Spark Day06: Spark Core

01 - [understand] - course content review
It mainly explains three aspects: Sogou log analysis, external data sources (HBase and MySQL) and shared variables.
1,Sogou Log analysis Search based on the official log SparkCore(RDD)Business analysis Data format: Text file data, and each data is the log data of the web page clicked by the user when searching Use tab breaks between fields Business requirements: - Search keyword statistics, involving knowledge points and Chinese word segmentation: HanLP - User search click statistics - Search time period statistics Coding implementation The first step is to read the log data and encapsulate it into the entity class object SougouRecord Step 2: analyze data according to business requirements word frequency count WordCount deformation 2,External data source SparkCore And HBase and MySQL Database interaction - HBase Data source, bottom layer MapReduce from HBase Table reading and writing data API Save data to HBase surface TableOutputFormat RDD[(RowKey, Put)],among RowKey = ImmutableBytesWritable from HBase Table load data TableInputFormat RDD[(RowKey, Result)] from HBase To read and write data, first find HBase Database dependency Zookeeper Address information - MySQL data source Save data RDD reach MySQL In the table, considering the performance problem, there are five aspects Consider reducing RDD Number of partitions Operate on partition data and create 1 connection for each partition Each partition writes data to MySQL Database table, batch write Each partition data can be added to the batch Batch write all data Transactional, the data in the batch is either successful or failed Human commit transaction Considering the particularity of big data analysis, run the program repeatedly, process the same data and save it to MySQL In the table Update the data when the primary key exists; Insert data when it does not exist REPLACE INTO ............ 3,Shared variable( Shared Variables) Indicates that a value (variable) is Task share - Broadcast variable Broadcast Variables,Shared variable values cannot be changed solve the problem: Shared variable storage problem, after the variable is broadcast, only in each Executor Store one copy in the; If the variables are not broadcast, each Task Store one copy in the. Save memory by broadcasting variables - accumulator Accumulators,Shared variable values can be changed and can only be "accumulated" similar MapReduce Frame type counter Counter,Play the role of cumulative statistics Spark The framework provides three types of accumulators: LongAccumulator,DoubleAccumulator,CollectionAccumulator
02 - [understanding] - course content outline
It mainly explains two aspects: Spark kernel scheduling and spark SQL quick start
1,Spark Kernel scheduling (understanding) understand Spark How does the framework work Job Program, word frequency statistics WordCount Program as an example, how to execute the program RDD rely on DAG Figure Stage stage Shuffle Job Scheduling process Spark Basic concepts Parallelism 2,SparkSQL quick get start SparkSQL Program entry in: SparkSession be based on SparkSQL Realize word frequency statistics SQL Statement, similar Hive DSL Statement, similar RDD Call in API,Chain programming SparkSQL Module overview Past life and present life Official definition Several characteristics
03 - [Master] - an example of Spark kernel scheduling WordCount
The core of Spark is implemented according to RDD, and Spark Scheduler is an important part of the core implementation of Spark, and its role is task scheduling.
Spark's task scheduling is how to organize tasks to process the data of each partition in RDD, build DAG according to the dependency of RDD, divide stages based on DAG, and send the tasks in each Stage to the specified node for operation.
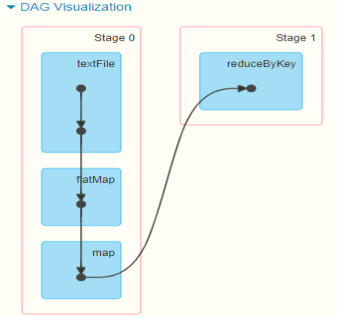
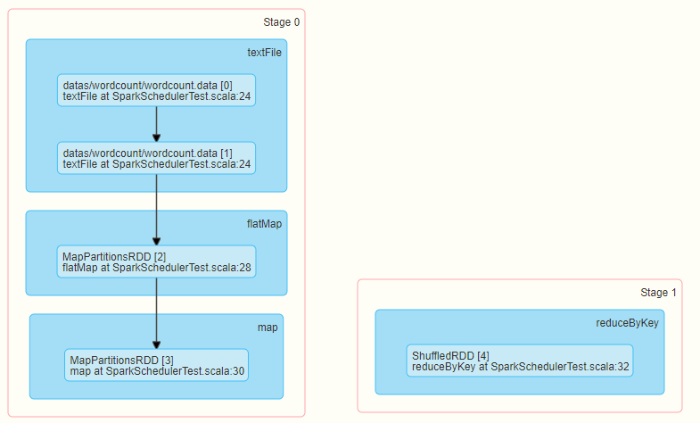
Take the WordCount program of word frequency statistics as an example. The Job execution is DAG diagram:
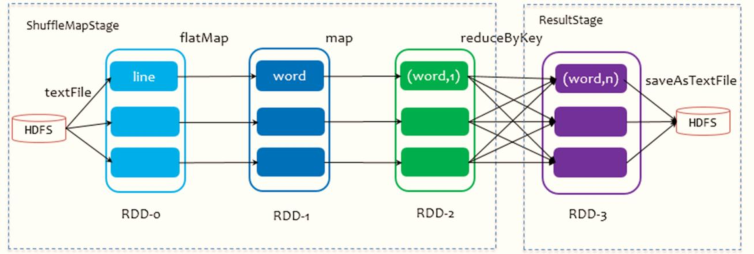
Run WordCount for word frequency statistics and intercept the DAG diagram on 4040 monitoring page:
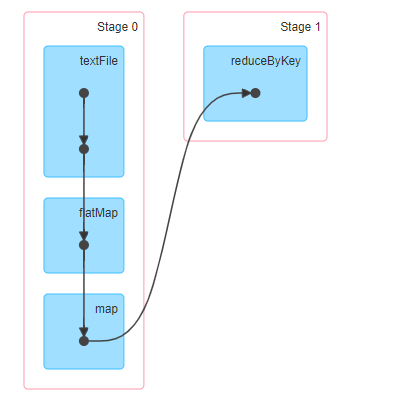
When RDD calls the Action function (Job trigger function), one Job is generated and executed.
