preface
This article belongs to the column big data technology system, which was originally created by the author. Please indicate the source of quotation. Please point out the deficiencies and errors in the comment area. Thank you!
Please refer to the table of contents and references of this column Big data technology system
catalogue
Spark SQL workflow source code analysis (I) overview (based on Spark 3.3.0)
Spark SQL workflow source code analysis (II) parsing phase (based on Spark 3.3.0)
Spark SQL workflow source code analysis (III) analysis stage (based on Spark 3.3.0)
Spark SQL workflow source code analysis (IV) optimization stage (based on Spark 3.3.0)
Spark SQL workflow source code analysis (V) planning stage (based on Spark 3.3.0)
relation
An article about spark 3 X's Catalog system
Spark 3. What is the Table Catalog API of version x?
What are we going to do?
Through the previous study, we can easily find that:
The thing to do in the parsing phase is to convert the SQL statement into AST, which is actually only related to the SQL statement, that is, the same SQL statement and the final AST should be the same.
What we need to do in the analysis stage is to further analyze the generated ast. After all, the previously generated AST is only transformed from SQL statements, and the effects of SQL statements are different in different environments. At this time, what we need to do is to adapt to local conditions.
How to adjust measures to local conditions?
First of all, understand what we have? We can consider everything according to what we have in hand.
What do we have?
After the parsing phase, we get an AST:
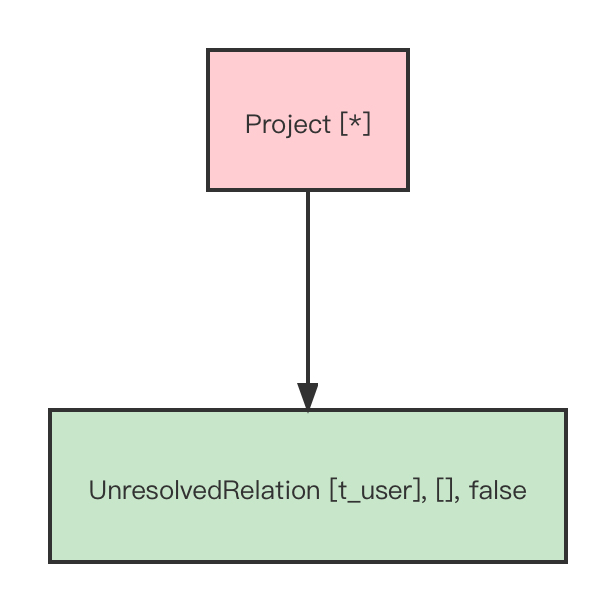
In addition, we have a set of configuration environment:
val spark = SparkSession.builder.master("local[*]").appName("SparkSQLExample").getOrCreate()
We also prepared the data source and schema
The data source comes from here:
val df = spark.read.json(DATA_PATH)
schema information comes from here:
df.createTempView("t_user")
Let's see what key information the above code can bring us:
- We know a temporary view: t_user
- We inferred the field name and field type from the JSON file:
| Field name | Field type |
|---|---|
| name | StringType |
| age | LongType |
| sex | StringType |
| addr | ArrayType |
The above field types are internal types from Apache Spark.
Look at the source code implementation
Find the entrance
def sql(sqlText: String): DataFrame = withActive {
val tracker = new QueryPlanningTracker
val plan = tracker.measurePhase(QueryPlanningTracker.PARSING) {
// Parking phase
sessionState.sqlParser.parsePlan(sqlText)
}
Dataset.ofRows(self, plan, tracker)
}
def ofRows(sparkSession: SparkSession, logicalPlan: LogicalPlan, tracker: QueryPlanningTracker)
: DataFrame = sparkSession.withActive {
val qe = new QueryExecution(sparkSession, logicalPlan, tracker)
qe.assertAnalyzed()
new Dataset[Row](qe, RowEncoder(qe.analyzed.schema))
}
// analyzed delayed initialization def assertAnalyzed(): Unit = analyzed
lazy val analyzed: LogicalPlan = executePhase(QueryPlanningTracker.ANALYSIS) {
// This is the entrance to the 'analysis' phase
sparkSession.sessionState.analyzer.executeAndCheck(logical, tracker)
}
Analyzer.executeAndCheck
def executeAndCheck(plan: LogicalPlan, tracker: QueryPlanningTracker): LogicalPlan = {
// If it has been resolved, it will directly return to the current logical plan
if (plan.analyzed) return plan
// Here, a 'ThreadLocal[Int]' type is used to avoid the parser calling itself recursively
AnalysisHelper.markInAnalyzer {
// implement
val analyzed = executeAndTrack(plan, tracker)
try {
// Verify the parsing results after execution
checkAnalysis(analyzed)
analyzed
} catch {
// Construct parse exception and throw
case e: AnalysisException =>
val ae = e.copy(plan = Option(analyzed))
ae.setStackTrace(e.getStackTrace)
throw ae
}
}
}
You can see that the core logic of the analysis phase consists of two steps:
- implement
- check
Let's look at the implementation first
implement
def executeAndTrack(plan: TreeType, tracker: QueryPlanningTracker): TreeType = {
// Set up the tracker. For the query plan tracker, please refer to the first lecture
QueryPlanningTracker.withTracker(tracker) {
execute(plan)
}
}
/**
* Execute the rule batch defined by the subclass.
* Rule batches are executed serially using defined execution policies.
* In each batch, the rule is also executed continuously.
*/
def execute(plan: TreeType): TreeType = {
var curPlan = plan
// This is used to count some operation information, such as how much time it takes, running rule batches, etc
val queryExecutionMetrics = RuleExecutor.queryExecutionMeter
// After the rule or rule batch is applied, log the changes of the logical plan
val planChangeLogger = new PlanChangeLogger[TreeType]()
// It's also the query plan tracker. See Lecture 1
val tracker: Option[QueryPlanningTracker] = QueryPlanningTracker.get
// Measurement information before execution
val beforeMetrics = RuleExecutor.getCurrentMetrics()
// This is used to check the integrity of the logical plan, mainly by checking whether the ID (exprId) of the named expression is unique and not repeated
if (!isPlanIntegral(plan, plan)) {
throw QueryExecutionErrors.structuralIntegrityOfInputPlanIsBrokenInClassError(
this.getClass.getName.stripSuffix("$"))
}
batches.foreach { batch =>
// Which logical plan does the rule batch start from
val batchStartPlan = curPlan
// Number of iterations
var iteration = 1
// Record the current logical plan
var lastPlan = curPlan
// Identification indicating whether to continue the cycle
var continue = true
// Run to a fixed point (or the maximum number of iterations specified in the execution strategy)
while (continue) {
curPlan = batch.rules.foldLeft(curPlan) {
case (plan, rule) =>
// Start time of rule run
val startTime = System.nanoTime()
// Apply rules to logical plans
val result = rule(plan)
// Run time of the rule
val runTime = System.nanoTime() - startTime
// The unequal description rule works and is effective
val effective = !result.fastEquals(plan)
if (effective) {
//Record the number of valid rules queryexecutionmetrics incNumEffectiveExecution(rule.ruleName)
// Record the effective running time queryexecutionmetrics incTimeEffectiveExecutionBy(rule.ruleName, runTime)
// Print the log to see how the rules have changed
planChangeLogger.logRule(rule.ruleName, plan, result)
}
// Record the execution time
queryExecutionMetrics.incExecutionTimeBy(rule.ruleName, runTime)
// Record how many rules you ran
queryExecutionMetrics.incNumExecution(rule.ruleName)
// Use the query plan tracker to record some time-related information
tracker.foreach(_.recordRuleInvocation(rule.ruleName, runTime, effective))
// After running each rule, check the integrity of the logical plan
if (effective && !isPlanIntegral(plan, result)) {
throw QueryExecutionErrors.structuralIntegrityIsBrokenAfterApplyingRuleError(
rule.ruleName, batch.name)
}
result
}
// Number of iterations plus 1
iteration += 1
if (iteration > batch.strategy.maxIterations) {
// Only those rules that have been run more than once will be printed in the log
if (iteration != 2) {
val endingMsg = if (batch.strategy.maxIterationsSetting == null) {
"."
} else {
s", please set '${batch.strategy.maxIterationsSetting}' to a larger value."
}
val message = s"Max iterations (${iteration - 1}) reached for batch ${batch.name}" +
s"$endingMsg"
if (Utils.isTesting || batch.strategy.errorOnExceed) {
throw new RuntimeException(message)
} else {
logWarning(message)
}
}
// Check the idempotency of a single rule batch
if (batch.strategy == Once &&
Utils.isTesting && !excludedOnceBatches.contains(batch.name)) {
checkBatchIdempotence(batch, curPlan)
}
continue = false
}
// If the logical plan has not changed, you need to exit the cycle
if (curPlan.fastEquals(lastPlan)) {
logTrace(
s"Fixed point reached for batch ${batch.name} after ${iteration - 1} iterations.")
continue = false
}
lastPlan = curPlan
}
// Log print how the logical plan has changed from the beginning to the present
planChangeLogger.logBatch(batch.name, batchStartPlan, curPlan)
}
// Log print some measurement information
planChangeLogger.logMetrics(RuleExecutor.getCurrentMetrics() - beforeMetrics)
curPlan
}
The flow chart is as follows:
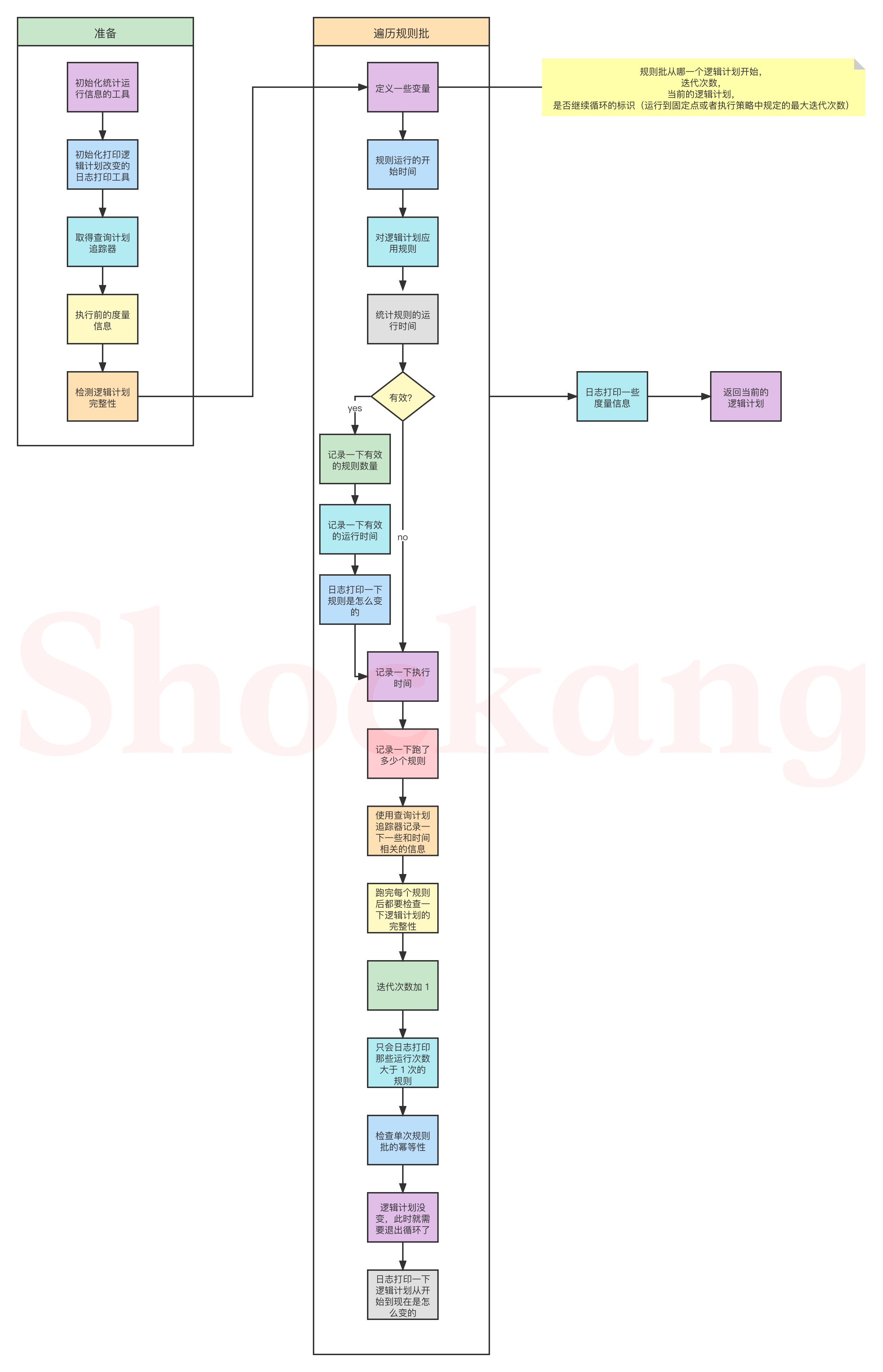
The whole process seems simple, and the core logic is actually the following line of code:
val result = rule(plan)
This represents applying specific rules to the current logical plan to get another logical plan.
After seeing this, we all understand that execution is not important. The core functions of the bottom layer are Batch and Rule.
What exactly are Batch and Rule?
Rule Batch
batches in the source code represents the regular batch sequence
/** * Define the batch sequence of rules to be overridden by the implementation. */ protected def batches: Seq[Batch]
A rule Batch consists of a rule name, an execution policy, and a rule list.
protected case class Batch(name: String, strategy: Strategy, rules: Rule[TreeType]*)
Execution strategy
abstract class Strategy {
/** Maximum number of iterations performed */
def maxIterations: Int
/** Whether to throw an exception after exceeding the maximum number of times */
def errorOnExceed: Boolean = false
/** SQLConf The key used to configure the maximum number of iterations in */
def maxIterationsSetting: String = null
}
There are two types of execution policies: fixedPoint and Once
fixedPoint
// If the plan cannot be resolved in maxIterations, analyzer will throw an exception to notify the user to increase sqlconf ANALYZER_ MAX_ The value of iterations.
protected def fixedPoint =
FixedPoint(
conf.analyzerMaxIterations,
errorOnExceed = true,
maxIterationsSetting = SQLConf.ANALYZER_MAX_ITERATIONS.key)
SQLConf. ANALYZER_ MAX_ Items represents the configuration item spark sql. analyzer. maxIterations
case class FixedPoint(
override val maxIterations: Int,
override val errorOnExceed: Boolean = false,
override val maxIterationsSetting: String = null) extends Strategy
FixedPoint represents the policy that runs to a fixed point or the maximum number of iterations, whichever comes first.
The rule batch for FixedPoint(1) should only run once.
Once
case object Once extends Strategy { val maxIterations = 1 }
Once stands for an idempotent policy that runs only once.
Rule
abstract class Rule[TreeType <: TreeNode[_]] extends SQLConfHelper with Logging {
// The integer ID of the rule is used to trim unnecessary tree traversal
protected lazy val ruleId = RuleIdCollection.getRuleId(this.ruleName)
/** The name of the current rule, which is automatically inferred according to the class name */
val ruleName: String = {
val className = getClass.getName
if (className endsWith "$") className.dropRight(1) else className
}
/** The core application function */
def apply(plan: TreeType): TreeType
}
TreeType represents any subclass of TreeNode, and TreeNode is the parent of all tree structures in Spark SQL. For example, the logical plan in the previous source code is one of its subclasses.
What are the rules?
We can from analyzer Find the answer in the scala file
override def batches: Seq[Batch] = Seq(
Batch("Substitution", fixedPoint,
OptimizeUpdateFields,
CTESubstitution,
WindowsSubstitution,
EliminateUnions,
SubstituteUnresolvedOrdinals),
Batch("Disable Hints", Once,
new ResolveHints.DisableHints),
Batch("Hints", fixedPoint,
ResolveHints.ResolveJoinStrategyHints,
ResolveHints.ResolveCoalesceHints),
Batch("Simple Sanity Check", Once,
LookupFunctions),
Batch("Keep Legacy Outputs", Once,
KeepLegacyOutputs),
Batch("Resolution", fixedPoint,
ResolveTableValuedFunctions(v1SessionCatalog) ::
ResolveNamespace(catalogManager) ::
new ResolveCatalogs(catalogManager) ::
ResolveUserSpecifiedColumns ::
ResolveInsertInto ::
ResolveRelations ::
ResolvePartitionSpec ::
ResolveFieldNameAndPosition ::
AddMetadataColumns ::
DeduplicateRelations ::
ResolveReferences ::
ResolveExpressionsWithNamePlaceholders ::
ResolveDeserializer ::
ResolveNewInstance ::
ResolveUpCast ::
ResolveGroupingAnalytics ::
ResolvePivot ::
ResolveOrdinalInOrderByAndGroupBy ::
ResolveAggAliasInGroupBy ::
ResolveMissingReferences ::
ExtractGenerator ::
ResolveGenerate ::
ResolveFunctions ::
ResolveAliases ::
ResolveSubquery ::
ResolveSubqueryColumnAliases ::
ResolveWindowOrder ::
ResolveWindowFrame ::
ResolveNaturalAndUsingJoin ::
ResolveOutputRelation ::
ExtractWindowExpressions ::
GlobalAggregates ::
ResolveAggregateFunctions ::
TimeWindowing ::
SessionWindowing ::
ResolveInlineTables ::
ResolveLambdaVariables ::
ResolveTimeZone ::
ResolveRandomSeed ::
ResolveBinaryArithmetic ::
ResolveUnion ::
typeCoercionRules ++
Seq(ResolveWithCTE) ++
extendedResolutionRules : _*),
Batch("Remove TempResolvedColumn", Once, RemoveTempResolvedColumn),
Batch("Apply Char Padding", Once,
ApplyCharTypePadding),
Batch("Post-Hoc Resolution", Once,
Seq(ResolveCommandsWithIfExists) ++
postHocResolutionRules: _*),
Batch("Remove Unresolved Hints", Once,
new ResolveHints.RemoveAllHints),
Batch("Nondeterministic", Once,
PullOutNondeterministic),
Batch("UDF", Once,
HandleNullInputsForUDF,
ResolveEncodersInUDF),
Batch("UpdateNullability", Once,
UpdateAttributeNullability),
Batch("Subquery", Once,
UpdateOuterReferences),
Batch("Cleanup", fixedPoint,
CleanupAliases),
Batch("HandleAnalysisOnlyCommand", Once,
HandleAnalysisOnlyCommand)
)
Because the bottom layer is actually running rules, we draw the following table with rules as granularity.
| rule | Rule batch | Execution strategy | interpretative statement | Supplementary notes |
|---|---|---|---|---|
| OptimizeUpdateFields | Substitution | fixedPoint | This rule optimizes the UpdateFields expression chain, so it looks more like an optimization rule. However, when manipulating deeply nested patterns, the UpdateFields expression tree can be very complex and cannot be analyzed. Therefore, we need to optimize UpdateFields as early as possible at the beginning of the analysis. | |
| CTESubstitution | Substitution | fixedPoint | Use nodes for analysis and replace sub plans With CTE references or CTE definitions according to the following conditions: 1. If you are in traditional mode, or if the query is an SQL command or DML statement, replace it With CTE definition, that is, inline CTE. 2. Otherwise, replace With CTE reference CTERelationRef. After query analysis, the InlineCTE rule will determine whether to inline. For each main query and sub query, all CTE definitions that are not inlined after this replacement will be grouped under a WithCTE node. Any main query or sub query that does not contain CTEs or has all CTEs inlined will obviously not contain any WithCTE nodes. If so, the WithCTE node will be located in the same location as the outermost With node. CTE definitions in the WithCTE node are saved in parsing order. This means that according to the dependency of CTE definitions on any valid CTE query, CTE definitions can be guaranteed to be arranged in topological order (that is, given CTE definitions A and B, B refers to a, and a is guaranteed to appear before B). Otherwise, it must be an invalid user query, and the relationship resolution rule will throw an analysis exception later. | |
| WindowsSubstitution | Substitution | fixedPoint | Replace the sub plan with WindowSpecDefinitions, where WindowSpecDefinition represents the specification of window functions. | |
| EliminateUnions | Substitution | fixedPoint | If there is only one child, remove the Union operator from the plan | |
| SubstituteUnresolvedOrdinals | Substitution | fixedPoint | Replace the sequence number in "order by" or "group by" with an unresolved ordinal expression, where unresolved ordinal represents the unresolved sequence number used by order by or group by. For example, select by group 1 and select from table 1 | |
| DisableHints | Disable Hints | Once | When the configuration item spark sql. optimizer. When disablehints is set, all hints in spark are deleted. This will be performed at the beginning of Analyzer to disable the hints feature. | |
| ResolveJoinStrategyHints | Hints | fixedPoint | The list of allowed join policy hint is in joinstrategyhint Defined in strategies. You can use the join policy hint to specify a series of relationship aliases, such as "MERGE(a, c)", "BROADCAST(a)". The join policy hint plan node is inserted at the top of any relationship (alias different), subquery, or common table expression that matches the specified name. The working principle of hint parsing is to recursively traverse the query plan and find the relationship or sub query that matches one of the specified relationship aliases. Traversal does not exceed any view references, including clauses or subquery aliases. This rule must occur before a common table expression. | The allowed join policies are: 1 BROADCAST(“BROADCAST”,“BROADCASTJOIN”,“MAPJOIN”)2.SHUFFLE_MERGE(“SHUFFLE_MERGE”,“MERGE”,“MERGEJOIN”)3.SHUFFLE_HASH(“SHUFFLE_HASH”)4.SHUFFLE_REPLICATE_NL ("SHUFFLE_REPLICATE_NL"), the category is outside the bracket, and the bracket is the specific hint string |
| ResolveCoalesceHints | Hints | fixedPoint | COALESCE Hint allows the following names: "COALESCE", "partition", "partition_by_range" | |
| LookupFunctions | Simple Sanity Check | Once | Check whether the function identifier of the unresolved function reference is defined in the function registry. Note that this rule does not attempt to resolve unsolvedfunctions. It only performs a simple existence check based on the function identifier to quickly identify undefined functions without triggering relationship resolution, which may lead to a potentially expensive partition / schema discovery process in some cases. To avoid duplicate external function lookups, the external function identifier is stored in the local hash set externalFunctionNameSet. | |
| KeepLegacyOutputs | Keep Legacy Outputs | Once | When Spark sql. legacy. When keepcommandoutputschema is set to true, Spark will keep the output format of commands such as SHOW DATABASES unchanged. | SHOW TABLES/SHOW NAMESPACES/DESCRIBE NAMESPACE/SHOW TBLPROPERTIES |
| ResolveTableValuedFunctions | Resolution | fixedPoint | Rules for parsing table valued function references. | |
| ResolveNamespace | Resolution | fixedPoint | Resolve rules such as SHOW TABLES and SHOW FUNCTIONS. | SHOW TABLES/SHOW TABLE EXTENDED/SHOW VIEWS/SHOW FUNCTIONS/ANALYZE TABLES |
| ResolveCatalogs | Resolution | fixedPoint | Resolve the catalog from the multi part identifier in the SQL statement. If the resolved catalog is not session catalog, convert the statement to the corresponding v2 command. | |
| ResolveUserSpecifiedColumns | Resolution | fixedPoint | Resolve user specified columns. | |
| ResolveInsertInto | Resolution | fixedPoint | Parse the INSERT INTO statement. | |
| ResolveRelations | Resolution | fixedPoint | Replace unresolved relationships (tables and views) with specific relationships in catalog. | For example, this rule will be used if the logical plan contains unresolved relation, which is used in our example. |
| ResolvePartitionSpec | Resolution | fixedPoint | ResolvedPartitionSpec to ResolvedPartitionSpec in partition related commands. | |
| ResolveFieldNameAndPosition | Resolution | fixedPoint | Rules for parsing, normalizing, and rewriting field names based on the case sensitivity of commands. | |
| AddMetadataColumnsResolution | Resolution | fixedPoint | When the node is missing the resolved attribute, the metadata column is added to the output of the child relationship. Use logicalplan Columns in metadata output resolve references to metadata columns. However, before replacing the relationship, the output of the relationship does not include metadata columns. Unless this rule adds metadata to the output of the relationship, analyzer will detect that there is nothing to generate the column. This rule adds metadata columns only when a node has been resolved but lacks input from its child nodes. This ensures that metadata columns are not added to the plan unless they are used. By checking only the resolved nodes, this ensures that * expansion has been completed so that * does not accidentally select metadata columns. This rule resolves operators to downward to avoid premature projection of metadata columns. | |
| DeduplicateRelations | Resolution | fixedPoint | Delete any duplicate relationships for LogicalPlan. | |
| ResolveReferences | Resolution | fixedPoint | Replace the unresolved attribute with the specific AttributeReference of the sub node of the logical plan section. | |
| ResolveExpressionsWithNamePlaceholders | Resolution | fixedPoint | Resolve the expression that contains the name placeholder. | |
| ResolveDeserializer | Resolution | fixedPoint | Replace UnsolvedDeserializer with a deserialization expression that has been resolved to the given input property. | |
| ResolveNewInstance | Resolution | fixedPoint | If the object to be constructed is an internal class, resolve the NewInstance by finding and adding an external scope to it. | |
| ResolveUpCast | Resolution | fixedPoint | Replace UpCast with Cast, and throw an exception if the conversion may be truncated. | |
| ResolveGroupingAnalytics | Resolution | fixedPoint | Parse the grouping function. | |
| ResolvePivot | Resolution | fixedPoint | Parse pivot (row to column) | |
| ResolveOrdinalInOrderByAndGroupBy | Resolution | fixedPoint | In many dialects of SQL, the order position used in the order/sort by and group by clauses is valid. This rule is used to convert the ordinal position to the corresponding expression in the selection list. This support was introduced in Spark 2.0. If you sort references or group by expressions that are not integers but collapsible expressions, ignore them. When spark sql. orderByOrdinal/spark. sql. Groupbyordinal is set to false and the location number is ignored. | Before Spark 2.0 was released, the characters in the order/sort by and group by clauses had no effect on the results. |
| ResolveAggAliasInGroupBy | Resolution | fixedPoint | Replace the unresolved expression in the grouping key with the resolved expression in the SELECT clause. This rule should run after ResolveReferences is applied. | |
| ResolveMissingReferences | Resolution | fixedPoint | In many dialects of SQL, sorting by attributes that do not exist in the SELECT clause is valid. This rule detects such queries and adds the required attributes to the original projection so that they are available during sorting. Add another projection to remove these attributes after sorting. The HAVING clause can also use grouping columns that are not displayed in the SELECT. | |
| ExtractGenerator | Resolution | fixedPoint | Extract the Generator from the Project list of the Project operator and create the Generate operator under Project. This rule will throw an AnalysisException in the following cases: 1 Generators are nested in expressions, such as select expand (list) + 1 from TBL. 2. There are multiple generators in the projectlist, such as select expand (list), expand (list) from TBL. 3. The Generator can be found in other operators other than Project or Generate, such as select * from TBL sort by expand (list). | |
| ResolveGenerate | Resolution | fixedPoint | Rewrite the table to Generate an expression that requires one or more of the following expressions to resolve: the specific Attribute reference of its output. Relocate from the SELECT clause (that is, from Project) to the Generate clause. The name of the output Attribute is extracted from the Alias or MultiAlias expression that encapsulates the Generator. | |
| ResolveFunctions | Resolution | fixedPoint | Replace unresolved function with specific LogicalPlan and unresolved function with specific Expression. | |
| ResolveAliases | Resolution | fixedPoint | Replace unresolved alias with a specific alias. | |
| ResolveSubquery | Resolution | fixedPoint | This rule parses and rewrites subqueries within expressions. Note: CTE is processed in CTESubstitution. | |
| ResolveSubqueryColumnAliases | Resolution | fixedPoint | Replace unresolved column aliases for subqueries with projections. | |
| ResolveWindowOrder | Resolution | fixedPoint | Check and add order to AggregateWindowFunction | |
| ResolveWindowFrame | Resolution | fixedPoint | Check and add appropriate window frames for all window functions | |
| ResolveNaturalAndUsingJoin | Resolution | fixedPoint | Delete the natural join or using join by calculating the output column based on the output on both sides, and then apply projection on the ordinary join to eliminate the natural join or using join. | |
| ResolveOutputRelation | Resolution | fixedPoint | Parse the columns of the output table from the data in the logical plan. This rule will: 1 Reorder columns when writing by name; 2. Insert forced conversion when the data types do not match; 3. Insert alias when the column names do not match; 4. Detect plans incompatible with the output table and raise AnalysisException | |
| ExtractWindowExpressions | Resolution | fixedPoint | Extract WindowExpressions from the projectList of the project operator and the aggregateExpressions of the aggregation operator, and create a separate window operator for each different WindowsSpecDefinition. This rule deals with three situations: 1 Project with WindowExpressions in the project list; 2. Include the aggregation of WindowExpressions in its aggregateExpressions. 3. A filter - > aggregate mode represents the HAVING clause, indicating GROUP BY. Aggregate has WindowExpressions in its aggregateExpressions. | |
| GlobalAggregates | Resolution | fixedPoint | Converts a projection containing an aggregate expression to an aggregate. | |
| ResolveAggregateFunctions | Resolution | fixedPoint | This rule looks for aggregate expressions that are not in the aggregate operator. For example, those in the HAVING clause or ORDER BY clause. These expressions are pushed down to the underlying aggregation operator and then projected after the original operator. | |
| TimeWindowing | Resolution | fixedPoint | Use the Expand operator to map time columns to multiple time windows. Since it is very important to calculate how many windows a time column can map to, we overestimate the number of windows and filter out the rows whose time column is not in the time window. | |
| SessionWindowing | Resolution | fixedPoint | Match the time column to the session window. | |
| ResolveInlineTables | Resolution | fixedPoint | Replace unresolved inlinetable with LocalRelation | |
| ResolveLambdaVariables | Resolution | fixedPoint | Analyze lambda variables exposed by higher-order functions. This rule is divided into two steps: 1 Bind the anonymous variables exposed by the higher-order function to the parameters of the lambda function; This creates named and typed lambda variables. In this step, you will check whether the parameter names are duplicate and check the number of parameters. 2. Analyze the lambda variables used in the function expression tree of lambda function. Note that we allow variables other than the current lambda, which can be lambda functions defined in an external scope or attributes generated by children of the plan. If the name is duplicate, the name defined in the innermost scope is used. | |
| ResolveTimeZone | Resolution | fixedPoint | Replace TimeZoneAwareExpression without time zone id with a copy of the session's local time zone. | |
| ResolveRandomSeed | Resolution | fixedPoint | Set the seed generated by random number. | |
| ResolveBinaryArithmetic | Resolution | fixedPoint | About addition: 1 If both sides are spaced, keep the same; 2. Otherwise, if one side is a date and the other side is an interval, convert it to DateAddInterval; 3. Otherwise, if one side is interval, it will be converted to TimeAdd; 4. Otherwise, if one side is date, change it to DateAdd; 5. Other aspects remain unchanged. About subtraction: 1 If both sides are spaced, keep the same; 2. Otherwise, if the left side is the date and the right side is the interval, it will be converted to DateAddInterval(l, -r); 3. Otherwise, if the right side is an interval, it will be converted to TimeAdd(l, -r); 4. Otherwise, if one side is a timestamp, convert it to SubtractTimestamps; 5. Otherwise, if date is on the right, it will be converted to DateDiff/Subtract Dates; 6. Otherwise, if the left side is date, convert it to DateSub; 7. Otherwise, it will remain unchanged. About multiplication: 1. If one side is an interval, convert it to MultiplyInterval; 2. Otherwise, it will remain unchanged. About division: 1. If interval is on the left, it will be converted to DivideInterval; 2. Otherwise, it will remain unchanged. | |
| ResolveUnion | Resolution | fixedPoint | Resolve the different children of the union into a set of common columns. | |
| typeCoercionRules | Resolution | fixedPoint | When spark sql. ansi. When enabled is set to true, ANSI parsing is adopted, which represents a set of parsing rules. | |
| ResolveWithCTE | Resolution | fixedPoint | Update the CTE reference with the resolve output attribute of the corresponding CTE definition. | |
| extendedResolutionRules | Resolution | fixedPoint | Convenient rewriting to provide additional rules. | |
| RemoveTempResolvedColumn | Remove TempResolvedColumn | Once | Delete all TempResolvedColumn in the query plan. This is a last resort in case some rules in the main parsing batch cannot delete TempResolvedColumn. We should run this rule immediately after the main parsing batch. | |
| ApplyCharTypePadding | Apply Char Padding | Once | This rule performs string padding for character type comparisons. When comparing a char type column / field with a string literal or char type column / field, right-click to fill the shorter column / field with the longer column / field. | |
| ResolveCommandsWithIfExists | Post-Hoc Resolution | Once | Rules for processing commands when tables or temporary views are not resolved. These commands support a flag "ifExists" so that they do not fail when the relationship is unresolved. If the "ifExists" flag is set to true, the logical plan will be resolved to NoopCommand. | DROP TABLE/DROP VIEW/UNCACHE TABLE/DROP FUNCTION |
| postHocResolutionRules | Post-Hoc Resolution | Once | Easily rewritten to provide rules for ex post facto resolution. Note that these rules are executed in a single batch. The batch will run after the normal parsing of the batch and its rules will be executed at one time. | |
| RemoveAllHints | Remove Unresolved Hints | Once | Delete all hints to delete invalid hints provided by the user. This must be done after all other hints rules have been executed. | |
| PullOutNondeterministic | Nondeterministic | Once | Extract uncertain expressions from LogicalPlan that is not a Project or filter, put them into internal Project, and finally Project them to external Project. | |
| HandleNullInputsForUDF | UDF | Once | The null check is performed by adding an additional if expression to correctly handle the null primitive input of UDF. When the user uses primitive parameters to define UDF, it is impossible to judge whether the primitive parameters are null. Therefore, here we assume that the primitive input is null and can be propagated. If the input is null, we should return null. | |
| ResolveEncodersInUDF | UDF | Once | The encoder of UDF is parsed by explicitly giving attributes. We explicitly give attributes to deal with cases where the data type of the input value is different from the internal mode of the encoder, which may lead to data loss. For example, if the actual data type is Decimal (30, 0), the encoder should not convert the input value to Decimal (38, 18). The parsed encoder will then be used to deserialize the internal row into Scala values. | |
| UpdateAttributeNullability | UpdateNullability | Once | Update the nullability of the attribute in the resolved LogicalPlan by using the nullability of the corresponding attribute of its child output attribute. This step is required because the user can use the resolved AttributeReference in the Dataset API, and the external join can change the nullability of AttributeReference. Without this rule, the NULL field of a column that can be NULL can actually be set to non NULL, which will lead to illegal optimization (such as NULL propagation) and wrong answers. For specific inquiries about this case, please refer to SPARK-13484 and SPARK-13801. | |
| UpdateOuterReferences | Subquery | Once | Push the aggregate expression in the sub query referencing the external query block down to the external query block for evaluation. The following rules update these external references as AttributeReference references to the attributes in the parentouter query block. | |
| CleanupAliases | Cleanup | fixedPoint | Clear unnecessary aliases in the plan. Basically, we only need to use Alias as a top-level expression in Project (Project list) or aggregation (aggregate expression) or window (window expression). Note that if an expression has other expression parameters that are not in its subexpression, such as runtimereplaceable, the Alias transformation in this rule cannot be used for these parameters. | |
| HandleAnalysisOnlyCommand | Cleanup | fixedPoint | Mark the command as a parsed rule to remove its subcommands to avoid optimization. This rule should run after running all other analysis rules. |
Parsing order
The parsing in the above table is performed in order.
The parsing sequence is shown in the following figure:

typeCoercionRules
Among the above rules, there is a special set of rules. Remember we talked about it in the second part( Spark SQL workflow source code analysis (II) parsing phase (based on Spark 3.3.0) )Mentioned Hive SQL ⇒ Spark SQL ⇒ evolution of ANSI SQL? This set of rules is related to it.
ANSI SQL
When Spark sql. ansi. When enabled is set to true, Spark will tend to handle SQL in an ANSI way.
| rule | explain |
|---|---|
| InConversion | Processing includes type coercion of IN expressions with subqueries and IN expressions without subqueries. 1. IN the first case, find the common type by comparing the left (LHS) expression type with the corresponding right (RHS) expression derived from the planned output of the subquery expression. Inject appropriate transformations into the LHS and RHS of the IN expression. 2. IN the second case, convert the value and in list expressions to the common operator type by looking at all parameter types and finding the closest type to which all parameters can be converted. When the common operator type is not found, the original expression is returned and a parsing exception is thrown during the type check phase. |
| PromoteStringLiterals | String text parsing that occurs in arithmetic, comparison, and datetime expressions. |
| DecimalPrecision | Calculates and propagates the precision of fixed precision decimals. Based on standard SQL and MS SQL, hive has many rules for this: https://cwiki.apache.org/confluence/download/attachments/27362075/Hive_Decimal_Precision_Scale_Support.pdf https://msdn.microsoft.com/en-us/library/ms190476.aspx |
| FunctionArgumentConversion | Ensure that the types of different functions are as expected. |
| ConcatCoercion | Force the Concat property children's type to the expected type. If spark sql. function. Concatbinaryasstring is false, all subtypes are binary, and the expected type is binary. Otherwise, a string is expected. |
| MapZipWithCoercion | Force the key type of two different MapType parameters of MapZipWith expression to public type. |
| EltCoercion | Force the type of the Elt property children to the expected type. If spark sql. function. Concatbinaryasstring is false, all subtypes are binary, and the expected type is binary. Otherwise, a string is expected. |
| CaseWhenCoercion | Force the type of different branches of the CASE WHEN statement to a public type. |
| IfCoercion | Force the type of different branches of If statement to public type. |
| StackCoercion | Force the NullType in the Stack expression to the column type at the corresponding position |
| Division | Hive performs integer division using only the DIV operator/ Arguments to are always converted to decimal type. |
| IntegralDivision | The DIV operator always returns a long integer value. This rule casts integer input to long type to avoid overflow during calculation. |
| ImplicitTypeCasts | Cast the type according to the expected input type of Expression. |
| DateTimeOperations | Datetime function for processing datetime_funcs( Spark SQL functions.scala source code analysis (VIII) DateTime functions (based on Spark 3.3.0)) |
| WindowFrameCoercion | Casts WindowFrame to the type of its operation. |
| GetDateFieldOperations | When a date field is obtained from a timestamp column, the column is cast to a date type. This is Spark's effort to simplify the implementation. In the default type coercion rule, the implicit coercion rule completes this work. However, ANSI implicit conversion rules do not allow the conversion of timestamp types to date types, so we need this additional rule to ensure that the extraction of date fields from timestamp columns works properly. |
HIVE SQL
When Spark sql. ansi. When enabled is set to false, Spark will tend to process SQL in the way of HIVE.
| rule | explain |
|---|---|
| InConversion | Processing includes type coercion of IN expressions with subqueries and IN expressions without subqueries. 1. IN the first case, find the common type by comparing the left (LHS) expression type with the corresponding right (RHS) expression derived from the planned output of the subquery expression. Inject appropriate transformations into the LHS and RHS of the IN expression. 2. IN the second case, convert the value and in list expressions to the common operator type by looking at all parameter types and finding the closest type to which all parameters can be converted. When the common operator type is not found, the original expression is returned and a parsing exception is thrown during the type check phase. |
| PromoteStrings | String text parsing that occurs in arithmetic expressions. |
| DecimalPrecision | Calculates and propagates the precision of fixed precision decimals. Based on standard SQL and MS SQL, hive has many rules for this: https://cwiki.apache.org/confluence/download/attachments/27362075/Hive_Decimal_Precision_Scale_Support.pdf https://msdn.microsoft.com/en-us/library/ms190476.aspx |
| BooleanEquality | Change the numeric type to Boolean so that expressions such as true=1 can be evaluated |
| FunctionArgumentConversion | Ensure that the types of different functions are as expected. |
| ConcatCoercion | Force the Concat property children's type to the expected type. If spark sql. function. Concatbinaryasstring is false, all subtypes are binary, and the expected type is binary. Otherwise, a string is expected. |
| MapZipWithCoercion | Force the key type of two different MapType parameters of MapZipWith expression to public type. |
| EltCoercion | Force the type of the Elt property children to the expected type. If spark sql. function. Concatbinaryasstring is false, all subtypes are binary, and the expected type is binary. Otherwise, a string is expected. |
| CaseWhenCoercion | Force the type of different branches of the CASE WHEN statement to a public type. |
| IfCoercion | Force the type of different branches of If statement to public type. |
| StackCoercion | Force the NullType in the Stack expression to the column type at the corresponding position |
| Division | Hive performs integer division using only the DIV operator/ Arguments to are always converted to decimal type. |
| IntegralDivision | The DIV operator always returns a long integer value. This rule casts integer input to long type to avoid overflow during calculation. |
| ImplicitTypeCasts | Cast the type according to the expected input type of Expression. |
| DateTimeOperations | Datetime function for processing datetime_funcs( Spark SQL functions.scala source code analysis (VIII) DateTime functions (based on Spark 3.3.0)) |
| WindowFrameCoercion | Casts WindowFrame to the type of its operation. |
| StringLiteralCoercion | A special rule that supports string text as date_ add/date_ The second parameter of the sub function to maintain backward compatibility as a temporary solution. |
Back to the original example
Due to space constraints, it is impossible for us to explain in detail how each rule is implemented.
So let's go back to the original example and understand its analysis. I believe we can bypass analogy.
In our example, two rules play a central role:
- ResolveRelations
- ResolveReferences
ResolveRelations
The resolverelationships rule replaces unresolved relationships (where relationships refer to tables and views) with concrete relationships in the catalog.
So how is it realized?
In fact, there are three steps. The specific flow chart is as follows:
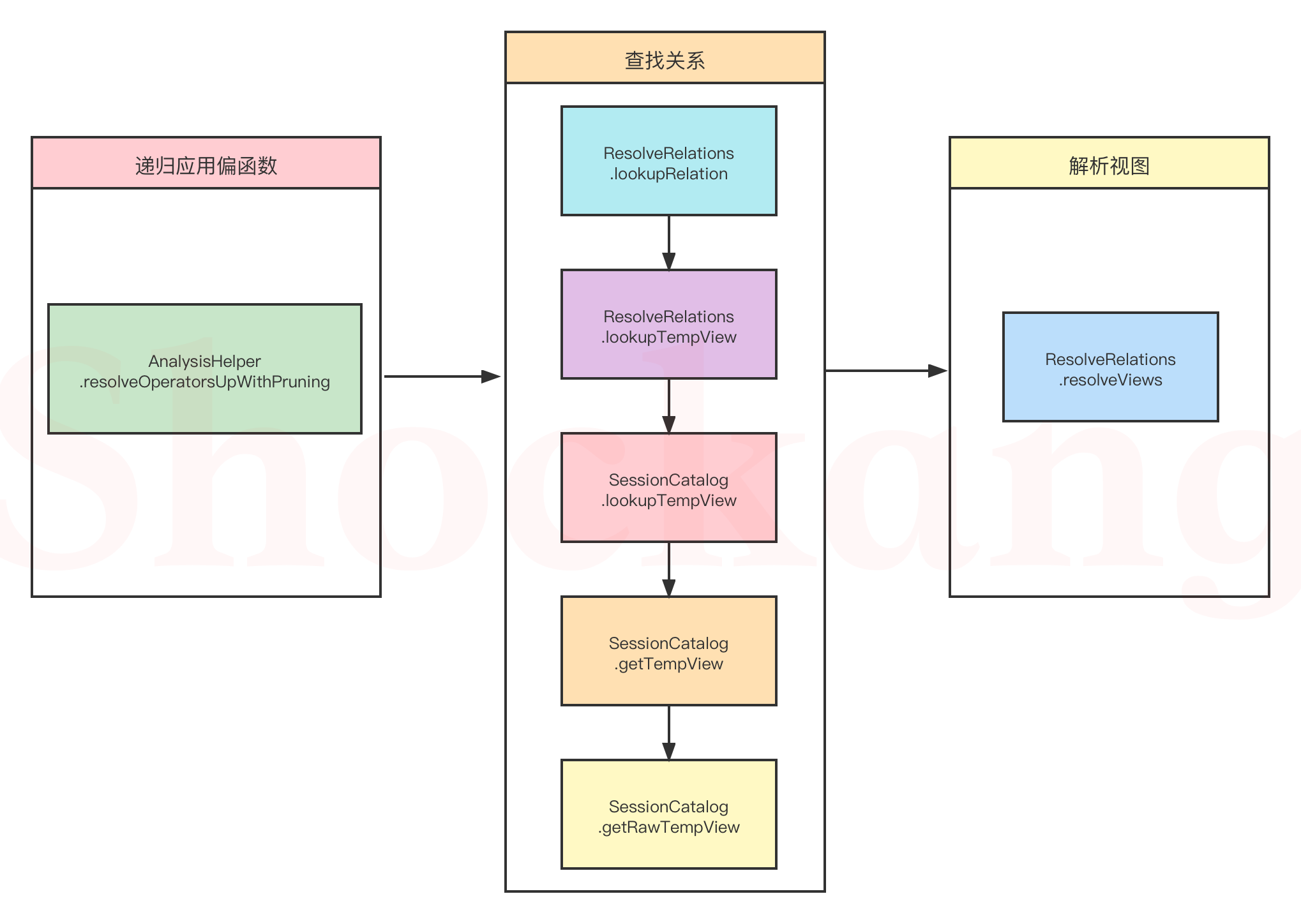
Let's follow the source code to understand the above flow chart:
apply
Let's take a look at the implementation of the apply function. As mentioned earlier, this is the core function in the Rule.
def apply(plan: LogicalPlan)
: LogicalPlan = plan.resolveOperatorsUpWithPruning(AlwaysProcess.fn, ruleId) {
Let's see what resolveoperators upwithpruning is first?
Recursive application partial function
/**
* Returns a copy of this node, where the rule is first recursively applied to all its child nodes and then recursively applied to itself (post order pass)
* Calendar, bottom-up). When the rule does not apply to a given node, it remains unchanged. This function is similar to transformUp,
* However, subtrees marked as parsed are skipped.
* @param rule–The function used to convert this node to a child node.
* @param cond–Lambda expression for pruning tree traversal. If ` cond Apply ` returns on operator T
* false,Skip processing T and its subtrees; Otherwise, T and its subtrees are processed recursively.
* @param ruleId–Is the unique Id of the rule used to trim unnecessary tree traversal. When it is an unknown rule, it will not be
* Trim. Otherwise, if the rule (id is ruleId) has been marked as valid on operator T, skip
* Over treated T and its subtree. If the rules are not purely functional and read differently for different calls
* Do not pass the initial state of.
*/
def resolveOperatorsUpWithPruning(cond: TreePatternBits => Boolean,
ruleId: RuleId = UnknownRuleId)(rule: PartialFunction[LogicalPlan, LogicalPlan])
: LogicalPlan = {
// The current logical plan is not resolved and its subtree can be processed recursively. For rules with id of ruleId, this tree node and its subtree are not marked as invalid.
if (!analyzed && cond.apply(self) && !isRuleIneffective(ruleId)) {
// To prevent nested calls, a ThreadLocal[Int] is used to record the depth of the call
AnalysisHelper.allowInvokingTransformsInAnalyzer {
// Returns a copy of the current node, recursively applied to all its child nodes
// The input of each rule is the output of its child nodes after applying the rule
val afterRuleOnChildren = mapChildren(_.resolveOperatorsUpWithPruning(cond, ruleId)(rule))
// If the logical plan has not changed
val afterRule = if (self fastEquals afterRuleOnChildren) {
CurrentOrigin.withOrigin(origin) {
// Apply rule to logical plan
rule.applyOrElse(self, identity[LogicalPlan])
}
} else {
CurrentOrigin.withOrigin(origin) {
// Apply rules to processed logical plan
rule.applyOrElse(afterRuleOnChildren, identity[LogicalPlan])
}
}
if (self eq afterRule) {
// The marking rule (with id ruleId) is not valid for this tree node and its subtrees.
self.markRuleAsIneffective(ruleId)
self
} else {
// Copy node label
afterRule.copyTagsFrom(self)
afterRule
}
}
} else {
self
}
}
We can see that the core of this part is the partial function rule. Let's take a look at its implementation.
After the parsing phase is completed, our logical plan is as follows:
'Project [*] +- 'UnresolvedRelation [t_user], [], false
Obviously, we can see that the branch of our corresponding partial function is the following:
case u: UnresolvedRelation =>
lookupRelation(u).map(resolveViews).getOrElse(u)
Find relationship
We need to find the corresponding relationship (table and view) from the Catalog.
/**
* If it is a v1 table in the session directory, resolve the relationship to a v1 relationship or a v2 relationship.
* This is used to parse DML commands and SELECT queries.
*/
private def lookupRelation(
u: UnresolvedRelation,
timeTravelSpec: Option[TimeTravelSpec] = None): Option[LogicalPlan] = {
// Find temporary view
lookupTempView(u.multipartIdentifier, u.isStreaming, timeTravelSpec.isDefined).orElse {
// If not, we will try to find it from the relationship cache
// If we parse database objects (relationships, functions, etc.) in the view, we may need to expand single or multi part identifiers using the current catalog and namespace after the view is created.
expandIdentifier(u.multipartIdentifier) match {
case CatalogAndIdentifier(catalog, ident) =>
val key = catalog.name +: ident.namespace :+ ident.name
// Find from relationship cache
AnalysisContext.get.relationCache.get(key).map(_.transform {
case multi: MultiInstanceRelation =>
val newRelation = multi.newInstance()
newRelation.copyTagsFrom(multi)
newRelation
}).orElse {
// Cannot find manual load and create relationship
val table = CatalogV2Util.loadTable(catalog, ident, timeTravelSpec)
val loaded = createRelation(catalog, ident, table, u.options, u.isStreaming)
// Update cache
loaded.foreach(AnalysisContext.get.relationCache.update(key, _))
loaded
}
case _ => None
}
}
}
}
How do I find temporary views?
private def lookupTempView(
identifier: Seq[String],
isStreaming: Boolean = false,
isTimeTravel: Boolean = false): Option[LogicalPlan] = {
// We are parsing a view, and when the view is created, the view name is not a temporary view, so we will return to None earlier
if (isResolvingView && !isReferredTempViewName(identifier)) return None
val tmpView = identifier match {
// In our example, there is only one identifier: t_user
// Find temporary views through SessionCatalog
case Seq(part1) => v1SessionCatalog.lookupTempView(part1)
case Seq(part1, part2) => v1SessionCatalog.lookupGlobalTempView(part1, part2)
case _ => None
}
// After you find it, you have to check it
tmpView.foreach { v =>
if (isStreaming && !v.isStreaming) {
throw QueryCompilationErrors.readNonStreamingTempViewError(identifier.quoted)
}
if (isTimeTravel) {
val target = if (v.isStreaming) "streams" else "views"
throw QueryCompilationErrors.timeTravelUnsupportedError(target)
}
}
tmpView
}
How can the metadata information of the corresponding temporary view be found in the SessionCatalog?
Students who are confused about SessionCatalog should first take a look at this blog—— An article about spark 3 X's Catalog system
def lookupTempView(table: String): Option[SubqueryAlias] = {
val formattedTable = formatTableName(table)
getTempView(formattedTable).map { view =>
SubqueryAlias(formattedTable, view)
}
}
Format the name of the table first
protected[this] def formatTableName(name: String): String = {
if (conf.caseSensitiveAnalysis) name else name.toLowerCase(Locale.ROOT)
}
Get the corresponding metadata information and convert it into the corresponding logical plan
def getTempView(name: String): Option[View] = synchronized {
getRawTempView(name).map(getTempViewPlan)
}
def getRawTempView(name: String): Option[TemporaryViewRelation] = synchronized {
tempViews.get(formatTableName(name))
}
Oh ~ it can be seen that the logic of finding temporary views is to fetch the corresponding temporary views from the Map cache of SessionCatalog. Let's take a look at the Map cache:
protected val tempViews = new mutable.HashMap[String, TemporaryViewRelation]
It is now clear that the metadata information of the temporary view we want to find comes from the HashMap cache.
So, the question is: when was the data added?
When was the data added?
Obviously, it comes from the following code in our example:
df.createTempView("t_user")
This step creates the temporary view we need. Let's see how it is implemented~
@throws[AnalysisException]
def createTempView(viewName: String): Unit = withPlan {
createTempViewCommand(viewName, replace = false, global = false)
}
private def createTempViewCommand(
viewName: String,
replace: Boolean,
global: Boolean): CreateViewCommand = {
val viewType = if (global) GlobalTempView else LocalTempView
val tableIdentifier = try {
// After reading the second lecture, the students believe that they will not be unfamiliar with this, which is basically similar to the logic of parsing stage
sparkSession.sessionState.sqlParser.parseTableIdentifier(viewName)
} catch {
case _: ParseException => throw QueryCompilationErrors.invalidViewNameError(viewName)
}
// After parsing the view, build a command to create the view for later execution
CreateViewCommand(
name = tableIdentifier,
userSpecifiedColumns = Nil,
comment = None,
properties = Map.empty,
originalText = None,
plan = logicalPlan,
allowExisting = false,
replace = replace,
viewType = viewType,
isAnalyzed = true)
}
Where is the specific implementation?
@inline private def withPlan(logicalPlan: LogicalPlan): DataFrame = {
Dataset.ofRows(sparkSession, logicalPlan)
}
def ofRows(sparkSession: SparkSession, logicalPlan: LogicalPlan): DataFrame =
sparkSession.withActive {
val qe = sparkSession.sessionState.executePlan(logicalPlan)
qe.assertAnalyzed()
new Dataset[Row](qe, RowEncoder(qe.analyzed.schema))
}
What do we see? Isn't this the beginning of this lecture on source code analysis?
We seem to be back to the origin.
However, this time we focus on the command to create a view, and this lecture analyzes the SQL statement.
Therefore, the following logic is similar to the above logic. In essence, rules are applied one by one!
So what are the core differences?
Since we are aiming at the command of creating view, if there is a command, it must be executed. Therefore, the key point is
In the run method of CreateViewCommand:
override def run(sparkSession: SparkSession): Seq[Row] = {
if (!isAnalyzed) {
throw QueryCompilationErrors.logicalPlanForViewNotAnalyzedError()
}
// This is a plan that has completed the analysis phase
val analyzedPlan = plan
// If the column specified by the user is not empty and different from the output column of the analysis stage, an exception is thrown
if (userSpecifiedColumns.nonEmpty &&
userSpecifiedColumns.length != analyzedPlan.output.length) {
throw QueryCompilationErrors.createViewNumColumnsMismatchUserSpecifiedColumnLengthError(
analyzedPlan.output.length, userSpecifiedColumns.length)
}
// Get SessionCatalog
val catalog = sparkSession.sessionState.catalog
// Temporary objects are not allowed to be referenced when creating a permanent view
// This should be in QE Assertanalyzed () is called later, that is, the child nodes have been resolved
verifyTemporaryObjectsNotExists(isTemporary, name, analyzedPlan, referredTempFunctions)
verifyAutoGeneratedAliasesNotExists(analyzedPlan, isTemporary, name)
// Temporary view, our example is this type
if (viewType == LocalTempView) {
val aliasedPlan = aliasPlan(sparkSession, analyzedPlan)
val tableDefinition = createTemporaryViewRelation(
name,
sparkSession,
replace,
catalog.getRawTempView,
originalText,
analyzedPlan,
aliasedPlan,
referredTempFunctions)
// Call the SessionCatalog method to create a temporary view
catalog.createTempView(name.table, tableDefinition, overrideIfExists = replace)
// Global temporary view
} else if (viewType == GlobalTempView) {
val db = sparkSession.sessionState.conf.getConf(StaticSQLConf.GLOBAL_TEMP_DATABASE)
val viewIdent = TableIdentifier(name.table, Option(db))
val aliasedPlan = aliasPlan(sparkSession, analyzedPlan)
val tableDefinition = createTemporaryViewRelation(
viewIdent,
sparkSession,
replace,
catalog.getRawGlobalTempView,
originalText,
analyzedPlan,
aliasedPlan,
referredTempFunctions)
catalog.createGlobalTempView(name.table, tableDefinition, overrideIfExists = replace)
// If it is a permanent view, the view name is in the cache of SessionCatalog
} else if (catalog.tableExists(name)) {
val tableMetadata = catalog.getTableMetadata(name)
if (allowExisting) {
// If you encounter this type of SQL: ` CREATE VIEW IF NOT EXISTS v0 AS SELECT... ` Do nothing when the target view does not exist
} else if (tableMetadata.tableType != CatalogTableType.VIEW) {
throw QueryCompilationErrors.tableIsNotViewError(name)
} else if (replace) {
// Circular View reference CREATE OR REPLACE VIEW detected
val viewIdent = tableMetadata.identifier
checkCyclicViewReference(analyzedPlan, Seq(viewIdent), viewIdent)
// When replacing an existing view, you should kill the cache
logDebug(s"Try to uncache ${viewIdent.quotedString} before replacing.")
CommandUtils.uncacheTableOrView(sparkSession, viewIdent.quotedString)
// Process this type of SQL: ` CREATE OR REPLACE VIEW v0 AS SELECT`
// We don't care about the information in the old view. Kill it directly and create a new one
catalog.dropTable(viewIdent, ignoreIfNotExists = false, purge = false)
catalog.createTable(prepareTable(sparkSession, analyzedPlan), ignoreIfExists = false)
} else {
// Handle this type of SQL: ` CREATE VIEW v0 AS SELECT... `
// Throw an exception when the target view already exists
QueryCompilationErrors.viewAlreadyExistsError(name)
}
} else {
// If it does not exist, create the view
catalog.createTable(prepareTable(sparkSession, analyzedPlan), ignoreIfExists = false)
}
Seq.empty[Row]
}
What is the method of creating temporary views in SessionCatalog?
def createTempView(
name: String,
viewDefinition: TemporaryViewRelation,
overrideIfExists: Boolean): Unit = synchronized {
val table = formatTableName(name)
if (tempViews.contains(table) && !overrideIfExists) {
throw new TempTableAlreadyExistsException(name)
}
tempViews.put(table, viewDefinition)
}
The tempViews here is the HashMap we mentioned earlier, indicating that the source of the data has been found~
Now another question comes. What does the data look like?
Let's put this problem aside and take a look at the last step of the above three steps: parsing the view
Parse view
/**
* The current catalog and namespace may be different from that when the view is created. We must resolve the logical meter of the view here
* Row, catalog and namespace are stored in view metadata. This is done by combining catalog and
* namespace It is implemented in "AnalysisContext". When resolving the relationship between single component names
* analyzer The method ` analysiscontext. Will be viewed catalogAndNamespace`. as
* Results ` analysiscontext Catalogandnamespace ` is not empty, analyzer will expand the single component name
* And use it instead of the current catalog and namespace.
*/
private def resolveViews(plan: LogicalPlan): LogicalPlan = plan match {
// The child of the view should be a logical plan resolved from "desc.viewText", and the variable "viewText" should be defined, otherwise we will throw an error when generating the view operator.
case view @ View(desc, isTempView, child) if !child.resolved =>
// Resolve all unresolved relationships and views in child nodes
val newChild = AnalysisContext.withAnalysisContext(desc) {
// Depth of nested views
val nestedViewDepth = AnalysisContext.get.nestedViewDepth
// Maximum allowable depth
val maxNestedViewDepth = AnalysisContext.get.maxNestedViewDepth
if (nestedViewDepth > maxNestedViewDepth) {
throw QueryCompilationErrors.viewDepthExceedsMaxResolutionDepthError(
desc.identifier, maxNestedViewDepth, view)
}
SQLConf.withExistingConf(View.effectiveSQLConf(desc.viewSQLConfigs, isTempView)) {
// Execution child node
executeSameContext(child)
}
}
// Since the unresolved operator is inside the view outside the AnalysisContext, it may be solved incorrectly.
checkAnalysis(newChild)
view.copy(child = newChild)
// An alias subquery object that encapsulates the table name
case p @ SubqueryAlias(_, view: View) =>
// Copy recursive call
p.copy(child = resolveViews(view))
case _ => plan
}
This is essentially a process of recursively calling nested view parsing, and there is nothing worth describing.
