preface
With the rapid development of wechat, communication in work and life also depends more on it. However, due to the formality and standardization of e-mail, it is still irreplaceable. However, whether it is the internal work mailbox or personal mailbox of the enterprise, it always receives all kinds of spam, including merchants' advertising, discount and promotion information, Macao gambling email, financial promotion information and so on. No matter how to classify spam, there are always missed fish. Most importantly, different users have different definitions of spam.
Moreover, most users' awareness of network security is relatively general. In case of delayed spam, or because spam drowns the key letters at work, it will cause losses to individuals or enterprises.
Spam identification has always been a pain point and difficulty. Although the method is nothing more than Bayesian learning, probability statistics or deep learning, due to the diversity of business scenarios, there are too many spam patterns, so the traditional spam interceptors can't keep up.
Therefore, we intend to gradually try various methods to identify and classify spam for the same data set - we hope that over time, this customized spam identification tool can greatly improve the user's email experience.
1, Overall thinking
In general, an email can be divided into sender, receiver, CC, subject, time, content and other elements, so it is natural to think that spam judgment is mainly based on the sender, subject and content of the above elements.
Therefore, we analyze the above elements in turn:
- Spam content classification (judged by extracting spam content)
- Chinese spam classification
- English spam classification
- Spam header classification
- Spam sender classification
Finally, we can make a comprehensive evaluation according to these three dimensions, so as to realize the accurate classification of spam. This paper will classify spam according to the content of e-mail.
2, Implementation steps of Chinese mail content classification
1. Data set introduction
TREC 2006 Spam Track Public Corpora First, we choose TREC 2006 Spam Track Public Corpora This is an open spam corpus. The corpus is provided by the international text retrieval conference and is divided into English data set (trec06p) and Chinese data set (trec06c). The emails contained in it are all from real emails and retain the original format and content of emails.
File directory form: delay and full are filtering mechanisms of spam filter respectively. Under the full directory, it is an ideal email classification result, which can be regarded as the research label.
trec06c
│
└───data
│ │ 000
│ │ 001
│ │ ...
│ └───215
└───delay
│ │ index
└───full
│ │ index
2. Data loading
2.1 extract mail elements from eml format and store them as csv
At present, the data set is stored in the form of e-mail and marked with spam through index, so we first extract the sender, recipient, CC, subject, sending time, content and whether spam label of each e-mail.
mailTable=pd.DataFrame(columns=('Sender','Receiver','CarbonCopy','Subject','Date','Body','isSpam'))
# path='trec06p/full/../data/000/004'
# emlContent= emlAnayalyse(path)
# print(emlContent)
f = open('trec06c/full/index', 'r')
csvfile=open('mailChinese.csv','w',newline='',encoding='utf-8')
writer=csv.writer(csvfile)
for line in f:
str_list = line.split(" ")
print(str_list[1])
# Set the spam tag to 0
if str_list[0] == 'spam':
label = '0'
# Set the normal mail label to 1
elif str_list[0] == 'ham':
label = '1'
emlContent= emlAnayalyse('trec06c/full/' + str(str_list[1].split("\n")[0]))
if emlContent is not None:
writer.writerow([emlContent[0],emlContent[1],emlContent[2],emlContent[3],emlContent[4],emlContent[5],label])The emlAnayalyze function uses the mime in the flanker library to extract the sender, recipient, CC, subject, sending time, content and other elements in the email. For details, please refer to my article python several lines of code to achieve mail parsing_ Yunlord's blog - CSDN blog_ flanker mail parsing , and then save it as csv to facilitate subsequent email analysis.
2.2 extract mail content from csv for classification
def get_data(path):
'''
get data
:return: Text data, corresponding to labels
'''
maildf = pd.read_csv(path,header=None, names=['Sender','Receiver','"CarbonCopy','Subject','Date','Body','isSpam'])
filteredmaildf=maildf[maildf['Body'].notnull()]
corpus=filteredmaildf['Body']
labels=filteredmaildf['isSpam']
corpus=list(corpus)
labels=list(labels)
return corpus, labelsThrough get_ The data function reads the data in csv format, and extracts the data whose content is not empty and the corresponding label.

You can see a total of 40348 data.
from sklearn.model_selection import train_test_split
# Divide the data
train_corpus, test_corpus, train_labels, test_labels = train_test_split(corpus, labels,
test_size=0.3, random_state=0)And then through sklearn model_ Train in selection Library_ test_ Split function divides training set and verification set.
# Normalize norm_train_corpus = normalize_corpus(train_corpus) norm_test_corpus = normalize_corpus(test_corpus)
Then through normalize_ The corpus function preprocesses the data.
def textParse(text):
listOfTokens=jieba.lcut(text)
newList=[re.sub(r'\W*','',s) for s in listOfTokens]
filtered_text=[tok for tok in newList if len(tok)>0]
return filtered_text
def remove_stopwords(tokens):
filtered_tokens = [token for token in tokens if token not in stopword_list]
filtered_text = ' '.join(filtered_tokens)
return filtered_text
def normalize_corpus(corpus, tokenize=False):
normalized_corpus = []
for text in corpus:
filtered_text = textParse(filtered_text)
filtered_text = remove_stopwords(filtered_text)
normalized_corpus.append(filtered_text)
return normalized_corpusIt includes textParse and remove_stopwords are two data preprocessing operations.
