1, Spark deployment cluster installation
Spark clusters can be deployed in many ways, including Standalone mode and ON YARN mode
1. Standalone mode
The Standalone mode is to deploy a set of independent Spark clusters, and the Spark tasks developed in the later stage are executed in this independent Spark cluster
2. ON YARN mode
ON YARN mode means that using the existing Hadoop cluster, the Spark tasks developed later will be executed in the Hadoop cluster. At this time, the Hadoop cluster is a public one, which can run not only MapReduce tasks, but also Spark tasks, so that the resources of the cluster can be shared, and there is no need to maintain a set of clusters, Reduce the operation and maintenance cost and pressure, and kill two birds with one stone.
Therefore, spark on Yen mode will be used in practical work
However, in order to consider that you may have some special scenarios, you really need to use the standalone mode to deploy an independent spark cluster, so here, we will talk about these two deployment modes.
3. Download installation package
Before the specific installation and deployment, you need to download the Spark installation package.
If you don't want to go to the official website to download, spark-2.4.3-bin-hadoop 2 7.tgz
The link of Baidu online disk version is as follows:
Link: https://pan.baidu.com/s/1T0lkgadUAnO3fjqREUprbw?pwd=b1w7 Extraction code: b1w7
Go to spark's official website and click the download button.
Here you can choose the Spark version and Hadoop version.
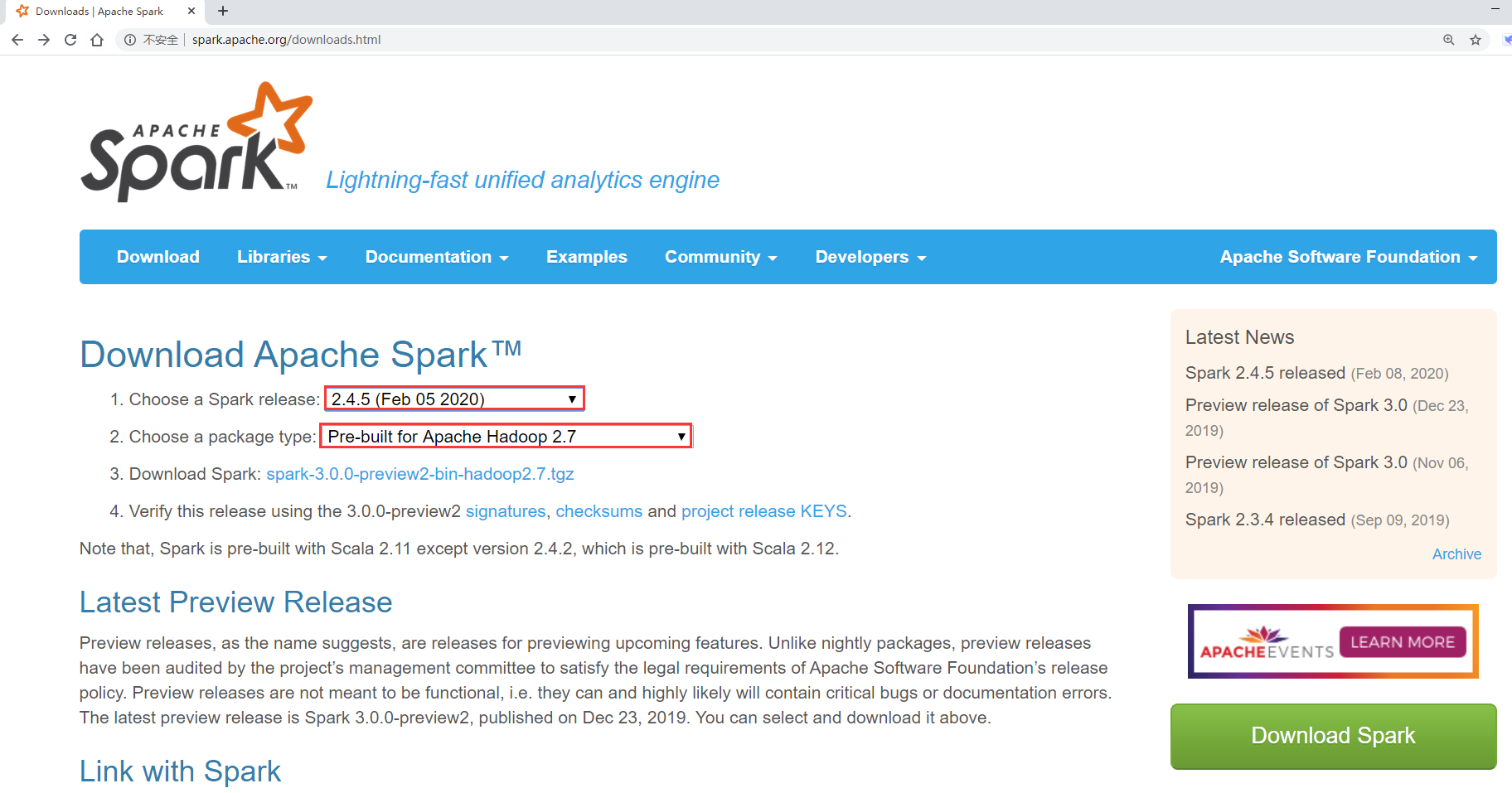
However, there is only the latest version of Spark. Generally, it is not recommended to choose the latest version. You can go back to one or two small versions below the latest version.
