demand
Suppose a company provides you with the following data. The modified data includes three. txt document data, namely date data, order header data and order details data. Let you conduct the following demand analysis according to the data provided by the company.
1. Calculate the annual sales orders and total sales in all orders.
2. Calculate the sales of the maximum amount of all orders every year.
3. Calculate the best-selling goods in all orders every year.
1, Data field description
1.1 date data
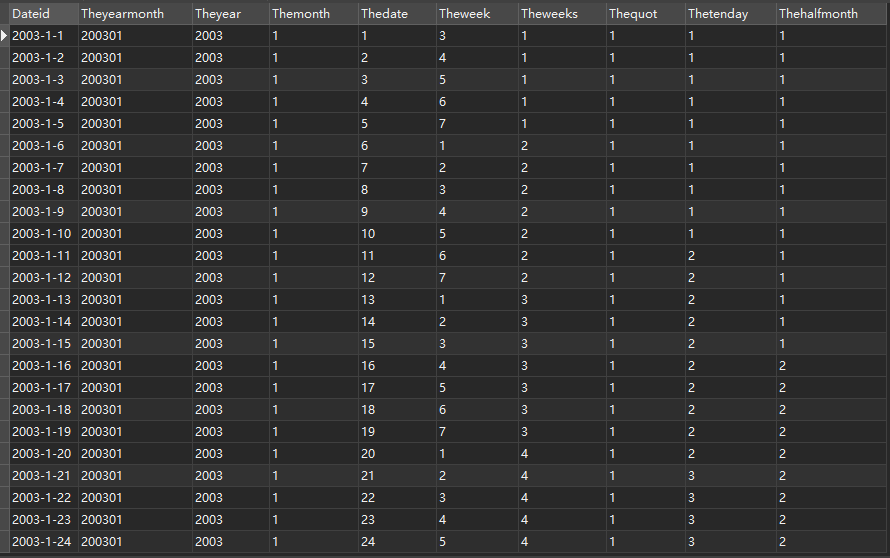
The fields correspond to: date, year, year, month, day, week, week, quarter, ten day and half month.
1.2 order header data
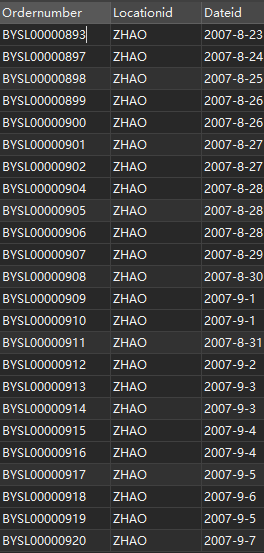
The fields correspond to: order number, transaction location and transaction date.
1.3 order details
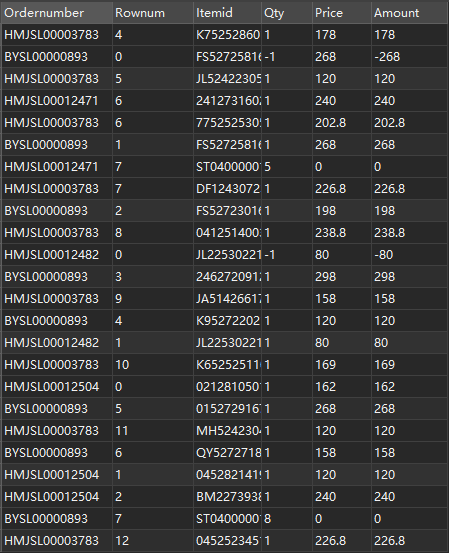
The fields correspond to: order number, line number, goods, quantity, unit price and total amount.
2, Analysis steps
2.1 calculate the annual sales orders and total sales in all orders.
code:
/**
* Calculate the annual sales orders and total sales in all orders
* @param session
*/
def calculate_salesCountByYear_salesMoneyByYear(session:SparkSession)={
//The date data is read as df
val frame_date = session.read.format("csv").option("header", true).load(tbDatePath)
//The order header data is read as df
val frame_stock = session.read.format("csv").option("header", true).load(toStockPath)
//Order detail data is read as df
val frame_detail = session.read.format("csv").option("header", true).load(toStockDetailPath)
//Create temporary tables separately
frame_date.createOrReplaceTempView("date");frame_stock.createOrReplaceTempView("stock")
frame_detail.createOrReplaceTempView("detail")
//Execute and analyze the join query information of three tables
session.sql("select sum(de.Qty) as sales_count," +
"sum(de.Amount) as sales_amount," +
"substring(da.Dateid,1,4) as date_Time " +
"from stock as st " +
"inner join detail as de " +
"on st.Ordernumber=de.Ordernumber " +
"inner join date as da " +
"on st.Dateid=da.Dateid " +
"group by substring(da.Dateid,1,4)").show()
}
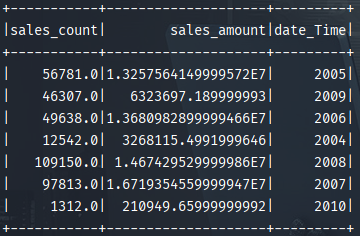
result:
2.2 calculate the sales volume of the maximum amount of all orders every year.
code:
/**
* Calculate the maximum annual sales amount of all orders
* @param session
*/
def salesMoneyOfMaxByYear(session:SparkSession)={
//Read data files separately and convert them to df
val frame_date = session.read.format("csv").option("header", true).load(tbDatePath)
val frame_stock = session.read.format("csv").option("header", true).load(toStockPath)
val frame_detail = session.read.format("csv").option("header", true).load(toStockDetailPath)
//Create temporary tables to be used separately
frame_date.createOrReplaceTempView("date");frame_stock.createOrReplaceTempView("stock")
frame_detail.createOrReplaceTempView("detail")
//First, calculate the sales volume of each order and its corresponding time
val money_date = session.sql("select (de.Qty*de.Price) as sales_money,da.Dateid " +
"from stock as st " +
"inner join detail as de " +
"on st.Ordernumber=de.Ordernumber " +
"inner join date as da " +
"on st.Dateid=da.Dateid")
//Register as temporary table
money_date.createOrReplaceTempView("money_date")
//Connect the results of the previous analysis with the date data table to calculate the sales volume of the maximum amount order every year
session.sql("select max(md.sales_money) as max_money," +
"substring(da.Dateid,1,4) as year " +
"from money_date as md " +
"inner join date as da " +
"on md.Dateid=da.Dateid " +
"group by substring(da.Dateid,1,4) order by year").show()
}
result:
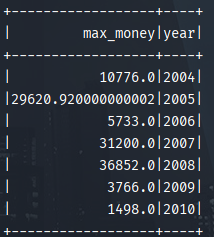
2.3 calculate the best-selling goods in all orders every year.
Idea: first find out the sales amount of each product every year, then find out the maximum amount of single product sales every year, and finally connect the tables to find that the goods that match the maximum sales every year are the best-selling goods.
code:
/**
* Calculate the best-selling items in all orders each year
* @param session
*/
def popular_product(session:SparkSession)={
val frame_date = session.read.format("csv").option("header", true).load(tbDatePath)
val frame_stock = session.read.format("csv").option("header", true).load(toStockPath)
val frame_detail = session.read.format("csv").option("header", true).load(toStockDetailPath)
frame_date.createOrReplaceTempView("date");frame_stock.createOrReplaceTempView("stock")
frame_detail.createOrReplaceTempView("detail")
//Find the annual sales amount of each product
val year_product_money_per = session.sql("select substring(da.Dateid,1,4) as year," +
"de.Itemid as product," +
"(de.Qty*de.Price) as money " +
"from stock as st " +
"inner join detail as de " +
"on st.Ordernumber=de.Ordernumber " +
"inner join date as da " +
"on st.Dateid=da.Dateid")
//Find the maximum amount of single product sales each year
val year_money_max = session.sql("select substring(da.Dateid,1,4) as year," +
"max(de.Qty*de.Price) as max_money " +
"from stock as st " +
"inner join detail as de " +
"on st.Ordernumber=de.Ordernumber " +
"inner join date as da " +
"on st.Dateid=da.Dateid " +
"group by year")
year_product_money_per.createOrReplaceTempView("year_product_money_per")
year_money_max.createOrReplaceTempView("year_money_max")
//Table connection to find the best-selling goods
session.sql("select ypmp.year,ypmp.product " +
"from year_product_money_per as ypmp " +
"inner join year_money_max as ymm " +
"on ypmp.year=ymm.year " +
"where ypmp.money=ymm.max_money " +
"order by ypmp.year").show()
}
result:
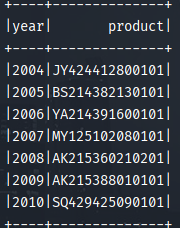
2.4 all codes
code:
package training.sectionC
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.apache.spark.{SparkConf, SparkContext}
/**
* @ClassName:company_data_analyse
* @author: Architect_Bo Wen Wang
* @date: 2021/10/6 12:01
*/
object company_data_analyse {
val tbDatePath="Path to date data"
val toStockPath="Order header data path"
val toStockDetailPath="Order detail data path "
//Defines how data is written to the database
def mysql_Position(frame:DataFrame, tbName:String)={
frame.write.format("jdbc")
.option("url","jdbc:mysql://IP address: 3306 / database name ")
.option("user","user name")
.option("password","password")
.option("dbtable",tbName)
.save()
}
//Execute data writing to database
def moveToMysql(session:SparkSession)={
val frame_date = session.read.format("csv").option("header", true).load(tbDatePath)
val frame_stock = session.read.format("csv").option("header", true).load(toStockPath)
val frame_detail = session.read.format("csv").option("header", true).load(toStockDetailPath)
mysql_Position(frame_date,"date")
mysql_Position(frame_stock,"stock")
mysql_Position(frame_detail,"stockDetail")
}
/**
