1. Differences between Spark on Hive and Hive on Spark
1)Spark on Hive
Spark on Hive is Hive's only storage role and Spark is responsible for sql parsing optimization and execution. You can understand that Spark uses Hive statements to manipulate Hive tables through Spark SQL, and Spark RDD runs at the bottom. The steps are as follows:
- Through SparkSQL, load Hive's configuration file to get Hive's metadata information;
- After getting Hive's metadata information, you can get the data of the Hive table.
- Manipulate data in Hive tables using SparkSQL.
The implementation is simple and can be referred to as: Big Data Hadoop--Spark SQL+Spark Streaming
[Summary] Spark uses Hive to provide metadata information for tables.
2) Hive on Spark (implemented in this chapter)
Hive on Spark is Hive responsible for both storage and parsing and optimization of sql, and Spark is responsible for execution. Hive's execution engine is now Spark, not MR anymore. To achieve this, it is more cumbersome than Spark on Hive. You must recompile your spark and import the jar package, but currently most of it is spark on hive.
- Hive uses MapReduce as the execution engine by default, Hive on MapReduce. In fact, Hive can also use Tez and Spark as its execution engines, Hive on Tez and Hive on Spark, respectively. Since all MapReduce intermediate computations need to be written to disk, and Spark is in memory, overall Spark is much faster than MapReduce. Therefore, Hive on Spark is also faster than Hive on MapReduce. Due to the drawbacks of Hive on MapReduce, it is rarely used in the enterprise.
[Summary] hive on spark is similar in structure to spark on hive, except that the SQL engine is different, but the computing engines are spark!
Reference documents:
- https://cwiki.apache.org/confluence/display/Hive/Hive+on+Spark
- https://cwiki.apache.org/confluence/display/Hive/Hive+on+Spark:+Getting+Started#HiveonSpark:GettingStarted-VersionCompatibility
- https://cwiki.apache.org/confluence/display/Hive/HiveDeveloperFAQ#HiveDeveloperFAQ-HowdoIimportintoEclipse?
2. Hive on Spark Implementation
Compile Spark Source
To use Hive on Spark, you must use a version of Spark that does not contain Hive's associated jar packages. The official website for hive on spark says "Note that you must have a version of Spark which does not include the Hive jars." The compiled Sparks downloaded on the Spark website are all Hive integrated, so you need to download the source code yourself to compile it, and you do not specify Hive when compiling. Final version: Hadoop3.3.1+Spark2.4.5+Hive3.1.2
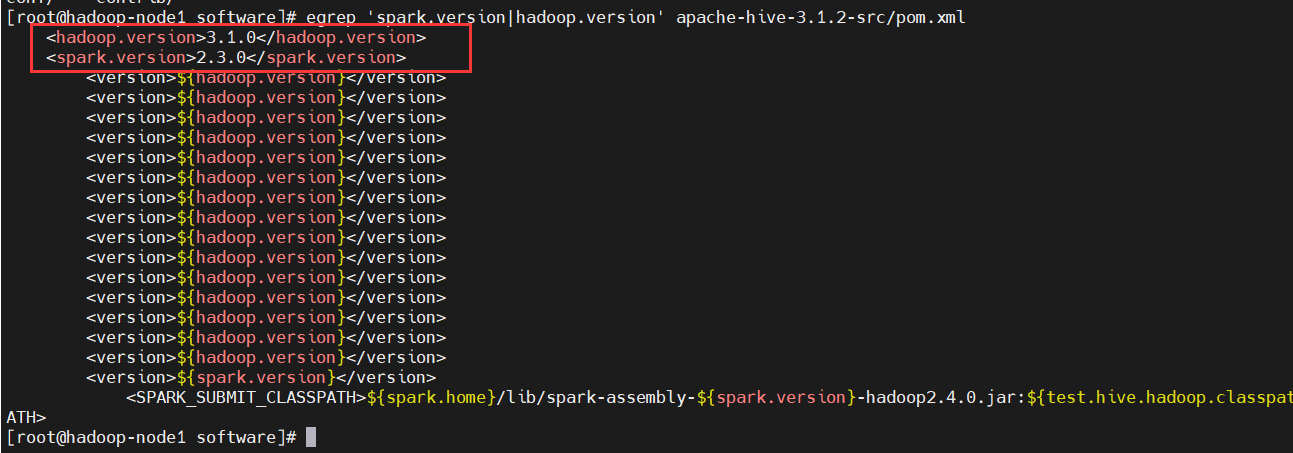
1) Download hive-3.1 first. 2 Source Pack View spark Version
$ cd /opt/bigdata/hadoop/software $ wget http://archive.apache.org/dist/hive/hive-3.1.2/apache-hive-3.1.2-src.tar.gz $ tar -zxvf apache-hive-3.1.2-src.tar.gz $ egrep 'spark.version|hadoop.version' apache-hive-3.1.2-src/pom.xml
2) Download spark
Download address: https://archive.apache.org/dist/spark/spark-2.3.0/
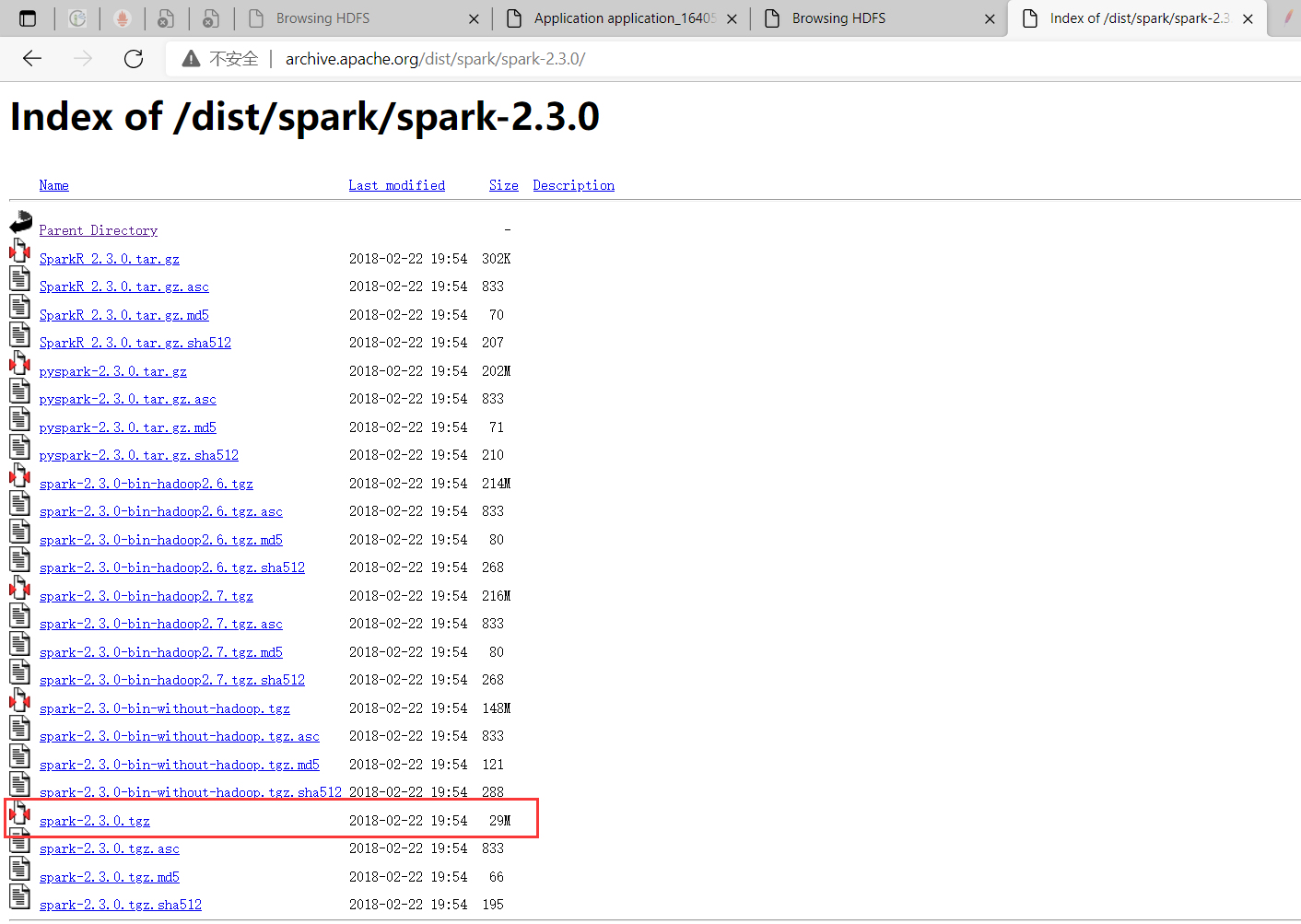
$ cd /opt/bigdata/hadoop/software # download $ wget http://archive.apache.org/dist/spark/spark-2.3.0/spark-2.3.0.tgz
3) Decompilation
# decompression $ tar -zxvf spark-2.3.0.tgz $ cd spark-2.3.0 # Start compiling, note the hadoop version $ ./dev/make-distribution.sh --name without-hive --tgz -Pyarn -Phadoop-2.7 -Dhadoop.version=3.3.1 -Pparquet-provided -Porc-provided -Phadoop-provided # Or (the following sentence is not executed here because it is equivalent to the above sentence) $ ./dev/make-distribution.sh --name "without-hive" --tgz "-Pyarn,hadoop-provided,hadoop-2.7,parquet-provided,orc-provided" Command Explanation: -Phadoop-3.3 \ -Dhadoop.version=3.3.1 \ ***Appoint hadoop Version 3.3.1 --name without-hive hive Is the name parameter of the compiled file --tgz ***Compress into tgz format -Pyarn Is Support yarn -Phadoop-2.7 Is Supported hadoop Version, starting with 3.3 Later prompt hadoop3.3 No, we have to change to 2.7,Compilation successful -Dhadoop.version=3.3.1 Running Environment
However, the compilation is stuck. The original compilation will automatically download maven and scala and store them in the build directory, as shown in the following figure:
After downloading maven and scala automatically, you start compiling. It will take a long time to compile. Wait for compilation to finish slowly.
It took about half an hour to compile, and finally it was finished. The compilation time is too long, so I will also put my compiled spark package on the disk for you to download.
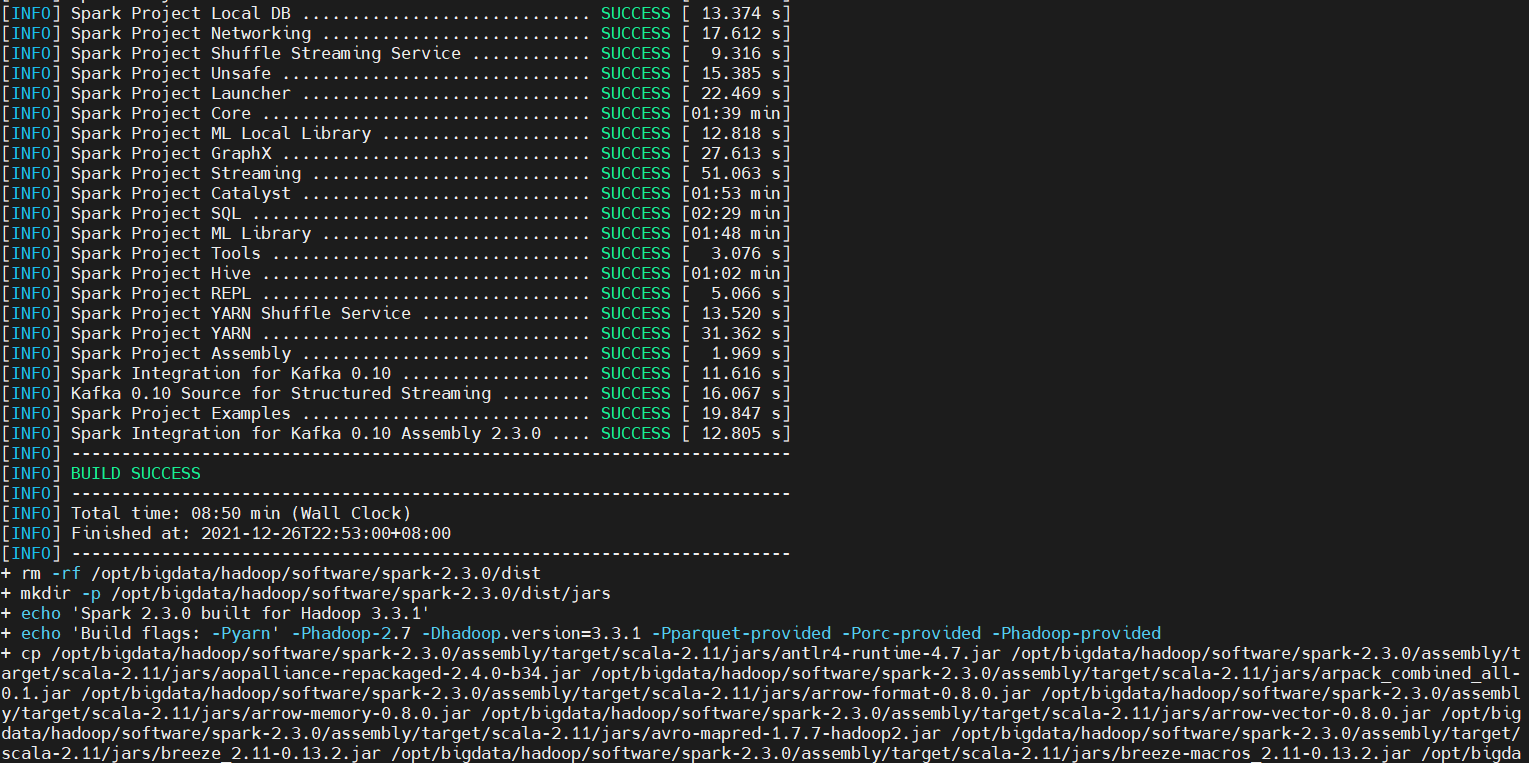
A compiled spark package exists in the current directory
$ ll
4) Decompression
$ tar -zxvf spark-2.3.0-bin-without-hive.tgz -C /opt/bigdata/hadoop/server/ $ cd /opt/bigdata/hadoop/server/spark-2.3.0-bin-without-hive $ ll
5) Play spark jar to upload to HDFS
[Warm Tips] Requirements for configuration in the hive-site.xml file.
$ cd /opt/bigdata/hadoop/server/spark-2.3.0-bin-without-hive/ ### Create log store directory $ hadoop fs -mkdir -p hdfs://hadoop-node1:8082/tmp/spark ### Create a directory to store jar packages on hdfs $ hadoop fs -mkdir -p /spark/spark-2.4.5-jars ## Upload jars to HDFS $ hadoop fs -put ./jars/* /spark/spark-2.4.5-jars/
If a packaged jar package is used, the hive operation will report the following error:
Failed to execute spark task, with exception 'org.apache.hadoop.hive.ql.metadata.HiveException(Failed to create Spark client for Spark session c8c46c14-4d2a-4f7e-9a12-0cd62bf097db)'
FAILED: Execution Error, return code 30041 from org.apache.hadoop.hive.ql.exec.spark.SparkTask. Failed to create Spark client for Spark session c8c46c14-4d2a-4f7e-9a12-0cd62bf097db
6) Package the spark jar package and upload it to HDFS
[Warm Tip] The spark-default.xml file needs to be configured with a packaged jar package, which is called spark-submit.
$ cd /opt/bigdata/hadoop/server/spark-2.3.0-bin-without-hive/ $ jar cv0f spark2.3.0-without-hive-libs.jar -C ./jars/ . $ ll ### Create a directory to store jar packages on hdfs $ hadoop fs -mkdir -p /spark/jars ## Upload jars to HDFS $ hadoop fs -put spark2.3.0-without-hive-libs.jar /spark/jars/
If not packaged, the following error will be reported:
Exception in thread "main" java.io.FileNotFoundException: File does not exist: hdfs://hadoop-node1:8082/spark/spark-2.3.0-jars/*.jar
at org.apache.hadoop.hdfs.DistributedFileSystem$29.doCall(DistributedFileSystem.java:1756)
at org.apache.hadoop.hdfs.DistributedFileSystem
29.
d
o
C
a
l
l
(
D
i
s
t
r
i
b
u
t
e
d
F
i
l
e
S
y
s
t
e
m
.
j
a
v
a
:
1749
)
a
t
o
r
g
.
a
p
a
c
h
e
.
h
a
d
o
o
p
.
f
s
.
F
i
l
e
S
y
s
t
e
m
L
i
n
k
R
e
s
o
l
v
e
r
.
r
e
s
o
l
v
e
(
F
i
l
e
S
y
s
t
e
m
L
i
n
k
R
e
s
o
l
v
e
r
.
j
a
v
a
:
81
)
a
t
o
r
g
.
a
p
a
c
h
e
.
h
a
d
o
o
p
.
h
d
f
s
.
D
i
s
t
r
i
b
u
t
e
d
F
i
l
e
S
y
s
t
e
m
.
g
e
t
F
i
l
e
S
t
a
t
u
s
(
D
i
s
t
r
i
b
u
t
e
d
F
i
l
e
S
y
s
t
e
m
.
j
a
v
a
:
1764
)
a
t
o
r
g
.
a
p
a
c
h
e
.
s
p
a
r
k
.
d
e
p
l
o
y
.
y
a
r
n
.
C
l
i
e
n
t
D
i
s
t
r
i
b
u
t
e
d
C
a
c
h
e
M
a
n
a
g
e
r
29.doCall(DistributedFileSystem.java:1749) at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81) at org.apache.hadoop.hdfs.DistributedFileSystem.getFileStatus(DistributedFileSystem.java:1764) at org.apache.spark.deploy.yarn.ClientDistributedCacheManager
29.doCall(DistributedFileSystem.java:1749)atorg.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81)atorg.apache.hadoop.hdfs.DistributedFileSystem.getFileStatus(DistributedFileSystem.java:1764)atorg.apache.spark.deploy.yarn.ClientDistributedCacheManager$anonfun
1.
a
p
p
l
y
(
C
l
i
e
n
t
D
i
s
t
r
i
b
u
t
e
d
C
a
c
h
e
M
a
n
a
g
e
r
.
s
c
a
l
a
:
71
)
a
t
o
r
g
.
a
p
a
c
h
e
.
s
p
a
r
k
.
d
e
p
l
o
y
.
y
a
r
n
.