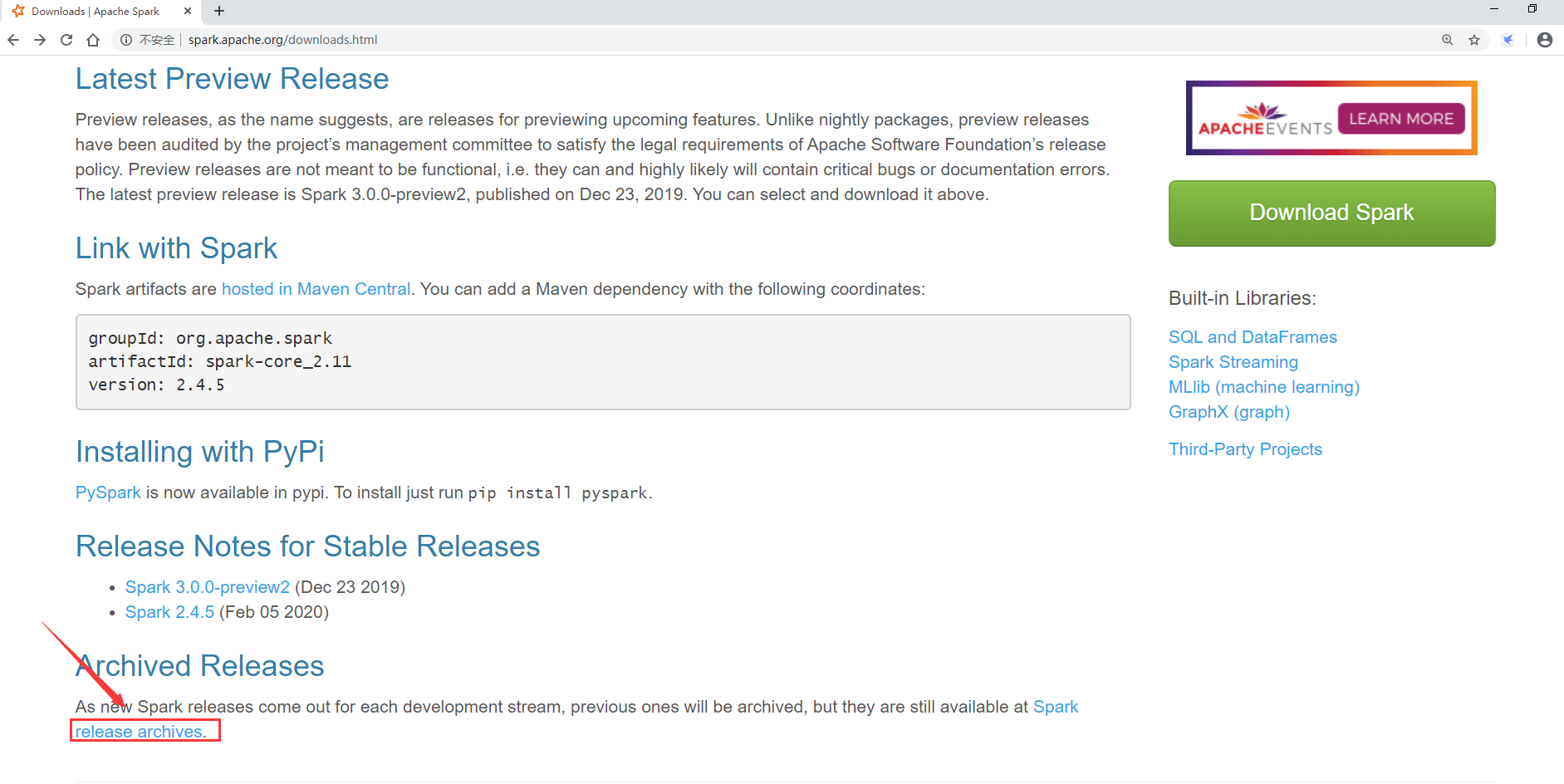
If we want to download other versions, we need to download them in the archive.
