[source code analysis] PyTorch distributed elastic training (5) -- rendezvous engine
0x00 summary
In the previous articles, we have learned the basic modules of PyTorch distribution and introduced several official examples. Next, we will introduce the elastic training of PyTorch. This is the fifth article. Let's take a look at the internal engine of Rendezvous, such as how to deal with node joining, node leaving, waiting, heartbeat, etc.
The flexibility training series is as follows:
[Source code analysis] PyTorch distributed elastic training (1) -- general idea
[Source code analysis] PyTorch distributed elastic training (2) -- Start & single node process
[Source code analysis] PyTorch distributed elastic training (3) -- agent
[Source code analysis] PyTorch distributed elastic training (4) -- rendezvous architecture and logic
0x01 Preface
1.1 overall system
Elastic training can be understood as an operating system based on Rendezvous.
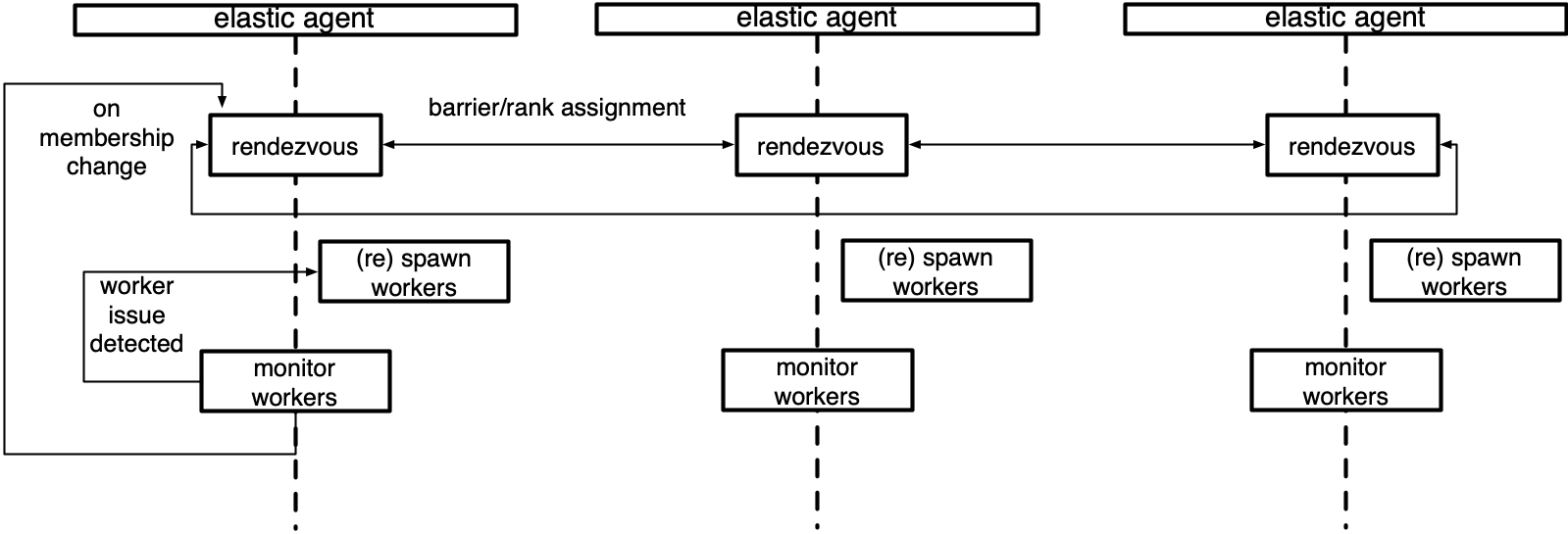
-
Agent focuses on the logic on specific nodes
- The Agent is responsible for specific business logic related operations, such as starting the process, executing the user program, monitoring the operation of the user program, and notifying Rendezvous if there are exceptions.
- Agent is a worker manager, which is responsible for starting / managing the workers process, forming a worker group, monitoring the running status of workers, capturing failed workers, and restarting the worker group if there is a fault / new worker.
- The Agent is responsible for maintaining WORLD_SIZE and RANK information. The user does not need to provide it manually, and the Agent will process it automatically.
- Agent is a background process on a specific node and an independent individual. The agent itself cannot realize the overall elastic training, so it needs a mechanism to complete the mutual discovery between worker s, change synchronization, etc. (in fact, the information of WORLD_SIZE and RANK also needs the synchronization of multiple nodes to be determined). This is the following Rendezvous concept.
-
Rendezvous is in charge
Cluster logic
To ensure that nodes reach a strong consensus on which nodes participate in training.
- Each Agent includes a Rendezvous handler. These handlers generally form a Rendezvous cluster, thus forming an Agent cluster.
- After Rendezvous is completed, a shared key value store will be created, which implements a torch.distributed.Store API. This store is only shared by members who have completed Rendezvous. It is designed to allow Torch Distributed Elastic to exchange control and data information during initialization.
- Rendezvous is responsible for maintaining all relevant information of the current group on each agent. There is a rendezvous on each agent. They will communicate with each other and generally maintain a set of information, which is stored in the Store mentioned above.
- Rendezvous is responsible for cluster logic, such as adding new nodes, removing nodes, allocating rank, etc.
1.2 Rendezvous
So far, the Rendezvous information is as follows. The dynamic Rendezvous handler belongs to dynamic logic, where_ RendezvousStateHolder is a state and other meta information store (static structure). You will find that there is another _rendezvousopexecutionin the figure, which is not introduced. This is the runtime engine, so let's see how _rendezvousopexecutionhandles it in this article.
+-----------------------------+ +------------------------------------------------+
| LocalElasticAgent | | WorkerSpec |
| | | |
| +------------------------+ | | rdzv_handler = {DynamicRendezvousHandler} -------+
| |WorkerGroup | | | | |
| | spec +--------------> | entry = worker_fn | |
| | workers | | | | |
| | store | | | role = {str} 'trainer' | |
| | group_rank | | | | |
| | group_world_size | | +------------------------------------------------+ |
| | | | |
| +------------------------+ | |
| | |
| rdzv_run_id | |
| store | +-----------------------------------------+ |
| | |DynamicRendezvousHandler | |
+-----------------------------+ | | |
| | |
| _settings: RendezvousSettings | <--+
| |
| _store: Store |
| |
| _state_holder: _RendezvousStateHolder |
| |
| _op_executor: _RendezvousOpExecutor |
| |
+-----------------------------------------+
1.3 decoupling
_ Rendezvousopexecution decouples the functions:
- Business logic is abstracted into a series of operators, such as_ RendevzousJoinOp.
- Rendezvous internally maintains a set of state machines composed of business functions, such as functions_ add_to_participants is used to add participants.
- _ Rendezvousopexecution engine executes various operators, obtains an Action according to the operator results, and then uses the Action to call the business function for operation.
This article mainly introduces the Rendezvous engine corresponding to C10d backend.
0x02 Engine Implementation
2.1 base class
_ Rendezvousopexecution is the base class of the engine, which only defines the virtual function run.
class _RendezvousOpExecutor(ABC):
"""Executes rendezvous operations."""
@abstractmethod
def run(
self, state_handler: Callable[[_RendezvousContext, float], _Action], deadline: float
) -> None:
"""Executes a rendezvous operation.
An operation is run inside a state machine and is expected to transition
the rendezvous from one state to another.
Args:
state_handler:
A callable that is expected to return the next state transition
action based on the current state of the rendezvous.
deadline:
The time, in seconds, at which the operation will be considered
timed-out.
"""
It's used here_ Rendezvous context is used to encapsulate various information of rendezvous and provide it to the operation engine. Here it is_ Use of RendezvousState and RendezvousSettings.
class _RendezvousContext:
"""Holds the context of the rendezvous.
Attributes:
node:
The node descriptor associated with the current rendezvous handler
instance.
state:
The current state of the rendezvous.
settings:
The rendezvous settings.
"""
node: _NodeDesc
state: _RendezvousState
settings: RendezvousSettings
def __init__(
self, node: _NodeDesc, state: _RendezvousState, settings: RendezvousSettings
) -> None:
self.node = node
self.state = state
self.settings = settings
2.2 distributed operation engine
_ Distributedrendezvousopexecution extends_ Rendezvous opexecution is the actual executor of ElasticTorch. Similar to Looper, it is responsible for message distribution, calling business and state maintenance.
2.2. 1 Definition
Compared with its base class_ Distributedrendezvousopexecution adds member variables such as node information, status and configuration.
class _DistributedRendezvousOpExecutor(_RendezvousOpExecutor):
"""Executes rendezvous operations using a shared state.
Args:
node:
The node descriptor associated with the current rendezvous handler
instance.
state_holder:
The ``RendezvousStateHolder`` to use to sync the rendezvous state
with other nodes.
settings:
The rendezvous settings.
"""
_node: _NodeDesc
_state: _RendezvousState
_state_holder: _RendezvousStateHolder
_settings: RendezvousSettings
def __init__(
self,
node: _NodeDesc,
state_holder: _RendezvousStateHolder,
settings: RendezvousSettings,
) -> None:
self._node = node
self._state_holder = state_holder
self._settings = settings
The logic is as follows:
+---------------------------------------------------------------+ | _DistributedRendezvousOpExecutor | | | | +------------------------+ | | _state +---> | _RendezvousState | | | | | | | | participants | | | | wait_list | | | | last_heartbeats | | | | deadline | | | +------------------------+ | | | | +-------------------------+ | | _settings +--> | RendezvousSettings | | | | | | | +-------------------------+ | | | | +--------------------------------------+ | | _state_holder +---> | _BackendRendezvousStateHolder | | | | | | | | _backend: RendezvousBackend | | | | _state: _RendezvousState | | | | _settings: RendezvousSettings | | | | | | | +--------------------------------------+ | | +--------------------------------------+ | | | _NodeDesc | | | _node +-------> | fqdn: str | | | | pid: int | | | | local_id: int | | | | | | | +--------------------------------------+ | +---------------------------------------------------------------+
2.2. 2 call
Let's take a few examples to see how to invoke the engine. We can see that we first set the operator and then call the run function of the engine.
2.2.2.1 _RendezvousKeepAliveOp
def _keep_alive(self) -> None:
self._heartbeat_lock.acquire()
op = _RendezvousKeepAliveOp() # Setting operator
deadline = self._get_deadline(self._settings.timeout.heartbeat)
self._op_executor.run(op, deadline) # call
2.2.2.2 _RendezvousCloseOp
def _close(self) -> None:
op = _RendezvousCloseOp() # Setting operator
deadline = self._get_deadline(self._settings.timeout.close)
self._op_executor.run(op, deadline) # call
2.2.2.3 _RendezvousJoinOp
def next_rendezvous(self) -> Tuple[Store, int, int]:
"""See base class."""
self._stop_heartbeats()
# Delay the execution for a small random amount of time if this is our
# first run. This will slightly skew the rendezvous attempts across the
# nodes and reduce the load on the backend.
if self._state_holder.state.round == 0:
_delay(seconds=(0, 0.3))
exit_op = _RendezvousExitOp() # Setting operator
join_op = _RendezvousJoinOp() # Setting operator
deadline = self._get_deadline(self._settings.timeout.join)
self._op_executor.run(exit_op, deadline) # This will be called
self._op_executor.run(join_op, deadline) # call
self._start_heartbeats()
rank, world_size = self._get_world()
store = self._get_store()
return store, rank, world_size
2.2. 3 functions
_ In the distributedrendezvousopexecution, the run function implements the basic logic, which is to perform various operations according to the action type.
2.2. 3.1 main body circulation
The specific code of run is as follows:
def run(
self, state_handler: Callable[[_RendezvousContext, float], _Action], deadline: float
) -> None:
"""See base class."""
action = None
while action != _Action.FINISH: # Loop until a FINISH action is obtained
# Reads or writes the latest rendezvous state shared by all nodes in
# the rendezvous. Note that our local changes might get overridden
# by another node if that node synced its changes before us.
# It is important to synchronize information between all node s
has_set = self._state_holder.sync() # Because the latest status is rendezvous.
self._state = self._state_holder.state
ctx = _RendezvousContext(self._node, self._state, self._settings)
# Determine the next action to take based on the current state of
# the rendezvous.
action = state_handler(ctx, deadline) # Decide the next operation, state_ A handler is an operator
if action == _Action.FINISH:
continue
if action == _Action.ERROR_CLOSED:
raise RendezvousClosedError()
if action == _Action.ERROR_TIMEOUT:
raise RendezvousTimeoutError()
if action == _Action.SYNC:
# Delay the execution by one second to avoid overloading the
# backend if we are asked to poll for state changes.
_delay(seconds=1)
else:
if action == _Action.KEEP_ALIVE:
self._keep_alive()
elif action == _Action.ADD_TO_PARTICIPANTS:
self._add_to_participants()
elif action == _Action.ADD_TO_WAIT_LIST:
self._add_to_wait_list()
elif action == _Action.REMOVE_FROM_PARTICIPANTS:
self._remove_from_participants()
elif action == _Action.REMOVE_FROM_WAIT_LIST:
self._remove_from_wait_list()
elif action == _Action.MARK_RENDEZVOUS_COMPLETE:
self._mark_rendezvous_complete()
elif action == _Action.MARK_RENDEZVOUS_CLOSED:
self._mark_rendezvous_closed()
# Attempt to sync our changes back to other nodes.
self._state_holder.mark_dirty()
See the figure below for details.
+-----------------------------------------+ +---------------------------------------------------------------+
|DynamicRendezvousHandler | | _DistributedRendezvousOpExecutor |
| | | |
| | | +------------------------+ |
| _settings: RendezvousSettings | | _state +---> | _RendezvousState | |
| | | | | |
| | | | participants | |
| _store: Store | | | wait_list | |
| | | | last_heartbeats | |
| | | | deadline | |
| _state_holder: _RendezvousStateHolder | | +------------------------+ |
| | run(_RendezvousJoinOp()) | +-------------------------+ |
| | | _settings +--> | RendezvousSettings | |
| _op_executor +------------------------------------------------> | | | |
| | | +-------------------------+ |
| | | +--------------------------------------+ |
+-----------------------------------------+ | _state_holder +---> | _BackendRendezvousStateHolder | |
| | | |
| | _backend: RendezvousBackend | |
| | _state: _RendezvousState | |
| | _settings: RendezvousSettings | |
| | | |
| +--------------------------------------+ |
| +--------------------------------------+ |
| | _NodeDesc | |
| _node +-------> | fqdn: str | |
| | pid: int | |
| | local_id: int | |
| | | |
| +--------------------------------------+ |
+---------------------------------------------------------------+
Mobile phones are as follows:

2.2. 3.2 synchronization
In the run function, it should be noted that self. Is called before performing various operator operations_ state_ holder. Sync () performs a state synchronization among worker s to reach a consensus.
def sync(self) -> Optional[bool]:
"""See base class."""
state_bits: Optional[bytes] = None
token = None
has_set: Optional[bool]
if self._dirty: # If the status of this node changes
has_set = False
state_bits = pickle.dumps(self._state)
# Set your status to backend
set_response = self._backend.set_state(state_bits, self._token)
if set_response is not None:
state_bits, token, has_set = set_response
else: # I haven't changed. I can only get it from the back end
has_set = None
if self._cache_duration > 0:
# Avoid overloading the backend if we are asked to retrieve the
# state repeatedly. Try to serve the cached state.
if self._last_sync_time >= max(time.monotonic() - self._cache_duration, 0):
return None
get_response = self._backend.get_state() # Get the latest status of other nodes from backend
if get_response is not None:
state_bits, token = get_response
if state_bits is not None:
try:
self._state = pickle.loads(state_bits) # Update the status of itself with the back-end status
except pickle.PickleError as exc:
raise RendezvousStateError(
"The rendezvous state is corrupt. See inner exception for details."
) from exc
else:
self._state = _RendezvousState()
if has_set and self._dead_nodes and log.isEnabledFor(logging.DEBUG):
node_list = ", ".join(f"'{dead_node}'" for dead_node in self._dead_nodes)
msg = (
f"As part of the sync operation the node(s) {node_list} have been removed from the "
f"rendezvous '{self._settings.run_id}' since they had no heartbeat."
)
self._record(message=msg)
self._token = token
self._dirty = False
self._last_sync_time = time.monotonic()
self._sanitize()
return has_set
back-end
torch/distributed/elastic/rendezvous/c10d_rendezvous_backend.py is the corresponding back-end code.
