Overall framework
Spark storage adopts master-slave mode, i.e. Master / Slave mode. The whole enclosure uses RPC message communication mode. Of which:
- The Master is responsible for the management and maintenance of data block metadata during the operation of the whole application
- Slave is responsible for reporting the status information of the local data block to the Master on the one hand, and receiving the execution command from the Master on the other hand. Such as obtaining data block status, deleting RDD / data block and other commands. Each slave has a data transmission channel, which can read and write remote data between the slave as needed.
The overall framework of Spark storage is as follows:
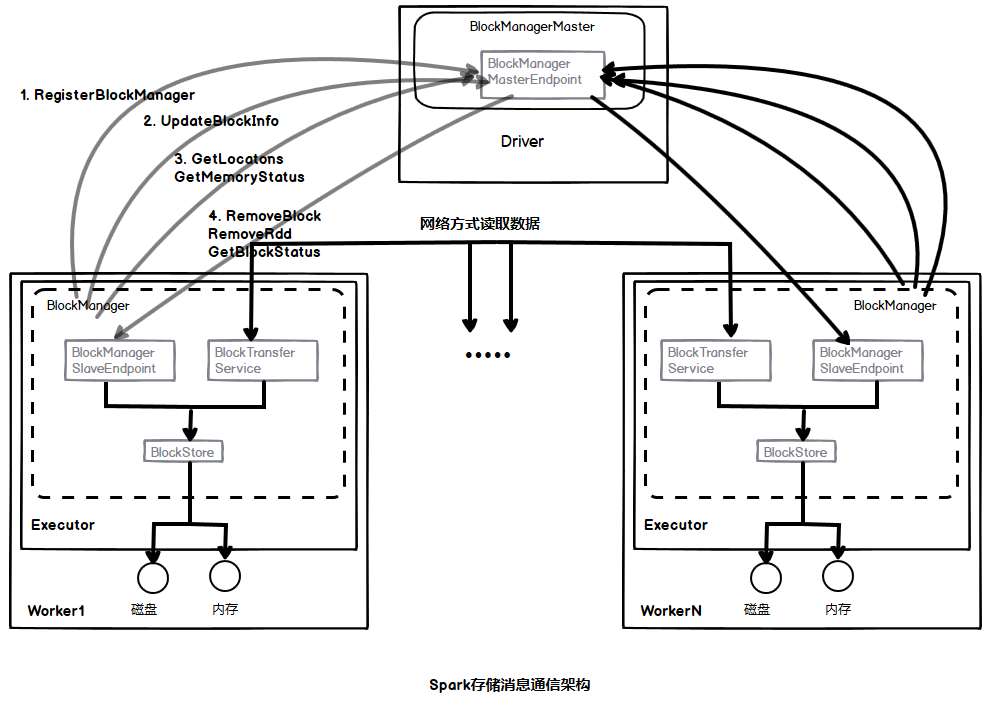
According to the overall framework diagram of Spark storage, the following will analyze the communication process according to the messages in the data life cycle.
(1) When the application starts, the SparkContext will create the SparkEnv on the Driver side, instantiate the BlockManager and BlockManagerMaster in the SparkEnv, and create the terminal point BlockManagerMasterEndpoint for message communication within the BlockManagerMaster.
When the Executor starts, its SparkEnv will also be created, and the BlockManager and BlockTransferService responsible for network data transmission services will be instantiated in the SparkEnv. In the process of BlockManager initialization, on the one hand, the reference of BlockManagerMasterEndpoint terminal point will be added, on the other hand, the BlockManagerSlaveEndpoint terminal point for Executor message communication will be created, and the reference of the terminal point will be registered in the Driver, so that the Driver and Executor hold the reference of communication terminal point, Message communication can be carried out during the execution of the application sequence.
The specific implementation code is as follows:
def registerOrLookupEndpoint(name: String, endpointCreator: => RpcEndpoint): RpcEndpointRef = {
...
//Create a remote data transmission service using Netty mode
val blockTransferService =
new NettyBlockTransferService(conf, securityManager, bindAddress, advertiseAddress,
blockManagerPort, numUsableCores)
//Create a blockManagerMaster. If the Driver side is inside the blockManagerMaster, create a terminal point BlockManagerMasterEndpoint
//If it is an Executor, a reference to BlockManagerMasterEndpoint is created
val blockManagerMaster = new BlockManagerMaster(registerOrLookupEndpoint(
BlockManagerMaster.DRIVER_ENDPOINT_NAME,
new BlockManagerMasterEndpoint(rpcEnv, isLocal, conf, listenerBus)),
conf, isDriver)
//Create a blockManager. If the Driver side contains a blockManagerMaster, if the executor contains a blockManagerMaster
//In addition, the blockmanager contains the remote data transmission service, which takes effect only when the blockmanager calls the initialize() method
val blockManager = new BlockManager(executorId, rpcEnv, blockManagerMaster,
serializerManager, conf, memoryManager, mapOutputTracker, shuffleManager,
blockTransferService, securityManager, numUsableCores)
...