After applying rules
After the above series of steps, after the rule resolverelationships is applied, the generated logical plan is as follows:
'Project [*]
+- SubqueryAlias t_user
+- View (`t_user`, [addr#7,age#8L,name#9,sex#10])
+- Relation [addr#7,age#8L,name#9,sex#10] json
Here we return to the above small question: what does the data look like?
What does the data look like?
Before executing the command to create a view, we get a logical plan of LogicalRelation type, so the key is how to print the plan as above?
LogicalRelation.simpleString
override def simpleString(maxFields: Int): String = {
s"Relation ${catalogTable.map(_.identifier.unquotedString).getOrElse("")}" +
s"[${truncatedString(output, ",", maxFields)}] $relation"
}
AttributeReference.toString
override def toString: String = s"$name#${exprId.id}$typeSuffix$delaySuffix"
Combining these two pieces of code, we actually understand a puzzle. The above #7, #8 actually represents the expression ID. this expression is named expression. We actually mentioned it many times in our blog. If you forget it, you might as well look back at the previous content.
ResolveReferences
The ResolveReferences rule is used to replace the unresolved attribute with the specific AttributeReference of the sub node of the logical plan node.
So, how is it realized?
Still the same, let's look at the apply method first:
apply
def apply(plan: LogicalPlan): LogicalPlan = plan.resolveOperatorsUpWithPruning(
AlwaysProcess.fn, ruleId) {
// All children of the this query plan have not been resolved
case p: LogicalPlan if !p.childrenResolved => p
// Wait for rule 'DeduplicateRelations' to resolve conflicting attributes first
case p: LogicalPlan if hasConflictingAttrs(p) => p
// If the projection contains an * sign, expand it.
case p: Project if containsStar(p.projectList) =>
p.copy(projectList = buildExpandedProjectList(p.projectList, p.child))
Project [*]
The Project projection object included in our example obviously has a * sign.
It is worth noting here that after the ResolveRelations rule, the logical plan we get is actually a tree result, in which only the Project node (that is, the root node) will go to the lower branch (our calling rule is actually a recursive calling process, first solving the lower child node, and then solving the upper parent node).
private def buildExpandedProjectList(
exprs: Seq[NamedExpression],
child: LogicalPlan): Seq[NamedExpression] = {
exprs.flatMap {
// API using Dataframe/Dataset: testdata2 groupBy($"a", $"b"). agg($"*")
case s: Star => expand(s, child)
// Using the API of SQL but not running the rule ResolveAlias: SELECT * FROM testData2 group by a, b
case UnresolvedAlias(s: Star, _) => expand(s, child)
// If exprs is a list type, it has multiple elements and contains the * sign
case o if containsStar(o :: Nil) => expandStarExpression(o, child) :: Nil
case o => o :: Nil
}.map(_.asInstanceOf[NamedExpression])
}
Through Project [*], we know that the incoming exprs is actually this *. In the second lecture, we know that the type of * is unresolved Star, which is a subclass of Star type, so it is obvious that the first branch is taken in the above call.
private def expand(s: Star, plan: LogicalPlan): Seq[NamedExpression] = {
// This is used to capture the analysis exceptions thrown inside the closure, and some origin information will be attached to the exception
withPosition(s) {
try {
// Call the expand method of unresolved star
s.expand(plan, resolver)
} catch {
case e: AnalysisException =>
AnalysisContext.get.outerPlan.map {
// Only Project and Aggregate can have star expressions
case u @ (_: Project | _: Aggregate) =>
Try(s.expand(u.children.head, resolver)) match {
case Success(expanded) => expanded.map(wrapOuterReference)
case Failure(_) => throw e
}
// Do not use external plans to parse star expressions
// Because the use of star is invalid
case _ => throw e
}.getOrElse { throw e }
}
}
}
*
Let's take another look at the expand method of unresolved star
override def expand(
input: LogicalPlan,
resolver: Resolver): Seq[NamedExpression] = {
// If no table is specified, all non hidden properties are used
if (target.isEmpty) return input.output
// If a table is specified, the hidden attribute must also be used
val hiddenOutput = input.metadataOutput.filter(_.supportsQualifiedStar)
val expandedAttributes = (hiddenOutput ++ input.output).filter(
matchedQualifier(_, target.get, resolver))
if (expandedAttributes.nonEmpty) return expandedAttributes
// An attempt was made to resolve it to a struct type extension.
val attribute = input.resolve(target.get, resolver)
if (attribute.isDefined) {
// If the target can be resolved into an attribute of a child node, it must be a structure and need to be extended
attribute.get.dataType match {
case s: StructType => s.zipWithIndex.map {
case (f, i) =>
val extract = GetStructField(attribute.get, i)
Alias(extract, f.name)()
}
case _ =>
throw QueryCompilationErrors.starExpandDataTypeNotSupportedError(target.get)
}
} else {
val from = input.inputSet.map(_.name).mkString(", ")
val targetString = target.get.mkString(".")
throw QueryCompilationErrors.cannotResolveStarExpandGivenInputColumnsError(
targetString, from)
}
}
Since we are only a *, not like a. *, the target is empty. We directly return in the first step, that is, return input Output, here comes the question: what is input?
input
Through previous analysishelper It can be seen from the source code analysis of resolveoperators upwithpruning (i.e. the previous section on recursive application of partial functions):
The input of each rule is the output of its child nodes after applying the rule
Therefore, input is the output of the child node of Project [*] after applying the rule, that is
+- SubqueryAlias t_user
+- View (`t_user`, [addr#7,age#8L,name#9,sex#10])
+- Relation [addr#7,age#8L,name#9,sex#10] json
SubqueryAlias and its child nodes have not changed since the rule was applied.
Therefore, input Output is subqueryalias output
SubqueryAlias.output
override def output: Seq[Attribute] = {
// Concatenate identifiers
val qualifierList = identifier.qualifier :+ alias
child.output.map(_.withQualifier(qualifierList))
}
SubqueryAlias. What output does is concatenate identifiers including child nodes.
What does the final parsed logical plan look like?
Project [addr#8, age#9L, name#10, sex#11]
+- SubqueryAlias t_user
+- View (`t_user`, [addr#8,age#9L,name#10,sex#11])
+- Relation [addr#8,age#9L,name#10,sex#11] json
As usual, let's draw a table to match the above output with the specific source code:
| Corresponding source code | explain | |
|---|---|---|
| Project | org.apache.spark.sql.catalyst.plans.logical.Project | Projection object |
| [addr#8, age#9L, name#10, sex#11] | SubqueryAlias.output | Concatenate identifiers including child nodes, where the number represents the ID of NamedExpression. |
| SubqueryAlias | org.apache.spark.sql.catalyst.plans.logical.SubqueryAlias | An alias subquery object that encapsulates the table name |
| t_user | SubqueryAlias.alias | Table alias |
| View | org.apache.spark.sql.catalyst.plans.logical.View | View object |
| (t_user, [addr#8,age#9L,name#10,sex#11]) | View.simpleString | The identifier and attribute sequence of the table, where the number represents the ID of NamedExpression. |
| Relation [addr#8,age#9L,name#10,sex#11] json | LogicalRelation.simpleString | Attribute sequence and relationship name, where the number represents the ID of NamedExpression. |
Why is it different from the output of Analyzed Logical Plan?
In the first lecture, we have actually given the final output of the analysis stage in advance:
== Analyzed Logical Plan ==
addr: array<string>, age: bigint, name: string, sex: string
Project [addr#7, age#8L, name#9, sex#10]
+- SubqueryAlias t_user
+- View (`t_user`, [addr#7,age#8L,name#9,sex#10])
+- Relation [addr#7,age#8L,name#9,sex#10] json
Why is it different from the above logical plan printing?
We can start from queryexecution Find the answer in writeplans
append("\n== Analyzed Logical Plan ==\n")
try {
if (analyzed.output.nonEmpty) {
append(
truncatedString(
analyzed.output.map(o => s"${o.name}: ${o.dataType.simpleString}"), ", ", maxFields)
)
append("\n")
}
QueryPlan.append(analyzed, append, verbose, addSuffix, maxFields)
You can see that the attribute name and type will be printed before printing the generated logical plan.
Summary
This lecture is about the source code analysis of the analysis phase of Spark SQL workflow.
We have made clear our goal - we need to further analyze the AST generated in the parsing phase.
After determining the goal, we first calculated what we had at hand - a temporary view: t_user and inferred the field name and field type from the JSON file.
Then we start the source code analysis of the main process, starting from the entrance, and talking about execution and verification.
At this time, we came into contact with the concept of rule Batch, and we combed all rule batches.
Due to space constraints, it is impossible for us to explain in detail how each rule is implemented.
Therefore, we return to our original example. By analyzing this simple and direct example, we can help us by analogy.
We analyzed in detail how the two rules of ResolveRelations and ResolveReferences act on our logical plan step by step, and finally completed the analysis stage.
So far, I believe you have a glance at the basic process of the analysis stage.
Please see the students here help three times and support one wave. Thank you very much~