-
1. Build a graph of all RDD S in the Job according to dependencies: DAG graph (directed acyclic graph)
-
2. DAG diagram is divided into Stage stage and two types
- ResultStage: process the result RDD
- ShuffleMapStage: the last RDD in this Stage generates a Shuffle
-
3. Each Stage has at least one RDD or multiple RDDS, each RDD has multiple partitions, and the data of each partition is processed by one Task
There are multiple tasks processing data in each Stage, and each Task processes one partition data
04 - [Master] - RDD dependency of Spark kernel scheduling
There is a lineage inheritance relationship between RDDS, which is essentially a Dependency relationship between RDDS.
For each RDD record, how to get it from the parent RDD and which conversion function to call
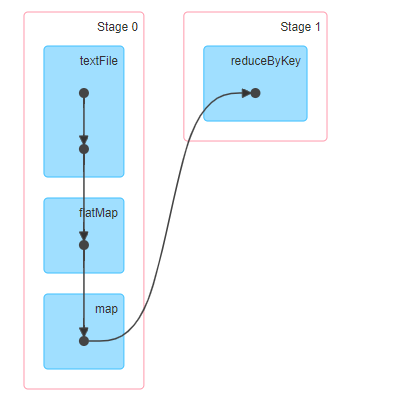
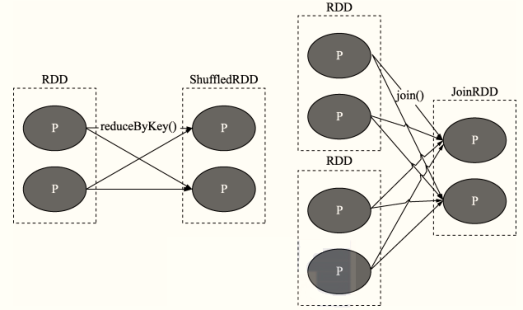
From the DAG diagram, there are two types of dependencies between RDD S:
- Narrow dependence, The dependency between two RDD S is represented by a directed arrow
- Wide dependency, also known as Shuffle dependency, The dependence between two RDD S is represented by the directional arrow of the S curve

- Narrow Dependency
Definition: the partition between parent RDD and child RDD is one-to-one, One (parent RDD) to one (child RDD)
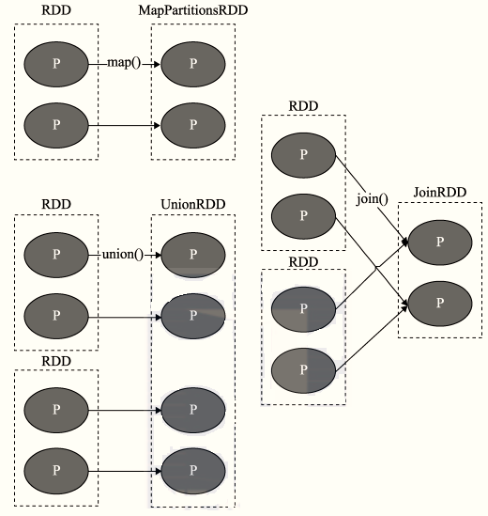
- Shuffle dependency (Wide Dependency)
Definition: partitions in the parent RDD may be used by multiple child RDD partitions, One (parent) to many (child)

05 - [Master] - DAG and Stage of Spark kernel scheduling
During the execution of Spark application, when each Job is executed (when RDD calls Action function), push forward according to the last RDD (call Action function RDD) and RDD dependency, and build all RDD dependency diagrams in the Job, which is called DAG diagram.
After the Job DAG diagram is built, continue to start from the last RDD of the Job, divide the DAG diagram into stages according to the dependencies between RDDS, and divide a Stage when the dependencies between RDDS are Shuffle dependencies.