C
l
i
e
n
t
D
i
s
t
r
i
b
u
t
e
d
C
a
c
h
e
M
a
n
a
g
e
r
1.apply(ClientDistributedCacheManager.scala:71) at org.apache.spark.deploy.yarn.ClientDistributedCacheManager
1.apply(ClientDistributedCacheManager.scala:71)atorg.apache.spark.deploy.yarn.ClientDistributedCacheManager$anonfun
1.
a
p
p
l
y
(
C
l
i
e
n
t
D
i
s
t
r
i
b
u
t
e
d
C
a
c
h
e
M
a
n
a
g
e
r
.
s
c
a
l
a
:
71
)
a
t
s
c
a
l
a
.
c
o
l
l
e
c
t
i
o
n
.
M
a
p
L
i
k
e
1.apply(ClientDistributedCacheManager.scala:71) at scala.collection.MapLike
1.apply(ClientDistributedCacheManager.scala:71)atscala.collection.MapLikeclass.getOrElse(MapLike.scala:128)
at scala.collection.AbstractMap.getOrElse(Map.scala:59)
at org.apache.spark.deploy.yarn.ClientDistributedCacheManager.addResource(ClientDistributedCacheManager.scala:71)
at org.apache.spark.deploy.yarn.Client.org
a
p
a
c
h
e
apache
apachespark
d
e
p
l
o
y
deploy
deployyarn
C
l
i
e
n
t
Client
Client$distribute
1
(
C
l
i
e
n
t
.
s
c
a
l
a
:
480
)
a
t
o
r
g
.
a
p
a
c
h
e
.
s
p
a
r
k
.
d
e
p
l
o
y
.
y
a
r
n
.
C
l
i
e
n
t
.
p
r
e
p
a
r
e
L
o
c
a
l
R
e
s
o
u
r
c
e
s
(
C
l
i
e
n
t
.
s
c
a
l
a
:
517
)
a
t
o
r
g
.
a
p
a
c
h
e
.
s
p
a
r
k
.
d
e
p
l
o
y
.
y
a
r
n
.
C
l
i
e
n
t
.
c
r
e
a
t
e
C
o
n
t
a
i
n
e
r
L
a
u
n
c
h
C
o
n
t
e
x
t
(
C
l
i
e
n
t
.
s
c
a
l
a
:
863
)
a
t
o
r
g
.
a
p
a
c
h
e
.
s
p
a
r
k
.
d
e
p
l
o
y
.
y
a
r
n
.
C
l
i
e
n
t
.
s
u
b
m
i
t
A
p
p
l
i
c
a
t
i
o
n
(
C
l
i
e
n
t
.
s
c
a
l
a
:
169
)
a
t
o
r
g
.
a
p
a
c
h
e
.
s
p
a
r
k
.
s
c
h
e
d
u
l
e
r
.
c
l
u
s
t
e
r
.
Y
a
r
n
C
l
i
e
n
t
S
c
h
e
d
u
l
e
r
B
a
c
k
e
n
d
.
s
t
a
r
t
(
Y
a
r
n
C
l
i
e
n
t
S
c
h
e
d
u
l
e
r
B
a
c
k
e
n
d
.
s
c
a
l
a
:
57
)
a
t
o
r
g
.
a
p
a
c
h
e
.
s
p
a
r
k
.
s
c
h
e
d
u
l
e
r
.
T
a
s
k
S
c
h
e
d
u
l
e
r
I
m
p
l
.
s
t
a
r
t
(
T
a
s
k
S
c
h
e
d
u
l
e
r
I
m
p
l
.
s
c
a
l
a
:
164
)
a
t
o
r
g
.
a
p
a
c
h
e
.
s
p
a
r
k
.
S
p
a
r
k
C
o
n
t
e
x
t
.
<
i
n
i
t
>
(
S
p
a
r
k
C
o
n
t
e
x
t
.
s
c
a
l
a
:
500
)
a
t
o
r
g
.
a
p
a
c
h
e
.
s
p
a
r
k
.
S
p
a
r
k
C
o
n
t
e
x
t
1(Client.scala:480) at org.apache.spark.deploy.yarn.Client.prepareLocalResources(Client.scala:517) at org.apache.spark.deploy.yarn.Client.createContainerLaunchContext(Client.scala:863) at org.apache.spark.deploy.yarn.Client.submitApplication(Client.scala:169) at org.apache.spark.scheduler.cluster.YarnClientSchedulerBackend.start(YarnClientSchedulerBackend.scala:57) at org.apache.spark.scheduler.TaskSchedulerImpl.start(TaskSchedulerImpl.scala:164) at org.apache.spark.SparkContext.<init>(SparkContext.scala:500) at org.apache.spark.SparkContext
1(Client.scala:480)atorg.apache.spark.deploy.yarn.Client.prepareLocalResources(Client.scala:517)atorg.apache.spark.deploy.yarn.Client.createContainerLaunchContext(Client.scala:863)atorg.apache.spark.deploy.yarn.Client.submitApplication(Client.scala:169)atorg.apache.spark.scheduler.cluster.YarnClientSchedulerBackend.start(YarnClientSchedulerBackend.scala:57)atorg.apache.spark.scheduler.TaskSchedulerImpl.start(TaskSchedulerImpl.scala:164)atorg.apache.spark.SparkContext.<init>(SparkContext.scala:500)atorg.apache.spark.SparkContext.getOrCreate(SparkContext.scala:2486)
at org.apache.spark.sql.SparkSession
B
u
i
l
d
e
r
Builder
Builder$anonfun
7.