The back-end uses the store as a centralized storage, which is the master. Each node is a client. It will go to the master to update its status and obtain the status of other nodes. In this way, all nodes will exchange what they need and reach a consensus. clients that do not update metadata will also be deleted regularly.
get_state is simply extracted from the store.
def get_state(self) -> Optional[Tuple[bytes, Token]]:
"""See base class."""
base64_state: bytes = self._call_store("get", self._key)
return self._decode_state(base64_state)
set_state will make a compare set, which returns new state and whether the state has been updated.
def set_state(
self, state: bytes, token: Optional[Token] = None
) -> Optional[Tuple[bytes, Token, bool]]:
"""See base class."""
base64_state_str: str = b64encode(state).decode()
if token:
# Shortcut if we know for sure that the token is not valid.
if not isinstance(token, bytes):
result = self.get_state()
if result is not None:
tmp = *result, False
# Python 3.6 does not support tuple unpacking in return
# statements.
return tmp
return None
token = token.decode()
else:
token = self._NULL_SENTINEL
base64_state: bytes = self._call_store("compare_set", self._key, token, base64_state_str)
state_token_pair = self._decode_state(base64_state)
if state_token_pair is None:
return None
new_state, new_token = state_token_pair
# C10d Store's compare_set method does not offer an easy way to find out
# whether our write attempt was successful. As a brute-force solution we
# perform a bitwise comparison of our local state and the remote state.
return new_state, new_token, new_state == state
_sanitize
_ The sanitize method is used to process messages from other nodes, such as cleaning up failed nodes. That is, if the last heartbeat time exceeds a certain threshold range, these nodes will be marked dead_node, and clear these nodes from the participant or wait list.
def _sanitize(self) -> None:
state = self._state
expire_time = datetime.utcnow() - (
self._settings.keep_alive_interval * self._settings.keep_alive_max_attempt
)
# Filter out the dead nodes.
self._dead_nodes = [
node
for node, last_heartbeat in state.last_heartbeats.items()
if last_heartbeat < expire_time
]
participant_removed = False
for dead_node in self._dead_nodes:
del state.last_heartbeats[dead_node] # Remove failed node
try:
del state.participants[dead_node] # Remove failed node
participant_removed = True
except KeyError:
pass
try:
state.wait_list.remove(dead_node) # Remove failed node
except KeyError:
pass
if participant_removed:
# Common epilogue shared with the _remove_from_participants()
# function of _DistributedRendezvousOpExecutor.
_remove_participant_epilogue(state, self._settings)
After introducing how to run the engine, let's take a look at the specific operators.
0x03 operator
_ The business logic of rendezvous opexecution engine is divided into two layers: user operation and internal business logic. User operations and internal business mechanisms are decoupled.
-
User operations are divided into various operators, including heartbeat, Join, close and end. For example, the Join operator is_ RendevzousJoinOp.
-
The internal business logic is divided into various business functions, such as_ add_ to_ The participants method removes a node from the waiting list and adds this node to participants.
-
Operators and internal business logic are not one-to-one correspondence, and need a mechanism similar to state machine to control.
- For example, the result of the heartbeat operator may be: timeout / keep alive / normal end, so different internal business functions should be called according to this result. This correspondence logic is completed through Action.
- Various operators combine and aggregate into a state machine.
- Various actions are generated inside the operator, which determines the next operation of the state machine.
-
Within the engine, the specific business logic is executed according to the Action, or it can be decoupled through the Action.
Specifically, the engine can be logically divided into three layers: the operator layer at the top, the Action layer in the middle, and the business function layer below.
+-----------------------------------------------------------------------------------------+
| |
| _RendezvousKeepAliveOp _RendezvousCloseOp _RendezvousExitOp _RendezvousJoinOp |
| |
+-------------+---------------------+--------------------+------------------+-------------+
| | | |
| | | |
| | | |
| | | |
v v v v
+-----------------------------------------------------------------------------------------+
| |
| KEEP_ALIVE ADD_TO_PARTICIPANTS ADD_TO_WAIT_LIST REMOVE_FROM_WAIT_LIST ...... |
| |
+-------------+----------+----------+----------+---------+---------+---------+------------+
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
v v v v v v v
+-----------------------------------------------------------------------------------------+
| |
| _add_to_participants _remove_from_participants _add_to_wait_list ...... |
| |
| |
+-----------------------------------------------------------------------------------------+
We analyze them one by one.
3.1 operation
First, analyze the actions in the middle tier to see how many actions there are. Based on the status of rendezvous, the actions of the engine are as follows. The code is located in torch/distributed/elastic/rendezvous/dynamic_rendezvous.py
class _Action(Enum):
"""Specifies the possible actions based on the state of the rendezvous."""
KEEP_ALIVE = 1
ADD_TO_PARTICIPANTS = 2
ADD_TO_WAIT_LIST = 3
REMOVE_FROM_PARTICIPANTS = 4
REMOVE_FROM_WAIT_LIST = 5
MARK_RENDEZVOUS_COMPLETE = 6
MARK_RENDEZVOUS_CLOSED = 7
SYNC = 8
ERROR_CLOSED = 9
ERROR_TIMEOUT = 10
FINISH = 11
3.2 operator
Some operators are implemented in the engine. Basically, an operation corresponds to an operator. We give several examples of operators. Operators set operation types according to the state of rendezvous.
3.2. 1 heartbeat
3.2. 1.1 check heartbeat
_ RendezvousKeepAliveOp is used to determine the next Action based on the current status and time. It is mainly to regularly check whether the Node is faulty.
class _RendezvousKeepAliveOp:
"""Represents a rendezvous keep-alive update operation."""
def __call__(self, ctx: _RendezvousContext, deadline: float) -> _Action:
if _should_keep_alive(ctx):
if time.monotonic() > deadline:
return _Action.ERROR_TIMEOUT
return _Action.KEEP_ALIVE
return _Action.FINISH
_ should_ keep_ The live method is:
def _should_keep_alive(ctx: _RendezvousContext) -> bool:
"""Determines whether a keep-alive heartbeat should be sent."""
try:
last_heartbeat = ctx.state.last_heartbeats[ctx.node]
except KeyError:
return False
return last_heartbeat <= datetime.utcnow() - ctx.settings.keep_alive_interval
3.2. 1.2 periodic call
It should be noted here that before any operator is performed, the sync operation must be called, and sync will synchronize the status between node s. Because the heartbeat is periodic, the synchronization status is also periodic.
A timer will be started in the DynamicRendezvousHandler and called periodically_ keep_alive_weak method.
def _start_heartbeats(self) -> None:
self._keep_alive_timer = _PeriodicTimer(
self._settings.keep_alive_interval, self._keep_alive_weak, weakref.ref(self)
)
self._keep_alive_timer.set_name(f"RendezvousKeepAliveTimer_{self._this_node.local_id}")
self._keep_alive_timer.start()
Second_ keep_alive_weak calls self_ keep_ alive().
@staticmethod
def _keep_alive_weak(weak_self) -> None:
self = weak_self()
if self is not None:
self._keep_alive()
_ keep_alive will call_ RendezvousKeepAliveOp.
def _keep_alive(self) -> None:
self._heartbeat_lock.acquire()
op = _RendezvousKeepAliveOp()
deadline = self._get_deadline(self._settings.timeout.heartbeat)
try:
self._op_executor.run(op, deadline)
msg = (
f"The node '{self._this_node}' has sent a keep-alive heartbeat to the rendezvous "
f"'{self._settings.run_id}'."
)
self._record(message=msg)
log.debug(msg)
except RendezvousError as ex:
msg = (
f"The node '{self._this_node}' has failed to send a keep-alive heartbeat to the "
f"rendezvous '{self._settings.run_id}' due to an error of type {type(ex).__name__}."
)
self._record(message=msg, node_state=NodeState.FAILED)
finally:
self._heartbeat_lock.release()
3.2. 1.2 setting heartbeat
In addition_ Distributedrendezvousopexecution has a_ keep_ The live function with the same name is used to implement internal logic, which we will talk about later.
3.2. 2 off
_ RendezvousCloseOp will determine the next Action based on the current status and time.
class _RendezvousCloseOp:
"""Represents a rendezvous close operation."""
def __call__(self, ctx: _RendezvousContext, deadline: float) -> _Action:
if ctx.state.closed:
return _Action.FINISH
if time.monotonic() > deadline:
return _Action.ERROR_TIMEOUT
return _Action.MARK_RENDEZVOUS_CLOSED
3.2. 3 end
_ RendezvousExitOp determines the next Action based on the current state and time. If this Node is not in the participants, it will not be processed. Otherwise, a next Action deleted from the participants list will be returned. If the timeout occurs, the corresponding Action is returned.
class _RendezvousExitOp:
"""Represents a rendezvous exit operation."""
def __call__(self, ctx: _RendezvousContext, deadline: float) -> _Action:
if ctx.node in ctx.state.participants:
if time.monotonic() > deadline:
return _Action.ERROR_TIMEOUT
return _Action.REMOVE_FROM_PARTICIPANTS
return _Action.FINISH
3.2.4 Join
_ RendezvousJoinOp performs different processing according to different system states, such as trying to add this Node to the participant, or waiting list, or continue to wait. For details, see the code notes.
- Extract from context_ RendezvousState state, and store the results in state.
- If the status is closed, it indicates that rendezvous has ended at this time, and returns_ Action.ERROR_CLOSED.
- See if you are a participant and store the results in is_participant.
- If the status has ended and this node is already a participant, it means that rendezvous can end and return_ Action.FINISH.
- Get the current time now.
- If now > deadline, it indicates that it has timed out.
- If there is still time for rollback, it means that this node needs to return to the previous state.
- If this node is already a participant, the total number of nodes does not reach min. although it is already a participant, it needs to be removed from the participant list, so it is returned_ Action.REMOVE_FROM_PARTICIPANTS.
- If this node is in the waiting list, it means that the total number of nodes does not reach max. although it is in the waiting list, it needs to be removed from the waiting list, so it returns_ Action.REMOVE_FROM_WAIT_LIST.
- Otherwise return_ Action.ERROR_TIMEOUT.
- If there is still time for rollback, it means that this node needs to return to the previous state.
- Otherwise, there is no timeout, continue processing.
- If state Complete and this node is not a participant (if the node is a participant, it has been handled earlier). It means that rendezvous has ended. If the maximum number of nodes has not been reached and the current node is not in the waiting list, it needs to be added to the waiting node list. When the next monitoring cycle arrives, redo rendezvous to add the nodes in the waiting list to the participating list. Therefore Return_ Action.ADD_TO_WAIT_LIST.
- If this node is a participant and the state is not in complete state (if it is in complete state, it has been handled earlier), if the minimum number of nodes has been reached & it has timed out, it indicates that rendezvous has ended, and _Action.MARK_RENDEZVOUS_COMPLETE is returned.
- Otherwise, if the description is not finished and this node is not a participant, it will be directly added to the participant list and returned_ Action.ADD_TO_PARTICIPANTS.
- If you need to keep your heart beating, go back_ Action.KEEP_ALIVE.
