By default, Spark can divide a job into multiple tasks and send it to the Executor node for parallel computing. The number of tasks that can be calculated in parallel is called parallelism. This number can be specified when building the RDD.
However, the number of splitting tasks is not necessarily equal to the number of tasks executed in parallel. For example, when the number of node resources is less than the number of splitting tasks.
There are four ways to create RDD S in Spark:
1, Create RDD from collection (memory)
1. Create RDD from collection
Using the makeRDD method
//*The number indicates the maximum number of available cores in the local environment. Multithreading is used to simulate the cluster environment
var sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
//Create RDD from memory and take the data collected in memory as the data source for processing
val seq = Seq[Int](1,2,3,4)
//Parallelize parallelize collection operations are RDD objects created based on an existing Scala collection and the current system environment.
// The elements in the set will be copied into a newly created distributed data set that can be operated in parallel.
//val rdd: RDD[Int] = sc.parallelize(seq)
//parallelize is called in makeRDD
val rdd: RDD[Int] = sc.makeRDD(seq)
rdd.collect().foreach(println)
sc.stop()
2. How is the number of partitions determined
When creating an RDD from a collection (memory), the number of partitions is first specified by the second (optional) parameter passed in by makeRDD
def makeRDD[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T] = withScope {
parallelize(seq, numSlices)
}
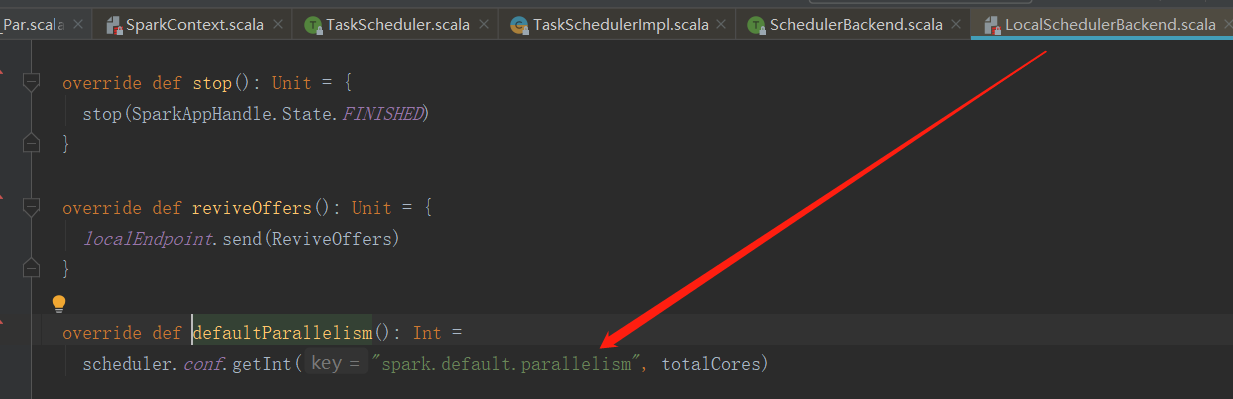
If it is not transmitted, it is sent by spark. In the defaultParallelism (configuration object (SparkConf)) default. The value of parallelism) specifies that if this value is not set in advance, the default value is totalCores (the maximum number of available cores in the current running environment)
//*The number indicates the maximum number of available cores in the local environment. Multithreading is used to simulate the cluster environment
var sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
sparkConf.set("spark.default.parallelism","5")
val sc = new SparkContext(sparkConf)
//Parallelism & partitioning of RDD
//The makeRDD method can pass a second parameter, which represents the number of partitions. If not, the method will use the default parallelism
// scheduler.conf.getInt("spark.default.parallelism", totalCores)
// Spark will get the configuration parameter spark from the configuration object sparkConf by default default. parallelism
// If it cannot be obtained, the totalCores attribute is used. This attribute value is the maximum number of available cores in the current running environment
val rdd: RDD[Int] = sc.makeRDD(
List(1, 2, 3, 4),2
)
//Save the processed data as a partition file
rdd.saveAsTextFile("output")
sc.stop()
3. Data partition when creating RDD from set (memory)
The core source code of the final data division method in makeRDD is as follows
def positions(length: Long, numSlices: Int): Iterator[(Int, Int)] = {
(0 until numSlices).iterator.map { i =>
val start = ((i * length) / numSlices).toInt
val end = (((i + 1) * length) / numSlices).toInt
(start, end)
}
}
This method passes in two parameters, one is the length of the data set, and the other is the number of partitions numSlices. In combination, you can see that the range of the data set taken by a partition numbered i is
[start, end], where
start = ((i * length) / numSlices).toInt
end = (((i + 1) * length) / numSlices).toInt
2, Create RDD from external storage (file)
RDD S created from data sets of external storage systems include local file systems and all data sets supported by Hadoop, such as HDFS, HBase, etc.