a
p
p
l
y
(
S
p
a
r
k
S
e
s
s
i
o
n
.
s
c
a
l
a
:
930
)
a
t
o
r
g
.
a
p
a
c
h
e
.
s
p
a
r
k
.
s
q
l
.
S
p
a
r
k
S
e
s
s
i
o
n
7.apply(SparkSession.scala:930) at org.apache.spark.sql.SparkSession
7.apply(SparkSession.scala:930)atorg.apache.spark.sql.SparkSessionBuilderKaTeX parse error: Can't use function '$' in math mode at position 8: anonfun$̲7.apply(SparkSe...runMain(SparkSubmit.scala:879)
at org.apache.spark.deploy.SparkSubmit$.doRunMain
1
(
S
p
a
r
k
S
u
b
m
i
t
.
s
c
a
l
a
:
197
)
a
t
o
r
g
.
a
p
a
c
h
e
.
s
p
a
r
k
.
d
e
p
l
o
y
.
S
p
a
r
k
S
u
b
m
i
t
1(SparkSubmit.scala:197) at org.apache.spark.deploy.SparkSubmit
1(SparkSubmit.scala:197)atorg.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:227)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:136)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
7) Configuration
1. Configure spark-defaults.conf
$ cd /opt/bigdata/hadoop/server/spark-2.3.0-bin-without-hive/conf # Cop a configuration file $ cp spark-defaults.conf.template spark-defaults.conf
Spark-defaults. The conf changes are as follows:
spark.master yarn spark.home /opt/bigdata/hadoop/server/spark-2.3.0-bin-without-hive spark.eventLog.enabled true spark.eventLog.dir hdfs://hadoop-node1:8082/tmp/spark spark.serializer org.apache.spark.serializer.KryoSerializer spark.executor.memory 1g spark.driver.memory 1g spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three" spark.yarn.archive hdfs:///spark/jars/spark2.3.0-without-hive-libs.jar spark.yarn.jars hdfs:///spark/jars/spark2.3.0-without-hive-libs.jar ### Parameter explanation without copying to configuration file # spark.master specifies the Spark mode of operation, which can be yarn-client, yarn-cluster... # spark.home specifies SPARK_HOME Path # Spark. EvetLog. Enabled needs to be set to true # Spark. EvetLog. Dir specifies the path, placed in the master node's hdfs, the port should match the port set by HDFS (default is 8020), otherwise error will occur # spark.executor.memory and spark.driver.memory specifies the memory of executor and dirver, 512m or 1g, which is neither too large nor too small because it is too small to run and too large to affect other services
2. Configure spark-env.sh
$ cd /opt/bigdata/hadoop/server/spark-2.3.0-bin-without-hive/conf
$ cp spark-env.sh.template spark-env.sh
# In spark-env.sh Add the following
$ vi spark-env.sh
export SPARK_DIST_CLASSPATH=$(hadoop classpath)
export HADOOP_CONF_DIR={HADOOP_HOME}/etc/hadoop/
# Load
$ source spark-env.sh
When running in Yarn mode, the following three packages need to be placed in HIVE_ Under HOME/lib: scala-library, spark-core, spark-network-common.