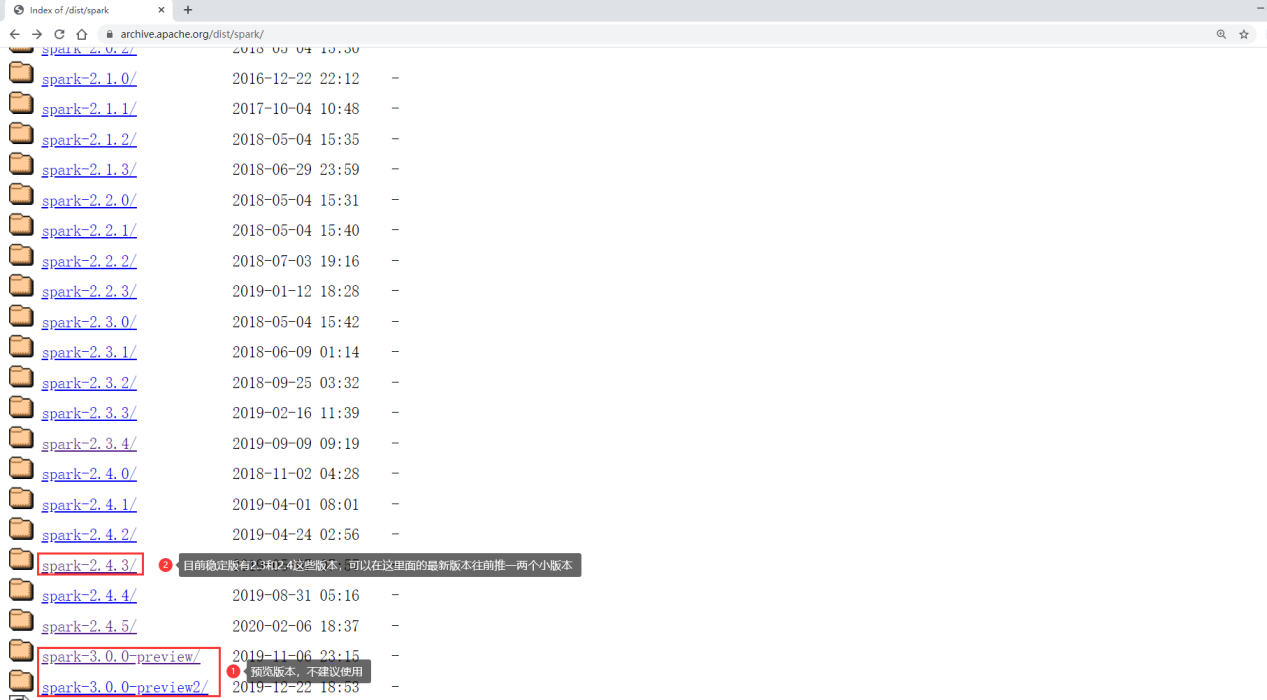
At present, spark has three major versions, 1 x,2.x and 3 x. Of which 3 X is a preview version and cannot be used in the production environment, so 2.0 is the most used version at present The version of X.
Here we download spark-2.4.3.
You need to pay attention to selecting the appropriate installation package
Because we generally need to interact with Hadoop when using Spark, we need to download the installation package with Hadoop dependency.
At this time, you need to select the Spark installation package corresponding to the Hadoop version. Our Hadoop is 3.2, and there are only 2.6 and 2.7 Hadoop versions, so choose Hadoop 2 7. In fact, there is no problem with the Spark installation package. If you have OCD, you need to download the Spark source package and compile the supporting version of the installation package yourself.
In fact, in spark3 The preview version of 0 has and Hadoop 3 It's not recommended to use the supporting version in the production environment, but it's not stable.
