Spark+Kafka Build Real-Time Analysis Dashboard
I. Framework
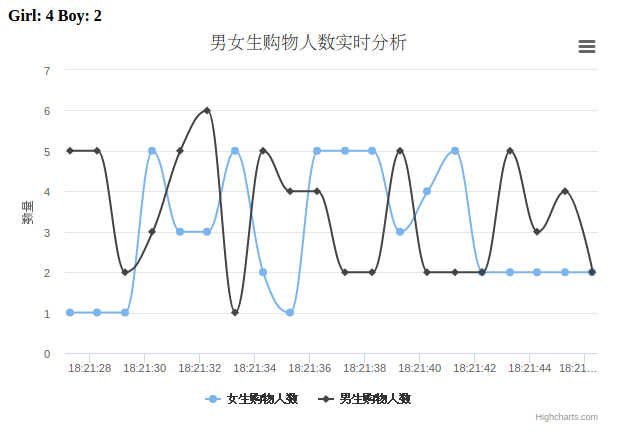
Spark+Kafka is used to analyze the number of male and female students shopping per second in real time, Spark Streaming is used to process the user shopping log in real time, then websocket is used to push the data to the browser in real time, and finally the browser displays the received data in real time. The overall framework of the case is as follows: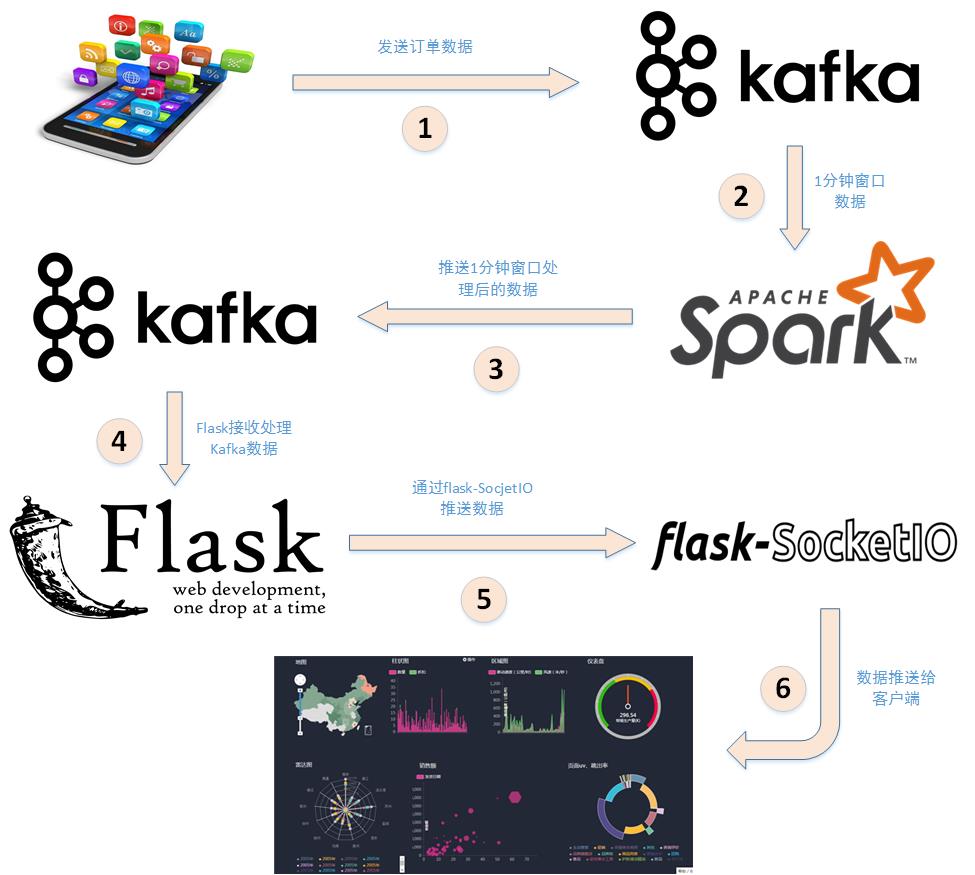
Detailed analysis of the following steps:
- The app sends the shopping log to Kafka, topic is "sex", because it only counts the number of male and female shoppers, so just send the gender attribute in the shopping log.Here, the shopping log is sent in a simulated way, that is, reading the shopping log data and sending it to Kafka at the same interval.
