[source code analysis] PyTorch distributed optimizer (2) -- data parallel optimizer
catalogue
- [source code analysis] PyTorch distributed optimizer (2) -- data parallel optimizer
0x00 summary
This series introduces the distributed optimizer, which is divided into three articles: the cornerstone, the data parallel optimizer in DP/DDP/Horovod, and the PyTorch distributed optimizer, which advance in depth.
This paper introduces the optimizer in data parallel DP/DDP/Horovod.
Other PyTorch distributed articles are as follows:
Automatic differentiation of deep learning tools (1)
Automatic differentiation of deep learning tools (2)
[Source code analysis] automatic differentiation of deep learning tools (3) -- example interpretation
[Source code analysis] how PyTorch implements forward propagation (1) -- basic class (I)
[Source code analysis] how PyTorch implements forward propagation (2) -- basic classes (Part 2)
[Source code analysis] how PyTorch implements forward propagation (3) -- specific implementation
[Source code analysis] how pytoch implements backward propagation (1) -- call engine
[Source code analysis] how pytoch implements backward propagation (2) -- engine static structure
[Source code analysis] how pytoch implements backward propagation (3) -- engine dynamic logic
[Source code analysis] how PyTorch implements backward propagation (4) -- specific algorithm
[Source code analysis] PyTorch distributed (1) -- history and overview
[Source code analysis] PyTorch distributed (2) -- dataparallel (Part 1)
[Source code analysis] PyTorch distributed (3) -- dataparallel (Part 2)
[Source code analysis] PyTorch distributed (4) -- basic concept of distributed application
[Source code analysis] PyTorch distributed (5) -- overview of distributeddataparallel & how to use
[Source code analysis] PyTorch distributed (6) -- distributeddataparallel -- initialization & store
[Source code analysis] PyTorch distributed (7) -- process group of distributeddataparallel
[Source code analysis] PyTorch distributed (8) -- distributed dataparallel
[Source code analysis] PyTorch distributed (9) -- initialization of distributeddataparallel
[Source code analysis] PyTorch distributed (12) -- distributeddataparallel forward propagation
[Source code analysis] PyTorch distributed (13) -- back propagation of distributed dataparallel
[Source code analysis] PyTorch distributed Autograd (1) -- Design
[Source code analysis] PyTorch distributed autograd (2) -- RPC Foundation
[Source code analysis] PyTorch distributed Autograd (3) -- context sensitive
[Source code analysis] PyTorch distributed Autograd (4) -- how to cut into the engine
[Source code analysis] PyTorch distributed Autograd (5) -- engine (I)
[Source code analysis] PyTorch distributed Autograd (6) -- engine (Part 2)
[source code analysis] PyTorch distributed optimizer (1) -- Cornerstone
For better explanation, the code in this article will be simplified according to the specific situation.
0x01 previous review
The main function of the conventional optimizer is to use gradients for optimization, and then update the current parameters: w.data -= w.grad * lr, which is carried out strictly and orderly.
The optimizer in data parallelism is another case. Because each worker calculates the gradient itself, the main technical difficulties of the optimizer are:
- Each worker has its own optimizer? Or only one worker has an optimizer, which is optimized by him?
- If there is only one optimizer, how to combine the gradients of each worker and pass each worker to the unique optimizer?
- If each worker has its own optimizer and the local optimizer optimizes into the local model, how to ensure that the model in each worker is always consistent?
This varies with specific framework programmes.
0x02 optimizer in DP
2.1 process
In DP, we should note that PyTorch uses multi-threaded parallelism, so there is only one optimizer in the application. This optimizer is also a common type of optimizer, and its process is as follows:
- Each GPU will carry out forward calculation independently and in parallel for its own input data on a separate thread to calculate the output.
- gather output on the master GPU.
- The loss is calculated on the primary GPU.
- scatter the loss between GPUs.
- Run backward propagation on each GPU to calculate the parameter gradient.
- Merge gradient above GPU 0.
- Perform gradient descent and update the model parameters on the main GPU with the gradient.
- Copy the updated model parameters to the remaining dependent GPU s for subsequent iterations.
DP modifies the forward and backward methods to merge the gradients of each thread and optimize them. Therefore, although the data is parallel, the optimizer does not need to modify it.
