I finally sank down and began to be more literate
Small talk:
This article will talk about some operators in Spark RDD, which are all about mapping.
Specifically, there are three operators: map, mappartitions and mappartitionwithindex There will be as few as possible to read the set of foreign operators in the set of six days after each time, because there will be as few as possible in the set of six points in the set of other operators.
map
We can do many things with map. We can extract the host name corresponding to each URL in the URL set, or simply average each number. The return value type of map() operator does not need to be the same as the input type.
First, let's look at the function signature of the map() operator
def map[U: ClassTag](f: T => U): RDD[U]
Parameter f is a function that can accept a function. When RDD executes the map method, it will traverse each element in RDD, and each element will go through the map operation, and then generate a new RDD.
Take an example
Create an RDD composed of 1-4 numbers and two partitions. It will be said that some elements * 2 get a new RDD
val wordCount = new SparkConf().setMaster("local").setAppName("WordCount")
val sparkContext = new SparkContext(wordCount)
val value = sparkContext.makeRDD(List(1, 2, 3, 4),2)
val value1 = value.map(_ * 2)
println(value1.partitions.size)
value1.collect().foreach(println(_))It should be noted that if Local is set in the Master above, if the number of partitions is not specified when reading the List, the system defaults to one partition. If the number of partitions is specified, the number of partitions is the number of partitions set. If Local [*] is not set, it defaults to the number of Local cpu cores. For example, if the number of cpu cores of my computer is 12, there will be 12 partitions, and there will be 12 files when saving astextfile.
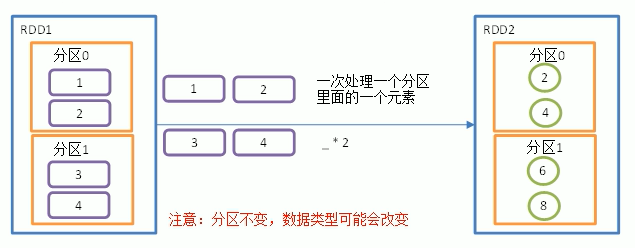
As mentioned above, the map will only process one element in one partition at a time.
After processing, it is still the original partition.
Mappartitions RDD is used at the bottom of the map
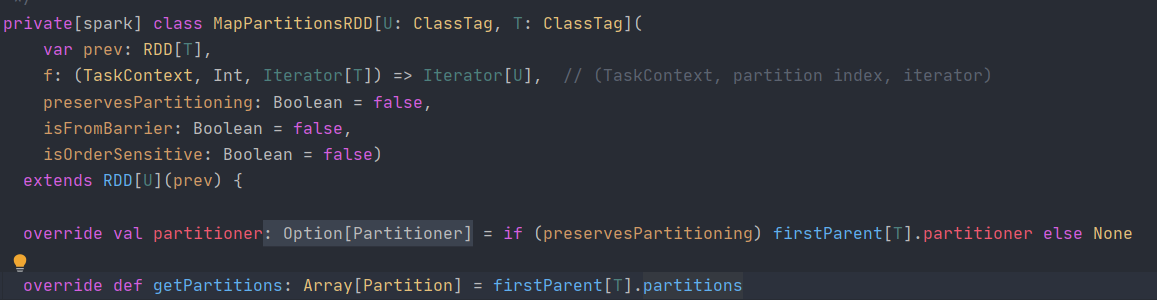
You can see that the getPartitions method is rewritten,
protected[spark] def firstParent[U: ClassTag]: RDD[U] = { dependencies.head.rdd.asInstanceOf[RDD[U]] }The above dependencies head. RDD refers to superior dependency. There is also dependency in RDD. Later, the blog will talk about that the newly created RDD depends on the previous RDD. The RDD after map conversion depends on the RDD before conversion. The new RDD will get the partition of the old RDD, which is why the partition elements remain unchanged after conversion
mapPartitions
mapPartitions will operate on the whole partition. Compared with map, it can process the number of whole partitions at one time. However, if the data is too large, there may be insufficient memory and an error will be reported
Look at the function signature
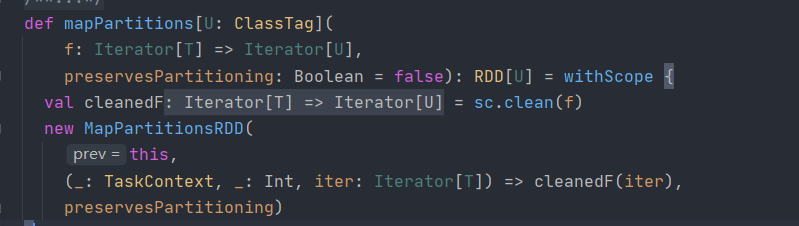
The required parameter is an iterator type.
In the 1-4 array, the filter can divide by 2
val wordCount = new SparkConf().setMaster("local").setAppName("WordCount")
val sparkContext = new SparkContext(wordCount)
val value = sparkContext.makeRDD(List(1, 2, 3, 4),2)
val value1 = value.mapPartitions(datas => { datas.filter(_ % 2 == 0) })
value1.collect().foreach(println(_))The above is just an introduction. The next training is to calculate the maximum value of each partition since it is calculated according to the partition
Let's illustrate it first,

For two partitions, each call will process one partition and find the maximum value of the partition. According to the idea, you can write code
val wordCount = new SparkConf().setMaster("local").setAppName("WordCount")
val sparkContext = new SparkContext(wordCount)
val value = sparkContext.makeRDD(List(1, 2, 3, 4),2)
val value1 = value.mapPartitions(iter => { List(iter.max).iterator })
value1.collect().foreach(println(_)) }mapPartitions requires that the input parameter is iter and the return value type is iter.
For each iter, the iter here refers to the iter composed of numbers in a partition. Find the maximum value in iter. Find the maximum value and then encapsulate it into iter type
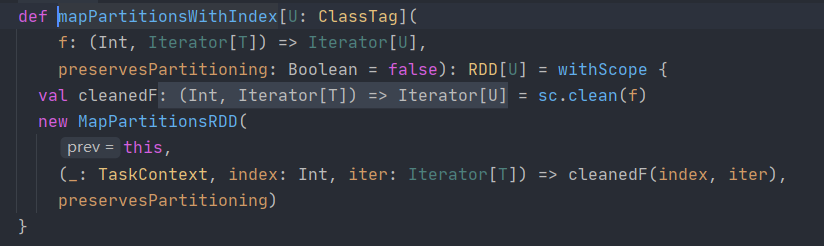
MapPartitionsWithIndex
The parameters required for this operator are (index,iter)
The first parameter is the subscript of the partition, and the second parameter is the data in each partition.
The table below each partition and the elements in each partition form a tuple
Let's take a case to filter out the elements with partition 2
val wordCount = new SparkConf().setMaster("local").setAppName("WordCount")
val sparkContext = new SparkContext(wordCount)
//1 2 one partition 3 4 one partition
val value = sparkContext.makeRDD(List(1, 2, 3, 4),2)
val value1 = value.mapPartitionsWithIndex((index, iter) => {
//If it is the second partition, it returns iter. If not, it returns null
if (index == 1) { iter } else { Nil.iterator } })
value1.collect().foreach(println(_))The second partition is 3 and 4, so the final output is 3 and 4
Here's an illustration
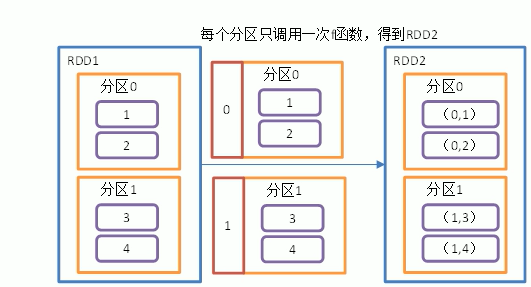
The code corresponding to the above diagram is as follows,
val wordCount = new SparkConf().setMaster("local").setAppName("WordCount")
val sparkContext = new SparkContext(wordCount)
val value = sparkContext.makeRDD(List(1, 2, 3, 4),2)
val value1 = value.mapPartitionsWithIndex((index, iter) => {
iter.map(num => (index, num)) })
value1.collect().foreach(println(_))Summary:
Today's introduction is about the operators of map. There are many operators of Spark. After introducing the operators in Spark, we will explain the accumulator and partition.
The next step is Spark SQL, which should be finished in 20 days.
When Spark SQL comes, it will be integrated with Hive. This is the role of Hive we learned earlier, not only for the learning of data warehouse, but also for the learning of Spark
Spark series and Scala series will also be updated tomorrow