After a busy day, I didn't do anything
Small talk:
I didn't do anything today. Unconsciously, it's the fifth day of the lunar new year. I'll start taking subject 4 in 5678 days. I hope to get my driver's license early
combineByKey

First explain the meaning of each parameter
- createCombiner: a function that creates a combination within a group. The popular point is to initialize the incoming data and take the current value as a parameter to perform some conversion operations Each key in the partition is called once
- The function of mergeValue: after merging each partition, that is, the function of mergeValue: before and after merging each partition. Accumulate the createCombiner result with the Value corresponding to the same key
- mergeCombiners: this function is mainly used to merge multiple partitions. The results corresponding to the same Key of each partition are aggregated
combineByKey() will traverse all elements in the partition. Therefore, each element has been encountered before or not. If it is a new element (referring to the key), createCombiner will be used to create the initial value of the accumulator corresponding to that key. It will only occur when each key appears for the first time, not when one appears
If it is a key that has appeared before, mergeValue will be used to merge the current value of the accumulator corresponding to the key with the new value
Just talking about the meaning of parameters without giving code is playing hooligans.
Let's practice this function through a case
One of Yuanzi's classmates asked for her average score. The scores of three subjects are 97, 96 and 95 Ask for her average score, three subjects, with a total score of 288 points. The average score was 96.
Look at the code
val wordCount = new SparkConf().setMaster("local").setAppName("WordCount")
val sparkContext = new SparkContext(wordCount)
val value1 = sparkContext.makeRDD(
List(("Yuanzi", 97), ("Yuanzi", 96), ("Yuanzi", 95)),2)
val value = value1.combineByKey(
//Convert grade to grade = = "
(Score, 1) score => (score, 1),
//Rules within the zone (score, 1) = (score + score, 1 + 1)
(tuple1: (Int, Int), v) => (tuple1._1 + v, tuple1._2 + 1),
//The regular scores and scores between divisions are added, and the times and times are added
(tuple2: (Int, Int), tuple3: (Int, Int)) =>
(tuple2._1 + tuple3._1, tuple2._2 + tuple3._2) )
val value2 = value.map {
case (name, (score, num)) => (name, score / num) }
value2.collect().foreach(println(_))Maybe you can't understand it just by looking at the code. Let's explain it one by one.
1.. First create the RDD
val value1 = sparkContext.makeRDD(List(("Yuanzi", 97), ("Yuanzi", 96), ("Yuanzi", 95)),2)2. Call combineByKey operator
val value = value1.combineByKey( //createCombiner, grouped by key, 97,96,95 //Average score = total score / number of subjects //First convert each subject score => (score, 1) //Rules within the zone (score, 1) = (score + score, 1 + 1) //(97,1) zone 2: (96 + 95,2) (tuple1: (Int, Int), v) => (tuple1._1 + v, tuple1._2 + 1), //The regular scores and scores between divisions are added, and the times and times are added (tuple2: (Int, Int), tuple3: (Int, Int)) => (tuple2._1 + tuple3._1, tuple2._2 + tuple3._2) )
3. Calculate the average
//Return value type of value
[String,[Int,Int]]
//String is the first Int of Yuanzi: total score, and the second Int: number of subjects
val value2 = value.map {
case (name, (score, num)) => (name, score / num) }Take a look at a similar illustration of the above case
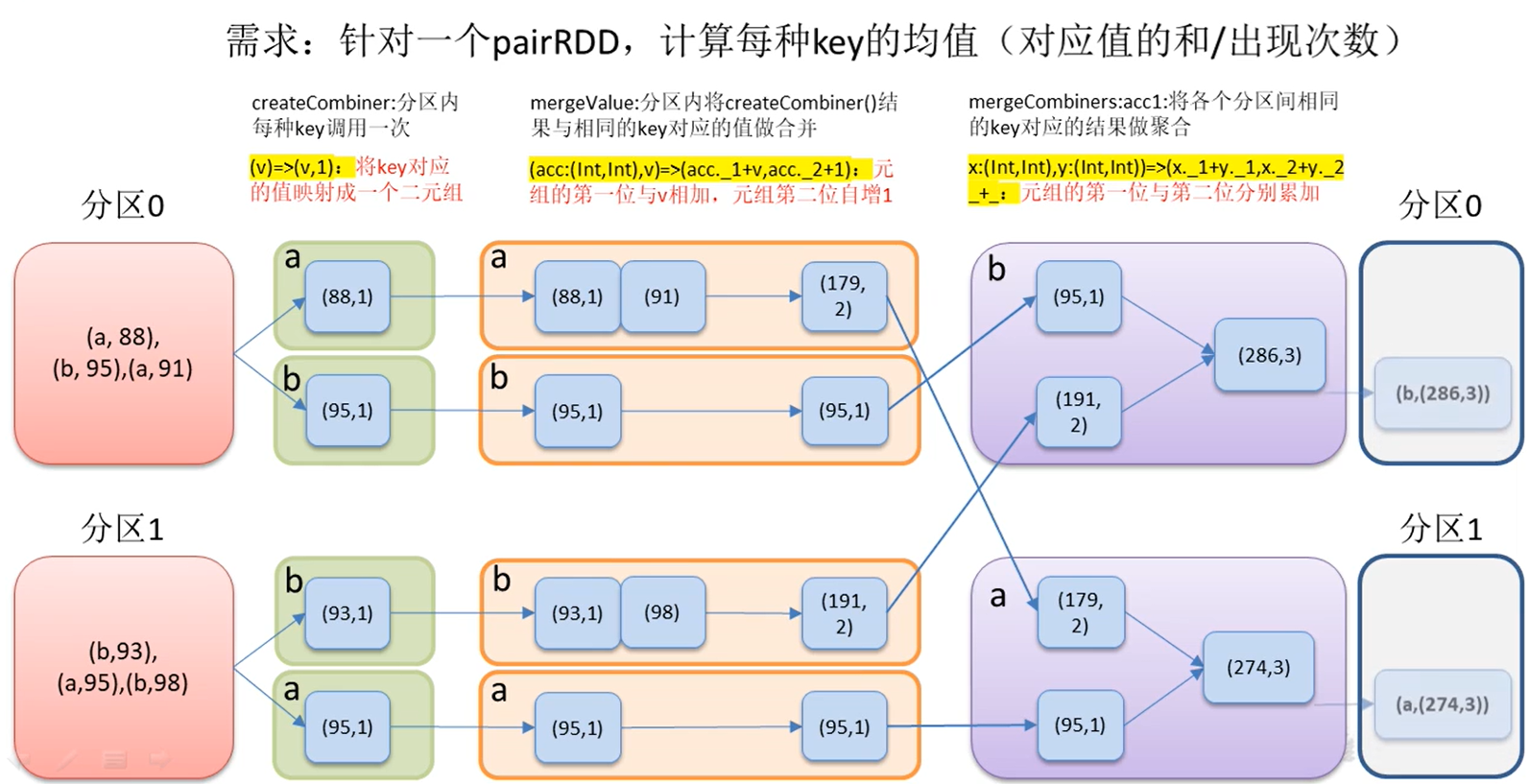
The above diagram can more clearly see the function of this operator.
Just after grouping, convert the grouped data
Add the data in the same group in the partition. When the total number is added, the number is also added
Add the data of the same key between partitions (the data here is the data calculated in the partition)
sortByKey
When called on a (k,v) RDD, K must implement the Ordered attribute and return one sorted by key
Let's look at this operator first
def sortByKey(ascending: Boolean = true,
numPartitions: Int = self.partitions.length) : RDD[(K, V)]
= self.withScope { val part = new RangePartitioner(numPartitions, self, ascending)
new ShuffledRDD[K, V, V](self, part) .setKeyOrdering(if (ascending) ordering else ordering.reverse) }shuffle will occur when using this operator, because the underlying layer inherits the new ShuffledRDD. Of course, you can choose whether to arrange in ascending or descending order according to the second parameter.
Get to know it through code
val wordCount = new SparkConf().setMaster("local").setAppName("WordCount")
val sparkContext = new SparkContext(wordCount)
val value1 = sparkContext.makeRDD(List((a, 97), (b, 96), (c, 95)),2) value1.sortByKey().collect().foreach(println(_))If the default is ascending, the result is
(a,97) (b,96) (c,95)
MapValues
Sometimes, we only want to access the value part of Pair RDD. At this time, it is troublesome to operate the binary. At this time, we use the mapValues(func) function provided by Spark. The function is similar to map {case (x, y): (x, func (y))}
Summary:
It's rotten today. I feel it's not written well. Tomorrow, we must study hard, output articles well, and accumulate so much writing. We must give full play to it.
TopN cases and action operators will be output tomorrow. If you can, you can also talk about RangePartitioner.
It's still four or five hundred to break the 20000 reading volume. Although this blog is very bad, I hope I can see the 20000 reading volume when I wake up tomorrow.
If you break 20000, you must blog well. It's too bad to put it away