}
The initialization of BlockManager calling initialize() method is as follows:
def initialize(appId: String): Unit = {
//Start the remote data transmission service in the Executor, and start the transmission server blockTransferService according to the configuration,
//After the server starts, it waits for other nodes to send request messages
blockTransferService.init(this)
shuffleClient.init(appId)
blockReplicationPolicy = {
val priorityClass = conf.get(
"spark.storage.replication.policy", classOf[RandomBlockReplicationPolicy].getName)
val clazz = Utils.classForName(priorityClass)
val ret = clazz.newInstance.asInstanceOf[BlockReplicationPolicy]
logInfo(s"Using $priorityClass for block replication policy")
ret
}
//Get blockManager number
val id =
BlockManagerId(executorId, blockTransferService.hostName, blockTransferService.port, None)
val idFromMaster = master.registerBlockManager(
id,
maxOnHeapMemory,
maxOffHeapMemory,
slaveEndpoint)
blockManagerId = if (idFromMaster != null) idFromMaster else id
//Get the shuffle service number. If the external shuffle service is started, add the external shuffle service port information,
//Otherwise, use the blockManager number
shuffleServerId = if (externalShuffleServiceEnabled) {
logInfo(s"external shuffle service port = $externalShuffleServicePort")
BlockManagerId(executorId, blockTransferService.hostName, externalShuffleServicePort)
} else {
blockManagerId
}
//If the external shuffle service is started and is an executor node, it is registered as an external shuffle service
if (externalShuffleServiceEnabled && !blockManagerId.isDriver) {
registerWithExternalShuffleServer()
}
logInfo(s"Initialized BlockManager: $blockManagerId")
}
(2) After writing, updating or deleting data, the latest status message UpdateBlockinfo of the data block is sent to the BlockManagerMasterEndpoint terminal point, which updates the metadata of the data block. The metadata of the terminal point is stored in three hashmaps of BlockManagerMasterEndpoint, as follows:
class BlockManagerMasterEndpoint(override val rpcEnv: RpcEnv,val isLocal: Boolean,conf: SparkConf,listenerBus: LiveListenerBus)
extends ThreadSafeRpcEndpoint with Logging {
...
//The HashMap stores the correspondence between BlockManagerId and BlockManagerInfo, where BlockManagerInfo
//It includes the memory usage of the executor, the usage of data blocks, cached data blocks and references to the executor terminal point
private val blockManagerInfo = new mutable.HashMap[BlockManagerId, BlockManagerInfo]
//The HashMap stores the corresponding list of BlockManagerId and executorId
private val blockManagerIdByExecutor = new mutable.HashMap[String, BlockManagerId]
//The HashMap stores the list corresponding to the BlockManagerId and BlockId sequence because a data block may store
//Multiple copies, saved in multiple executor s
private val blockLocations = new JHashMap[BlockId, mutable.HashSet[BlockManagerId]]
...
}
(3) After the application data is stored, when obtaining the remote node data and the preferred location for RDD execution, you need to query the location of the data block according to the number of the data block. At this time, send messages such as GetLocations or getlocationsmompleblocks to the BlockManagerMasterEndpoint terminal point to obtain the location information of the data block through metadata query.
The code implementation is as follows:
private def getLocations(blockId: BlockId): Seq[BlockManagerId] = {
//Judge whether the data block is included according to the blockId. If so, return its corresponding BlockManagerId sequence
if (blockLocations.containsKey(blockId)) blockLocations.get(blockId).toSeq
else Seq.empty
}
(4) Spark provides ways to delete RDDS, data blocks and broadcast variables. When the data needs to be deleted, submit a deletion message to the BlockManagerSlaveEndpoint terminal point, where the deletion operation is initiated. On the one hand, the Driver metadata information needs to be deleted, on the other hand, a message needs to be sent to inform the Executor to delete the corresponding physical data. The deletion process of RDD is described below with the unpersistRDD method of RDD. The class call diagram is as follows:
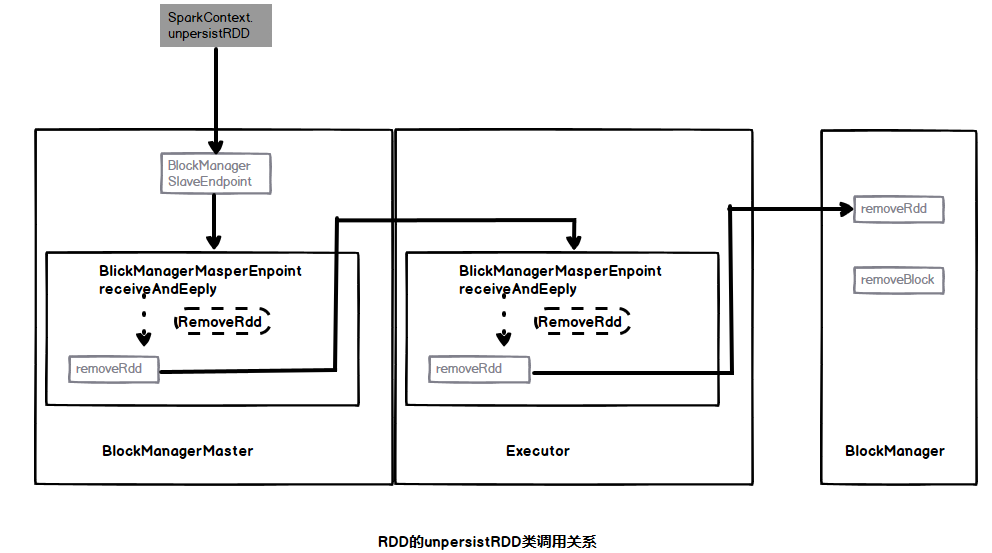
First, the unpersistRDD method is invoked in SparkConext, and the removeRdd message is sent to the BlockManagerMasterEndpoint terminal point in the method. Then, when receiving the message, the terminal point finds out that the data corresponding to the ROD exists in the BlockManagerld list from the blockLocations list, and updates the blockLocations and blockManagerlnfo metadata lists after the query; Then, send a message to the BlockManagerSlaveEndpoint terminal point to notify it to delete the RDD on the Executor. When deleting, call the removedd method of BlockManager to delete the data block corresponding to the RDD on the Executor. The removedd code of the blockmanagermasterendpoint terminal point is as follows:
private def removeRdd(rddId: Int): Future[Seq[Int]] = {
//Delete the data element message of the RDD in blockLocations and blockManagerInfo
//First, the data block information stored in the RDD is obtained according to the RDD number
val blocks = blockLocations.asScala.keys.flatMap(_.asRDDId).filter(_.rddId == rddId)
blocks.foreach { blockId =>
//Find out the BlockManagerId list of these data blocks according to the data block information, traverse these lists and delete them
//The BlockManager contains the metadata of the data block and deletes the metadata of the data block corresponding to blockLocations
val bms: mutable.HashSet[BlockManagerId] = blockLocations.get(blockId)
bms.foreach(bm => blockManagerInfo.get(bm).foreach(_.removeBlock(blockId)))
blockLocations.remove(blockId)
}
//Finally, a removedd message is sent to the executor to notify it to delete the RDD
val removeMsg = RemoveRdd(rddId)
val futures = blockManagerInfo.values.map { bm =>
bm.slaveEndpoint.ask[Int](removeMsg).recover {
case e: IOException =>
logWarning(s"Error trying to remove RDD $rddId from block manager ${bm.blockManagerId}",
e)
0 // zero blocks were removed
}
}.toSeq
Future.sequence(futures)
}
Storage level
Although Spark is a memory based calculation, RDD data sets can not only be stored in memory, but also be displayed and cached in memory or disk using the persist method or cache method. The code implementation of persist is as follows:
private def persist(newLevel: StorageLevel, allowOverride: Boolean): this.type = {
// TODO: Handle changes of StorageLevel
//If the RDD specifies a storage level other than NONE, the storage level cannot be modified
if (storageLevel != StorageLevel.NONE && newLevel != storageLevel && !allowOverride) {
throw new UnsupportedOperationException(
"Cannot change storage level of an RDD after it was already assigned a level")
}
//When the original storage level of RDD is NONE, you can persist the RDD. You need to clear the SparkContext before processing
//Store metadata related to RDD, and then add the persistence information of RDD
if (storageLevel == StorageLevel.NONE) {
sc.cleaner.foreach(_.registerRDDForCleanup(this))
sc.persistRDD(this)
}
//When the original RDD storage level is NONE, modify the RDD storage level to pass in a new value
storageLevel = newLevel
this
}
When the RDD is calculated for the first time, the persist method will adopt a specific cache policy according to the setting of the parameter StorageLevel. The operation will be carried out only when the original storage level of the RDD is NONE or the newly passed storage level value is equal to the original storage level. Because the persist operation is a kind of control operation, it only changes the metadata information of the original RDD, There is no data storage operation, but it is in the iterator method of RDD. For the cache method, it is only a special case of the persist method, that is, the parameter of the persist method is MEMORY_ONLY.
In the StorageLevel class, according to the combination of useDisk, useMemory, useOffHeap, deserialized and replication5 parameters, Spark provides 12 storage level caching strategies, which can persist RDD to memory, disk and external storage systems, or serialize it to memory, From to, you can store multiple copies between different nodes of the cluster. The code implementation is as follows:
class StorageLevel private(
private var _useDisk: Boolean,
private var _useMemory: Boolean,
private var _useOffHeap: Boolean,
private var _deserialized: Boolean,
private var _replication: Int = 1)
extends Externalizable {
...
object StorageLevel {
val NONE = new StorageLevel(false, false, false, false)
val DISK_ONLY = new StorageLevel(true, false, false, false)
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
val OFF_HEAP = new StorageLevel(true, true, true, false, 1)
...
}
RDD store call
Relationship between RDD and data Block
RDD contains multiple partitions, each Partition corresponds to a data Block, then each RDD contains one or more data Block blocks, each Block has a unique number BlockId, and the corresponding data Block numbering rule: "rdd_" + rddd + '"_ "+ splitIndex. Where splitIndex is the serial number of the Partition corresponding to the data Block.
There is no data storage operation in the persist method. The actual data operation occurs when RDD calls the iterator method during the task running. In the calling process, judge whether the data has been stored according to the specified storage level according to the data Block number. If there is a data Block, read the data from the local or remote node ; if the data Block does not exist, call the calculation method of RDD to get the result, and store the result according to the specified storage level. The iterator method code of RDD is as follows:
final def iterator(split: Partition, context: TaskContext): Iterator[T] = {
if (storageLevel != StorageLevel.NONE) {
//If there is a storage level, try to read the data in memory for iterative calculation
getOrCompute(split, context)
} else {
//If there is no storage level, read the data directly for iterative calculation or read the checkpoint results for iterative calculation
computeOrReadCheckpoint(split, context)
}
}
The called getOrCompute method is the core of storage logic. The code is as follows:
private[spark] def getOrCompute(partition: Partition, context: TaskContext): Iterator[T] = {
//Get the number of data block through the number of RDD and partition sequence number
val blockId = RDDBlockId(id, partition.index)
var readCachedBlock = true
// This method is called on executors, so we need call SparkEnv.get instead of sc.env.
//Since this method is called by the executor, you can use sparkEnv instead of sc.env
//Read the data first according to the block number of the data block, and then update the data. Here is the entry point for reading and writing data (getOrElseUpdate)
SparkEnv.get.blockManager.getOrElseUpdate(blockId, storageLevel, elementClassTag, () => {
//If the data block is not in memory, try to read the checkpoint result for iterative calculation
readCachedBlock = false
computeOrReadCheckpoint(partition, context)
}) match {
//Process the result returned by getOrElseUpdate, which indicates that the processing is successful, and record the result measurement information
case Left(blockResult) =>
if (readCachedBlock) {
val existingMetrics = context.taskMetrics().inputMetrics
existingMetrics.incBytesRead(blockResult.bytes)
new InterruptibleIterator[T](context, blockResult.data.asInstanceOf[Iterator[T]]) {
override def next(): T = {
existingMetrics.incRecordsRead(1)
delegate.next()
}
}
} else {
new InterruptibleIterator(context, blockResult.data.asInstanceOf[Iterator[T]])
}
//Process the result returned by getOrElseUpdate, which indicates that the processing failed. The result is returned to the caller, who decides how to process it
case Right(iter) =>
new InterruptibleIterator(context, iter.asInstanceOf[Iterator[T]])
}
}
Call the getOrElseUpdate method in getOrCompute, which is the entry point for storing read-write data:
//This method is the entry point for storing read-write data
def getOrElseUpdate[T](
blockId: BlockId,
level: StorageLevel,
classTag: ClassTag[T],
makeIterator: () => Iterator[T]): Either[BlockResult, Iterator[T]] = {
// Attempt to read the block from local or remote storage. If it's present, then we don't need
// to go through the local-get-or-put path.