The textParse function first performs word segmentation through jieba, and then removes useless characters.
remove_ The stopwords function first loads stop_words.txt stop word list, and then remove stop words.
So as to realize data preprocessing.
2.3 # construct word vector
# Characteristics of word bag model bow_vectorizer, bow_train_features = bow_extractor(norm_train_corpus) bow_test_features = bow_vectorizer.transform(norm_test_corpus) # tfidf features tfidf_vectorizer, tfidf_train_features = tfidf_extractor(norm_train_corpus) tfidf_test_features = tfidf_vectorizer.transform(norm_test_corpus)
Including bow_extractor,tfidf_ The two functions of extractor transform the training set into word bag model features and TFIDF features respectively.
from sklearn.feature_extraction.text import CountVectorizer
def bow_extractor(corpus, ngram_range=(1, 1)):
vectorizer = CountVectorizer(min_df=1, ngram_range=ngram_range)
features = vectorizer.fit_transform(corpus)
return vectorizer, features
from sklearn.feature_extraction.text import TfidfTransformer
def tfidf_transformer(bow_matrix):
transformer = TfidfTransformer(norm='l2',
smooth_idf=True,
use_idf=True)
tfidf_matrix = transformer.fit_transform(bow_matrix)
return transformer, tfidf_matrix
from sklearn.feature_extraction.text import TfidfVectorizer
def tfidf_extractor(corpus, ngram_range=(1, 1)):
vectorizer = TfidfVectorizer(min_df=1,
norm='l2',
smooth_idf=True,
use_idf=True,
ngram_range=ngram_range)
features = vectorizer.fit_transform(corpus)
return vectorizer, features
2.4 training model and evaluation
For the above two different vector representations, Bayesian classifier, logistic regression classifier and support vector machine classifier are trained respectively to verify the effect.
from sklearn.naive_bayes import MultinomialNB
from sklearn.linear_model import SGDClassifier
from sklearn.linear_model import LogisticRegression
mnb = MultinomialNB()
svm = SGDClassifier(loss='hinge', n_iter_no_change=100)
lr = LogisticRegression()
# Multinomial naive Bayes based on word bag model
print("Bayesian classifier based on the features of word bag model")
mnb_bow_predictions = train_predict_evaluate_model(classifier=mnb,
train_features=bow_train_features,
train_labels=train_labels,
test_features=bow_test_features,
test_labels=test_labels)
# Logistic regression based on the characteristics of word bag model
print("Logistic regression based on the characteristics of word bag model")
lr_bow_predictions = train_predict_evaluate_model(classifier=lr,
train_features=bow_train_features,
train_labels=train_labels,
test_features=bow_test_features,
test_labels=test_labels)
# Support vector machine method based on word bag model
print("Support vector machine based on word bag model")
svm_bow_predictions = train_predict_evaluate_model(classifier=svm,
train_features=bow_train_features,
train_labels=train_labels,
test_features=bow_test_features,
test_labels=test_labels)
joblib.dump(svm, 'svm_bow.pkl')
# Polynomial naive Bayesian model based on tfidf
print("be based on tfidf Bayesian model")
mnb_tfidf_predictions = train_predict_evaluate_model(classifier=mnb,
train_features=tfidf_train_features,
train_labels=train_labels,
test_features=tfidf_test_features,
test_labels=test_labels)
# Logistic regression model based on tfidf
print("be based on tfidf Logistic regression model")
lr_tfidf_predictions=train_predict_evaluate_model(classifier=lr,
train_features=tfidf_train_features,
train_labels=train_labels,
test_features=tfidf_test_features,
test_labels=test_labels)
# Support vector machine model based on tfidf
print("be based on tfidf Support vector machine model")
svm_tfidf_predictions = train_predict_evaluate_model(classifier=svm,
train_features=tfidf_train_features,
train_labels=train_labels,
test_features=tfidf_test_features,
test_labels=test_labels)The output results are as follows
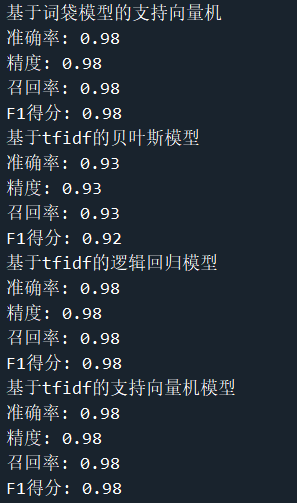
summary
Through the training of different models according to the mail content and transformed into two different word vectors, the support vector machine model based on tfidf has the best effect and can achieve 98% accuracy.
This article is Mail identification from scratch The second in a series of articles, I hope you can give me more support!
reference resources: