Pan Chuang AI sharing
Author | Md Sohel Mahmood Compile | VK Source: Towards Data Science
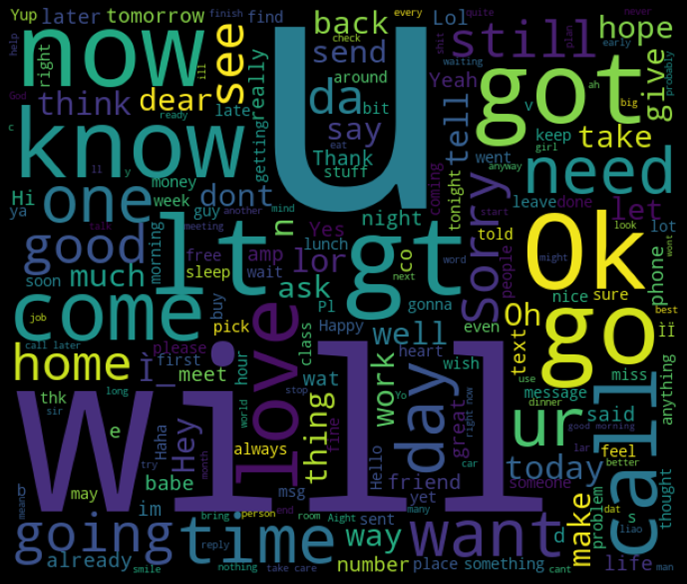
Spam detection is an important application of machine learning algorithm in filtering spam. In the field of natural language processing, several algorithms can be used for such classification. Usually spam has some typical words.
In this article, we will use the nltk package to introduce spam and non spam text processing in detail. In particular, we will see the stem analysis and morphological reduction process of NLP. We will also implement NB classifier, SVC and random forest classifier to detect spam, and compare the accuracy of the classifier. Let's start.
According to the nltk document, "nltk is the leading platform for building Python programs to process human language data". Using nltk to process and mark up text is very simple, such as stemming and morphological reduction, which we will see later.
First, we need to import the necessary packages.
import numpy as np import pandas as pd import nltk from nltk.corpus import stopwords import matplotlib.pyplot as plt from wordcloud import WordCloud, ImageColorGenerator from PIL import Image import re from nltk.tokenize import word_tokenize as wt from nltk.stem.porter import PorterStemmer from nltk.stem import WordNetLemmatizer
Data label
After importing the csv file containing spam and non spam tag text, I created two data frames: one for real email and the other for spam, which we will use for analysis.
spam_data = spam[spam['label'] == 'spam'] real_data = spam[spam['label'] == 'ham']
Stem analysis and form reduction
Let's do stem analysis first, and then restore their forms. According to Stanford NLP team, "stemming analysis usually refers to a rough heuristic process, that is, cutting off the suffix, hoping to achieve this goal correctly in most cases, usually including removing derived affixes.
Word form reduction usually refers to the correct handling of things by using vocabulary and word form analysis. Usually, the purpose is to remove the ending of word form changes and return the basic form or dictionary form of a word, which is called word form. "Here, stem analysis is applied to all data, spam data and real data respectively.
all_data_stem = []
spam_data_stem = []
real_data_stem = []
stemmer = PorterStemmer()
for i in range(spam.shape[0]):
sms = spam.iloc[i, 1]
sms = re.sub('[^A-Za-z]', ' ', sms)
sms = sms.lower()
tokenized_sms = wt(sms)
sms_processed = []
for word in tokenized_sms:
if word not in set(stopwords.words('english')):
sms_processed.append(stemmer.stem(word))
sms_text = " ".join(sms_processed)
all_data_stem.append(sms_text)
for i in range(spam_data.shape[0]):
sms = spam_data.iloc[i, 1]
sms = re.sub('[^A-Za-z]', ' ', sms)
sms = sms.lower()
tokenized_sms = wt(sms)
sms_processed = []
for word in tokenized_sms:
if word not in set(stopwords.words('english')):
sms_processed.append(stemmer.stem(word))
sms_text = " ".join(sms_processed)
spam_data_stem.append(sms_text)
for i in range(real_data.shape[0]):
sms = real_data.iloc[i, 1]
sms = re.sub('[^A-Za-z]', ' ', sms)
sms = sms.lower()
tokenized_sms = wt(sms)
sms_processed = []
for word in tokenized_sms:
if word not in set(stopwords.words('english')):
sms_processed.append(stemmer.stem(word))
sms_text = " ".join(sms_processed)
real_data_stem.append(sms_text)
all_data_stem[0]
Then word form restoration is applied to all data, spam data and real data respectively.
all_data_lemma = []
spam_data_lemma = []
real_data_lemma = []
lemmatizer = WordNetLemmatizer()
for i in range(spam.shape[0]):
sms = spam.iloc[i, 1]
sms = re.sub('[^A-Za-z]', ' ', sms)
sms = sms.lower()
tokenized_sms = wt(sms)
sms_processed = []
for word in tokenized_sms:
if word not in set(stopwords.words('english')):
sms_processed.append(lemmatizer.lemmatize(word))
sms_text = " ".join(sms_processed)
all_data_lemma.append(sms_text)
for i in range(spam_data.shape[0]):
sms = spam_data.iloc[i, 1]
sms = re.sub('[^A-Za-z]', ' ', sms)
sms = sms.lower()
tokenized_sms = wt(sms)
sms_processed = []
for word in tokenized_sms:
if word not in set(stopwords.words('english')):
sms_processed.append(lemmatizer.lemmatize(word))
sms_text = " ".join(sms_processed)
spam_data_lemma.append(sms_text)
for i in range(real_data.shape[0]):
sms = real_data.iloc[i, 1]
sms = re.sub('[^A-Za-z]', ' ', sms)
sms = sms.lower()
tokenized_sms = wt(sms)
sms_processed = []
for word in tokenized_sms:
if word not in set(stopwords.words('english')):
sms_processed.append(lemmatizer.lemmatize(word))
sms_text = " ".join(sms_processed)
real_data_lemma.append(sms_text)
all_data_lemma[0]
If we look at the stemming analysis of the first data text, we will get:
'go jurong point crazi avail bugi n great world la e buffet cine got amor wat'.
Word form restore provides:
'go jurong point crazy available bugis n great world la e buffet cine got amore wat'
It is obvious from the first batch of data that stem analysis and morphological reduction work in different ways. For example, the stem of the word "availability" is "available", but the word form is "available".
Wordcloud
After marking with numbers, let's create a wordcloud to see the most common words.
spam['num_label'] = spam['label'].map({'ham': 0, 'spam': 1})
spam_words = ' '.join(list(spam[spam['num_label'] == 1]['text']))
spam_wc = WordCloud(width = 600,height = 512).generate(spam_words)
plt.figure(figsize = (12, 8), facecolor = 'k')
plt.imshow(spam_wc)
plt.axis('off')
plt.tight_layout(pad = 0)
plt.show()