- Then use Spark Streaming to read and process messages from the Kafka theme "sex".Here the data is read sequentially by the size of the sliding window, for example, once every 5 seconds as the window size, and then processed.
- Spark sends the processed data to Kafka with top as "result".
- Then use Flask to build a web application that receives a message with the Kafka theme "result".
- Use Flask-SocketIO to push data to clients in real time.
- Client browsers use the JS framework socketio to receive data in real time, and then use the JS visualization library hightlights.js library to display dynamically.
2. Preparing experimental environment
Environmental requirements
- Ubuntu: 16.04
Spark: 2.1.0
Scala: 2.11.8
kafka: 0.8.2.2
Python: 3.x (version 3.0 and above)
Flask: 0.12.1
Flask-SocketIO: 2.8.6
kafka-python: 1.3.3
3. Python operation kafka
1. Data introduction
The data set package used is data_format.zip Click here Download data_format.zip dataset
This data set compression package is the transaction data of Taobao in the first 6 months of Double 11 in 2015 (including Double 11), which has offset but does not affect the results of the experiment). It contains three files, user_log.csv, train.csv, test.csv. In this case, only user_log.csv is used. The file user_log.csv is listed below.Data format definition for log.csv:
User behavior log user_log.csv, the fields in the log are defined as follows:
- user_id | buyer ID
- item_id | commodity ID
- cat_id | commodity category ID
- merchant_id | vendor ID
- brand_id | brand ID
- Month | trading time: month
- Day | transaction event: day
- action | behavior, value range {0,1,2,3}, 0 means click, 1 means join shopping cart, 2 means purchase, 3 means focus on goods
- age_range | Buyer age segment: 1 for age <18,2 for age [18,24], 3 for age [25,29], 4 for age [30,34], 5 for age [35,39], 6 for age [40,49], 7 and 8 for age >=50,0 and NULL for unknown
- gender | gender: 0 for female, 1 for male, 2 for unknown
- province|harvest address province
The data is formatted as follows:
user_id,item_id,cat_id,merchant_id,brand_id,month,day,action,age_range,gender,province
328862,323294,833,2882,2661,08,29,0,0,1,Inner Mongolia
328862,844400,1271,2882,2661,08,29,0,1,1,Shanxi
328862,575153,1271,2882,2661,08,29,0,2,1,Shanxi
328862,996875,1271,2882,2661,08,29,0,1,1,Inner Mongolia
328862,1086186,1271,1253,1049,08,29,0,0,2,Zhejiang
328862,623866,1271,2882,2661,08,29,0,0,2,Heilongjiang
328862,542871,1467,2882,2661,08,29,0,5,2,Sichuan
328862,536347,1095,883,1647,08,29,0,7,1,Jilin
Real-time statistics of the number of male and female students shopping per second, so for each shopping log, we just need to get the gender, send it to Kafka, and Spark Streaming receives the gender for processing.
2. Data Preprocessing
Use Python to preprocess the data and send it directly to Kafka through the Kafka producer, where you need to install the code library for Python to operate on Kafka.
2.1 Create Producer
# coding: utf-8 import csv import time from kafka import KafkaProducer # Instantiate a KafkaProducer example for delivering messages to Kafka producer = KafkaProducer(bootstrap_servers='192.168.1.30:9092') # Open Data File csvfile = open("../data/user_log.csv", "r", encoding='UTF-8') # Generate a reader that can be used to read csv files reader = csv.reader(csvfile) for line in reader: gender = line[9] # Sex is the ninth element in each line of log code if gender == 'gender': continue # Remove the first row header time.sleep(0.1) # Send a row of data every 0.1 seconds # Send data, top is'sex' print(line[9].encode('utf8')) producer.send('sex', line[9].encode('utf8'))
2.2 Creating Consumers
from kafka import KafkaConsumer consumer = KafkaConsumer('result', bootstrap_servers='192.168.1.30:9092') for msg in consumer: print((msg.value).decode('utf8'))
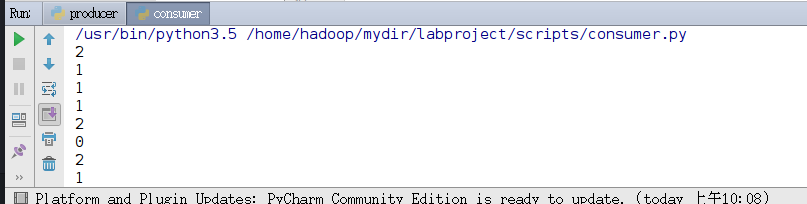
3. Spark Streaming real-time data processing
- Copy the jar package of spark-streaming-kafka (version kafka010) into the jars package on each node of the cluster.
