catalogue
2, SparkApplication startup - JavaMainApplication, YarnClusterApplication
3, SparkContext initialization
4, YarnClientSchedulerBackend and YarnClusterSchedulerBackend initialization
6, Spark on Yan task submission process summary
1, Entry class - SparkSubmit
When submitting the spark task to the yarn cluster with the following command:
./bin/spark-submit --class org.apache.spark.examples.SparkPi \ --master yarn \ --deploy-mode client \ --driver-memory 2g \ --executor-memory 5g \ --executor-cores 10 \ examples/target/scala-2.11/jars/spark-examples*.jar 10
The java class finally called by spark submit command is SparkSubmit, and its main method code is as follows:
object SparkSubmit extends CommandLineUtils with Logging {
override def main(args: Array[String]): Unit = {
val appArgs = new SparkSubmitArguments(args)
appArgs.action match {
case SparkSubmitAction.SUBMIT => submit(appArgs, uninitLog)
case SparkSubmitAction.KILL => kill(appArgs)
case SparkSubmitAction.REQUEST_STATUS => requestStatus(appArgs)
}
}
private def submit(args: SparkSubmitArguments, uninitLog: Boolean): Unit = {
val (childArgs, childClasspath, sparkConf, childMainClass) =
prepareSubmitEnvironment(args)
runMain(childArgs, childClasspath, sparkConf, childMainClass, args.verbose)
}
}The main() method first instantiates the SparkSubmitArguments object to convert the command line parameters. When it is judged that its action is SUBMIT, it calls the SUBMIT () method to SUBMIT the task.
The preparesubmittenvironment () method is used to prepare the environment. It will find the main class running the application (childMainClass in the returned result) according to the -- master and -- deploy mode parameters in the submit command line:
- When submitting the parameter -- Master = yarn, -- deploy mode = client, the running main class is the value of its specified -- class parameter, or read the META-INFO information of the submitted jar package to obtain its running main class, that is, the entry class of the program we write.
- When submitting parameters -- Master = yarn, -- deploy mode = cluster, the main running class is org apache. spark. deploy. yarn. YarnClusterApplication
The sumbit() method finally calls the runMain() method, and the incoming parameter childMainClass is obtained by the above method. The code is as follows:
private def runMain(
childArgs: Seq[String],
childClasspath: Seq[String],
sparkConf: SparkConf,
childMainClass: String,
verbose: Boolean): Unit = {
val loader =
if (sparkConf.get(DRIVER_USER_CLASS_PATH_FIRST)) {
new ChildFirstURLClassLoader(new Array[URL](0),
Thread.currentThread.getContextClassLoader)
} else {
new MutableURLClassLoader(new Array[URL](0),
Thread.currentThread.getContextClassLoader)
}
Thread.currentThread.setContextClassLoader(loader)
for (jar <- childClasspath) {
addJarToClasspath(jar, loader)
}
mainClass = Utils.classForName(childMainClass)
val app: SparkApplication = if (classOf[SparkApplication].isAssignableFrom(mainClass)) {
mainClass.newInstance().asInstanceOf[SparkApplication]
} else {
// SPARK-4170
if (classOf[scala.App].isAssignableFrom(mainClass)) {
printWarning("Subclasses of scala.App may not work correctly. Use a main() method instead.")
}
new JavaMainApplication(mainClass)
}
app.start(childArgs.toArray, sparkConf)
}The runMain() method will create an app object based on the passed in mainClass type. It judges that if the mainClass is a subclass of SparkApplication, it will directly create the object, otherwise it will create a JavaMainApplication object. Then the start method of the app object is called.
2, SparkApplication startup - JavaMainApplication, YarnClusterApplication
The above code analysis shows that when the value of mainClass is YarnClusterApplication, the object will be created directly and its start method will be called. The core source code of the start method of YarnClusterApplication class is as follows:
private[spark] class YarnClusterApplication extends SparkApplication {
override def start(args: Array[String], conf: SparkConf): Unit = {
// SparkSubmit would use yarn cache to distribute files & jars in yarn mode,
// so remove them from sparkConf here for yarn mode.
conf.remove("spark.jars")
conf.remove("spark.files")
new Client(new ClientArguments(args), conf).run()
}
}The start() method will go to the new Client object and call its run() method to submit tasks to the yarn cluster. The source code of the run() method will be analyzed later.
When mainClass is the value specified by the -- class parameter (i.e. deployMode is client), a JavaMainApplication object will be created:
private[deploy] class JavaMainApplication(klass: Class[_]) extends SparkApplication {
override def start(args: Array[String], conf: SparkConf): Unit = {
val mainMethod = klass.getMethod("main", new Array[String](0).getClass)
if (!Modifier.isStatic(mainMethod.getModifiers)) {
throw new IllegalStateException("The main method in the given main class must be static")
}
val sysProps = conf.getAll.toMap
sysProps.foreach { case (k, v) =>
sys.props(k) = v
}
mainMethod.invoke(null, args)
}
}The start method of this class will call the main class specified when we submit the command, and then call its main method.
After the above code analysis, we come to the conclusion that when the deploy mode is a cluster, the YarnClusterApplication object will be created. The object will go to the new Client object and call its run() method to submit tasks directly to the yarn cluster. When deploy mode is client, the main class class specified by us will be run.
When is the task submitted to yarn in client mode? The answer is: when creating a SparkContext object in the program code we write:
val sparkContext = new SparkContext(conf)
Next, we will analyze what will be done during the initialization of the SparkContext class (since the run method of the Client class will be called to submit the task in the cluster mode, and the method of this class will be called in the Client mode, so the method of the Client class will be analyzed later).
At this stage, you can make a preliminary summary of the running process of spark Code:
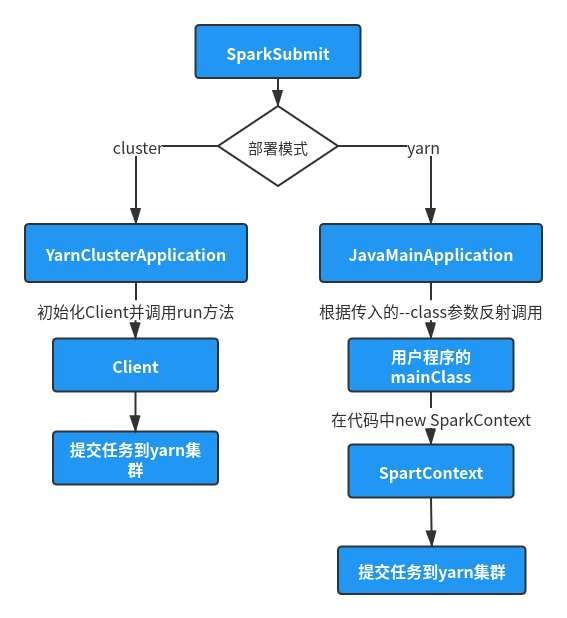
3, SparkContext initialization
When the SparkContext class is initialized, some core codes are as follows:
class SparkContext(config: SparkConf) extends Logging {
_conf = config.clone()
_conf.validateSettings()
logInfo(s"Submitted application: $appName")
_conf.set(DRIVER_HOST_ADDRESS, _conf.get(DRIVER_HOST_ADDRESS))
_conf.setIfMissing("spark.driver.port", "0")
_conf.set("spark.executor.id", SparkContext.DRIVER_IDENTIFIER)
_jars = Utils.getUserJars(_conf)
_files = _conf.getOption("spark.files").map(_.split(",")).map(_.filter(_.nonEmpty))
.toSeq.flatten
_eventLogDir =
if (isEventLogEnabled) {
val unresolvedDir = conf.get("spark.eventLog.dir", EventLoggingListener.DEFAULT_LOG_DIR)
.stripSuffix("/")
Some(Utils.resolveURI(unresolvedDir))
} else {
None
}
// Create the Spark execution environment (cache, map output tracker, etc)
_env = createSparkEnv(_conf, isLocal, listenerBus)
SparkEnv.set(_env)
_heartbeatReceiver = env.rpcEnv.setupEndpoint(
HeartbeatReceiver.ENDPOINT_NAME, new HeartbeatReceiver(this))
// Create and start the scheduler
val (sched, ts) = SparkContext.createTaskScheduler(this, master, deployMode)
_schedulerBackend = sched
_taskScheduler = ts
_dagScheduler = new DAGScheduler(this)
_heartbeatReceiver.ask[Boolean](TaskSchedulerIsSet)
// start TaskScheduler after taskScheduler sets DAGScheduler reference in DAGScheduler's
// constructor
_taskScheduler.start()
_applicationId = _taskScheduler.applicationId()
_applicationAttemptId = taskScheduler.applicationAttemptId()
_conf.set("spark.app.id", _applicationId)
if (_conf.getBoolean("spark.ui.reverseProxy", false)) {
System.setProperty("spark.ui.proxyBase", "/proxy/" + _applicationId)
}
_ui.foreach(_.setAppId(_applicationId))
_env.blockManager.initialize(_applicationId)
}This method initializes some key information:_ Set} driver in conf object_ HOST_ The address variable value, that is, the host and port number of the driver process (if no parameter is specified, one will be generated randomly). Set the attribute spark.executor.id to the fixed value "driver". Then call the createparkenv() method to create the SparkEnv object, which is very important. This object is the cornerstone of communication between driver and Executor and between Executor and Executor. The underlying rpc framework based on netty.
Then there is a key piece of code:
val (sched, ts) = SparkContext.createTaskScheduler(this, master, deployMode)
This method will create the TaskScheduler object. The key code of the method is as follows:
private def createTaskScheduler(
sc: SparkContext,
master: String,
deployMode: String): (SchedulerBackend, TaskScheduler) = {
import SparkMasterRegex._
// When running locally, don't try to re-execute tasks on failure.