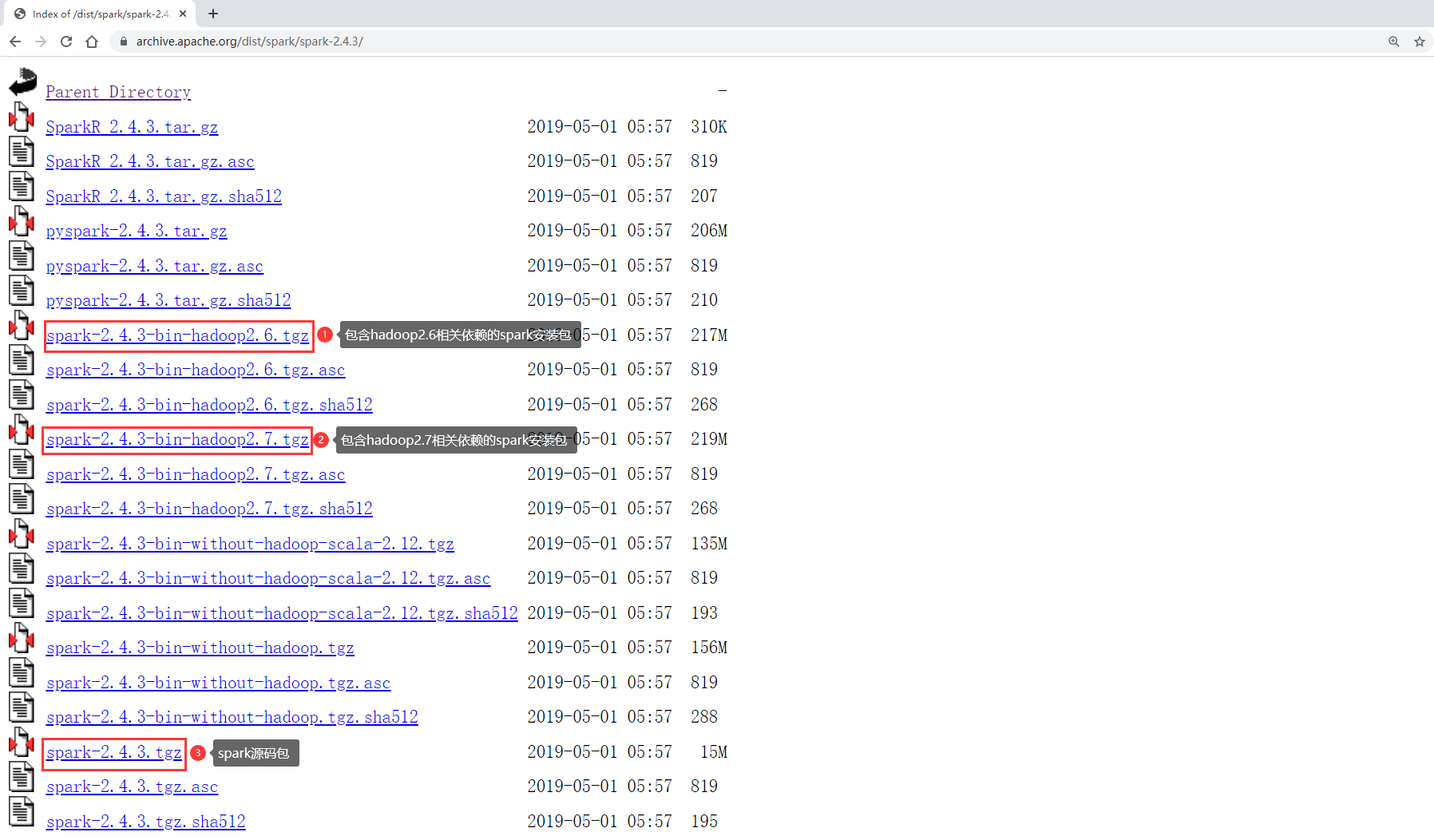
So we finally downloaded this version:
spark-2.4.3-bin-hadoop2.7.tgz
2, Standalone mode installation and deployment
Since Spark cluster also supports master-slave, we use three machines to deploy a set of one master and two slave clusters
Master node: bigdata01
Slave nodes: bigdata02,bigdata03
Note: it is necessary to ensure that the basic environment on these machines is OK Yes, firewall, password free login, and JDK Because we have used these machines before and the basic environment has been configured, we can use them directly here
1. Configure on bigdata01 first
(1) Upload installation package
Add spark-2.4.3-bin-hadoop 2 7. Upload tgz to the / data/soft directory of bigdata01
(2) Decompress
decompression
[root@bigdata01 soft]# tar -zxvf spark-2.4.3-bin-hadoop2.7.tgz
(3) Rename spark env sh.template
[root@bigdata01 soft]# cd spark-2.4.3-bin-hadoop2.7/conf/ [root@bigdata01 conf]# mv spark-env.sh.template spark-env.sh
(4) Modify spark env sh
Add these two lines at the end of the file to specify JAVA_HOME and host name of the primary node
export JAVA_HOME=/data/soft/jdk1.8 export SPARK_MASTER_HOST=bigdata01
(5) Rename slave template
[root@bigdata01 conf]# mv slaves.template slaves
(6) Modify slave
Remove the localhost at the end of the file and add the host names of the two slave nodes bigdata02 and bigdata03
bigdata02 bigdata03
(7) Copy the modified spark installation package to bigdata02 and bigdata03
[root@bigdata01 soft]# scp -rq spark-2.4.3-bin-hadoop2.7 bigdata02:/data/soft/ [root@bigdata01 soft]# scp -rq spark-2.4.3-bin-hadoop2.7 bigdata03:/data/soft/
(8) Start Spark cluster
[root@bigdata01 soft]# cd spark-2.4.3-bin-hadoop2.7 [root@bigdata01 spark-2.4.3-bin-hadoop2.7]# sbin/start-all.sh starting org.apache.spark.deploy.master.Master, logging to /data/soft/spark-2.4.3-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.master.Master-1-bigdata01.out bigdata02: starting org.apache.spark.deploy.worker.Worker, logging to /data/soft/spark-2.4.3-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-bigdata02.out bigdata03: starting org.apache.spark.deploy.worker.Worker, logging to /data/soft/spark-2.4.3-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-bigdata03.out