- Otherwise return_ Action.SYNC.
class _RendezvousJoinOp:
"""Represents a rendezvous join operation."""
def __call__(self, ctx: _RendezvousContext, deadline: float) -> _Action:
state = ctx.state # Extract from context_ RendezvousState state
# A closed rendezvous means that it no longer accepts new nodes.
if state.closed:
return _Action.ERROR_CLOSED # If it's over, go back_ Action.ERROR_CLOSED
is_participant = ctx.node in state.participants # See if it's a participant
# If we are part of the rendezvous and it is already complete there is
# no further action to take.
if state.complete and is_participant: # If it is a participant and the status is end, return_ Action.FINISH
return _Action.FINISH
now = time.monotonic()
if now > deadline: # If it has timed out
rollback_period = 5 # 5 seconds
# If we still have time to rollback (a short period on top of the
# operation deadline), try to remove ourself from the rendezvous.
# It is okay if we can't though as our keep-alive will eventually
# expire.
if now <= deadline + rollback_period: # If you still have time to rollback
# If we are part of the rendezvous, it means we couldn't find
# enough participants to complete it on time.
if is_participant: # At this time, min has not been reached. Although it is already a participant, it needs to be removed
return _Action.REMOVE_FROM_PARTICIPANTS # Need to remove from participant list
# If we are in the wait list, it means we couldn't wait till the
# next round of the rendezvous.
if ctx.node in state.wait_list: # At this time, max has been reached, although it is already in the waiting list and needs to be removed
return _Action.REMOVE_FROM_WAIT_LIST # Need to remove from waiting list
return _Action.ERROR_TIMEOUT # Return timeout
if state.complete: # If rendezvous is over
# If we are here, it means we are not part of the rendezvous. In
# case the rendezvous has capacity for additional participants add
# ourself to the wait list for the next round.
if len(state.participants) < ctx.settings.max_nodes: # If the maximum number of nodes has not been reached
if ctx.node not in state.wait_list: # If the current node is not in the waiting list
return _Action.ADD_TO_WAIT_LIST # Add to the waiting list and send a waiting action
elif is_participant: # If already in the participant list
# If the rendezvous has enough number of participants including us,
# check whether we have passed the rendezvous deadline. If yes,
# complete it.
if len(state.participants) >= ctx.settings.min_nodes: # If the minimum number of nodes is reached
if cast(datetime, state.deadline) < datetime.utcnow(): # If timeout is reached
return _Action.MARK_RENDEZVOUS_COMPLETE # Indicates that rendezvous is over
else: # Otherwise, join the participants directly
# The rendezvous is not complete yet and we are not part of it. Try
# to join.
return _Action.ADD_TO_PARTICIPANTS
if _should_keep_alive(ctx): # If you need to keep your heart beating, go back_ Action.KEEP_ALIVE
return _Action.KEEP_ALIVE
# At this point either the rendezvous is not complete, but we are part
# of it, which means we have to wait for other participants to join; or
# the rendezvous is complete, but we are not part of it, which means we
# have to wait for the next round.
return _Action.SYNC # Otherwise, the synchronization status will be returned_ Action.SYNC
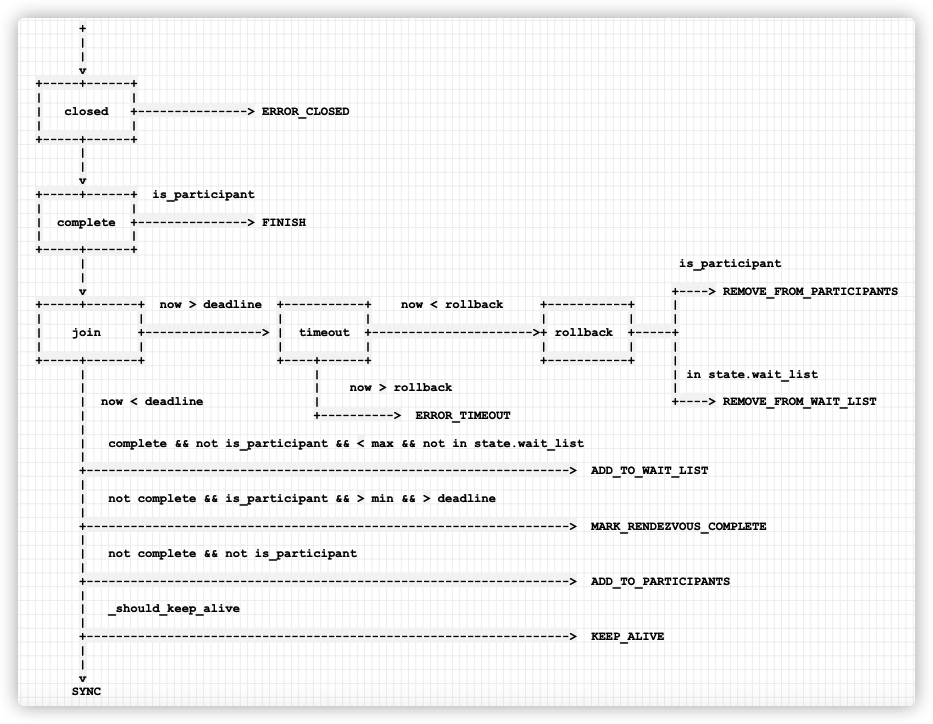
The specific logic is as follows:
state.closed
+--------------------------> _Action.ERROR_CLOSED
|
|
| complete & participant
+--------------------------> _Action.FINISH
|
|
| timeout & participant
+--------------------------> _Action.REMOVE_FROM_PARTICIPANTS
|
|
| timeout & wait
+--------------------------> _Action.REMOVE_FROM_WAIT_LIST
|
+-------------------+ |
| | | timeout
| _RendezvousJoinOp +------------------------------> _Action.ERROR_TIMEOUT
| | |
+-------------------+ | complete & < max & not wait
|
+--------------------------> _Action.ADD_TO_WAIT_LIST
|
| complete & participant & > min & deadline
|
+--------------------------> _Action.MARK_RENDEZVOUS_COMPLETE
|
| not complete & not participant
|
+--------------------------> _Action.ADD_TO_PARTICIPANTS
|
| _should_keep_alive
|
+--------------------------> _Action.KEEP_ALIVE
|
| else
|
+--------------------------> _Action.SYNC
The following is the status description diagram of ETCD backend Rendezvous in the source code. We can roughly refer to the status of c10d.
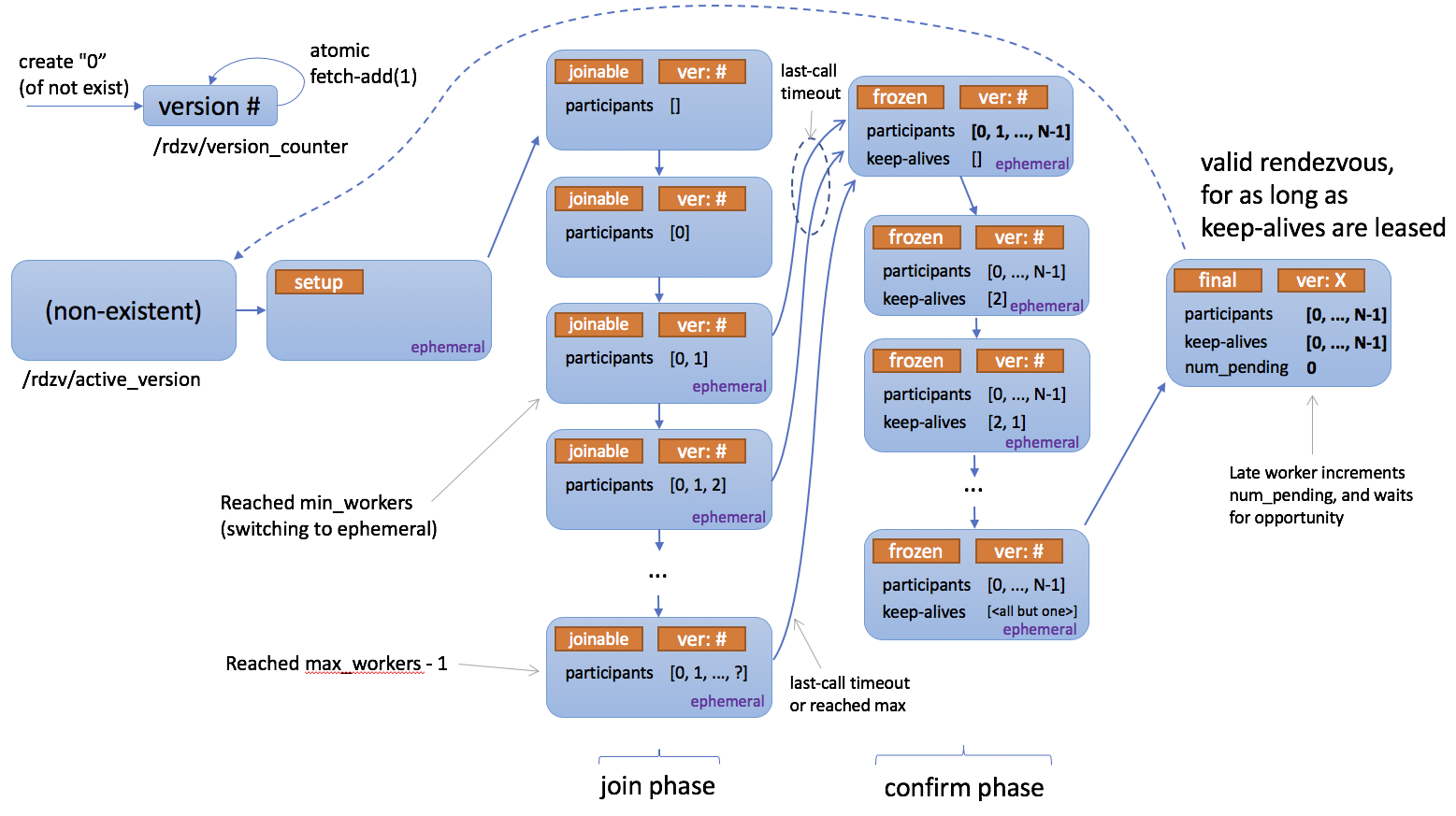
It can be seen that the Join of etcd backend can be divided into four stages:
- In the setup phase, a value will be written to the fixed directory, which is an exclusive lock. If the writing fails, it indicates that a rendezvous process is in progress.
- Join (joinable) stage. If the value is written successfully, enter the join stage. If the waiting time is over or the node participating in the training reaches the maximum value, enter the freeze stage.
- frozen (confirm) stage. All nodes need to be confirmed to enter the final stage.
- final stage. Assign rank, and the instance of RANK 0 becomes master.
Following the above figure, we expand c10d as follows.
+
|
|
v
+-----+------+
| |
| closed +---------------> ERROR_CLOSED
| |
+-----+------+
|
|
v
+-----+------+ is_participant
| |
| complete +---------------> FINISH
| |
+-----+------+
| is_participant
|
v +----> REMOVE_FROM_PARTICIPANTS
+-----+-------+ now > deadline +-----------+ now < rollback +-----------+ |
| | | | | | |
| join +----------------> | timeout +---------------------->+ rollback +-----+
| | | | | | |
+-----+-------+ +----+------+ +-----------+ |
| | | in state.wait_list
| | now > rollback |
| now < deadline | +----> REMOVE_FROM_WAIT_LIST
| +----------> ERROR_TIMEOUT
|
| complete && not is_participant && < max && not in state.wait_list
|
+------------------------------------------------------------------> ADD_TO_WAIT_LIST
|
| not complete && is_participant && > min && > deadline
|
+------------------------------------------------------------------> MARK_RENDEZVOUS_COMPLETE
|
| not complete && not is_participant
|
+-----------------------------------------> ADD_TO_PARTICIPANTS
|
| _should_keep_alive
|
+---------------------------> KEEP_ALIVE
|
|
v
SYNC
Mobile phones are as follows:
0x04 business operation
_ DistributedRendezvousOpExecutor. The internal of run is to select different business functions to execute according to action.
if action == _Action.KEEP_ALIVE:
self._keep_alive()
elif action == _Action.ADD_TO_PARTICIPANTS:
self._add_to_participants()
elif action == _Action.ADD_TO_WAIT_LIST:
self._add_to_wait_list()
elif action == _Action.REMOVE_FROM_PARTICIPANTS:
self._remove_from_participants()
elif action == _Action.REMOVE_FROM_WAIT_LIST:
self._remove_from_wait_list()
elif action == _Action.MARK_RENDEZVOUS_COMPLETE:
self._mark_rendezvous_complete()
elif action == _Action.MARK_RENDEZVOUS_CLOSED:
self._mark_rendezvous_closed()
Let's take a look at these internal function logic.