val MAX_LOCAL_TASK_FAILURES = 1
master match {
// local operation mode
case "local" =>
val scheduler = new TaskSchedulerImpl(sc, MAX_LOCAL_TASK_FAILURES, isLocal = true)
val backend = new LocalSchedulerBackend(sc.getConf, scheduler, 1)
scheduler.initialize(backend)
(backend, scheduler)
// spark standalone operating mode
case SPARK_REGEX(sparkUrl) =>
val scheduler = new TaskSchedulerImpl(sc)
val masterUrls = sparkUrl.split(",").map("spark://" + _)
val backend = new StandaloneSchedulerBackend(scheduler, sc, masterUrls)
scheduler.initialize(backend)
(backend, scheduler)
// Otherwise, use the java spi mechanism to find the clusterManager
case masterUrl =>
val cm = getClusterManager(masterUrl) match {
case Some(clusterMgr) => clusterMgr
case None => throw new SparkException("Could not parse Master URL: '" + master + "'")
}
try {
val scheduler = cm.createTaskScheduler(sc, masterUrl)
val backend = cm.createSchedulerBackend(sc, masterUrl, scheduler)
cm.initialize(scheduler, backend)
(backend, scheduler)
} catch {
case se: SparkException => throw se
case NonFatal(e) =>
throw new SparkException("External scheduler cannot be instantiated", e)
}
}
}The createTaskScheduler() method creates taskscheduler and SchedulerBackend instance objects according to its master parameter. When the master is yarn, it cannot match the local and spark standard patterns, but can only enter the lowest matching pattern. It first calls getClusterManager method to find the implementation subclass of ExternalClusterManager class. The code is as follows:
private def getClusterManager(url: String): Option[ExternalClusterManager] = {
val loader = Utils.getContextOrSparkClassLoader
val serviceLoaders =
ServiceLoader.load(classOf[ExternalClusterManager], loader).asScala.filter(_.canCreate(url))
if (serviceLoaders.size > 1) {
throw new SparkException(
s"Multiple external cluster managers registered for the url $url: $serviceLoaders")
}
serviceLoaders.headOption
}The getClusterManager() method uses the ServiceLoader class in the java toolkit to load the implementation class of ExternalClusterManager. The file is defined in spark yarn_ xxx. Under the MEIA-INF/services directory in the. Jar package, the implementation class is specified in this file as org. Inf apache. spark. scheduler. cluster. Yarnclustermanager class (this class is in the resource managers / yarn directory in the spark source package).
After the YarnClusterManager object is created, return to the above sparkcontext In the createtaskscheduler method, it calls its cm Createtaskscheduler and cm Createtaskschedulerbackend method.
Before looking further at the source code, you should first understand the relationship between taskscheduler and SchedulerBackend. In the network communication of each component of spark (Driver, Executor and ApplicationMaster), if it is a large amount of data transmission (data shuffle), the http service of netty is used. If it is a small-scale data communication (command or information transfer between components), the rpc framework of netty is used.
TaskScudeler is responsible for task scheduling. When it wants to send rdd tasks to the Executor for execution, it does not directly communicate with the Executor, but hand them over to the scheduler backend for processing.
ok, continue to look down. The core code of YarnClusterManager class is as follows:
private[spark] class YarnClusterManager extends ExternalClusterManager {
override def canCreate(masterURL: String): Boolean = {
masterURL == "yarn"
}
override def createTaskScheduler(sc: SparkContext, masterURL: String): TaskScheduler = {
sc.deployMode match {
case "cluster" => new YarnClusterScheduler(sc)
case "client" => new YarnScheduler(sc)
case _ => throw new SparkException(s"Unknown deploy mode '${sc.deployMode}' for Yarn")
}
}
override def createSchedulerBackend(sc: SparkContext,
masterURL: String,
scheduler: TaskScheduler): SchedulerBackend = {
sc.deployMode match {
case "cluster" =>
new YarnClusterSchedulerBackend(scheduler.asInstanceOf[TaskSchedulerImpl], sc)
case "client" =>
new YarnClientSchedulerBackend(scheduler.asInstanceOf[TaskSchedulerImpl], sc)
case _ =>
throw new SparkException(s"Unknown deploy mode '${sc.deployMode}' for Yarn")
}
}
override def initialize(scheduler: TaskScheduler, backend: SchedulerBackend): Unit = {
scheduler.asInstanceOf[TaskSchedulerImpl].initialize(backend)
}
}
The createTaskScheduler method will create different TaskScheduler implementation classes according to the deployMode. Their class inheritance relationship is shown in the following figure:
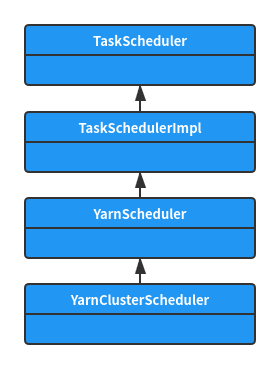
The YarnScheduler class and YarnClusterScheduler class do not have any additional core functions. All functions are implemented in the TaskSchedulerImpl class, so no analysis is made here.