- For narrow dependencies, there is no need to Shuffle the data between RDD S, and multiple data processing can be completed in the memory of the same machine
Therefore, narrow dependencies are divided into the same Stage in Spark; - For wide dependency, due to the existence of Shuffle, the next calculation can not be started until the Shuffle processing of the parent RDD is completed
So the Stage will be segmented here.
You can run WordCount to view the corresponding DAG diagram and Stage stage
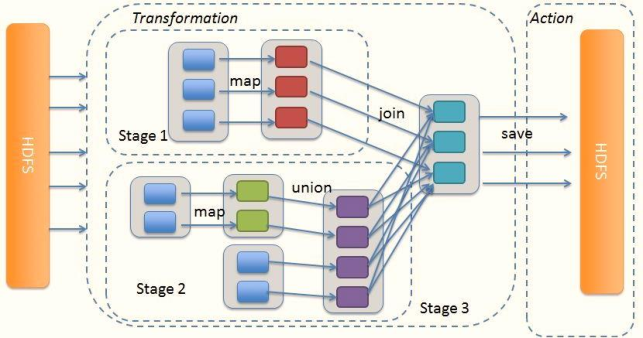
DAG is divided into multiple interdependent stages based on the wide dependence between RDD S. Stage is composed of a group of parallel tasks.
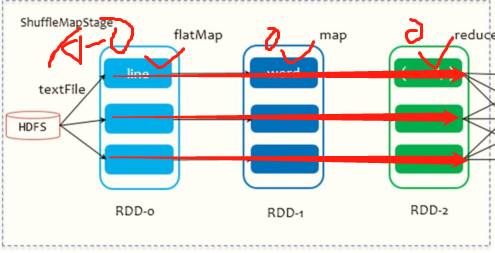
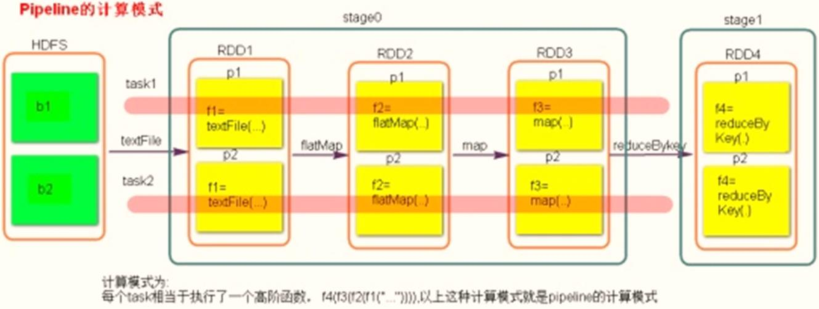
1,Stage Cutting rule: from back to front, cut in case of wide dependence Stage.
2,Stage Calculation mode: pipeline Pipeline calculation mode
pipeline It's just a calculation idea and mode. One piece of data and then calculate one piece of data. Finish all logic and then land.
Statistics by word frequency WordCount For example:
from HDFS Read data on each Block Corresponding to 1 partition, when from Block After reading a piece of data in flatMap,map and reduceByKey Operation, and finally write the result data to the local disk( Shuffle Write).
block0: hadoop spark spark
|textFile
RDD-0 hadoop spark spark
|flatMap
RDD-1 hadoop\spark\spark
|map
RDD-2 (hadoop, 1)\(spark, 1)\(spark, 1)
|reduceByKey
Write to disk hadoop, 1 || spark, 1\ spark, 1
3,To be exact: one task Complete the calculation of the whole data partition
The interview questions are as follows: a piece of code in Spark Core to judge the execution result
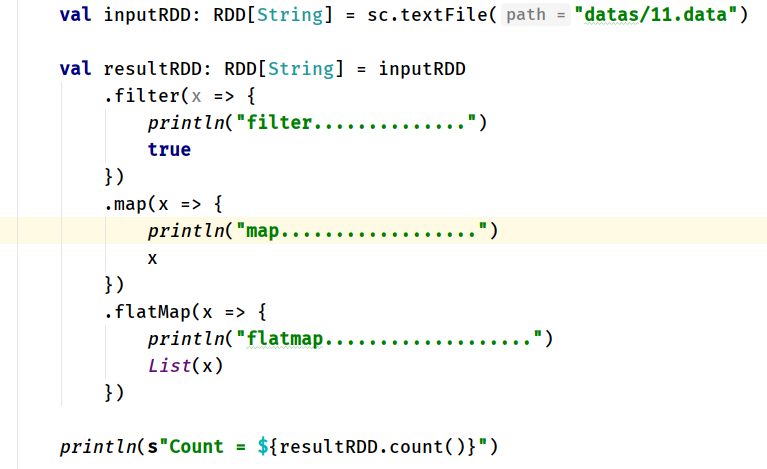
