Record
Basic environment
- JDK8
- Python3.7
Setting up Spark environment in Window
First install JDK8 and python 3, which will not be repeated here
Install Hadoop 2 seven
-
Download address: http://archive.apache.org/dist/hadoop/core/hadoop-2.7.7/hadoop-2.7.7.tar.gz
-
decompression
-
Download winutils of hadoop: https://github.com/steveloughran/winutils
-
Unzip the downloaded winutils to the bin directory of the hadoop directory
-
Setting up Java for hadoop_ HOME
Modify etc / hadoop / hadoop env CMD file: set the actual java installation directory
set JAVA_HOME=%JAVA_HOME%
Change to
set JAVA_HOME=E:\study\jdk1.8.0_144
-
Set HADOOP environment variable
The method is the same as configuring JDK environment variables:
New HADOOP_HOME variable, whose value is the extracted hadoop root directory;
Put% Hadoop_ Add home% \ bin to Path
-
cmd test whether hadoop is installed
cmd -- "run hadoop, hadoop version"
C:\Users\Minke>hadoop version Hadoop 2.7.7 Subversion Unknown -r c1aad84bd27cd79c3d1a7dd58202a8c3ee1ed3ac Compiled by stevel on 2018-07-18T22:47Z Compiled with protoc 2.5.0 From source with checksum 792e15d20b12c74bd6f19a1fb886490 This command was run using /F:/ITInstall/hadoop-2.7.7/share/hadoop/common/hadoop-common-2.7.7.jar
If error: Java appears_ Home is incorrect set. Generally, if your jdk is installed on Disk C, move it to another disk
Install spark 2 4.x
Here I install version 2.4.8
-
Download, download address: https://archive.apache.org/dist/spark/spark-2.4.8/spark-2.4.8-bin-hadoop2.7.tgz
-
Unzip to your directory
-
Set SPARK_HOME environment variable and put% spark_ Add home% \ bin to Path
-
cmd test
cmd – > run pyspark
C:\Users\Minke>pyspark Python 3.7.0 (v3.7.0:1bf9cc5093, Jun 27 2018, 04:59:51) [MSC v.1914 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. 22/02/11 17:21:57 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /__ / .__/\_,_/_/ /_/\_\ version 2.4.8 /_/ Using Python version 3.7.0 (v3.7.0:1bf9cc5093, Jun 27 2018 04:59:51) SparkSession available as 'spark'. >>> -
quit() to exit
-
Test spark task
cmd --> spark-submit %SPARK_HOME%/examples/src/main/python/pi.py
The calculation results can be seen from the log:
Pi is roughly 3.142780
Build Spark environment with Linux
JDK and python 3 need to be installed in advance seven
Only single node and multi node are demonstrated here. For the installation of Hadoop cluster, please refer to:
-
Download. The download path is the same as above
You can download wget or window and transfer it to linux through the transmission tool
-
decompression
tar -zvxf spark-2.4.8-bin-hadoop2.7.tgz -C /opt/module mv spark-2.4.8-bin-hadoop2.7 spark-2.4.8
-
test
cd /opt/module/spark-2.4.8 bin/spark-submit examples/src/main/python/pi.py The results can be seen in the print log Pi is roughly 3.137780
-
Setting environment variables
vi /etc/profile add to #==================spark==================== export SPARK_HOME=/opt/module/spark-2.4.8 export PATH=$PATH:$SPARK_HOME/bin wq!After saving source /etc/profile
-
Modify log level
Modify the conf directory and copy log4j properties. The template is log4j properties
Modify log4j Rootcategory = info, just console
Jupiter notebook installation
JupyterNotebook integration pyspark in Linux Environment
-
Install jupyterNotebook
pip3 install jupyter
-
Install findpark
The package findpark is required for jupyter to access spark
pip3 install findspark
-
Start jupyter
If you don't know where the jupyter command is installed, you can find it first
find / -name /jupyter
perhaps
cd /usr/local/python3/bin There are in this directory jupyter Command. If this directory is not in the environment variable, it needs to be started in this way ./jupyter notebook --allow-root
-
Open the web page of Jupiter notebook and test it
Create a new file
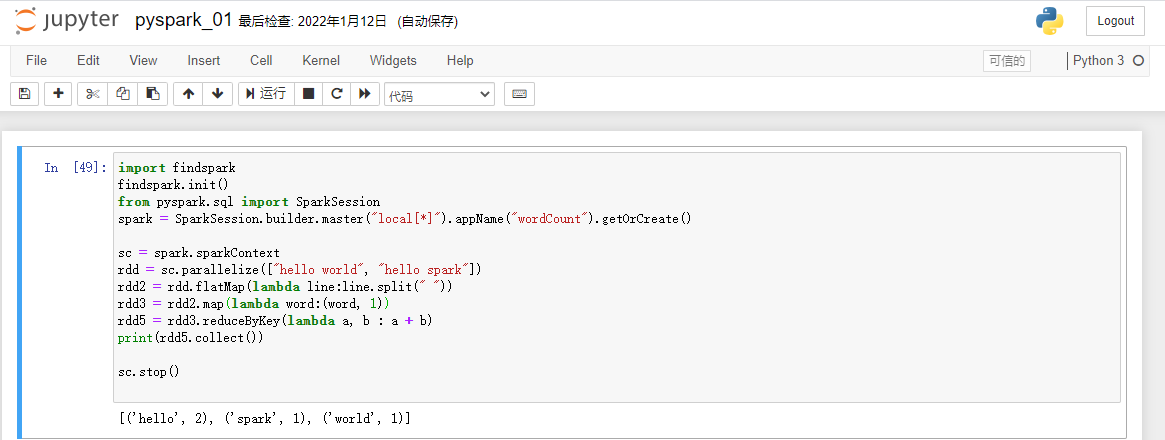
import findspark findspark.init() from pyspark.sql import SparkSession spark = SparkSession.builder.master("local[*]").appName("wordCount").getOrCreate() sc = spark.sparkContext rdd = sc.parallelize(["hello world", "hello spark"]) rdd2 = rdd.flatMap(lambda line:line.split(" ")) rdd3 = rdd2.map(lambda word:(word, 1)) rdd5 = rdd3.reduceByKey(lambda a, b : a + b) print(rdd5.collect()) sc.stop()Output results
[('hello', 2), ('spark', 1), ('world', 1)]
Window environment JupyterNotebook integration pyspark
Install Anaconda first, download the installation package from Baidu, and then install it. There is no special step. Anaconda will install JupyterNotebook. Anaconda is an integrated environment, which is also convenient for the installation of other tools and python packages. It is recommended to install it
-
Install Anaconda
-
Enter Anaconda directory
-
Enter the Scripts directory
-
Open the command line cmd in the Scripts directory. Be sure to use this directory. Otherwise, the installed toolkit, Jupiter notebook, cannot be found. This is a flaw in the windows environment
-
Install findpark
pip3 install findspark
If the process is long, you can consider changing the image to Ali, which will be faster
-
Test: start the jupyter notebook and open the web page in your browser
-
Create a new Python 3 file
import findspark findspark.init() from pyspark.sql import SparkSession spark = SparkSession.builder.master("local[*]").appName("wordCount").getOrCreate() sc = spark.sparkContext rdd = sc.parallelize(["hello world", "hello spark"]) rdd2 = rdd.flatMap(lambda line:line.split(" ")) rdd3 = rdd2.map(lambda word:(word, 1)) rdd5 = rdd3.reduceByKey(lambda a, b : a + b) print(rdd5.collect()) sc.stop()results of enforcement
[('hello', 2), ('spark', 1), ('world', 1)]