1: RDD operator
RDD operators, also known as RDD methods, are mainly divided into two categories. Conversion operator and action operator.

2: RDD conversion operator
According to different data processing methods, the operators are divided into value type, double value type and key value type
2.1: map value conversion
package com.atguigu.bigdata.spark.rdd.operator.transform
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object Spark01_RDD_Operator_Transform {
def main(args: Array[String]): Unit = {
//Prepare the environment
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
//Create RDD
val rdd = sc.makeRDD(List(1,2,3,4))
def mapFunction(num:Int):Int = {
num * 2
}
val mapRDD:RDD[Int] = rdd.map(mapFunction)
mapRDD.collect().foreach(println) //2 4 6 8
//Turn off the environment
sc.stop()
}
}
2.2: map parallel effect display
package com.atguigu.bigdata.spark.rdd.operator.transform
import org.apache.spark.{SparkConf, SparkContext}
object Spark01_RDD_Operator_Transform_Par {
def main(args: Array[String]): Unit = {
//Prepare the environment
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
//Create RDD
//1.rdd calculation, data in a partition executes logic one by one
// The next data will be executed only after all the logic of the previous data has been executed
// The execution of data in the partition is orderly
//2. The data calculation of different partitions is out of order
val rdd = sc.makeRDD(List(1,2,3,4))
val mapRDD = rdd.map(
num => {
println(">>>>>>" + num)
num
}
)
val mapRDD1 = mapRDD.map(
num => {
println("#####" + num)
num
}
)
mapRDD1.collect()
//Turn off the environment
sc.stop()
}
}
2.3: mapPartitions: data conversion can be performed in partitions
package com.atguigu.bigdata.spark.rdd.operator.transform
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object Spark02_RDD_Operator_Transform {
def main(args: Array[String]): Unit = {
//Prepare the environment
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
//Create RDD
val rdd = sc.makeRDD(List(1,2,3,4),2)
val mapRDD:RDD[Int] = rdd.mapPartitions(
//The number of executions is the number of partitions
iter => {
println(">>>>>>>>")
iter.map(_*2)
}
)
mapRDD.collect().foreach(println) //2 4 6 8
//Turn off the environment
sc.stop()
}
}
2.4: the difference between map and mapPartitions
Data processing angle
map: the execution of one data in a partition, similar to serial operation.
Mappartitions: batch operations are performed in partitions.
Functional perspective
map: Transform and change the data in the data source, but it will not reduce or increase the data
Mappartitions: you need to pass an iterator and return an iterator. The number of elements not required remains unchanged, so you can increase or decrease data.
Performance perspective
map: similar to serial operation, the performance is relatively low.
Mappartitions: similar to batch operation, with high performance. However, if the content is occupied for a long time, it will lead to insufficient memory and memory overflow errors. Therefore, it is not recommended when the memory is limited. Use the map operation.