//Read the data block entry and try to read data from local data or remote data
get[T](blockId)(classTag) match {
case Some(block) =>
return Left(block)
case _ =>
// Need to compute the block.
}
// Initially we hold no locks on this block.
//Write input entry
doPutIterator(blockId, makeIterator, level, classTag, keepReadLock = true) match {
case None =>
val blockResult = getLocalValues(blockId).getOrElse {
releaseLock(blockId)
throw new SparkException(s"get() failed for block $blockId even though we held a lock")
}
releaseLock(blockId)
Left(blockResult)
case Some(iter) =>
Right(iter)
}
}
Data reading process
The get method of BlockManager is the entrance point of reading data. It reads two steps for local reading and remote node reading at reading time. Local reading uses getLocalValues method, in this method, different storage implementation methods are directly called according to different storage level: while remote node reading is done by getRemote Values, getRemoteBytes is invoked in getRemoteValues method. Method, in the method, call the fetchBlockSync of the remote data transfer service class BlockTransferService to process, and use the fetchBlocks method of Netty to get data. The whole data read class is called as follows:
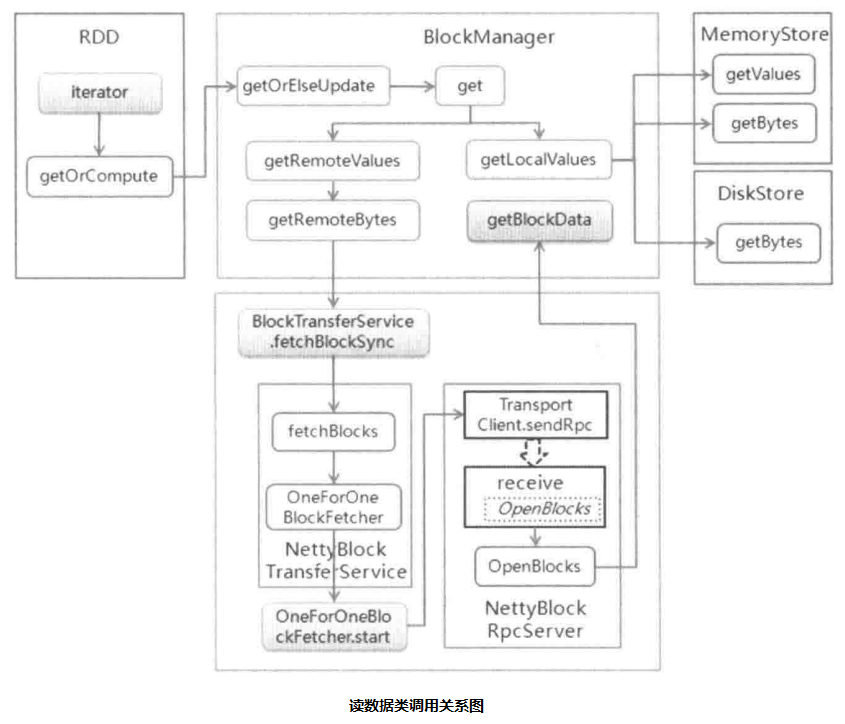
Local read
Local reading can be divided into memory and disk reading methods according to different storage levels. Their descriptions are as follows:
1. Memory reading
In the getLocalValues method, read the data in memory, and call the getValues and getBytes methods of MemoryStore respectively according to whether the returned data is encapsulated into BlockResult or data stream. The code is as follows:
def getLocalValues(blockId: BlockId): Option[BlockResult] = {
...
//The memory storage level is used, and the data is stored in memory
if (level.useMemory && memoryStore.contains(blockId)) {
val iter: Iterator[Any] = if (level.deserialized) {
//If deserialization is used during storage, the data in memory is read directly
memoryStore.getValues(blockId).get
} else {
//If deserialization is not used during storage, the data in memory will be deserialized
serializerManager.dataDeserializeStream(
blockId, memoryStore.getBytes(blockId).get.toInputStream())(info.classTag)
}
// We need to capture the current taskId in case the iterator completion is triggered
// from a different thread which does not have TaskContext set; see SPARK-18406 for
// discussion.
//After reading the data, return the data, data block size, reading method and other information
val ci = CompletionIterator[Any, Iterator[Any]](iter, {
releaseLock(blockId, taskAttemptId)
})
Some(new BlockResult(ci, DataReadMethod.Memory, info.size))
}
...
}
In the getValues and getBytes methods of MemoryStore, the data in memory is finally obtained through the data block number. The code is:
val entry = en seven ries.synchronized { entries.get(blockld) }
2. Disk reading
The disk read in the getLocalValues method calls the DiskStore getBytes method. After reading the data in the disk, we need to cache the data into the memory. The code is as follows:
def getLocalValues(blockId: BlockId): Option[BlockResult] = {
...
else if (level.useDisk && diskStore.contains(blockId)) {
//Get data from the disk. Since the data saved to the disk is serialized, the read data is also serialized
val diskData = diskStore.getBytes(blockId)
val iterToReturn: Iterator[Any] = {
if (level.deserialized) {
//If the storage level needs to be deserialized, the read data is deserialized and then stored in memory
val diskValues = serializerManager.dataDeserializeStream(
blockId,
diskData.toInputStream())(info.classTag)
maybeCacheDiskValuesInMemory(info, blockId, level, diskValues)
} else {
//If the storage level does not require deserialization, the serialized data is directly stored in memory
val stream = maybeCacheDiskBytesInMemory(info, blockId, level, diskData)
.map { _.toInputStream(dispose = false) }
.getOrElse { diskData.toInputStream() }
//The returned data needs to be deserialized
serializerManager.dataDeserializeStream(blockId, stream)(info.classTag)
}
}
//After reading the data, return the data, data block size, reading method and other information
val ci = CompletionIterator[Any, Iterator[Any]](iterToReturn, {
releaseLockAndDispose(blockId, diskData, taskAttemptId)
})
Some(new BlockResult(ci, DataReadMethod.Disk, info.size))
...