2.2 use
The specific use is as follows:
model=torch.nn.DaraParallel(model);
optimizer = torch.optim.SGD(model.parameters(), args.lr,
momentum=args.momentum,
weight_decay=args.weight_decay)
for batch_idx, (data, label) in pbar:
if args.cuda:
data,label= data.cuda(),label.cuda(); # The data is placed on the default GPU
data_v = Variable(data)
target_var = Variable(label)
prediction= model(data_v,target_var,args) # Multithreaded parallel forward propagation
criterion = nn.CrossEntropyLoss()
loss = criterion(prediction,target_var) # Calculate loss on the default GPU
optimizer.zero_grad()
loss.backward() # Multithreaded parallel backward propagation
optimizer.step() # Update parametersWe give a simplified diagram as follows. Each thread performs gradient calculation. Finally, the gradient is merged into GPU 0 and optimized on GPU 0:
Forward Backward
+-------------------+ +------------------+
+-->+ Thread 0 on GPU0 +--+ +-->+ Thread 1 on GPU0 +-+
| +-------------------+ | GPU 0 | +------------------+ |
| +-------------------+ | output +---------------+ loss | +------------------+ |
+---->+ Thread 1 on GPU1 +---------> | Compute Loss +---------->+ Thread 2 on GPU1 +---+
| | +-------------------+ | +---------------+ | +------------------+ | |
| | +-------------------+ | | +------------------+ | |
| +-->+ Thread 2 on GPU2 +--+ +-->+ Thread 3 on GPU2 +-+ |
| +-------------------+ +------------------+ |
| |
| |
| GPU 0 |
| Model +-------------------------+ gradient |
+--------------------------+ optimizer.step | <--------------------------------+
+-------------------------+0x03 optimizer in DDP
The following is a quick essay from the Kwai eight diagrams, which shows the comparison between native training and DDP/Horovod.
- vanilla above is the native training process, and part U corresponds to the optimizer process. The main function of the general optimizer is to update the current parameters of the model according to the gradient: w.data -= w.grad * lr.
- The following part is the DDP/Horovod optimization process. It can be seen that the backward calculation and merging gradient are partially parallel.
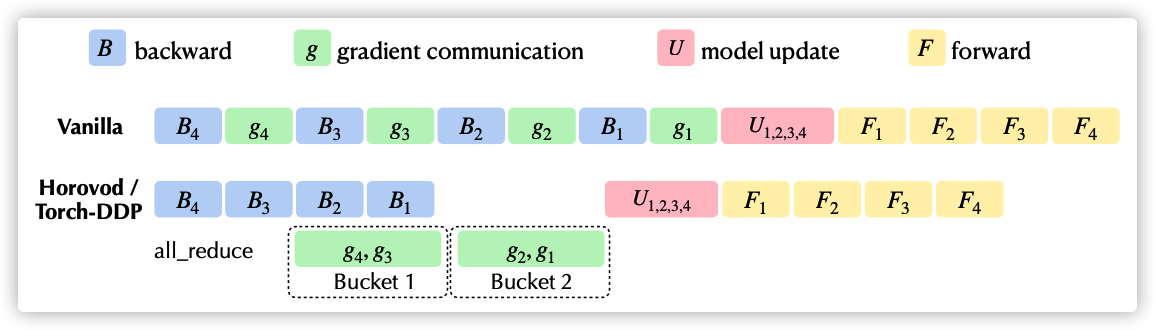
3.1 process
In DDP, the common optimizer is still used, but the multi process method is adopted. Each process completes the whole process of training, but all reduce needs to be used to merge the gradient in backward calculation. Each process has its own independent optimizer, which is also a regular optimizer.
There are two characteristics:
- Each process maintains its own optimizer and performs a complete optimization step in each iteration. Although this may seem redundant, since the gradient has been aggregated and averaged across processes, the gradient is the same for each process, which means that there is no need for parameter broadcasting steps and reduces the time spent transmitting tensors between nodes.
- The all reduce operation is completed in backward propagation.
- During DDP initialization, a Reducer will be generated and autograd will be registered internally_ hook.
- autograd_hook performs gradient synchronization during back propagation.
DDP is modified from the perspective of PyTorch kernel and handled in the initialization and forward operation of distributed dataparallel model.
