Spark BigData Program: big data real-time stream processing log
1, Project content
- Write python scripts to continuously generate user behavior logs of learning websites.
- Start Flume to collect the generated logs.
- Start Kafka to receive the log received by Flume.
- Use Spark Streaming to consume Kafka's user logs.
- Spark Streaming cleans the data and filters illegal data, then analyzes the user's access courses in the log and counts the user search volume of each course
- Write the result of Spark Streaming processing to MySQL database.
- The front end uses Django integration as the data display platform.
- Use Ajax to asynchronously transfer data to Html pages, and use the Echarts framework to display the data.
- In this practice, IDEA2019 is used as the development tool. JDK version is 1.8, Scala version is 2.11 and python version is 3.7
2, Demand analysis
This project integrates real-time stream processing and off-line processing of big data for actual combat
Big data real-time stream processing features:
- Continuous generation of massive data
- Massive real-time data needs to be processed in real time
- The processed data results are written into the database in real time
Big data offline processing features:
- Huge amount of data and long storage time
- Complex batch operations are required on a large amount of data
- The data will not change before and during processing
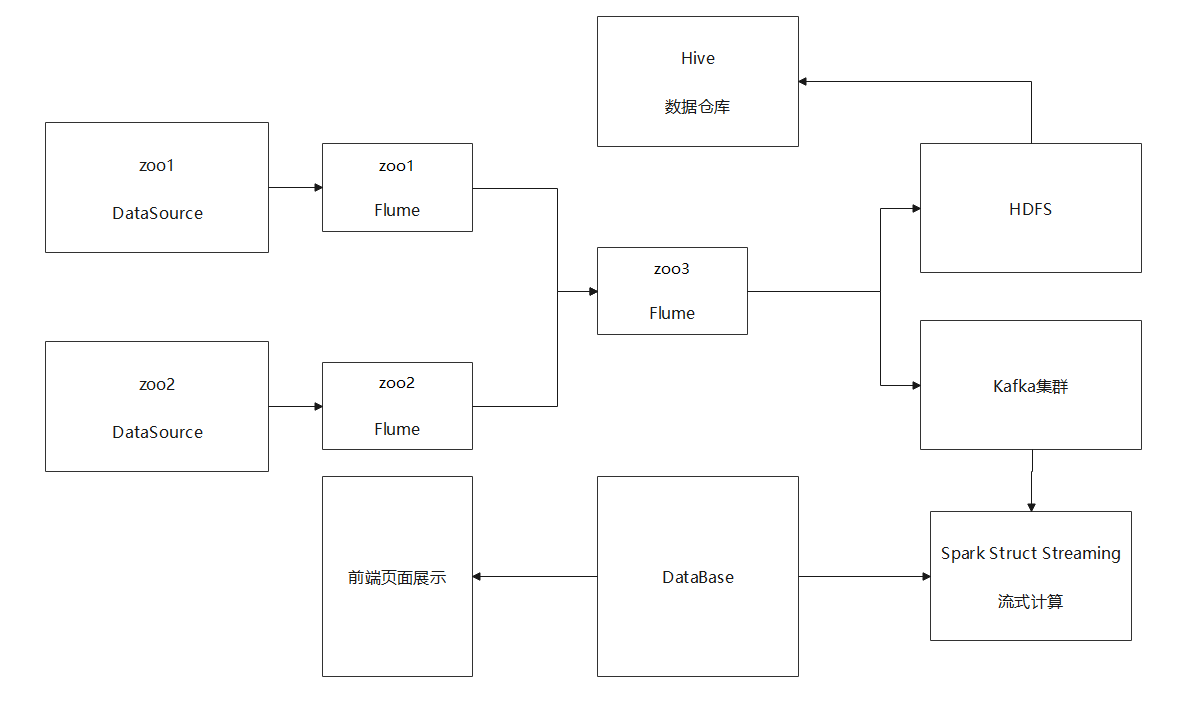
3, Project architecture
In view of the above requirements, the project adopts the architecture of Flume+Kafka+Spark+MySQL+Django
4, Data source
python data source
- Default data saving path * * / usr/app/BigData/StreamingComputer/log**
- The default log production rate is 200 entries / s
- Default log error rate 8%
- The default file name is timestamp
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
import random
import time
import sys
url_paths = [
"class/112.html",
"class/128.html",
"class/145.html",
"class/146.html",
"class/500.html",
"class/250.html",
"class/131.html",
"class/130.html",
"class/271.html",
"class/127.html",
"learn/821",
"learn/823",
"learn/987",
"learn/500",
"course/list"
]
ip_slices = [
132, 156, 124, 10, 29, 167, 143, 187, 30, 46,
55, 63, 72, 87, 98, 168, 192, 134, 111, 54, 64, 110, 43
]
http_refer = [
"http://www.baidu.com/s?wd={query}",
"https://www.sogou.com/web?query={query}",
"http://cn.bing.com/search?q={query}",
"https://search.yahoo.com/search?p={query}",
]
search_keyword = [
"SparkSQL",
"Hadoop",
"Storm",
"Flume",
"Python",
"MySql",
"Linux",
"HTML",
]
status_codes = [
"200", "404", "500", "403"
]
# Randomly generated ip
def get_ip():
return '{}.{}.{}.{}'.format(
random.choice(ip_slices),
random.choice(ip_slices),
random.choice(ip_slices),
random.choice(ip_slices)
)
# Randomly generated url
def get_url():
return '"/GET {}"'.format(random.choice(url_paths))
# Randomly generated refer
def get_refer():
if random.uniform(0, 1) > 0.92:
return "Na"
return random.choice(http_refer).replace('{query}', random.choice(search_keyword))
# Randomly generated status code
def get_code():
return random.choice(status_codes)
# Get current time
def get_time():
return time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time()))
# Generate log data
def get_log_data():
return '{} {} {} {} {}\n'.format(
get_ip(),
get_time(),
get_url(),
get_code(),
get_refer()
)
# Save log data
def save(n):
count = 0
print(get_time()[0: 10]+'\tDataSource Server has been prepared..')
fp = open(
'/usr/app/BigData/StreamingComputer/log/{}.log'.format(int(time.time())),
'w+',
encoding='utf-8'
)
for i in range(n):
fp.write(get_log_data())
count += 1
time.sleep(0.005)
if count > 8000:
count = 0
fp.close()
fp = open(
'/usr/app/BigData/StreamingComputer/log/{}.log'.format(int(time.time())),
'w+',
encoding='utf-8'
)
fp.close()
if __name__ == '__main__':
save(int(sys.argv[1]))
Scala data source
- Default data saving path * * / usr/app/BigData/StreamingComputer/log**
- The default file name is timestamp
- Log error rate is 0%
- The log saving path, production rate and quantity can be manually transferred
package common
import java.io.FileOutputStream
import java.text.SimpleDateFormat
import java.util.Date
import scala.util.Random
object DataProducer {
val random = new Random()
val urlPath: Array[String] = Array(
"class/112.html",
"class/128.html",
"class/145.html",
"class/146.html",
"class/500.html",
"class/250.html",
"class/131.html",
"class/130.html",
"class/271.html",
"class/127.html",
"learn/821",
"learn/823",
"learn/987",
"learn/500",
"course/list")
val ipSlice: Array[Int] = Array(
132,156,124,10,29,167,143,187,30,46,55,63,72,87,98,168,192,134,111,54,64,110,43
)
val httpRefers: Array[String] = Array(
"http://www.baidu.com/s?wd={query}",
"https://www.sogou.com/web?query={query}",
"http://cn.bing.com/search?q={query}",
"https://search.yahoo.com/search?p={query}",
)
val keyWords: Array[String] = Array(
"Spark SQL actual combat",
"Hadoop Ecological development",
"Storm actual combat",
"Spark Streaming actual combat",
"python From entry to prison",
"Shell From the beginning to the end, as shown in the figure",
"Linux From getting started to giving up",
"Vue.js"
)
val stateCode: Array[String] = Array(
"200",
"404",
"500",
"403"
)
var count = 0
def main(args: Array[String]): Unit = {
if(args.length !=3) throw new Exception("arguments error: arg must be 3") else run(args)
}
def getIp: String = s"${ipSlice(random.nextInt(ipSlice.length))}.${ipSlice(random.nextInt(ipSlice.length))}.${ipSlice(random.nextInt(ipSlice.length))}.${ipSlice(random.nextInt(ipSlice.length))}"
def getTime: String = new SimpleDateFormat("YYYY-MM-dd HH:mm:ss.[SSS]").format(new Date())
def getRequestRow: String ="\""+s"/GET ${urlPath(random.nextInt(urlPath.length))}"+"\""
def getRequestUrl:String = s"${httpRefers(random.nextInt(httpRefers.length)).replace("{query}",keyWords(random.nextInt(keyWords.length)))}"
def getStateCode:String = s"${stateCode(random.nextInt(stateCode.length))}"
def getLogData:String = s"$getIp $getTime $getRequestRow $getStateCode $getRequestUrl" + "\n"
def run(args: Array[String]): Unit ={
println(s"${new SimpleDateFormat("YYYY-MM-dd HH:mm:ss").format(new Date())} DataSource Server has been prepared")
var out = new FileOutputStream(args(0)+"/"+ new SimpleDateFormat("YYYY-MM-dd HH:mm:ss").format(new Date())+".log")
for(i <- 1 to args(2).toInt){
out.write(getLogData.getBytes)
out.flush()
count += 1
Thread.sleep(1000/args(1).toInt)
if(count == 3000){
out.close()
out = new FileOutputStream(args(0)+"/"+ new SimpleDateFormat("YYYY-mm-DD HH:MM:ss").format(new Date())+".log")
}
}
out.close()
}
}
Data sample
64.87.98.30 2021-05-28 00:19:58 "/GET course/list" 200 https://search. yahoo. com/search? P = proficient in Linux 46.132.30.124 2021-05-28 00:19:58 "/GET class/271.html" 500 https://search.yahoo.com/search?p=SparkSQL actual combat 10.143.143.30 2021-05-28 00:19:58 "/GET class/500.html" 500 https://search.yahoo.com/search?p=SparkSQL actual combat 168.110.143.132 2021-05-28 00:19:58 "/GET learn/500" 200 https://search.yahoo.com/search?p=HTML front-end three swordsman 54.98.29.10 2021-05-28 00:19:58 "/GET learn/500" 500 Na 63.168.132.124 2021-05-28 00:19:58 "/GET course/list" 403 https://search.yahoo.com/search?p=HTML front-end three swordsman 72.98.98.167 2021-05-28 00:19:58 "/GET class/112.html" 404 https://search.yahoo.com/search?p=Python crawler advanced 29.87.46.54 2021-05-28 00:19:58 "/GET class/146.html" 403 http://cn. bing. com/search? Q = proficient in Linux 43.43.110.63 2021-05-28 00:19:58 "/GET learn/987" 500 http://cn. bing. com/search? Q = proficient in Linux 54.111.98.43 2021-05-28 00:19:58 "/GET course/list" 403 Na 187.29.10.10 2021-05-28 00:19:58 "/GET learn/823" 200 http://cn.bing.com/search?q=SparkSQL actual combat 10.187.29.168 2021-05-28 00:19:58 "/GET class/146.html" 500 http://www.baidu.com/s?wd=Storm actual combat
5, Acquisition system (Flume)
- The architecture adopts distributed collection. zoo1 and zoo2 collect data sources, and zoo3 integrates the data and transmits it to Kafka
- **Flume Chinese document:** https://flume.liyifeng.org/
zoo1 zoo2
a1.sources=r1 a1.channels=c1 a1.sinks=k1 a1.sources.r1.type = TAILDIR a1.sources.r1.filegroups = f1 a1.sources.r1.filegroups.f1 = /usr/app/BigData/StreamingComputer/log/.*log.* a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 a1.sinks.k1.type = avro a1.sinks.k1.hostname = zoo3 a1.sinks.k1.port = 12345 a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
zoo3
a1.sources=r1 a1.channels=c1 a1.sinks=k1 a1.sources.r1.type = avro a1.sources.r1.bind = zoo3 a1.sources.r1.port = 12345 a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink a1.sinks.k1.kafka.topic = log a1.sinks.k1.kafka.bootstrap.servers = zoo1:9092,zoo2:9092,zoo3:9092 a1.sinks.k1.kafka.flumeBatchSize = 100 a1.sinks.k1.kafka.producer.acks = -1 a1.sinks.k1.kafka.producer.linger.ms = 1 a1.sinks.k1.kafka.producer.compression.type = snappy a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
Start command
bin/flume-ng agent --conf conf --conf-file conf/streaming_avro.conf --name a1 -Dflume.root.logger=INFO,console
6, Message queue (Kafka)
-
**Kfka official Chinese document:** https://kafka.apachecn.org/
-
Kafka cluster runs based on zookeeper. The installation and configuration details of zookeeper are as follows:
server.properties configuration
# Each machine has a unique broker ID, zoo2 and zoo3 are set to 2 and 3 respectively
broker.id=1
host.name=zoo1
listeners=PLAINTEXT://zoo1:9092
zookeeper.connect=zoo1:2181,zoo2:2182,zoo3:2181
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/usr/app/kafka_2.13-2.8.0/kafka-logs
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=localhost:2181
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=0
Kafka start command
bin/kafka-server-start.sh -daemon config/server.properties
Kafka cluster startup script
#!/bin/bash
for i in {1..3}
do
ssh zoo$i ". /etc/profile;echo '------------node$i--------';/usr/app/kafka_2.13-2.8.0/bin/kafka-server-start.sh -daemon /usr/app/kafka_2.13-2.8.0/config/server.properties"
done
Kafka add topic theme
bin/kafka-topics.sh --create --zookeeper zoo1:2181 --replication-factor 1 --partitions 1 --topic log # View theme bin/kafka-topics.sh --list --zookeeper zoo1:2181
IDEA consumer model
maven dependency
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>1.0.0</version>
</dependency>
Scala consumer model (test)
package kafka
import java.util
import java.util.Properties
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord, ConsumerRecords, KafkaConsumer}
import org.apache.kafka.common.serialization.StringDeserializer
object Consumer {
val bootstrapServer = "zoo1:9092,zoo2:9092,zoo3:9092"
val topic = "log"
def main(args: Array[String]): Unit = {
val pop = new Properties()
// Establish the "host / port pair" configuration list initially connected to the Kafka cluster
pop.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServer)
// Specifies the implementation class of the parsing serialization interface of the Key. The default is
pop.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, classOf[StringDeserializer].getName)
// Specifies the implementation class of the parsing serialization interface of the Value. The default is
pop.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, classOf[StringDeserializer].getName)
// The unique of the group to which the consumer belongs. This attribute is required if the consumer is used for the group management function of subscription or offset management policy.
pop.put(ConsumerConfig.GROUP_ID_CONFIG, "001")
/**
* The minimum amount of data returned by the pull request. If the data is insufficient, the request will wait for data accumulation.
* The default setting is 1 byte, which means that the read request will be answered as long as the data of a single byte is available or the read waiting request times out.
* Setting this value higher will cause the server to wait longer for data accumulation, which may improve the server throughput at the cost of some additional delay.
*/
pop.put(ConsumerConfig.FETCH_MIN_BYTES_CONFIG,1)
val consumer = new KafkaConsumer[String, String](pop)
//Subscribe to topics
val list = new util.ArrayList[String]()
list.add(topic)
consumer.subscribe(list)
//Consumption data
while (true) {
val value: ConsumerRecords[String, String] = consumer.poll(100)
val value1: util.Iterator[ConsumerRecord[String, String]] = value.iterator()
while (value1.hasNext) {
val value2: ConsumerRecord[String, String] = value1.next()
println(value2.key() + "," + value2.value())
}
}
}
}
7, Stream real time computing (Struct Stream)
- scala version: 2.12.10
- spark version: 3.0.0
Structure streaming real-time streaming processing
package bin
import java.sql.{Connection,Timestamp}
import java.text.SimpleDateFormat
import common.DataBaseConnection
import org.apache.spark.SparkConf
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
import org.apache.spark.sql.functions._
object Computer {
// Kafka cluster address and subject
val bootstrapServer = "zoo1:9092,zoo2:9092,zoo3:9092"
val topic = "log"
// Time conversion object
val ft = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
var sql = "delete from app01_data where 1=1 limit 8;"
val spark: SparkSession = SparkSession.builder().appName("log")
.config(new SparkConf().setMaster("spark://zoo1:7077")).getOrCreate()
import spark.implicits._
// main method
def main(args: Array[String]): Unit = run()
// Program entry
private def run(): Unit = {
val res = transData(spark)
val windowCounts: DataFrame = setWindow(res)
scannerData()
startProcess(windowCounts)
}
// Start StructStreaming and write to the database
private def startProcess(windowCounts: DataFrame): Unit = {
val query = windowCounts
.writeStream
.outputMode("Complete")
.foreachBatch((data: DataFrame, id: Long) => {
data.groupBy("course").max("count")
.withColumnRenamed("max(count)", "count")
.write
.format("jdbc")
.option("url", "jdbc:mysql://zoo1:3306/streaming_computer?useSSL=false")
.option("dbtable", "app01_data")
.option("user", "root")
.option("password", "1234")
.mode(SaveMode.Append)
.save()
})
.start()
query.awaitTermination()
query.stop()
}
// Set event window size
private def setWindow(res: DataFrame) = {
val windowCounts: DataFrame = res.withWatermark("timestamp", "60 minutes")
.groupBy(window($"timestamp", "30 minutes", "10 seconds"), $"course")
.count()
.drop("window")
windowCounts
}
// Clean and process data and convert data format
def transData(spark: SparkSession): DataFrame = {
val data = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", bootstrapServer)
.option("subscribe", topic)
.load()
// 2. Convert the data format to obtain the required data course+timestamp
val res = data.selectExpr("CAST(value AS STRING)")
.as[String]
.filter(!_.contains("Na"))
.map(line => (line.split(" ")(6).split("=")(1), new Timestamp(ft.parse(line.split(" ")(1) + " " + line.split(" ")(2)).getTime)))
.toDF("course", "timestamp")
res
}
// Scan database
def scannerData(): Unit = {
new Thread(() => {
val DBCon: Connection = new DataBaseConnection(
"jdbc:mysql://zoo1:3306/streaming_computer?useSSL=false",
"root",
"1234"
).getConnection
var len = 0
while (true) {
val pst = DBCon.prepareStatement(s"select count(*) from app01_data;")
val res = pst.executeQuery()
while (res.next()) {
len = res.getInt(1)
}
if (len > 16) {
DBCon.prepareStatement(sql).execute()
}
Thread.sleep(3000)
}
}).start()
}
}
jdbc tool class
package common
import java.sql.{Connection, DriverManager}
class DataBaseConnection(url:String, user:String, password:String) {
def getConnection: Connection ={
Class.forName("com.mysql.jdbc.Driver")
var con:Connection = DriverManager.getConnection(url, user, password)
con
}
}
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>chaney02_BigData</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<scala.version>2.12.10</scala.version>
<spark.version>3.0.0</spark.version>
<encoding>UTF-8</encoding>
</properties>
<dependencies>
<!--Import scala Dependence of-->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<!-- kafka -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql-kafka-0-10_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<!-- spark -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.38</version>
</dependency>
</dependencies>
<build>
<!--scala Directory of files to be compiled-->
<sourceDirectory>src/main/scala</sourceDirectory>
<!--scala plug-in unit-->
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<!--<arg>-make:transitive</arg>--><!--scala2.11 netbean This parameter is not supported-->
<arg>-dependencyfile</arg>
<arg>${project.build.directory}/.scala_dependencies</arg>
</args>
</configuration>
</execution>
</executions>
</plugin>
<!--manven Package plug-in-->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.AppendingTransformer">
<resource>reference.conf</resource>
</transformer>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>bin.Computer</mainClass> <!--main method-->
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
8, Front end data visualization (Django+EChars)
- Django version: 1.11.11
- Python version: 3.7.0
index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>ChaneyBigData</title>
<link href="https://cdn.jsdelivr.net/npm/bootstrap@3.3.7/dist/css/bootstrap.min.css" rel="stylesheet">
<script src="https://cdn.jsdelivr.net/npm/jquery@1.12.4/dist/jquery.min.js"></script>
<script src="https://cdn.jsdelivr.net/npm/bootstrap@3.3.7/dist/js/bootstrap.min.js"></script>
<script src="https://cdn.bootcss.com/echarts/4.2.1-rc1/echarts.min.js"></script>
</head>
<body>
<nav class="navbar navbar-inverse text-center">
<div class="page-header" style="color: white">
<h1>Spark BigData Program: Big data real-time stream processing log
<small>
<span class="glyphicon glyphicon-send center" aria-hidden="true"> </span>
<span class="glyphicon glyphicon-send center" aria-hidden="true"> </span>
<span class="glyphicon glyphicon-send center" aria-hidden="true"> </span>
</small>
</h1>
</div>
</nav>
<div class="container">
<div class="row">
<div class="col-md-10 col-md-offset-1">
<div class="jumbotron">
<h1>Real Time Course Selection</h1>
<div id="main" style="width: 800px;height:300px;"></div>
<script type="text/javascript">
</script>
</div>
</div>
</div>
<hr>
<div class="row">
<div class="col-md-8 col-md-offset-2">
<span><h4 class="text-center">
<span class="glyphicon glyphicon-home" aria-hidden="true"> </span>
Chaney.BigData.com
<span class="glyphicon glyphicon-envelope" aria-hidden="true"> </span>
Email: 133798276@yahoo.com
</h4>
</span>
</div>
</div>
</div>
<script>
$(function () {
flush()
});
function flush() {
setTimeout(flush, 10000);
$.ajax({
url: "http://127.0.0.1:8000/",
type: "post",
data: 1,
// Two key parameters
contentType: false,
processData: false,
success: function (data) {
const myChart = echarts.init(document.getElementById('main'));
const option = {
title: {},
tooltip: {},
legend: {},
xAxis: {
data: data.course
},
yAxis: {},
series: [{
type: 'bar',
data: [
{value: data.count[0],itemStyle: {color: '#00FFFF'}},
{value: data.count[1],itemStyle: {color: '#000000'}},
{value: data.count[2],itemStyle: {color: '#cff900'}},
{value: data.count[3],itemStyle: {color: '#cf0900'}},
{value: data.count[4],itemStyle: {color: '#d000f9'}},
{value: data.count[5],itemStyle: {color: '#FF7F50'}},
{value: data.count[6],itemStyle: {color: '#FF1493'}},
{value: data.count[7],itemStyle: {color: '#808080'}},
]
}]
};
myChart.setOption(option);
}
});
}
</script>
</body>
</html>
Django
models.py
from django.db import models class Data(models.Model): course = models.CharField(verbose_name='Course name', max_length=255) count = models.BigIntegerField(verbose_name='Number of selected courses')
views.py
from django.http import JsonResponse
from django.shortcuts import render
from app01 import models
def home(request):
if request.method == 'POST':
back_dic = {
"course": [],
"count": []
}
data = models.Data.objects.all()[:8]
for res in data:
back_dic["course"].append(res.course)
back_dic["count"].append(res.count)
return JsonResponse(back_dic)
return render(request, "index.html", locals())
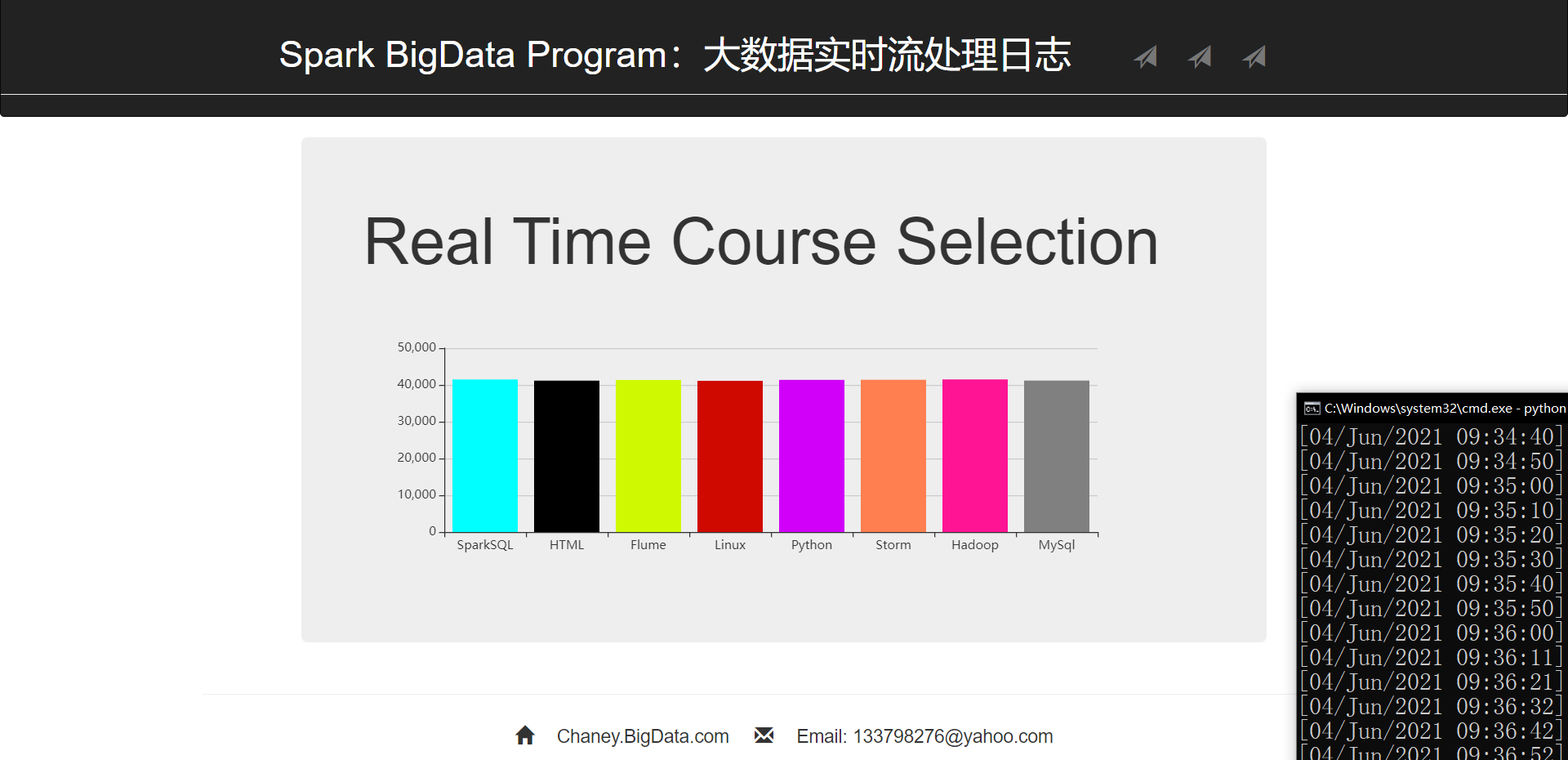
9, Project display
The chart refreshes automatically every 10 seconds
@Author: chaney
@Blog: https://blog.csdn.net/wangshu9939