}
In the getBytes method of DiskStore, the getfile method of DiskBlockManager is used to get the handle of the file where the data block is located. The file is named as the file name of the data block, and the index of the first level directory and the two level subdirectory of the file is obtained by the hash value of the file name. The code is implemented as follows:
def getFile(filename: String): File = {
//Obtain the primary directory and secondary directory index values according to the hash value of the file name, wherein the primary directory index value is the modulus of the hash value and the number of primary directories,
// The index value of the secondary directory is the modulus of the hash value and the number of secondary subdirectories
val hash = Utils.nonNegativeHash(filename)
val dirId = hash % localDirs.length
val subDirId = (hash / localDirs.length) % subDirsPerLocalDir
//First obtain the directory through the index values of the primary directory and the secondary directory, and then judge whether the directory exists
val subDir = subDirs(dirId).synchronized {
val old = subDirs(dirId)(subDirId)
if (old != null) {
old
} else {
//If the directory does not exist, create the directory in the range of 00-63
val newDir = new File(localDirs(dirId), "%02x".format(subDirId))
if (!newDir.exists() && !newDir.mkdir()) {
throw new IOException(s"Failed to create local dir in $newDir.")
}
//Judge whether the file exists. If it does not exist, create it
subDirs(dirId)(subDirId) = newDir
newDir
}
}
//Get the handle of the file through the path of the file and return it
new File(subDir, filename)
}
After obtaining the file handle, read the entire file content. The code is as follows:
def getBytes(blockId: BlockId): BlockData = {
//Gets the handle to the file where the data block is located
val file = diskManager.getFile(blockId.name)
val blockSize = getSize(blockId)
securityManager.getIOEncryptionKey() match {
case Some(key) =>
new EncryptedBlockData(file, blockSize, conf, key)
case _ =>
new DiskBlockData(minMemoryMapBytes, maxMemoryMapBytes, file, blockSize)
}
}
Remote read
When reading data from a remote node, Spark only provides the Netty remote reading method. The nety remote data reading process is analyzed below. In Spark, Netty remote data reading is mainly handled by the following two classes:
- NettyBlockTransferService: this class provides data access interfaces to shuffles and enclosures. When receiving a data access command, it sends a message to the specified node through Netty's RPC architecture to request data access operations.
- NettyBlockRpcServer: when the Executor is started, the RCP listener will be started at the same time. When the monitor hears the message, the message will be delivered to this class for processing. The message content includes reading data OpenBlocks and writing data Upload Block.
The remote data reading process using Netty is as follows:
(1) the Spark remotely reads the data entrance to be getRemoteValues, then calls the getRemoteBytes method. In this method, the sortLocations method is called to send the SortLocations message to the BlockManagerMasterEndpoint terminal point, and the location information is requested according to the data block. When the terminal point of the Driver receives the request message, it obtains the location list of the data block according to the number of the data block, and sorts the location list according to whether it is local node data. The code snippet of sortlocations method in BlockManager class is as follows:
private def sortLocations(locations: Seq[BlockManagerId]): Seq[BlockManagerId] = {
//Get the information of the node where the data block node is located
val locs = Random.shuffle(locations)
//From the obtained node information, the local node data is read first
val (preferredLocs, otherLocs) = locs.partition { loc => blockManagerId.host == loc.host }
blockManagerId.topologyInfo match {
case None => preferredLocs ++ otherLocs
case Some(_) =>
val (sameRackLocs, differentRackLocs) = otherLocs.partition {
loc => blockManagerId.topologyInfo == loc.topologyInfo
}
preferredLocs ++ sameRackLocs ++ differentRackLocs
}
}
After obtaining the location list of the data block, the fetchBlockSync method provided by BlockTransferService is used to read the remote data in the BlockManager.getRemoteBytes method. The code implementation is as follows:
def getRemoteBytes(blockId: BlockId): Option[ChunkedByteBuffer] = {
...
var runningFailureCount = 0
var totalFailureCount = 0
//Gets the location of the data block
val locations = sortLocations(blockLocations)
val maxFetchFailures = locations.size
var locationIterator = locations.iterator
while (locationIterator.hasNext) {
val loc = locationIterator.next()
logDebug(s"Getting remote block $blockId from $loc")
//Get data remotely through the fetchBlockSync method provided by blockTransferService
val data = try {
blockTransferService.fetchBlockSync(
loc.host, loc.port, loc.executorId, blockId.toString, tempFileManager)
} catch {
...
}
//After obtaining the data, the data block is returned
if (data != null) {
if (remoteReadNioBufferConversion) {
return Some(new ChunkedByteBuffer(data.nioByteBuffer()))
} else {
return Some(ChunkedByteBuffer.fromManagedBuffer(data))
}
}
logDebug(s"The value of block $blockId is null")
}
logDebug(s"Block $blockId not found")
None
}
(2) After calling the fetchBlockSync method of the remote data transfer service BlockTransferService, continue to call the fetchBlocks method in this method.
override def fetchBlocks(
host: String,
port: Int,
execId: String,
blockIds: Array[String],
listener: BlockFetchingListener,
tempFileManager: DownloadFileManager): Unit = {
logTrace(s"Fetch blocks from $host:$port (executor id $execId)")
try {
val blockFetchStarter = new RetryingBlockFetcher.BlockFetchStarter {
override def createAndStart(blockIds: Array[String], listener: BlockFetchingListener) {
//Create a communication client based on the node and port of the remote node
val client = clientFactory.createClient(host, port)
//Send the get data message to the specified node through the client
new OneForOneBlockFetcher(client, appId, execId, blockIds, listener,
transportConf, tempFileManager).start()
}
}
...