2.5: mapParitionsWithIndex: get the specified partition
package com.atguigu.bigdata.spark.rdd.operator.transform
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object Spark03_RDD_Operator_Transform {
def main(args: Array[String]): Unit = {
//Prepare the environment
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
//Create RDD
//Get the data in the second partition
val rdd = sc.makeRDD(List(1,2,3,4),2)
val mapRDD:RDD[Int] = rdd.mapPartitionsWithIndex(
(index,iter) => {
if (index == 1){
iter
}else{
Nil.iterator
}
}
)
mapRDD.collect().foreach(println) //2 4 6 8
//Turn off the environment
sc.stop()
}
}
2.6: flatmap: flattening operation
package com.atguigu.bigdata.spark.rdd.operator.transform
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object Spark04_RDD_Operator_Transform {
def main(args: Array[String]): Unit = {
//Prepare the environment
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
//Create RDD
val rdd:RDD[List[Int]] = sc.makeRDD(List(List(1,2),List(3,4)))
val flatRDD:RDD[Int] = rdd.flatMap(
list => {
list
}
)
flatRDD.collect().foreach(println)
//Turn off the environment
sc.stop()
}
}
2.6: flattening exercise: output 1, 2, 3, 4, 5
package com.atguigu.bigdata.spark.rdd.operator.transform
import org.apache.spark.{SparkConf, SparkContext}
object Spark04_RDD_Operator_Transform {
def main(args: Array[String]): Unit = {
//Environmental preparation
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
//Create RDD
val rdd = sc.makeRDD(List(List(1,2),3,List(4,5)))
val flatRDD = rdd.flatMap(
date => {
date match {
case list:List[_] => list
case dat => List(dat)
}
}
)
flatRDD.collect().foreach(println)
//Turn off the environment
sc.stop()
}
}
2.7: glom
package com.atguigu.bigdata.spark.rdd.operator.transform
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark05_RDD_Operator_Transform {
def main(args: Array[String]): Unit = {
//Prepare the environment
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
//Create RDD
val rdd:RDD[Int] = sc.makeRDD(List(1,2,3,4),2)
//List => Int
//Int => List
val glomRDD:RDD[Array[Int]] = rdd.glom()
glomRDD.collect().foreach(data=>println(data.mkString(",")))
//Turn off the environment
sc.stop()
}
}
2.8: glom case: calculate the sum of the maximum values of all partitions, the maximum values within partitions and the maximum values between partitions
package com.atguigu.bigdata.spark.rdd.operator.transform
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object Spark06_RDD_Operator_Transform_Test {
def main(args: Array[String]): Unit = {
//Prepare the environment
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
//Create RDD
val rdd:RDD[Int] = sc.makeRDD(List(1,2,3,4),2)
val glomRDD:RDD[Array[Int]] = rdd.glom()
val maxRDD:RDD[Int] = glomRDD.map(
array => {
array.max
}
)
println(maxRDD.collect().sum)
//Turn off the environment
sc.stop()
}
}
2.9 the meaning of partition invariability, partition name and data are invariable. output has 00000 and 00001, which are 1, 2 and 3, 4 respectively. output1 has 00000 and 00001, which are 2, 4, 6 and 8 respectively
package com.atguigu.bigdata.spark.rdd.operator.transform
import org.apache.spark.{SparkConf, SparkContext}
object Spark01_RDD_Operator_Transform_Part {
def main(args: Array[String]): Unit = {
//Prepare the environment
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
//Create RDD
val rdd = sc.makeRDD(List(1,2,3,4),2)
rdd.saveAsTextFile("output")
//
val mapRDD = rdd.map(_*2)
mapRDD.saveAsTextFile("output1")
//Turn off the environment
sc.stop()
}
}
2.10: group by, there is no necessary relationship between grouping and partition. groupby will disrupt and shuffle the data
package com.atguigu.bigdata.spark.rdd.operator.transform
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object Spark06_RDD_Operator_Transform {
def main(args: Array[String]): Unit = {
//Prepare the environment
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
//Create RDD
val rdd:RDD[Int] = sc.makeRDD(List(1,2,3,4),2)
//groupby will group and judge each data in the data source and group it according to the returned grouping key
//Data with the same key value will be placed in a group
def groupFunction(num:Int):Int = {
num % 2
}
val groupRDD:RDD[(Int,Iterable[Int])] = rdd.groupBy(groupFunction)
groupRDD.collect().foreach(println)
//Turn off the environment
sc.stop()
}
}
package com.atguigu.bigdata.spark.rdd.operator.transform
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object Spark06_RDD_Operator_Transform1 {
def main(args: Array[String]): Unit = {
//Prepare the environment
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
//Create RDD
//Grouping according to the initial letter has no necessary relationship with grouping
val rdd = sc.makeRDD(List("hello","spark","scala","hadoop"),2)
val groupRDD = rdd.groupBy(_.charAt(0))
groupRDD.collect().foreach(println)
//Turn off the environment
sc.stop()
}
}
2.11: filter. Data filtering operation. May cause data skew. For example, there are 1000 pieces of data in the previous two partitions. After filtering, there may be a large difference in the amount of data in the two partitions.