(9) Verify
Execute jps on bigdata01 and you can see the Master process
[root@bigdata01 spark-2.4.3-bin-hadoop2.7]# jps 1731 Master
Execute jps on bigdata02 and bigdata03, and you can see the Worker process
[root@bigdata02 ~]# jps 1714 Worker [root@bigdata03 ~]# jps 1707 Worker
You can also access port 8080 of the master node to view the cluster information
http://bigdata01:8080/
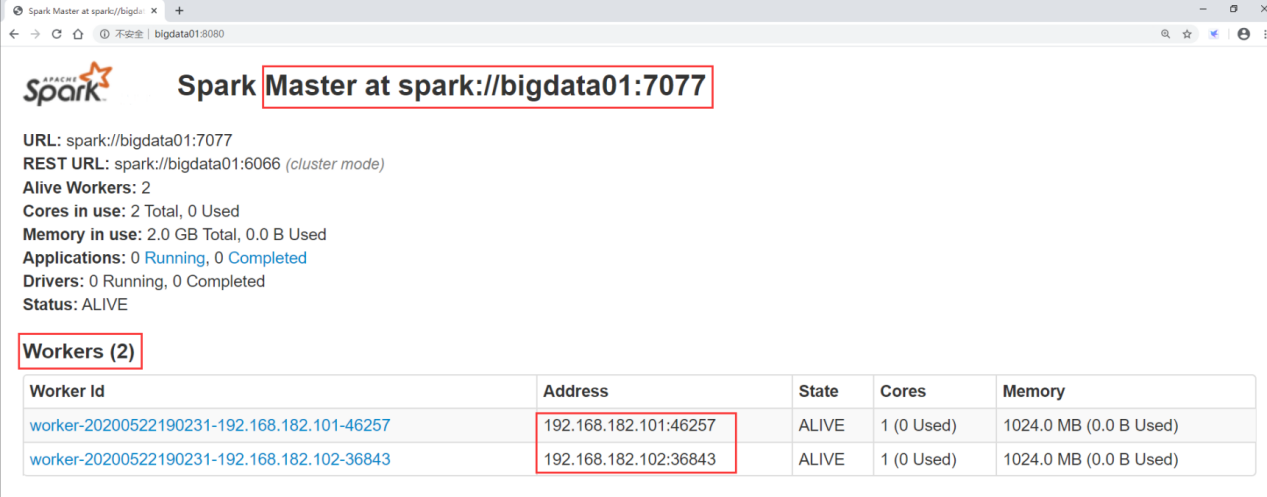
This is the independent cluster of Spark
(10) Submit task
Let's try to submit a spark task to the spark independent cluster
How to write the command to submit a task?
Take a look at the official documents of Spark
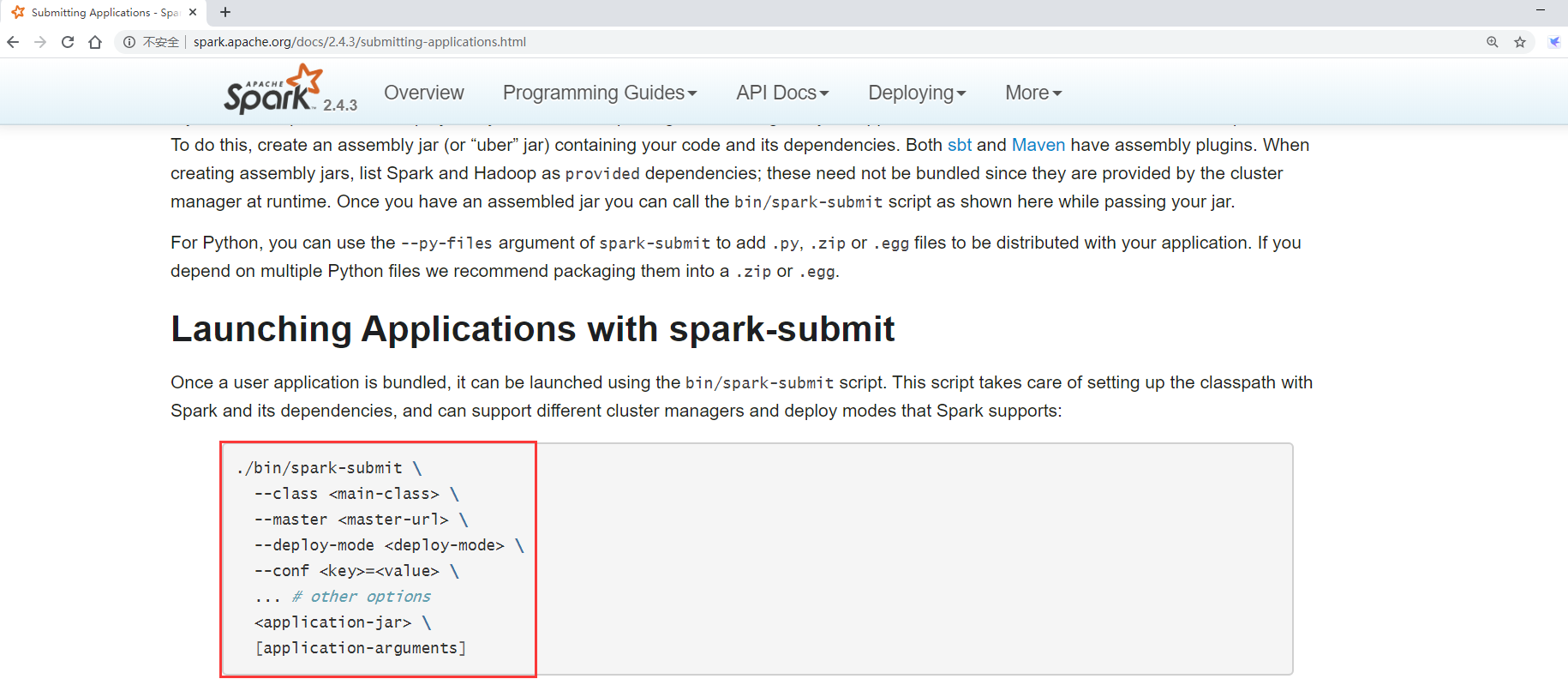
You need to submit the task using the spark submit script under the bin directory
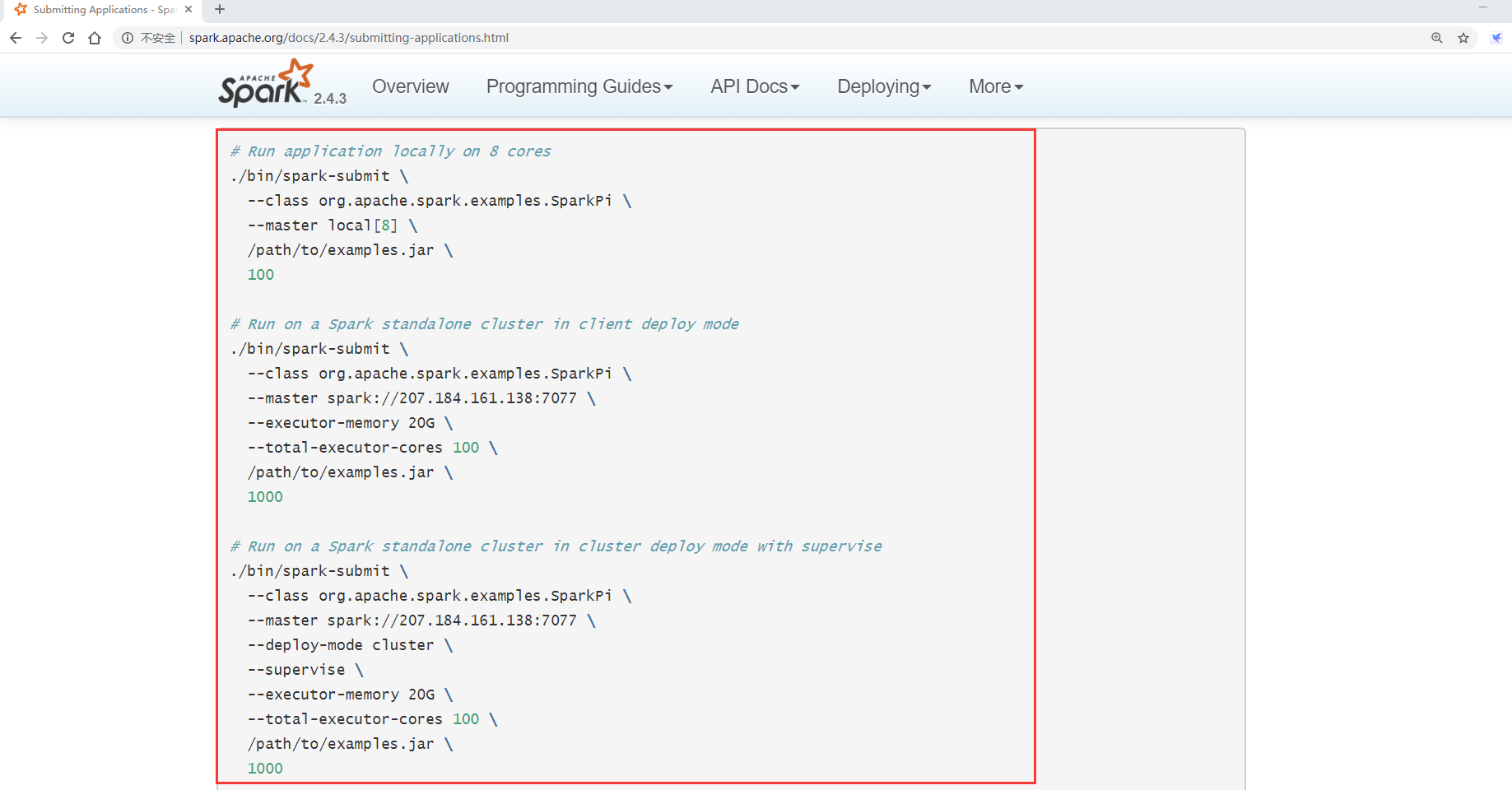
--class Specify the entry class that needs to be specified to represent the calculationπvalue --master Specify the address of the cluster
Then specify the task jar package to be submitted. The last parameter is to calculate the π value, which is required by the task itself