The specific logic is as follows:
- DDP uses multiple processes to load data in parallel. On the host, each worker process will load data from the hard disk into page locked memory. The distributed minibatch sampler ensures that the data loaded by each process does not overlap each other.
- Instead of broadcasting data, minibatch data is loaded from page locked memory into each GPU in parallel. Each GPU has a copy of the model, so there is no need to copy the model.
- Run forward propagation and calculate output on each GPU. Each GPU performs the same training without a master GPU.
- Calculate the loss on each GPU, run backward propagation to calculate the gradient, and perform all reduce on the gradient at the same time.
- Update model parameters. Because each GPU starts training from exactly the same model, and the gradient is all reduced, each GPU finally gets the same copy of the average gradient at the end of back propagation, and the weight updates on all GPUs are the same, so that the models on all worker s are consistent, and model synchronization is not required.
Because it is also modified in the forward and backward operations of the model, the optimizer does not need to modify it. Each worker optimizes in its own local process.
3.2 optimizer status
Here, we should pay attention to how to ensure that the optimizer state of each process is the same?
DDP is not actually associated with the optimizer, and DDP is not responsible for it. Therefore, users need to cooperate to ensure that the optimizer status between processes is the same. This revolves around two links:
- The optimizer parameters have the same initial values.
- The initial value of the optimizer is the same, which is ensured by "the user initializes the optimizer after the DDP model is created".
- The optimizer parameters have the same value each time they are updated.
- Each updated gradient is all reduced, so the gradient delta value obtained by each optimizer is the same.
3.3 use
Examples are as follows:
model = ToyModel().to(rank) # Construct DDP model ddp_model = DDP(model, device_ids=[rank]) loss_fn = nn.MSELoss() # The optimizer cannot be initialized until the DDP model is constructed. optimizer = optim.SGD(ddp_model.parameters(), lr=0.001) optimizer.zero_grad() outputs = ddp_model(torch.randn(20, 10)) labels = torch.randn(20, 5).to(rank) loss_fn(outputs, labels).backward() optimizer.step()
The diagram is as follows:
+--------------------------------------------------------------------------------------+
| Process 1 on GPU 1 |
| +------------------------------+ |
| | Backward | |
| | | |
| Forward +----> Loss +-----> | Compute +----> ALL+REDUCE | +----> Optimizer.step |
| | ^ | |
| | | | |
| +------------------------------+ |
| | |
| | |
+--------------------------------------------------------------------------------------+
|
|
|
|
+
SYNC GRADS
+
|
|
|
+--------------------------------------------------------------------------------------+
| Process 2 on GPU 2 | |
| | |
| +------------------------------+ |
| | Backward | | |
| | v | |
| Forward +----> Loss +-----> | Compute +----> ALL+REDUCE | +----> Optimizer.step |
| | | |
| | | |
| +------------------------------+ |
| |
+--------------------------------------------------------------------------------------+0x04 optimizer for horovod
Horovod did not modify the model fw/bw (perhaps because it was not as easy as Facebook's own modification), but modified the optimizer to implement a distributed optimizer.
We use horovod / Torch / optimizer Py as an example.
An optimizer that wraps another torch.optim.Optimizer, using an allreduce to combine gradient values before applying gradients to model weights. Allreduce operations are executed after each gradient is computed by ``loss.backward()`` in parallel with each other. The ``step()`` method ensures that all allreduce operations are finished before applying gradients to the model.
DistributedOptimizer wraps another torch optim. Optimizer, which is used to:
- Execute loss. In parallel in worker After backward() calculates each gradient, use allreduce to merge the gradients at the time point "before applying the gradient to the model weight".
- Use the step() method to ensure that all allreduce operations are completed before the gradient is applied to the model.
The specific implementation is _DistributedOptimizer, and _distributedoptimizerhas two ways to merge gradients, one is through hook, and the other is to explicitly call the synchronize function. We will introduce it one by one.
4.1 hook synchronization gradient
Hook uses PyTorch's hook method, which is very similar to DDP's idea, that is, it registers hook on the gradient calculation function. Its function is to call hook after computing the gradient, so all-reduce is automatically completed in the calculation of gradient process, and it does not need to wait for step method to make explicit call (similar to DP).
- Calculate the loss on each GPU, run backward propagation to calculate the gradient, and perform all reduce on the gradient at the same time.
- Update model parameters. Because each GPU starts training from the same model and the gradient is all reduced, each GPU finally gets the same copy of the average gradient at the end of back propagation. The weight updates on all GPUs are the same, so model synchronization is not required.
Note: the code is mainly divided into two parts, dealing with groups related and general situations.
groups is the related configuration of PyTorch. It is used to carry out gradient allreduce operations together. Because the code is complex and not related to the main logic of this article, we skip this part and only look at ordinary non grouping situations.
groups: The parameter to group the gradient allreduce ops. Accept values is a
non-negative integer or a list of list of tf.Variable.
If groups is a non-negative integer, it is the number of groups to assign
gradient allreduce ops to for explicit grouping.
If groups is a list of list of tf.Variable. Variables in the same
inner list will be assigned to the same group, while parameter that does
not appear in any list will form a group itself.
Defaults as None, which is no explicit groups.4.1.1 register hooks
The Hook function is divided into two steps. The first part is to register hooks.
def _register_hooks(self):
if self._groups is not None: # groups, interested students can study by themselves, which can be understood as grouping gradients
p_list = []
# Get list of parameters with grads
for param_group in self.param_groups:
for p in param_group['params']:
if p.requires_grad:
p_list.append(p)
# To ensure parameter order and group formation is consistent, broadcast p_list order
# from rank 0 and use for every worker
p_list_names = [self._parameter_names.get(p) for p in p_list]
p_list_names = broadcast_object(p_list_names, root_rank=0)
p_list = sorted(p_list, key=lambda p : p_list_names.index(self._parameter_names.get(p)))
# Form groups
if isinstance(self._groups, list):
p_groups = []
grouped_id = set()
p_list_ids = [id(p) for p in p_list]
for group in self._groups:
p_groups.append([p for p in group if id(p) in p_list_ids])
for p in p_groups[-1]:
grouped_id.add(id(p))
for p in p_list:
if id(p) not in grouped_id:
p_groups.append([p])
else:
p_groups = split_list(p_list, self._groups)
p_groups = [tuple(p) for p in p_groups]
for group in p_groups:
for p in group:
self._p_to_group[p] = group
self._group_counts[group] = 0
# Register hooks
for param_group in self.param_groups: # Traversal group
for p in param_group['params']: # Traversing parameters in a group
if p.requires_grad: # If necessary, calculate the gradient
p.grad = p.data.new(p.size()).zero_()
self._requires_update.add(p)
p_tmp = p.expand_as(p)
grad_acc = p_tmp.grad_fn.next_functions[0][0] # Get gradient function
grad_acc.register_hook(self._make_hook(p)) # Register hook on gradient function
self._grad_accs.append(grad_acc)_make_hook will build hooks and return the hook function, which will be called during back propagation and execute all reduce internally.
def _make_hook(self, p):
def hook(*ignore):
# Omit some codes
handle, ctx = None, None
self._allreduce_delay[p] -= 1
if self._allreduce_delay[p] == 0:
if self._groups is not None: # We'll skip dealing with groups
group = self._p_to_group[p]
self._group_counts[group] += 1
if self._group_counts[group] == len(group):
handle, ctxs = self._grouped_allreduce_grad_async(group) # All reduce will be performed when called
self._handles[group] = (handle, ctxs)
# Remove any None entries from previous no-op hook calls
for gp in group:
self._handles.pop(gp, None)
self._group_counts[group] = 0
return
else:
handle, ctx = self._allreduce_grad_async(p) # All reduce will be performed when called
self._handles[p] = (handle, ctx) # Register the handle locally and use it later
return hook4.1.2 merge gradient
The second stage is merging, that is, in the back propagation stage, the hook function is called for all reduce.
def _allreduce_grad_async(self, p):
name = self._parameter_names.get(p)
tensor = p.grad
tensor_compressed, ctx = self._compression.compress(tensor)
if self.op == Average:
# Split average operation across pre/postscale factors
# C++ backend will apply additional 1 / size() factor to postscale_factor for op == Average.
prescale_factor = 1.0 / self.gradient_predivide_factor
postscale_factor = self.gradient_predivide_factor
else:
prescale_factor = 1.0
postscale_factor = 1.0
# Call allreduce_async_ to complete the MPI call
handle = allreduce_async_(tensor_compressed, name=name, op=self.op,
prescale_factor=prescale_factor,
postscale_factor=postscale_factor)
return handle, ctx
def _grouped_allreduce_grad_async(self, ps):
name = self._parameter_names.get(ps[0])
tensors_compressed, ctxs = zip(*[self._compression.compress(p.grad) for p in ps])
handle = grouped_allreduce_async_(tensors_compressed, name=name, op=self.op)
return handle, ctxs4.1.2.1 MPI function
The specific MPI functions are located in horovod/torch/mpi_ops.py
The key point here is: allreduce_async_returns a handle that can be controlled later, such as poll or synchronize.