There are many attractive words in spam, while the text in real e-mail is very random, as shown below.

frequency distribution
We may be interested in looking at the most commonly used words in spam. It can be obtained by the following frequency distribution
from nltk import FreqDist spam_token = nltk.tokenize.word_tokenize(spam_words) spam_freq = FreqDist(spam_token) spam_freq
FreqDist({'.': 1004, 'to': 608, '!': 542, ',': 371, 'a': 358, 'you': 189, 'call': 187, 'your': 187, 'or': 185, '&': 178, ...})
At other times, we may be interested in focusing on the most common parts of repeated sentences in spam.
FreqDist(spam_data_lemma).most_common(5)
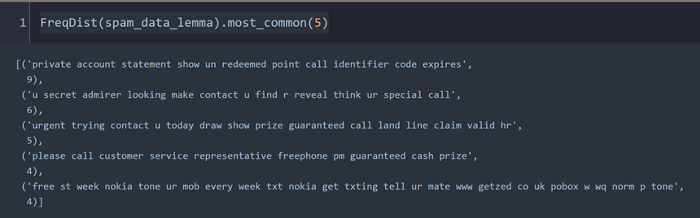
Obviously, sentence parts such as "private account statement" or "secret admirer" are one of the most attractive phrases in spam.
Discrete graph
We can get the dispersion diagram of the target words to see the distribution. It will provide information about the occurrence of a specific word based on the total number of words. I chose the words "free", "private", "account", "contact" as the presentation words.

classifier
Here, I created a classifier from the scikit learn library. We need to convert the text into a token count matrix. The CountVectorizer of scikit learn is very convenient.
We will first try the NaiveBayes function, which is easy to implement and has shorter training time. In order to facilitate training, I chose 80% of the data.
from sklearn.feature_extraction.text import CountVectorizer from sklearn.model_selection import train_test_split matrix = CountVectorizer(max_features=1000) X = matrix.fit_transform(all_data_lemma).toarray() y = spam.iloc[:, 0] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2) from sklearn.naive_bayes import GaussianNB classifier = GaussianNB() classifier.fit(X_train, y_train) from sklearn.metrics import confusion_matrix, classification_report, accuracy_score y_pred = classifier.predict(X_test) cm = confusion_matrix(y_test, y_pred) rep = classification_report(y_test, y_pred)

Accuracy is the ratio of TP (true positive) to the sum of TP and FP (false positive). Recall rate is the ratio of TP to the sum of TP and FN (false negative). If a real spam is mistakenly recognized as a real email, it is a false positive. On the other hand, if a real email is identified as spam, it is false negative.
The report shows that the model performs well in detecting real mail, but not in detecting SPAM. The accuracy of SPAM is ~ 0.38, indicating that a large number of false positives are obtained from the model.
Although the accuracy of the model is 0.79, it may be misleading. The recall rate of spam is high and the accuracy is low. This shows that the model is biased towards spam. It can correctly identify most spam, but it also mistakenly identifies some normal emails as spam.
array([[744, 224],
[ 12, 135]], dtype=int64)
The confusion matrix shows a similar scenario. There are no large numbers on the diagonal. This means that the performance is not good enough for naive Bayes.
Let's try support vector classification and random forest algorithm.
from sklearn.svm import SVC classifier = SVC() classifier.fit(X_train, y_train) y_pred = classifier.predict(X_test) cm = confusion_matrix(y_test, y_pred) rep = classification_report(y_test, y_pred)

The performance of the model is good. The accuracy and recall rate of normal and spam are very high. Finally, let's try to use random forest as classifier.
from sklearn.ensemble import RandomForestClassifier classifier = RandomForestClassifier() classifier.fit(X_train, y_train) y_pred = classifier.predict(X_test) cm = confusion_matrix(y_test, y_pred) rep = classification_report(y_test, y_pred)

In this spam detection case, Random Forest is also a good classifier, which can provide high precision and recall for real and spam.
conclusion
In this paper, nltk library is used to demonstrate the process of word stem analysis and word form restoration of NLP, and several binary classifier algorithms are compared.
Naive Bayes has lower accuracy, while SVC and random forest provide higher accuracy, recall and accuracy.
Cross validation techniques can be used to evaluate the skills of these classifiers. Now, there are many open source platforms that can be trained or cross validated without any code, which I will discuss in another article.
Github provides code blocks: https://mdsohelmahmood.github.io/2021/06/23/Spam-email-classification-using-NB-SVC-Random-Forest.html
Thanks for reading!