* Calculate the annual sales orders and total sales in all orders
* @param session
*/
def calculate_salesCountByYear_salesMoneyByYear(session:SparkSession)={
val frame_date = session.read.format("csv").option("header", true).load(tbDatePath)
val frame_stock = session.read.format("csv").option("header", true).load(toStockPath)
val frame_detail = session.read.format("csv").option("header", true).load(toStockDetailPath)
frame_date.createOrReplaceTempView("date");frame_stock.createOrReplaceTempView("stock")
frame_detail.createOrReplaceTempView("detail")
session.sql("select sum(de.Qty) as sales_count," +
"sum(de.Amount) as sales_amount," +
"substring(da.Dateid,1,4) as date_Time " +
"from stock as st " +
"inner join detail as de " +
"on st.Ordernumber=de.Ordernumber " +
"inner join date as da " +
"on st.Dateid=da.Dateid " +
"group by substring(da.Dateid,1,4)").show()
}
/**
* Calculate the maximum annual sales amount of all orders
* @param session
*/
def salesMoneyOfMaxByYear(session:SparkSession)={
//Read data files separately and convert them to df
val frame_date = session.read.format("csv").option("header", true).load(tbDatePath)
val frame_stock = session.read.format("csv").option("header", true).load(toStockPath)
val frame_detail = session.read.format("csv").option("header", true).load(toStockDetailPath)
//Create temporary tables to be used separately
frame_date.createOrReplaceTempView("date");frame_stock.createOrReplaceTempView("stock")
frame_detail.createOrReplaceTempView("detail")
//First, calculate the sales volume of each order and its corresponding time
val money_date = session.sql("select (de.Qty*de.Price) as sales_money,da.Dateid " +
"from stock as st " +
"inner join detail as de " +
"on st.Ordernumber=de.Ordernumber " +
"inner join date as da " +
"on st.Dateid=da.Dateid")
//Register as temporary table
money_date.createOrReplaceTempView("money_date")
//Connect the results of the previous analysis with the date data table to calculate the sales volume of the maximum amount order every year
session.sql("select max(md.sales_money) as max_money," +
"substring(da.Dateid,1,4) as year " +
"from money_date as md " +
"inner join date as da " +
"on md.Dateid=da.Dateid " +
"group by substring(da.Dateid,1,4) order by year").show()
}
/**
* Calculate the best-selling items in all orders each year
* @param session
*/
def popular_product(session:SparkSession)={
val frame_date = session.read.format("csv").option("header", true).load(tbDatePath)
val frame_stock = session.read.format("csv").option("header", true).load(toStockPath)
val frame_detail = session.read.format("csv").option("header", true).load(toStockDetailPath)
frame_date.createOrReplaceTempView("date");frame_stock.createOrReplaceTempView("stock")
frame_detail.createOrReplaceTempView("detail")
val year_product_money_per = session.sql("select substring(da.Dateid,1,4) as year," +
"de.Itemid as product," +
"(de.Qty*de.Price) as money " +
"from stock as st " +
"inner join detail as de " +
"on st.Ordernumber=de.Ordernumber " +
"inner join date as da " +
"on st.Dateid=da.Dateid")
val year_money_max = session.sql("select substring(da.Dateid,1,4) as year," +
"max(de.Qty*de.Price) as max_money " +
"from stock as st " +
"inner join detail as de " +
"on st.Ordernumber=de.Ordernumber " +
"inner join date as da " +
"on st.Dateid=da.Dateid " +
"group by year")
year_product_money_per.createOrReplaceTempView("year_product_money_per")
year_money_max.createOrReplaceTempView("year_money_max")
session.sql("select ypmp.year,ypmp.product " +
"from year_product_money_per as ypmp " +
"inner join year_money_max as ymm " +
"on ypmp.year=ymm.year " +
"where ypmp.money=ymm.max_money " +
"order by ypmp.year").show()
}
def main(args: Array[String]): Unit = {
val session = SparkSession.builder().master("local[*]").appName("company").getOrCreate()
calculate_salesCountByYear_salesMoneyByYear(session)
salesMoneyOfMaxByYear(session)
popular_product(session)
moveToMysql(session)
session.stop()
}
}
3, Summary
The above is my process of processing and analyzing the company's sales data. When we face the actual needs, it is true that the problem will be very difficult when we are not familiar with the business. My suggestion is to get familiar with the business first, think about what you want to do, and then consider the division of content and the relationship between parts. As a big data developer, the code is very important Like writing, everyone can, but the program function is like a beautiful article. As long as you are familiar with the business, I believe all problems can be solved! Come on!