- Real-time statistics of the number of male and female shoppers per second, while Spark Streaming receives data of 1,1,0,2...Of these, 0 is for women and 1 is for men, SO 2 or null values are not considered.In fact, through analysis, we can find that this is a typical wordcount problem and is based on the Spark stream calculation.The number of girls, that is, the number of 0, and the number of boys, that is, the number of 1.Using ReducByKeyAndWindow with Spark Streaming interface, set the window size to 1 and the sliding step to 1, so the number of 0 and 1 is the number of boys and girls per second.
- First, the Kafka message is read at a frequency per second;
- Then the wordcount algorithm is executed on the data per second, and the number of 0, 1 and 2 is counted.
- Finally, the results are encapsulated as json and sent to Kafka.
1. Set log formatting
import org.apache.spark.internal.Logging import org.apache.log4j.{Level, Logger} /** Utility functions for Spark Streaming examples. */ object StreamingExamples extends Logging { /** Set reasonable logging levels for streaming if the user has not configured log4j. */ def setStreamingLogLevels() { val log4jInitialized = Logger.getRootLogger.getAllAppenders.hasMoreElements if (!log4jInitialized) { // We first log something to initialize Spark's default logging, then we override the // logging level. logInfo("Setting log level to [WARN] for streaming example." + " To override add a custom log4j.properties to the classpath.") Logger.getRootLogger.setLevel(Level.WARN) } } }
2.spark streaming real-time data analysis
Accepts Kafka data for real-time flow analysis, creates producers, sends analysis results to kakfa, and the Python web side receives visualization of analysis results from kafka.
import java.util.HashMap import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, ProducerRecord} import org.json4s._ import org.json4s.jackson.Serialization import org.json4s.jackson.Serialization.write // import org.json4s._ // import org.json4s.JsonDSL._ // import org.json4s.jackson.JsonMethods._ import org.apache.spark.SparkConf import org.apache.spark.streaming._ import org.apache.spark.streaming.Interval import org.apache.spark.streaming.kafka010._ import org.apache.kafka.common.serialization.StringDeserializer import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe object KafkaWordCount{ def main(args:Array[String]){ // Format Log StreamingExamples.setStreamingLogLevels() val sparkConf = new SparkConf().setAppName("KafkaWordCount") val ssc = new StreamingContext(sparkConf, Seconds(1)) // Set chackpoint ssc.checkpoint(".") // Create consumers, get data from kafka for real-time processing by spark streaming // Parameter settings for new version of kafka val kafkaParams = Map[String, Object]( "bootstrap.servers" -> "192.168.1.30:9092", "key.deserializer" -> classOf[StringDeserializer], "value.deserializer" -> classOf[StringDeserializer], "group.id" -> "1", "auto.offset.reset" -> "latest", "enable.auto.commit" -> (false: java.lang.Boolean) ) // How to set the number of partitions for each topic by possibly subscribing to multiple topics at the same time val topics = Array("sex") // create data source val lineMap = KafkaUtils.createDirectStream[String, String]( ssc, PreferConsistent, Subscribe[String, String](topics, kafkaParams) ) val lines =lineMap.map(record => record.value) val words=lines.flatMap(_.split(" ")) // val wordCounts = words.map(x => (x, 1L)).reduceByKeyAndWindow(_+_,_-_, Seconds(1), Seconds(1), 1).print // Windows Interception of Data for Real-Time Flow Analysis val wordCounts = words.map(x => (x, 1L)).reduceByKeyAndWindow(_+_,_-_, Seconds(1), Seconds(1), 1).foreachRDD(rdd => { if(rdd.count !