1. Create RDD from file
The path path is based on the root path of the current environment by default. So you can write absolute paths or relative paths
//val rdd: RDD[String] = sc.textFile("D:\\IdeaProjects\\syc-classes\\datas\\1.txt")
val rdd: RDD[String] = sc.textFile("datas/1.txt")
In addition, path can also be the path of a directory, which can read multiple files at one time
val rdd: RDD[String] = sc.textFile("datas")
The path path can also use wildcards to read only specific files
val rdd: RDD[String] = sc.textFile("datas/1*.txt")
Path can also be a distributed storage system path: HDFS
val rdd: RDD[String] = sc.textFile("hdfs://linux1:8080/text.txt")
There are two methods to create RDD S from files: testFile() and wholeTextFiles()
textFile: reads data in behavioral units, regardless of where the file comes from
wholeTextFiles: reads data in file units. The read results are represented as tuples. The first element represents the file path and the second element represents the file content
2. How is the number of partitions determined
(1) First confirm the minimum number of partitions
When creating an RDD from a file, the number of partitions depends on the second parameter (optional) passed in by testFile(), which is the minimum number of partitions.
def textFile(
path: String,
minPartitions: Int = defaultMinPartitions): RDD[String] = withScope {
assertNotStopped()
hadoopFile(path, classOf[TextInputFormat], classOf[LongWritable], classOf[Text],
minPartitions).map(pair => pair._2.toString).setName(path)
}
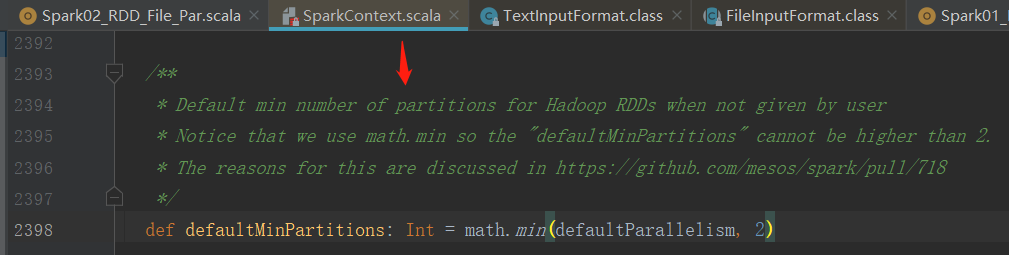
If it is not transmitted, the smaller value of defaultParallelism (explained above, the same here) and 2 is taken as the minimum number of partitions
(2) Then calculate the final actual number of partitions
Spark's underlying method for reading files actually calls Hadoop's reading method, which is available at org. Org apache. hadoop. mapred. In the getSplits() method of fileinputformat class, divide the total bytes of the file by the minimum number of partitions, and then round to get a value goalSize. If the remaining bytes are less than 10% of goalSize, the final number of partitions is the minimum number of partitions obtained in the previous step, otherwise another partition needs to be added.
For example, use the following file data / 1 Txt file as an example, use @ @ to represent line feed, accounting for two bytes, so the file has a total of 7 bytes.
1@@
2@@
3
Let the code for creating RDD be as follows, so the minimum number of partitions is 2
val rdd: RDD[String] = sc.textFile("datas/1.txt",2)
7 / 2 = 3... 1, so the goalSize value is 3, the remainder is 1, and the remainder is greater than 10% of goalSize, so the final number of partitions is 3, and the partition numbers are 0, 1 and 2 respectively
3. Data division when creating RDD from external storage (file)
Refer directly to the slicing mechanism of Hadoop
3, Create from other RDD S
It mainly generates a new RDD after an RDD operation. Please refer to the following chapters for details
4, Create RDD directly (new)
RDD is directly constructed by using new, which is generally used by Spark framework itself.