | | | input_metadata_ |
| | +-------------> | |
| | contextId_ = context_id_1 | | | | next_edges_ |
| | + | | | |
| | sendAutogradFunctions_ = [msg_id_1, SendRpcBackward_1] | | +-------------------+
| | | |
| | recvAutogradFunctions_ | |
| | | |
| +---------------------------------------------------------+ |
| |
| + |
| | |
+----------------------------------------------------------------+
|
|
| Sender
+-----------------------------------------------------------------------------------------+
| Receiver
|
v
+-----------------------------+----------------------------------+
| worker |
| | +-------------------+
| +---------------------------------------------------------+ | |RecvRpcBackward |
| | DistAutogradContext | | | |
| | | | | |
| | contextId_ = context_id_1 +-----------------> | input_metadata_ |
| | | | | | |
| | sendAutogradFunctions_ | | | | next_edges_ |
| | + | | | |
| | recvAutogradFunctions_ = [msg_id_1, RecvRpcBackward_1]| | +-------------------+
| | | |
| +---------------------------------------------------------+ |
| |
+----------------------------------------------------------------+Let's add Container and expand it. The current logic is as follows:
- Each worker includes a DistAutogradContainer.
- Each DistAutogradContainer includes several distautogradcontexts, which are extracted according to the context id.
- Each DistAutogradContext includes sendAutogradFunctions_ And recvuutogradfunctions_, Use msg id to obtain SendRpcBackward or RecvRpcBackward.
In this way, the back propagation chain is constructed.
+------------------------------------------------------------------------------------------------------------------------------------+
| worker |
| |
| +---------------------------------------+ +---------------------------------------------------------+ +-------------------+ |
| | DistAutogradContainer | | DistAutogradContext | |SendRpcBackward | |
| | | | +----------> | | |
| | worker_id_ | | contextId_ = ctx_id_1 | | | input_metadata_ | |
| | | | + | | | |
| | next_autograd_message_id_ +---------> | sendAutogradFunctions_ = [msg_id_1, SendRpcBackward_1] | | next_edges_ | |
| | | | | | | | |
| | next_context_id_ | | | recvAutogradFunctions_ | +-------------------+ |
| | + | | | |
| | autograd_contexts_[ctx_id_1 : ctx] | +---------------------------------------------------------+ |
| | | |
| +----------------------------+----------+ |
| | |
+------------------------------------------------------------------------------------------------------------------------------------+
|
|
+-------------------------------------------------------------------------------------------------------------------------------------+
|
v
+------------------------------+-----------------------------------------------------------------------------------------------------+
| worker |
| |
| +---------------------------------------+ +---------------------------------------------------------+ +-------------------+ |
| | DistAutogradContainer | | DistAutogradContext | |RecvRpcBackward | |
| | | | +----------> | | |
| | worker_id_ | | contextId_ = ctx_id_1 | | | input_metadata_ | |
| | | | | | | | |
| | next_autograd_message_id_ +---------> | sendAutogradFunctions_ | | | next_edges_ | |
| | | | | + | | | |
| | next_context_id_ | | | recvAutogradFunctions_ = [msg_id_1, RecvRpcBackward_1] | +-------------------+ |
| | + | | | |
| | autograd_contexts_[ctx_id_1 : ctx] | +---------------------------------------------------------+ |
| | | |
| +---------------------------------------+ |
| |
+------------------------------------------------------------------------------------------------------------------------------------+Mobile phones are as follows:
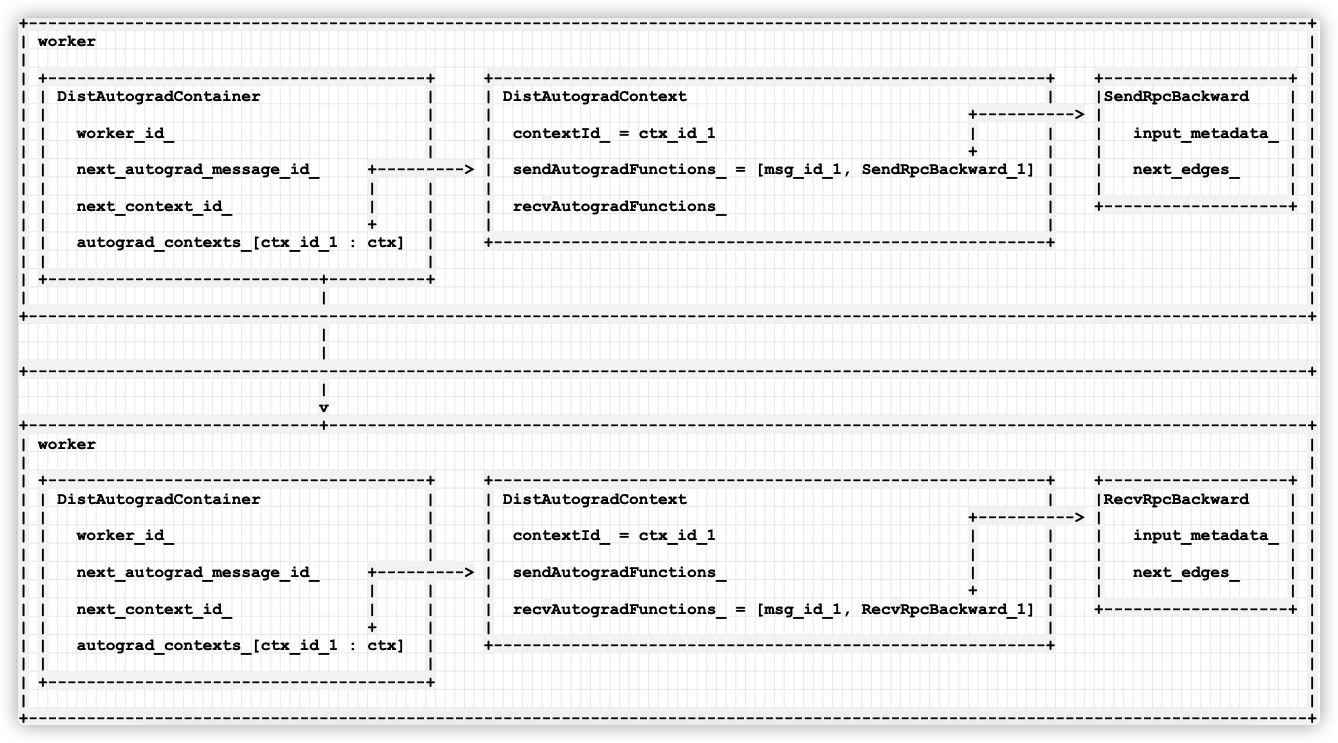
So far, we have preliminarily analyzed the context related classes. Below, we will combine the contents that have been analyzed so far and take a systematic look at the business logic.