$ cd /opt/bigdata/hadoop/server/spark-2.3.0-bin-without-hive # Delete first $ rm -f ../apache-hive-3.1.2-bin/lib/scala-library-*.jar $ rm -f ../apache-hive-3.1.2-bin/lib/spark-core_*.jar $ rm -f ../apache-hive-3.1.2-bin/lib/spark-network-common_*.jar # copy the three jar s to the hive lib directory $ cp jars/scala-library-*.jar ../apache-hive-3.1.2-bin/lib/ $ cp jars/spark-core_*.jar ../apache-hive-3.1.2-bin/lib/ $ cp jars/spark-network-common_*.jar ../apache-hive-3.1.2-bin/lib/
3. Configure hive-site.xml
$ cd /opt/bigdata/hadoop/server/apache-hive-3.1.2-bin/conf/
#Configure hive-site.xml, main mysql database
$ cat << EOF > hive-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- To configure hdfs Storage directory -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive_remote/warehouse</value>
</property>
<!-- Connected MySQL The address of the database, hive_remote Is the database, the program will be created automatically, just customize it -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop-node1:3306/hive_remote2?createDatabaseIfNotExist=true&useSSL=false&serverTimezone=Asia/Shanghai</value>
</property>
<!-- Local mode
<property>
<name>hive.metastore.local</name>
<value>false</value>
</property>
-->
<!-- MySQL drive -->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- mysql Connect user -->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- mysql Connection Password -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<!--Is Metadata Checked-->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>system:user.name</name>
<value>root</value>
<description>user name</description>
</property>
<!-- host -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop-node1</value>
<description>Bind host on which to run the HiveServer2 Thrift service.</description>
</property>
<!-- hs2 port -->
<property>
<name>hive.server2.thrift.port</name>
<value>11000</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop-node1:9083</value>
</property>
<!--Spark Dependent location, upload above jar Packaged hdfs Route-->
<property>
<name>spark.yarn.jars</name>
<value>hdfs:///spark/spark-2.3.0-jars/*.jar</value>
</property>
<!--Hive Execution engine, using spark-->
<property>
<name>hive.execution.engine</name>
<value>spark</value>
</property>