def allreduce_async_(tensor, average=None, name=None, op=None,
prescale_factor=1.0, postscale_factor=1.0):
"""
A function that performs asynchronous in-place averaging or summation of the input
tensor over all the Horovod processes.
The reduction operation is keyed by the name. If name is not provided, an incremented
auto-generated name is used. The tensor type and shape must be the same on all
Horovod processes for a given name. The reduction will not start until all processes
are ready to send and receive the tensor.
Arguments:
tensor: A tensor to reduce.
average:
.. warning:: .. deprecated:: 0.19.0
Use `op` instead. Will be removed in v0.21.0.
name: A name of the reduction operation.
op: The reduction operation to combine tensors across different ranks. Defaults to
Average if None is given.
prescale_factor: Multiplicative factor to scale tensor before allreduce.
postscale_factor: Multiplicative factor to scale tensor after allreduce.
Returns:
A handle to the allreduce operation that can be used with `poll()` or
`synchronize()`.
"""
op = handle_average_backwards_compatibility(op, average)
return _allreduce_async(tensor, tensor, name, op, prescale_factor, postscale_factor)_allreduce_async is located in horovod/torch/mpi_ops.py, which extracts functions from the MPI library for processing.
def _allreduce_async(tensor, output, name, op, prescale_factor, postscale_factor):
# Set the divisor for reduced gradients to average when necessary
if op == Average:
if rocm_built():
# For ROCm, perform averaging at framework level
divisor = size()
op = Sum
else:
divisor = 1
elif op == Adasum:
if tensor.device.type != 'cpu' and gpu_available('torch'):
if nccl_built():
if rocm_built():
# For ROCm, perform averaging at framework level
divisor = local_size()
else:
divisor = 1
else:
divisor = 1
else:
divisor = 1
else:
divisor = 1
function = _check_function(_allreduce_function_factory, tensor)
try:
handle = getattr(mpi_lib, function)(tensor, output, divisor,
name.encode() if name is not None else _NULL, op,
prescale_factor, postscale_factor)
except RuntimeError as e:
raise HorovodInternalError(e)
_handle_map[handle] = (tensor, output)
return handle4.1.2.2 schematic diagram
This figure is similar to DDP, so it is omitted.
4.2 step synchronization gradient
step is another way to perform all reduce operations.
The step function is defined as follows. You can see that if forced synchronization is required, call self.synchronize(), otherwise call the step function of the base class to update the parameters.
def step(self, closure=None):
if self._should_synchronize:
if self._synchronized:
warnings.warn("optimizer.step() called without "
"optimizer.skip_synchronize() context after "
"optimizer.synchronize(). This can cause training "
"slowdown. You may want to consider using "
"optimizer.skip_synchronize() context if you use "
"optimizer.synchronize() in your code.")
self.synchronize()
self._synchronized = False
return super(self.__class__, self).step(closure)4.2.1 synchronize
Synchronization is mentioned above. Let's study it carefully.
As you can see from the comments, synchronize() is used to force the allreduce operation to complete, which is important for gradient clipping clipping () or other operations with in place gradient modification are particularly useful. These operations need to be completed before step().
Synchronize() needs to work with optimizer.skip_synchronize().
DistributedOptimizer exposes the ``synchronize()`` method, which forces allreduce operations to finish before continuing the execution. It's useful in conjunction with gradient clipping, or other operations that modify gradients in place before ``step()`` is executed. Make sure to use ``optimizer.skip_synchronize()`` if you're calling ``synchronize()`` in your code.
4.2.2 gradient cutting
First of all, we should understand what is gradient explosion. Gradient explosion refers to that in the process of model training, because the gradient becomes too large and makes the model unstable, it is easy to skip the optimal solution directly. gradient clipping It is a technology to solve gradient explosion: if the gradient becomes too large, adjust it to keep it small, so as to avoid the model from crossing the best point.