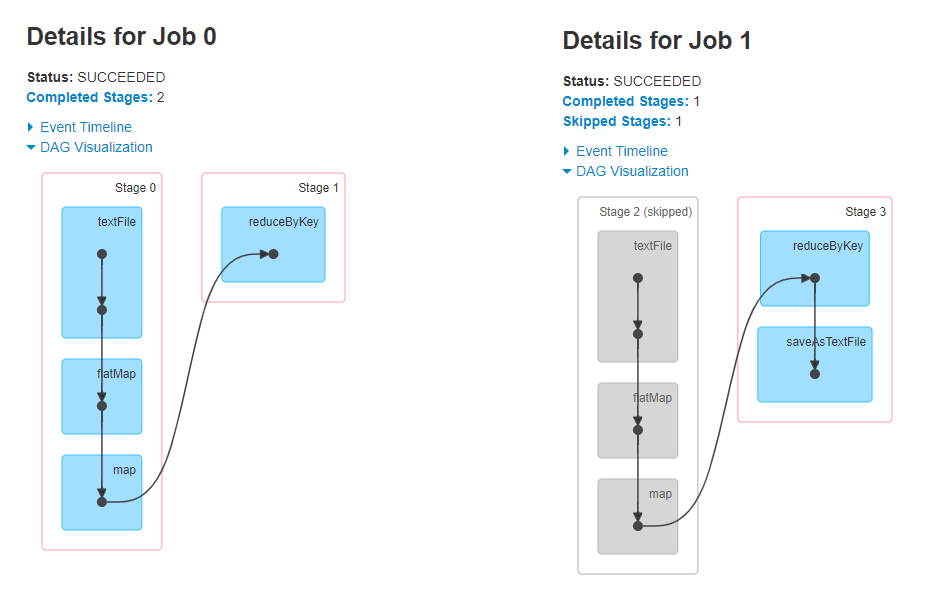
Prerequisites: 11.data Three data in result A: filter.................. filter.................. filter.................. map.................. map.................. map.................. flatMap.................. flatMap.................. flatMap.................. Count = 3 result B: filter.................. map.................. flatMap.................. filter.................. map.................. flatMap.................. filter.................. map.................. flatMap.................. Count = 3
In a Spark Application, if an RDD calls the Action function many times to trigger Job execution, reuse the Shuffle data in the process of RDD result generation (write to the local disk), save the time of recalculating RDD and improve performance.
You can cache a data that has been used for many times as RDD data manually.
06 - [understand] - Spark Shuffle for Spark kernel scheduling
First, review the Shuffle process in MapReduce framework. The overall flow chart is as follows:
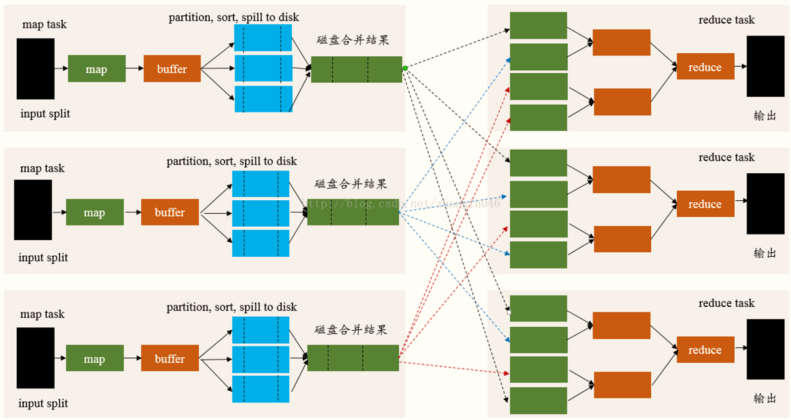
Spark will divide a Job into multiple stages in DAG scheduling Stage. The upstream Stage will do map work and the downstream Stage will do reduce work. In essence, it is still a MapReduce computing framework.
Shuffle is a bridge between map and reduce. It corresponds the output of map to the input of reduce, involving serialization and deserialization, cross node network IO, disk read-write IO, etc.
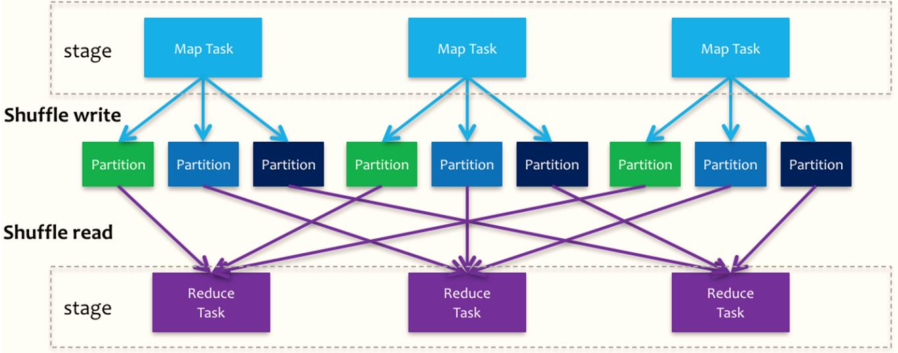
Spark's Shuffle is divided into two stages: Write and Read, which belong to two different stages. The former is the last step of Parent Stage and the latter is the first step of Child Stage.
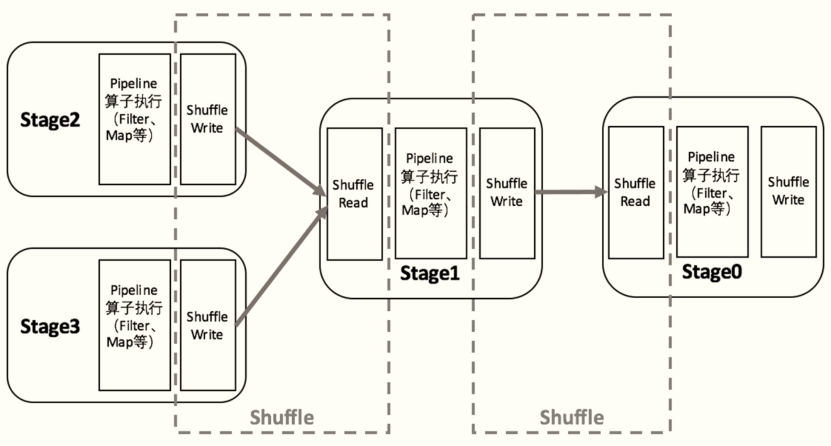
Stage is divided into two types:
- 1) ShuffleMapStage: in one spark Job, all other stages are of this type except the last Stage
- Write Shuffle data to local disk, ShuffleWriter
- In this Stage, all tasks are called ShuffleMapTask
- 2) ResultStage, the last Stage in one Job of Spark, operates the result RDD
- It will read the data in the previous Stage, ShuffleReader
- In this Stage, all Task tasks are called resulttasks.
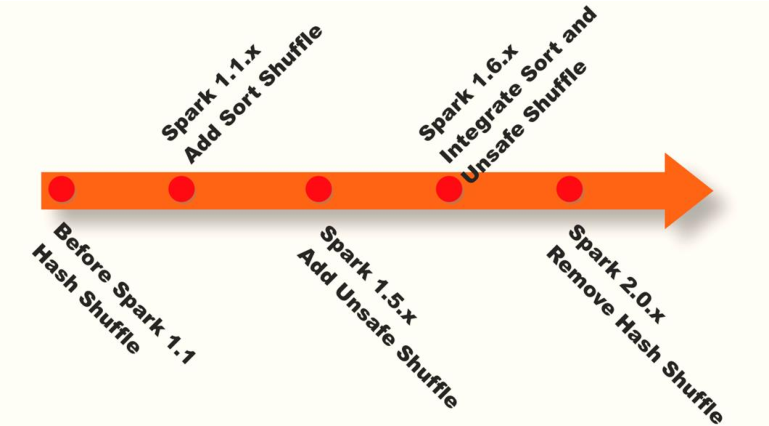
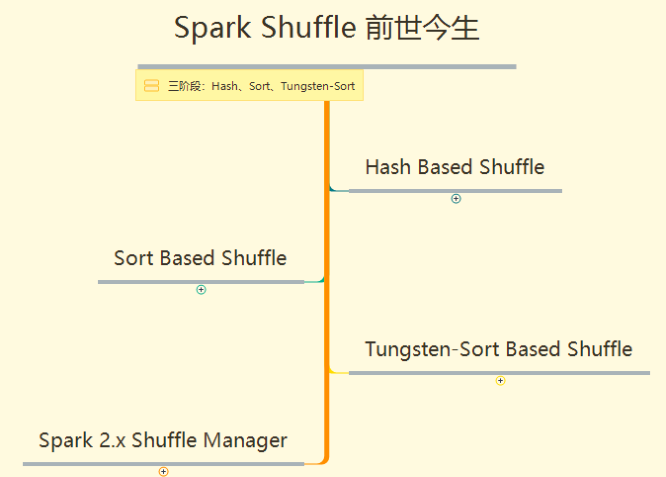
Spark Shuffle Implementation history: - Spark In 1.1 Previous versions have been adopted Hash Shuffle Implementation of - To 1.1 Version reference HadoopMapReduce The implementation of began to be introduced Sort Shuffle - In 1.5 Start at version Tungsten Tungsten wire plan, introduction UnSafe Shuffle Optimize memory and CPU Use of - In 1.6 Lieutenant general Tungsten Unified to Sort Shuffle To achieve self perception and choose the best Shuffle mode - To 2.0 edition, Hash Shuffle Deleted, all Shuffle All methods are unified to Sort Shuffle An implementation is in progress.
For the specific implementation of Shuffle in each stage, refer to the mind map XMIND. The outline is as follows:
07 - [Master] - Job scheduling process of Spark kernel scheduling
When starting the Spark Application, run the MAIN function and first create the SparkContext object (build DAGScheduler and TaskScheduler).
- First, DAGScheduler instance object
- The DAG diagram of each Job is divided into stages, and the dependency between RDD S is wide dependency (generating Shuffle)
- Second, TaskScheduler instance object
- Schedule all tasks in each Stage: TaskSet, and send it to the Executor for execution
- There will be multiple tasks in each Stage. The processing data of all tasks are different (each partition data is processed by one Task), but the processing logic is the same.
- Putting all the tasks in each Stage together is called TaskSet.
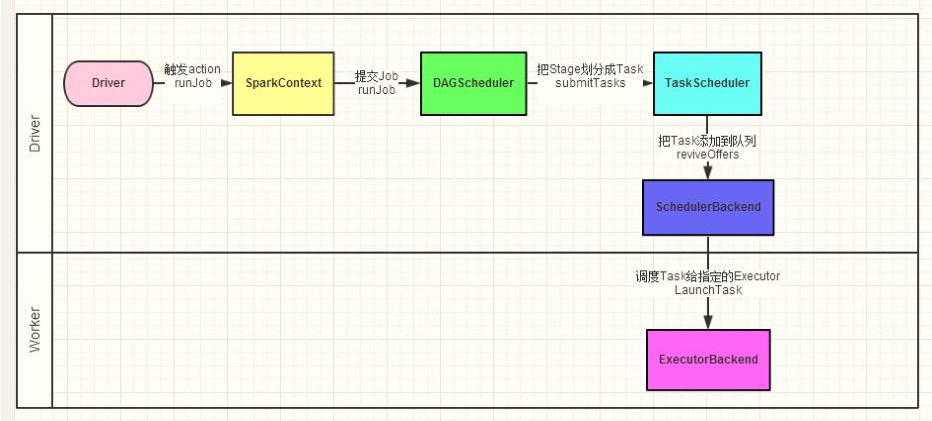
When RDD calls the Action function (such as count, saveTextFile or foreachPartition), a Job execution is triggered. The process in scheduling is shown in the following figure:
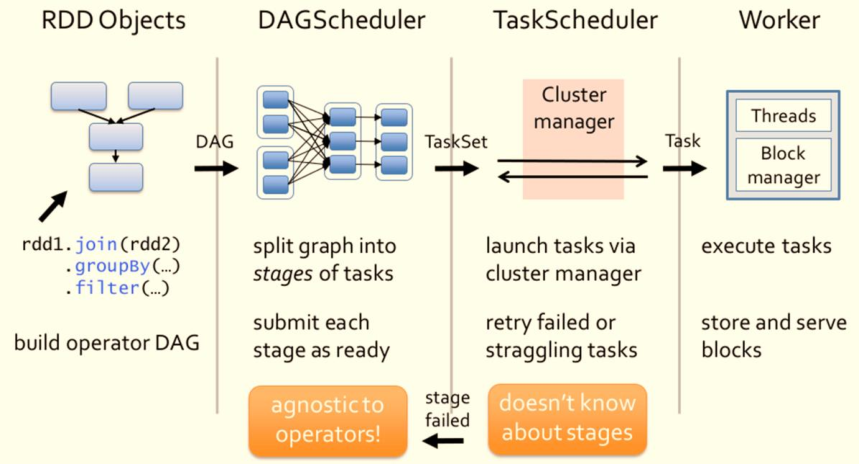
Spark RDD forms RDD blood relationship diagram (DAG) through its Transactions operation. Finally, the Job is triggered and scheduled for execution through the call of Action.
- 1) The DAGScheduler is responsible for scheduling at the Stage level, which is mainly to divide the DAG into several Stages, package each Stage into a TaskSet and send it to the TaskScheduler for scheduling.
- 2) TaskScheduler is responsible for Task level scheduling, and distributes the TaskSet sent by DAGScheduler to the Executor for execution according to the specified scheduling policy. In the scheduling process, SchedulerBackend is responsible for providing available resources. SchedulerBackend has multiple implementations, which are connected to different resource management systems.
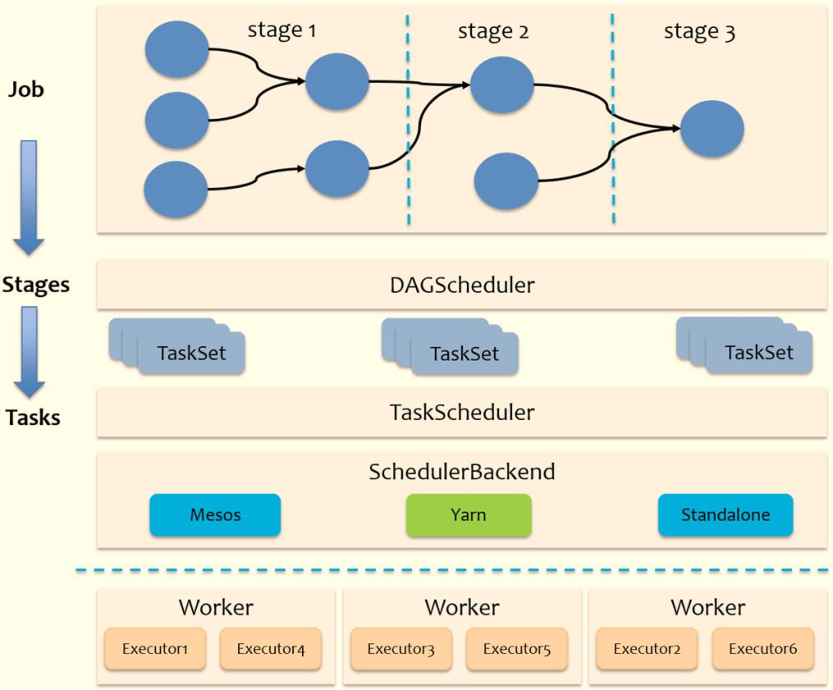
Generally speaking, Spark's Task scheduling is divided into two ways: one is Stage level scheduling and the other is Task level scheduling.
One Spark Applications include Job,Stage and Task:
First Job So Action Method is bounded, encountered a Action Method triggers a Job;
Second Stage yes Job Subset of to RDD Wide dependence(Namely Shuffle)As a boundary, encounter Shuffle Make a division;
Third Task yes Stage Subset to parallelism(Number of partitions)To measure how many partitions there are task.
08 - [Master] - basic concepts of Spark kernel scheduling
Spark Application runtime covers many concepts, mainly as follows:

Official documents: http://spark.apache.org/docs/2.4.5/cluster-overview.html#glossary
09 - [understanding] - parallelism of Spark kernel scheduling
When Spark Application is running, parallelism can be understood from two aspects:
- 1) . parallelism of resources: determined by the number of nodes (executors) and the number of CPUs (cores)
- 2) . data parallelism: task data, partition size
The number of tasks should be 2-3 times the total number of core s
parameter spark.defalut.parallelism There is no value by default. If a value is set, it is in the shuffle The process will work

In an actual project, when running a Spark Application, you need to set resources, especially the number of executors and CPU cores. How to calculate?
- First, determine the total number of CPU Core cores, According to the data volume (original data size) and considering the data volume in business analysis
- Then determine the number of executors, Assuming the number of cores per Executor, get the number
- Finally, determine the memory size of the Executor, In general, the memory of each Executor is often 2-3 times the number of CPU cores
Analyze website log data: 20 GB,store in HDFS Up, 160 Block,from HDFS Read data, RDD Number of partitions: 160 1,RDD If the number of partitions is 160, then Task The number is 160 2,total CPU Core Kernel number 160/2 = 80 CPU Core = 60 160/3 = 50 3,Suppose each Executor: 6 Core 60 / 6 = 10 individual 4,each Executor Memory 6 * 2 = 12 GB 6 * 3 = 18 GB 5,Parameter setting --executor-memory= 12GB --executor-cores= 6 --num-executors=10
10 - [Master] - SparkSQL application portal SparkSession
Starting from Spark 2.0, the application entry is SparkSession, which loads data from different data sources and encapsulates it into the DataFrame/Dataset set data structure, making programming simpler and the program run faster and more efficient.

1,SparkSession Program entry, loading data bottom SparkContext,Encapsulate 2,DataFrame/Dataset Dataset[Row] = DataFrame Data structure, from Spark 1.3 It began to appear until 2.0 Version, confirm bottom RDD,add Schema Constraints (metadata): field names and field types
- 1) SparkSession in the SparkSQL module, add MAVEN dependency
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.4.5</version>
</dependency>
- 2) . the SparkSession object instance is built through the builder mode. The code is as follows:

Where ① refers to the package where the SparkSession is imported, ② refers to the builder mode to build objects and set properties, and ③ refers to the implicit conversion function in the implicit object object in the SparkSession class.
- 3) Example demonstration: build a SparkSession instance, load text data, and count the number of entries.
package cn.itcast.spark.sql.start
import org.apache.spark.sql.{Dataset, SparkSession}
/**
* Spark 2.x At the beginning, the SparkSession class is provided as the entry of Spark Application program,
* It is used to read data and schedule jobs. The bottom layer is still SparkContext
*/
object _03SparkStartPoint {
def main(args: Array[String]): Unit = {
// Use the builder design pattern to create a SparkSession instance object
val spark: SparkSession = SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[2]")
.getOrCreate()
import spark.implicits._
// TODO: loading data using SparkSession
val inputDS: Dataset[String] = spark.read.textFile("datas/wordcount.data")
// Display the first 5 data
println(s"Count = ${inputDS.count()}")
inputDS.show(5, truncate = false)
// After application, close the resource
spark.stop()
}
}
Learning task: Design Pattern [Builder Design Pattern] in Java. In many big data frameworks, API design is the builder design pattern.
11 - [Master] - DSL based programming of word frequency statistics WordCount
DataFrame data structure is equivalent to adding constraint Schema to RDD. It knows the internal structure of data (field name and field type), and provides two ways to analyze and process data: DataFrame API (DSL programming) and SQL (similar to HiveQL programming). Next, take WordCount program as an example to experience the use of DataFrame.
use SparkSession Load text data and encapsulate it into Dataset/DataFrame Call in API Function processing analysis data (similar) RDD in API Functions, such as flatMap,map,filter Etc.), programming steps: Step 1: build SparkSession Instance object, setting the application name and running local mode; Step 2: read HDFS Text file data on; Step 3: use DSL(Dataset API),similar RDD API Process and analyze data; Step 4: print result data and close the console SparkSession;
package cn.itcast.spark.sql.wordcount
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}
/**
* Word frequency statistics using SparkSQL WordCount: DSL
*/
object _04SparkDSLWordCount {
def main(args: Array[String]): Unit = {
// Create a SparkSession instance object using the build design pattern
val spark: SparkSession = SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[2]")
.getOrCreate()
import spark.implicits._
// TODO: loading data using SparkSession
val inputDS: Dataset[String] = spark.read.textFile("datas/wordcount.data")
// DataFrame/Dataset = RDD + schema
/*
root
|-- value: string (nullable = true)
*/
//inputDS.printSchema()
/*
+----------------------------------------+
|value |
+----------------------------------------+
|hadoop spark hadoop spark spark |
|mapreduce spark spark hive |
|hive spark hadoop mapreduce spark |
|spark hive sql sql spark hive hive spark|
|hdfs hdfs mapreduce mapreduce spark hive|
+----------------------------------------+
*/
//inputDS.show(10, truncate = false)
// TODO: use DSL (Dataset API), similar to RDD API to process and analyze data
val wordDS: Dataset[String] = inputDS.flatMap(line => line.trim.split("\\s+"))
/*
root
|-- value: string (nullable = true)
*/
//wordDS.printSchema()
/*
+---------+
|value |
+---------+
|hadoop |
|spark |
+---------+
*/
// wordDS.show(10, truncate = false)
/*
table: words , column: value
SQL: SELECT value, COUNT(1) AS count FROM words GROUP BY value
*/
val resultDS: DataFrame = wordDS.groupBy("value").count()
/*
root
|-- value: string (nullable = true)
|-- count: long (nullable = false)
*/
resultDS.printSchema()
/*
+---------+-----+
|value |count|
+---------+-----+
|sql |2 |
|spark |11 |
|mapreduce|4 |
|hdfs |2 |
|hadoop |3 |
|hive |6 |
+---------+-----+
*/
resultDS.show(10, truncate = false)
// After application, close the resource
spark.stop()
}
}
12 - [Master] - SQL based programming of word frequency statistics WordCount
It is similar to HiveQL method for word frequency statistics. Directly group words by and count them. The steps are as follows:
Step 1: build SparkSession Object, load file data, and divide each line of data into words; The second step is to DataFrame/Dataset Register as temporary view( Spark 1.x Temporary table in); Step 3: preparation SQL Statements, using SparkSession Execute and obtain results; Step 4: print result data and close the console SparkSession;
package cn.itcast.spark.sql.wordcount
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}
/**
* Word frequency statistics using SparkSQL WordCount: SQL
*/
object _05SparkSQLWordCount {
def main(args: Array[String]): Unit = {
// Create a SparkSession instance object using the build design pattern
val spark: SparkSession = SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[2]")
.getOrCreate()
import spark.implicits._
// TODO: loading data using SparkSession
val inputDS: Dataset[String] = spark.read.textFile("datas/wordcount.data")
/*
root
|-- value: string (nullable = true)
*/
//inputDS.printSchema()
/*
+--------------------+
| value|
+--------------------+
|hadoop spark hado...|
|mapreduce spark ...|
|hive spark hadoop...|
+--------------------+
*/
//inputDS.show(5, truncate = false)
// Divide each row of data into words according to segmentation
val wordDS: Dataset[String] = inputDS.flatMap(line => line.trim.split("\\s+"))
/*
table: words , column: value
SQL: SELECT value, COUNT(1) AS count FROM words GROUP BY value
*/
// step 1. Register Dataset or DataFrame as a temporary view
wordDS.createOrReplaceTempView("tmp_view_word")
// step 2. Write and execute SQL
val resultDF: DataFrame = spark.sql(
"""
|SELECT value as word, COUNT(1) AS count FROM tmp_view_word GROUP BY value
|""".stripMargin)
/*
+---------+-----+
|word |count|
+---------+-----+
|sql |2 |
|spark |11 |
|mapreduce|4 |
|hdfs |2 |
|hadoop |3 |
|hive |6 |
+---------+-----+
*/
resultDF.show(10, truncate = false)
// After application, close the resource
spark.stop()
}
}