package com.atguigu.bigdata.spark.rdd.operator.transform
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object Spark07_RDD_Operator_Transform {
def main(args: Array[String]): Unit = {
//Prepare the environment
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
//Create RDD
val rdd:RDD[Int] = sc.makeRDD(List(1,2,3,4))
val filter:RDD[Int] = rdd.filter(num=>num%2!=0)
filter.collect().foreach(println)
//Turn off the environment
sc.stop()
}
}
2.12: sample: data extraction operation, which can judge what affects data skew according to random extraction.
package com.atguigu.bigdata.spark.rdd.operator.transform
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object Spark08_RDD_Operator_Transform {
def main(args: Array[String]): Unit = {
//Prepare the environment
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
//Create RDD
val rdd:RDD[Int] = sc.makeRDD(List(1,2,3,4,5,6,7,8,9,10))
//The sample operator needs to pass three parameters
//1. The first parameter indicates whether to return the data to true (put back) and false (discard) after extracting the data
//2. The second parameter indicates,
// If the extraction is not put back: the probability that each data in the data source is extracted: the concept of reference value
// If the extraction is put back, it indicates the possible number of times each data in the data source is extracted
//3. The third parameter represents the seed of the random algorithm when extracting data
// If the third parameter is not passed, the current system time is used
println(rdd.sample(
false,
fraction = 0.4, //The probability of each value is not necessarily 10 pieces of data, but four pieces of data will be extracted
seed = 1
).collect().mkString(","))
//Turn off the environment
sc.stop()
}
}
2.13: distinct: weight removal
package com.atguigu.bigdata.spark.rdd.operator.transform
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object Spark09_RDD_Operator_Transform {
def main(args: Array[String]): Unit = {
//Prepare the environment
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
//Create RDD
val rdd:RDD[Int] = sc.makeRDD(List(1,2,3,4,1,2,3,4))
val rdd1:RDD[Int] = rdd.distinct()
rdd1.collect().foreach(println)
//Turn off the environment
sc.stop()
}
}
2.14: coalesce: after filtering, the data in the partition may be greatly reduced to avoid resource waste. The partition can be reduced according to the amount of data. After filtering large data sets, it can improve the execution efficiency of small data sets..
package com.atguigu.bigdata.spark.rdd.operator.transform
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object Spark10_RDD_Operator_Transform {
def main(args: Array[String]): Unit = {
//Prepare the environment
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
//Create RDD
val rdd:RDD[Int] = sc.makeRDD(List(1,2,3,4,5,6),3)
//coalesce: by default, the data will not be disordered and recombined, and the data in the same partition will not be assigned to different partitions
//Reducing partitions in this case may lead to data imbalance and data skew
//If you want to balance the data, you can use shuffle. The second parameter represents shuffle
val newRDD:RDD[Int] = rdd.coalesce(2,true)
newRDD.saveAsTextFile("output")
//Turn off the environment
sc.stop()
}
}
2.15: repartition: expand partition
package com.atguigu.bigdata.spark.rdd.operator.transform
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object Spark11_RDD_Operator_Transform {