The createTaskSchedulerBackend method will create different SchedulerBackend implementation classes according to the deployMode. The class relationship is shown in the following figure:
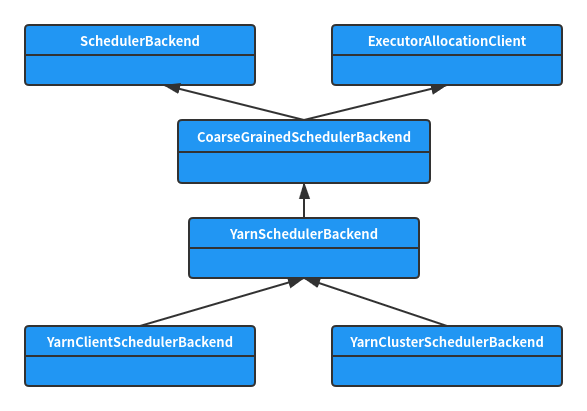
4, YarnClientSchedulerBackend and YarnClusterSchedulerBackend initialization
After analyzing SparkContext After the createtaskscheduler() method, return to the SparkContext initialization process code:
_dagScheduler = new DAGScheduler(this) _heartbeatReceiver.ask[Boolean](TaskSchedulerIsSet) _taskScheduler.start()
This method creates a DAGScheduler object, which is used to generate a task DAG diagram. Then called TaskScheduler Start() method. According to the above code analysis, the implementation subclasses of TaskScheduler are YarnScheduler and YarnClusterScheduler. Neither of these two classes has the start method of the parent class. The start method is specifically implemented in TaskShedulerImpl class:
private[spark] class TaskSchedulerImpl(
val sc: SparkContext,
val maxTaskFailures: Int,
isLocal: Boolean = false)
extends TaskScheduler with Logging {
var backend: SchedulerBackend = null
override def start() {
backend.start()
if (!isLocal && conf.getBoolean("spark.speculation", false)) {
logInfo("Starting speculative execution thread")
speculationScheduler.scheduleWithFixedDelay(new Runnable {
override def run(): Unit = Utils.tryOrStopSparkContext(sc) {
checkSpeculatableTasks()
}
}, SPECULATION_INTERVAL_MS, SPECULATION_INTERVAL_MS, TimeUnit.MILLISECONDS)
}
}
}Its backend variable is in taskschedulerimpl It is assigned in the initialize (backend: SchedulerBackend) method. According to the above analysis, the specific implementation classes of SchedulerBackend are YarnClientSchedulerBackend and YarnClusterSchedulerBackend. Calling the start method is to call the start methods of these two classes. Next, let's analyze the start methods of these two classes.
The start() method code of YarnClientSchedulerBackend class is as follows:
private[spark] class YarnClientSchedulerBackend(
scheduler: TaskSchedulerImpl,
sc: SparkContext)
extends YarnSchedulerBackend(scheduler, sc)
with Logging {
private var client: Client = null
private var monitorThread: MonitorThread = null
/**
* Create a Yarn client to submit an application to the ResourceManager.
* This waits until the application is running.
*/
override def start() {
val driverHost = conf.get("spark.driver.host")
val driverPort = conf.get("spark.driver.port")
val hostport = driverHost + ":" + driverPort
sc.ui.foreach { ui => conf.set("spark.driver.appUIAddress", ui.webUrl) }
val argsArrayBuf = new ArrayBuffer[String]()
argsArrayBuf += ("--arg", hostport)
logDebug("ClientArguments called with: " + argsArrayBuf.mkString(" "))
val args = new ClientArguments(argsArrayBuf.toArray)
totalExpectedExecutors = SchedulerBackendUtils.getInitialTargetExecutorNumber(conf)
// Initialize Client object
client = new Client(args, conf)
// Call the submitApplication() method to submit code to the yarn cluster
bindToYarn(client.submitApplication(), None)
// SPARK-8687: Ensure all necessary properties have already been set before
// we initialize our driver scheduler backend, which serves these properties
// to the executors
super.start()
// Wait for the end of the task
waitForApplication()
if (conf.contains("spark.yarn.credentials.file")) {
YarnSparkHadoopUtil.startCredentialUpdater(conf)
}
monitorThread = asyncMonitorApplication()
monitorThread.start()
}
}YarnClientSchedulerBackend. The start () method initializes the Client object and then calls the submitApplication() method to submit the task to the cluster. Remember the YarnClusterApplication class we mentioned earlier, we also initialize the Client object in the start method of this class, then we call the run() method, then we will analyze the run and submitApplication methods of the next Client class:
private[spark] class Client(val args: ClientArguments,
val sparkConf: SparkConf) extends Logging {
def run(): Unit = {
this.appId = submitApplication()
}
def submitApplication(): ApplicationId = {
var appId: ApplicationId = null
try {
launcherBackend.connect()
// Setup the credentials before doing anything else,
// so we have don't have issues at any point.
setupCredentials()
// Initialize YarnClient
yarnClient.init(hadoopConf)
// Start YarnClient
yarnClient.start()
logInfo("Requesting a new application from cluster with %d NodeManagers"
.format(yarnClient.getYarnClusterMetrics.getNumNodeManagers))
// Get a new application from our RM
val newApp = yarnClient.createApplication()
val newAppResponse = newApp.getNewApplicationResponse()
appId = newAppResponse.getApplicationId()
new CallerContext("CLIENT", sparkConf.get(APP_CALLER_CONTEXT),
Option(appId.toString)).setCurrentContext()
// Verify whether the cluster has enough resources for our AM
verifyClusterResources(newAppResponse)
// Set up the appropriate contexts to launch our AM
val containerContext = createContainerLaunchContext(newAppResponse)
val appContext = createApplicationSubmissionContext(newApp, containerContext)
// Finally, submit and monitor the application
logInfo(s"Submitting application $appId to ResourceManager")
yarnClient.submitApplication(appContext)
launcherBackend.setAppId(appId.toString)
reportLauncherState(SparkAppHandle.State.SUBMITTED)
appId
} catch {
case e: Throwable =>
if (appId != null) {
cleanupStagingDir(appId)
}
throw e
}
}
}This method first calls the init and start methods of the yarnClient object, and then calls yarnClient The createapplication method creates an application on the yarn cluster. The method returns a YarnClientApplication object, which contains two important things:
- 1) applicationId
- 2) ApplicationSubmissionContext object
The core code of createrConainerLuanchContext() method is as follows:
private def createContainerLaunchContext(newAppResponse: GetNewApplicationResponse)
: ContainerLaunchContext = {
logInfo("Setting up container launch context for our AM")
val appId = newAppResponse.getApplicationId
val launchEnv = setupLaunchEnv(appStagingDirPath, pySparkArchives)
val localResources = prepareLocalResources(appStagingDirPath, pySparkArchives)
val amContainer = Records.newRecord(classOf[ContainerLaunchContext])
amContainer.setLocalResources(localResources.asJava)
amContainer.setEnvironment(launchEnv.asJava)
val userClass =
if (isClusterMode) {
Seq("--class", YarnSparkHadoopUtil.escapeForShell(args.userClass))
} else {
Nil
}
val amClass =
if (isClusterMode) {
Utils.classForName("org.apache.spark.deploy.yarn.ApplicationMaster").getName
} else {
Utils.classForName("org.apache.spark.deploy.yarn.ExecutorLauncher").getName
}
val amArgs =
Seq(amClass) ++ userClass ++ userJar ++ primaryPyFile ++ primaryRFile ++ userArgs ++
Seq("--properties-file", buildPath(Environment.PWD.$$(), LOCALIZED_CONF_DIR, SPARK_CONF_FILE))
// Command for the ApplicationMaster
val commands = prefixEnv ++
Seq(Environment.JAVA_HOME.$$() + "/bin/java", "-server") ++
javaOpts ++ amArgs ++
Seq(
"1>", ApplicationConstants.LOG_DIR_EXPANSION_VAR + "/stdout",
"2>", ApplicationConstants.LOG_DIR_EXPANSION_VAR + "/stderr")
// TODO: it would be nicer to just make sure there are no null commands here
val printableCommands = commands.map(s => if (s == null) "null" else s).toList
amContainer.setCommands(printableCommands.asJava)
amContainer
}The createrConainerLuanchContext method is used to create an abstract application master} container description, that is, to tell yarn how to start the am} process. The prepareLocalResources() method is used to prepare the jar packages and resources that the task depends on. It will_ All jars in the home / jars directory are uploaded to hdfs and downloaded when the Executor process is running.
Next, look down and create several key parameters:
- userClass: if it is a cluster deployment mode, the -- class parameter value specified for the user. If it is in client mode, it is empty, because in client mode, userClass has been started first.
- amClass: the main class that starts the Application Master process. If it is in cluster mode, it is ApplicationMaster; If it is client mode, it is ExecutorLuancher. What is the difference between the two classes? It will be analyzed below.
Finally, the parameters are spliced to obtain a commands object, which is a java startup command. The content is roughly as follows:
java -server -jar xxx -Xms xxx ApplicationMaster --class xxx
The createApplicationSubmissionContext() method is used to create a task submission environment, including specifying appName, task queue, appType, etc. its core code is as follows:
def createApplicationSubmissionContext(
newApp: YarnClientApplication,
containerContext: ContainerLaunchContext): ApplicationSubmissionContext = {
val appContext = newApp.getApplicationSubmissionContext
appContext.setApplicationName(sparkConf.get("spark.app.name", "Spark"))
appContext.setQueue(sparkConf.get(QUEUE_NAME))
appContext.setAMContainerSpec(containerContext)
appContext.setApplicationType("SPARK")
sparkConf.get(APPLICATION_TAGS).foreach { tags =>
appContext.setApplicationTags(new java.util.HashSet[String](tags.asJava))
}
sparkConf.get(MAX_APP_ATTEMPTS) match {
case Some(v) => appContext.setMaxAppAttempts(v)
case None => logDebug(s"${MAX_APP_ATTEMPTS.key} is not set. " +
"Cluster's default value will be used.")
}
sparkConf.get(AM_ATTEMPT_FAILURE_VALIDITY_INTERVAL_MS).foreach { interval =>
appContext.setAttemptFailuresValidityInterval(interval)
}
val capability = Records.newRecord(classOf[Resource])
capability.setMemory(amMemory + amMemoryOverhead)
capability.setVirtualCores(amCores)
sparkConf.get(AM_NODE_LABEL_EXPRESSION) match {
case Some(expr) =>
val amRequest = Records.newRecord(classOf[ResourceRequest])
amRequest.setResourceName(ResourceRequest.ANY)
amRequest.setPriority(Priority.newInstance(0))
amRequest.setCapability(capability)
amRequest.setNumContainers(1)
amRequest.setNodeLabelExpression(expr)
appContext.setAMContainerResourceRequest(amRequest)
case None =>
appContext.setResource(capability)
}
appContext
}After the appContext object is created, the following code is used to submit the application:
// Finally, submit and monitor the application logInfo(s"Submitting application $appId to ResourceManager") yarnClient.submitApplication(appContext) launcherBackend.setAppId(appId.toString)
So far, the yarn task submission function has been completed. Let's look back at the start method of the YarnClusterSchedulerBackend class:
private[spark] class YarnClusterSchedulerBackend(
scheduler: TaskSchedulerImpl,
sc: SparkContext)
extends YarnSchedulerBackend(scheduler, sc) {
override def start() {
val attemptId = ApplicationMaster.getAttemptId
bindToYarn(attemptId.getApplicationId(), Some(attemptId))
super.start()
totalExpectedExecutors = SchedulerBackendUtils.getInitialTargetExecutorNumber(sc.conf)
}
}This method has no special work, because in the cluster mode, the client has been called first The run () method completes the task submission.
5, ApplicationMaster startup
Through the previous code analysis, we know that when the deployment mode is cluster, the class started is ApplicationMaster class, and when the mode is client, the class started is ExecutorLauncher class. Before looking at the code, we should first understand that, ApplicationMaster is in the master process (yarn is assigned to a container of the application program, which is specially used to run the application master). The specified ApplicationMaster class and ExecutorLauncher class are of object type and are located in the ApplicationMaster.scala file. There is also an ApplicationMaster of class type in the file. The structure is as follows:
private[spark] class ApplicationMaster(args: ApplicationMasterArguments) extends Logging {
}
object ApplicationMaster extends Logging {
}
object ExecutorLauncher {
}
The main() method codes of ApplicationMaster and executorlauncher objects are as follows:
object ApplicationMaster extends Logging {
private var master: ApplicationMaster = _
def main(args: Array[String]): Unit = {
SignalUtils.registerLogger(log)
val amArgs = new ApplicationMasterArguments(args)
master = new ApplicationMaster(amArgs)
System.exit(master.run())
}
}
/**
* This object does not provide any special functionality. It exists so that it's easy to tell
* apart the client-mode AM from the cluster-mode AM when using tools such as ps or jps.
*/
object ExecutorLauncher {
def main(args: Array[String]): Unit = {
ApplicationMaster.main(args)
}
}ExecutorLauncher. The main () method actually calls applicationmaster The main () method goes to new ApplicationMaster(amArgs) and then calls the run() method. So here comes the question...? What is the meaning of this executorlauncher? The answer is that it only serves as a marker to distinguish the deployment mode by starting different main classes when using ps or jps commands.
Next, let's look at the run() method of the ApplicationMaster class:
private[spark] class ApplicationMaster(args: ApplicationMasterArguments) extends Logging {
private val isClusterMode = args.userClass != null
private val sparkConf = new SparkConf()
if (args.propertiesFile != null) {
Utils.getPropertiesFromFile(args.propertiesFile).foreach { case (k, v) =>
sparkConf.set(k, v)
}
}
private val client = doAsUser { new YarnRMClient()
final def run(): Int = {
doAsUser {
runImpl()
}
exitCode
}
private def runImpl(): Unit = {
try {
val appAttemptId = client.getAttemptId()
var attemptID: Option[String] = None
if (isClusterMode) {
runDriver()
} else {
runExecutorLauncher()
}
} catch {
case e: Exception =>
// catch everything else if not specifically handled
logError("Uncaught exception: ", e)
finish(FinalApplicationStatus.FAILED,
ApplicationMaster.EXIT_UNCAUGHT_EXCEPTION,
"Uncaught exception: " + e)
}
}
}The run() method calls the runImpl() method. runImpl() will call different methods according to the value of isClusterMode variable. The judgment basis of this value is:
private val isClusterMode = args.userClass != null
If it is in client mode, the runExecutorLauncher method will be called; if it is in cluster mode, the runDriver method will be called. First, analyze the runDriver method in cluster mode. The code is as follows:
private def runDriver(): Unit = {
addAmIpFilter(None)
userClassThread = startUserApplication()
// This a bit hacky, but we need to wait until the spark.driver.port property has
// been set by the Thread executing the user class.
logInfo("Waiting for spark context initialization...")
val totalWaitTime = sparkConf.get(AM_MAX_WAIT_TIME)
try {
val sc = ThreadUtils.awaitResult(sparkContextPromise.future,
Duration(totalWaitTime, TimeUnit.MILLISECONDS))
if (sc != null) {
rpcEnv = sc.env.rpcEnv
val driverRef = createSchedulerRef(
sc.getConf.get("spark.driver.host"),
sc.getConf.get("spark.driver.port"))
registerAM(sc.getConf, rpcEnv, driverRef, sc.ui.map(_.webUrl))
registered = true
} else {
// Sanity check; should never happen in normal operation, since sc should only be null
// if the user app did not create a SparkContext.
throw new IllegalStateException("User did not initialize spark context!")
}
resumeDriver()
userClassThread.join()
} catch {
case e: SparkException if e.getCause().isInstanceOf[TimeoutException] =>
logError(
s"SparkContext did not initialize after waiting for $totalWaitTime ms. " +
"Please check earlier log output for errors. Failing the application.")
finish(FinalApplicationStatus.FAILED,
ApplicationMaster.EXIT_SC_NOT_INITED,
"Timed out waiting for SparkContext.")
} finally {
resumeDriver()
}
}It will first call the startUserApplication() method to start the user program and return a userClassThread. After much effort, we finally found the entry to start the user program mainClass. The code is as follows:
private def startUserApplication(): Thread = {
logInfo("Starting the user application in a separate Thread")
var userArgs = args.userArgs
if (args.primaryPyFile != null && args.primaryPyFile.endsWith(".py")) {
// When running pyspark, the app is run using PythonRunner. The second argument is the list
// of files to add to PYTHONPATH, which Client.scala already handles, so it's empty.