4.1 joining participants
Add received_ TO_ After PARTICIPANTS, call the add_to_participants removes the node from the waiting list and adds it to participants.
def _add_to_participants(self) -> None:
state = self._state
try:
state.wait_list.remove(self._node)
except KeyError:
pass
# The ranks of the participants will be set once the rendezvous is
# complete.
state.participants[self._node] = 0
self._keep_alive()
if len(state.participants) == self._settings.min_nodes:
state.deadline = datetime.utcnow() + self._settings.timeout.last_call
if len(state.participants) == self._settings.max_nodes:
self._mark_rendezvous_complete()
4.2 removing participants
Remove accepted_ FROM_ After PARTICIPANTS, call the remove_from_participants from participants and last_ Delete participants from heartbeat.
def _remove_from_participants(self) -> None:
state = self._state
del state.participants[self._node]
del state.last_heartbeats[self._node]
if state.complete:
# If we do not have any participants left, move to the next round.
if not state.participants:
state.complete = False
state.round += 1
else:
if len(state.participants) < self._settings.min_nodes:
state.deadline = None
4.3 adding waiting sequence
Add received_ TO_ WAIT_ After LIST, call the add_to_wait_list network wait_ Add nodes to the list.
def _add_to_wait_list(self) -> None:
self._state.wait_list.add(self._node)
self._keep_alive()
4.4 remove wait sequence
Remove accepted_ FROM_ WAIT_ After LIST, call the remove_from_wait_list from wait_list to remove the node.
def _remove_from_wait_list(self) -> None:
self._state.wait_list.remove(self._node)
del self._state.last_heartbeats[self._node]
4.5 end of setting
Mark received_ RENDEZVOUS_ After complete, set rank for each participant after the rendezvous aggregation operation is completed.
Each node is sorted according to the same algorithm, so the rank is the same on each node.
def _mark_rendezvous_complete(self) -> None:
state = self._state
state.complete = True
state.deadline = None
# Assign the ranks.
for rank, node in enumerate(sorted(state.participants)):
state.participants[node] = rank
def _mark_rendezvous_closed(self) -> None:
self._state.closed = True
4.6 heartbeat
Keep received_ After alive action, the_ keep_ Live to maintain the heartbeat. In addition, keep_alive will be there, too_ add_ to_ When called in the participants and other methods, the last heartbeat in the local state will be updated. The next sync will update the last heartbeat_ Heartbeat writes to the key value store so that other nodes can know the status of this Node. The local will_ sanitize according to last_ Heartbeat, as we mentioned before.
def _keep_alive(self) -> None:
msg = (
f"The node '{self._node}' updated its keep-alive heartbeat time for the rendezvous "
f"'{self._settings.run_id}'. Pending sync."
)
self._record(message=msg)
self._state.last_heartbeats[self._node] = datetime.utcnow()
_ The record method is as follows:
def _record(self, message: str, node_state: NodeState = NodeState.RUNNING) -> None:
construct_and_record_rdzv_event(
name=f"{self.__class__.__name__}.{get_method_name()}",
run_id=self._settings.run_id,
message=message,
node_state=node_state,
hostname=self._node.fqdn,
pid=self._node.pid,
local_id=self._node.local_id,
)
This is to call the following code to record the log.
def record_rdzv_event(event: RdzvEvent) -> None:
_get_or_create_logger("dynamic_rendezvous").info(event.serialize())
def construct_and_record_rdzv_event(
run_id: str,
message: str,
node_state: NodeState,
name: str = "",
hostname: str = "",
pid: Optional[int] = None,
master_endpoint: str = "",
local_id: Optional[int] = None,
rank: Optional[int] = None,
) -> None:
# We don't want to perform an extra computation if not needed.
if isinstance(get_logging_handler("dynamic_rendezvous"), logging.NullHandler):
return
# Set up parameters.
if not hostname:
hostname = socket.getfqdn()
if not pid:
pid = os.getpid()
# Determines which file called this function.
callstack = inspect.stack()
filename = "no_file"
if len(callstack) > 1:
stack_depth_1 = callstack[1]
filename = os.path.basename(stack_depth_1.filename)
if not name:
name = stack_depth_1.function
# Delete the callstack variable. If kept, this can mess with python's
# garbage collector as we are holding on to stack frame information in
# the inspect module.
del callstack
# Set up error trace if this is an exception
if node_state == NodeState.FAILED:
error_trace = traceback.format_exc()
else:
error_trace = ""
# Initialize event object
event = RdzvEvent(
name=f"{filename}:{name}",
run_id=run_id,
message=message,
hostname=hostname,
pid=pid,
node_state=node_state,
master_endpoint=master_endpoint,
rank=rank,
local_id=local_id,
error_trace=error_trace,
)
# Finally, record the event.
record_rdzv_event(event)
So far, the engine has been analyzed. In the next article, let's see if we can comb it comprehensively from the overall perspective.
0xFF reference
[Source code analysis] PyTorch distributed elastic training (1) -- general idea
[Source code analysis] PyTorch distributed elastic training (2) -- Start & single node process
[Source code analysis] PyTorch distributed elastic training (3) -- agent
[Source code analysis] PyTorch distributed elastic training (4) -- rendezvous architecture and logic