def main(args: Array[String]): Unit = {
//Prepare the environment
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
//Create RDD
val rdd:RDD[Int] = sc.makeRDD(List(1,2,3,4,5,6),2)
//coalesce: you can expand the partition, but you need to pay attention to whether the expansion partition needs to be disrupted again. If necessary, you need to change the second parameter to true and use shuffle
val newRDD:RDD[Int] = rdd.repartition(3)
newRDD.saveAsTextFile("output")
//Turn off the environment
sc.stop()
}
}
Default: sortby 16.2:
package com.atguigu.bigdata.spark.rdd.operator.transform
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object Spark12_RDD_Operator_Transform {
def main(args: Array[String]): Unit = {
//Prepare the environment
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
//Create RDD
val rdd:RDD[Int] = sc.makeRDD(List(6,2,4,5,3,1),2)
//sortby defaults to ascending order. The second parameter can change the sorting method
//sortby by default, the partition will not be changed, but there is a shuffle operation in the middle
val newRDD:RDD[Int] = rdd.sortBy(num=>num)
newRDD.saveAsTextFile("output")
//Turn off the environment
sc.stop()
}
}
2.17: double value types: intersection, union, difference and zipper
package com.atguigu.bigdata.spark.rdd.operator.transform
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object Spark13_RDD_Operator_Transform {
def main(args: Array[String]): Unit = {
//Prepare the environment
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
//Create rdd double value operation, two RDDS
val rdd1 = sc.makeRDD(List(1,2,3,5))
val rdd2 = sc.makeRDD(List(3,4,5,6))
//Intersection, union and difference sets need to keep the data types of the two data sources consistent
//The zipper operation can make the data types of the two data sources inconsistent. The zipper requires that the number of partitions of the two data sources should be consistent, and the contents of the data sources should also be consistent
//Intersection [3,4]
val rdd3:RDD[Int] = rdd1.intersection(rdd2)
println(rdd3.collect().mkString(","))
//Union [1,2,3,4,3,4,5,6]
val rdd4:RDD[Int] = rdd1.union(rdd2)
println(rdd4.collect().mkString(","))
//Angle of difference set rdd1 = = > [1,2]
val rdd5:RDD[Int] = rdd1.subtract(rdd2)
println(rdd5.collect().mkString(","))
//Zipper [1-3,2-4,3-5,4-6]
val rdd6:RDD[(Int, Int)] = rdd1.zip(rdd2)
println(rdd6.collect().mkString(","))
//Turn off the environment
sc.stop()
}
}
2.18: key value type: paritionby. Partition device to change the location of data storage.
package com.atguigu.bigdata.spark.rdd.operator.transform
import org.apache.spark.{HashPartitioner, SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object Spark14_RDD_Operator_Transform {
def main(args: Array[String]): Unit = {
//Prepare the environment
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
//Create rdd double value operation, two RDDS
val rdd = sc.makeRDD(List(1,2,3,4),2)
val mapRDD = rdd.map((_,1))
mapRDD.partitionBy(new HashPartitioner(2))
.saveAsTextFile("output")
//Turn off the environment
sc.stop()
}
}
2.19: reduceByKey: aggregate value data with the same key data
package com.atguigu.bigdata.spark.rdd.operator.transform
import org.apache.spark.{HashPartitioner, SparkConf, SparkContext}
object Spark15_RDD_Operator_Transform {
def main(args: Array[String]): Unit = {
//Prepare the environment
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
//Create rdd double value operation, two RDDS
val rdd = sc.makeRDD(List(("a",1),("a",2),("a",3),("a",4)))
//Aggregate the value data with the same key
//If there is only one data in reduceby key, it will not participate in the operation
val reduceRDD = rdd.reduceByKey((x:Int,y:Int) => {x+y})
reduceRDD.collect().foreach(println)
//Turn off the environment
sc.stop()
}
}
2.20: groupByKey: divide the numbers in the data source and the data with the same key into a group to form a dual tuple
package com.atguigu.bigdata.spark.rdd.operator.transform
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark16_RDD_Operator_Transform {
def main(args: Array[String]): Unit = {
//Prepare the environment
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
//Create rdd double value operation, two RDDS
val rdd = sc.makeRDD(List(("a",1),("a",2),("a",3),("b",4)))
//groupByKey: divide the data in the data source and the data with the same key into a group to form a dual tuple
// The first element in the tuple is the key, and the second element in the tuple is the set of value s of the same key
val groupRDD:RDD[(String,Iterable[Int])] = rdd.groupByKey()
groupRDD.collect().foreach(println)
//Turn off the environment
sc.stop()
}
}
2.21: the difference between reduceByKey and groupByKey
Performance: reduceByKey be better than groupByKey
reduceByKey Support the function of pre aggregation in the partition, which can effectively reduce shuffle Data volume of falling disk
Function: groupByKey be better than reduceByKey
If we say that we only need grouping, we don't need aggregation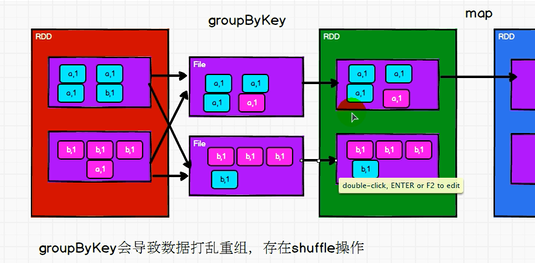
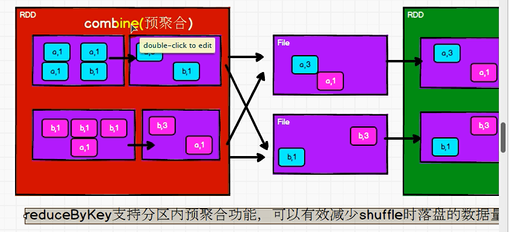
2.22: aggregateByKey: different operations can be performed within and between partitions
package com.atguigu.bigdata.spark.rdd.operator.transform
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object Spark17_RDD_Operator_Transform {
def main(args: Array[String]): Unit = {
//Prepare the environment
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
//Create rdd double value operation, two RDDS
val rdd = sc.makeRDD(List(("a",1),("a",2),("a",3),("b",4)),2)
//aggregateByKey has function coritization and has two parameter lists
//For the first parameter list, you need to pass a parameter expressed as the initial value
// It is mainly used for intra partition calculation with value when the first key is encountered
//The second parameter list needs to pass 2 parameters
// The first parameter represents the calculation rule in the partition
// The second parameter represents the inter partition calculation rule
rdd.aggregateByKey(0)(
(x,y) => math.max(x,y),
(x,y) => x + y
).collect.foreach(println)
//Turn off the environment
sc.stop()
}
}
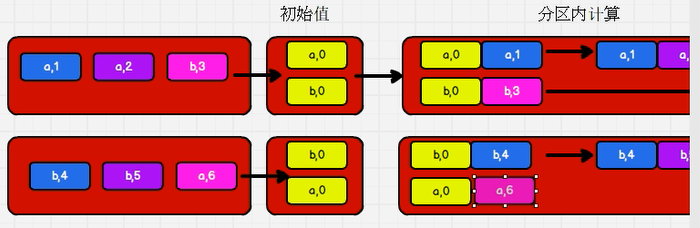
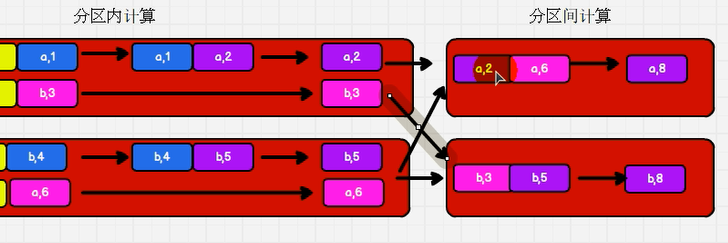
2.23: foldByKey: the calculation rules within and between partitions are the same
package com.atguigu.bigdata.spark.rdd.operator.transform
import org.apache.spark.{SparkConf, SparkContext}
object Spark17_RDD_Operator_Transform2 {
def main(args: Array[String]): Unit = {
//Prepare the environment
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
//Create rdd double value operation, two RDDS
val rdd = sc.makeRDD(List(("a",1),("a",2),("b",3),("b",4),("b",5),("a",6)),2)
rdd.foldByKey(0)(_+_).collect.foreach(println)
//Turn off the environment
sc.stop()
}
}