userArgs = Seq(args.primaryPyFile, "") ++ userArgs
}
if (args.primaryRFile != null && args.primaryRFile.endsWith(".R")) {
// TODO(davies): add R dependencies here
}
val mainMethod = userClassLoader.loadClass(args.userClass)
.getMethod("main", classOf[Array[String]])
val userThread = new Thread {
override def run() {
try {
mainMethod.invoke(null, userArgs.toArray)
finish(FinalApplicationStatus.SUCCEEDED, ApplicationMaster.EXIT_SUCCESS)
logDebug("Done running users class")
} catch {
case e: InvocationTargetException =>
e.getCause match {
case _: InterruptedException =>
// Reporter thread can interrupt to stop user class
case SparkUserAppException(exitCode) =>
val msg = s"User application exited with status $exitCode"
logError(msg)
finish(FinalApplicationStatus.FAILED, exitCode, msg)
case cause: Throwable =>
logError("User class threw exception: " + cause, cause)
finish(FinalApplicationStatus.FAILED,
ApplicationMaster.EXIT_EXCEPTION_USER_CLASS,
"User class threw exception: " + StringUtils.stringifyException(cause))
}
sparkContextPromise.tryFailure(e.getCause())
} finally {
// Notify the thread waiting for the SparkContext, in case the application did not
// instantiate one. This will do nothing when the user code instantiates a SparkContext
// (with the correct master), or when the user code throws an exception (due to the
// tryFailure above).
sparkContextPromise.trySuccess(null)
}
}
}
userThread.setContextClassLoader(userClassLoader)
userThread.setName("Driver")
userThread.start()
userThread
}This method first creates a separate thread, uses classloader to load the mainClass specified by the user in this thread, and then calls its main() method.
Returning to the runDriver() method, this method calls the registerAM() method to tell the yarn cluster that the applicationmaster process has started. This method is analyzed below.
Go back to applicationmaster Runimpl() method, which determines that if it is in client mode, it will call the runExecutorLauncher() method. The code is as follows:
private def runExecutorLauncher(): Unit = {
val hostname = Utils.localHostName
val amCores = sparkConf.get(AM_CORES)
rpcEnv = RpcEnv.create("sparkYarnAM", hostname, hostname, -1, sparkConf, securityMgr,
amCores, true)
val driverRef = waitForSparkDriver()
addAmIpFilter(Some(driverRef))
registerAM(sparkConf, rpcEnv, driverRef, sparkConf.getOption("spark.driver.appUIAddress"))
registered = true
// In client mode the actor will stop the reporter thread.
reporterThread.join()
}The code of the runExecutorLauncher() method is much simpler. It first calls rpcenv The Create method creates the rpcEnv variable and then calls the waitForSparkDriver() method to communicate with the Driver process. Then it will call the registerAM() method to register the master with the yarn cluster. The method code is as follows:
private def registerAM(
_sparkConf: SparkConf,
_rpcEnv: RpcEnv,
driverRef: RpcEndpointRef,
uiAddress: Option[String]) = {
allocator = client.register(driverUrl,
driverRef,
yarnConf,
_sparkConf,
uiAddress,
historyAddress,
securityMgr,
localResources)
// Initialize the AM endpoint *after* the allocator has been initialized. This ensures
// that when the driver sends an initial executor request (e.g. after an AM restart),
// the allocator is ready to service requests.
rpcEnv.setupEndpoint("YarnAM", new AMEndpoint(rpcEnv, driverRef))
allocator.allocateResources()
reporterThread = launchReporterThread()
}Method calls client Regsiter() (this client object is an instance of the YarnRMClient class). The code is as follows:
private[spark] class YarnRMClient extends Logging {
def register(
driverUrl: String,
driverRef: RpcEndpointRef,
conf: YarnConfiguration,
sparkConf: SparkConf,
uiAddress: Option[String],
uiHistoryAddress: String,
securityMgr: SecurityManager,
localResources: Map[String, LocalResource]
): YarnAllocator = {
amClient = AMRMClient.createAMRMClient()
amClient.init(conf)
amClient.start()
this.uiHistoryAddress = uiHistoryAddress
val trackingUrl = uiAddress.getOrElse {
if (sparkConf.get(ALLOW_HISTORY_SERVER_TRACKING_URL)) uiHistoryAddress else ""
}
logInfo("Registering the ApplicationMaster")
synchronized {
amClient.registerApplicationMaster(Utils.localHostName(), 0, trackingUrl)
registered = true
}
new YarnAllocator(driverUrl, driverRef, conf, sparkConf, amClient, getAttemptId(), securityMgr,
localResources, new SparkRackResolver())
}
}
This method calls the method of the AMRMClient class of yarn itself, registers the applicationMaster, and then returns a YarnAllocator object.
After returning the YarnAllocator object, first call the allocateResources() method to apply for resources from yarn. The allocateResources() method code is as follows:
def allocateResources(): Unit = synchronized {
updateResourceRequests()
val progressIndicator = 0.1f
// Poll the ResourceManager. This doubles as a heartbeat if there are no pending container
// requests.
val allocateResponse = amClient.allocate(progressIndicator)
val allocatedContainers = allocateResponse.getAllocatedContainers()
if (allocatedContainers.size > 0) {
logDebug(("Allocated containers: %d. Current executor count: %d. " +
"Launching executor count: %d. Cluster resources: %s.")
.format(
allocatedContainers.size,
runningExecutors.size,
numExecutorsStarting.get,
allocateResponse.getAvailableResources))
handleAllocatedContainers(allocatedContainers.asScala)
}
val completedContainers = allocateResponse.getCompletedContainersStatuses()
if (completedContainers.size > 0) {
logDebug("Completed %d containers".format(completedContainers.size))
processCompletedContainers(completedContainers.asScala)
logDebug("Finished processing %d completed containers. Current running executor count: %d."
.format(completedContainers.size, runningExecutors.size))
}
}The allocateResources() method calls the allocate method of AMRMClient class to apply for resources from the yarn cluster (the number of applied resources is determined by the parameters specified when submitting the task -- executor memory, - executor cores, etc.). This method returns the allocateResonse object, which contains two types of containers: the newly allocated container and the container that has completed the task. However, yarn may not be able to return all the required number of containers at one time, so the code reporterThread = launchReporterThread() at the end of the registerAM() method solves this problem by calling the allocateResources method in a loop. The code is as follows:
private def launchReporterThread(): Thread = {
// The number of failures in a row until Reporter thread give up
val reporterMaxFailures = sparkConf.get(MAX_REPORTER_THREAD_FAILURES)
val t = new Thread {
override def run() {
var failureCount = 0
while (!finished) {
try {
if (allocator.getNumExecutorsFailed >= maxNumExecutorFailures) {
finish(FinalApplicationStatus.FAILED,
ApplicationMaster.EXIT_MAX_EXECUTOR_FAILURES,
s"Max number of executor failures ($maxNumExecutorFailures) reached")
} else {
logDebug("Sending progress")
allocator.allocateResources()
}
failureCount = 0
} catch {
case i: InterruptedException => // do nothing
case e: ApplicationAttemptNotFoundException =>
failureCount += 1
logError("Exception from Reporter thread.", e)
finish(FinalApplicationStatus.FAILED, ApplicationMaster.EXIT_REPORTER_FAILURE,
e.getMessage)
case e: Throwable =>
failureCount += 1
if (!NonFatal(e) || failureCount >= reporterMaxFailures) {
finish(FinalApplicationStatus.FAILED,
ApplicationMaster.EXIT_REPORTER_FAILURE, "Exception was thrown " +
s"$failureCount time(s) from Reporter thread.")
} else {
logWarning(s"Reporter thread fails $failureCount time(s) in a row.", e)
}
}
try {
val numPendingAllocate = allocator.getPendingAllocate.size
var sleepStart = 0L
var sleepInterval = 200L // ms
allocatorLock.synchronized {
sleepInterval =
if (numPendingAllocate > 0 || allocator.getNumPendingLossReasonRequests > 0) {
val currentAllocationInterval =
math.min(heartbeatInterval, nextAllocationInterval)
nextAllocationInterval = currentAllocationInterval * 2 // avoid overflow
currentAllocationInterval
} else {
nextAllocationInterval = initialAllocationInterval
heartbeatInterval
}
sleepStart = System.currentTimeMillis()
allocatorLock.wait(sleepInterval)
}
val sleepDuration = System.currentTimeMillis() - sleepStart
if (sleepDuration < sleepInterval) {
// log when sleep is interrupted
logDebug(s"Number of pending allocations is $numPendingAllocate. " +
s"Slept for $sleepDuration/$sleepInterval ms.")
// if sleep was less than the minimum interval, sleep for the rest of it
val toSleep = math.max(0, initialAllocationInterval - sleepDuration)
if (toSleep > 0) {
logDebug(s"Going back to sleep for $toSleep ms")
// use Thread.sleep instead of allocatorLock.wait. there is no need to be woken up
// by the methods that signal allocatorLock because this is just finishing the min
// sleep interval, which should happen even if this is signalled again.
Thread.sleep(toSleep)
}
} else {
logDebug(s"Number of pending allocations is $numPendingAllocate. " +
s"Slept for $sleepDuration/$sleepInterval.")
}
} catch {
case e: InterruptedException =>
}
}
}
}
// setting to daemon status, though this is usually not a good idea.
t.setDaemon(true)
t.setName("Reporter")
t.start()
logInfo(s"Started progress reporter thread with (heartbeat : $heartbeatInterval, " +
s"initial allocation : $initialAllocationInterval) intervals")
t
}6, Spark on Yan task submission process summary
1. The program entry class is SparkSubmit, which will run different main classes according to the submission parameter -- deploy mode.
2. In the client mode, create a JavaMainApplication object and call the start method. The start method runs the mainClass specified by the -- class parameter through reflection call. In the cluster mode, create the YarnClusterApplication object, create the client object in the start method, and call its run method, which calls the submitApplication method to complete the task submission.
In the 3. client mode, we run the user mainClass and initialize the SparkContext object. During the initialization of the object, we create the instance subclass TaskSchedulerImpl of the TaskSchduler, the instance subclass YarnClientSchedulerBackend and YarnClusterSchedulerBackend class of SchedulerBackend, and then call the start methods of the two classes.
4. The start method of YarnClientSchedulerBackend initializes the Client object and calls its sumbitApplication() method.
5. the Client class submitAppliation method initializes the YarnClient object first and then calls api to complete the task submission. The client mode specifies that the main class of the master process is ExecutorLauncher, and the main class of the cluster mode is ApplicationMaster. ExecutorLauncher is just a tag class. In fact, it also calls the run method of the ApplicationMaster class.
6. The applicationmaster class runs in the master process. Its run method will judge whether it is in the client or cluster mode. If it is in the client mode, it will call the registerAm() method to register its own information with yarn; If it is in cluster mode, a separate thread will be started, the user program mainClass code will be run, and then the registerAm() method will be called to register.