spark advanced (V): use of DataFrame and DataSet
DataFrame is a programming abstraction provided by Spark SQL. Similar to RDD, it is also a distributed data collection. But different from RDD, the data of DataFrame is organized into named columns, just like tables in relational database. In addition, a variety of data can be transformed into DataFrame, such as RDD generated during Spark calculation, structured data file, table in Hive, external database, etc.
In Spark, a DataFrame represents a Dataset whose element type is Row, that is, DataFrame is only a type alias of Dataset[Row]. Compared with RDD, Dataset provides strong type support and adds type constraints to each Row of data in RDD. Moreover, using Dataset API will also be optimized by Spark SQL optimizer, so as to improve program execution efficiency.
The data structures and operations of DataFrame and R and python pandas DataFrame are basically the same.
1, Create DataFrame, DataSet
- Create RDD
- RDD to ROW
- Generate DataFrame through ROW and metadata information
- Then it is transformed into DataSet through DataFrame and corresponding class
- That is, the DataFrame is a DataSet[Row], which can be converted through the specified class, DataSet[User]
- One thing to note is that when converting the class used, the internal class is required, and then the variable name in the class should be aligned with the column name of metadata information
/**
* @author: ffzs
* @Date: 2021/10/7 8:33 am
*/
object MovieLenDataSet {
case class User(UserID:String, Gender:String, Age:String, Occupation:String, Zip_Code:String)
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.ERROR)
val spark = SparkSession.builder()
.appName("MovieLenDataSet")
.master("local[*]")
.getOrCreate()
import spark.implicits._
val dataPath = "/home/ffzs/data/ml-1m"
val schema4users = StructType(
"UserID::Gender::Age::Occupation::Zip_code"
.split("::")
.map(it => StructField(it, StringType, nullable = true))
)
val usersRdd = spark.sparkContext.textFile(f"$dataPath/users.dat")
val usersRows = usersRdd.map(_.split("::"))
.map(it => {
it.map(_.trim)
})
.map(it => Row(it(0), it(1), it(2), it(3), it(4)))
val usersDF: DataFrame = spark.createDataFrame(usersRows, schema4users)
val usersDataSet = usersDF.as[User]
usersDataSet.show(5)
}
}
2, DataSet usage exercise
1. Most common movie types
- split the movie type, and then aggregate the count
- Then sort by counting
println("Most common movie types:")
moviesDataSet.select("Genres")
.flatMap(_(0).toString.split("\\|"))
.map(genre => (genre, 1))
.groupBy("_1")
.sum()
.withColumnRenamed("_1", "genre")
.withColumnRenamed("sum(_2)", "sum")
.orderBy($"sum".desc)
.show(5)
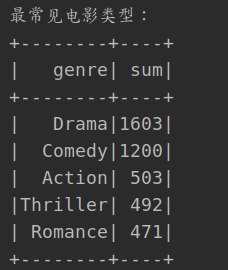
The most is the drama. It's a little unexpected.
2. The most popular film among the most common film types
- First, select films with Drama type
- Then, the viewing users of these movies are obtained through the MovieID
- Then, the average score and comments of the film are obtained through film aggregation
- Filter out movies with more than 10 comments
- Last sort output
println("The most popular film of the most common film types(More than 10 viewers): ")
val mostMovieGenre = "Drama"
moviesDataSet.filter(it => it.Genres.split("\\|").toSet.contains(mostMovieGenre))
.join(ratingsDataSet.select("MovieID", "Rating"), usingColumn = "MovieID")
.groupBy("MovieID", "Title")
.agg("Rating"->"avg", "Rating"->"count")
.filter($"count(Rating)">10)
.orderBy($"avg(Rating)".desc, $"count(Rating)".desc)
.show(3)
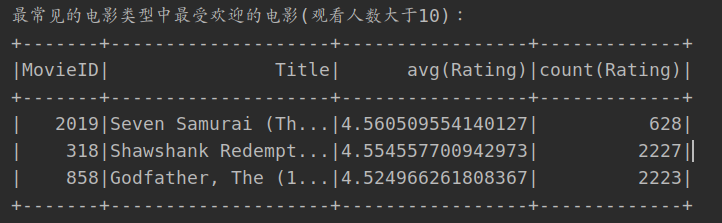
The best reputation is: seven warriors
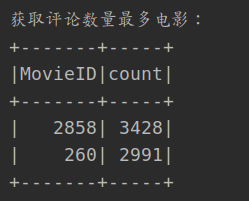
3. Movies with the largest number of reviews
- Get the number of comments for each movie directly through MovieID aggregation
- Then sort the quantity
println("Get movies with the most comments:")
ratingsDataSet.groupBy("MovieID")
.count()
.orderBy($"count".desc)
.show(2)
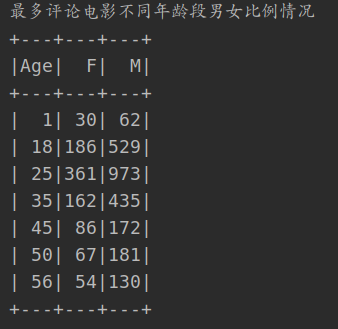