2.24: combineByKey
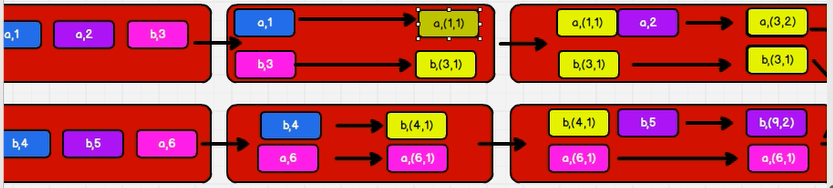
val list: List[(String, Int)] = List(("a", 88), ("b", 95), ("a", 91), ("b", 93),
("a", 95), ("b",
val input: RDD[(String, Int)] = sc.makeRDD(list, 2)
val combineRdd: RDD[(String, (Int, Int))] = input. combineByKey
(_,
(acc: (Int, Int), v) => (acc._1 + v, acc._2 +
(acc1: (Int, Int), acc2: (Int, Int)) => (acc1._1 + acc2._1, acc1._2 + acc2._2.25: differences among reduceByKey, foldByKey, aggregateByKey and combineByKey
reduceByKey: the first data of the same key is not calculated. The calculation rules within and between partitions are the same
FoldByKey: the first data and initial value of the same key are calculated within the partition. The calculation rules within and between partitions are the same
AggregateByKey: the first data and initial value of the same key are calculated within the partition. The calculation rules within and between partitions can be different
CombineByKey: when it is found that the data structure does not meet the requirements during calculation, the first data structure can be converted. The calculation rules within and between partitions are different.
2.26: join: for data from two different data sources, the value of the same key will be connected together to form a tuple
package com.atguigu.bigdata.spark.rdd.operator.transform
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark19_RDD_Operator_Transform {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
//Create rdd double value operation, two RDDS
val rdd1 = sc.makeRDD(List(("a",1),("b",2),("c",3)))
val rdd2 = sc.makeRDD(List(("b",4),("c",5),("a",6)))
//join: data from two different data sources and the value of the same key will be connected together to form a tuple
// If the key s in the two data sources are not matched, the data will not appear in the result. There are m items in one data source and n items in the other data source, and the matching times are n*m
val joinRDD: RDD[(String, (Int, Int))] = rdd1.join(rdd2)
joinRDD.collect().foreach(println)
//Turn off the environment
sc.stop()
}
}
2.27: left outer join: a left outer join similar to sql / / right outer join
package com.atguigu.bigdata.spark.rdd.operator.transform
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object Spark20_RDD_Operator_Transform {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
//Create rdd double value operation, two RDDS
val rdd1 = sc.makeRDD(List(("a",1),("b",2),("c",3)))
val rdd2 = sc.makeRDD(List(("a",4),("b",5)))
val joinRDD = rdd1.leftOuterJoin(rdd2)
joinRDD.collect().foreach(println)
//Turn off the environment
sc.stop()
}
}
2.28: cogroup: put the same key in the same data source into a group, and then connect it with other data sources
package com.atguigu.bigdata.spark.rdd.operator.transform
import org.apache.spark.{SparkConf, SparkContext}
object Spark21_RDD_Operator_Transform {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
//Create rdd double value operation, two RDDS
val rdd1 = sc.makeRDD(List(("a",1),("b",2)))
val rdd2 = sc.makeRDD(List(("a",4),("b",5),("c",6),("c",7)))
// cogroup connect + group put the same key in one data source into one group, and then connect with other data sources
val cgRDD = rdd1.cogroup(rdd2)
cgRDD.collect().foreach(println)
//Turn off the environment
sc.stop()
}
}
2.29: collect
package com.atguigu.bigdata.spark.rdd.operator.action
import org.apache.spark.{SparkConf, SparkContext}