In order to cooperate with gradient clipping, we need to call synchronize before step to force all-reduce to complete. Examples in the source code are as follows:
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.synchronize()
torch.nn.utils.clip_grad_norm_(model.parameters(), args.clip)
with optimizer.skip_synchronize():
optimizer.step()4.2. 3 Implementation
Let's look at the implementation of synchronize. The most important thing here is that outputs = synchronize(handle) calls horovod torch. mpi_ ops. Synchronize completes the synchronization operation, which is easy to be misunderstood by novices. Because the names are the same, it is easy to be misunderstood as recursion.
from horovod.torch.mpi_ops import synchronize
def synchronize(self):
completed = set()
for x in self._handles.keys():
completed.update(x) if isinstance(x, tuple) else completed.add(x)
missing_p = self._requires_update - completed # Find the gradient that has not been calculated at present
for p in missing_p:
handle, ctx = self._allreduce_grad_async(p) # For those that have not been calculated, explicitly perform all reduce
self._handles[p] = (handle, ctx) # Record the handle of this calculation
for p, (handle, ctx) in self._handles.items():
if handle is None: # If there is no record, all reduce has been called
handle, ctx = self._allreduce_grad_async(p) # Perform all reduce
self._handles[p] = (handle, ctx)
for p, (handle, ctx) in self._handles.items(): # Finally, synchronize uniformly!
if isinstance(p, tuple):
# This was a grouped result, need to unpack
outputs = synchronize(handle) # Call mpi synchronization operation
for gp, output, gctx in zip(p, outputs, ctx):
self._allreduce_delay[gp] = self.backward_passes_per_step
gp.grad.set_(self._compression.decompress(output, gctx))
else:
output = synchronize(handle) # Call mpi synchronization operation
self._allreduce_delay[p] = self.backward_passes_per_step
p.grad.set_(self._compression.decompress(output, ctx))
self._handles.clear()
self._synchronized = True4.2.4 MPI synchronous operation
The code is located in horovod/torch/mpi_ops.py, which directly calls the MPI library function. Interested students can study it in depth by themselves.
def synchronize(handle):
"""
Synchronizes an asynchronous allreduce, allgather or broadcast operation until
it's completed. Returns the result of the operation.
Arguments:
handle: A handle returned by an allreduce, allgather or broadcast asynchronous
operation.
Returns:
An output tensor of the operation.
"""
if handle not in _handle_map:
return
try:
mpi_lib.horovod_torch_wait_and_clear(handle)
output = _handle_map.pop(handle)[-1]
return output
except RuntimeError as e:
raise HorovodInternalError(e)4.2. 5 Diagram
The current logic is shown in the figure below:
+---------------------------------------------------------------------------------+
| Process 1 on GPU 1 |
| +----------------------------+ |
| | Optimizer | |
| | | |
| Forward +----> Loss +-----> Backward +----> | ALL-REDUCE +----> step | |
| | | |
| | ^ | |
| | | | |
| +----------------------------+ |
| | |
+---------------------------------------------------------------------------------+
|
|
|
|
|
SYNC|GRADS
|
|
|
|
+----------------------------------------------------------------------------------+
| Process 2 on GPU 2 | |
| | |
| +-----------------------------+ |
| | Optimizer | | |
| | | | |
| Forward +----> Loss +-----> Backward +----> | v | |
| | ALL-REDUCE +----> step | |
| | | |
| +-----------------------------+ |
| |
+----------------------------------------------------------------------------------+So far, the analysis of the data parallel optimizer has been completed. In the next article, we will introduce the PyTorch distributed optimizer. Please look forward to it.
0xFF reference
torch.optim.optimizer source code reading and flexible use
pytorch source code reading (II) optimizer principle
Summary and comparison of various optimization methods (sgd/momentum/Nesterov/adagrad/adadelta)
[optimizer] optimizer algorithm and PyTorch implementation (I): Eternal SGD
With optim Take SGD as an example to introduce the pytorch optimizer
Pytoch learning notes 08 --- detailed explanation of Optimizer algorithm (SGD, Adam)
Detailed explanation of pytorch optimizer: SGD
addmm() and addmm in pytoch_ Detailed explanation of () usage