}
The sending and reading message is implemented in the OneForOneBlockFetcher class. The constructor in this class defines the message this.openMessage = new OpenBlocks(appld, execld, blocklds), and then sends a message to the RPC client in the start method of this class:
public void start() {
if (blockIds.length == 0) {
throw new IllegalArgumentException("Zero-sized blockIds array");
}
//Send a message to read the data block through the client
client.sendRpc(openMessage.toByteBuffer(), new RpcResponseCallback() {
@Override
public void onSuccess(ByteBuffer response) {
try {
...
}
});
}
(3) When the RPC server of the remote node receives the message sent by the client, it matches the message in the NettyBI ockRpcServer class. If it is a request to read quietly, call the getBlockData method of BlockManager to negotiate the data of the node. The read data block is encapsulated as a ManagedBuffer sequence and cached in memory, and then use the transmission pressure provided by Netty to transfer the data to the requesting node to complete the remote transmission task.
override def receive(
client: TransportClient,
rpcMessage: ByteBuffer,
responseContext: RpcResponseCallback): Unit = {
val message = BlockTransferMessage.Decoder.fromByteBuffer(rpcMessage)
logTrace(s"Received request: $message")
message match {
case openBlocks: OpenBlocks =>
val blocksNum = openBlocks.blockIds.length
//Call getBlockData of blockManager to read the data on this node
val blocks = for (i <- (0 until blocksNum).view)
yield blockManager.getBlockData(BlockId.apply(openBlocks.blockIds(i)))
//Register the ManagedBuffer sequence and use the Netty transmission channel to transmit data
val streamId = streamManager.registerStream(appId, blocks.iterator.asJava,
client.getChannel)
logTrace(s"Registered streamId $streamId with $blocksNum buffers")
responseContext.onSuccess(new StreamHandle(streamId, blocksNum).toByteBuffer)
...
}
}
Write data process
The doputlator method of BlockManager is the entry point for writing data. In this method, it is processed according to whether the data is cached in memory. If it is not cached in memory, call the putIterator method of BlockManager to directly store the disk: if it is cached in memory, first judge whether the data storage level is deserialized. If deserialization is set, it means that the obtained data is of value type, and the putliteratoravalues method is called to store the data in memory; If deserialization is not set, the obtained data is of byte type, and the putIteratorAsBytes method is called to store the data in memory. In the process of storing data into memory, judge whether the size of expanding the data in memory is enough. When it is enough, call the putArray method of BlockManager to write to memory, otherwise write the data to disk.
When writing data, on the one hand, send the metadata of the data block to the BockManagerMasterEndpoint terminal point on the Driver side to request it to update the data metadata. On the other hand, judge whether to create a data copy. If necessary, call the replicate method to write the data to the remote node, which is similar to reading the data of the remote node. Spark provides Netty write input. The calling relationship of data writing class is as follows:
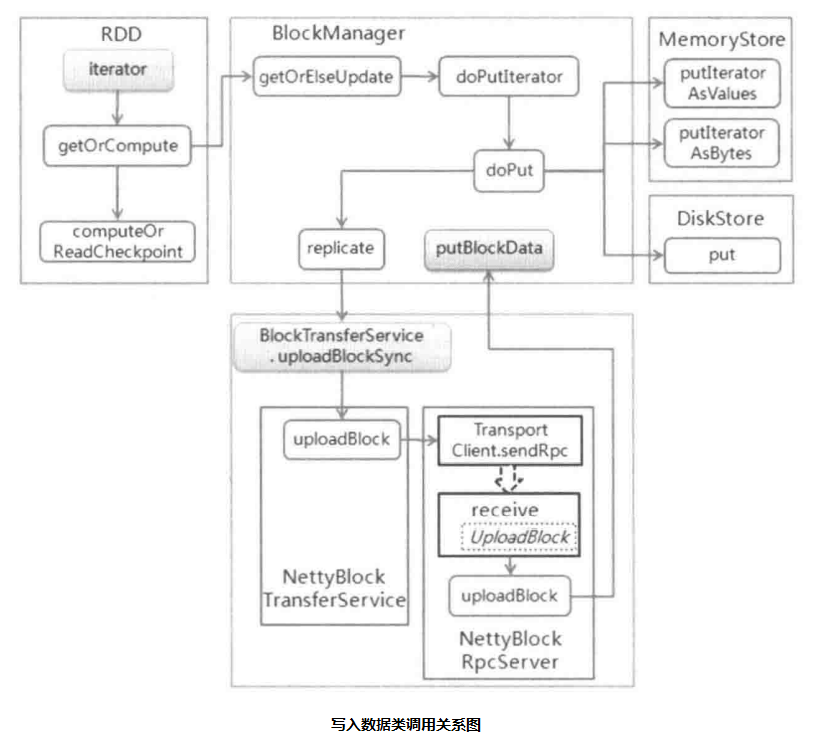
From the above method call diagram, we can know that the method to be called is determined according to the storage level and data type in the doputlator method of BlockManager. When the storage level is memory, the write method of MemoryStore is called; When the storage level is hard disk, call the write method of DiskStore. The code of BlockManager.doPutlterator is as follows:
private def doPutIterator[T](
blockId: BlockId,
iterator: () => Iterator[T],
level: StorageLevel,
classTag: ClassTag[T],
tellMaster: Boolean = true,
keepReadLock: Boolean = false): Option[PartiallyUnrolledIterator[T]] = {
//Auxiliary class, which is used to obtain data block information and process the write data results
doPut(blockId, level, classTag, tellMaster = tellMaster, keepReadLock = keepReadLock) { info =>
val startTimeMs = System.currentTimeMillis
var iteratorFromFailedMemoryStorePut: Option[PartiallyUnrolledIterator[T]] = None
var size = 0L
//Write data to memory
if (level.useMemory) {
//If deserialization is set, it indicates that the obtained data is of numeric type, and the putIteratorAsValues method is called
//Store data in memory
if (level.deserialized) {
memoryStore.putIteratorAsValues(blockId, iterator(), classTag) match {
//The data is written successfully, and the size of the data block is returned
case Right(s) =>
size = s
//Failed to write data to memory. If the storage level setting is written to disk, it will be written to disk. Otherwise, the result will be returned
case Left(iter) =>
// Not enough space to unroll this block; drop to disk if applicable
if (level.useDisk) {
logWarning(s"Persisting block $blockId to disk instead.")
diskStore.put(blockId) { channel =>
val out = Channels.newOutputStream(channel)
serializerManager.dataSerializeStream(blockId, out, iter)(classTag)
}
size = diskStore.getSize(blockId)
} else {
iteratorFromFailedMemoryStorePut = Some(iter)
}
}
} else { // !level.deserialized
//If deserialization is not set, the obtained data type is byte type, and the putIteratorAsBytes method is called
//Store data in memory
memoryStore.putIteratorAsBytes(blockId, iterator(), classTag, level.memoryMode) match {
//The data is written successfully, and the size of the data block is returned
case Right(s) =>
size = s
//Failed to write data to memory. If the storage level setting is written to disk, it will be written to disk. Otherwise, the result will be returned
case Left(partiallySerializedValues) =>
if (level.useDisk) {
logWarning(s"Persisting block $blockId to disk instead.")
diskStore.put(blockId) { channel =>
val out = Channels.newOutputStream(channel)
partiallySerializedValues.finishWritingToStream(out)
}
size = diskStore.getSize(blockId)
} else {
iteratorFromFailedMemoryStorePut = Some(partiallySerializedValues.valuesIterator)
}
}
}
}
//Call the put method of diskStore to write the data to disk
else if (level.useDisk) {
diskStore.put(blockId) { channel =>
val out = Channels.newOutputStream(channel)
serializerManager.dataSerializeStream(blockId, out, iterator())(classTag)
}
size = diskStore.getSize(blockId)
}
val putBlockStatus = getCurrentBlockStatus(blockId, info)
val blockWasSuccessfullyStored = putBlockStatus.storageLevel.isValid
if (blockWasSuccessfullyStored) {
// Now that the block is in either the memory or disk store, tell the master about it.
//If it is successfully written, the metadata of the data block is sent to the Driver
info.size = size
if (tellMaster && info.tellMaster) {
reportBlockStatus(blockId, putBlockStatus)
}
addUpdatedBlockStatusToTaskMetrics(blockId, putBlockStatus)
logDebug("Put block %s locally took %s".format(blockId, Utils.getUsedTimeMs(startTimeMs)))
//If you need to create a copy, get the data according to the data block number and copy it to other nodes
if (level.replication > 1) {
val remoteStartTime = System.currentTimeMillis
val bytesToReplicate = doGetLocalBytes(blockId, info)
// [SPARK-16550] Erase the typed classTag when using default serialization, since
// NettyBlockRpcServer crashes when deserializing repl-defined classes.
// TODO(ekl) remove this once the classloader issue on the remote end is fixed.
val remoteClassTag = if (!serializerManager.canUseKryo(classTag)) {
scala.reflect.classTag[Any]
} else {
classTag
}
try {
replicate(blockId, bytesToReplicate, level, remoteClassTag)
} finally {
bytesToReplicate.dispose()
}
logDebug("Put block %s remotely took %s"
.format(blockId, Utils.getUsedTimeMs(remoteStartTime)))
}
}
assert(blockWasSuccessfullyStored == iteratorFromFailedMemoryStorePut.isEmpty)
iteratorFromFailedMemoryStorePut
}
}
There are two ways to write data in Spark: memory and disk. The corresponding writing process is as follows:
Write memory
In the memory processing class MemoryStore, there are two write methods, putteratorasvalues and putteratorasbytes. The difference between the two methods is that the data types written to memory are different. Putteratorasvalues is for data writing of value type, while putateratorasbytes is for data writing of bytecode. The two methods are basically similar in the process of writing to memory. The following explains the writing process with putlteratorAsValues.
- (1) Before the data block is expanded, obtain the initialization memory for the expansion thread. The memory size is unrollMemoryThreshold. After obtaining, return the success result keepUnrolling.
- (2) If there are elements in the Iterator[T] and keepUnrolling is true, continue to traverse the Iterator[T], and the number of memory expansion elements elementsUnrolled increases by 1. If Iterator[T] is traversed to the end or keepUnrolling is false, skip to step (4).
- (3) After each memoryCheckPeriod, i.e. 16 expansion actions, conduct yi times to check whether the expanded memory size exceeds the currently allocated memory. If it does not exceed, continue to expand. If it is insufficient, calculate the memory size to be increased according to the growth factor, and then apply for the increased memory size according to the size: current expansion size * memory growth factor - current allocated memory size. If the application is successful, the memory size will be added to the used memory, and the memory size obtained by the expansion line is: current expansion size * memory growth factor.
- (4) Judge whether the data block is successfully expanded in memory. If the expansion fails, record that the memory is insufficient and exit. If the expansion succeeds, continue to the next step.
- (5) First estimate the size of the data block stored in the memory, and then compare the expanded memory of the data block with the size of the data block stored in the memory. If the expanded memory of the data block < = the size of the data block stored, it indicates that the size of the expanded memory is not enough to store the data block, and the difference between them needs to be applied. If the application is successful, It calls the transferUnrollToStorage method to handle the data block expansion memory, the size of the data block storage, which indicates that the size of the expanded memory is enough to store the data block, then release the extra memory first and then call the transferUnrollToStorage method to handle it.
- (6) In the transferunrolltorage method, release the space expanded in memory for the data block, and then judge whether the memory is enough to write data. If there is enough memory, put the data block into the entries of memory. Otherwise, the message of insufficient memory and failure to write memory will be returned.
private[storage] def putIteratorAsValues[T](
blockId: BlockId,
values: Iterator[T],
classTag: ClassTag[T]): Either[PartiallyUnrolledIterator[T], Long] = {
val valuesHolder = new DeserializedValuesHolder[T](classTag)
putIterator(blockId, values, classTag, MemoryMode.ON_HEAP, valuesHolder) match {
case Right(storedSize) => Right(storedSize)
case Left(unrollMemoryUsedByThisBlock) =>
val unrolledIterator = if (valuesHolder.vector != null) {
valuesHolder.vector.iterator
} else {
valuesHolder.arrayValues.toIterator
}
Left(new PartiallyUnrolledIterator(
this,
MemoryMode.ON_HEAP,
unrollMemoryUsedByThisBlock,
unrolled = unrolledIterator,
rest = values))
}
}
private def putIterator[T](
blockId: BlockId,
values: Iterator[T],
classTag: ClassTag[T],
memoryMode: MemoryMode,
valuesHolder: ValuesHolder[T]): Either[Long, Long] = {
require(!contains(blockId), s"Block $blockId is already present in the MemoryStore")
// Number of elements unrolled so far
var elementsUnrolled = 0
// Whether there is still enough memory for us to continue unrolling this block
var keepUnrolling = true
// Initial per-task memory to request for unrolling blocks (bytes).
val initialMemoryThreshold = unrollMemoryThreshold
// How often to check whether we need to request more memory
val memoryCheckPeriod = conf.get(UNROLL_MEMORY_CHECK_PERIOD)
// Memory currently reserved by this task for this particular unrolling operation
var memoryThreshold = initialMemoryThreshold
// Memory to request as a multiple of current vector size
val memoryGrowthFactor = conf.get(UNROLL_MEMORY_GROWTH_FACTOR)
// Keep track of unroll memory used by this particular block / putIterator() operation
var unrollMemoryUsedByThisBlock = 0L
// Request enough memory to begin unrolling
keepUnrolling =
reserveUnrollMemoryForThisTask(blockId, initialMemoryThreshold, memoryMode)
if (!keepUnrolling) {
logWarning(s"Failed to reserve initial memory threshold of " +
s"${Utils.bytesToString(initialMemoryThreshold)} for computing block $blockId in memory.")
} else {
unrollMemoryUsedByThisBlock += initialMemoryThreshold
}
// Unroll this block safely, checking whether we have exceeded our threshold periodically
while (values.hasNext && keepUnrolling) {
valuesHolder.storeValue(values.next())
if (elementsUnrolled % memoryCheckPeriod == 0) {
val currentSize = valuesHolder.estimatedSize()
// If our vector's size has exceeded the threshold, request more memory
if (currentSize >= memoryThreshold) {
val amountToRequest = (currentSize * memoryGrowthFactor - memoryThreshold).toLong
keepUnrolling =
reserveUnrollMemoryForThisTask(blockId, amountToRequest, memoryMode)
if (keepUnrolling) {
unrollMemoryUsedByThisBlock += amountToRequest
}
// New threshold is currentSize * memoryGrowthFactor
memoryThreshold += amountToRequest
}
}
elementsUnrolled += 1
}
// Make sure that we have enough memory to store the block. By this point, it is possible that
// the block's actual memory usage has exceeded the unroll memory by a small amount, so we
// perform one final call to attempt to allocate additional memory if necessary.
if (keepUnrolling) {
val entryBuilder = valuesHolder.getBuilder()
val size = entryBuilder.preciseSize
if (size > unrollMemoryUsedByThisBlock) {
val amountToRequest = size - unrollMemoryUsedByThisBlock
keepUnrolling = reserveUnrollMemoryForThisTask(blockId, amountToRequest, memoryMode)
if (keepUnrolling) {
unrollMemoryUsedByThisBlock += amountToRequest
}
}
if (keepUnrolling) {
val entry = entryBuilder.build()
// Synchronize so that transfer is atomic
memoryManager.synchronized {
releaseUnrollMemoryForThisTask(memoryMode, unrollMemoryUsedByThisBlock)
val success = memoryManager.acquireStorageMemory(blockId, entry.size, memoryMode)
assert(success, "transferring unroll memory to storage memory failed")
}
entries.synchronized {
entries.put(blockId, entry)
}
logInfo("Block %s stored as values in memory (estimated size %s, free %s)".format(blockId,
Utils.bytesToString(entry.size), Utils.bytesToString(maxMemory - blocksMemoryUsed)))
Right(entry.size)
} else {
// We ran out of space while unrolling the values for this block
logUnrollFailureMessage(blockId, entryBuilder.preciseSize)
Left(unrollMemoryUsedByThisBlock)
}
} else {
// We ran out of space while unrolling the values for this block
logUnrollFailureMessage(blockId, valuesHolder.estimatedSize())
Left(unrollMemoryUsedByThisBlock)
}
}
Write to disk
The method of Spark writing to disk calls the put method of DiskStore, which provides a callback method writefunc for writing files. In this method, first obtain the write file handle, then serialize the data into a data stream, and finally write the data to the file according to the callback method. The processing code is as follows:
def put(blockId: BlockId)(writeFunc: WritableByteChannel => Unit): Unit = {
if (contains(blockId)) {
throw new IllegalStateException(s"Block $blockId is already present in the disk store")
}
logDebug(s"Attempting to put block $blockId")
val startTime = System.currentTimeMillis
//To obtain the file handle that needs to be written, see the reading process of the external storage system
val file = diskManager.getFile(blockId)
val out = new CountingWritableChannel(openForWrite(file))
var threwException: Boolean = true
try {
//Using the callback method, you need to serialize the value type data into a data stream before writing
writeFunc(out)
blockSizes.put(blockId, out.getCount)
threwException = false
} finally {
try {
out.close()
} catch {
case ioe: IOException =>
if (!threwException) {
threwException = true
throw ioe
}
} finally {
if (threwException) {
remove(blockId)
}
}
}
val finishTime = System.currentTimeMillis
logDebug("Block %s stored as %s file on disk in %d ms".format(
file.getName,
Utils.bytesToString(file.length()),
finishTime - startTime))
}