4. Comment on the viewing of films by men and women of different ages at most
println("Most comments on the viewing of films by men and women of different ages")
ratingsDataSet.filter(_.MovieID.equals(mostReviewMovieID)).select("UserID")
.join(usersDataSet.select("UserID", "Age", "Gender"), "UserID")
.groupBy("Age")
.pivot("Gender")
.count()
.orderBy($"Age")
.show()
5. Operate through SQL
- Generate a view from a DataSet
- Then perform SQL operations through the view name
ratingsDataSet.createTempView("rating")
spark.sql("select MovieID, count(1) cnt from rating group by MovieID limit 1").show()
+-------+--------+
|MovieID|count(1)|
+-------+--------+
| 2294| 645|
+-------+--------+
6. Storage
- Store DataSet
- There are four mode s:
- overwrite: replace
- Append: append after
- ErrorIfExists: if it exists, an error will be reported. The default method is
- Ignore: do not operate if it exists
println("take DataSet Data storage hit HDFS in")
ratingsDataSet.write
.mode(SaveMode.Overwrite)
.parquet("hdfs://localhost:9000/movieLen/rating")
Write successful:

Full code:
/**
* @author: ffzs
* @Date: 2021/10/7 8:33 am
*/
object MovieLenDataSet {
case class User(UserID:String, Gender:String, Age:String, Occupation:String, Zip_Code:String)
case class Rating(UserID:String, MovieID:String, Rating:Double, Timestamp: String)
case class Movie(MovieID:String, Title:String, Genres:String)
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.ERROR)
val spark = SparkSession.builder()
.appName("MovieLenDataSet")
.master("local[*]")
// .master("spark://localhost:7077")
.getOrCreate()
import spark.implicits._
val dataPath = "/home/ffzs/data/ml-1m"
// Construct user's DataSet, convert it to DataFrame through Row, and then convert it to DataSet
val schema4users = StructType(
"UserID::Gender::Age::Occupation::Zip_code"
.split("::")
.map(it => StructField(it, StringType, nullable = true))
)
val usersRdd = spark.sparkContext.textFile(f"$dataPath/users.dat")
val usersRows = usersRdd.map(_.split("::"))
.map(it => {it.map(_.trim)})
.map(it => Row(it(0), it(1), it(2), it(3), it(4)))
val usersDF: DataFrame = spark.createDataFrame(usersRows, schema4users)
val usersDataSet = usersDF.as[User].cache()
// Construct a movie DataSet, directly read the file, generate a DataFrame, and then convert it into a DataSet
val moviesRows = spark.read.textFile(f"$dataPath/movies.dat")
val moviesDataSet = moviesRows.map(row => {
val values = row.split("::").map(_.trim)
Movie(values(0), values(1), values(2))
}).cache()
// Constructing a rating DataSet
val ratingsRows = spark.read.textFile(f"$dataPath/ratings.dat")
val ratingsDataSet = ratingsRows.map(row => {
val values = row.split("::").map(_.trim)
Rating(values(0), values(1), values(2).toDouble, values(3))
}).cache()
println("The most popular film of the most common film types(More than 10 viewers): ")
val mostMovieGenre = "Drama"
moviesDataSet.filter(it => it.Genres.split("\\|").toSet.contains(mostMovieGenre))
.join(ratingsDataSet.select("MovieID", "Rating"), usingColumn = "MovieID")
.groupBy("MovieID", "Title")
.agg("Rating"->"avg", "Rating"->"count")
.filter($"count(Rating)">10)
.orderBy($"avg(Rating)".desc, $"count(Rating)".desc)
.show(3)
println("Get movies with the most reviews ID: ")
val mostReviewMovieID = ratingsDataSet.groupBy("MovieID")
.count()
.orderBy($"count".desc)
.first()(0)
println("Most comments on the viewing of films by men and women of different ages")
ratingsDataSet.filter(_.MovieID.equals(mostReviewMovieID)).select("UserID")
.join(usersDataSet.select("UserID", "Age", "Gender"), "UserID")
.groupBy("Age")
.pivot("Gender")
.count()
.orderBy($"Age")
.show()
println("adopt SQL Statement pair dataset Operate on data")
ratingsDataSet.createTempView("rating")
spark.sql("select MovieID, count(1) cnt from rating group by MovieID limit 1").show()
println("take DataSet Data storage hit HDFS in")
ratingsDataSet.write
.mode(SaveMode.Overwrite)
.parquet("hdfs://localhost:9000/movieLen/rating")
}
}