=0 ){ implicit val formats = DefaultFormats//Data formatting requires that, in order to exclude serialization issues, you place it here val props = new HashMap[String, Object]() // Provide brokers address props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.1.30:9092") // Specifies how the value in the key value can be serialized because of network transport props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer") // Specifies how keys in key value can be serialized because of network transport props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer") // Producer object, providing serialization of borker and kv val producer = new KafkaProducer[String, String](props) // Converting an array in rdd to an array and then to json val str = write(rdd.collect) // Another way to convert rdd to json // val json=rdd.collect().toList.map{case (word, count) =>(word, count)} // val str=compact(render(json)) // println(rdd.collect.getClass().getName()) //Lscala.Tuple2; // println(str) val message = new ProducerRecord[String, String]("result", null, str) producer.send(message) } }) ssc.start() ssc.awaitTermination() } }
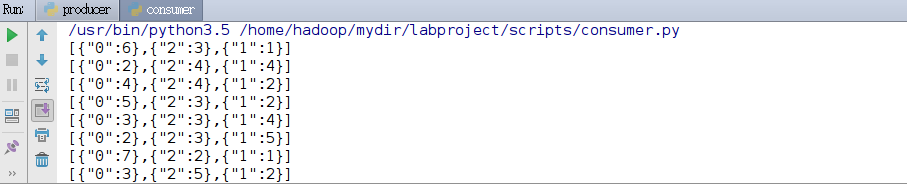
3. Visualization of real-time analysis results ( Source Download)
- Push data in real time using Flask-SocketIO
- socket.io.js Real-time Data Acquisition
- highlights.js Show Data
3.1 Flask-SocketIO Real-Time Push Data
Spark Streaming receives real-time log data sent by topic for'sex'in Kafka, and Spark Streaming processes the data in real-time. After counting the number of male and female shoppers per second, the result is sent to Kafka with topic as'result'.In this section, you will learn how to use Flask-SocketIO to push results to your browser in real time.
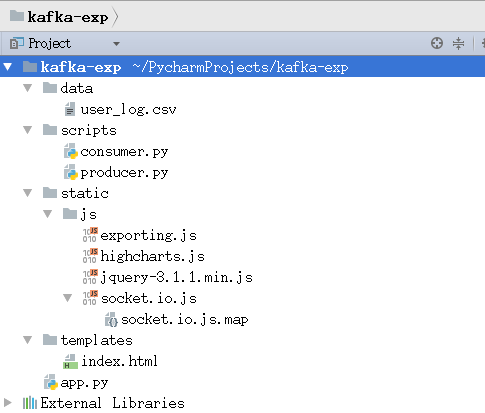
The file directory structure is as follows:
- 1. The data directory stores user log data;
- 2. The scripts directory stores Kafka producers and consumers;
- 3. The static/js directory stores the JS framework needed by the front end;
- 4. The templates directory holds html pages;
- 5.app.py is a web server that receives results from Spark Streaming processing and pushes real-time data to the browser;
- 6.External Libraries is the Python library on which this project relies and is automatically generated by PyCharm.
The function of app.py is to act as a simple server, handle connection requests, and process data received from kafka, and push it to the browser in real time.The code for app.py is as follows:
import json from flask import Flask, render_template from flask_socketio import SocketIO from kafka import KafkaConsumer app = Flask(__name__) app.config['SECRET_KEY'] = 'secret!' socketio = SocketIO(app) thread = None # Instantiate a consumer to receive a message with top as result consumer = KafkaConsumer('result', bootstrap_servers='192.168.1.30:9092') # A background thread that continuously receives Kafka messages and sends them to client browsers def background_thread(): girl = 0 boy = 0 for msg in consumer: data_json = msg.value.decode('utf8') data_list = json.loads(data_json) for data in data_list: if '0' in data.keys(): girl = data['0'] elif '1' in data.keys(): boy = data['1'] else: continue result = str(girl) + ',' + str(boy) print(result) socketio.emit('test_message', {'data': result}) # Handler when client sends connect event @socketio.on('test_connect') def connect(message): print(message) global thread if thread is None: # Open a separate thread to send data to clients thread = socketio.start_background_task(target=background_thread) socketio.emit('connected', {'data': 'Connected'}) # Access index.html by accessing http://127.0.0.1:5000/ @app.route("/") def handle_mes(): return render_template("index.html") # main function if __name__ == '__main__': socketio.run(app, debug=True)
4. Effect display
With all the above steps in place, we can start the program to see the final result.The startup steps are as follows: (multiple python files need to be started using the command line startup method)
1. Make sure kafka is turned on.
2. Open producer.py analog data stream.
3. Start Spark Streaming to process data in real time.Tip you can change the top of comsumer.py to result after data processing is started in real time. Run comsumer.py to see the output of data processing.
4.Start app.py.
Use your browser to access the web address http://127.0.0.1:5000/, given in the figure above, to see the final result: