In order to introduce these two mechanisms, here we write an operation to realize Pi. Here, we only need to calculate the probability ratio of the point falling in the circle to the point falling in the square
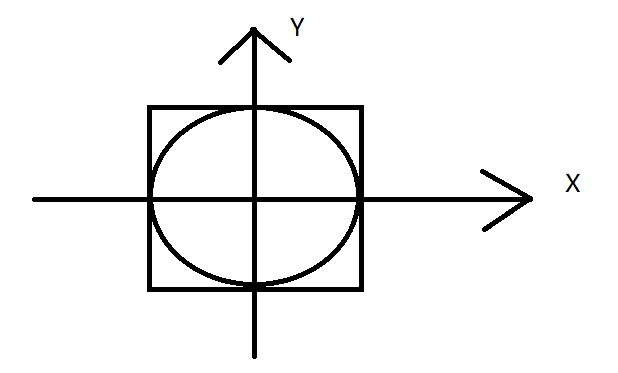
Here we highlight
slices indicates how many tasks are generated
cnt indicates how many points are generated in each task
For the number of tasks here, we will create a task every time we calculate, which leads to a very large number of files to be processed. Here, we can appropriately reduce the number of slices and increase the number of CNTs to improve the calculation efficiency; Although the number of points to be calculated is the same, the efficiency is completely different
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local")
conf.setAppName("Demo6Pi")
val sc = new SparkContext(conf)
//This is a random number between 0 and 1
// println(Random.nextDouble())
//slices indicates how many tasks are generated, and cnt indicates how many points are generated in each task
val slices = 100
val cnt = 10000
//parallelize supports passing in a parameter numSlices, which is consistent with the parallelism by default and can be specified manually, indicating the number of RDD partitions generated at last
//Finally, the number of task s will be determined
val seqRDD: RDD[Int] = sc.parallelize(0 to cnt*slices,slices)
//Here, N points between [- 1,1] are randomly generated
val pointRDD: RDD[(Double, Double)] = seqRDD.map(seq => {
val x: Double = Random.nextDouble() * 2 - 1
val y: Double = Random.nextDouble() * 2 - 1
(x, y)
})
//Filter out the points in the circle from these points
val circlePointNum: Long = pointRDD.filter(
(kv) => {
val x: Double = kv._1
val y: Double = kv._2
val res: Double = x * x + y * y
res <= 1
}
).count()
println(circlePointNum)
val pi: Double = circlePointNum.toDouble/ (cnt * slices) * 4
println(pi)
}
Cache - > improve efficiency
Our cache is cached in the Executor, which has CPU and memory, and the program runs in the Executor
Why use cache
Before we added cache, the spark task we ran was no different from mapreduce. It was both map and reduce. Although it was classified as stage in spark, the principle was both map and reduce, mixed with shuffle
Here we calculate the number of students in each class and the overall number of gender
val conf: SparkConf = new SparkConf()
.setMaster("local")
.setAppName("Demo16Cache")
val sc: SparkContext = new SparkContext(conf)
val stuRDD: RDD[String] = sc.textFile("D:\\BigDaTa\\JAVA_Project\\ShuJia01\\data\\students.txt")
//Count the number of classes
stuRDD.map(line=>{
val strings: Array[String] = line.split(",")
(strings(4),1)
}).reduceByKey(_+_)
.foreach(println)
//Gender Statistics
stuRDD.map(line=>{
val strings: Array[String] = line.split(",")
(strings(3),1)
}).reduceByKey(_+_)
.foreach(println)
We can find that stuRDD is repeatedly called by us
How can we see that it is repeatedly called? We make some minor adjustments. For the stuRDD reading data, we use a map method, and each time we use it, we add a print
val conf: SparkConf = new SparkConf()
.setMaster("local")
.setAppName("Demo16Cache")
val sc: SparkContext = new SparkContext(conf)
val stuRDD: RDD[String] = sc.textFile("D:\\BigDaTa\\JAVA_Project\\ShuJia01\\data\\students.txt")
val stuRDDMap: RDD[String] = stuRDD.map(stu => {
println("stuRDD")
stu
})
// stuRDDMap.cache()
//Count the number of classes
stuRDDMap.map(line=>{
val strings: Array[String] = line.split(",")
(strings(4),1)
}).reduceByKey(_+_)
.foreach(println)
//Gender Statistics
stuRDDMap.map(line=>{
val strings: Array[String] = line.split(",")
(strings(3),1)
}).reduceByKey(_+_)
.foreach(println)
As a result, we can find that "stuRDD" is printed twice when printing data (one student data and one gender data),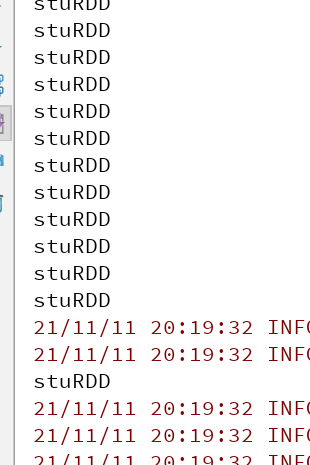
Therefore, we can find that stuRDD is called twice every time the data is read and used
Every time you do a calculation, you need to repeatedly fetch data from HDFS, load it into stuRDD, and then pull it for calculation. This is not in line with the calculation characteristics of spark
See this blog
The reason why spark has fast calculation speed is that it does not need to repeatedly fetch data for calculation. Therefore, here, we can make a cache of the data. Each time we take this score for use, we do not need to repeatedly select from HDFS
When a piece of data is fetched multiple times, it does not need to be read repeatedly (repeated reading is no different from mapreduce)
Cache cache
We can cache RDD S that are used multiple times
val conf: SparkConf = new SparkConf()
.setMaster("local")
.setAppName("Demo16Cache")
val sc: SparkContext = new SparkContext(conf)
val stuRDD: RDD[String] = sc.textFile("D:\\BigDaTa\\JAVA_Project\\ShuJia01\\data\\students.txt")
val stuRDDMap: RDD[String] = stuRDD.map(stu => {
println("stuRDD")
stu
})
stuRDDMap.cache()
//Count the number of classes
stuRDDMap.map(line=>{
val strings: Array[String] = line.split(",")
(strings(4),1)
}).reduceByKey(_+_)
.foreach(println)
//Gender Statistics
stuRDDMap.map(line=>{
val strings: Array[String] = line.split(",")
(strings(3),1)
}).reduceByKey(_+_)
.foreach(println)
After running here, we found that "stuRDD" was printed only once while printing a class result and a number of sex people
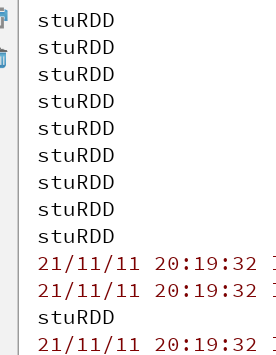
Level of cache
We can see that the cache calls the persist method by default

Click persist, and we can see that a MEMORY_ONLY is given by default

Click StorageLevel and we can see that there are many caching mechanisms by default
The difference between cache and persist

We can see that both cache and persist can be used as cache by default, but cache can only use MEMORY_ONLY by default, that is, the strategy based on memory cache, and persist can give many different cache strategies
Selection of cache policy

In here
DISK_ONLY refers to disk based storage cache
MEMORY_ONLY refers to memory based storage cache
The meaning of SER added later is whether compression is required
Adding 2 means whether backup is required
1. When the data is small and the memory is sufficient
Select MEMORY_ONLY
2. When the amount of data is a little large and the memory cannot be completely put down
Select MEMORY_AND_DISK_SER
Cache data into memory as much as possible, which is the most efficient
unpersist release cache
We also have sparkstreaming in spark. Data is read in continuously. If we keep caching, memory overflow will occur sooner or later. At this time, we need to release the cache
When the cache is not used, the cache is released
Checkpoint - > fault tolerance
Persistence, HDFS does not hang, it does not hang
We have learned from the above that the data cached in the cache is in the Executor, but the Executor may hang. Once hung, our data will disappear and need to be recalculated;
At this time, we can write the cached data to HDFS, but the efficiency will be reduced. This method can be used for fault tolerance
Here we just need to do these two steps

However, the cache here outputs "stuRDD" twice, which is related to the working mechanism of our checkpoint
Principle of checkpoint
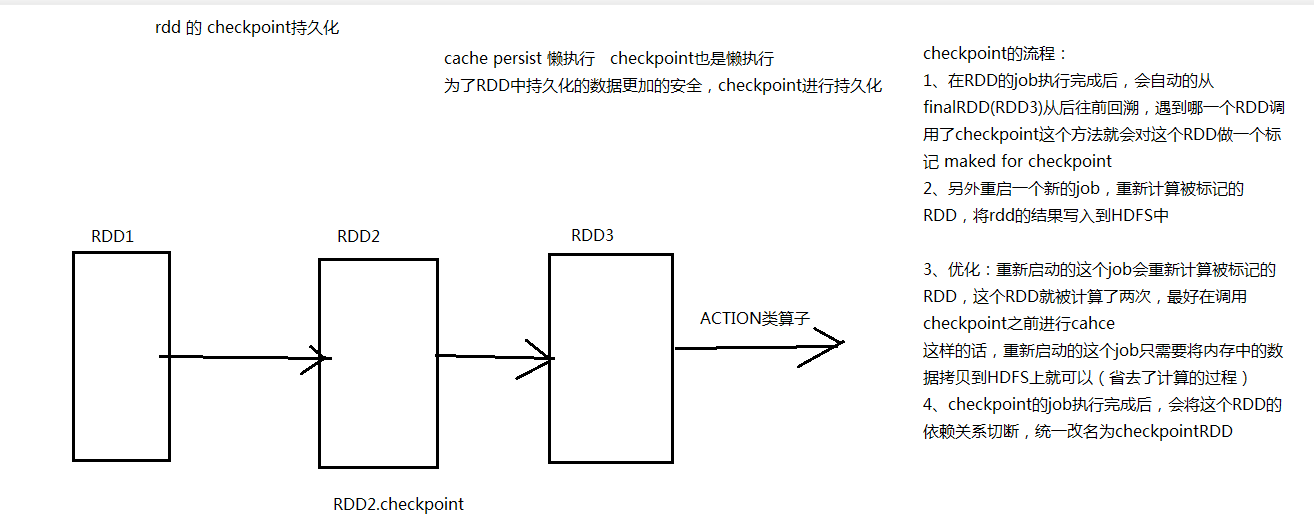
1. First calculate from front to back, and make a mark for which checkpoint is needed
2. Restart a new job, recalculate it, and write the marked rdd to HDFS
Our cache writes the rdd that needs to be cached directly into memory after it encounters it
optimization
It is better to use the cache once before calling the checkpoint. In this way, the restarted job only needs to copy the data in memory to HDFS, so the calculation process can be omitted
After the job execution of the checkpoint is completed, the RDD dependency will be cut off
Therefore, cache is mainly used to improve efficiency and checkpoint is mainly used for fault tolerance
Thank you for reading. I am shuaihe, a senior majoring in big data. I wish you happiness.