1, Driver
val sparkConnf=new SparkConf().setAppName("wordCount").setMaster("local[3]")
val sparkContext=new SparkContext(sparkConnf)
val rdd = sparkContext.parallelize(Array(1, 2, 3, 4, 5), 3)
val rdd_increace=rdd.map(_+1)
rdd_increace.collect()
sparkContext.stop()

The above code creates two RDDS without shuffle dependency, so there are only resulttasks. The number of mappartitions RDD partitions is 3.
def parallelize[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T] = withScope {
assertNotStopped()
new ParallelCollectionRDD[T](this, seq, numSlices, Map[Int, Seq[String]]())
}
def map[U: ClassTag](f: T => U): RDD[U] = withScope {
val cleanF = sc.clean(f)
new MapPartitionsRDD[U, T](this, (_, _, iter) => iter.map(cleanF))
}
The method body of f function in MapPartitionsRDD object is "+ 1".
private[spark] class MapPartitionsRDD[U: ClassTag, T: ClassTag](
var prev: RDD[T],
f: (TaskContext, Int, Iterator[T]) => Iterator[U], // (TaskContext, partition index, iterator)
preservesPartitioning: Boolean = false,
isFromBarrier: Boolean = false,
isOrderSensitive: Boolean = false)
extends RDD[U](prev)
2, Task related classes
The distributed computing of spark executes the specific computing logic of each partition by distributing the Task object to different excutors and executing the Task.runTask(context: TaskContext) method after deserialization.
2.1 view the runTask(context: TaskContext) method of ResultTask class:
override def runTask(context: TaskContext): U = {
// Deserialize the RDD and the func using the broadcast variables.
val threadMXBean = ManagementFactory.getThreadMXBean
val deserializeStartTimeNs = System.nanoTime()
val deserializeStartCpuTime = if (threadMXBean.isCurrentThreadCpuTimeSupported) {
threadMXBean.getCurrentThreadCpuTime
} else 0L
val ser = SparkEnv.get.closureSerializer.newInstance()
val (rdd, func) = ser.deserialize[(RDD[T], (TaskContext, Iterator[T]) => U)](
ByteBuffer.wrap(taskBinary.value), Thread.currentThread.getContextClassLoader)
_executorDeserializeTimeNs = System.nanoTime() - deserializeStartTimeNs
_executorDeserializeCpuTime = if (threadMXBean.isCurrentThreadCpuTimeSupported) {
threadMXBean.getCurrentThreadCpuTime - deserializeStartCpuTime
} else 0L
func(context, rdd.iterator(partition, context))
}
First, get rdd and func through deserialization, and track the method call chain of the program,
Here, rdd is in the driver
rdd_ Increase: mappartitionsrdd object;
func is a function of type:
(ctx: TaskContext, it: Iterator[T]): => Iterator[U]

The function body of func function comes from RDD_ Increase. Collect() and pass it back during the call process. The specific transfer process can track the call chain in the source code.
def collect(): Array[T] = withScope {
val results = sc.runJob(this, (iter: Iterator[T]) => iter.toArray)
Array.concat(results: _*)
}
Here is the approximate result of func deserialization
val func=(ctx: TaskContext, it: Iterator[Int]) => {it.toArray}
2.2. Execute func function after deserialization
func(context, rdd.iterator(partition, context))
View rdd.iterator(partition, context)
iterator(split: Partition, context: TaskContext) method
Is an immutable function defined in the RDD class. Its function is to either read data from the cache checkpoint or calculate data. The key code for executing logical calculation is compute(split, context).
final def iterator(split: Partition, context: TaskContext): Iterator[T] = {
if (storageLevel != StorageLevel.NONE) {
getOrCompute(split, context)
} else {
computeOrReadCheckpoint(split, context)
}
}
/**
* Compute an RDD partition or read it from a checkpoint if the RDD is checkpointing.
*/
private[spark] def computeOrReadCheckpoint(split: Partition, context: TaskContext): Iterator[T] =
{
if (isCheckpointedAndMaterialized) {
firstParent[T].iterator(split, context)
} else {
compute(split, context)
}
}
compute(split: Partition, context: TaskContext): Iterator[T] is an abstract class defined in RDD and implemented in RDD subclasses.
def compute(split: Partition, context: TaskContext): Iterator[T]
3, MapPartitionsRDD class
private[spark] class MapPartitionsRDD[U: ClassTag, T: ClassTag](
var prev: RDD[T],
f: (TaskContext, Int, Iterator[T]) => Iterator[U], // (TaskContext, partition index, iterator)
preservesPartitioning: Boolean = false,
isFromBarrier: Boolean = false,
isOrderSensitive: Boolean = false)
extends RDD[U](prev) {
.
.
.
override def compute(split: Partition, context: TaskContext): Iterator[U] =
f(context, split.index, firstParent[T].iterator(split, context))
.
.
.
}
Here, the f function is a class constructor parameter, its value is the value of the driver map conversion operation above, and its function body is "_ 1" operation.
Before executing the f function, first calculate the result of the function parameter. Here, firstParent[T] returns the first RDD of the parent dependency (MapPartitionsRDD will only have one parent RDD, and union RDD will have multiple). The parent RDD repeats the iterator - > compute method call process, executes its own compute(split: Partition, context: TaskContext) function, and returns the Iterator[T] composed of the processed results,
The parent RDD here is ParallelCollectionRDD
4, ParallelCollectionRDD
override def compute(s: Partition, context: TaskContext): Iterator[T] = {
new InterruptibleIterator(context, s.asInstanceOf[ParallelCollectionPartition[T]].iterator)
}
The compute function of ParallelCollectionRDD wraps the iterator of the collection element as an InterruptibleIterator and returns it. Because it does not have an upper level RDD, it does not continue to iterate. So far, the dependency chain of RDD has been executed.
5, ShuffleMapTask
There are two types of tasks, ResultTask and ShuffleMapTask. ShuffleMapTask involves the IO of temporary cache files.
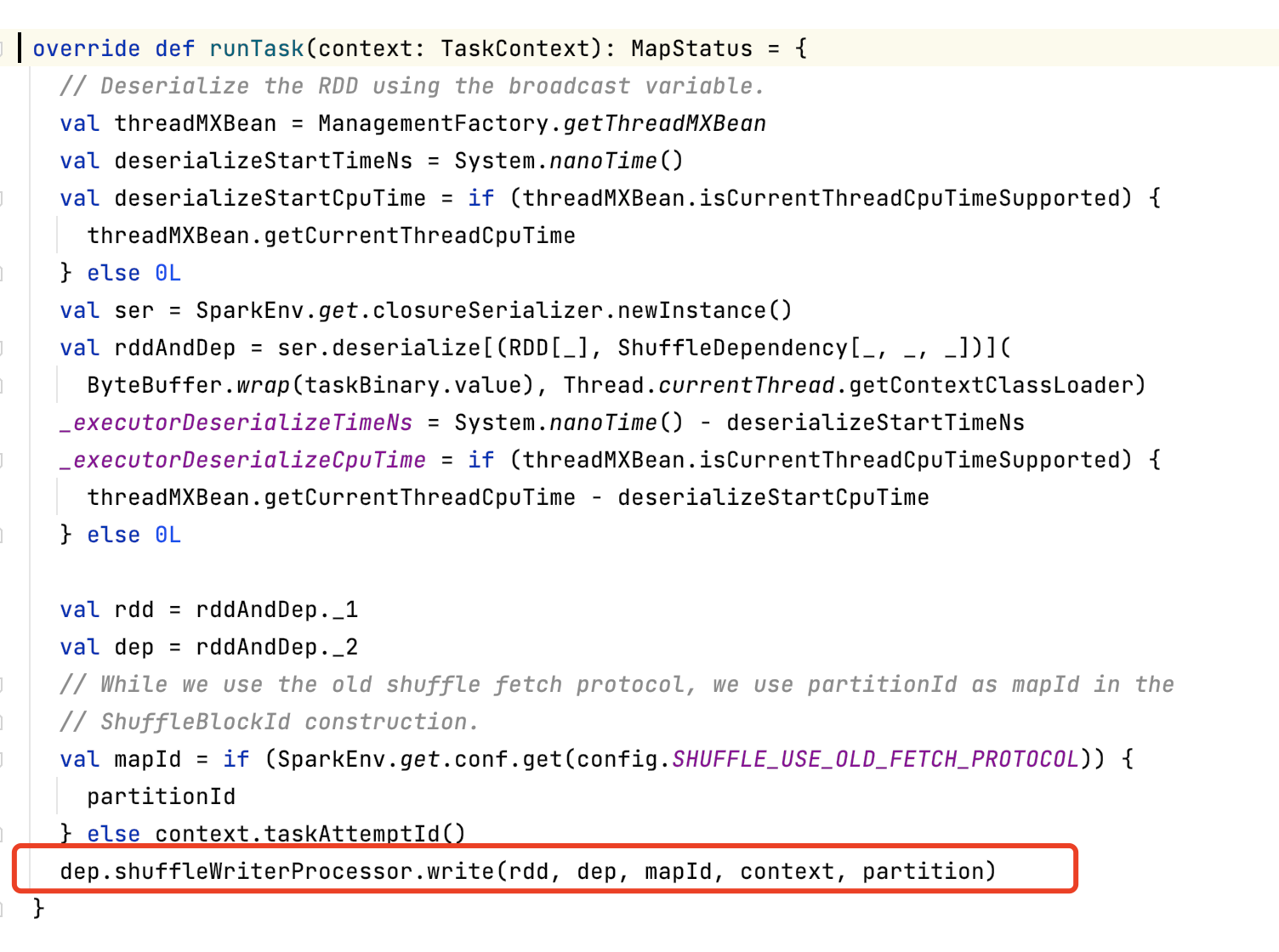
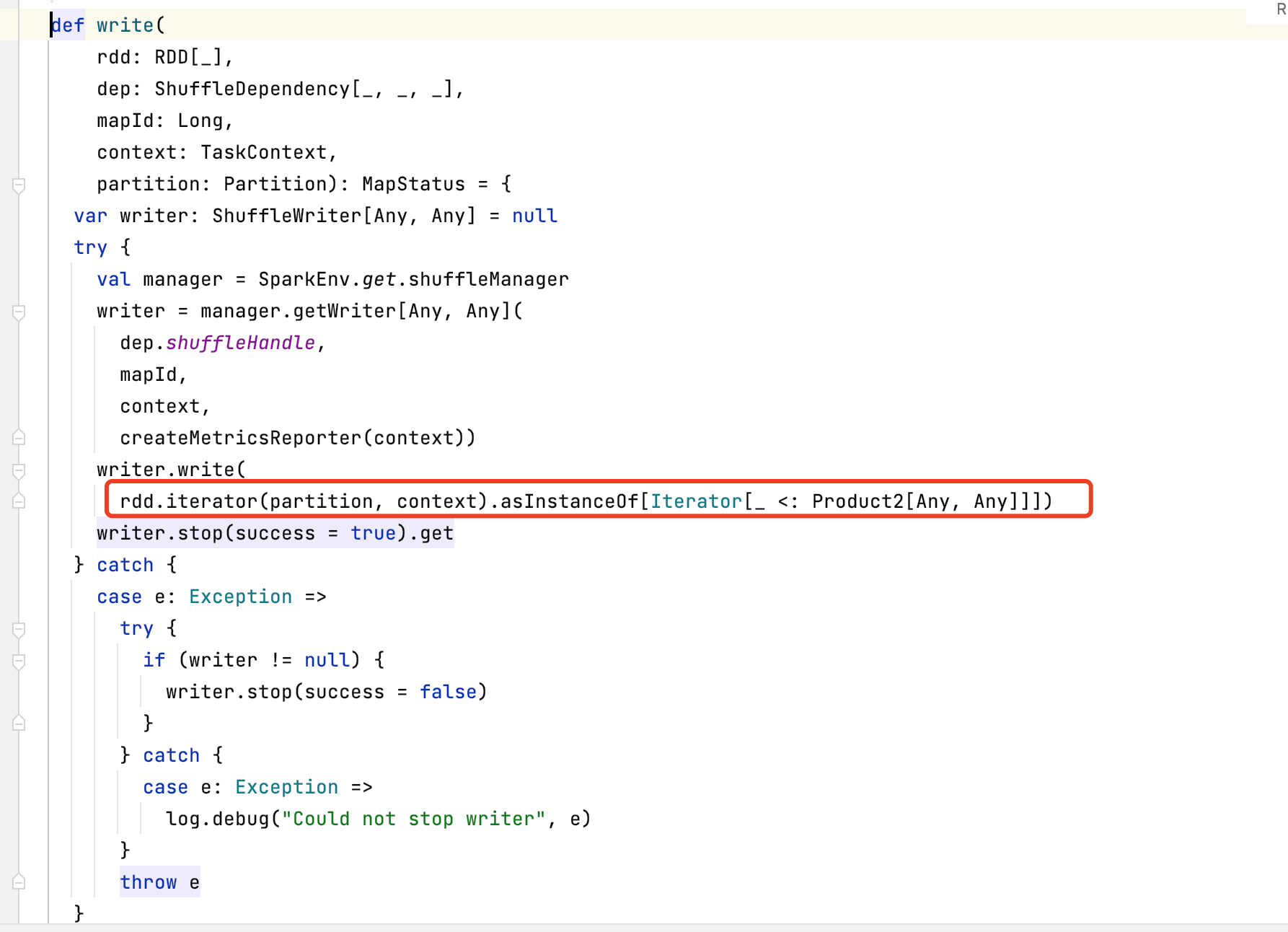
It can be seen that when the ShuffleMapTask writes the cache, it also triggers the sequential calculation of the operators of the rdd dependency chain by calling the compute method with the ResultTask through the iterator.
6, Summary
1. The calculation logic of RDD operator is passed to each RDD class through the class parameters of function type, and
def compute(split: Partition, context: TaskContext): Iterator[T]
Class method. compute is
2. If the parent RDD of RDD is not Nil, the compute method of its parent RDD will be iteratively executed by calculating the method parameter value when executing the compute method. In this way, it can be ensured that each RDD in the RDD DAG will be executed sequentially. If a checkpoint exists in the parent RDD of an RDD, the data is read from the cache without double calculation.
3. RDD execution is called in the runTask(context: TaskContext) method of the Task task. The Task task is generated and assigned to a specific Excutor for execution after the Application is submitted. The conversion RDD will not submit the Task, and the action RDD will not trigger the Task execution. Therefore, no action RDD will not trigger the Task execution.