object Spark01_RDD_Operator_Action {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD(List(1,2,3,4))
//Method for action operator to trigger job execution
rdd.collect()
//The underlying code calls the runJob method of the environment object
//ActiveJob will be created in the underlying code and submitted for execution
sc.stop()
}
}
2.30: action operator
package com.atguigu.bigdata.spark.rdd.operator.action
import org.apache.spark.{SparkConf, SparkContext}
object Spark02_RDD_Operator_Action {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD(List(1,2,3,4))
/* //The action operator reduce aggregates all the elements in the rdd, first aggregating the data in the partition, and then aggregating the data between partitions
val i = rdd.reduce(_+_)
println(i) // 10*/
//collect, which returns all elements of the data set in the form of array according to the partition order of the data in different partitions
/*rdd.collect().foreach(println)*/
//count: the number of data in the data source
val cnt = rdd.count()
println(cnt)
//First: get the first data in the data source
val first = rdd.first()
println(first)
//Get the first three data in the data source
val ints = rdd.take(3)
println(ints.mkString(","))
//After sorting, take the first three and sort from small to large
val ints1 = rdd.takeOrdered(3)
println(ints1.mkString(","))
sc.stop()
}
}
2.31: action operator aggregate
package com.atguigu.bigdata.spark.rdd.operator.action
import org.apache.spark.{SparkConf, SparkContext}
object Spark03_RDD_Operator_Action {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD(List(1,2,3,4),2)
//aggregateByKey: the initial value will only participate in the calculation within the partition
//aggregate: the initial value will participate in intra partition calculation and inter partition calculation
val i = rdd.aggregate(10)(_+_,_+_)
println(i)
sc.stop()
}
}
2.32: action operator - countByKey and countByValue
package com.atguigu.bigdata.spark.rdd.operator.action
import org.apache.spark.{SparkConf, SparkContext}
object Spark05_RDD_Operator_Action {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
// val rdd = sc.makeRDD(List(1,2,3,4),2)
val rdd = sc.makeRDD(List(("a",1),("a",1),("a",1)))
//countByValue: the number of occurrences of the statistical value
// val intToLong = rdd.countByValue()
//countByKey: counts the number of key occurrences
val intToLong = rdd.countByKey()
println(intToLong)
sc.stop()
}
}
2.33 - action operator - save
package com.atguigu.bigdata.spark.rdd.operator.action
import org.apache.spark.{SparkConf, SparkContext}
object Spark06_RDD_Operator_Action {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD(List(("a",1),("a",2),("a",3)))
rdd.saveAsTextFile("output")
rdd.saveAsObjectFile("output1")
// saveAsSequenceFile requires that the format of data must be key value type to use this method
rdd.saveAsSequenceFile("output2")
sc.stop()
}
}
2.34 - action operator foreach
package com.atguigu.bigdata.spark.rdd.operator.action
import org.apache.spark.{SparkConf, SparkContext}
object Spark07_RDD_Operator_Action {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD(List(1,2,3,4))
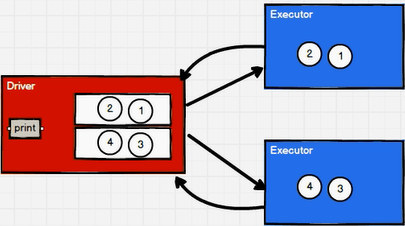
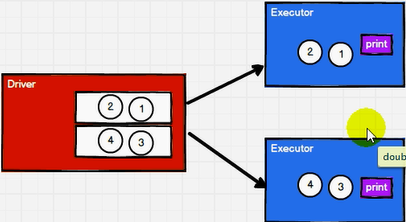
rdd.collect().foreach(println) //Loop traversal method of driver side memory set
println("-------")
rdd.foreach(println) //executor side, memory data printing, no sequence concept
sc.stop()
}
}