[root@bigdata01 spark-2.4.3-bin-hadoop2.7]# bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://bigdata01:7077 examples/jars/spark-examples_2.11-2.4.3.jar 2
After submitting, you can view the task information in Spark's 8080 web interface
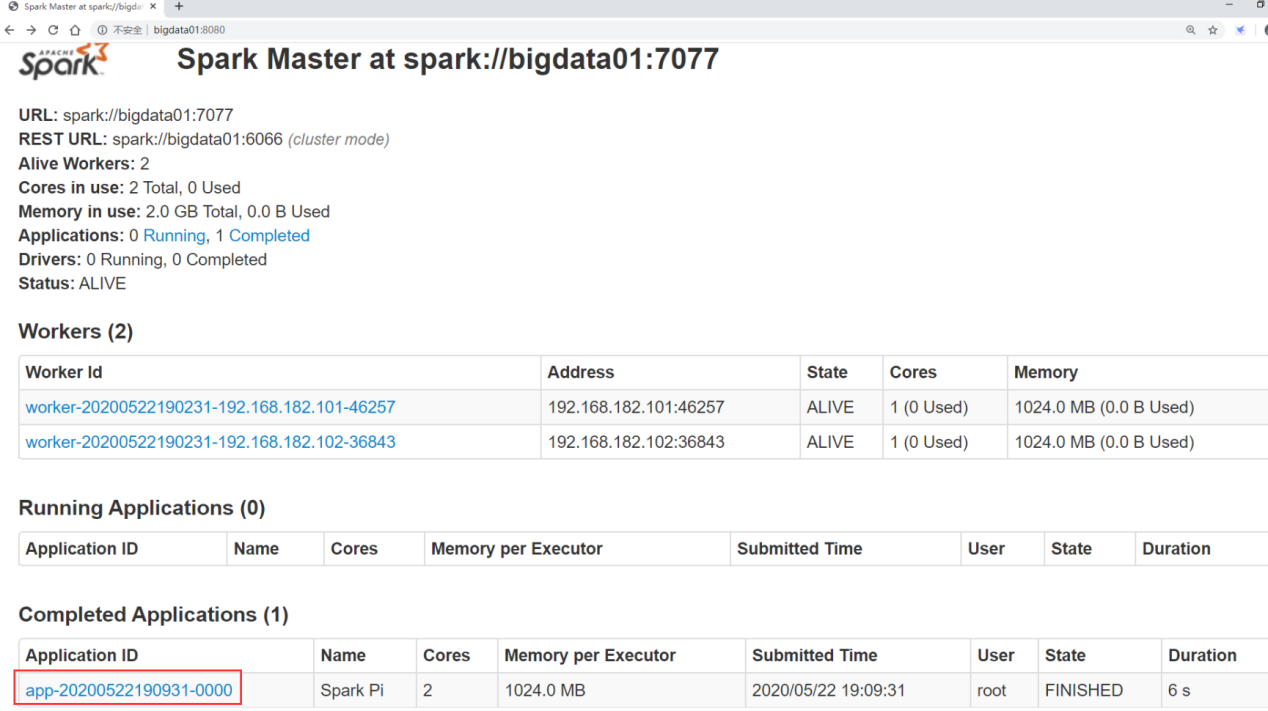
(11) Stop Spark cluster
Execute on the master node bigdata01
[root@bigdata01 spark-2.4.3-bin-hadoop2.7]# sbin/stop-all.sh bigdata03: stopping org.apache.spark.deploy.worker.Worker bigdata02: stopping org.apache.spark.deploy.worker.Worker stopping org.apache.spark.deploy.master.Master
3, ON YARN mode
The ON YARN mode is simple,
First ensure that there is a Hadoop cluster, and then just deploy a Spark client node without starting any process,
be careful: Spark The client node also needs to be Hadoop Client node because Spark Need to rely on Hadoop
Our Hadoop clusters are bigdata01, bigdata02 and bigdata03
Then we can choose to deploy Spark on a separate node. In fact, it is similar to the client node we deployed Hadoop before.
Here, we use bigdata04 to deploy spark on yarn, because this node is also the client node of Hadoop.
1. Upload installation package
Add spark-2.4.3-bin-hadoop 2 7. Upload tgz to the / data/soft directory of bigdata04
2. Decompress
[root@bigdata04 soft]# tar -zxvf spark-2.4.3-bin-hadoop2.7.tgz
3. Rename spark env sh.template
[root@bigdata04 soft]# cd spark-2.4.3-bin-hadoop2.7/conf/ [root@bigdata04 conf]# mv spark-env.sh.template spark-env.sh
4. Modify spark env sh
Add these two lines at the end of the file to specify Java_ Configuration file directories for home and Hadoop
export JAVA_HOME=/data/soft/jdk1.8 export HADOOP_CONF_DIR=/data/soft/hadoop-3.2.0/etc/hadoop
5. Submit task
Then we submit the spark task to the Hadoop cluster through the spark client node
[root@bigdata04 spark-2.4.3-bin-hadoop2.7]# bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster examples/jars/spark-examples_2.11-2.4.3.jar 2
6. You can view the submitted task information in the 8088 interface of YARN
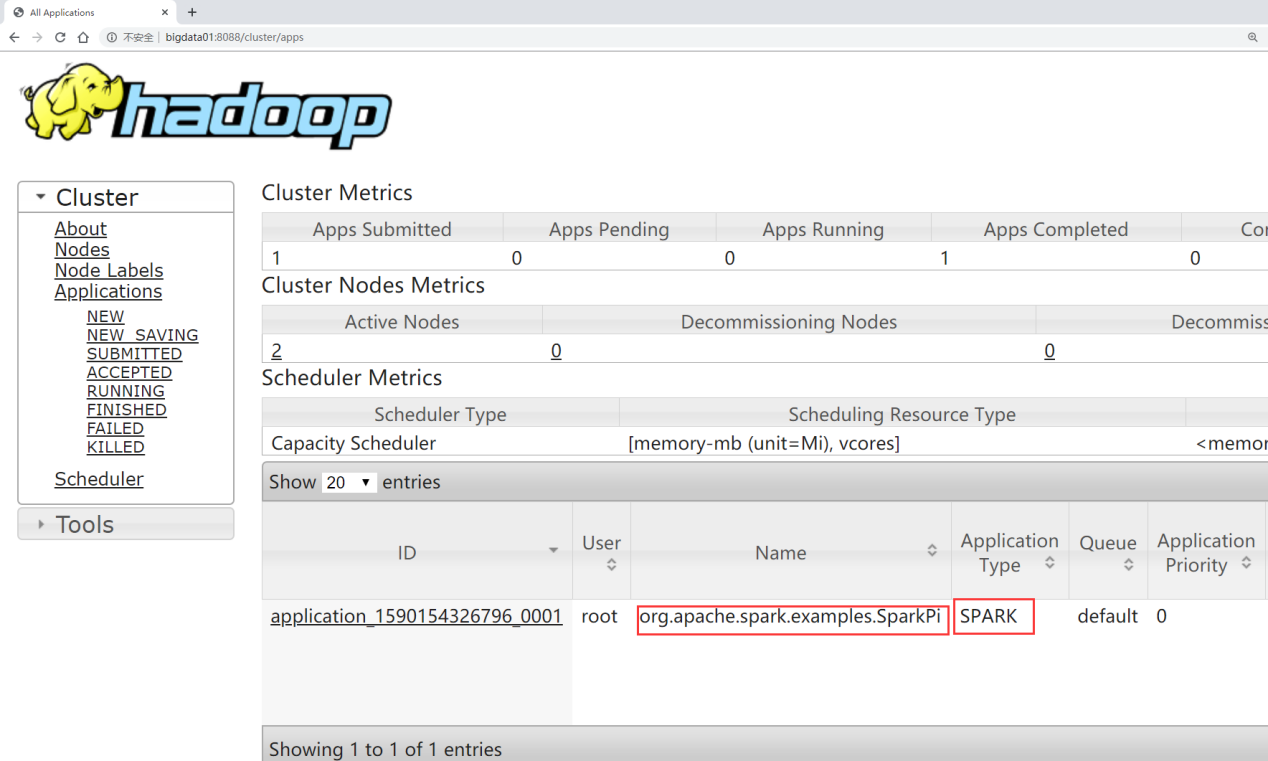
At this point, you can use the ON YARN mode to execute the Spark task.