<!--Hive and spark Connection timeout-->
<property>
<name>hive.spark.client.connect.timeout</name>
<value>10000ms</value>
</property>
</configuration>
EOF
8) Setting environment variables
Add the following configuration in/etc/profile:
export HIVE_HOME=/opt/bigdata/hadoop/server/apache-hive-3.1.2-bin export PATH=$HIVE_HOME/bin:$PATH export SPARK_HOME=/opt/bigdata/hadoop/server/spark-2.3.0-bin-without-hive export PATH=$SPARK_HOME/bin:$PATH
Load
$ source /etc/profile
9) Initialize the database (mysql)
If it's not clear, you can read this article first Big Data Hadoop - Data Warehouse Hive
# Initialization, --verbose: Query for details without adding $ schematool -initSchema -dbType mysql --verbose
10) Start or restart hive's metstore service
# First check if the process exists, then kill it $ ss -atnlp|grep 9083 # Start metstore service $ nohup hive --service metastore &
11) Test Verification
First verify that the compiled spark is ok, use the example provided by spark: SparkPI
$ spark-submit \ --class org.apache.spark.examples.SparkPi \ --master yarn \ --deploy-mode client \ --driver-memory 1G \ --num-executors 3 \ --executor-memory 1G \ --executor-cores 1 \ /opt/bigdata/hadoop/server/spark-2.3.0-bin-without-hive/examples/jars/spark-examples_*.jar 10
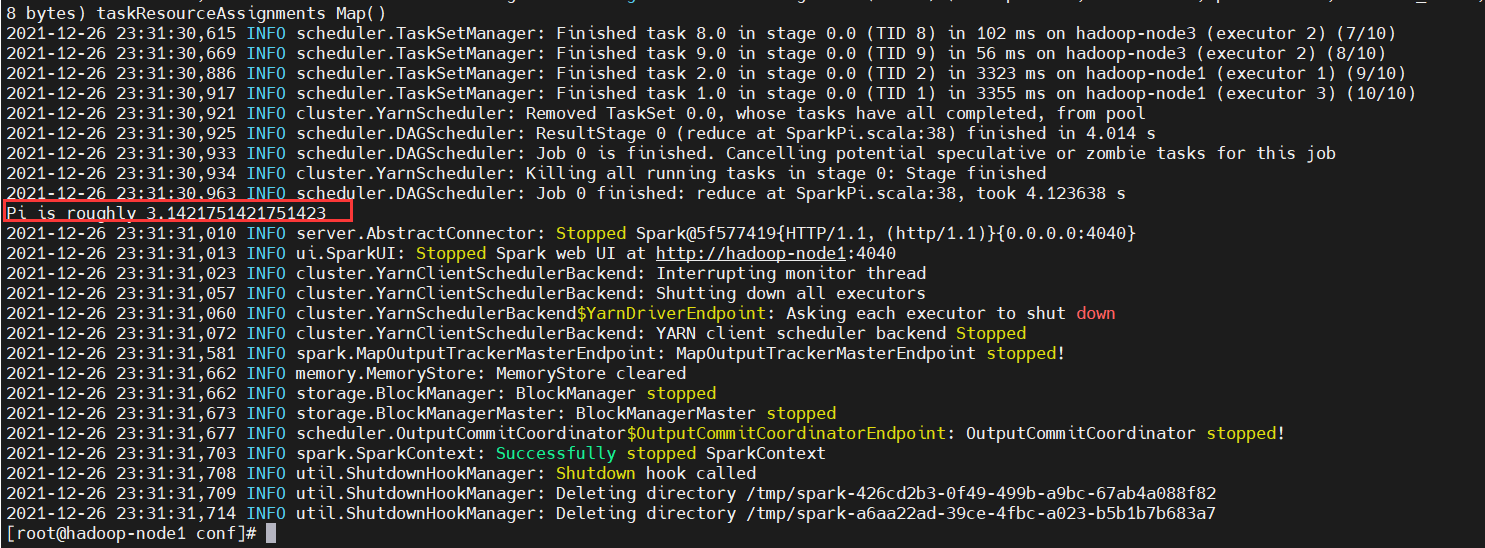
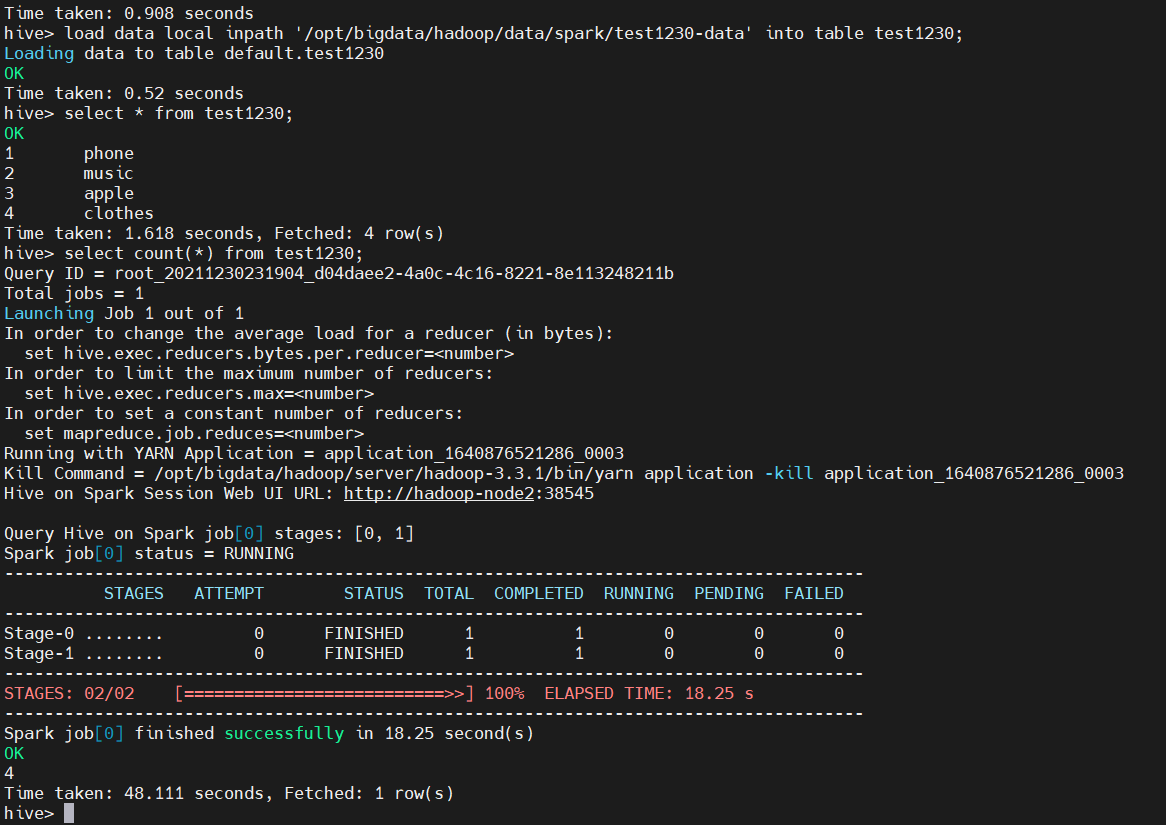
The compiled spark package is found to be OK from the figure above, and the next step is to verify that hive submits the spark task
$ mkdir /opt/bigdata/hadoop/data/spark $ cat << EOF > /opt/bigdata/hadoop/data/spark/test1230-data 1,phone 2,music 3,apple 4,clothes EOF # Start hive $ hive # Create tables to separate fields by commas create table test1230(id string,shop string) row format delimited fields terminated by ','; # Loading data from local, where local refers to the local linux file system on the machine where the hs2 service resides load data local inpath '/opt/bigdata/hadoop/data/spark/test1230-data' into table test1230; # Adding data through insert submits a spark task select * from test1230; select count(*) from test1230;
Finally, provide my compiled spark2 above. Version 3.0 packages downloaded at the following address:
Links: https://pan.baidu.com/s/1OY_Mn8UdRkTiiMktjQ3wlQ
Extraction code: 8888